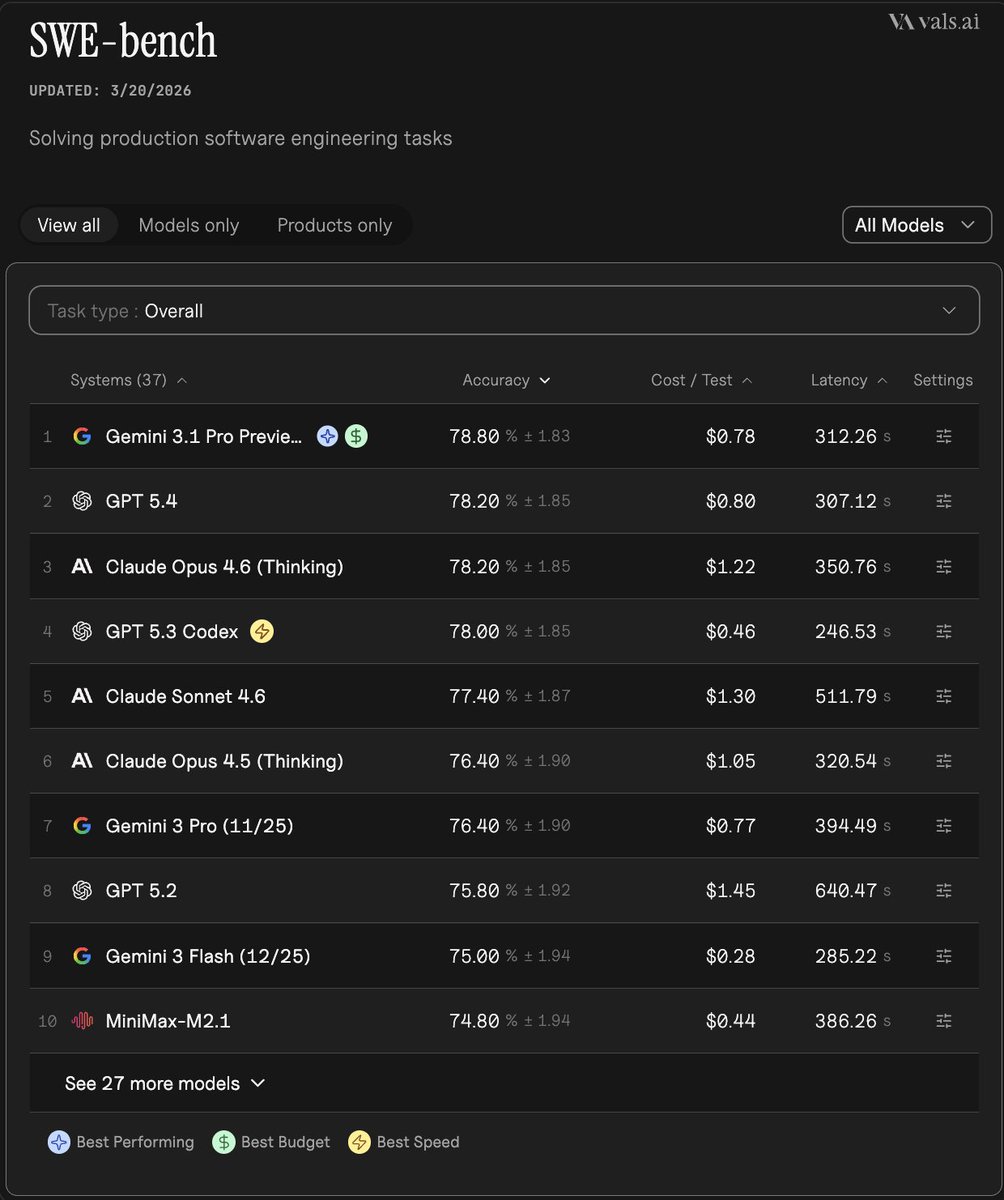
NVIDIA released Nemotron 3 Super, a 120B open model with 1M-token context and a hybrid architecture tuned for agent workloads, then landed it in Perplexity and Baseten. Try it if you need an open-weight long-context option that is already available in hosted stacks.

Nemotron 3 Super is an open-weight 120B model built for long-running agent systems rather than single-turn chat. The core problem, as the launch thread frames it, is that collaborating agents can generate "15x more text than normal" by repeatedly restating shared context, which turns reasoning-heavy workflows into a latency and cost problem.
NVIDIA's launch post says the model attacks that in three ways. First, it stretches context to 1 million tokens so agents can retain full workflow state. Second, it uses a sparse setup with 12B active parameters out of 120B total, reducing the compute used per task. Third, it combines Mamba layers for memory efficiency with Transformer layers for reasoning, then adds multi-token prediction to generate multiple future tokens per step. The same NVIDIA blog post claims up to 5x higher throughput and 2x better accuracy than prior models in agentic settings, and names AI-Q research agents and multistep enterprise workflows as target use cases.
Distribution was part of the launch, not a later follow-up. Perplexity's product update says Nemotron 3 Super is already selectable in its consumer chat product and available through Agent API and Computer, which matters for teams that want to test the model inside an existing hosted agent stack instead of standing up open weights from scratch. The attached [img:5|Perplexity model picker] shows it shipping alongside other frontier model options with a direct selector in the UI.
Baseten's launch-partner post says it is a day-0 partner and that users can try the model immediately on its platform. That gives engineers two early paths: a productized agent surface in Perplexity and model hosting through Baseten. For performance context, the benchmark graphic shared from Artificial Analysis puts Nemotron 3 Super at 452 output tokens per second, ahead of the other models shown on that chart, while Grok 4.20 appears at 265 tokens per second. That speed figure is from a third-party graphic rather than NVIDIA's launch materials, but it lines up with the release narrative that Nemotron 3 Super is being positioned as a high-throughput open option for long-context agent workloads.
Epoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
NVIDIA’s Nemotron 3 Super is now available in Perplexity, Agent API, and Computer.

NVIDIA open-sourced Nemotron 3 Super, a 120B param open model built to fix the massive bottlenecks slowing down autonomous AI agents. When collaborating AI agents talk to each other, they suffer from context explosion by constantly repeating their entire conversation history. Show more

In this piece, @kirkby_max and @oneill_c use constitutional alignment as a testbed to evaluate the importance of on- versus off-policy and dense versus sparse feedback during post-training.

x.com/i/article/2032…