Anthropic launched Code Review in research preview for Team and Enterprise, using multiple agents to inspect pull requests, verify findings, and post one summary with inline comments. Teams shipping more AI-written code can try it to increase review depth, but should plan for higher token spend.

Code Review adds an automated PR-review path to Claude Code. When a pull request opens, Anthropic says Claude “dispatches a team of agents to hunt for bugs,” with those agents running independently, cross-checking one another’s findings, and then collapsing the output into a single high-signal summary plus inline comments in the diff, according to Anthropic's launch thread and the product post.
This is explicitly a deeper pass, not the company’s existing lightweight PR tooling. Anthropic says Code Review “optimizes for depth,” while a follow-up note says the older open-source pr-review Skill remains available but the new setup is “far more powerful.”
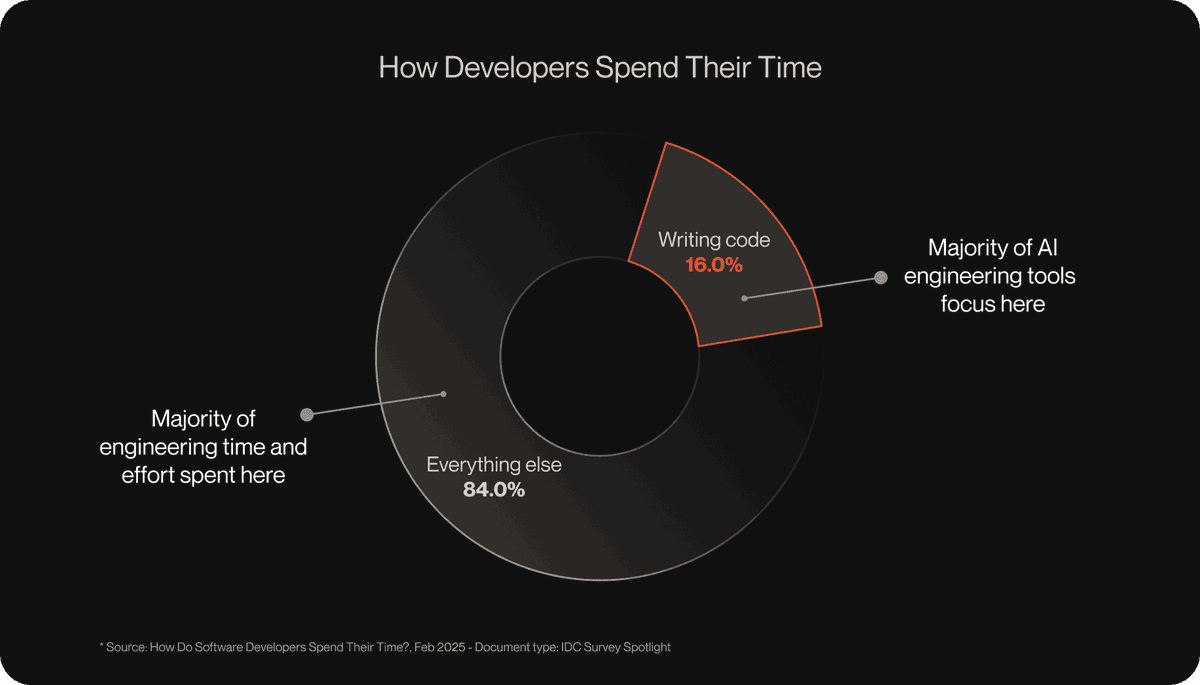
Anthropic built the feature against its own workflow first. An Anthropic engineer said code output per engineer is up “200% this year” and that reviews had become the bottleneck, which frames why the company is spending more tokens on deeper review passes rather than faster, cheaper checks Engineer context.
The internal metrics are the main technical payload in this launch. Anthropic says PRs with substantive review comments increased from 16% to 54%, and fewer than 1% of review findings were marked incorrect by engineers Anthropic's data. On PRs larger than 1,000 lines, it says 84% produced findings with an average of 7.5 issues each large-PR stats. A supporting walkthrough adds that a typical review takes about 20 minutes and cites examples including a one-line auth change that “would have broken production authentication” and a type mismatch that silently cleared an encryption-key cache supporting walkthrough.
Anthropic is positioning Code Review above its existing GitHub Action in both depth and price. The company says reviews generally average $15–25 and scale with PR complexity, while a pricing summary reiterates that this is “more expensive than lighter-weight options” and is currently limited to Team and Enterprise in research preview.
The immediate practitioner pushback is about independence, not capability. One reaction argues that “creation and verification are different engineering problems” and questions whether the same vendor stack should both write and review code trust critique; another puts it more bluntly, saying they “wouldn't want the same system reviewing my code that wrote it” skeptical reaction. That makes this launch less a generic AI-review feature than a bet that multi-agent verification can raise review depth enough to justify both the extra spend and the governance questions.
Claude can now drive macOS apps, browser tabs, the keyboard, and the mouse from Claude Cowork and Claude Code, with permission prompts when it needs direct screen access. That makes legacy desktop workflows automatable, and Anthropic is pairing the push with more background-task support for longer agent loops.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
New in Claude Code: Code Review. A team of agents runs a deep review on every PR. We built it for ourselves first. Code output per Anthropic engineer is up 200% this year and reviews were the bottleneck Personally, I’ve been using it for a few weeks and have found it catches Show more
Code review for Claude Code is here. More attention on this problem is a good thing. Because it is a big one. The question isn't whether you need AI-assisted review. It's whether the system doing the reviewing is actually independent from the system that wrote the code. Show more

Introducing Code Review, a new feature for Claude Code. When a PR opens, Claude dispatches a team of agents to hunt for bugs.
Introducing Code Review, a new feature for Claude Code. When a PR opens, Claude dispatches a team of agents to hunt for bugs.
AI is helping us write code 200% faster, which means human code review has become a massive bottleneck. To fix this, Anthropic launched Code Review for Claude Code! When a PR is opened, Code Review dispatches a team of AI agents that work in parallel. They hunt for bugs, Show more
Introducing Code Review, a new feature for Claude Code. When a PR opens, Claude dispatches a team of agents to hunt for bugs.
The existing pr-review Skill is still a good reference and will remain open source, but this new Code Review for Claude Code setup is far more powerful.