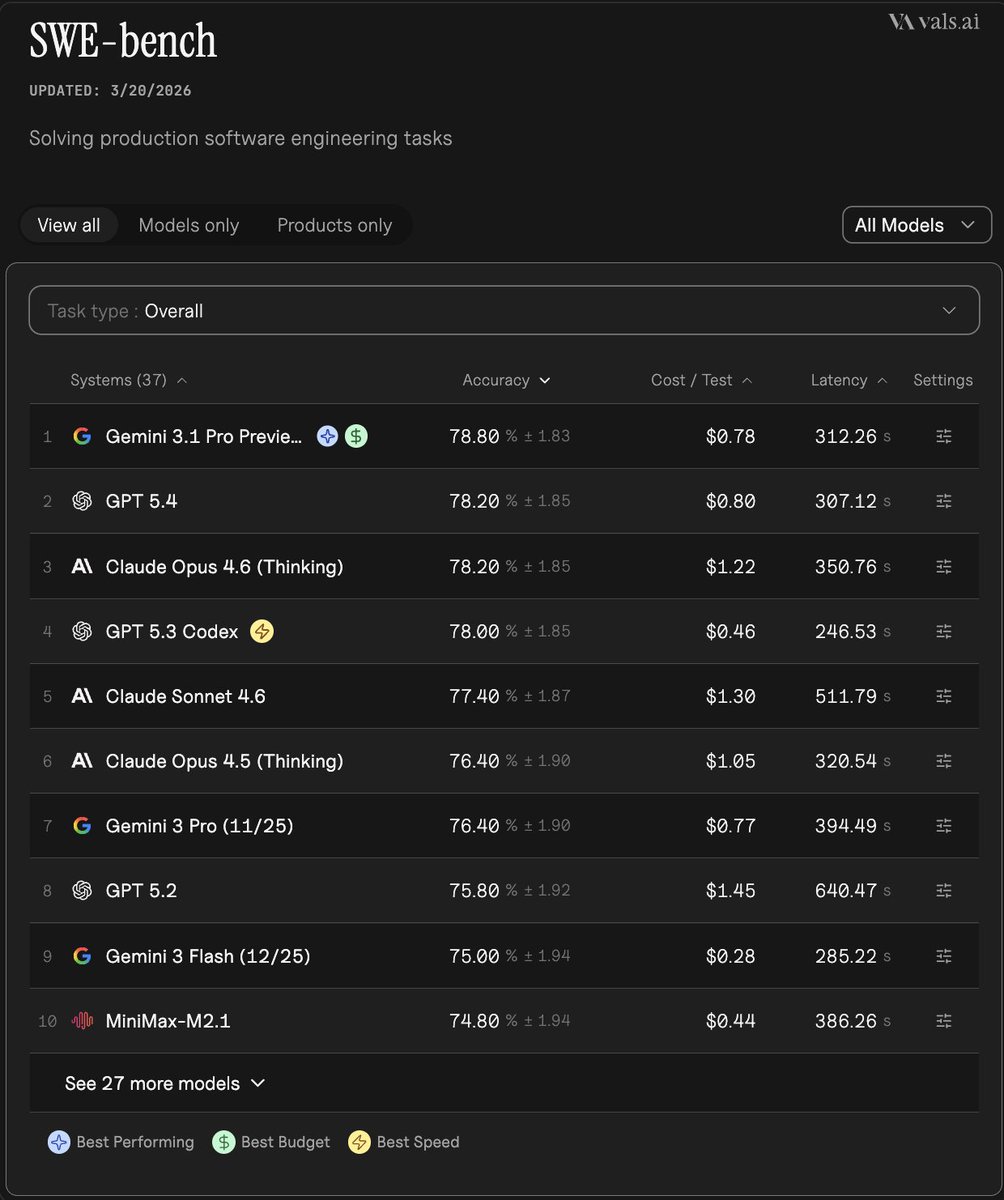
LLM Debate Benchmark ran 1,162 side-swapped debates across 21 models and ranked Sonnet 4.6 first, ahead of GPT-5.4 high. It adds a stronger adversarial eval pattern for judge or debate systems, but you should still inspect content-block rates and judge selection when reading the leaderboard.

This eval tests debate, not just answer generation. According to the benchmark thread, it targets “adversarial, multi-turn debates,” where models must combine factual recall, rebuttal quality, and consistency across several rounds. That is closer to how judge models, debate agents, and structured planning systems fail in production than a static single-turn benchmark.
The task mix is broad enough to stress generality rather than a narrow policy niche. Mazur’s coverage note says the set spans 683 curated motions, from shrinkflation labeling to eurozone fallout and dating-app market structure. The released examples in quotable lines show why this is interesting for practitioners: models are being judged on whether they can produce concise, defensible claims such as “You cannot reject a trap you cannot see” or “It is exclusion protected by aesthetics,” not just retrieve facts.
The design has a few strong controls. Mazur’s format details says each debate runs 10 turns with openings, two rebuttals, a pressure-question exchange, and closings. Rankings are computed with Bradley-Terry over side-swapped matchups, which helps control for topic asymmetry. Completed debates are judged by three LLM judges drawn from six models, and the judging setup says same-family judging against the debaters is excluded.
The leaderboard still needs to be read with caveats. The coverage note includes content-block rates, which can change effective participation and comparability across motions. The sample transcript in sample debate also shows how much the results depend on prompt format and interaction structure: a Sonnet 4.6 adaptive vs. GPT-5.4 high match turns on whether consent creates a meaningful “paper trail” or just “consent theater,” and even the judge notes split across winners. That makes judge composition and transcript inspection part of the eval, not an afterthought.
The project is unusually inspectable. The long-form posts in full thread mirror and release thread point to charts, transcripts, model profiles, reports, judgments, and the GitHub repo; repo link post separately surfaces the code link. For teams building debate, arbitration, or self-critique systems, that makes this more useful as a reproducible eval pattern than as a simple winner board.
OpenHands introduced EvoClaw, a benchmark that reconstructs milestone DAGs from repo history to test continuous software evolution instead of isolated tasks. The first results show agents can clear single tasks yet still collapse under regressions and technical debt over longer runs.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
Some quotable lines: Encryption backdoors, Claude Sonnet 4.6 (no reasoning): "Children don't disappear in percentages. They disappear one at a time, in exactly these cases." Historic-district housing, GPT-5.4 (high reasoning): "If preservation wins even there, then it is not Show more
Each completed debate is judged by a panel of three judges drawn from six LLM judges: Sonnet 4.6 (high), GPT-5.4 (high), Gemini 3.1 Pro, Grok 4.20 Beta 0309 (Reasoning), Qwen3.5-397B-A17B, and Kimi K2.5 Thinking. Same-family judging against the debaters is avoided.

Which LLM is the best debater? New LLM Debate Benchmark! Models debate the same motion twice with sides swapped. A wide variety of controversial and relevant topics. 21 models, 1,162 debates. Sonnet 4.6 (high) is #1, ahead of GPT-5.4 (high). GLM-5 is the open weights leader.

Sample debate: - proposition: Governments should prohibit data brokers from selling individuals’ precise location data without explicit, time-limited opt-in consent. - model_pro: claude-sonnet-4-6-adaptive - model_con: gpt-5.4-high Turn 1: PRO Opening - model: Show more