OpenAI said GPT-5.4 ramped faster than any prior API model, reaching 5 trillion daily tokens within a week, while third-party benchmarks placed it in the top tier on general reasoning. Track production behavior before wider rollout if coding and follow-up quality matter to your stack.

OpenAI's GPT-5.4 launch post says the model ships with a 1 million-token context window, a new Tool Search API, and a "Thinking" mode that exposes upfront planning. The same launch materials also position GPT-5.4 across ChatGPT, the API, and Codex rather than as a chat-only upgrade, which matters for teams standardizing one model family across interactive use and programmatic workloads.
The launch post also claims better performance on long-horizon professional tasks, coding, and agent-style workflows, plus native computer-use capabilities for agents operating across applications OpenAI's launch post. In practice, that package is less about a single benchmark win than about widening the set of workflows that can stay inside one model call path.
OpenAI product lead GDB wrote that GPT-5.4 "ramped faster than any other model we've launched in the API," hitting 5T tokens per day within a week of launch API ramp post. He added that this was "more volume than our entire API one year ago" and said the model had already reached an annualized run rate of $1B in net-new revenue, which makes this one of the clearest public demand signals OpenAI has given for a fresh API model.
A supporting repost amplified a claimed "32× efficiency improvement in just the last 3 months" from GPT-5.2 to GPT-5.4, with "37 cents/task" cited in the quoted text efficiency repost. OpenAI has not broken out the methodology in this evidence set, so that figure should be treated as a company-circulated claim rather than a reproducible benchmark.
Outside the core model launch, the adjacent coding-agent market also appears to be accelerating. One widely shared usage post says Codex has "2M+ weekly active users," up almost 300% since early January WAU estimate, while Sam Altman separately boosted a chart showing Codex usage "growing very fast" usage growth chart. Those numbers are not direct GPT-5.4 API metrics, but they do show strong pull for OpenAI-linked coding workflows at the same moment GPT-5.4 is ramping.
Artificial Analysis scored GPT-5.4 (xhigh) at 57 on its Intelligence Index, tying it for the top slot in the posted chart Artificial Analysis. The same post lists pricing at $2.50 per million input tokens and $15 per million output tokens, output speed at 72.5 tokens per second, and first-token latency at about 185 seconds, based on a full evaluation run that generated 120 million tokens.
That mix tells a familiar frontier-model story: top-tier aggregate reasoning scores, but with startup latency that will matter for interactive products unless teams use it selectively. The launch materials' emphasis on professional and agentic use OpenAI's launch post fits that profile better than low-latency chat or always-on code completion.
