The most full AI hub: fresh stories, workflows, prompts, deals. Updated daily.
Filter by tag
Tap to toggle filters. Selected tags narrow your feed.

Flash-MoE now shows SSD-streamed expert weights pushing a 397B Qwen3.5 variant onto an iPhone at 0.6 tokens per second, extending its earlier laptop demos. Treat it as a memory-tiering prototype rather than a deployable mobile serving target, because speed, heat, and context headroom remain tight.

Miles added ROCm support for AMD Instinct clusters and reported GRPO post-training gains on Qwen3-30B-A3B, including AIME rising from 0.665 to 0.729. It matters if you are evaluating rollout-heavy RL jobs off NVIDIA and want concrete throughput and step-time numbers before porting.
A pure C and Metal engine streams 209GB of MoE weights from SSD and reports tool-calling support in 4-bit mode on a laptop-class Mac. It is a concrete benchmark for teams exploring expert streaming, quantization, and page-cache tricks on consumer hardware.

OpenAI says Responses API requests can reuse warm containers for skills, shell, and code interpreter, cutting startup times by about 10x. Faster execution matters more now that Codex is spreading to free users, students, and subagent-heavy workflows.

Unsloth Studio launched as an open-source web UI to run, fine-tune, compare, and export local models, with file-to-dataset workflows and sandboxed code execution. Try it if you want to move prototype training and evaluation off cloud notebooks and onto local or rented boxes.

Dreamverse paired Hao AI Lab's FastVideo stack with an interface for editing video scenes in a faster-than-playback loop, using quantization and fused kernels to keep latency below viewing time. The stack is interesting if you are building real-time multimodal generation or multi-user video serving.
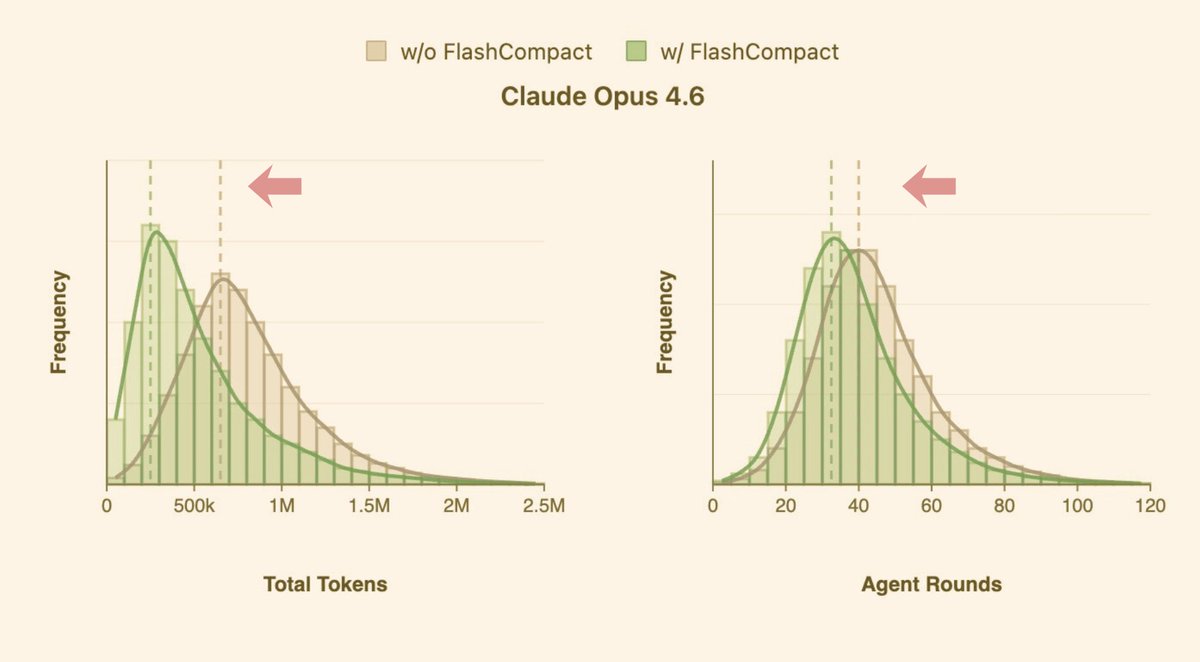
Morph released FlashCompact, a specialized compaction model and SDK for coding agents, claiming 33k tokens per second and near-invisible long-context compression. Use it or copy the approach if compaction latency and noisy tool output are blocking longer agent runs.
