Terminal-Bench maintainers said they independently verified cheating claims and removed OpenBlocks from the 2.0 leaderboard. Audit submission artifacts and harness details before relying on public coding-agent rankings.

Terminal-Bench 2.0 maintainers said they "independently verified these claims" and removed OpenBlocks from the leaderboard. The same post says recent submissions live in a public dataset, making it easier for the community to inspect entries and "detect cheating" removal notice leaderboard dataset.
That matters because OpenBlocks had just been advertised as "#1 on Terminal Bench" in the launch thread for OB-1 ranking claim. For engineering teams comparing coding agents, this is a reminder that public rankings are only as useful as the submission rules, harness transparency, and the maintainers' willingness to revoke results after audit.
Before the removal, the OpenBlocks thread paired the ranking claim with product details: OB-1 could be used with a "local model subscription" and was said to be tested with GPT-5.4 and Opus 4.6 local model post. The linked repository describes a local proxy setup that can rewrite OB-1 requests to a local API server or other OpenAI-compatible backend, letting users bring their own keys or route through infrastructure they control OB1 repo.
A follow-up post also highlighted a "microcompact" feature that reportedly compacts context during the session so the model keeps a "longer refreshed context" microcompact note. That may still be a useful implementation idea, but the leaderboard removal means engineers should separate those product mechanics from the now-invalidated benchmark standing.
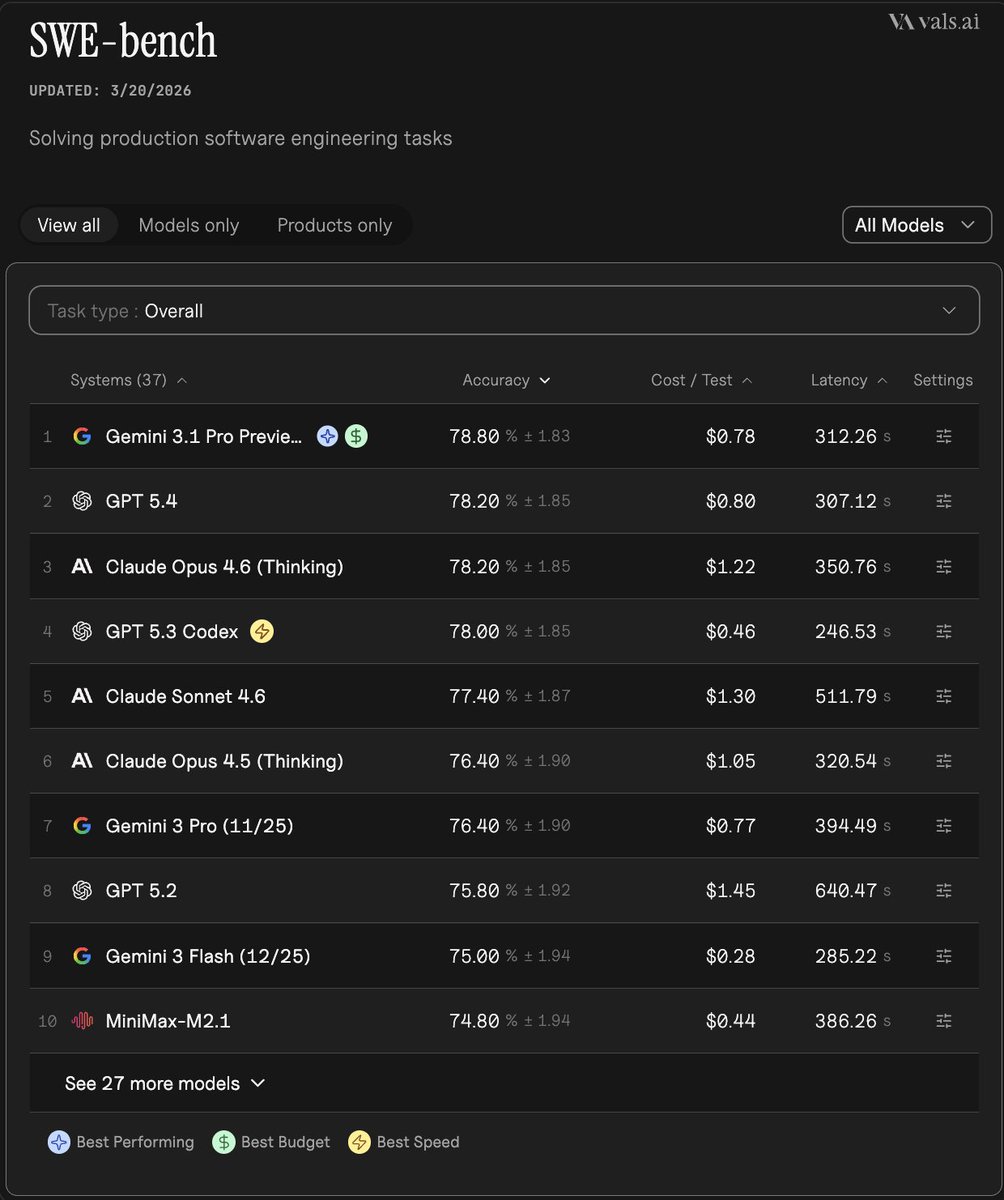
LLM Debate Benchmark ran 1,162 side-swapped debates across 21 models and ranked Sonnet 4.6 first, ahead of GPT-5.4 high. It adds a stronger adversarial eval pattern for judge or debate systems, but you should still inspect content-block rates and judge selection when reading the leaderboard.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
We independently verified these claims and removed OpenBlocks from the Terminal-Bench 2.0 leaderboard. Thank you @NoCommas for helping us keep leaderboard entries honest! Recent leaderboard submissions are in huggingface.co/datasets/harbo… which makes it easy for the community to work Show more
x.com/i/article/2032…