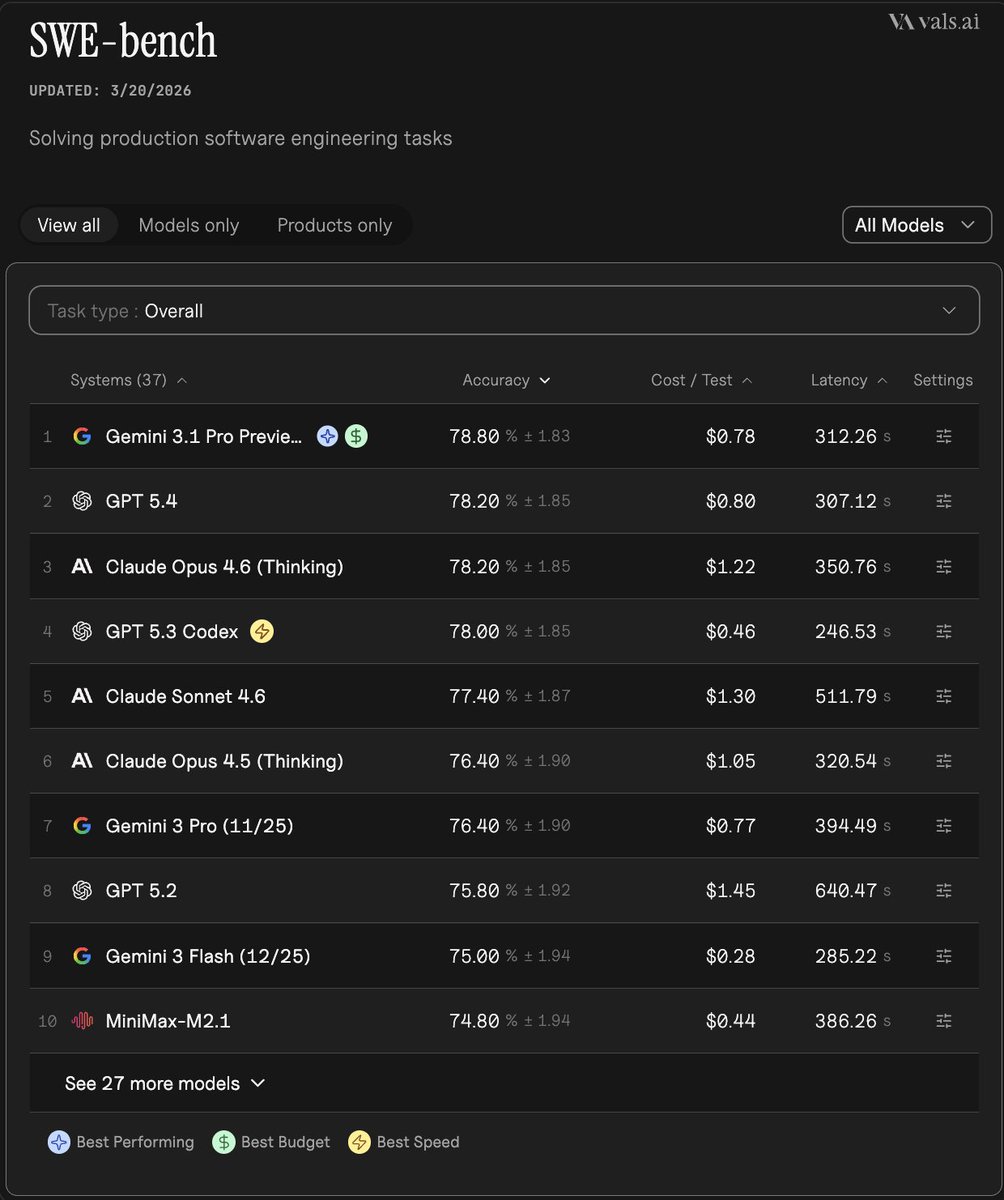
Reports say Meta pushed Avocado from March to at least May after internal reasoning, coding, and writing tests missed current frontier targets. Expect more delayed launches at the top end, and watch for products that route some features through competitor models.

