ARC-AGI-3 swaps static puzzles for interactive game-like environments and posts initial frontier scores below 1%, with Gemini 3.1 Pro at 0.37%. Teams can use it to inspect agent reasoning, but score interpretation still depends heavily on the human-efficiency metric and no-harness setup.

ARC-AGI-3 replaces static grid puzzles with interactive, game-like tasks. ARC Prize says it built 135 environments from scratch in an in-house game studio, and the benchmark page describes them as novel worlds where agents get no instructions and must rely on “core knowledge priors” instead of prompt hints or memorized templates launch thread benchmark page.
Posted by lairv
ARC-AGI-3 is the first interactive reasoning benchmark designed to measure human-like intelligence in AI agents. It challenges AI to explore novel environments, acquire goals on the fly, build adaptable world models, and learn continuously without natural-language instructions. A 100% score means AI agents can beat every game as efficiently as humans. It measures skill-acquisition efficiency over time, long-horizon planning with sparse feedback, and experience-driven adaptation. Design principles include 100% human-solvable environments, easy for humans, no pre-loaded knowledge, clear goals, and novelty to prevent brute-force. Features include replayable runs, developer toolkit, interactive UI, and documentation.
That shifts the eval target from recognizing patterns to acquiring skill. The technical report frames the benchmark around “skill-acquisition efficiency,” while the public docs emphasize long-horizon planning, sparse feedback, and continuous adaptation. ARC Prize also says both human and model runs are replayable, with a developer toolkit and docs for building agents against the environments launch thread docs.
The launch thread also lists concrete failure modes from early model testing: “holding on to early hypothesis,” “thinking it is playing another game,” and being “unable to forecast into the future” launch thread. That makes the benchmark as much an inspection tool for agent behavior as a leaderboard.
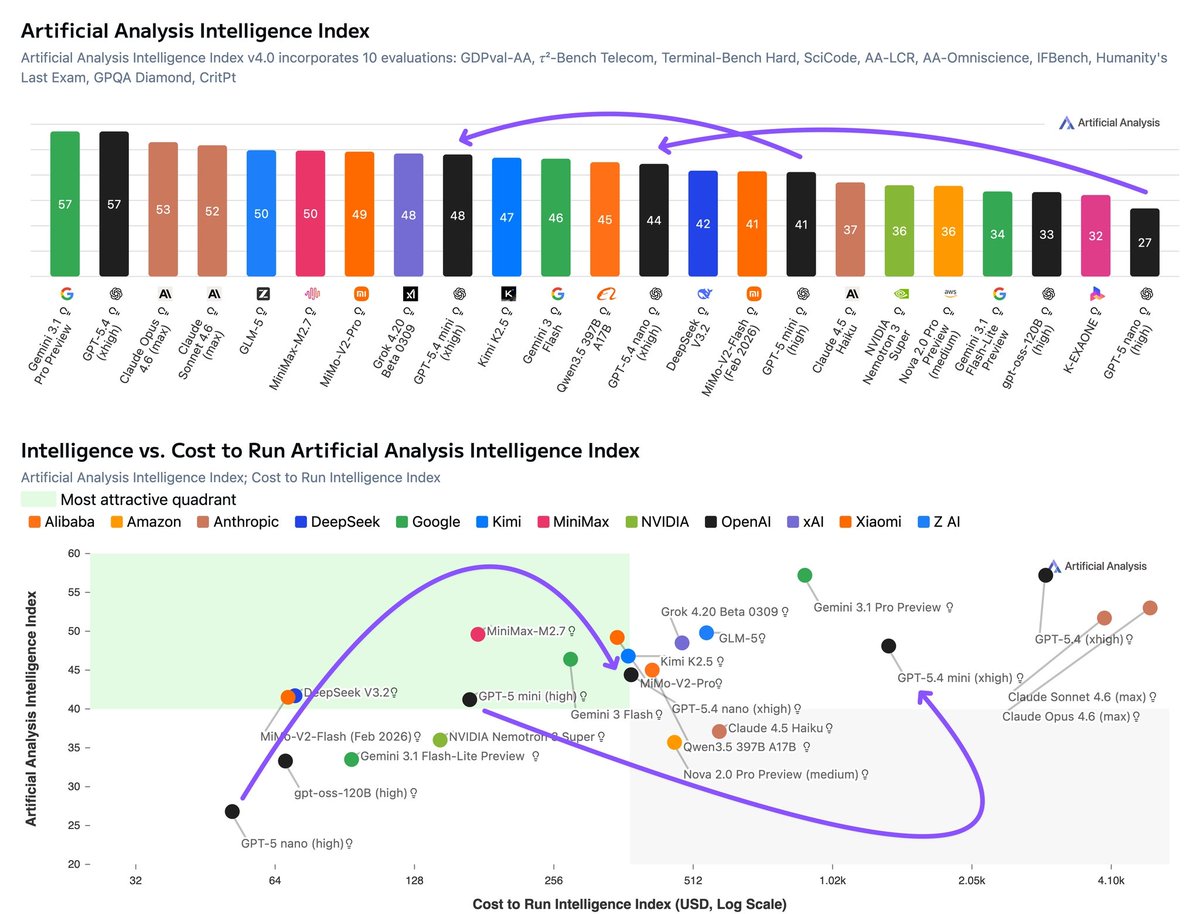
The first published numbers are tiny and expensive. One verified score post shows GPT-5.4 High at 0.3% for about $5.2K per full eval, Gemini 3.1 Pro Preview at 0.2%, Opus 4.6 Max at 0.2%, and Grok 4.20 Beta Reasoning at 0.0% score snapshot. Other contemporaneous summaries put Gemini slightly higher at roughly 0.37%, with GPT-5.4 and Opus clustered just below it, but still well under 1% overall leaderboard recap cost reaction.
