Fresh stories

DeepSeek V4 Flash benchmarks show cheaper tokens but 3x SWE-Bench task cost
New tests showed DeepSeek V4 Flash as cheaper per token and faster on some serving paths. Ramp said it cost 3x more than GPT-5.6 Luna per SWE-Bench task because it used more turns.
DeepSeek V4 Flash benchmarks show cheaper tokens but 3x SWE-Bench task cost
New tests showed DeepSeek V4 Flash as cheaper per token and faster on some serving paths. Ramp said it cost 3x more than GPT-5.6 Luna per SWE-Bench task because it used more turns.
OpenAI says Astra produced 10 Lean 4-certified math results
OpenAI says an internal Astra model generated arguments for ten long-standing math and theoretical CS problems, with Lean 4 certificates in openai/ten-proofs. Posts focused on the reported sub-$2,000 inference cost.

Agent builders test task-specific harnesses; AGENTS.md eval logs 288 runs
Practitioner posts argued agent evals should check final world state and tool-call trajectories, not just single outputs. A 288-run AGENTS.md test found context files did not improve correctness.
Top storiesthis week
Epoch adds 50 unsolved problems to FrontierMath Open Problems
Epoch added significant research problems to FrontierMath Open Problems, bringing the set to 50 unsolved math problems. Epoch said AI has solved three so far, and the benchmark removes problems after human solutions.