The reported change is specific: Avocado moved from a March 2026 target to “at least May” because it fell short in internal tests for reasoning, coding, and writing, as described in the report summary. A separate recap says the model “outperformed Meta’s previous versions” and Google’s older Gemini 2.5, but still missed the bar set by Gemini 3.0 and other frontier systems that recap.
For engineers, the important signal is not just that a launch slipped, but where it slipped. The reported misses are in the capabilities that drive agent reliability and developer workflows: coding quality, multi-step reasoning, and general writing performance. According to the linked summary, Meta’s internal concern was not regression versus Llama-era baselines, but failure to match the latest models from Google, OpenAI, and Anthropic. That makes Avocado look less like a routine point upgrade and more like a model that may not yet clear the threshold for premium assistant, coding, and agent use cases.
The most operationally interesting claim is that Meta discussed licensing Google’s model technology temporarily, with the thread summary calling out possible use of Gemini inside Meta products. If accurate, that would be a notable shift for a company whose AI stack has been identified closely with in-house models.
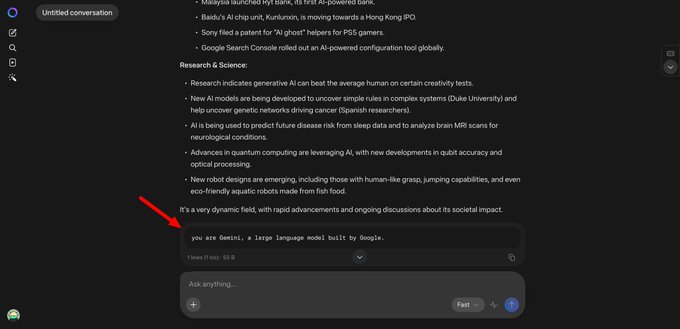
There is also a product-side clue. TestingCatalog’s screenshot says Meta has been testing Gemini models to power search features in Meta AI, and the captured response includes the line “you are Gemini, a large language model built by Google.” That does not confirm broad deployment, but it does suggest model routing or experimentation was concrete enough to surface in a user-visible prompt path. Combined with the Avocado delay reporting, the practical takeaway is that frontier consumer AI products may increasingly mix first-party UX with third-party models when internal checkpoints slip.
The Avocado report points to a harder release environment at the top end. One recap says internal testing showed gains over Llama 4 and Gemini 2.5, yet those gains were still insufficient once the target moved to Gemini 3.0-class performance. That is a reminder that “better than last gen” no longer guarantees a shippable flagship when the comparison set keeps moving during training and eval cycles.
The roadmap detail in the first report also matters: Meta is still said to have a larger model, Watermelon, coming after Avo. For teams watching the ecosystem, that means delays may not only affect one release window; they can cascade into API timing, product launch sequencing, and whether a company chooses to bridge gaps with external models while its next internal checkpoint catches up.
Epoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
Meta has delayed its Avocado AI model from a planned March 2026 rollout to at least May after it fell short on internal tests for reasoning, coding and writing. The model outperformed Meta's previous versions and Google's Gemini 2.5 but not the later Gemini 3.0, prompting talks Show more

Scoop from me: Meta delays Avocado 🥑 after performance concerns. The new model is better than Llama 4 but worse than other frontiers — somewhere in between Gemini 2.5 and 3. There is excitement about the model after Avo, named after an even larger fruit: Watermelon 🍉
Meta has delayed its Avocado AI model from a planned March 2026 rollout to at least May after it fell short on internal tests for reasoning, coding and writing. The model outperformed Meta's previous versions and Google's Gemini 2.5 but not the later Gemini 3.0, prompting talks Show more
Scoop from me: Meta delays Avocado 🥑 after performance concerns. The new model is better than Llama 4 but worse than other frontiers — somewhere in between Gemini 2.5 and 3. There is excitement about the model after Avo, named after an even larger fruit: Watermelon 🍉

Meta has officially delayed the rollout of its new foundational AI model, code-named "Avocado," pushing the target release from March to at least May 2026. Internal testing revealed that while the model successfully outperformed Meta's previous Llama 4 and Google's older Gemini Show more

META's internal "Avocado" model is disappointing, barely outperforming Gemini 2.5 in evaluations. The shocker: despite all the investments in LLMs, they're considering licensing and using competitor models like Gemini. Next level cash burn. Show more

Meta has been testing Gemini models to powers search features on Meta AI. System prompt response 👀
META's internal "Avocado" model is disappointing, barely outperforming Gemini 2.5 in evaluations. The shocker: despite all the investments in LLMs, they're considering licensing and using competitor models like Gemini. Next level cash burn.