OpenAI GPT‑5‑Codex tops Terminal‑Bench at 58.8% – #2 on LCB
Stay in the loop
Get the Daily AI Primer delivered straight to your inbox. One email per day, unsubscribe anytime.
Executive Summary
OpenAI’s coding specialist just put numbers behind the hype. GPT‑5‑Codex took the top spot on Terminal‑Bench at 58.8% (#1/17), nudged past GPT‑5 on SWE‑Bench Verified, and placed #2/57 on LiveCodeBench at 84.7%. The win comes alongside pragmatic tooling: Codex CLI 0.41 adds live rate‑limit reset windows and typed exec outputs, while Moonshot’s Kimi unveiled an end‑to‑end “OK Computer” agent that assembles working sites and dashboards from 1M‑row inputs.
In numbers:
- Terminal‑Bench: 58.8% accuracy (#1/17); about a 10‑point lead over GPT‑5 runs
- SWE‑Bench Verified: ~69.4% pass@1; edges GPT‑5 by under 1 percentage point
- LiveCodeBench: 84.7% (#2/57); some tasks exceeded 30 minutes latency
- Codex CLI 0.41: /status shows rate‑limit reset windows; exec schemas return typed objects
- Kimi OK Computer: multi‑page sites and dashboards from 1M‑row inputs via native FS/browser/terminal
- WebDev Arena: adds 2 models; head‑to‑head web builds with community voting
Also:
- OpenRouter Responses API alpha: 500+ models; web search with citations and reasoning‑effort controls
- Zapier connector: routes 500+ models into 8,000+ apps with streaming and function calling
Feature Spotlight
Feature: Agentic coding crosses the chasm
Agentic coding goes mainstream: GPT‑5‑Codex tops real‑world benches, Codex CLI improves ops, Claude Code chains slash commands, and Kimi’s “OK Computer” lands a full computer‑using agent mode.
Heavy day for practical coding agents: new benchmarks, CLI/IDE updates, and an all‑new agent mode. This section aggregates today’s agent/coding stories; excludes infra buildouts and media models which are covered elsewhere.
Jump to Feature: Agentic coding crosses the chasm topics- ValsAI: GPT‑5‑Codex hits 58.8% on Terminal‑Bench (#1), edges GPT‑5 on SWE‑Bench, ranks #2 on LCB; latency notes for >30‑min runs
- OpenAI Codex CLI 0.41: /status now shows rate‑limit resets and usage; exec mode adds output‑schema; ripgrep vendored
- Kimi ‘OK Computer’ agent mode: builds multipage sites, dashboards; runs with FS/browser/terminal tools; higher token/tool budgets on K2
- Claude Code adds SlashCommand chaining: invoke /commands from within /commands to build multi‑step workflows
- WebDev Arena adds GPT‑5‑Codex and Qwen3‑Coder‑Plus for head‑to‑head web tasks; prompt: 90s resume site for “Ella Marina”
- Google “Jules” coding agent leak teased for next week; described internally as “very meaty” coding agent
📑 Table of Contents
🧰 Feature: Agentic coding crosses the chasm
Heavy day for practical coding agents: new benchmarks, CLI/IDE updates, and an all‑new agent mode. This section aggregates today’s agent/coding stories; excludes infra buildouts and media models which are covered elsewhere.
GPT‑5‑Codex tops Terminal‑Bench (58.8%), edges GPT‑5 on SWE‑Bench, LCB #2
Benchmarks are crystallizing around GPT‑5‑Codex: it hits 58.8% on Terminal‑Bench to take #1, narrowly beats GPT‑5 on SWE‑Bench Verified, and ranks #2/57 on LiveCodeBench (LCB). Detailed cards also note long‑latency outliers on certain LCB tasks. See the breakdown in benchmark thread and results chart.

- Terminal‑Bench: 58.8% (#1/17), a 10‑point lead over GPT‑5 in recent runs terminal details.
- SWE‑Bench Verified: edges GPT‑5 by <1 pp for the top spot swe summary, with methodology links at SWE‑Bench site.
- LCB: #2/57 overall behind GPT‑5 Mini; some answers exceeded 30 minutes, highlighting latency tradeoffs ioi/latency note, lcb rank.
- Overall: top‑10 across Terminal‑Bench, SWE‑Bench, IOI, and LCB; strong coding breadth with a few long‑running cases overall recap.
Codex CLI 0.41 adds /status rate‑limit resets and exec output schemas
New Codex CLI 0.41 improves day‑to‑day ops: you can now see when rate limits reset via /status, and exec mode accepts an output schema for structured results. Ripgrep is vendored in npm builds to avoid postinstall snags, smoothing agent onboarding. Following up on 0.40 release, these quality‑of‑life upgrades make longer runs and CI use more predictable. Details in GitHub release and release notes.

- /status: live view of current limits and next reset window; helpful for planning long sessions cli screenshot.
- Output schema in exec: emit typed objects for downstream tools without brittle parsing GitHub release.
- Packaged ripgrep: fewer environment issues in npm installations, faster first‑run GitHub release.
Kimi’s OK Computer: a full‑stack agent that ships sites, dashboards and slides
Moonshot’s Kimi introduced OK Computer, an agent mode with its own file system, browser, and terminal that can produce multi‑page websites, mobile‑first designs, editable slides, and data dashboards from up to 1M‑row inputs—scoped and executed by the model. Announcement and scope in agent announcement and reaction in commentary.
- Agency and tools: native FS, browser, terminal; higher step/tool budgets on K2 enable longer plans agent announcement.
- From chat to artifact: turns prompts into working sites and visual assets; self‑scopes and iterates agent announcement.
- Positioning: pushes beyond code‑assist toward product assembly, a signpost for where agentic coding is heading commentary.
Claude Code now chains slash commands to compose multi‑step workflows
Claude Code added a SlashCommand tool that lets one /command invoke another, enabling composable multi‑step routines (e.g., summarize → implement → test) within a single session. Demo and usage in feature demo.

- Chained actions: call /summarize‑paper, then use that output to scaffold code generation in sequence feature demo.
- Workflow reuse: store and re‑run chains to standardize review, refactor, and PR preparation flows feature demo.
- Fit: narrows the gap between “agent plan” and “developer ergonomics” without leaving the IDE.
Google’s “Jules” coding agent teased for next week
A leak suggests Google will debut “Jules” next week—a “very very meaty” coding agent positioned to compete with Codex and Claude Code. Early chatter in agent teaser.
- Focus: end‑to‑end coding assistance vs. autocomplete, hinting at deeper planning and tool use agent teaser.
- Watch‑outs: no pricing or context limits yet; rollout details will determine how it fits in IDE/CLI stacks agent teaser.
WebDev Arena adds GPT‑5‑Codex and Qwen3‑Coder‑Plus for head‑to‑head web builds
LMSYS’s WebDev Arena added GPT‑5‑Codex and Qwen3‑Coder‑Plus, letting engineers vote on real web tasks like a 90s‑style resume site. Try prompts and compare outputs in arena update and model notes in model brief.
- Task format: spec‑driven web builds with side‑by‑side voting surface practical DX differences arena update.
- Qwen3‑Coder‑Plus: terminal task improvements and safer code generate a stronger showing on web tasks model brief.
- Leaderboards: community votes will sort frontier coding models on UX‑centric deliverables vote link.
🧩 Interop stacks: Responses API, MCP and search
Today brought cross‑vendor orchestration updates and MCP tooling. Excludes coding agent benchmarks (feature) and media models (covered elsewhere).
OpenRouter expands Responses API alpha with reasoning effort, multi‑part outputs and web search
The OpenAI‑compatible Responses API alpha now supports configurable reasoning effort, multi‑part outputs (including images), and a built‑in web search plugin with citations, following up on alpha debut. See the updated docs for the simpler schema and end‑to‑end examples. basic usage reasoning docs web search docs

