TurboQuant claims 6x KV-cache memory reduction and up to 8x faster attention on H100s without retraining or quality loss on long-context tasks. If those results hold in serving stacks, teams should revisit long-context cost, capacity, and vector-search design.

Posted by ray__
Google Research introduces TurboQuant, a set of advanced quantization algorithms including TurboQuant (ICLR 2026), Quantized Johnson-Lindenstrauss (QJL), and PolarQuant (AISTATS 2026), that enable massive compression for large language models and vector search engines by eliminating memory overhead in vector quantization. It achieves high-quality compression with zero accuracy loss, quantizing key-value caches to 3 bits without training, yielding 6x memory reduction and up to 8x speedup in attention computation on H100 GPUs. Tested on benchmarks like Needle In A Haystack, LongBench, and others using models such as Gemma, Mistral, and Llama-3.1-8B, it matches full-precision performance while supporting efficient semantic search at scale.
Google Research introduced TurboQuant as a family of quantization methods rather than a single narrow kernel. The main package combines TurboQuant, Quantized Johnson-Lindenstrauss, and PolarQuant to remove vector-quantization overhead for both transformer KV caches and vector search indexes, as described in the research post.
The practical claim is aggressive low-bit compression without retraining. Google's announcement says KV caches can be quantized to 3 bits for about a 6x memory reduction while preserving quality on tests including Needle In A Haystack and LongBench, using models such as Gemma, Mistral, and Llama-3.1-8B. A practitioner summary in this explainer describes the two-step method as random rotation followed by a 1-bit residual correction step that "eliminates bias" in attention scores.
The performance charts matter because they move this beyond a storage-only claim. In the chart thread, the 4-bit variant is shown reaching up to roughly 7x speedup over einsum at million-token sequence lengths, and the same thread shows TurboQuant variants staying close to full-cache quality and outperforming other low-bit vector-search baselines at similar bit budgets.
If the reported numbers hold in production stacks, TurboQuant changes the cost model for long-context inference first. Google's launch post ties lower KV-cache footprint directly to higher effective context capacity, and the recap video repeats the headline combination of "6x smaller footprint, 8x faster" on H100-class hardware.
That also makes this relevant to system design, not just model compression. The research post explicitly extends the same ideas to semantic search, where compressed embeddings can preserve Recall@k while reducing storage overhead. For teams balancing long prompts, batch size, and memory pressure, that means the same compression work could affect both serving tiers and retrieval infrastructure.
Early ecosystem signals are already appearing. The vLLM post points to TurboQuant running in vLLM with "4M+ KV-cache tokens on a USB-charger-sized box," which is anecdotal but useful as a sign that implementers are testing the serving path quickly.
Posted by ray__
This matters if you work on LLM serving, long-context inference, or vector search: the core claim is that KV caches and embeddings can be compressed far more aggressively, potentially changing memory footprint and attention throughput. The thread also surfaces practical concerns engineers would care about—GPU compatibility, wall-clock performance, prior-art lineage, and the fact that the community is already prototyping implementations in PyTorch and llama.cpp.
The main caveat is that the launch claims are benchmark-heavy and engineers immediately asked about hardware reality. The HN summary says the thread centered on "GPU compatibility, wall-clock performance, prior-art lineage," which are the right objections for anyone deciding whether to change an inference stack.
Those concerns are concrete in the discussion digest. One commenter argued the method is "hardly compatible with modern GPU architectures" and said the paper emphasizes accuracy-versus-space more than end-to-end latency. Another pointed to prior work, saying the "geometric rotation prior to extreme quantization" was introduced earlier in DRIVE. The same discussion also surfaced an independent PyTorch implementation via a working implementation, which suggests the fastest validation path will come from third-party kernels and framework ports rather than the paper alone.
Posted by ray__
Thread discussion highlights: - amitport on prior art / citations: This is a great development for KV cache compression... the foundational technique of applying a geometric rotation prior to extreme quantization... was introduced in our NeurIPS 2021 paper, "DRIVE". - gavinray on math intuition: Can someone ELI5 these two concepts please... I don't understand how taking a series of data and applying a random rotation could mathematically lead every time to "simpler" geometry. - mskkm on GPU skepticism: As far as I can tell, this algorithm is hardly compatible with modern GPU architectures... the paper reports accuracy-vs-space, but conveniently avoids reporting inference wall-clock time.
