OpenHands introduced EvoClaw, a benchmark that reconstructs milestone DAGs from repo history to test continuous software evolution instead of isolated tasks. The first results show agents can clear single tasks yet still collapse under regressions and technical debt over longer runs.

OpenHands' launch thread positions EvoClaw as a shift away from one-shot coding evals and toward the harder question of codebase maintenance across evolving requirements. The benchmark is built with OpenHands and evaluates agents on sequences of changes derived from real repositories rather than synthetic standalone tickets.
The design choice in the milestone post is to reconstruct milestone DAGs from repo history, so tasks are “meaningful, executable, and dependent on what came before.” That gives the benchmark a way to score not just whether an agent can land a patch, but whether it can extend a project without breaking earlier work. OpenHands' blog, paper, and leaderboard expand that setup beyond the thread.
The headline number from the results post is that continuous evolution is much harder than isolated tasks: scores that can exceed 80% on single tasks fall to a best overall score of 38.03% once agents have to operate across dependent milestones. OpenHands also separates “overall score” from “resolve rate,” with Claude Opus 4.6 plus OpenHands topping the former and Gemini 3 Pro plus Gemini CLI reaching the highest resolve rate at 13.37%.
The failure mode matters as much as the score. In the failure analysis, OpenHands says recall “keeps climbing,” meaning agents still add requested functionality, but precision “saturates much earlier,” so regressions accumulate faster than they can be repaired. The error-chain post adds that unresolved failures then propagate downstream through milestone dependencies, which makes long-horizon coding look less like a code-generation problem and more like a system-health problem. OpenHands' resource roundup calls EvoClaw “the benchmark to watch” for long-running coding agents, mainly because it exposes this maintenance gap directly.
LLM Debate Benchmark ran 1,162 side-swapped debates across 21 models and ranked Sonnet 4.6 first, ahead of GPT-5.4 high. It adds a stronger adversarial eval pattern for judge or debate systems, but you should still inspect content-block rates and judge selection when reading the leaderboard.
 release
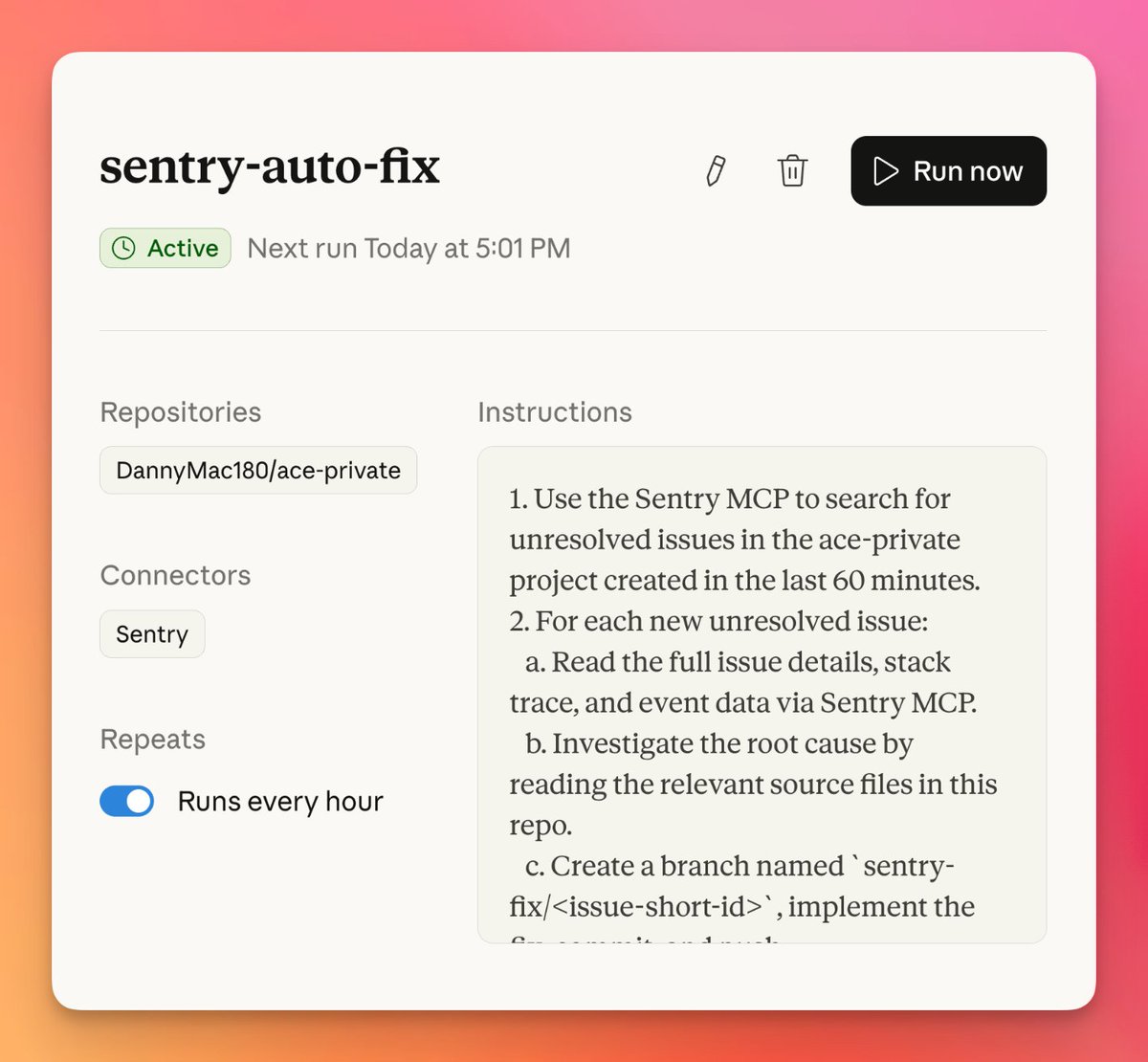
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.

Result: isolated-task scores can exceed 80%, but performance drops hard in continuous evolution. Best overall score: 38.03% (Claude Opus 4.6 + OpenHands) Highest resolve rate: 13.37% (Gemini 3 Pro + Gemini CLI)

EvoClaw's error-chain analysis shows how unresolved failures propagate downstream through milestone dependencies. Long-horizon coding is less about generating more code and more about preserving system health over time.