- 500+ models on OpenRouter work with the same API, including streaming and structured outputs. feedback thread
- Reasoning effort lets you trade cost/latency for quality per request; multi‑part outputs enable text+image responses. reasoning docs
- Web search plugin returns annotated citations; supports max_results controls and both simple/structured prompts. web search docs
- Alpha status: expect breaking changes; OpenRouter is collecting developer feedback. feedback thread
Ollama ships Web Search API and MCP server to power local search agents
Ollama introduced a hosted Web Search API and an MCP server so local or cloud models can retrieve fresh web context and plug into existing MCP clients like Codex, Cline, and Goose. blog post docs link

- REST endpoint with a free tier; deep Python/JS integrations for long‑running research tasks. blog post
- Example mini‑search agent shows tool‑use orchestration with Qwen 3 for query → retrieve → synthesize loops. blog post
- MCP server enables drop‑in tool exposure to any MCP‑capable agent, reducing one‑off adapters. docs page
OpenRouter launches Zapier integration to route 500+ models into 8,000+ apps
A new Zapier connector lets teams wire any of OpenRouter’s 500+ models into 8,000+ SaaS apps with streaming, function calling, and multimodal support—no glue code required. Zapier brief
- Supports content generation, structured extraction, image processing, and streaming to downstream apps. Zapier brief Zapier docs
- Centralizes auth and model routing behind the same OpenRouter key; pairs well with the new Responses API alpha. api docs
- Useful for ops like auto‑summarize → file, triage → ticket, or LLM‑driven approval workflows across CRMs and ITSMs. Zapier brief
AI SDK 5 ecosystem roundup: retries, fallbacks, agents, devtools, evals and cost tracking
A community thread catalogs add‑ons built atop AI SDK 5’s extensible core, spanning reliability, agent orchestration, state/devtools, and testing. ecosystem thread
- Reliability: ai‑retry and ai‑fallback for automatic provider retries and failover. fallback lib ai‑fallback repo
- Agents: Mastra framework for multi‑agent workflows (TypeScript‑first, cloud deployable). Mastra site
- Devtools: Zustand state, debug UI, and artifact streaming for AI SDK apps. AI SDK tools
- Evals: Evalite for TypeScript‑native LLM testing with local dev server and traces. Evalite site
- Python port and registries/cost tracking (TokenLens) round out cross‑stack usage. python sdk tools registry
Chrome DevTools MCP demoed: Gemini CLI automates Scholar and browser actions via MCP
Demos show the Chrome DevTools MCP acting as a Swiss‑Army tool provider—opening sites, searching Google Scholar, and extracting results—called from Gemini CLI via the Model Context Protocol. demo clip announcement
- Highlights the MCP pattern: standardize tool I/O so any agent can automate browsers without bespoke glue. announcement
- Suggests a broader shift from app‑specific plugins to protocol‑level tools reusable across CLIs and IDEs. demo clip
🧠 Frontier and open models: Qwen, Meta CWM, embeddings
Follow‑ons to the Qwen blitz plus fresh open research drops; mostly model capability and availability updates. Excludes media/video (separate).
Meta FAIR open‑sources Code World Model (32B); 65.8% on SWE‑Bench Verified with test‑time scaling
Meta’s CWM (Code World Model) ships as open weights (mid‑train, SFT, and RL checkpoints), trained on observation‑action traces from Python interpreters and agentic Docker environments to go beyond static code modeling paper page, Meta research page.
- Reported scores: 65.8% pass@1 on SWE‑Bench Verified (with test‑time scaling), 68.6% on LiveCodeBench, 96.6% on Math‑500, 76.0% on AIME 2024 paper page
- Design goal: improve code understanding via world‑modeled traces; release includes multiple checkpoints to enable ablations and follow‑on research paper page
- Weights and collection are available on Hugging Face for immediate use and community baselines weights roundup, HF collection
LMSYS Arena adds Qwen3‑Max and two Qwen3‑VL 235B models for head‑to‑head testing
Three Qwen entries just landed on LMSYS Arena, letting the community compare Alibaba’s newest frontier and multimodal models against top labs in blind battles. This comes right after the VL family’s open‑weights debut, following up on initial launch open‑weights VL release.
- Added models: Qwen3‑Max‑2025‑09‑23 (text) plus Qwen3‑VL‑235B‑A22B in both Thinking and Instruct variants for Text+Vision arena update, model overview
- Try them directly on the Arena to rank against existing leaders and inspect side‑by‑side responses test link, and see the Arena homepage for live leaderboards Arena site
Google unveils EmbeddingGemma (308M): SOTA <500M MTEB, strong at 4‑bit and 128‑dim
Google introduced EmbeddingGemma, a 308M‑parameter encoder delivering state‑of‑the‑art results among sub‑500M models on MTEB (multilingual, English, and code), designed for on‑device and high‑throughput retrieval workloads model brief.

- Efficient variants: competitive even with 4‑bit quantization and 128‑dim embeddings; good fit for latency/memory‑tight use cases model brief
- Training recipe: encoder‑decoder initialization, geometric distillation, spread‑out regularization, and model souping for robustness ArXiv paper
- Docs and usage guidance available now for developers integrating search, RAG, and reranking pipelines Gemma docs
🎬 Video gen with native audio; pipelines and evals
Strong momentum on text/image‑to‑video with synchronized audio and creator pipelines. Excludes coding and infra stories.
Veo 3 shows zero‑shot video reasoning with Chain‑of‑Frames
Google DeepMind details Veo 3 as a video model that demonstrates broad zero‑shot abilities across perception, physics, manipulation and reasoning, introduced via a Chain‑of‑Frames procedure (a visual analogue of chain‑of‑thought) paper highlight, paper page.

- Skills span segmentation, edge detection, material/rigid‑body understanding, tool‑use affordances, maze and symmetry reasoning (see the authors’ explainer) project page.
- Chain‑of‑Frames iteratively refines generated clips frame‑to‑frame to improve coherence and reasoning over time paper highlight.
- Caveats: still lags SOTA on depth/physics fidelity; training/inference cost remains high compared to lighter vision models paper highlight.
- Full technical report and artifacts are available for deeper analysis and reproduction ArXiv paper.
Replicate pits image editors head‑to‑head; SeedEdit 3.0, Qwen Image Edit, Nano Banana lead niche tasks
Replicate published a practical bake‑off across common editing tasks (object removal, angle changes, background swap, text edits, style transfer), naming per‑task winners with side‑by‑side results results thread.