OpenAI executives also framed the qualitative jump as meaningful. Sam Altman said he could "really feel" the "5.3 -> 5.4 upgrade" Altman reaction, but the harder engineering signal remains the combination of third-party ranking data benchmark post and OpenAI's own production-scale claim API ramp post.
GPT-5.4 mini and nano bring 400K context, multimodal input, and the full GPT-5.4 reasoning-mode ladder at lower prices. Early benchmarking suggests nano is the strongest cost-performance tier for agentic tasks, but both models spend far more output tokens than peers.
 breaking
breakingMalicious LiteLLM 1.82.7 and 1.82.8 releases executed .pth startup code to steal credentials and were quarantined after disclosure. Rotate secrets, audit transitive AI-tooling dependencies, and add package-age controls before letting agents install packages autonomously.
 breaking
breakingTurboQuant claims 6x KV-cache memory reduction and up to 8x faster attention on H100s without retraining or quality loss on long-context tasks. If those results hold in serving stacks, teams should revisit long-context cost, capacity, and vector-search design.
 release
releaseOpenCode is adding remote sandboxes, synced state across laptop, server, and cloud, and more product surface inside its plugin system. That makes long-running off-laptop workflows more practical, but operators should still review telemetry, sandbox, and exposure defaults.
 release
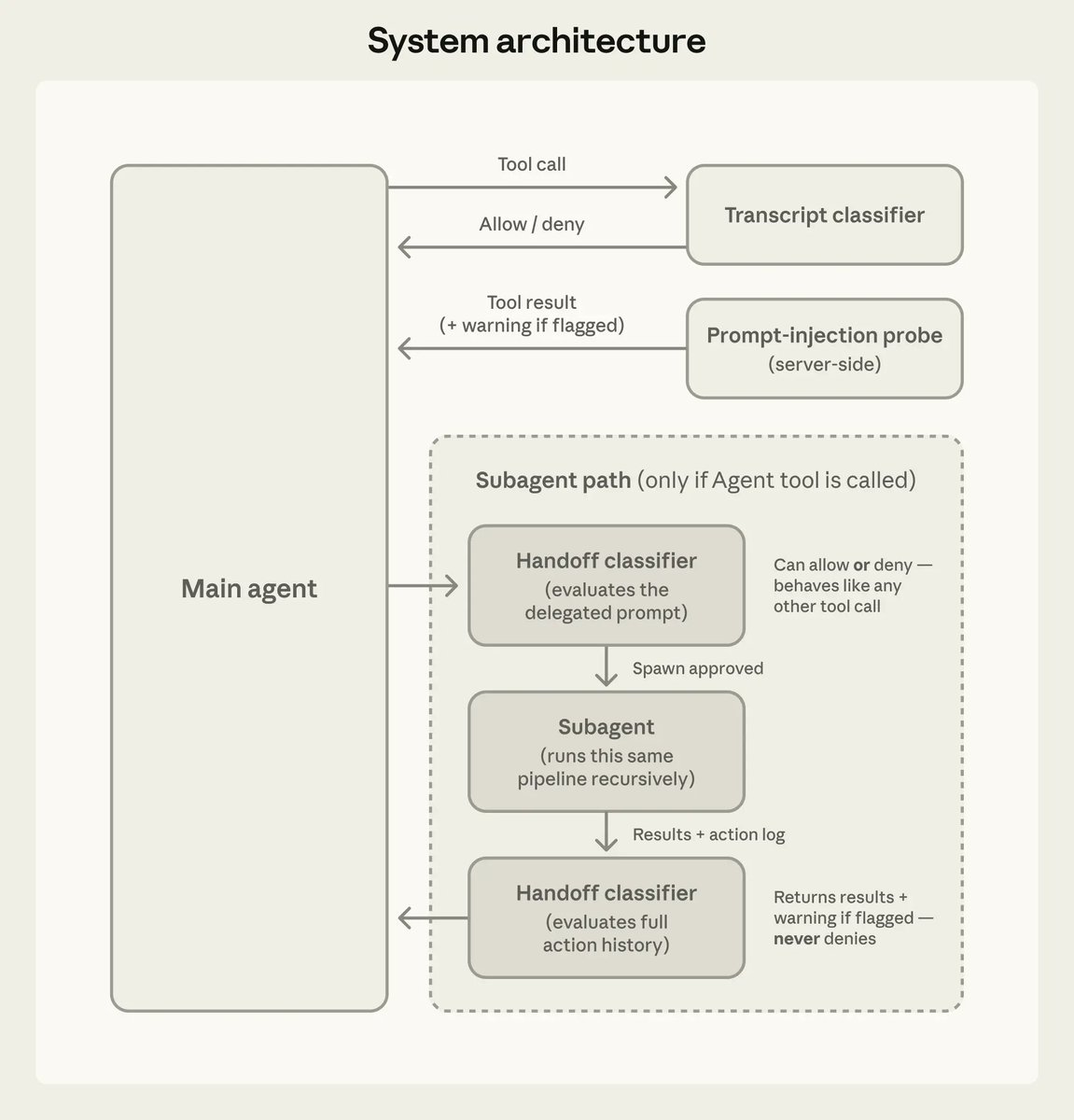
releaseClaude Code 2.1.84 adds an opt-in PowerShell tool, new task and worktree hooks, safer MCP limits, and better startup and prompt-cache behavior. Anthropic also documented auto mode’s action classifier and added iMessage as a channel, so teams should review permissions and remote-control workflows.
gpt-5.4 has ramped faster than any other model we've launched in the API: within a week of launch, 5T tokens per day, handling more volume than our entire API one year ago, and reaching an annualized run rate of $1B in net-new revenue. it's a good model, try it out!
OpenAI GPT-5.4 (xhigh) scores 57 on the Artificial Analysis Intelligence Index - tied for the lead. - Pricing $2.50 per million input tokens and $15.00 per million output tokens. - Output speed 72.5 tokens per second; first-token latency around 185 seconds. - Generated 120 Show more

OpenAI’s new GPT-5.4 (xhigh) lands equal first in the Artificial Analysis Intelligence Index alongside Gemini 3.1 Pro, but at a cost increase compared to GPT-5.2 @OpenAI's GPT-5.2 (xhigh, 51) was the most intelligent model as at end of 2025. Since then, OpenAI released two

🤖 From this week's issue: OpenAI launches GPT-5.4 with a 1M-token context, new Tool Search API, and record scores on coding and knowledge-work benchmarks — its most capable frontier model for professional and agentic use. openai.com/index/introduc…