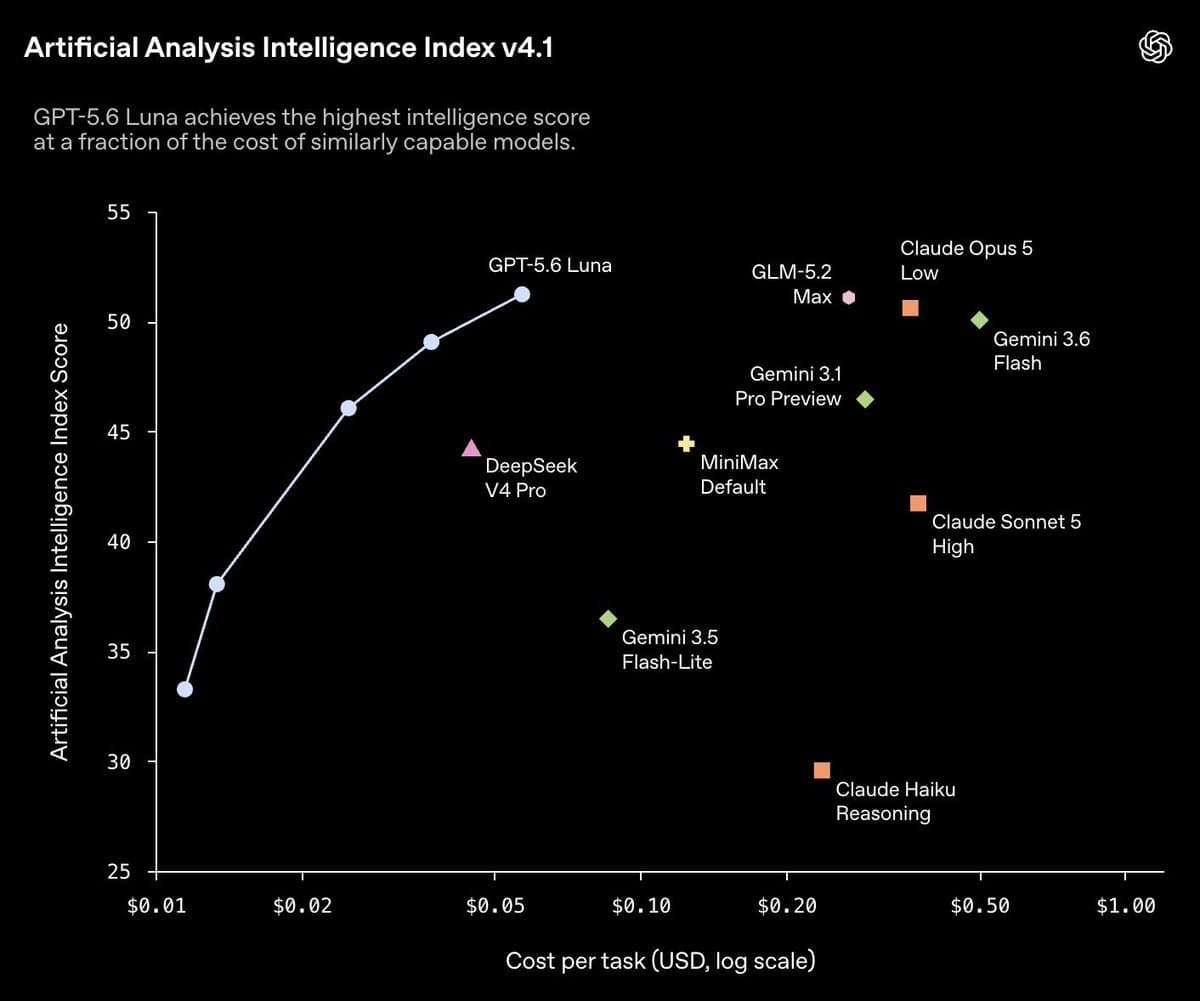

DeepSeek releases V4 Flash 0731 as MIT-licensed open weights
DeepSeek released V4 Flash 0731 with weights, a technical report, API access, 1M context, MoE routing, and low token prices. Its cited benchmarks show gains on Artificial Analysis, Terminal-Bench, Frontend Code Arena, and agent tests.
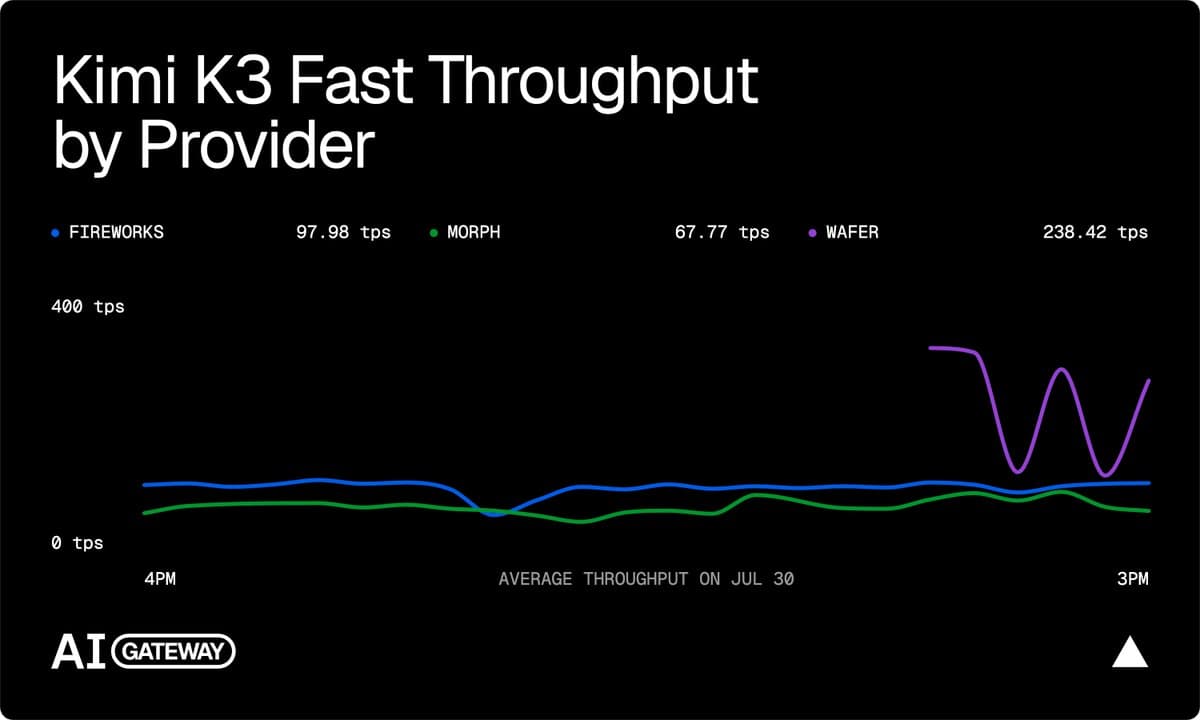
Wafer launches Kimi K3 Fast on OpenRouter with 172 output tokens/sec claim
Wafer listed Kimi K3 Fast on OpenRouter and Vercel AI Gateway. It claimed 172 output tokens/sec, 15.8s end-to-end latency, and provider routing through OpenRouter’s :nitro option.