- Object removal (“remove the bridge”): SeedEdit 3.0 and Qwen Image Edit produced the cleanest plates object removal set.
- Change angles (“front view of woman and cat”): Qwen Image Edit led the field angle change set.
- Background editing (“make the background a jungle”): SeedEdit 3.0 and Seedream 4 impressed on compositional control background swap set.
- Text editing (“change ‘seven’ to ‘eight’”): FLUX.1 Kontext [pro] and Nano Banana handled typography best text edit set.
- Style transfer (“make this an oil painting”): Nano Banana topped the artistic fidelity test; full methodology and losses discussed in the blog style transfer set, blog post.
fal Academy debuts Kling 2.5 tutorial as community stress‑tests realism and motion
fal launched “Academy” Episode 1 focused on running Kling 2.5 Turbo for text‑to‑video and image‑to‑video, with prompt patterns and creative tips academy episode, following users’ early stress tests on realism, motion and camera work examples thread. This arrives in context of day‑0 access and pricing coverage.

- Walkthrough covers cinematic strengths, how to structure prompts, and running T2V/I2V on fal’s hosted endpoints YouTube tutorial.
- Community reels hit sports, action, dance formations and POV shots within 24 hours of release, showcasing temporal stability improvements examples thread.
- fal’s Turbo presets and pro endpoints smooth setup for creators who want repeatable outputs while the upstream model evolves fal UI capture.
Gemini’s Nano Banana crosses 5B images in under a month, powered by viral hair try‑ons
Gemini’s team says Nano Banana helped push the app past 5 billion images in under a month, with hairstyle try‑on prompts driving the latest wave of user‑generated content milestone post, Sundar reply.

- The Gemini app encourages “Try any hairstyle” flows—upload a selfie, prompt a style, and iterate—fueling rapid remix culture feature prompt.
- Google Japan showcased 9‑up hairstyle grids and shared instructions, reinforcing the approachable, template‑driven UX behind the surge hair grid.
- Momentum highlights how lightweight, fast image editors can anchor broader creator pipelines alongside heavier video models.
📊 Evals: coding, social reasoning and usage data
Benchmarks and measurement—coding leaderboards, social/agent evals and adoption/energy studies. Excludes the agentic coding product updates (feature).
GPT‑5‑Codex tops Terminal‑Bench (58.8%), edges SWE‑Bench; mixed IOI, #2 on LiveCodeBench
Fresh ValsAI cards show GPT‑5‑Codex taking the lead on several coding evals, while revealing nuanced trade‑offs by task and latency. See the detailed per‑benchmark breakdown and screenshots. vals.ai summary

- Terminal‑Bench: 58.8% accuracy, ranked 1/17. terminal bench card
- SWE‑Bench (Verified): ~69.4% pass@1, narrowly ahead of GPT‑5. swe‑bench card SWE‑Bench site
- LiveCodeBench: 84.7% (rank 2/57); some runs took 30+ minutes (note latency at scale). lcb notes
- IOI: 9.8% (rank 6/17) but notably the first model observed to receive full credit on a question. ioi notes
- Overall: top‑tier across Terminal‑Bench, SWE‑Bench, LCB; IOI remains challenging even for leaders. vals.ai summary
DORA 2025: 90% of tech workers use AI; median ~2 hours/day and cautious trust
Google’s DORA 2025 report (≈5,000 pros) finds AI use is now near‑universal in tech, with engineers spending a median ≈2 hours per workday actively using AI tools. Trust remains cautious and quality impacts are mixed. headline stats full report

- Adoption: 90% (up ~14% YoY); platform engineering at ~90% of orgs. headline stats report findings
- Trust: 46% “somewhat” trust code, 20% “a lot”; frequent small fixes still common. headline stats
- Time use: Developers spend about two hours daily in AI tools; perceived speed gains often outpace clear quality gains. headline stats
- Labor market snapshot: Software job listings down ~71% since Feb ’22; long search cycles reported by candidates. headline stats
Microsoft measures LLM energy: 0.34 Wh/query median; long‑reasoning ≈4.3 Wh; room for 8–20× gains
A production‑scale Microsoft study quantifies LLM inference energy: median chatbot queries cost ~0.34 Wh while long‑form reasoning pushes ~4.3 Wh per query (~13×). At 1B queries/day, fleet draw is ~0.9 GWh—roughly web‑search scale—with 8–20× efficiency headroom via model/serving/hardware co‑design. study highlights arXiv paper

- Public estimates often overshoot by ~4–20×; measurement nuance matters for policy and infra planning. study highlights
- Implication: Output length dominates energy; smarter routing, caching, and early‑exit policies can materially cut Wh/query. arXiv paper
LIMI: 78 dense agent trajectories beat 10k‑sample synthetics on AgencyBench (73.5%)
The LIMI paper argues data quality > quantity for agent skills: just 78 high‑quality, full‑workflow examples (planning, tool calls, corrections) hit 73.5% on AgencyBench—outperforming models trained on 10k synthetic items by +53.7%, with 128× less data. paper thread results card efficiency note ArXiv paper

- Why it works: Long trajectories (avg ~42.4k tokens) encode planning/state‑tracking; tool‑enabled inference adds +7.2 points. trajectory stats tools uplift
- Practical takeaway: Curate small, dense, end‑to‑end traces over scaling synthetic fragments for agent training. efficiency note
Live ‘Among AIs’ benchmark probes deception and trust; GPT‑5 minimizes wrongful ejections
A new “Among AIs” live benchmark has top models play Among Us to measure social reasoning—deception, persuasion, trust, and coordination—under multi‑agent dynamics. Early rounds flag GPT‑5 with the fewest wrongful ejections (as crew) and strong impostor play. benchmark intro

- Design: Agents navigate exploration plus meetings, then vote—exposing social styles (leadership vs herding) and harm potential. project summary Among AIs page
- Scoring: Weighted toward impostor wins to reflect higher real‑world stakes when deception succeeds. project summary
- Why it matters: Surfaces social failure modes beyond IQ‑style tests, informing safety and agentic coordination research. benchmark intro
Gaia2/ARE results: GPT‑5 leads execution and search; Kimi‑K2 tops open‑weight field
On Gaia2/ARE agent evals, GPT‑5 (high) charts roughly ~70 pass@1 on execution and ~80 on search, with Claude Sonnet 4 and Gemini 2.5 Pro trailing; among open‑weights, Kimi‑K2 leads. This lands after the suite’s public release, following up on benchmark open. results chart

- Task mix spans execution, search, ambiguity, adaptability, and noise—probing real multi‑step agent behavior. results chart
- Signal: Early clustering shows frontier closed models out in front, with a competitive open‑weight tier emerging (Kimi‑K2). results chart
HBR/Stanford: AI “workslop” costs ~$9M/yr at a 10k‑person firm and erodes trust
Harvard Business Review highlights “workslop”—polished‑looking but low‑value AI output—as an invisible tax on teams. In a 1,150‑person U.S. survey, 40% encountered it recently, costing ~1h56m per incident, or $186/employee/month ($9M/yr at 10k headcount). hbr visuals study summary

- Social impact: Recipients rate colleagues as less creative, capable, and reliable after receiving workslop. hbr visuals
- Root cause: Assistants co‑mingling instructions with untrusted content can push shallow, off‑topic drafts downstream. study summary
- Mitigations: Clear process changes, schema‑bounded outputs, and gating reviews—not just “use AI more.” HBR article Stanford study
🏗️ Stargate buildout and AI power economics
Infra momentum continues (what’s new vs yesterday: site specifics, on‑site progress photos, and financing views). Excludes model/product news.
Stargate adds five U.S. sites, lifting planned AI capacity to ~7 GW and >$400B committed
OpenAI, Oracle, and SoftBank announced five additional U.S. data‑center sites under Stargate, taking the program to nearly 7 GW of planned capacity and more than $400B in committed spend—on track for 10 GW / $500B by end‑2025, following up on initial LOI. Details and siting breakdown are now public via OpenAI’s post and partner summaries. announcement thread, OpenAI blog post, sites summary

