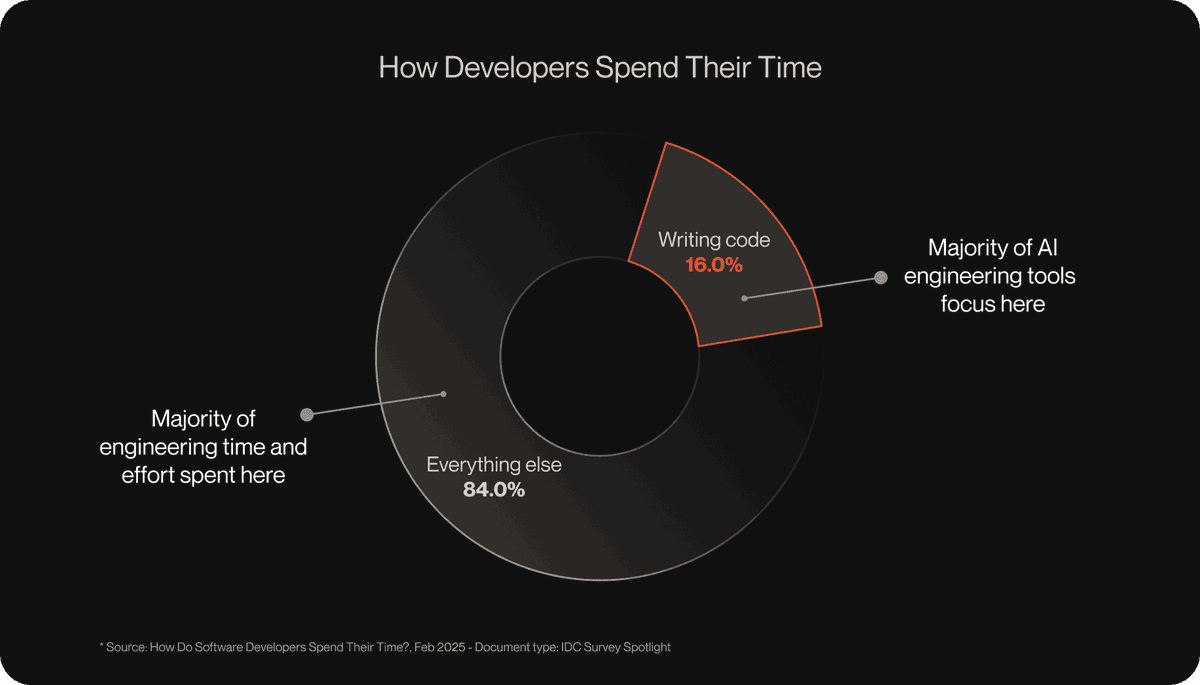
W&B shipped robotics-focused evaluation views including synchronized video playback, pinned run baselines, semantic coloring, and side-by-side media comparisons. These tools matter if your model outputs are videos or trajectories and loss curves alone hide failure modes.

W&B is positioning these updates as tooling for teams whose outputs are easier to inspect visually than numerically. In its launch thread, the company says robotics AI evaluation is "uniquely hard" because models "perceive, reason, and act in the physical world," so regressions often show up in clips and trajectories before they show up in aggregate metrics robotics eval thread.
The new workspace features are aimed at that gap. W&B's walkthrough thread lists four additions: synchronized video playback, pinned runs with a baseline view, semantic coloring, and side-by-side media comparison. The company also published a fuller walkthrough via the demo page, framing the release around robotics, simulation, and embodied AI teams.
The most deployment-relevant feature is synchronized playback for experiment videos. W&B says teams can compare runs "side by side, perfectly in sync" to spot "timing changes, control instability, perception errors instantly" synced playback demo. That matters for policy iteration where two runs may have similar scalar metrics but diverge on contact timing, recovery behavior, or sensor interpretation.
Pinned baselines make the workspace act more like a persistent eval bench than a scrolling run list. According to W&B's baseline comparison post, users can lock a reference experiment at the top, set a baseline, and pin up to five runs with those references highlighted directly in line plots. That gives teams a fixed comparator when they are testing new checkpoints, reward settings, or sim configs.
The other two changes reduce manual sorting. W&B's semantic coloring post says runs can now be automatically grouped and color-coded by parameter or metric, which is useful when a sweep spans hundreds of configurations. Its comparison post also says users can place up to four images or videos from different runs in one workspace, while a fan-out view shows how outputs evolve across training steps. The practical claim is simple: less downloading files, less stitching clips together, and faster visual review inside the experiment dashboard comparison post.
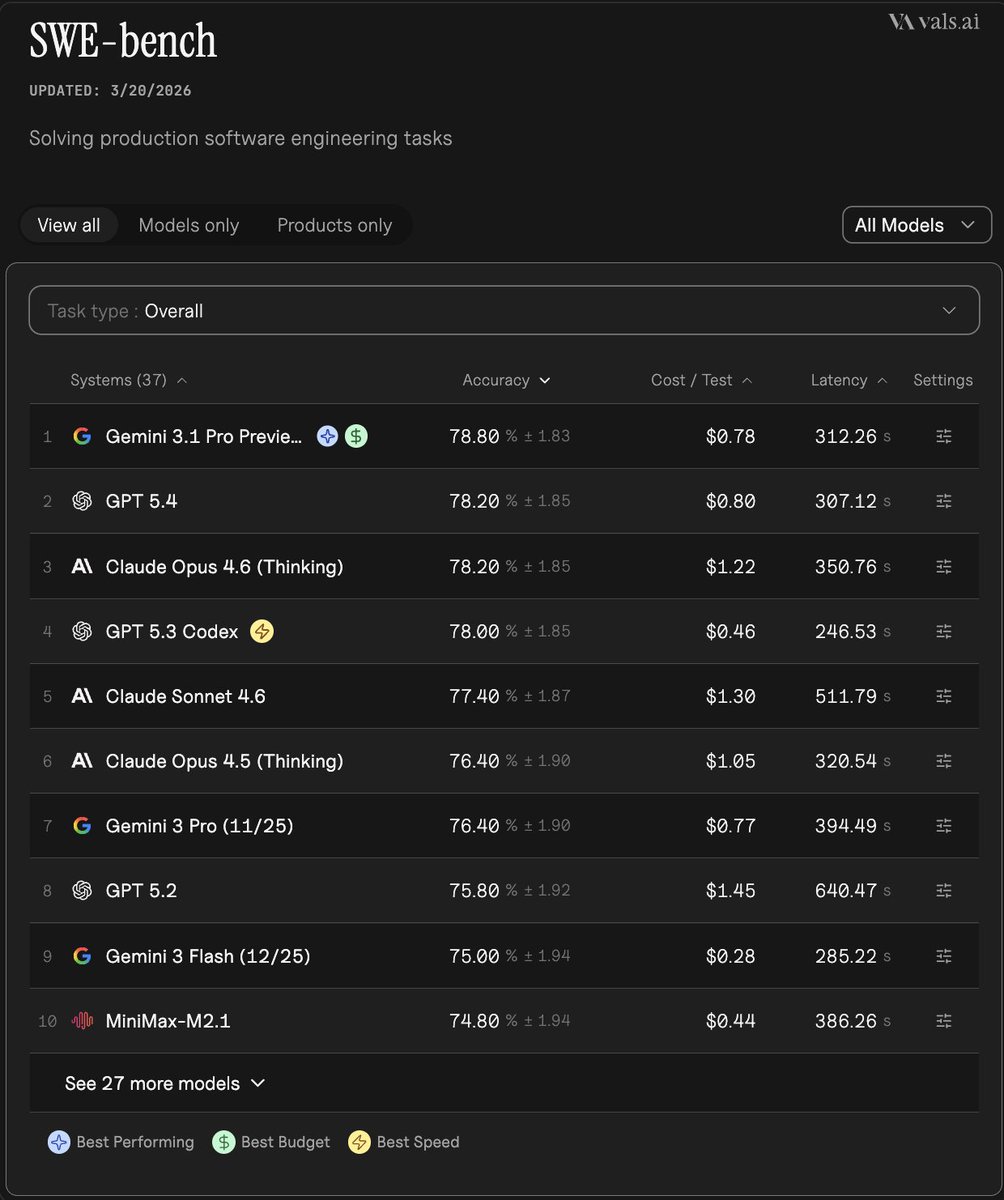
Epoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
Robotics AI evaluation is uniquely hard. Your models perceive, reason, and act in the physical world. Outputs are videos, trajectories, sim results, not just loss curves. We shipped tools in W&B Models built for exactly this! 👇

Pinned runs and baseline comparisons. Lock your reference experiments at the top of your workspace. Set a baseline, pin up to five runs, see them highlighted in line plots. Always know if your new policy beats the last checkpoint.
Semantic coloring. Automatically groups and color codes runs by parameter or metric. When you're running hundreds of experiments across configs, being able to visually parse what's what without squinting at legends saves real time.
Synchronized video playback. Compare experiment videos side by side, perfectly in sync. Spot timing changes, control instability, perception errors instantly instead of scrubbing through clips one at a time.