OpenHands published a skill-eval recipe with bounded tasks, deterministic verifiers, and no-skill baselines, then showed some skills speed agents up while others make them brittle. Teams shipping skill libraries should measure them per task and model before rollout.

OpenHands' core claim is simple: a skill is not useful just because an agent completes a task after you add it. Its evaluation recipe says a credible test needs three parts: "a bounded task," "a deterministic verifier," and "a no-skill baseline." That setup is meant to isolate whether the skill changed outcomes, rather than rewarding prompt stuffing or unconstrained demos.
The team packaged that into a public tutorial repo and a blog post that walk through running the same task with and without a skill. The examples span dependency audits, financial-report extraction, and sales analysis, which makes the project more of an evaluation recipe than a single benchmark blog and tutorial.
The strongest result came from the dependency-audit task. In OpenHands' dependency audit result, the agent had to inspect a package-lock.json and produce a vulnerability report. Without the skill, pass rate was 0%. With it, pass rate hit 100%, and runtime dropped by more than half, from 266 seconds to 109 seconds. OpenHands' explanation is that some skills are "essential" because they encode the workflow the task actually requires.
A second task showed a much smaller gain. The financial extraction result says most models already passed financial-report extraction 90% of the time without help. Adding a skill that supplied exact formulas and told the agent to use Python for arithmetic pushed that to 100%. That looks less like new capability than a guardrail for occasional arithmetic or procedure errors.
The most useful result for engineering teams may be the negative one. In the sales-pivot analysis task, overall pass rate improved from 70% to 80%, but OpenHands says the effect "varied by model" and that one skill made at least one model less reliable by nudging it into a brittle execution path sales pivot result. That is the practical warning behind the whole release: skill libraries need per-task, per-model measurement before rollout, not blanket assumptions that more scaffolding helps.
Vals AI switched SWE-Bench Verified from SWE-Agent to the bash-only mini-swe-agent harness, aligning results more closely with the official benchmark setup. Top score dipped slightly to 78.8%, but the change reduces harness-specific confounds when comparing models.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
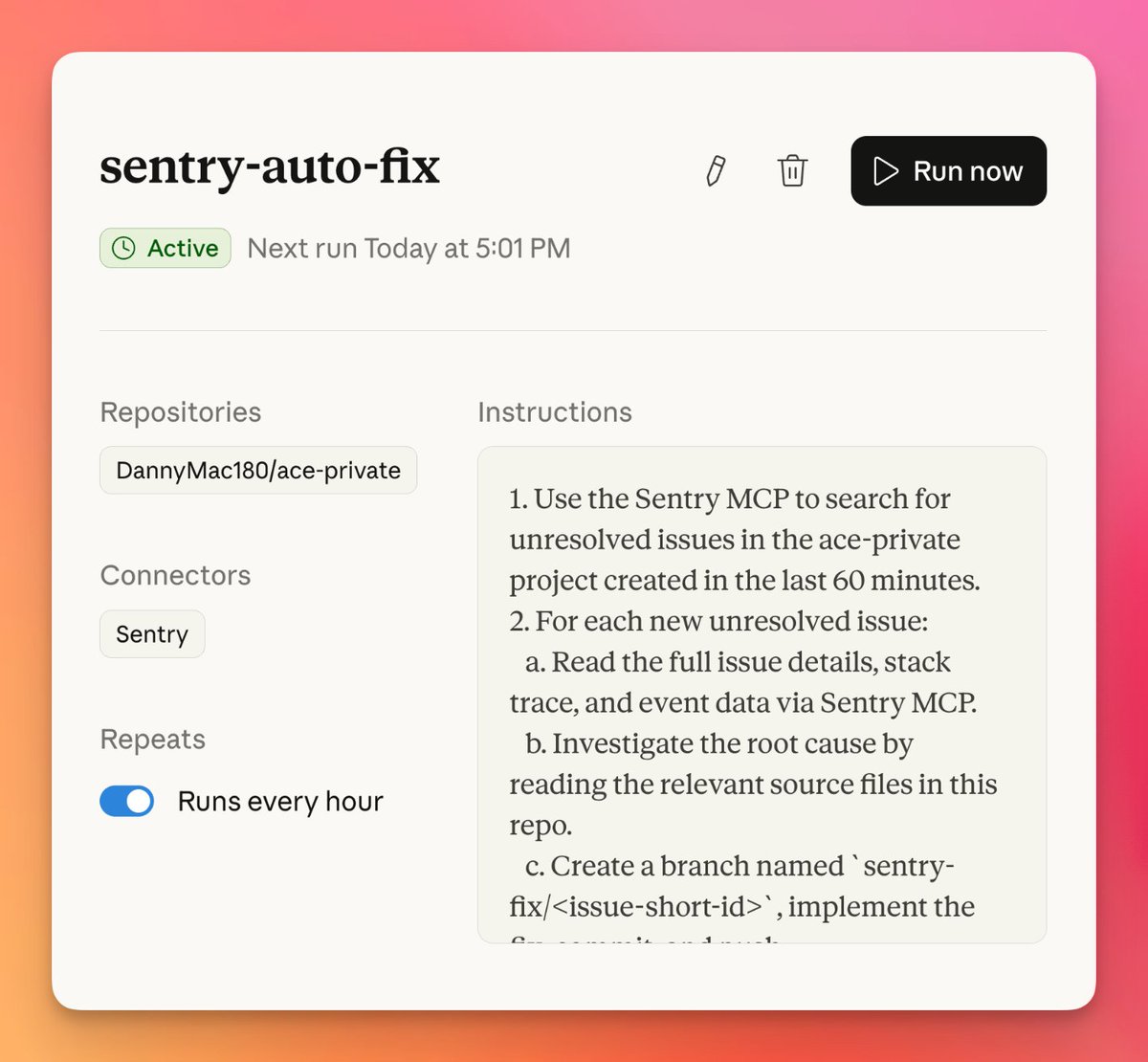
Skills are becoming a core building block for AI coding agents. But some skills make the agent worse. We ran three tasks across five models to show how to measure when skills actually help - and when they don't.

Check out our new research project with OpenHands community members and CMU on training the strongest open-source language model for agentic code search!
Can we train code agents to search relevant locations in a codebase only using a terminal? Introducing CodeScout: an effective RL recipe for code search 🚀 🏆 Outperforms 18x larger OSS LLMs 🔥 Comparable to proprietary LLMs 📈 SoTA on SWE-Bench Verified, Pro, & Lite 🧵 [1/N]

Task 3: sales pivot analysis. Overall pass rate went from 70% to 80% with the skill. But the effect varied by model. Some improved. Some regressed. The skill nudged one model into a brittle path that made it less reliable. Skills can be counterproductive. You have to measure.