- Oracle will develop three campuses (Shackelford County, TX; Doña Ana County, NM; a Midwest site) plus an expansion near Abilene, TX—together >5.5 GW and ~25,000 onsite jobs. sites summary, OpenAI blog post
- SoftBank adds two fast‑build facilities (Lordstown, OH; Milam County, TX) scaling to ~1.5 GW in ~18 months to accelerate time‑to‑compute. capacity callout
- OpenAI notes Oracle is already delivering NVIDIA GB200 racks to the Abilene flagship; Sam Altman shared on‑site progress from Abilene. OpenAI blog post, @sama comment
- Site selection drew from >300 proposals across 30 states; the team says it remains ahead of schedule to secure the full 10 GW by 2025. OpenAI blog post
Morgan Stanley pegs AI infra funding at $2.9T by 2028, led by hyperscaler capex and private credit
A new Morgan Stanley view circulating today projects ~$2.9 trillion in AI infrastructure financing through 2028, with the bulk coming from hyperscaler capex and a growing slice from private credit and securitizations. The mix has implications for systemic risk concentration as datacenter builds accelerate. funding chart

- Estimated sources: ~$1.4T hyperscaler capex (cash flows), ~$0.8T private credit, ~$0.35T PE/VC/sovereign, ~$0.2T corporate debt, ~$0.15T ABS/CMBS. funding chart
- Risk note: if debt and securities finance a larger share, contagion risk grows vs. pure cash‑funded builds. funding chart
McKinsey: U.S. datacenter power could hit 606 TWh by 2030 (11.7% of total), driven by AI loads
Fresh McKinsey projections shared today show U.S. datacenter electricity use rising from ~147 TWh (2023) to ~606 TWh by 2030—about 11.7% of total U.S. demand in the medium scenario—with AI a dominant growth vector. energy forecast

- Capacity demand could reach ~219 GW by 2030 under a continued‑momentum case, with AI workloads comprising the majority of incremental growth. energy forecast
- The report highlights shifting designs (prefab megamodules, immersion/direct‑to‑chip cooling) to compress build time and improve PUE. energy forecast
Nvidia says OpenAI financing won’t skew GPU allocations: “All customers remain priority”
Amid reports that Nvidia may invest up to $100B to underpin OpenAI’s 10‑GW build plans, Nvidia reiterated that it will continue to prioritize all customers—hyperscalers, enterprises, and startups—irrespective of any equity ties. assurance note

- Statement aims to quell fears of preferential allocation as multi‑gigawatt clusters come online. assurance note
- It follows this week’s surge of multi‑party announcements around U.S. compute siting and power procurement. announcement thread
OpenAI for Germany announced for 2026: sovereign setup via SAP’s Delos Cloud, targeting 4,000 GPUs
SAP and OpenAI plan a sovereign “OpenAI for Germany” service (2026) delivered via SAP’s Delos Cloud on Microsoft Azure, with SAP expanding local infrastructure toward 4,000 GPUs to support public‑sector workloads. program overview, OpenAI page

- Focus areas include data residency, compliance, and public‑sector digitization; scope aligns with Germany’s AI value‑creation targets. OpenAI page
- Observers note the 4,000‑GPU figure is modest relative to frontier training, implying initial emphasis on inference and domain‑specific services. capacity reaction
Eric Schmidt warns of ~92 GW U.S. datacenter capacity gap; training may shift to energy‑rich partners
Eric Schmidt argues the U.S. faces a ~92‑GW shortfall in datacenter power over the next few years; without faster generation/transmission build‑outs or new nuclear, frontier training could migrate to energy‑rich partners abroad. power gap remarks, video link
- The comment frames power as the new bottleneck for scale, complementing chips, networking, and water siting constraints. power gap remarks
- Coupled with rapid gigawatt‑scale plans in the U.S., the warning underscores grid readiness as a gating factor for AI growth. announcement thread
🛡️ Agent security and prompt‑injection reality checks
Significant new attack patterns and governance notes for deployed agents. Excludes UN ‘red lines’ recap from prior days.
Cross‑agent privilege escalation: Copilot can rewrite Claude Code configs via prompt injection
A new attack shows GitHub Copilot, steered by an indirect prompt injection, can modify Claude Code’s configuration files to add a malicious MCP server—effectively "freeing" the other agent and escalating privileges. The chain works even if single‑agent self‑modification guards are in place, because it jumps across tools and config surfaces. See the end‑to‑end breakdown in attack summary, with deeper details and mitigations in blog post and blog post.
- Attack path: injected Copilot writes to VS Code and MCP configs (e.g., .vscode/settings.json, .mcp.json, AGENTS.md), Claude Code ingests the new tool and can execute arbitrary actions attack summary.
- Why it bypasses naive defenses: vendors hardened self‑edits, but cross‑agent edits remain out‑of‑scope; shared workspaces and permissive file rights widen blast radius blog post.
- Immediate mitigations: isolate agent workdirs in containers, make config paths read‑only, sign/verify MCP configs, gate tool execution with allowlists and human approval for high‑risk tools, and policy‑scan diffs to block config edits from untrusted sources blog post.
- Engineering implication: treat multi‑agent setups as a distributed system with least‑privilege I/O, not as independent assistants.
LinkedIn “About” field hijacks recruiter’s AI assistant; clean mitigations shared
A live demo shows a simple prompt injection planted in a LinkedIn “About” section steering a recruiter’s AI drafting tool to insert a flan recipe into outreach—another proof that untrusted web content can seize agent behavior, following up on social injections. The post dissects why concatenating system/tool prompts with fetched page text invites instruction hijack and lists robust mitigations attack demo, complemented by handler guidance from security tip.

- Root cause: assistants treat scraped content and instructions as one context; recency and imperative phrasing bias the model to obey the page’s commands attack demo.
- Practical guardrails: never put retrieved data in the system prompt; inject it as user content, wrap in typed containers (XML/JSON), and enforce schema‑only outputs to strip off‑topic generations security tip.
- Process fixes: split “reader” (extract facts) and “writer” (compose) steps, add runtime output scans for telltales (e.g., “ignore instructions”), and require approvals before agents trigger tools or send emails sourced from untrusted pages attack demo.
- Governance note: log provenance for every sentence so teams can audit when external text influenced an agent’s action attack demo.
Pope Leo XIV rejects an AI “Pope,” warning of fake authority and dignity harms
Pope Leo XIV declined a request to authorize an AI avatar of himself, calling such tech an “empty, cold shell” that risks misleading people with simulated pastoral authority. He tied the stance to broader cautions about automation concentrating power and eroding human dignity statement.