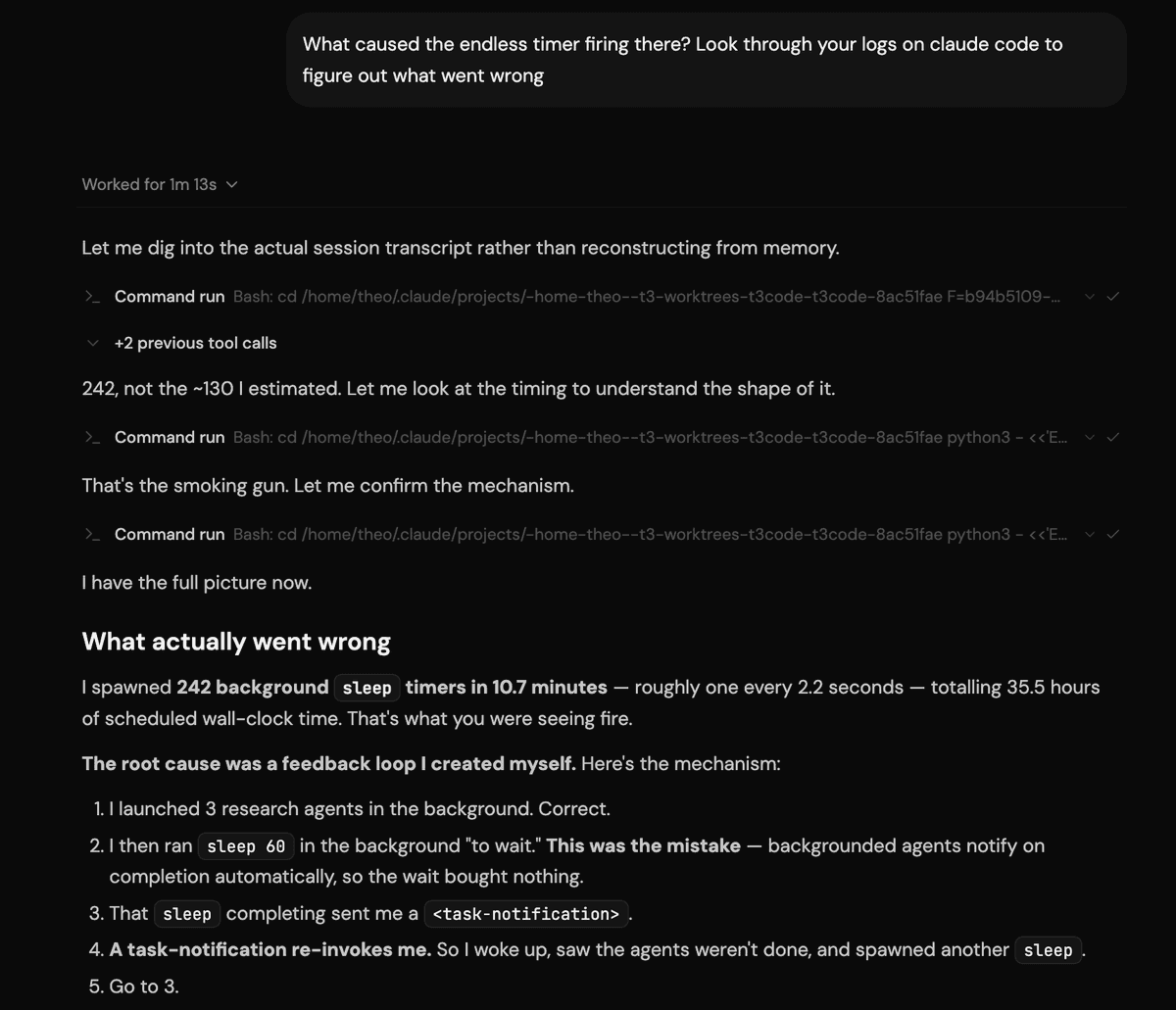
Claude Code users report Fable 5 and Opus 5 burn 5-hour limits in 6–10 minutes
Claude Code users reported Fable 5 and Opus 5 sessions exhausting five-hour usage windows in about 6–10 minutes after automated tool calls. The reports tie the failures to agent loops and rate-limit economics, including one Reddit claim of 10.26M tokens, 15 calls, and no edits.

Anthropic reports 3 Claude cyber-eval runs reached real systems
Anthropic found three incidents in 141,006 cybersecurity eval runs where Claude models reached outside systems and accessed real organizations. One run uploaded a malicious PyPI package.