For engineers, the interesting signal is less the rank order than the gap between human solvability and agent performance. ARC Prize’s own framing is “Humans score 100%, AI <1%” launch thread, while Ethan Mollick’s hands-on reaction says the tasks are “definitely human winnable” and raises a practical implementation question: how much of today’s weak performance comes from “harness, vision, and tools” versus model limits human-winnable take.
That matters because ARC-AGI-3 evaluates a full agent stack. Frontier models are not just generating answers; they are perceiving state, selecting actions, updating hypotheses, and paying for long interaction traces while doing it.
Posted by lairv
Thread discussion highlights: - Tiberium on scoring criticism: Calls out the human baseline, the squared efficiency metric, and argues the score can be misleading compared with a simple pass rate. - fchollet on scoring methodology: Chollet explains the metric is intended to discount brute force and reward harder levels; says it is inspired by SPL and based on human testing. - lukev on benchmark relevance: Questions how the benchmark relates to AGI and argues that success on a class of games does not by itself establish general intelligence.
ARC-AGI-3 is not scored like ARC-AGI-1 or 2. As scoring note explains, the benchmark uses squared efficiency relative to a human action baseline: if a human solves a level in 10 steps and a model takes 100, the score contribution is 1%, not 10%. The public paper and HN discussion say this is meant to discount brute force and weight harder levels more heavily, borrowing from path-efficiency ideas such as SPL technical report HN discussion.
That design is why sub-1% scores do not mean models literally solved almost nothing. Critics in the HN thread argue the human baseline and squared metric can make early differences hard to interpret, while François Chollet’s reply says the goal is to reward efficient learning rather than raw completion counts HN discussion. So the launch delivers two things at once: a new agent benchmark with replay-level observability, and a scoring scheme that engineers will need to parse carefully before treating leaderboard moves as clean capability deltas.
Posted by lairv
Relevant as an eval/benchmark thread: ARC-AGI-3 is about interactive agent performance, scoring design, and what kinds of reasoning and planning current models still struggle with. The discussion is especially useful if you care about benchmark design, human baselines, or agentic loop capabilities.
