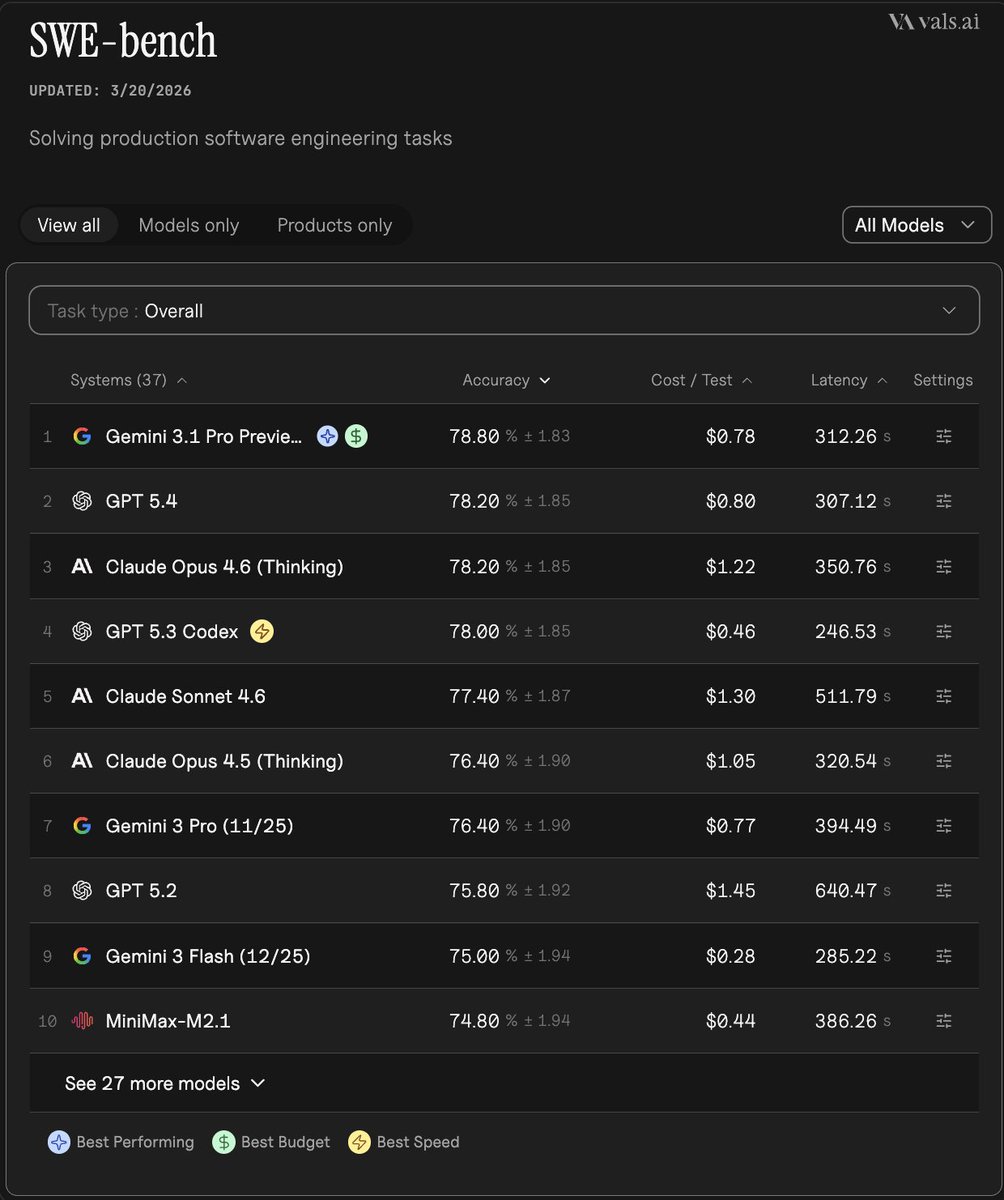
Epoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.

Epoch says the solved item is a "Moderately Interesting" FrontierMath Open Problems entry: a conjecture from a 2019 paper by Will Brian and Paul Larson. In the follow-up post, Epoch says Brian had tried and failed to solve it both at the time of writing and in later attempts, which makes the claim more meaningful than a benchmark win on a synthetic task.
The linked problem page identifies the problem as a Ramsey-style hypergraph construction question and says GPT-5.4 Pro produced a solution that Brian confirmed. Epoch's publication update says Brian now plans to write up the result for publication, "possibly including follow-on work" generated by the model's ideas.
A context post quoting Brian's statement says the AI approach "works out perfectly" and "eliminates an inefficiency" in the prior lower-bound construction, which is the clearest public hint so far about what changed technically in the proof idea Brian quote screenshot.
Epoch is not presenting this as a single lucky prompt. In the main replication claim, it says Kevin Barreto and Liam Price first elicited a solution from GPT-5.4 Pro and that a third user did so shortly after, suggesting the result can be recovered by multiple operators rather than one irreproducible conversation.
More importantly for engineers building evals, Epoch says it reproduced the solve in its own scaffold. Its scaffold result says Gemini 3.1 Pro, GPT-5.4 xhigh, and Opus 4.6 max are all able to solve the problem "at least some of the time," which points to a harnessable capability rather than a model-specific anecdote.
Epoch also says the problem-page post includes a full chat transcript for GPT-5.4 Pro's original solution plus other models' solutions from the harness. That makes this unusually inspectable for a frontier-model math claim, even if the underlying success probabilities, prompt sensitivity, and verification costs are still not quantified in the thread.