Flash-MoE now shows SSD-streamed expert weights pushing a 397B Qwen3.5 variant onto an iPhone at 0.6 tokens per second, extending its earlier laptop demos. Treat it as a memory-tiering prototype rather than a deployable mobile serving target, because speed, heat, and context headroom remain tight.
 breaking
breakingMalicious LiteLLM 1.82.7 and 1.82.8 releases executed .pth startup code to steal credentials and were quarantined after disclosure. Rotate secrets, audit transitive AI-tooling dependencies, and add package-age controls before letting agents install packages autonomously.
 release
releaseOpenCode is adding remote sandboxes, synced state across laptop, server, and cloud, and more product surface inside its plugin system. That makes long-running off-laptop workflows more practical, but operators should still review telemetry, sandbox, and exposure defaults.
 release
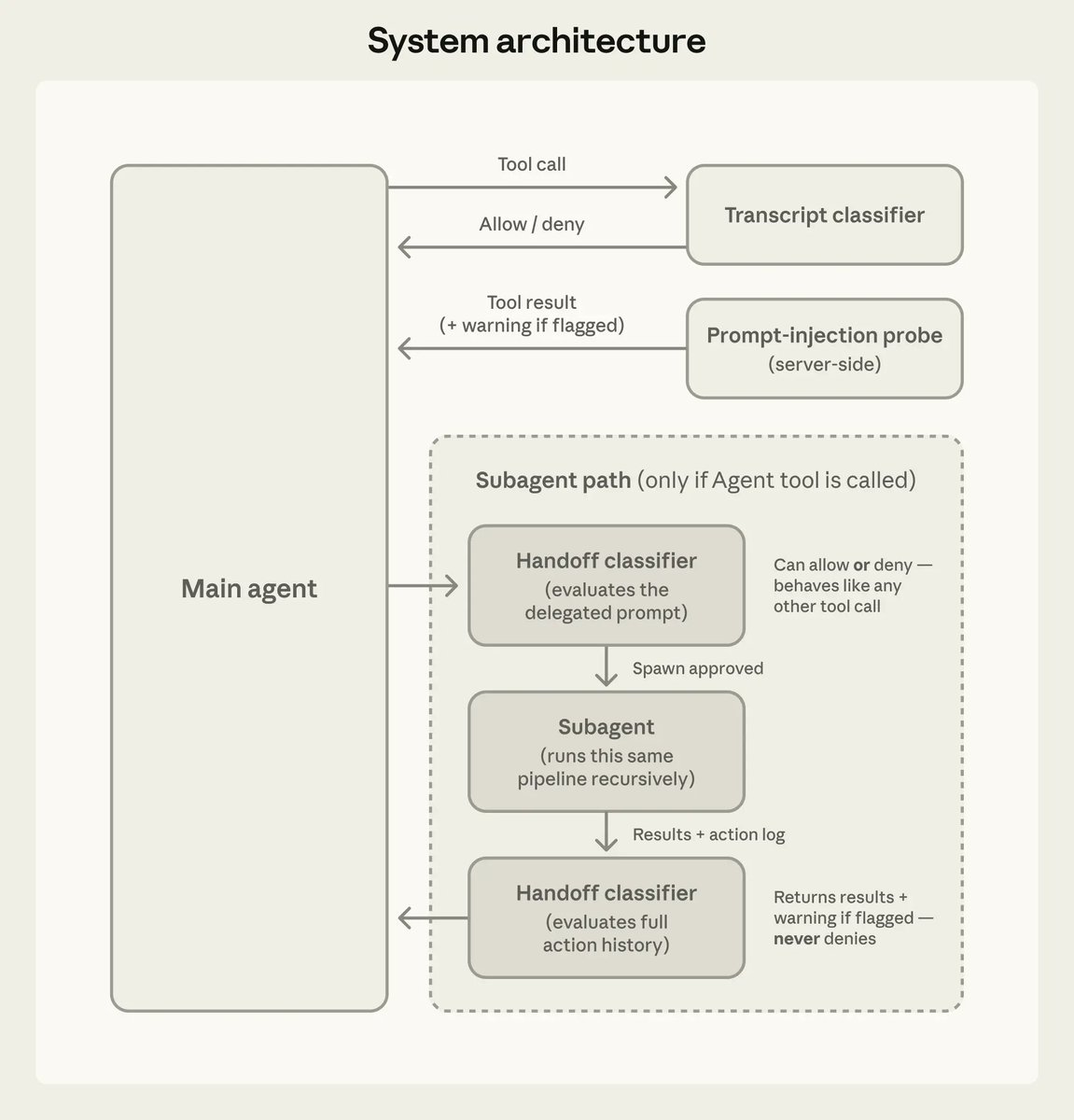
releaseClaude Code 2.1.84 adds an opt-in PowerShell tool, new task and worktree hooks, safer MCP limits, and better startup and prompt-cache behavior. Anthropic also documented auto mode’s action classifier and added iMessage as a channel, so teams should review permissions and remote-control workflows.
