GitHub will start using Copilot interaction data from Free, Pro, and Pro+ tiers for model training unless users opt out, while Business and Enterprise remain excluded. Engineers should recheck privacy settings and keep personal and company repository usage boundaries explicit.

Posted by prefork
GitHub announces that from April 24, 2026, interaction data (inputs, outputs, code snippets, context) from Copilot Free, Pro, and Pro+ users will be used to train and improve AI models unless users opt out via settings under 'Privacy'. Copilot Business and Enterprise users are unaffected. Previous opt-outs are preserved. Data includes accepted outputs, prompts, code context, comments, file names, interactions, and feedback, but excludes Business/Enterprise data and opted-out users. Data may be shared with affiliates like Microsoft but not third parties. Aims to enhance model performance using real-world developer data.
GitHub's policy update makes the scope explicit: for individual paid and free tiers, Copilot interaction data will be used for model improvement by default unless the user disables "Allow GitHub to use my data for AI model training" under Privacy. The same post says Business and Enterprise customers are not included, and that previously saved opt-out choices will carry forward.
The data boundary is broad. According to the HN summary, it includes prompts, code context, outputs, and feedback; GitHub's own list also names accepted suggestions, comments, file names, and interaction metadata. GitHub says the data may be shared with affiliates such as Microsoft, but not third parties, as described in the policy post.
Posted by prefork
If you use Copilot, this affects your data boundary: prompts, code context, outputs, and feedback from Free/Pro/Pro+ may be used for model training unless you disable it, while Business/Enterprise are excluded. The thread highlights the exact opt-out setting, questions around mixed personal/work repos, and concerns about secrets or private code being exposed through normal IDE usage.
In the discussion roundup, one user said the training toggle was "enabled by default," and another said they "just checked" and found sharing was on. That reaction matters because many engineers use the same GitHub identity across hobby repos, side projects, and employer-adjacent work.
Posted by prefork
Thread discussion highlights: - mentalgear on Default privacy settings: "Allow GitHub to use my data for AI model training" is enabled by default. Turn it off here: https://github.com/settings/copilot/features - OtherShrezzing on Business and Enterprise exclusions: How can enterprises be confident that their IP isn’t being absorbed into the GH models in that scenario? - rectang on User opt-in surprise: I just checked my Github settings, and found that sharing my data was "enabled".
The thread also surfaces a more operational concern: whether sensitive code or secrets can be exposed through ordinary Copilot usage. One commenter argued there is "no way to ignore sensitive files with API keys" in the IDE flow, as quoted in the thread summary, while another questioned how confidently enterprises can separate corporate IP from personal-account activity when only Business and Enterprise plans are excluded.
Data Agent Benchmark launches with 54 enterprise-style queries across 12 datasets, nine domains, and four database systems, while the best frontier model reaches only 38% pass@1. It gives teams a stronger eval for cross-database agents than text-to-SQL-only benchmarks.
 breaking
breakingMalicious LiteLLM 1.82.7 and 1.82.8 releases executed .pth startup code to steal credentials and were quarantined after disclosure. Rotate secrets, audit transitive AI-tooling dependencies, and add package-age controls before letting agents install packages autonomously.
 breaking
breakingTurboQuant claims 6x KV-cache memory reduction and up to 8x faster attention on H100s without retraining or quality loss on long-context tasks. If those results hold in serving stacks, teams should revisit long-context cost, capacity, and vector-search design.
 release
releaseOpenCode is adding remote sandboxes, synced state across laptop, server, and cloud, and more product surface inside its plugin system. That makes long-running off-laptop workflows more practical, but operators should still review telemetry, sandbox, and exposure defaults.
 release
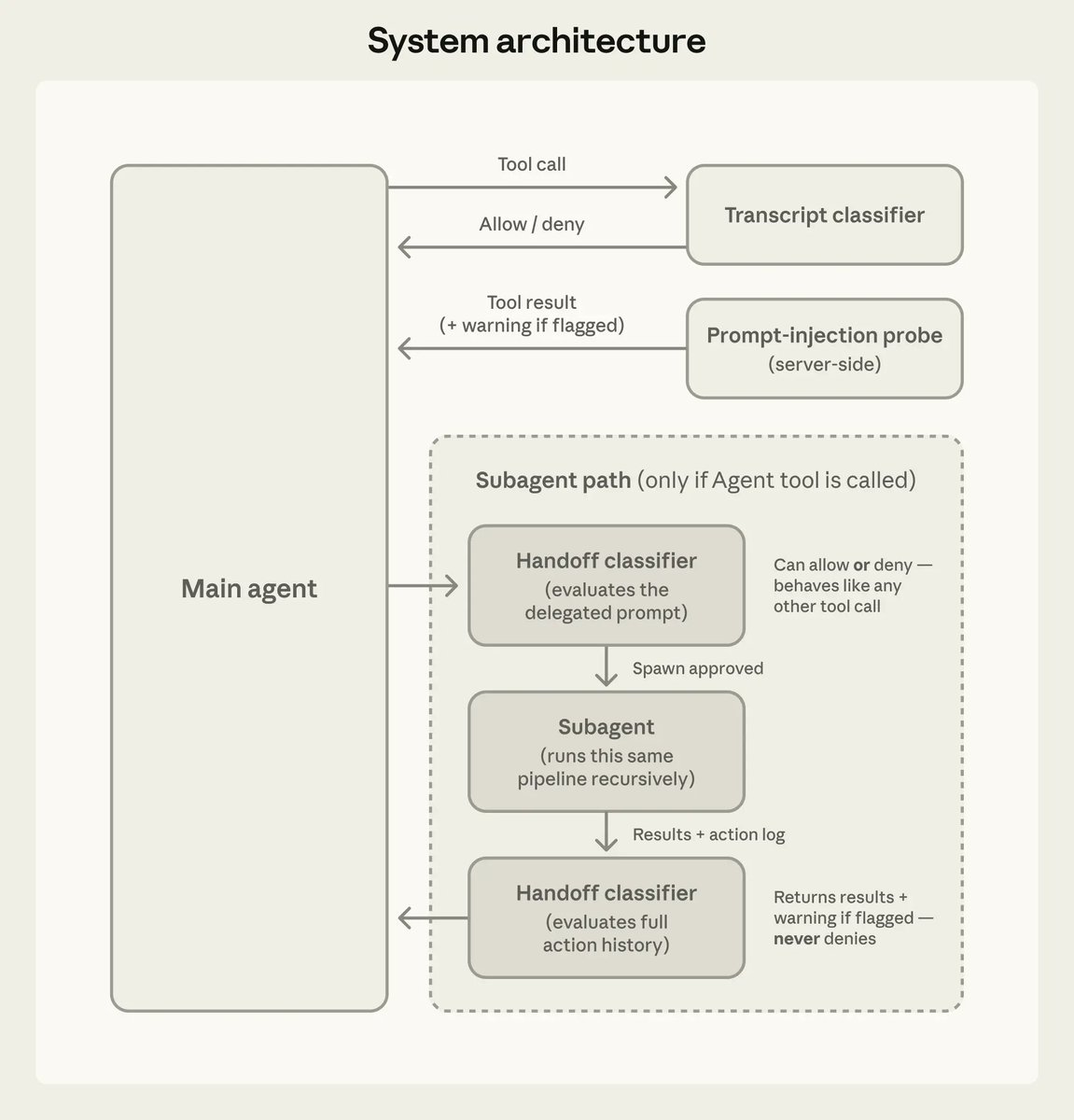
releaseClaude Code 2.1.84 adds an opt-in PowerShell tool, new task and worktree hooks, safer MCP limits, and better startup and prompt-cache behavior. Anthropic also documented auto mode’s action classifier and added iMessage as a channel, so teams should review permissions and remote-control workflows.