Data Agent Benchmark launches with 54 enterprise-style queries across 12 datasets, nine domains, and four database systems, while the best frontier model reaches only 38% pass@1. It gives teams a stronger eval for cross-database agents than text-to-SQL-only benchmarks.
DAB is built around enterprise-style data tasks where an agent has to inspect databases, issue queries, run Python, and return an answer inside a ReAct-style loop. The authors' launch thread say the benchmark covers 54 queries across 12 datasets, nine domains, and four database management systems, grounded in a formative study of real enterprise data-agent workloads.
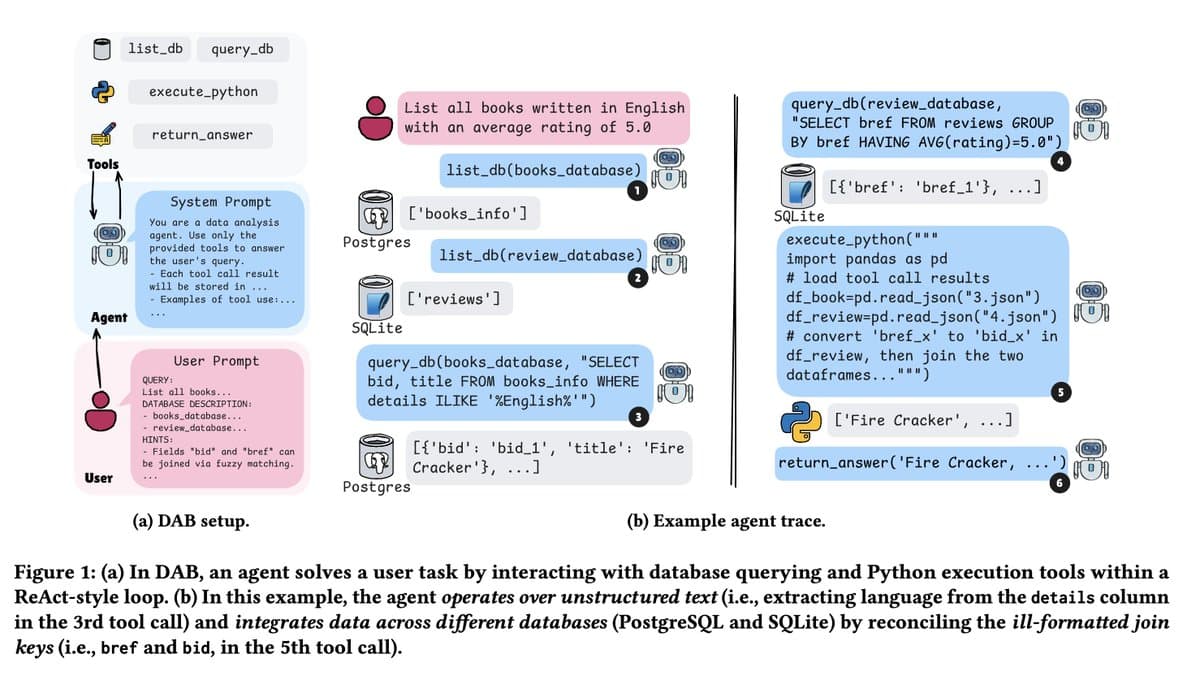
The attached [img:0|DAB setup] shows the benchmark is not just SQL synthesis. In the example trace, the agent lists tables in PostgreSQL and SQLite, queries both systems, then uses Python to reconcile mismatched keys before producing a final answer. That means the eval includes cross-database joins, unstructured-text extraction, and tool use, not just generating one correct query string. The project is also published with a paper, benchmark code, and leaderboard.
The headline result is the difficulty curve: the launch thread reports that the best frontier model manages only 38% pass@1 over 50 trials. For engineering teams, that makes DAB more useful as a live eval than saturated text-to-SQL suites where top models bunch near the ceiling.
The release thread frames DAB as "going beyond vanilla text2SQL/TableQA benchmarks," and the release repost makes the same point directly. A supporting reaction from the reposted comment captures the critique of older evals: they keep testing SQL generation on "single clean tables like it's 2019." Even a contextual reaction from Lech Mazur treats DataAgentBench as one of the still-unsaturated agent benchmarks, reinforcing the case that multi-database, tool-using data agents remain far from solved.
Epoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
 breaking
breakingMalicious LiteLLM 1.82.7 and 1.82.8 releases executed .pth startup code to steal credentials and were quarantined after disclosure. Rotate secrets, audit transitive AI-tooling dependencies, and add package-age controls before letting agents install packages autonomously.
 breaking
breakingTurboQuant claims 6x KV-cache memory reduction and up to 8x faster attention on H100s without retraining or quality loss on long-context tasks. If those results hold in serving stacks, teams should revisit long-context cost, capacity, and vector-search design.
 release
releaseOpenCode is adding remote sandboxes, synced state across laptop, server, and cloud, and more product surface inside its plugin system. That makes long-running off-laptop workflows more practical, but operators should still review telemetry, sandbox, and exposure defaults.
 release
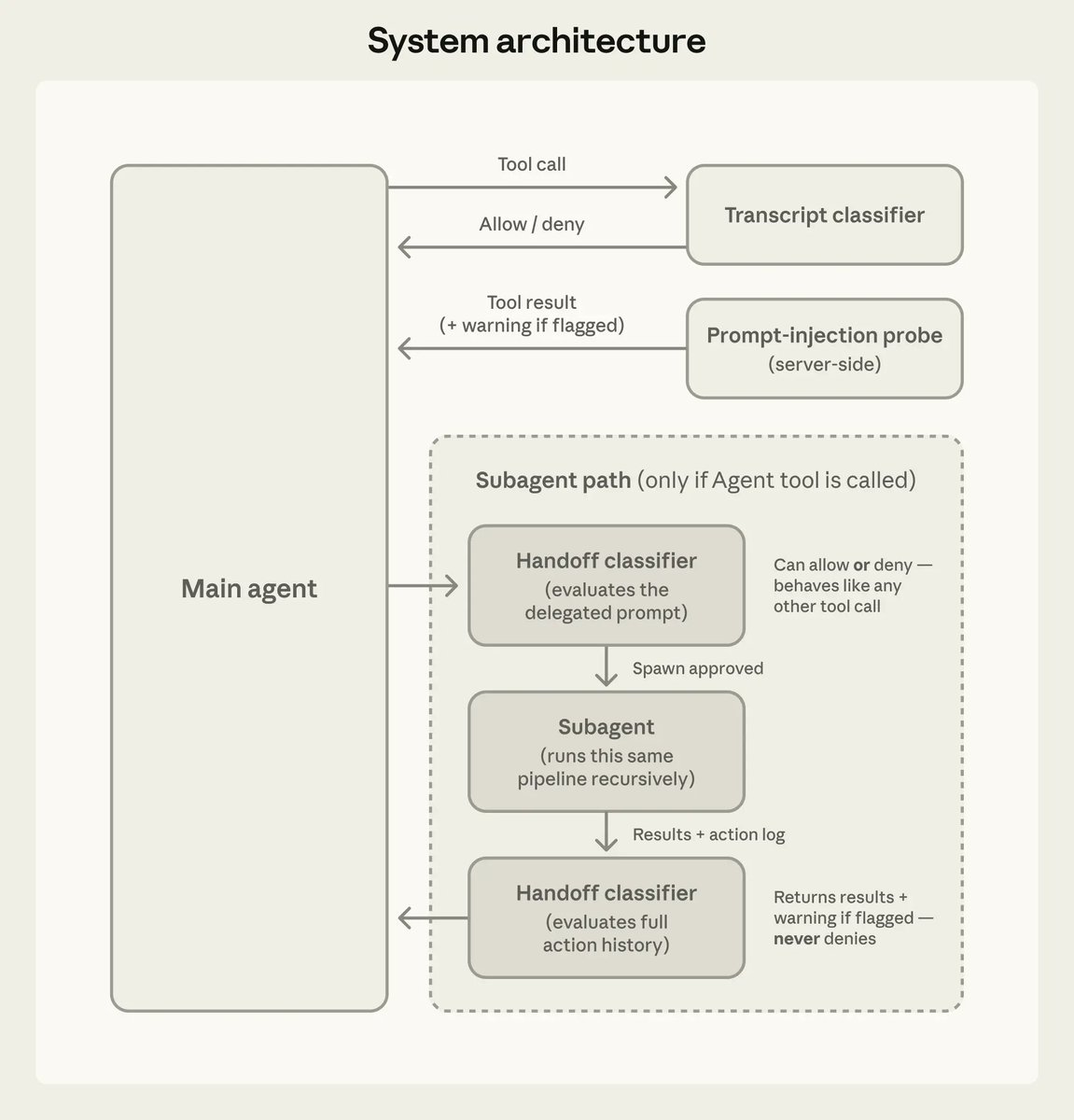
releaseClaude Code 2.1.84 adds an opt-in PowerShell tool, new task and worktree hooks, safer MCP limits, and better startup and prompt-cache behavior. Anthropic also documented auto mode’s action classifier and added iMessage as a channel, so teams should review permissions and remote-control workflows.
Databases are arguably the most commonly used enterprise tool, and enterprises typically have many of them. Yet no popular AI agent benchmark actually tests how well agents can query, join, and make sense of data across different databases! So, we built DAB (Data Agent Show more

Excited to release the Data Agent Benchmark, going beyond vanilla text2SQL/TableQA benchmarks to stress-test how models work with (and join data across) multiple database backends employing different schemas and encodings. Turns out no models do well! Hoping this will spur Show more
This was a fun collaboration between @UCBEPIC, @Berkeley_EECS, and @PromptQL Read our paper here: arxiv.org/abs/2603.20576 Check out the benchmark here: github.com/ucbepic/DataAg… Leaderboard here: ucbepic.github.io/DataAgentBench/