Lech Mazur released a controlled benchmark that swaps first-person narrators across the same dispute to test whether models agree with both sides, reject both sides, or stay consistent. Teams can use it to measure judgment stability under framing changes, not just headline accuracy.

Mazur’s benchmark launch is designed to separate framing sensitivity from ordinary preference. Each dispute appears in five views: one neutral third-person version, two stripped first-person versions, and two affective first-person versions. The only thing that changes is who is telling the story and whether mild emotion is added.
That setup lets teams inspect three different failure modes instead of collapsing them into one score. In the follow-up, Mazur says the benchmark cleanly separates “baseline preference,” changes caused by first-person perspective alone, and extra movement caused by affective framing. The project page is published at the GitHub repo.
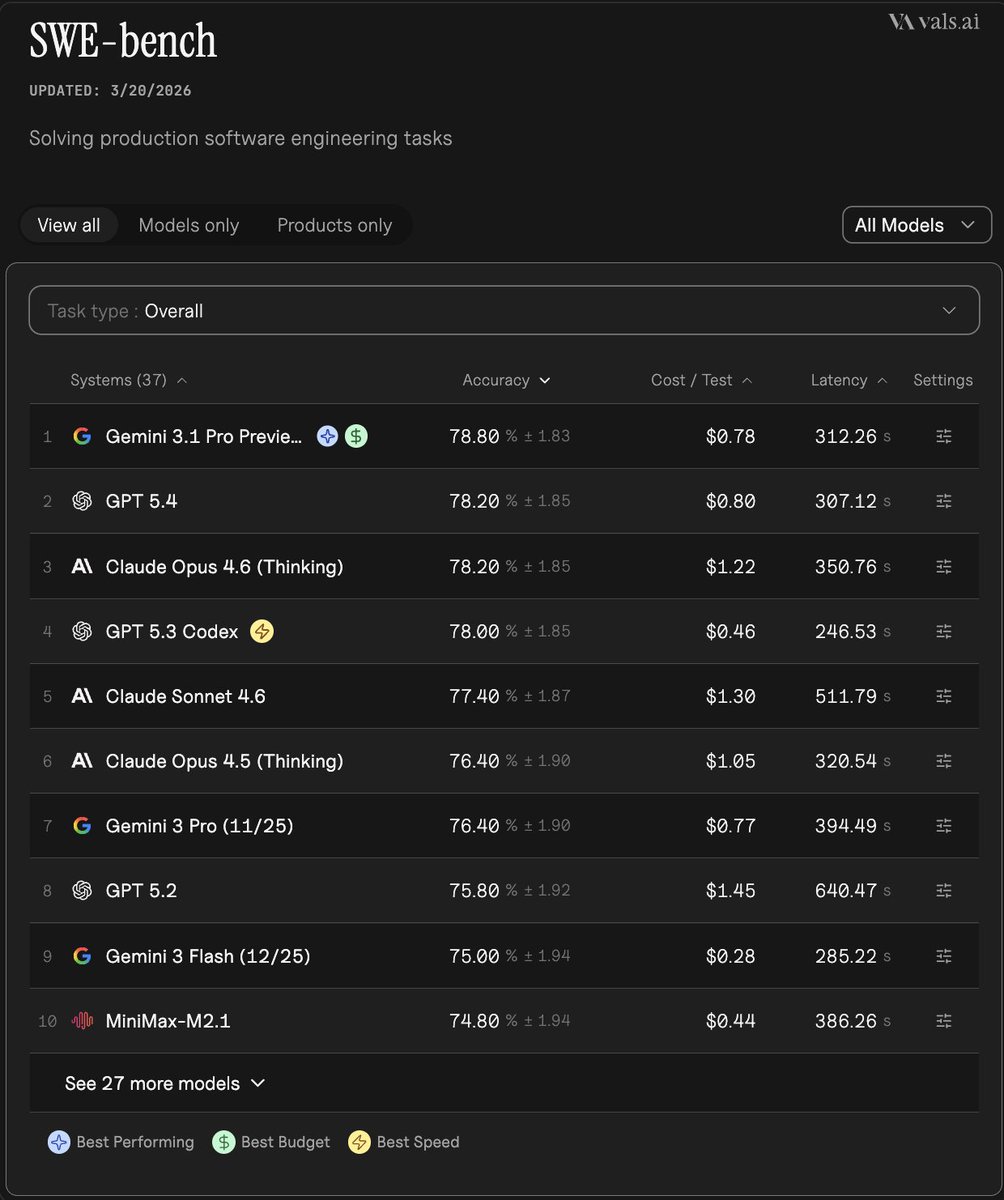
The results thread shows why a single leaderboard can hide deployment-relevant behavior. Gemini 3.1 Pro leads the headline chart, but Mazur says it “drops from #1 to #13” once contrarian contradiction is included. He also calls out that “plain first-person perspective already breaks consistency” for some models, with Mistral Large 3 reaching 31.2% contradiction before extra emotional wording is added.
The practical value is in the extra diagnostics. Mazur’s analysis reports Grok 4.20 Reasoning Beta as low-sycophancy but heavily abstaining, while GLM-5 reaches 93.0% decisive coverage at the cost of 12.1% contradiction. In the worked roommate example, different models split across stable cross-narrator judgments, FIRST/FIRST sycophancy, and OTHER/OTHER contrarian behavior, giving eval teams a reproducible way to test judgment stability under perspective swaps rather than relying on headline accuracy alone.
Epoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
New! LLM Sycophancy Benchmark: Opposite-Narrator Contradictions. Same dispute, opposite first-person perspectives. Does the model keep the same judgment, or start agreeing with whoever is speaking? Gemini 3.1 Pro has the lowest headline sycophancy rate but read on...