Moonshot introduced Attention Residuals, replacing fixed depth-wise residual accumulation with learned lookbacks over earlier layers, and reports a 1.25x compute advantage on Kimi Linear. Try it as a drop-in lever for deeper stacks, but verify memory tradeoffs and downstream gains on your own architecture.

Moonshot is pitching Attention Residuals as a drop-in replacement for standard residual stacks. Instead of every layer receiving the same accumulated history, the launch thread says each layer can "selectively retrieve past representations" through learned attention over prior layers.
That is the main architectural shift: residual connections stop being fixed depth-wise recurrence and become an attention problem over model depth. Moonshot says Block AttnRes makes that usable at scale by grouping layers into compressed blocks, and the
from a supporting explainer shows the intended tradeoff clearly: full lookback behavior with a blockwise memory reduction. The company links the full method description in its paper.
A practitioner summary from Cedric Chee's note captures the practical pitch in plain language: old stacks "keep piling layers on top," while Attention Residuals let a layer "look back" and pull the most useful earlier state.
Moonshot's benchmark claim is narrow but concrete. Its scaling-law post says experiments show a "consistent 1.25× compute advantage" across model sizes, and the main announcement adds that the latency cost is negligible at "<2%" during inference.
The training-side argument is that learned lookbacks improve optimization, not just efficiency. According to the training-dynamics post, AttnRes mitigates hidden-state growth and yields a "more uniform gradient distribution across depth." The same thread says results were validated on Kimi Linear, with 48B total parameters and 3B activated, and Moonshot reports "consistent downstream performance gains" there launch thread.
What Moonshot has not shown in the thread is a broad reproduction set outside Kimi Linear or a detailed public accounting of memory costs under different stack depths and block settings. The strongest current evidence remains Moonshot's own paper and thread-level summaries, including a supporting recap from AlphaSignalAI's summary that repeats the headline numbers but does not add independent results.
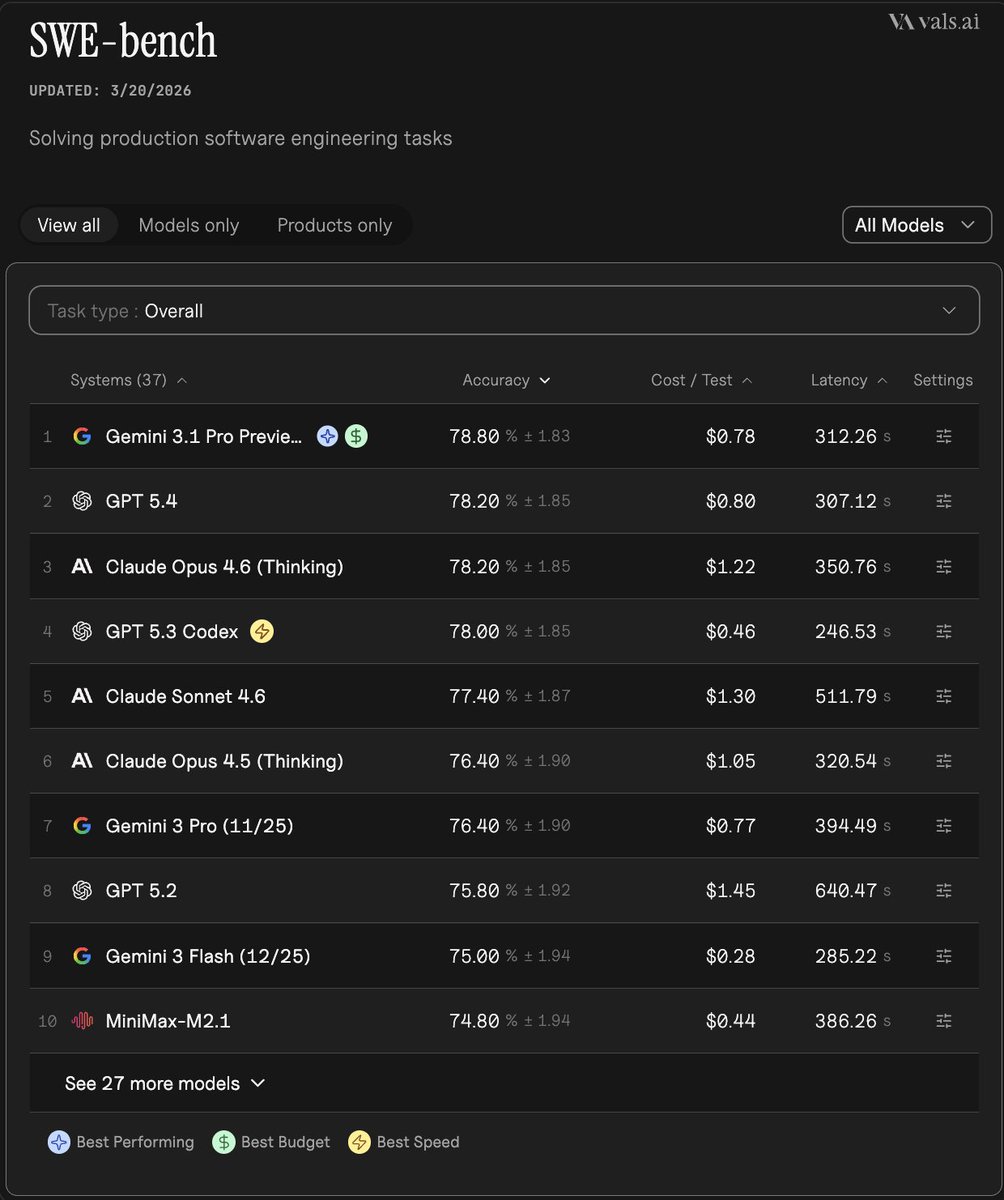
LLM Debate Benchmark ran 1,162 side-swapped debates across 21 models and ranked Sonnet 4.6 first, ahead of GPT-5.4 high. It adds a stronger adversarial eval pattern for judge or debate systems, but you should still inspect content-block rates and judge selection when reading the leaderboard.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with Show more

Scaling law experiments reveal a consistent 1.25× compute advantage across varying model sizes.

Analysis of training dynamics demonstrates how AttnRes naturally mitigates hidden-state magnitude growth and yields a more uniform gradient distribution across depth.