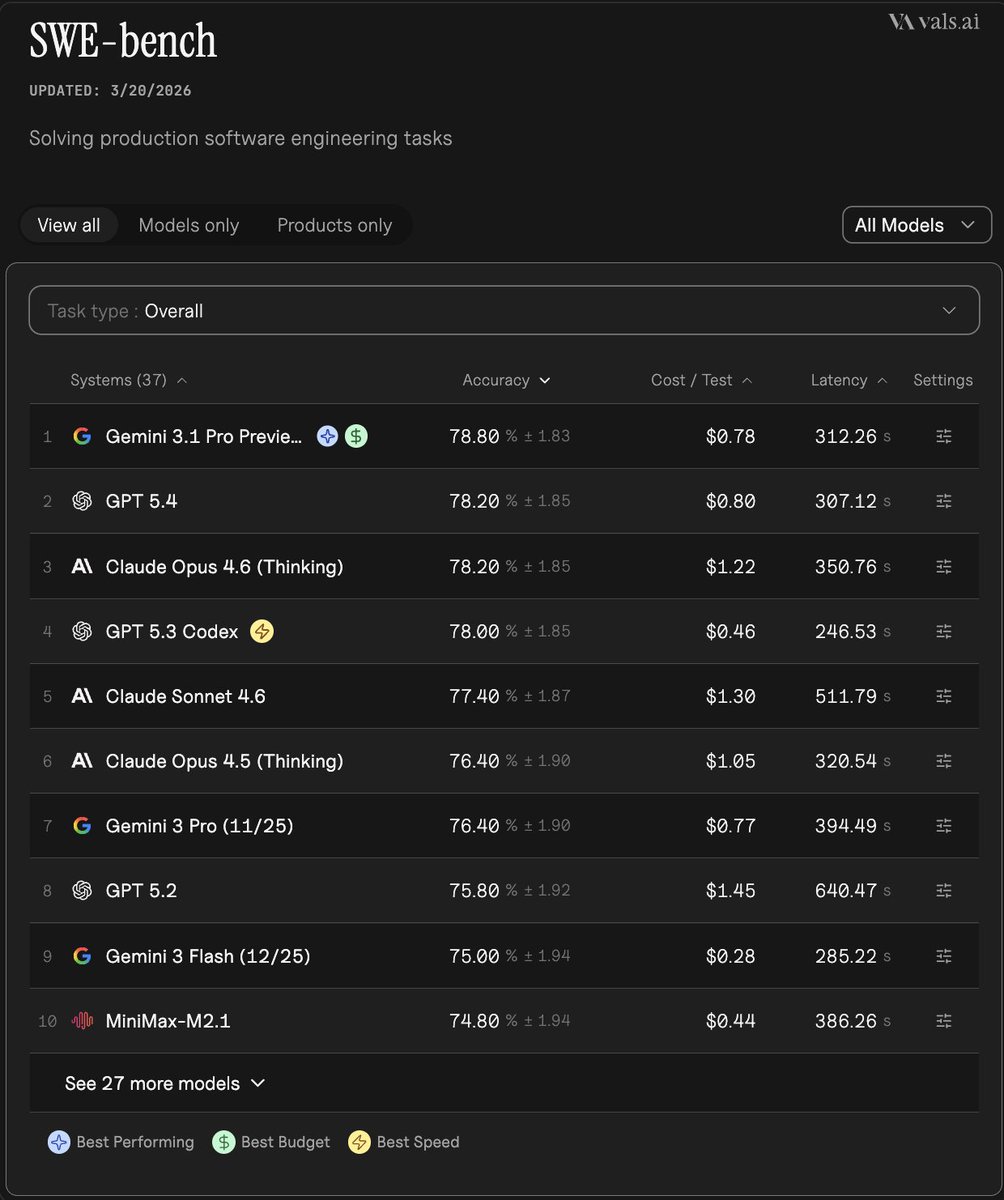
Data Agent Benchmark launches with 54 enterprise-style queries across 12 datasets, nine domains, and four database systems, while the best frontier model reaches only 38% pass@1. It gives teams a stronger eval for cross-database agents than text-to-SQL-only benchmarks.
 breaking
breakingMalicious LiteLLM 1.82.7 and 1.82.8 releases executed .pth startup code to steal credentials and were quarantined after disclosure. Rotate secrets, audit transitive AI-tooling dependencies, and add package-age controls before letting agents install packages autonomously.
 breaking
breakingTurboQuant claims 6x KV-cache memory reduction and up to 8x faster attention on H100s without retraining or quality loss on long-context tasks. If those results hold in serving stacks, teams should revisit long-context cost, capacity, and vector-search design.
 release
releaseOpenCode is adding remote sandboxes, synced state across laptop, server, and cloud, and more product surface inside its plugin system. That makes long-running off-laptop workflows more practical, but operators should still review telemetry, sandbox, and exposure defaults.
