MiniMax released M2.7 on its API and agent platform with coding and office-task claims plus a self-improving training harness. Engineers should validate the benchmark gains on real workloads, especially given mixed third-party results and aggressive pricing.

MiniMax is positioning M2.7 as a production model for software work, agent teams, and office-style workflows. In its own launch thread, the company claims “SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%),” says the model hit “97% skill adherence across 40+ complex skills,” and says it can edit Office files across multi-turn sessions launch thread. A broader benchmark summary from the launch ecosystem puts M2.7 at 56.2 on SWE-Pro, 52.7 on Multi-SWE Bench, 55.6 on VIBE-Pro, 46.3 on Toolathlon, 62.7 on MM-ClawBench, and 50 on the Artificial Analysis index benchmark summary.
The access story is unusually broad on day one. MiniMax’s quickstart post points developers to a quickstart that uses the Anthropic SDK and documents integrations with Claude Code, Cursor, Cline, Roo Code, Codex CLI, and MCP-style tooling via Quick Start docs. Outside MiniMax’s own platform, OpenRouter says the model is live now OpenRouter launch, Ollama added a cloud-hosted variant with direct commands for Claude Code and OpenClaw Ollama launch, and Vercel exposed both a standard model and a “high-speed” variant that it says reaches about 100 tokens per second Vercel AI Gateway.
MiniMax’s pricing is aggressive for a model making frontier-adjacent coding claims. Artificial Analysis says the model keeps M2.5 pricing at $0.30 per million input tokens and $1.20 per million output tokens with a 200K context window AA results, and OpenRouter listings show a 204,800-token context window at the same rates OpenRouter pricing.
MiniMax’s core differentiator is not just benchmark position but the claim that M2.7 helped build the system around itself. The company says it ran 22 OpenAI open-sourced MLE-Bench Lite competitions on a single A30-class setup, with an agent harness built around “short-term memory, self-feedback, and self-optimization” self-evolving thread. After each round, the agent writes a memory file, critiques its own results, and uses that chain to guide the next iteration. Across three 24-hour runs, MiniMax says the best run earned 9 golds, 5 silvers, and 1 bronze, for a 66.6% average medal rate self-evolving thread.
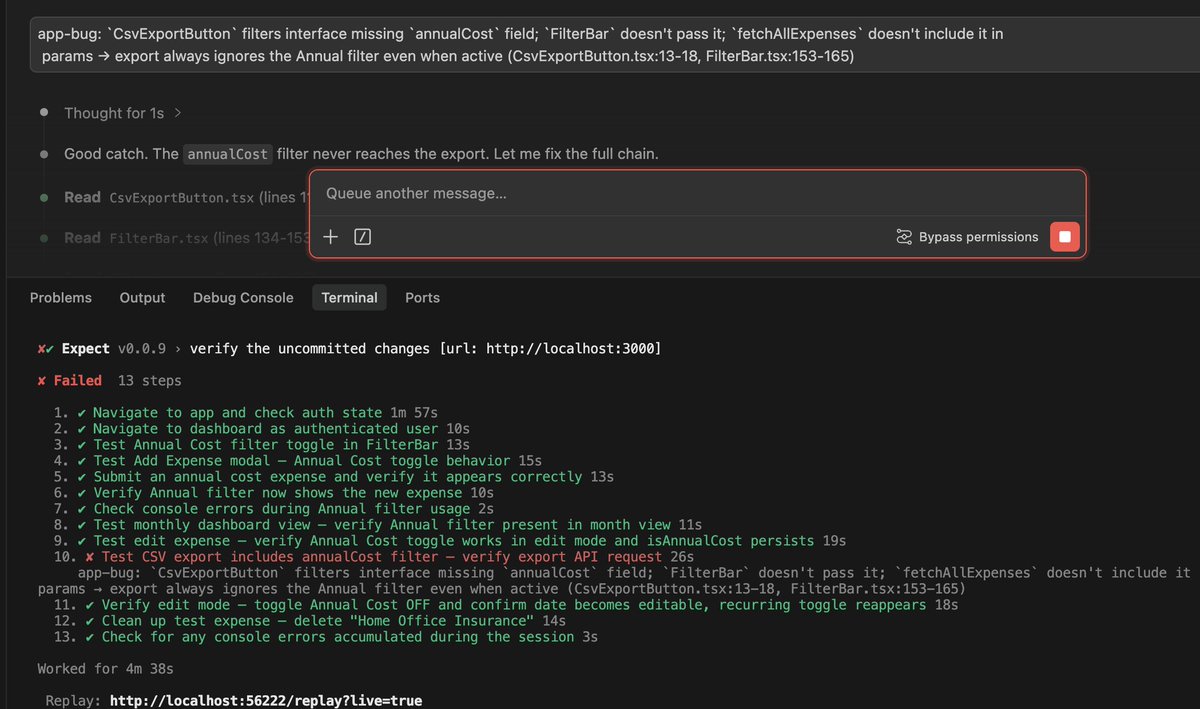
The more operational claim is that the harness also evolved. MiniMax says its internal setup “autonomously collects feedback, builds evaluation sets,” and iterates on “architecture, skills/MCP implementation, and memory mechanisms” harness details. The system diagram shows humans still setting goals, guardrails, and escalation boundaries, while the agent reads docs and logs, chains skills, generates reports, and escalates for approval rather than running fully unsupervised [img:3|iteration system].
