Datalab-to open-sourced Chandra OCR 2, a 4B document model with repo, weights, demo, and CLI quickstart, and claims state-of-the-art 85.9 on olmOCR Bench. It gives document pipelines a practical multilingual OCR option that can run with local tooling instead of only hosted APIs.

chandra-ocr, starts chandra_vllm, and runs chandra input.pdf ./output quickstart.Chandra OCR 2 is available as open-source weights, code, and a hosted demo rather than only as a managed OCR API. The release thread points users to a GitHub repo and HF weights, while the quickstart shows a minimal local flow: install the package, launch chandra_vllm, then run OCR on a PDF from the command line quickstart.
The repository description adds the implementation details engineers will care about: local inference via Hugging Face Transformers or a production-oriented vLLM server, structured outputs with layout coordinates, and export targets including Markdown, HTML, and JSON GitHub repo. The same repo also frames the target workload as harder document parsing, including handwriting, tables with merged cells, equations rendered as LaTeX, forms, invoices, and multi-column pages repo docs.
The headline metric is 85.9 on olmOCR Bench, which Datalab describes as state of the art, alongside a multilingual eval showing “major improvements across languages” in the launch thread eval thread. A benchmark screenshot from a separate post places datalab-to/chandra-ocr-2 at the top of the allenai/olmOCR-bench leaderboard, ahead of dots.ocr-1.5 at 83.9 and LightOnOCR-2-1B at 83.2 leaderboard screenshot.
The sample outputs are aimed at the messy cases that usually force fallback logic in document pipelines. The image set shows extraction of Chinese academic text with formulas, handwritten math notes, and layout-heavy matrix notation, with the rendered side preserving structure instead of flattening everything into plain text
.
The release is not pitched as flawless. Datalab says known limitations include cases where leading line numbers are reproduced verbatim, which matters for downstream parsing, chunking, and citation-sensitive workflows limitations.
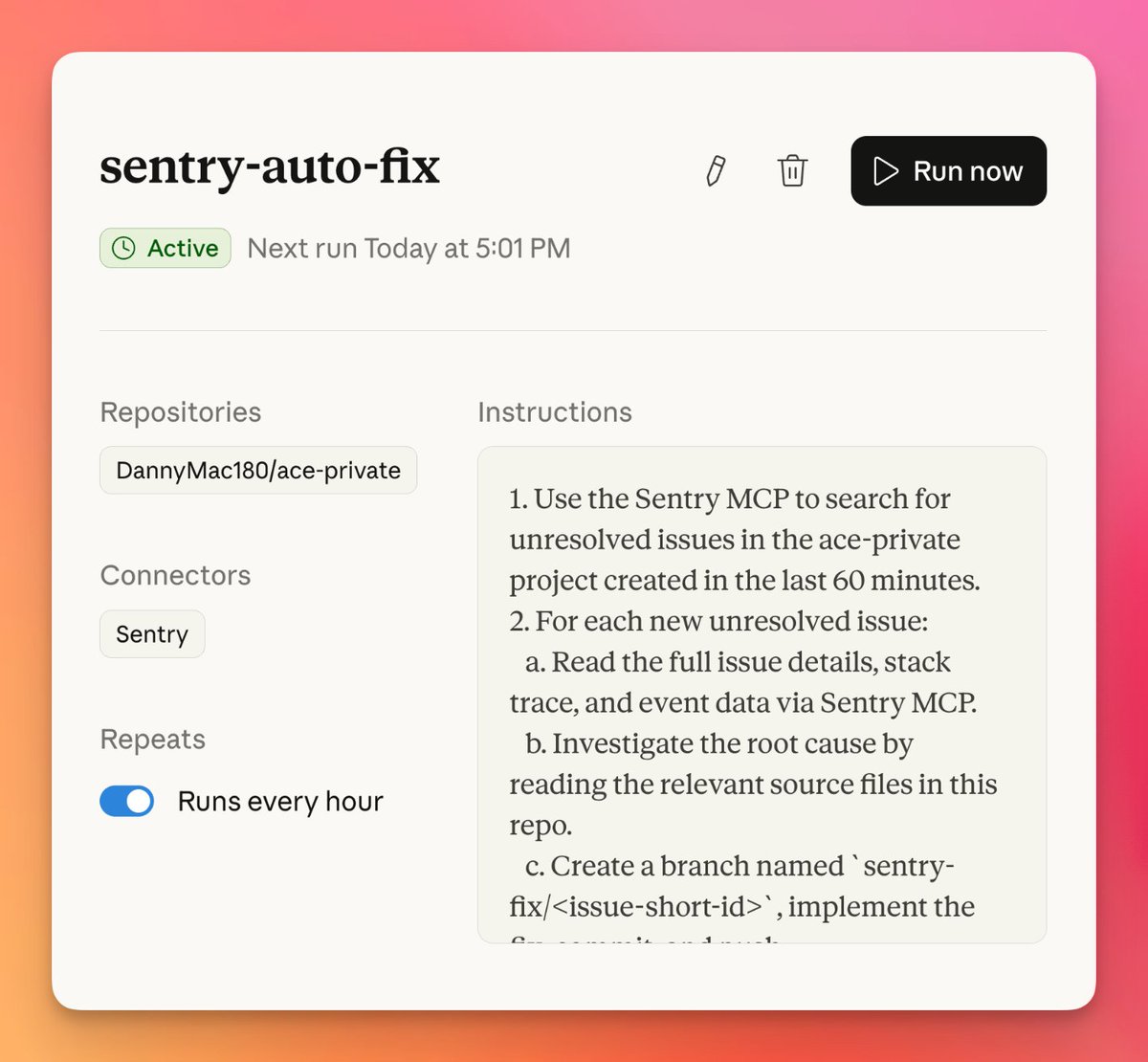
Vercel Emulate added a programmatic API for creating, resetting, and closing local GitHub, Vercel, and Google emulators inside automated tests. That makes deterministic integration tests easier to wire into CI and agent loops without manual setup.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
I'm excited to open source Chandra OCR 2! - 85.9% (sota) on olmocr bench - 90+ language support w/benchmarks - 4B model (down from 9B) - Full layout information - Extracts + captions images and diagrams - Strong handwriting, math, form, table support

Here are a few more examples of math, handwriting, image captioning, and layout:




Chandra OCR 2 has some known limitations we're working on: - Leading line numbers will sometimes be included verbatim - Very complex newspaper layouts may skip some text
How to get it: - Huggingface - huggingface.co/datalab-to/cha… - Github - github.com/datalab-to/cha… - Demo - datalab.to/playground