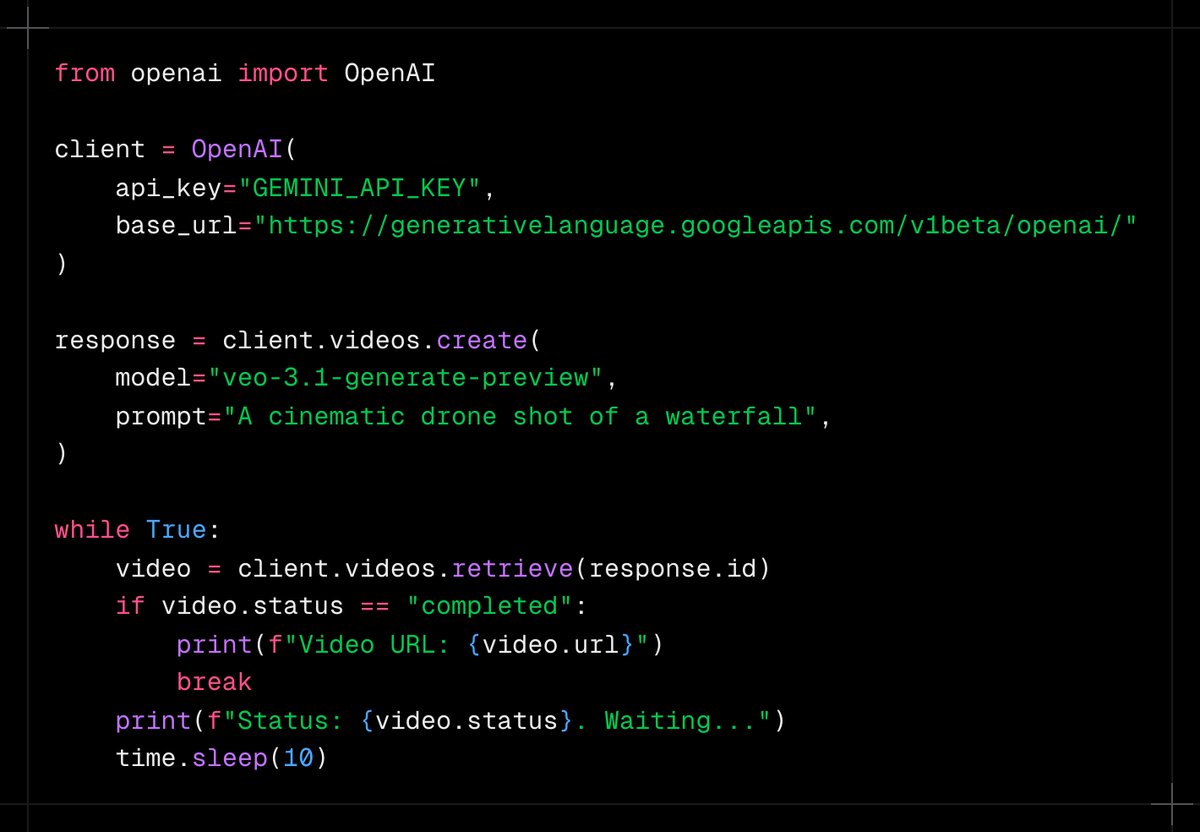
A Google bot-authored LiteRT-LM pull request references Gemma4 and AIcore NPU support, while multiple posts claim a largest version around 120B total and 15B active parameters. Engineers targeting on-device inference should wait for a formal model card before locking plans.

google-ai-edge/LiteRT-LM repo explicitly says "Add NPU support for AIcore for Gemma4 model," and the screenshots shared by the first sighting and a second capture show it coming from copybara-service[bot], Google's internal sync bot.The concrete signal is narrow but real. The screenshots shared in the original post and a second post show an open PR titled "Add NPU support for AIcore for Gemma4 model" in google-ai-edge/LiteRT-LM, with a comment from copybara-service[bot] repeating the same text. The image OCR in both posts identifies Copybara-Service as "an helper app for Google Copybara, synchronizing repositories maintained by Google," which makes this look like an internal-to-public repo sync rather than a random third-party fork.
For engineers, the interesting part is not just the string "Gemma4." It is the coupling of Gemma4 with LiteRT-LM, NPU support, and AIcore in the PR title itself. That suggests Google is plumbing runtime support for a new model family into its lightweight inference stack before, or alongside, a public release.
The parameter details are still rumor, not announcement. In one supporting post, the claim is that Gemma 4's biggest model will be "around 120B total" with "15B active" parameters; another post repeats "120b in total, 15b active parameters." If accurate, that would imply an MoE-style architecture where only a subset of parameters is active per token.
What is missing matters just as much. None of the evidence includes an official Google post, model card, context window, tokenizer details, benchmark table, quantization guidance, license update, or API availability. So the sizing rumor is useful as an early planning signal, but it does not yet answer deployability questions.
The strongest timing hint comes from the launch-week comment, which says Logan Kilpatrick called it "going to be a fun week of launches." Read together with the LiteRT-LM PR, that makes an imminent Gemma 4 reveal plausible.
But the evidence still describes a pre-release state. There are no published weights, no serving endpoints, and no reproducible evals attached to the leak. Right now the actionable facts are limited to a Google-linked LiteRT-LM PR mentioning "Gemma4" and "AIcore" NPU support, plus an unverified large-model sizing claim circulating in social posts.
Miles added ROCm support for AMD Instinct clusters and reported GRPO post-training gains on Qwen3-30B-A3B, including AIME rising from 0.665 to 0.729. It matters if you are evaluating rollout-heavy RL jobs off NVIDIA and want concrete throughput and step-time numbers before porting.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
Gemma 4 has been spotted on GitHub. The PR appears to be from Google’s bot account

Yes, Gemma 4 will soon be released this time their largest size might be around 120B total with 15B active

Google Gemma 4 incoming! Let’s go!

Google DeepMind’s Logan Kilpatrick says its “going to be a fun week of launches” We have already spotted Gemma 4 (see below), so we could potentially also see Gemini 3.1 Pro GA, Gemini Flash 3.1 GA Gemini Pro 3.2 preview and more What AI models are you hoping to see this week?

Going to be a fun week of launches : )