The practical takeaway is that frontier models look increasingly useful as research assistants on hard formal problems, but only under heavy elicitation and verification. In the Tao discussion, Terence Tao describes current models as a "trustworthy coworker" for applying standard techniques, while also saying their broader hit rate on hard math remains around 1-2%.
That framing matters here. Epoch's own benchmark overview says only one of the four "Moderately Interesting" problems is solved so far, with every higher-importance tier still at zero. A reaction screenshot makes that breakdown explicit as 1/4 solved in the lowest tier and 0/11 in the more ambitious tiers scoreboard image.
So this story is best read as a reproducible milestone for evaluation design and assisted theorem discovery. It is not yet evidence that a lab can hand frontier models an open-problem queue and expect reliable autonomous research throughput.
OpenHands introduced EvoClaw, a benchmark that reconstructs milestone DAGs from repo history to test continuous software evolution instead of isolated tasks. The first results show agents can clear single tasks yet still collapse under regressions and technical debt over longer runs.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
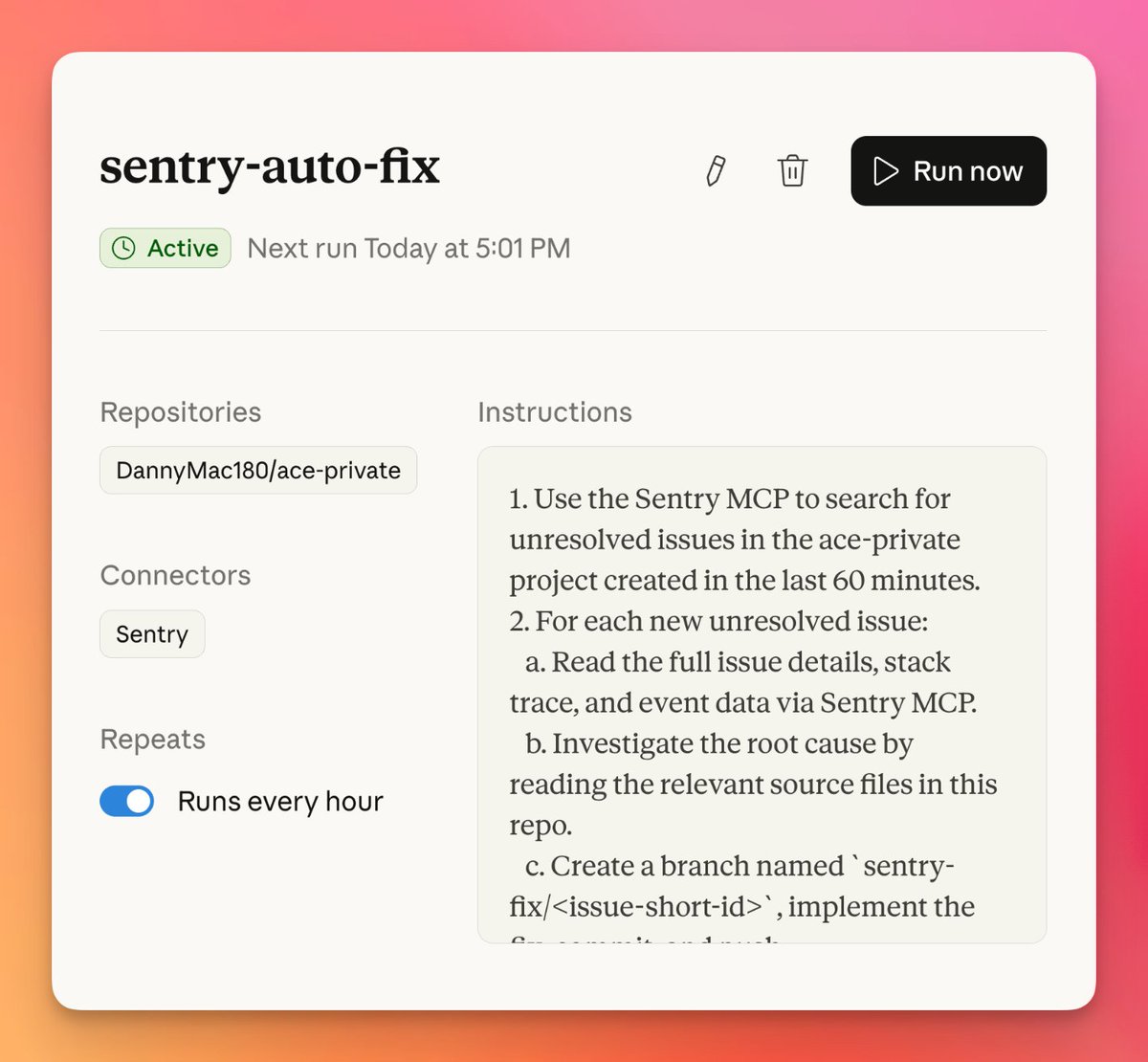 breaking
breakingClaude can now drive macOS apps, browser tabs, the keyboard, and the mouse from Claude Cowork and Claude Code, with permission prompts when it needs direct screen access. That makes legacy desktop workflows automatable, and Anthropic is pairing the push with more background-task support for longer agent loops.
AI has solved 50 Erdős problems in the last year. But on a wider sweep of problems, the models’ success rate is only about 1-2%: labs have just been publishing the wins. This isn’t because AI isn’t useful for mathematicians. Terence Tao thinks the models are currently at theShow more
AI has solved one of the problems in FrontierMath: Open Problems, our benchmark of real research problems that mathematicians have tried and failed to solve. See thread for more.

Congratulations to @AcerFur and @Liam06972452, who first elicited a solution from GPT-5.4 Pro! They have the option to be coauthors, with Brian, on any resulting paper. Congratulations also to @spicey_lemonade who elicited a solution shortly thereafter.