OpenAI described an internal system that uses its strongest models to review almost all coding-agent traffic for misalignment and suspicious behavior. It is a sign that powerful internal agents may need continuous oversight, not just pre-deployment policy checks.

OpenAI's new write-up describes an internal monitoring system for coding agents that reviews agent interactions within roughly 30 minutes and looks at both actions and internal reasoning for signs of behavior that diverges from user intent or company policy. The post positions this as monitoring for "misaligned behavior in real-world deployments," not just red-teaming before launch deployment write-up.
The clearest new metric is the reported coverage level: Marcus J. Williams, in a post amplified by OpenAI, said the company now monitors "99.9% of internal coding traffic" for misalignment coverage claim. That suggests OpenAI has pushed this from a sampling-based safety exercise into near-universal observability for internal agent use.
The engineering takeaway is that powerful coding agents may need continuous runtime oversight once they gain real tool access. OpenAI's monitoring page says internal deployments create unique risks because agents can access sensitive systems and could potentially modify safeguards, so the company built a pipeline that flags suspicious sessions for fast triage instead of relying only on static policy checks.
That matters beyond OpenAI because the pattern is concrete: use a stronger model to watch production-like agent traces, inspect both tool use and reasoning, and close the loop quickly when something looks off. OpenAI's write-up explicitly argues for industry-wide monitoring standards for internal coding agents as those systems become more autonomous.
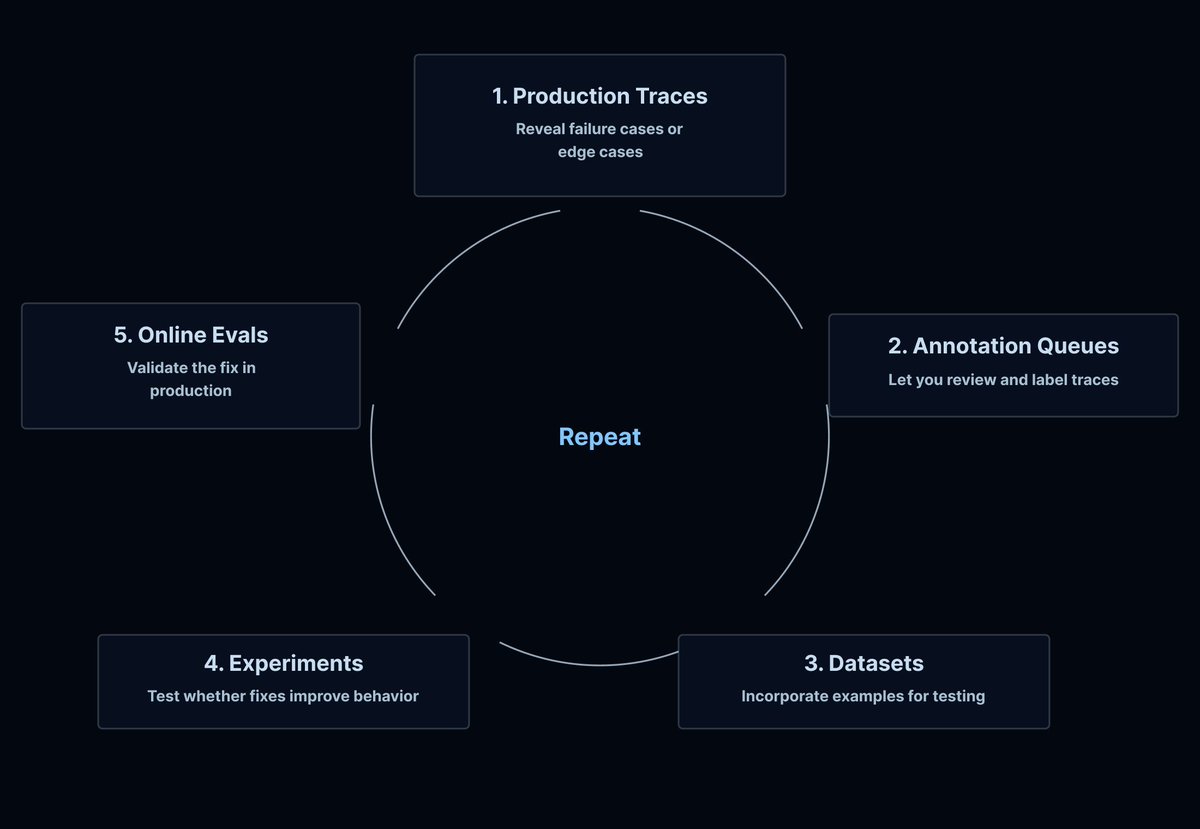
LangChain published a free course on taking agents from first run to production-ready systems with LangSmith loops for observability and evals. The timing lines up with new NVIDIA integration messaging, so teams can study process and stack choices together.
 release
releaseOpenClaw shipped version 2026.3.22 with ClawHub, OpenShell plus SSH sandboxes, side-question flows, and more search and model options, then followed with a 2026.3.23 patch. Teams get a broader plugin surface, but should patch quickly and review plugin trust boundaries as the ecosystem grows.
 release
releaseCursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
 breaking
breakingChatGPT now saves uploaded and generated files into an account-level Library that can be reused across conversations from the web sidebar or recent-files picker. It removes repetitive re-uploading and makes past PDFs, spreadsheets, and images part of a persistent working context.
 breaking
breakingEpoch AI says GPT-5.4 Pro elicited a publishable solution to one 2019 conjecture in its FrontierMath Open Problems set, with a formal writeup planned. Treat it as an early milestone worth reproducing, not blanket evidence that frontier models can already automate math research.
openai.com/index/how-we-m… "How we monitor internal coding agents for misalignment - Using our most powerful models to detect and study misaligned behavior in real-world deployments."
Sharing some of the work I’ve been doing at OpenAI: we now monitor 99.9% of internal coding traffic for misalignment using our most powerful models, reviewing full trajectories to catch suspicious behavior, escalate serious cases quickly, and strengthen our safeguards over time.

Sharing some of the work I’ve been doing at OpenAI: we now monitor 99.9% of internal coding traffic for misalignment using our most powerful models, reviewing full trajectories to catch suspicious behavior, escalate serious cases quickly, and strengthen our safeguards over time.