 release
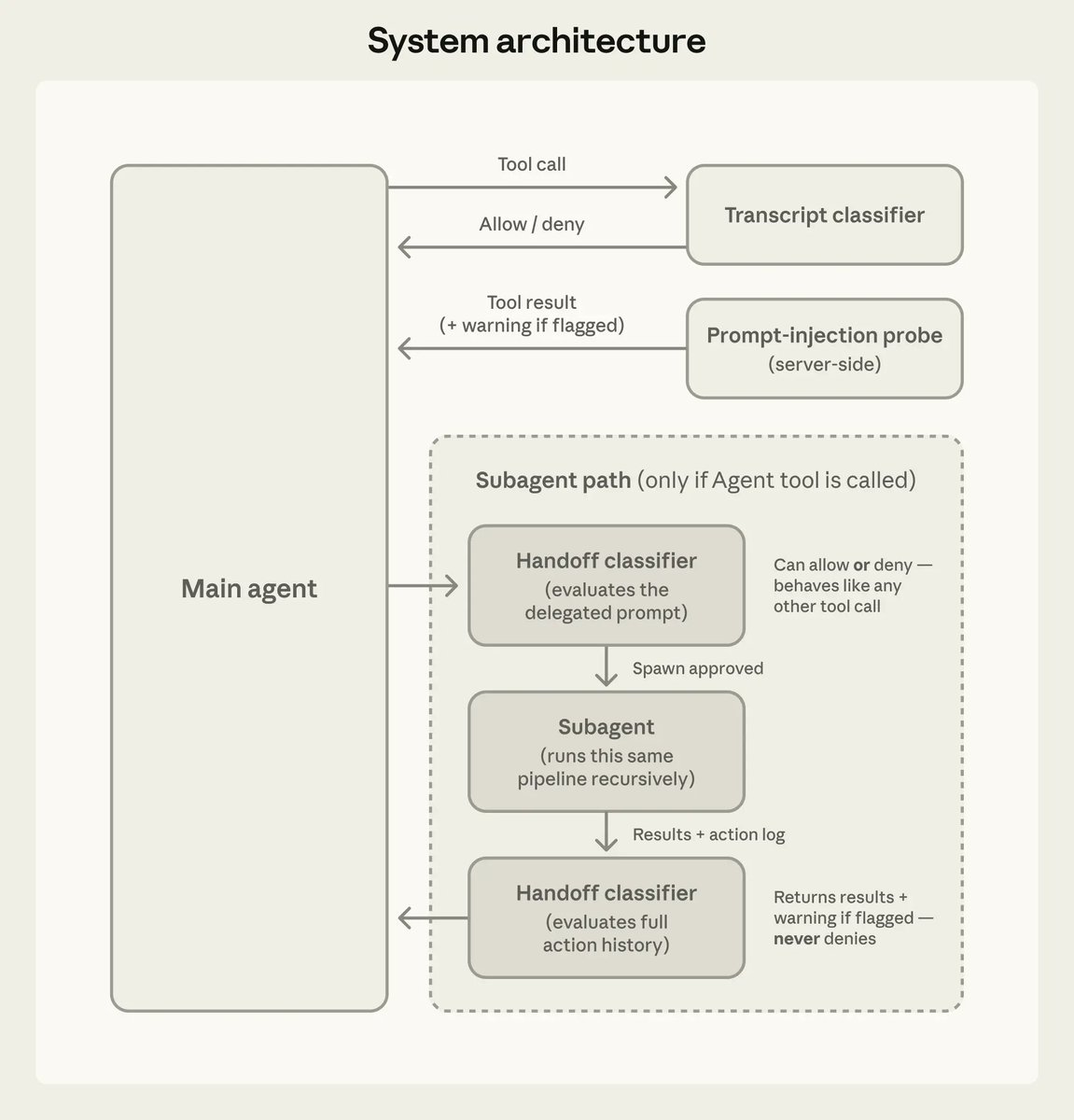
releaseClaude Code 2.1.84 adds an opt-in PowerShell tool, new task and worktree hooks, safer MCP limits, and better startup and prompt-cache behavior. Anthropic also documented auto mode’s action classifier and added iMessage as a channel, so teams should review permissions and remote-control workflows.
ARC-AGI-3 took me a few tries, but it is definitely human winnable. I am curious how much of the very initially very low performance of frontier models is harness, vision, and tools, versus how much are limitations of LLMs. I guess we will find out! arcprize.org/arc-agi/3
The Scoring of ARC-AGI-3 doesn't tell you how many levels the models completed but how efficiently they completed them compared to humans actually using squared efficiency meaning if a human took 10 steps to solve it and the model 100 steps then the model gets a score of 1% Show more


ARC-AGI-3 scores for GPT-5.4, Gemini 3.1 Pro and Opus 4.6 Gemini 3.1 Pro: 0.37% GPT-5.4: 0.26% Opus 4.6: 0.25% Grok 4.2: 0%