 release
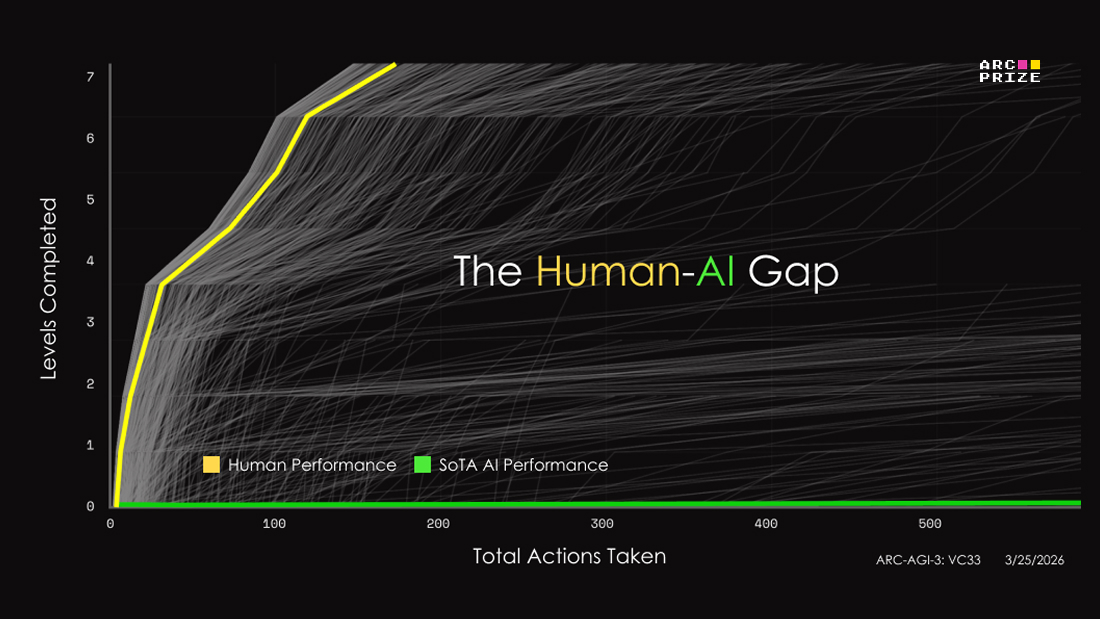
releaseARC-AGI-3 swaps static puzzles for interactive game-like environments and posts initial frontier scores below 1%, with Gemini 3.1 Pro at 0.37%. Teams can use it to inspect agent reasoning, but score interpretation still depends heavily on the human-efficiency metric and no-harness setup.
Great work @iotcoi 🔥 Google's TurboQuant in vLLM. 4M+ KV-cache tokens on a USB-charger-sized box.
I just implemented Google’s TurboQuant for vLLM. My USB-charger-sized HP ZGX now fits 4,083,072 KV-cache tokens on GB10. This may be the biggest open inference breakthrough of 2026 so far. Training is the flex. Inference is the forever bill.

Thats freaking awesome: Google Research has introduced TurboQuant, a compression algorithm (presenting at ICLR 2026) that shrinks the memory footprint of large language models by at least 6x, without any retraining or drop in accuracy. It works by converting data into a polar Show more




Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
Google Research introduced a major breakthrough in AI efficiency with TurboQuant, a new data compression algorithm that drastically shrinks the memory footprint of Large Language Models (LLMs) and vector search engines without losing any performance. In testing on models like Show more
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI


