Meta открывает исходный код Omnilingual ASR для более чем 1600 языков — модели от 300 млн до 7 млрд параметров.
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Meta открыла исходники Omnilingual ASR, семейство энкодер–декодер речевых моделей размером от 300 млн до 7 млрд параметров и охватывающее более 1 600 языков. Если вы занимаетесь дубляжом, субтитрами или поиском, это объединяет разрозненные региональные стеки в единую рабочую конвейерную цепочку, которую можно разместить и настроить самостоятельно.
Ключ — масштаб и охват. Обученная на больших self-supervised корпусах и созданная для охвата недостаточно обслуживаемых языков, Omnilingual ASR безупречно интегрируется в голосовые рабочие процессы: транскрибируйте локально, подавайте ваш любимый TTS и выполняйте редактирование в обе стороны с меньшим количеством ошибок в именах и акцентах. Модели и артефакты наборов данных размещены на Hugging Face, так что вы сможете A/B проверить её на самых сложных аудио примерах перед развёртыванием (да, даже на той конференционной линии).
Меж тем, инструменты в реальном времени замыкают цикл: FlashVSR достигает 17 FPS при 4× увеличении масштаба с когерентными кадрами, а MotionStream сообщает ~29 FPS с задержкой примерно 0.4 с для путей камеры/объектов, управляемых мышью, на одном H100. Итог: речь в глобальном масштабе на входе, более чёткое видео на выходе и предпросмотр, которым можно управлять вживую — производственный цикл стал более тесным.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Feature Spotlight
Move the camera after the shot (Freepik)
Freepik’s Camera Angles brings post‑gen camera moves to the masses—rotate/reframe without re‑rendering, powered by Qwen Image Edit; creators across feeds demo real 3D‑style control inside Spaces.
Freepik ships Camera Angles, letting creators rotate views, shift perspective, and keep details—powered by Qwen Image Edit. Multiple demos show real 3D‑like camera control inside Spaces; this is new vs prior Flow/Veo posts.
Jump to Move the camera after the shot (Freepik) topicsTable of Contents
🎥 Move the camera after the shot (Freepik)
Freepik ships Camera Angles, letting creators rotate views, shift perspective, and keep details—powered by Qwen Image Edit. Multiple demos show real 3D‑like camera control inside Spaces; this is new vs prior Flow/Veo posts.
Freepik ships Camera Angles in Spaces for post‑shot reframing
Freepik launched Camera Angles in Spaces, a control that rotates views, shifts perspective, and keeps details—effectively moving the camera after the shot Launch video, with access live on the product page Spaces page.

Creator demos show on‑canvas angle/zoom handles for quick reframes Canvas demo and smooth orbit/zoom on an Eiffel Tower model 3D control demo. A recap notes it’s powered by Qwen Image Edit and calls out storyboard and consistent‑variant use cases Feature recap, and Freepik’s "Start now" link backs availability Spaces page, though at least one user says it hasn’t appeared yet Rollout feedback. This follows Shareable workflows in Spaces, tightening Freepik’s post‑gen toolkit for designers and filmmakers.
🧪 Google’s image model watch: Nano Banana 2 → “Ketchup”
Creators spot code showing Nano Banana 2 renamed to Ketchup—signals imminent image model update. New visual feats circulate (puzzle assembly, Blender‑style mockup). Excludes Freepik Camera Angles feature.
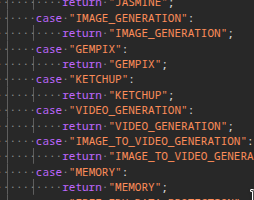
GEMPIX_2 shows up as “KETCHUP” in Gemini code, hinting NB2 launch
Code on Gemini’s site now maps GEMPIX_2 to KETCHUP, pointing to a rename and near‑term release Code on site; a second snippet backs the change and sparked the banana→tomato jokes Code snippet. This lands after Timing vs Gemini talk that NB2 might ship before Gemini 3, and it’s the first concrete naming signal.
Why it matters: naming flips like this often precede public endpoints and UI toggles creatives can actually use for image gen inside Gemini-powered tools.
Creators tout NB2 torn‑paper “reassembly” as image reasoning proof
A widely shared example claims Nano Banana 2 assembled torn handwritten scraps into a clean, correctly ordered sentence image Puzzle demo. If accurate, that suggests stronger spatial layout reasoning for page recovery, poster comps, and graphic cleanups that designers care about.
NB prompts yield “Blender screenshot” mockups with wireframes and UI
Asked to “turn this into a Blender screenshot,” Nano‑Banana produced a convincing composite with viewport UI chrome and mesh wireframes Blender request. Useful for quick look‑dev and pitch decks, but it also raises provenance risk for studios that require tool‑authentic captures.
🧩 Runway Workflows: sketch → image → video compositing
Runway posts a 6‑step guide for turning a still into an inserted moving element via Workflows (sketch keyframe → image gen → image‑to‑video → composite in edit). Excludes Freepik Camera Angles (feature).
Runway Workflows turn a sketch into a composited moving element
Runway shared a practical 6-step recipe to turn a sketched keyframe into a generated clip and composite it back into your original 4K footage using Workflows. The chain is: export a still, sketch the insert, generate a high‑fidelity image from the sketch with a reference, bridge clean plate→keyframe via Image‑to‑Video, then re‑import, scale, and position on your timeline; repeat per object to reimagine multiple areas without re‑rendering entire scenes Step one clip, Step two clip, Step three clip, Step five clip, Wrap-up note.

This matters if you need controlled post‑gen integration, previz, or quick set extensions with consistent lighting and placement. The flow is live in Workflows and demonstrated across the full thread, with a direct entry point here Runway Workflows.
🖼️ Fast edits and upscalers for stills
Two practical drops for image creators: Replicate’s Reve Image Edit Fast at ~$0.01/output and Qwen‑Edit‑2509 Upscale LoRA (16× recovery, blur/noise/JPEG fix). Heavier on photo realism than pure style today.
Replicate ships Reve Image Edit Fast at ~$0.01 per output
Replicate launched Reve Image Edit Fast, a natural‑language photo editor that preserves composition and spatial relationships at roughly $0.01 per output Release thread. The tool targets quick, localized edits (color, background, lighting) without re‑rendering the full scene, with a direct try link live now Reve edit fast page.
For fast social and product workflows, the appeal is speed and predictability: prompt in plain English, keep framing intact, and iterate cheaply.
Qwen‑Edit‑2509 Upscale LoRA promises up to 16× photo recovery
A new Qwen‑Edit‑2509 Upscale LoRA dropped on Hugging Face with claims of up to 16× resolution recovery and robust artifact cleanup across noise, motion blur (to ~64 px), and harsh JPEGs (~5% quality) Model card. A creator rundown recommends LCM or Euler Ancestral samplers and pairing with AuraFlow for smoother lighting transitions Creator guide. There’s also a quick Space demo and a before/after still to gauge behavior on real photos Space demo.
Who should try it: photographers and content teams restoring noisy, low‑res assets or cleaning oversharpened library shots before design/layout.
Lovart debuts Edit Elements (live editable text + layers), free for a month
Lovart introduced Edit Elements: live editable text (change copy/size/fonts without regenerating) and layer separation to move/resize subjects and backgrounds directly in the canvas Feature thread. The company says all plan subscribers can use it free for a month starting 11/11 with 0 credits required.

This is aimed at designers tired of rerolling whole images for small type/layout tweaks—treat outputs more like layered files and keep iterating in place.
Photo‑to‑Anime LoRA gets a live demo Space for Qwen‑Image‑Edit 2509
The Qwen‑Image‑Edit 2509 Photo‑to‑Anime LoRA now has a public demo Space to convert portraits into consistent anime looks in a single pass Hugging Face Space. This follows creator tests we noted earlier Photo-to-anime test, now with an official try link and broader visibility via Tongyi/Alibaba community shares LoRA overview.
Useful when you need stylized avatars or character sheets quickly without building a full pipeline.
⚡ 8‑up ideation with Hedra Batches
Hedra adds “Batches” for up to 8 images/videos in one click—speeding look dev and comparison passes. Separate from Freepik’s camera moves; this is about parallel generation throughput.
Hedra ships Batches: one click, eight generations for images and video
Hedra launched Batches, a new feature that generates up to 8 images or videos in one click to speed look‑dev and comparison passes for creative teams release thread. The launch includes a 12‑hour promo offering 1,000 free credits via follow/RT/reply, and early creator notes frame it as a quick way to explore motion and style variations in parallel creator recap.

This matters because it compresses the explore‑select loop. You can spin a grid, pick the keeper, then branch immediately into refinement, rather than waiting serially. For storyboards, music visuals, and shortform experiments, parallel outputs raise the odds that one option lands the brief on the first pass.
- Batch on the same prompt with different seeds to isolate composition vs. palette gains.
- Lock camera and subject tags, then vary motion/style words to compare movement feel across the 8.
- Route the winning frame or clip into your existing edit/upscale chain and archive the near‑misses as style references.
🎨 Today’s style recipes and references
Prompt/style assets shared for quick looks: anthropomorphic turnarounds, MJ V7 param collages, a Western‑anime sref, Firefly 5 prompt examples, and Leonardo’s Font Matcher Blueprint.
Leonardo’s Font Matcher Blueprint recreates type from a sample
Leonardo rolls out a Blueprint that lets you upload any typography sample and generate new copy in the same style—handy for mockups and brand frames without manual kerning or font hunts Feature demo.

Anthropomorphic triple‑view prompt: instant mascot turnarounds
Azed shares a reusable prompt for 3‑view character sheets (front‑left, front, back) that outputs clean, flat‑shaded mascots with consistent proportions and styling cues for branding or game UI Prompt and examples.
Firefly 5 photo prompts: Portra rose, B&W portraits, shadow play
Creator tests highlight Firefly Image 5’s photoreal lean using concrete prompts (e.g., Kodak Portra rose, ISO 100; high‑contrast B&W with deep shadows), useful as starting templates for product or editorial looks Prompt examples.
New MJ V7 collage preset: sref 2896183941 with chaos 13, stylize 500
A fresh Midjourney V7 recipe lands with --sref 2896183941, --chaos 13, --ar 3:4, --stylize 500, giving a cohesive crayon‑collage look—useful for editorial spreads and poster sets Param recipe, following up on MJ V7 collage look where an earlier sref + param combo was shared.
Midjourney sref for Cinematic Western Anime (4192156778)
Artedeingenio posts a style reference (--sref 4192156778) dubbed “Cinematic Western Anime/Hybrid Toon Realism,” tuned for bold, 2000s‑era toon lines with Western character design sensibilities Style reference.
🎙️ Voices, dubbing, and lipsync control
Higgsfield’s Lipsync Studio shows emotion sliders and music lipsync; their Swap Bundle promo adds year‑long face/character/voice swaps. ElevenLabs Summit teases product talks (live updates this week).
Higgsfield Lipsync Studio adds emotion slider and music‑accurate lip sync
Higgsfield’s Lipsync Studio now lets creators upload audio, drive mouth motion that tracks the song, and dial performance with an “Emotion” slider; it works on both stills and video and slots into the same toolset as Infinite Talk for longer dialogue Lipsync demo. Following up on Recast voice dubbing, this adds hands‑on performance control and a clean music‑sync pass in the UI, with a public workflow thread and partner link for immediate trials Workflow thread, and access via the official portal Higgsfield partner page.

ElevenLabs Summit SF starts; product announcements and sessions will be posted online
ElevenLabs kicked off its San Francisco Summit with a full agenda and says product announcements and recorded sessions will roll out online this week—useful if you rely on their voices, dubbing, or speech APIs and can’t attend live Summit agenda. The schedule highlights a keynote, enterprise talks, and a closing conversation with Jack Dorsey, hinting at both platform and ecosystem updates for voice creators.
Higgsfield Swap Bundle offers 365 days of unlimited face, character and voice swaps
Higgsfield introduced an annual Swap Bundle with unlimited Face Swap, Character Swap, plus voices and languages across images and videos for 365 days; the promo window ends Monday 23:59 UTC, signaling aggressive pricing for high‑volume creators Bundle offer.

📽️ Creator reels: Grok, Hailuo, Veo, Kling, PixVerse
A lighter but steady stream of short demos across video models—stylized Grok cuts, Hailuo 2.3 action, Veo 3.1 motifs, Kling anime camera work, and a PixVerse character vignette. Excludes Freepik Camera Angles (feature).
Hailuo 2.3: action montage and Midjourney→Hailuo handoff tests
Hailuo 2.3 showed off fast, readable action with a monster fight montage, plus a creator demo handing a Midjourney still into Hailuo for motion—useful for stylized previz and punchy shorts. See the fight cut in Action demo and a still‑to‑motion pass in Model handoff demo.

Kling 2.5 nails anime camera moves: orbit and crash‑zoom tests
Anime‑style camera control looks convincing in Kling 2.5, with smooth orbits and snappy crash zooms that hold character detail. A separate chambara test reinforces motion fidelity for stylized combat. See the orbit+crash zoom in Orbit and zoom demo and another motion sample in Chambara test.

More Grok Imagine micro‑shorts land with stylized motion and mood
Creators dropped fresh Grok Imagine cuts today, leaning on stylized motion, abstract light, and clean typography—following up on Creator praise that the latest build animates well. Two new clips highlight moody abstraction and a fantasy dragon reveal, showing usable beats for bumpers and interstitials. See examples in Dragon teaser and Abstract poetry clip.

Veo 3.1 gets a tight Batman signal beat from runware
A quick Veo 3.1 vignette nails a cinematic Bat‑Signal moment, with stable lighting and on‑brand framing. It’s a neat reference for logo reveals or title cards where you need a clean eight‑second hit without artifacts. Watch the cut in Short Batman clip.

PixVerse posts a charming micro‑vignette with an expressive pet
A light “Good Morning” beat from PixVerse shows a small character performance that reads well in a vertical format—handy for reels or bumper ideas where one emotive gesture carries the scene. Watch the moment in Pet good‑morning clip.

🤖 Agent tools and MCP interoperability for creatives
Agentic workflows inch toward standardization: Google’s MCP whitepaper for tools/interop, an OSS MCP‑compatible runtime in progress, and a curated repo of Claude skills for real‑world ops.
Google details agent tool interop with MCP in new Nov 2025 paper
Google published a November 2025 "Agent Tools & Interoperability with MCP" white paper, outlining patterns for tool schemas, capability negotiation, and how to keep agents backward‑compatible with MCP servers. It surfaced via a Google course and is free to grab now Kaggle whitepaper, with the PDF on the same page Kaggle white paper.
Why it matters: creative teams can standardize agent skills across editors, renderers, and asset pipelines without locking into one vendor; the paper gives a blueprint for shared tool contracts and routing.
OSS MCP‑compatible runtime in the works; backward‑compatible by design
Matt Shumer says he’s building an MCP alternative that “just works better,” will be open‑sourced, and remain backward‑compatible with MCP OSS plan. For creatives, a sturdier, drop‑in runtime could stabilize agent chains that call image, video, and voice tools while keeping existing MCP skills usable.
Curated “Awesome Claude Skills” repo hits 450+ stars
A community list of Claude “Skills” — reusable workflows for Claude.ai, Claude Code, and the API — now spans document ops, code generation, and research automation with real examples, and has cleared 450+ stars Repo spotlight. The index is organized by category and welcomes PRs, useful for bootstrapping agent tasks in creative studios GitHub repo.
📚 R&D to watch: spatial reasoning, agents, ASR
A mixed stack of new papers: visuospatial tuning for VLMs, agentic multimodal planning, large‑scale multilingual ASR, and studies on LLM villain role‑play limits. Mostly research teasers and project pages today.
Meta open-sources Omnilingual ASR: 300M–7B models for 1,600+ languages
Meta unveiled Omnilingual ASR, an encoder‑decoder family from 300M up to 7B parameters covering 1,600+ languages, built with large‑scale self‑supervised pretraining and designed for extensibility to underserved tongues Paper overview. For dubbing, captions, and search, this materially widens language reach; dataset details sit on Hugging Face Dataset page.
Visual Spatial Tuning ships 4.1M-sample dataset and hits SOTA spatial scores
ByteDance Seed and HKU introduced Visual Spatial Tuning (VST), pairing VST‑P (4.1M samples across 19 skills) with VST‑R (135K) to train visuospatial perception and reasoning in VLMs, reporting 34.8% on MMDI‑Bench and 61.2% on VSIBench without extra expert encoders Paper teaser, with the full write‑up available in an ArXiv mirror ArXiv paper. For creatives, stronger spatial grounding means tighter control over layout, blocking, and camera instructions in image/video models.
DeepEyesV2 outlines a path to agentic multimodal planning
The DeepEyesV2 paper sketches an "agentic multimodal" stack aimed at planning and tool‑use across vision and language—positioned more as a framework than a product today Project video, with details in the accompanying paper ArXiv paper. If it holds up, teams get a clearer recipe for models that can both understand scenes and decide what to do next.

Physical world model steers a real robot to sort blocks
“Robot Learning from a Physical World Model” shows a learned world model guiding a real robotic arm to quickly sort tabletop blocks, with the demo highlighting fast, precise behaviors and transfer from model to robot Robot demo. The method and evaluation details are outlined in the paper ArXiv paper, hinting at more reliable perception‑to‑action loops for creative robotics and on‑set tools.

LLMs still avoid convincing villain role-play under alignment constraints
The “Too Good to be Bad” study introduces a Moral RolePlay benchmark and finds popular LLMs falter on antagonistic traits such as deceit and manipulation, attributing failures to safety alignment rather than capability gaps Paper summary, with the paper hosted on ArXiv ArXiv paper. This follows self‑reporting, which flagged low success detecting injected thoughts; together, they mark current limits for controlled persona in narrative tools.
🚀 Real‑time video enhancement and control
Two R&D‑grade pipelines relevant to editors: FlashVSR hits 17 FPS 4× upscaling with temporal coherence; MotionStream runs mouse‑driven object/camera paths at ~29 FPS on a single H100.
FlashVSR hits real-time 4× video upscaling at 17 FPS with streaming pipeline
FlashVSR debuts a real‑time 4× HD upscaler that runs at 17 FPS with minimal‑latency streaming and claims 12× speedups over prior diffusion upscalers, while maintaining temporal coherence and offering pretrained weights for immediate use feature summary, with technical details in the team’s write‑up FlashVSR blog. This moves AI upscaling from overnight renders to interactive preview for editors and motion designers.

If you’ve been holding off on AI upscaling due to lag and jitter, this looks production‑viable for dailies and social cuts; teams can wire it in as a live “quality bump” pass before final conform.
MotionStream shows mouse‑driven camera/object control at ~29 FPS on one H100
MotionStream, from Adobe Research with CMU and SNU, runs infinite‑length generative streams where you drag the mouse to set object motions and camera paths; the demo cites ~29 FPS and ~0.4 s latency on a single H100, aimed at real‑time previs and blocking demo clip. For small video teams, this hints at layout and timing work you can do interactively instead of prompt‑iterate‑wait.

Expect limits on complex scene physics today, but the latency and FPS numbers make it useful as a live sandbox for beats and camera feels.
📅 Screenings, challenges, and hack nights
Opportunities to learn/show work: Generative Media Conference recap+talks, Build’s “Real World Hack”, Dreamina’s Thanksgiving design challenge, and AI Slop Review live stream with Gerdegotit.
Generative Media Conference posts full talks and recap
fal published the recorded talks from the Oct 24 Generative Media Conference alongside a written recap and confirmed the event returns in Oct 2026. Creatives can now binge the sessions and pull detailed notes today. See highlights in the wrap video Event wrap video, the written debrief in the blog Blog recap, and the full YouTube playlist Talks playlist.
“Building for the Real World” hack hits SF on Dec 2
Build, Operators & Friends, and Pebble Bed are hosting a six‑hour hack night in San Francisco on Dec 2, aiming to gather 100 engineers, founders, and makers working with AI for physical-world problems. Apply if you want dense, practical collisions around cities, factories, and machines Hackathon brief, with details on the event site Event site.
Dreamina launches Thanksgiving Turkey challenge: 30 winners by Nov 16 PT
Dreamina’s “Thanksgiving Turkey Design Challenge” is live across X/Instagram/TikTok with 30 winners, free credits/subscriptions, and custom certificates. Submissions close Nov 16 (PT), with winners announced Nov 27; rules, prizes, and how to enter are spelled out in the post Challenge post.
OpenArt × MachineCinema share Gen Jam winners from LA, NY, SF
OpenArt posted the three winning music videos from recent Gen Jam events in Los Angeles, New York, and San Francisco—useful references for pacing, grading, and AI‑assisted story beats. Start with the winners roundup Winners roundup, then sample the LA piece LA winner and the New York selection NY winner.


AI Slop Review goes live 11/12 with GerdeGotIt (10pm CET)
heyglif is streaming a live AI Slop Review on Nov 12 at 10pm CET featuring @GerdeGotIt, billed as the first AI artist to cross 1M followers. It’s a good watch‑along for art direction and process; grab the YouTube link and timebox it now Livestream details, with the stream link here YouTube stream.

While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught