Vals published a benchmark pass for Grok 4.20 Beta showing gains on coding, math, multimodal, and Terminal Bench 2, alongside weaker legal-task results. Check task-level results before adopting it, especially if legal workflows matter more than headline benchmark gains.

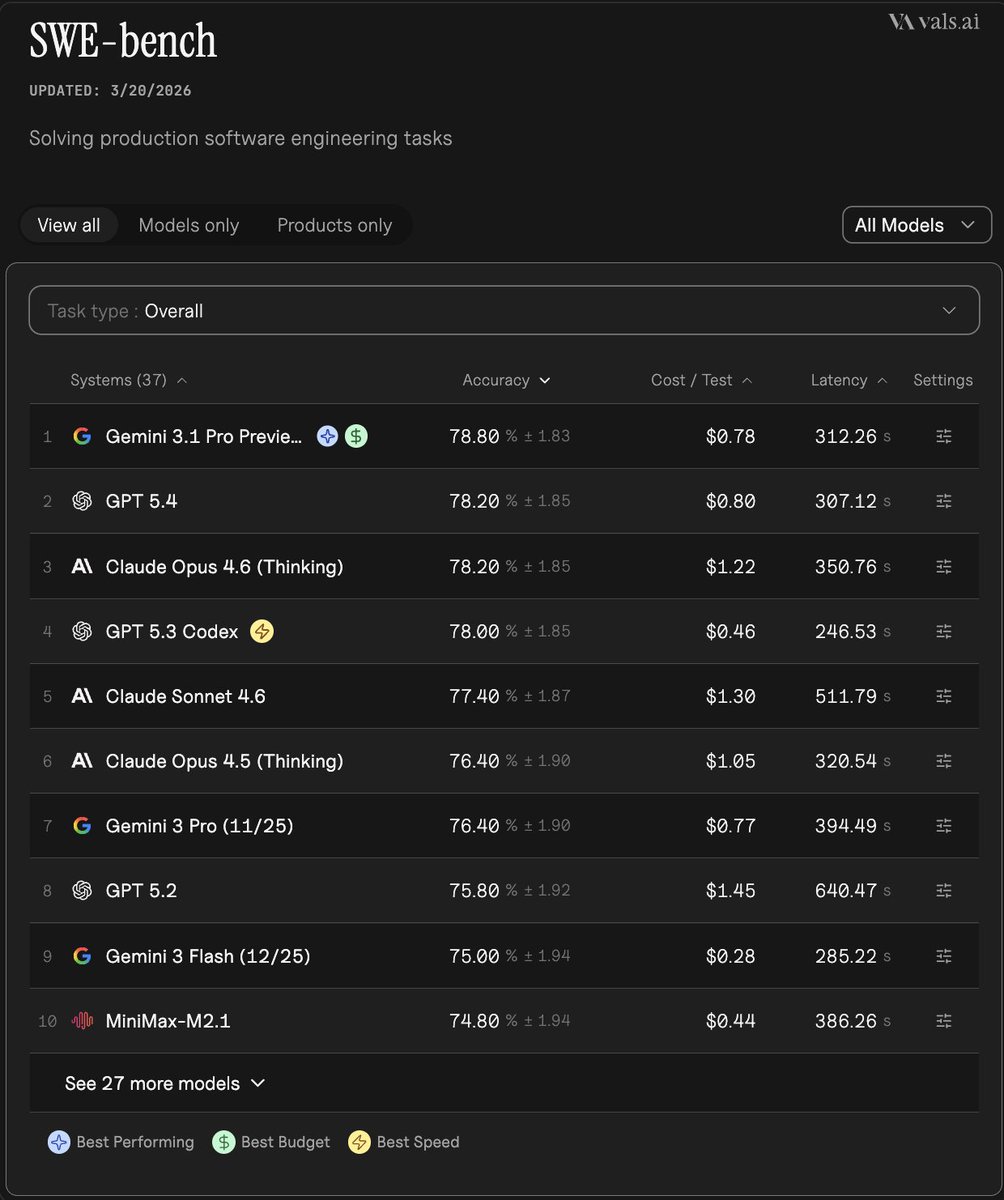
Vals' benchmark pass says Grok 4.20 Beta improved over Grok 4.1 Fast on a broad set of engineering-relevant tests, including AIME, GPQA, IOI, LiveCodeBench, SWE-Bench, and Terminal Bench 2 coding gains. The same thread says Vibe Code Bench rose from "1% to ~4%," a small absolute number but still a measurable gain on a test for building web apps from scratch coding gains.
The clearest single delta was ProofBench. Vals says the model "jumps up to 14%" from 4% on a benchmark for formally verified graduate-level math proofs ProofBench jump. On the multimodal side, Vals reports 83.47% and a #9 MMMU ranking, up from #31 for Grok 4.1 Fast, plus improvement on SAGE for grading handwritten solutions multimodal gains.
Vals says the model is "generally quite fast," with per-test latency on the Vals Index at roughly 20% to 50% of higher-performing models latency note. The benchmark card in Vals' post lists 85.58s latency, $0.28 cost per test, and a 2M context window and max output size for this snapshot benchmark card.
The same evaluation thread also flags two reasons not to overread the headline gains. First, legal-task performance lagged: Vals reports rankings of #30 on CaseLaw and #62 on LegalBench, calling out "less improvement or even regressions" on legal benchmarks legal regressions. Second, these numbers come from a beta snapshot run at temperature 0.7 and top_p 0.95 through the xAI API endpoint grok-4.20-beta-0309-reasoning, and Vals says performance may change in later releases eval settings beta caveat.
Epoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
We’ve finished evaluating the Grok 4.20 Beta (Reasoning) snapshot on our full suite of benchmarks. We find it to be an overall improvement over Grok 4.1 Fast (Reasoning).

Evaluations were run with a temperature of 0.7 and a `top_p` of 0.95 via the @xai API using the grok-4.20-beta-0309-reasoning endpoint. Full results are available on Vals AI.
The model is generally quite fast. On the Vals Index, it is approximately 20% to 50% of the latency (on a per-test basis) of higher performing models.