Chroma released Context-1, a 20B search agent it says pushes the speed-cost-accuracy frontier for agentic search, with open weights on Hugging Face. Benchmark it against your current search stack before wiring it into production.

chromadb/context-1 model package. the Hugging Face repoChroma's launch post positions Context-1 as a specialized 20B model for multi-step search, where "the output of one search often informs the next." The core claim is not just model quality but a better latency-cost tradeoff for long agentic retrieval trajectories, which Chroma says have been too expensive and slow with frontier LLMs. According to the launch thread, Context-1 is meant to improve "accuracy, speed, and cost" at the same time rather than trade one off for another.
The practical implementation detail is that Chroma shipped weights under Apache 2.0, and the Hugging Face listing makes the model immediately accessible for self-hosting, benchmarking, or adapter work. Chroma also says the model was evaluated on both internal and public benchmarks, naming Browsecomp-Plus, SealQA, LongSealQA, and FRAMES in the announcement, but the evidence here does not include the full benchmark tables or serving requirements. Context-1 launch
The release is already being framed as something engineers can plug into search-heavy agent stacks rather than a research-only checkpoint. In early discussion, one practitioner argued that search subagents are a "best case scenario" for smaller RL-trained models because the task can be separated from larger agent traces and fed with effectively unbounded synthetic data. That matters if you're comparing Context-1 against a larger general-purpose model currently doing retrieval orchestration.
Workflow fit is still uneven. A short follow-up thread showed a minimal code demo around Chroma, while a reply asking "can I use this with claude code?" got the answer "no but you can with codex" alongside Codex advanced configuration docs. Codex reply That suggests the open weights are available now, but editor and coding-agent integration is still more ad hoc than turnkey for some popular agent environments.
Firecrawl’s new /interact endpoint lets agents click, fill, scroll, and keep live browser sessions right after /scrape. It shortens the path from page extraction to web automation, but Playwright remains the better fit when you need deterministic full-session control.
 breaking
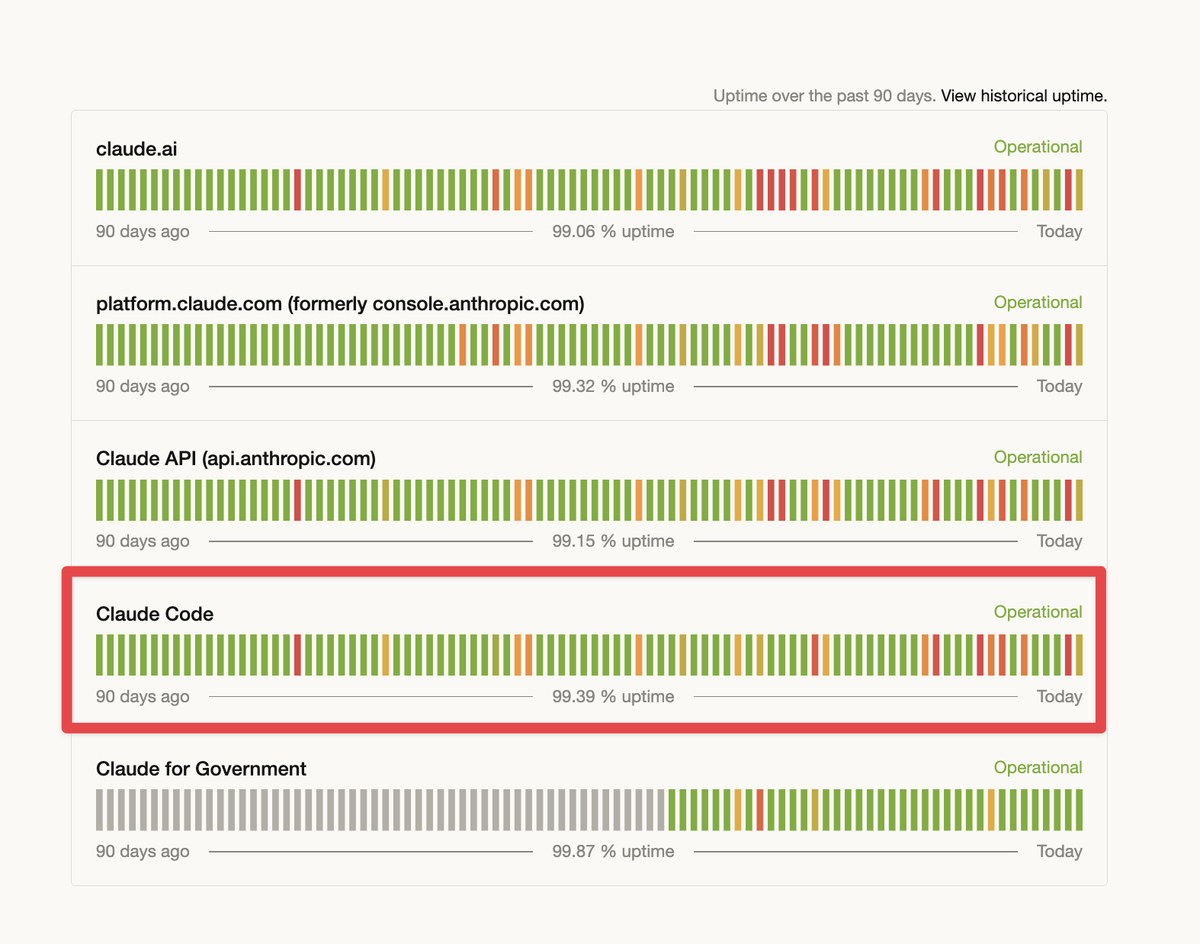
breakingAnthropic said free, Pro, and Max users will hit 5-hour Claude session limits faster on weekdays from 5am to 11am PT, while weekly caps stay the same. Shift long Claude Code jobs off-peak and watch prompt-cache misses.
 release
releaseOpenAI rolled out Codex plugins across the app, CLI, and IDE extensions, with app auth, reusable skills, and optional MCP servers. Teams should test plugin-backed workflows and permission models before broad rollout.
 release
releaseCline launched Kanban, a local multi-agent board that runs Claude, Codex, and Cline CLI tasks in isolated worktrees with dependency chains and diffs. Teams can use it as a visual control layer for parallel coding agents on repo chores that split cleanly.
 release
releaseMistral released open-weight Voxtral TTS with low-latency streaming, voice cloning, and cross-lingual adaptation, and vLLM Omni shipped day-0 support. Voice-agent teams should compare quality, latency, and serving cost against closed APIs.
Introducing Chroma Context-1, a 20B parameter search agent. > pushes the pareto frontier of agentic search > order of magnitude faster > order of magnitude cheaper > Apache 2.0, open-source
Model weights are here: huggingface.co/chromadb/conte…!
Introducing Chroma Context-1, a 20B parameter search agent. > pushes the pareto frontier of agentic search > order of magnitude faster > order of magnitude cheaper > Apache 2.0, open-source
Model weights are here: huggingface.co/chromadb/conte…!
Introducing Chroma Context-1, a 20B parameter search agent. > pushes the pareto frontier of agentic search > order of magnitude faster > order of magnitude cheaper > Apache 2.0, open-source