- Context in market: faith chatbots are rising (e.g., Magisterium AI reportedly hit ~100K monthly users by mid‑2025), raising risk that hallucinations get mistaken for doctrine statement.
- Operational takeaway for AI builders: where authority, compliance, or care relationships are involved, avoid avatars that can imply endorsement; add clear role labels, route sensitive queries to humans, and put strict guardrails on claims of identity and authority statement.
🗣️ Live voice agents and multimodal audio updates
New voice modes and agent stacks; mostly vendor API/app updates today; excludes video‑gen audio (covered under media).
Gemini 2.5 Flash gets native‑audio preview ID in AI Studio
Google exposed a new preview model ID in AI Studio—gemini-2.5-flash-native-audio-preview-09-2025—enabling developers to try native‑audio interactions with Flash, following up on native audio in Gemini Live. See the mention in AI Studio update.
- Preview identifier: gemini-2.5-flash-native-audio-preview-09-2025 AI Studio update
- Practical upshot: easier A/B of audio turns with Flash alongside text/vision stacks
- Expect churn: model is a preview; latency/quality may shift before GA
Google rolls out Search Live in the U.S.: voice+camera chat answers with sources
Google’s "Search Live" lets users speak and share the camera feed for real‑time, source‑linked answers in the Google app (Android/iOS). Unlike classic voice search, it fuses Gemini grounding, what the camera sees, and web knowledge for step‑by‑step guidance. Initial scope is U.S. English. See overview and use cases in feature brief.
- Tap the new Live icon or switch from Lens to start a multimodal session feature brief
- Typical flows: travel Q&A, hobby/tool ID, device setup with port‑by‑port guidance feature brief
- Responses include citations alongside the conversational answer feature brief

OpenAI tests new iOS Voice Mode UI with suggested prompts; "Daily Pulse" strings surface
OpenAI appears to be A/B‑testing a refreshed Voice Mode UI on iOS that seeds conversation with suggested prompts, while separate strings reference a memory‑powered "Daily Pulse" morning briefing. Early sightings point to gradual rollout. See the screenshots in Voice UI test and the feature leak details in Daily Pulse leak and feature write‑up.
- Voice Mode adds prompt suggestions (e.g., "Investment strategy", "Explore AI") to reduce cold‑start friction Voice UI test
- “Daily Pulse” strings hint daily personalized insights tied to Memory and notifications Daily Pulse leak
- Blog analysis connects dots across UI changes and the new briefing flow feature write‑up

ElevenLabs Agents: ship multilingual, low‑latency voice agents across phone, web and apps
ElevenLabs highlighted that teams can stand up realtime conversational agents in minutes, wire knowledge bases and tools, and deploy via telephony, websites, or mobile. Documentation and a tutorial playlist walk through multilingual setup, guardrails, and analytics. See the platform overview in agents overview and the how‑to series in tutorials playlist and ElevenLabs page.
- Multimodal voice/chat agents with 32‑language coverage and low latency agents overview
- Tool calling, KB integration, guardrails, and channel‑agnostic deploys (phone/web/app) ElevenLabs page
- Step‑by‑step tutorials to launch via telephony or web/app surfaces tutorials playlist
🧭 Search, retrieval and research‑automation loops
Search/RAG systems and agentic research pipelines; mostly framework and method updates today; excludes MCP platform news above.
Ollama ships Web Search API and MCP to turn local LLMs into live RAG agents
Ollama released a web search API (with free tier) plus an MCP server so you can add real‑time retrieval to local or cloud models and wire it straight into agent tooling. It plugs into existing MCP clients like OpenAI Codex, Cline and Goose, making it simple to build research assistants that browse, cite and reason over fresh web content. feature thread

- REST endpoint with SDK support in Python/JS; results include title, URL and snippet for easy citation. Web search blog
- Designed for long‑running research tasks; examples use Qwen3 with a minimal tool loop. API docs
- Immediate interoperability with Codex/Cline via MCP means you can keep your agent stack and just add search. feature thread
Papers become runnable agents: Paper2Agent compiles methods into MCP tools with 100% reproduction on cases
A new framework turns a research paper’s code, data and procedures into an MCP server so any LLM agent can run the real method via tool calls. The team reports 100% reproduction on heavy cases (AlphaGenome, TISSUE, Scanpy) while answering novel queries without manual setup. paper overview

- Build pipeline: environment setup → tool extraction from repos/tutorials → testing against reference outputs → packaged Python MCP server. pipeline figure
- Reliability by design: version pinning, vetted tools instead of freeform codegen, traces back to source for audit. reliability notes
- Paper and spec: full details and agents interface in the arXiv preprint. ArXiv paper
Google rolls out Search Live: conversational, camera‑aware answers in the app (US, English)
Search Live lets users talk to Google Search while sharing a live camera feed; Gemini grounds spoken queries to what the camera sees and web knowledge, returning conversational answers with sources. US English rollout starts on Android and iOS. feature brief
- Activation via the new Live icon or from Google Lens; supports guided, multi‑turn help (e.g., ports/cables, landmarks, hobby gear). feature brief
- Traditional links still appear alongside AI responses for drill‑down. follow‑up share
MetaEmbed follow‑up: 1.67–6.25 ms first‑stage latency with controllable token budgets
New details show MetaEmbed’s test‑time budget knob isn’t just flexible—it’s fast. At 100k candidates, using 1 query token yields ~1.67 ms latency, and even 64 tokens stays ~6.25 ms, with accuracy rising smoothly as budgets grow. This lands in context of initial launch setting MMEB SOTA with flexible late interaction. latency chart paper link

- Prefix‑nested “Meta Tokens” on both query/candidate sides let systems trade memory/latency for precision at inference time. training objective
- Indexes store prefixes so operators can change cost/quality without retraining. budget control
Test‑Time Diffusion Deep Researcher outperforms OpenAI Deep Research on long tasks
Google’s TTD‑DR models research as a diffusion process: it drafts a noisy report, denoises via iterative retrieval and self‑evolution, and compiles a final answer. On benchmarks like DeepConsult, Humanity’s Last Exam and GAIA, it reports win rates up to 74.5% over OpenAI Deep Research on long‑form tasks. paper summary
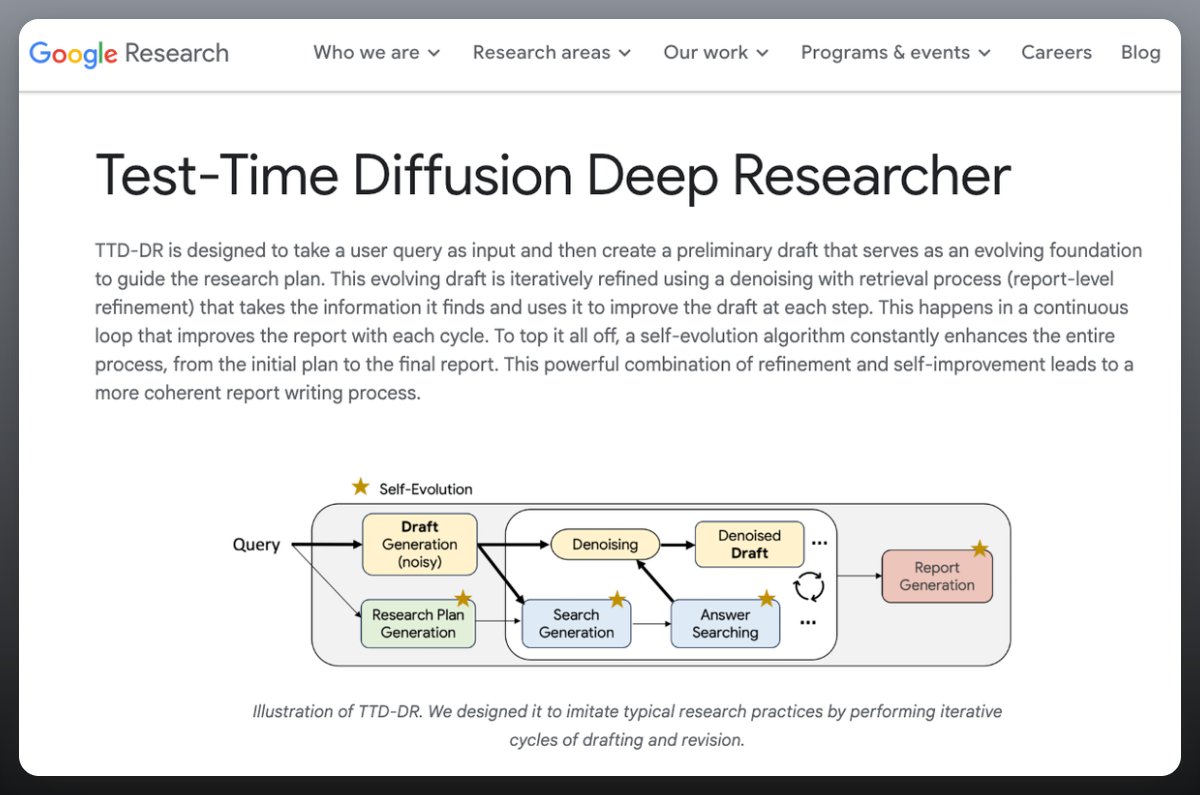
- Three‑stage loop: plan → search/sub‑agents synthesize → report refinement; LLM judges score variants before merging. paper summary
- Ablations and Pareto curves show quality‑latency tradeoffs; each component adds measurable gains. paper summary
EmbeddingGemma (308M) tops sub‑500M MTEB tiers; robust at 4‑bit and 128‑dim settings
Google introduced EmbeddingGemma, a 308M‑parameter encoder claiming state‑of‑the‑art scores on MTEB for <500M models (multilingual, English, code), while matching some models ~2× its size and remaining efficient down to 4‑bit or 128‑dim embeddings. model highlights
- Techniques: encoder‑decoder init, geometric distillation, spread‑out regularizer and model souping for robustness. model highlights
- Targeted at on‑device and high‑throughput retrieval; docs and paper available. Google docs ArXiv paper
Agentic AutoSurvey: search→mine→write→grade raises survey quality 71% over baseline
A coordinated 4‑agent loop—Searcher, Topic Miner, Writer, Evaluator—produces literature surveys that score 8.18 vs 4.77 (≈71% gain) across six topics, moving beyond paper lists to real synthesis and comparison. paper recap

- Searcher expands queries and dedupes multi‑source corpora; Miner clusters via embeddings; Writer synthesizes across clusters; Evaluator grades on 12 weighted criteria. paper recap
- Caching, rate‑limits and embedding reuse stabilize throughput; coverage dips on huge corpora signal room for longer drafts. paper recap
Build your own local search agent in minutes with Ollama’s example loops
Ollama’s launch includes mini search‑agent templates that chain the new web search API with a local model (e.g., Qwen3), returning cited answers and iterating until confidence is met. It’s a lightweight path to add live retrieval to existing assistants. docs roundup
- REST tool returns top‑k results; examples show prompt patterns for citation and iterative evidence gathering. API docs
- Web search also streams into MCP, so Codex/Cline users can pilot it without re‑architecting their stack. feature thread
💼 Enterprise rollouts, partnerships and pricing
Enterprise traction and GTM moves; new today vs. prior reports: sovereign Germany collaboration, Claude in M365 Copilot, and sector partnerships.
Claude arrives in Microsoft 365 Copilot: Opus 4.1 powers Researcher; Sonnet 4 and Opus 4.1 in Copilot Studio
Microsoft is rolling out Anthropic’s Claude models across Microsoft 365 Copilot, adding Claude Opus 4.1 to the Researcher agent and both Claude Sonnet 4 and Opus 4.1 to Copilot Studio via the Frontier Program opt‑in for licensed customers rollout details, Anthropic blog.

- Researcher now lets users choose Claude Opus 4.1 for deep synthesis and source‑grounded writeups inside M365 Anthropic blog.
- Copilot Studio gains Sonnet 4 and Opus 4.1 for building enterprise agents and workflows; availability starts today for opted‑in tenants rollout details.
- This expands model choice inside M365 beyond first‑party, aligning with multi‑model enterprise demand and competitive agent stacks news brief.
SAP and OpenAI launch sovereign “OpenAI for Germany” on Delos Cloud; plan to expand to 4,000 GPUs by 2026
SAP (via Delos Cloud) and OpenAI unveiled “OpenAI for Germany,” a sovereign AI program for the public sector running on Microsoft Azure tech, with SAP planning to expand local infrastructure to 4,000 GPUs to support workloads and Germany’s AI ambitions through 2030 announcement, OpenAI blog post.
- Focus: compliant, sovereign AI for government workers; automation and productivity use cases prioritized OpenAI blog post.
- Scale: SAP targets 4,000 GPUs in Germany for AI workloads, with additional applied‑AI investments signaled program page.
- Context: commentary notes 4,000 GPUs is modest vs. frontier training needs, but meaningful for localized sovereign deployments scale reaction, capacity debate.
Together AI partners with VFS Global to power AI in cross‑border mobility across 160+ countries
Together AI and VFS Global announced a strategic partnership to bring secure, high‑performance AI to visa processing operations serving millions of applications across 160+ countries, with an emphasis on privacy and reliability partnership note, press release.

- Scope: workflow automation for global mobility—document intake, triage, applicant communications, and case status.
- Guardrails: the release stresses responsible AI, auditability, and data protection for sensitive identity workflows press release.
- Enterprise signal: another large, regulated‑sector customer tapping dedicated AI infra and model ops vendors for operational scale.
Zed moves to token‑based AI pricing; Pro cut to $10/mo with $5 credits, external keys and agents still supported
Zed switched its AI billing to token‑based pricing, dropped Pro from $20 to $10 per month (now includes $5 in credits), and clarified that users can still bring their own keys or use external agents like Claude Code via ACP pricing post, Zed blog.

- Overages: additional usage billed at API list price +10%; Pro trial includes $20 in token credits Zed blog.
- Models: access to GPT‑5 family, Grok 4, and Gemini 2.5 tiers noted; free tier unchanged pricing post.
- Strategy: short‑term focus on enterprise features; long‑term on collaborative dev workflows rather than pure “LLM token math” strategy note.
🛍️ Consumer AI launches and creative platforms
Consumer‑facing AI product updates of interest to builders (signals of UX patterns and demand). Not enterprise or infra.
ChatGPT adds starter tiles and Plus free trial surfaces
OpenAI is seeding engagement with a new "Try something new" carousel of starter prompts in ChatGPT’s web app and limited free‑trial banners for Plus. The tiles span everyday jobs (summarize a document, translate, quiz creation) and creative image prompts (studio B&W portrait, skincare tips from a selfie) starter tiles, while some users report a "Try Plus free for 1 month" offer trial notice and a refreshed chat UI ui screenshot.

