The most full AI hub: fresh stories, workflows, prompts, deals. Updated daily.
Filter by tag
Tap to toggle filters. Selected tags narrow your feed.

OpenHands introduced EvoClaw, a benchmark that reconstructs milestone DAGs from repo history to test continuous software evolution instead of isolated tasks. The first results show agents can clear single tasks yet still collapse under regressions and technical debt over longer runs.

LLM Debate Benchmark ran 1,162 side-swapped debates across 21 models and ranked Sonnet 4.6 first, ahead of GPT-5.4 high. It adds a stronger adversarial eval pattern for judge or debate systems, but you should still inspect content-block rates and judge selection when reading the leaderboard.
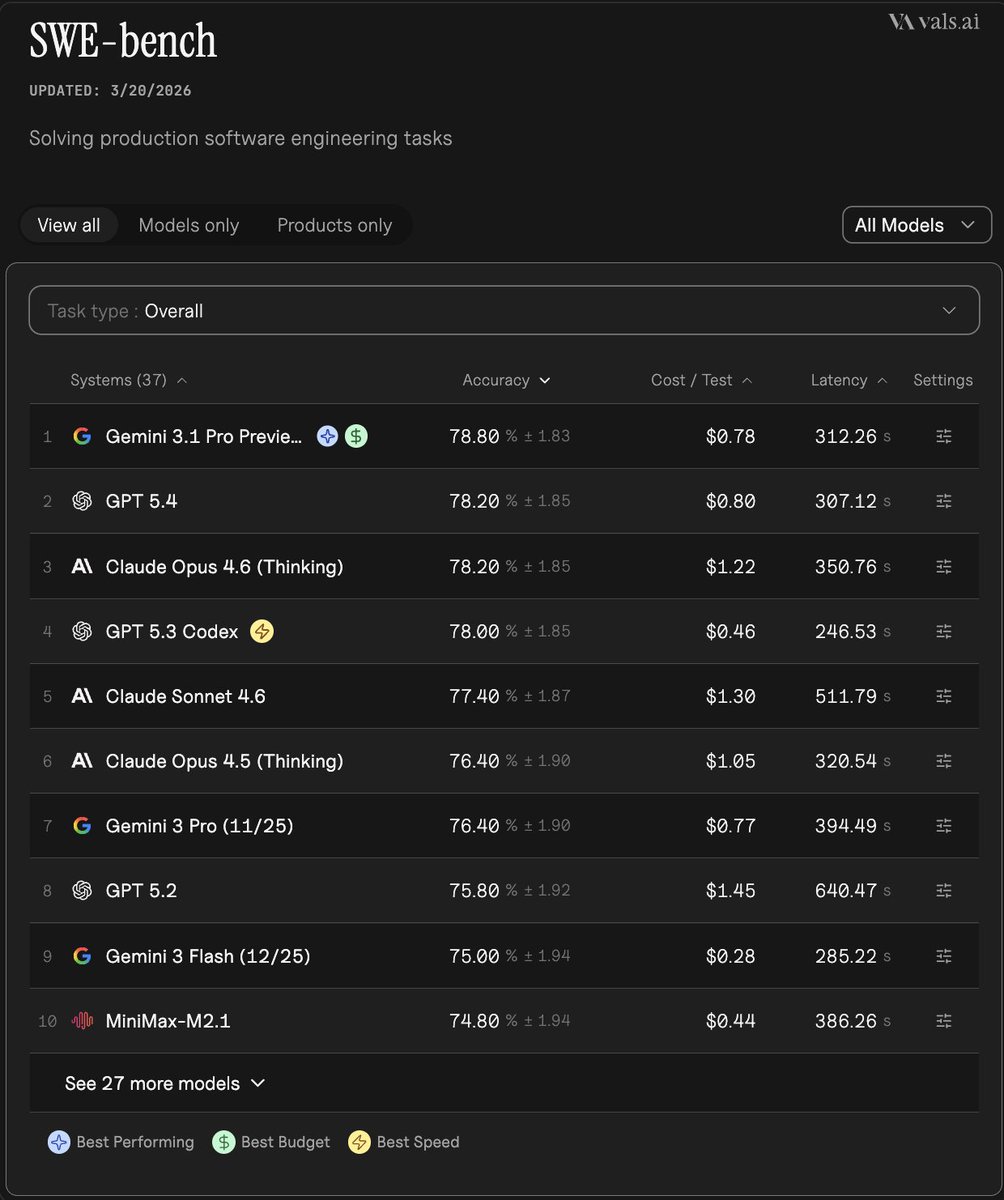
Vals AI switched SWE-Bench Verified from SWE-Agent to the bash-only mini-swe-agent harness, aligning results more closely with the official benchmark setup. Top score dipped slightly to 78.8%, but the change reduces harness-specific confounds when comparing models.
The toolkit sweeps contiguous layer ranges in GGUF and llama.cpp-style setups to test whether duplicating them can unlock better reasoning without retraining. Treat the jump as a reproducible experiment, not a settled mechanism, because thread responses challenge whether the effect reflects circuits, routing, or training artifacts.


Vercel's Next.js evals place Composer 2 second, ahead of Opus and Gemini despite the recent Kimi-base controversy. The result matters because it separates base-model branding from measured task performance on a real framework workflow.

A developer says an autoresearch loop hill-climbed a vibecoded Rust engine to 2718 Elo after running more than 70 experiments under a 500 ms move budget. The real takeaway is the workflow: automated experiment loops can optimize code against a measurable target.

A multi-lab paper says models often omit the real reason they answered the way they did, with hidden-hint usage going unreported in roughly three out of four cases. Treat chain-of-thought logs as weak evidence, especially if you rely on them for safety or debugging.

Physical Intelligence says its RL token compresses VLA state into a lightweight signal that an on-robot actor-critic can adapt in minutes. This matters for last-millimeter manipulation, where full-size models are often too slow or too coarse to tune online.