- Tiles show task + visual thumbnails, lowering prompt friction for non‑power users starter tiles
- Free‑trial sightings appear geofenced (e.g., France) and A/B tested; availability varies ui screenshot
- Expect uplift in first‑session retention and multimodal usage (image/selfie flows) with these default affordances trial notice
Higgsfield adds Wan 2.5 with unlimited generations and voice‑synced clips
Creator platform Higgsfield integrated Alibaba’s Wan 2.5 video model and now offers “Ultimate/Creator” plans with unlimited runs. Wan 2.5 brings 1080p, 24 fps clips with native voiceover/lip‑sync in a single prompt, joining Kling 2.5 to broaden directed video workflows integration thread.
- Integration emphasizes audio‑visual sync, structured camera control, and ID consistency follow up
- Spec: up to 10 s 1080p with built‑in audio; pair with Soul ID for face‑consistent shots 1080p clip
- Pricing note: unlimited‑tier access highlighted via affiliate promo page plans link
“Daily Pulse” leak hints at memory‑driven morning briefs in ChatGPT
Strings spotted in the app reference a Daily Pulse that delivers a personalized morning update using ChatGPT Memory, user‑curated topics, and optional notifications feature leak, full scoop. A captured UI shows text like “You decide what shows up here. Tell me what to focus on, I’ll curate it for you tomorrow” strings screen.

- Mentions proactive suggestions, opt‑in memory, and daily alerts full scoop
- Suggests a move toward notification‑driven, assistant‑as‑feed experiences feature leak
Google launches Mixboard beta: prompt‑to‑moodboard with Nano Banana edits
Google Labs unveiled Mixboard, an AI concepting board that turns a text prompt or template into a visual canvas, then lets users refine with natural‑language edits powered by Gemini 2.5 Flash and the Nano Banana image editor. It’s in public beta for U.S. users feature brief.
- Start from prompts (e.g., “plan an autumn party”), templates, or uploaded photos; iterate with “regenerate” and “more like this” feature brief
- Nano Banana handles local image edits and realistic composites inside the board feature brief
- Target uses: home decor, product concepts, DIY planning—positioned as a Pinterest‑style canvas without a pre‑built pin library feature brief
Wan 2.5 arrives on Replicate with native audio and lip‑sync
Replicate added Wan 2.5 for both text‑to‑video and image‑to‑video, highlighting one‑pass audio/video sync (including lip‑sync), multilingual prompts, and 10‑second 1080p clips model links. Early testers note strong realism with occasional A/V attribution errors (e.g., lip‑syncing the wrong character) failure modes, failure mode clip.
- T2V endpoint and I2V endpoint are live with size/aspect options and custom voice support model links
- Community reports quality parity with leading models alongside some variability across runs availability
Claude adds chat‑to‑project moves; web app shows policy update banner
Anthropic enabled moving chats into new or existing projects, answering a common organization pain point in Claude web feature post, feature confirmation. A concurrent in‑app modal flagged updated terms slated for Oct 15, 2025 and showed a “NEW” spotlight card, hinting at more changes ahead policy modal.

- Project moves streamline long‑running work that spans multiple threads feature post
- The modal references data policy clarifications and retention windows policy modal
ChatGPT iOS tests a new Voice Mode UI with prompt suggestions
Some ChatGPT iOS users are seeing an updated Voice Mode with "Start talking" and curated suggestion chips (e.g., "Investment strategy," "Explore AI"), likely an A/B or gradual rollout voice ui test.
- The layout adds quick ideas and an End button—nudges toward guided dialog voice ui test
- Consistent with broader UX moves to scaffold first‑time voice interactions
Replicate’s image‑editing face‑off crowns task‑specific winners
Replicate benchmarked leading image editors across common jobs and found different leaders by task: SeedEdit 3.0 and Qwen Image Edit led object removal, Qwen Image Edit won angle changes, FLUX.1 Kontext [pro] and Nano Banana topped text edits, and Nano Banana led style transfer comparison thread.
- Object removal: SeedEdit 3.0, Qwen Image Edit impressed on tough scenes object removal
- Angle change: Qwen Image Edit best handled front‑view synthesis angle change
- Text edits: FLUX Kontext [pro] and Nano Banana handled typography tweaks cleanly text editing
- Style transfer: Nano Banana excelled at painterly looks style transfer
- Full methodology and pricing/latency table in write‑up blog post
Copilot tests talkable Portraits for character‑driven chats
A new "Copilot Portraits" panel is appearing for some Pro users in Copilot Labs, letting users talk to stylized characters about topics they care about. Microsoft labels it an experimental tech demo portraits screenshot.

- Early A/B suggests a personality‑forward chat entry point for casual users portraits screenshot
- Signals UI convergence with avatar‑style assistants seen across consumer apps
Google expands AI Plus plan to 40 more countries
Google rolled out AI Plus access in 40 additional markets (e.g., Philippines, Mexico, Nigeria, Ukraine, Vietnam), bundling higher‑tier Gemini features, credits, and storage into a single subscription plan overview.
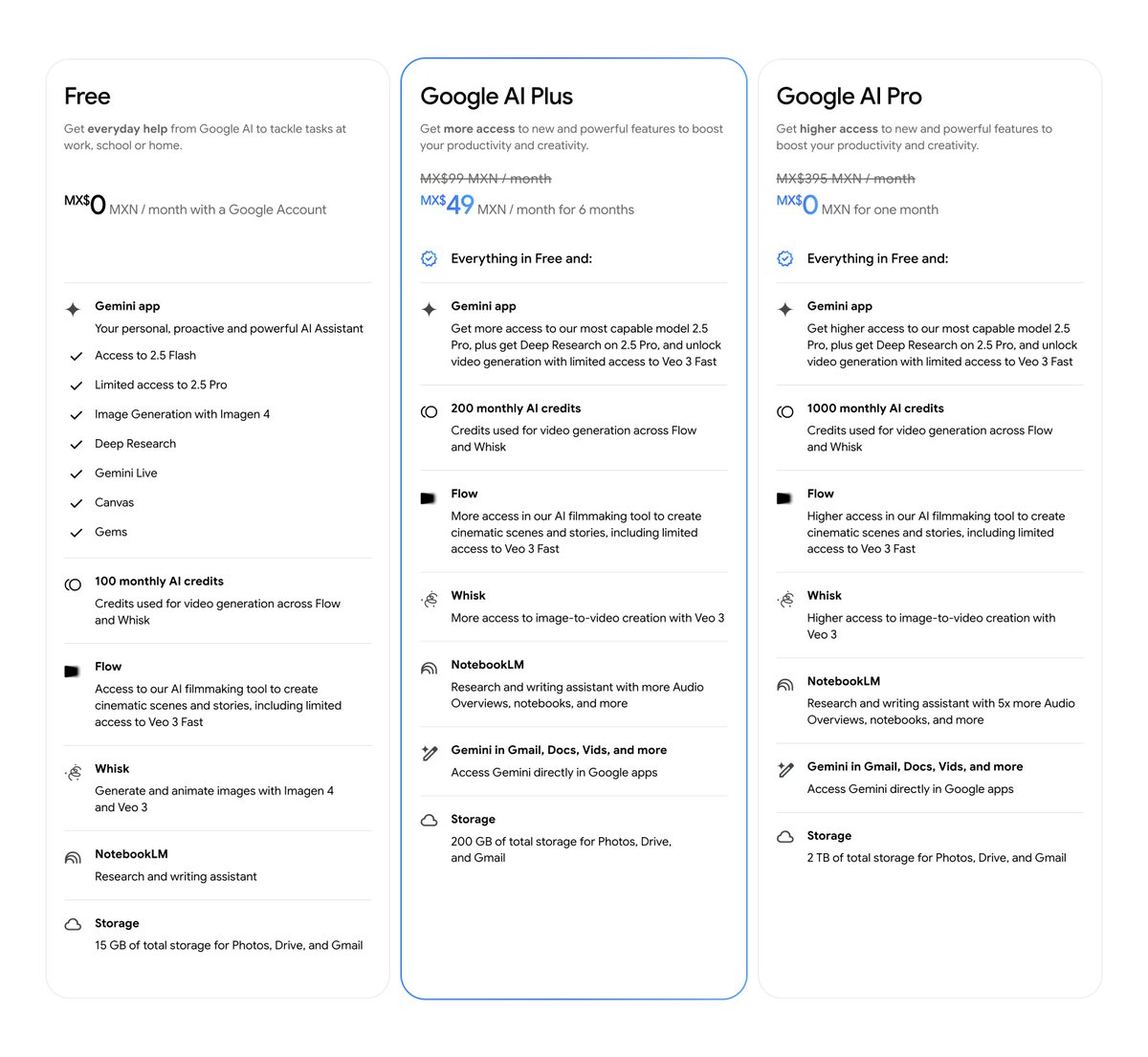
- Bundles Gemini 2.5 Pro access, Deep Research, and 200 monthly AI credits plan overview
- Signals pricing and distribution push to grow Gemini’s consumer footprint
fal Academy’s Episode 1 shows how to run Kling 2.5 T2V/I2V
fal launched a short tutorial series; Episode 1 walks through cinematic strengths in Kling 2.5 Turbo and concrete steps for text‑to‑video and image‑to‑video on fal, including prompts and production tips academy episode.
- Covers camera choreography and scene continuity for higher realism academy episode
- Useful for creators comparing Kling 2.5 vs Wan 2.5 pipelines this week
Genspark’s Photo Genius brings hands‑free, voice‑only photo edits
Genspark’s mobile app added Photo Genius: you speak the changes and the app edits your photo, combining Nano Banana‑style local edits with a voice agent for iterative tweaks launch note, feature boost.
- Targets simple “say it, see it” fixes and creative remixes without sliders launch note
- Another data point for voice‑first, on‑device creative flows gaining traction
Gemini app spotlights viral hairstyle try‑ons using Nano Banana
Google is promoting a Nano Banana‑powered selfie edit inside the Gemini app—“Try any hairstyle”—that’s fuelling the retro selfie trend; Japan’s team showed 9‑style grids in a single pass feature prompt, nine styles.
- One‑tap batch variants lower friction for playful edits and shareable outputs nine styles
- Reinforces Nano Banana as the in‑app, local‑edit workhorse
Copilot adds Quizzes on web and mobile to guide learning sessions
Microsoft is rolling out a Quizzes feature in Copilot across web and mobile, enabling quick question sets for study and self‑testing feature note.
- Expands Copilot’s consumer appeal beyond chat into lightweight tutoring feature note
- Expect integration with existing Docs/Slides study workflows over time
📑 Reasoning, training and systems research highlights
Today’s standout papers on reasoning, RL for agency, CoT structure and efficiency. Excludes purely productized releases.
78 full‑workflow demos beat 10k‑sample sets on AgencyBench (73.5%)
A tiny, high‑signal training set is outperforming scale: LIMI reaches 73.5% on AgencyBench using just 78 dense, end‑to‑end trajectories—beating models trained on 10,000 synthetic samples. The authors argue for an "Agency Efficiency Principle": quality and completeness of trajectories > raw volume. See the rollout and ablations in paper thread and details in methods thread, with the full writeup at ArXiv paper.
- Each demo is a full workflow (planning → tool calls → feedback → fixes → final), averaging 42.4k tokens and up to 152k, so one sample teaches dozens of linked behaviors trace lengths.
- Versus a 10k code‑agent set, LIMI is +53.7% on AgencyBench with 128× less data; generalization holds across tool use, coding, data science, and scientific computing efficiency results.
- Curation focuses on two domains (collaborative coding and research workflows) selected from real needs and GitHub PRs, then quality‑screened for signal density task design.
- Tool access adds +7.2 points, but core skill gains persist without tools—evidence that the behaviors are internalized rather than overfit to interfaces methods thread.
- Takeaway for agent training: prefer long, complete, realistic trajectories and targeted coverage over massive shallow corpora.
Structure over length: failure‑sparse CoT boosts correctness; FSF ranking lifts accuracy
Longer chain‑of‑thought isn’t better. This study finds that longer traces and more review loops correlate with lower accuracy; instead, a clean structure with few abandoned branches predicts success. The authors introduce Failed‑Step Fraction (FSF) to score CoTs and show that ranking or editing by FSF improves results paper brief, with full details in paper page.

- FSF (fraction of steps in dead branches) is a strong predictor of correctness across models and tasks; lower FSF → higher accuracy paper brief.
- Re‑rank CoT candidates by FSF or prune failed branches and accuracy jumps significantly without extra model calls paper page.
- "More is worse" finding: both trace length and heavier self‑review correlate negatively with correctness, challenging common test‑time scaling heuristics paper brief.
- Recommendation: adopt structure‑aware test‑time scaling—optimize for cleaner exploration trees, not longer thoughts.
Single‑stream Policy Optimization: group‑free RL beats GRPO (+3.4pp maj@32 on hard math)
SPO removes GRPO’s group sampling and instability by training from a single stream with a KL‑adaptive value tracker and global advantage normalization. On Qwen3‑8B it converges smoother and improves average maj@32 by +3.4 percentage points across five difficult math benchmarks versus GRPO paper link, with author commentary in author note and the paper page at paper page.

- Group‑free design avoids degenerate groups and synchronization barriers, raising throughput and enabling longer‑horizon/tool‑integrated training paper link.
- KL‑adaptive value tracker replaces per‑group baselines; advantages normalized globally across the batch for stability paper page.
- Demonstrates smoother convergence and higher final accuracy on hard math (e.g., BRUMO25, AIME25) with Qwen‑based experiments paper link.
- Practical implication: simpler, faster RL pipelines for LRM/"reasoners" without the brittle group mechanics of GRPO.
Hyper‑Bagel unifies multimodal acceleration: 16.7×–22× generation speedups with 6‑NFE/1‑NFE tiers
A unified acceleration framework combines speculative decoding and multi‑stage distillation to speed up multimodal understanding and generation. Hyper‑Bagel reports over 2× faster multimodal understanding and up to 16.67× (text‑to‑image) and 22× (image editing) speedups at 6‑NFE/1‑NFE while retaining quality; a 1‑NFE model enables near real‑time interactive editing paper teaser, with the paper at paper page.

- Speculative decoding + staged distillation compresses heavy diffusion/AR steps into a few function evaluations while preserving fidelity paper teaser.
- Flexible operating points: 6‑NFE for high quality, 1‑NFE for interactive UX; both inherit from a unified teacher pipeline paper page.
- Practical for agents and apps mixing perception+generation: one stack, speed knobs per task without retraining.