Third-party measurements support part of the launch story, especially on cost-adjusted performance. Artificial Analysis says M2.7 gained 8 points over M2.5 to reach 50 on its intelligence index, tied GLM-5 at that level, and did so at roughly $176 to run the suite versus $547 for GLM-5 AA results. It also reports a GDPval-AA Elo around 1494-1495 and says the jump was driven partly by “reduced hallucinations,” with M2.7 improving to a 34% hallucination rate and an AA-Omniscience score of +1 from -40 on M2.5 AA results AA breakdown. Vals also published a dashboard showing 60.14% on its aggregate index, 72.4% on SWE-bench, and 47.19% on Terminal-Bench 2.0, though with very uneven performance across domains like ProofBench and MedCode Vals dashboard.
But the early read is not uniformly bullish. BridgeBench says M2.7 fell from M2.5’s rank 12 to rank 19 on its vibe-coding benchmark, with drops in UI, refactor, and generation subtasks, despite M2.7’s much stronger showing on synthetic or semi-synthetic coding leaderboards BridgeBench post. That gap matters because MiniMax is marketing M2.7 for “online incidents,” tool use, and multi-step agent work, and those are exactly the cases where benchmark wins need confirmation in real repos and long-running workflows launch thread.
OpenHands introduced EvoClaw, a benchmark that reconstructs milestone DAGs from repo history to test continuous software evolution instead of isolated tasks. The first results show agents can clear single tasks yet still collapse under regressions and technical debt over longer runs.
 breaking
breakingMalicious LiteLLM 1.82.7 and 1.82.8 releases executed .pth startup code to steal credentials and were quarantined after disclosure. Rotate secrets, audit transitive AI-tooling dependencies, and add package-age controls before letting agents install packages autonomously.
 breaking
breakingTurboQuant claims 6x KV-cache memory reduction and up to 8x faster attention on H100s without retraining or quality loss on long-context tasks. If those results hold in serving stacks, teams should revisit long-context cost, capacity, and vector-search design.
 release
releaseOpenCode is adding remote sandboxes, synced state across laptop, server, and cloud, and more product surface inside its plugin system. That makes long-running off-laptop workflows more practical, but operators should still review telemetry, sandbox, and exposure defaults.
 release
releaseClaude Code 2.1.84 adds an opt-in PowerShell tool, new task and worktree hooks, safer MCP limits, and better startup and prompt-cache behavior. Anthropic also documented auto mode’s action classifier and added iMessage as a channel, so teams should review permissions and remote-control workflows.
During the iteration process, we also realized that the model's ability to recursively evolve its harness is equally critical. Our internal harness autonomously collects feedback, builds evaluation sets for internal tasks, and based on this continuously iterates on its own Show more

During the iteration process, we also realized that the model's ability to recursively evolve its harness is equally critical. Our internal harness autonomously collects feedback, builds evaluation sets for internal tasks, and based on this continuously iterates on its own Show more
MiniMax M2.7 scores worse than M2.5 on BridgeBench. M2.5 ranked #12. Overall 92.3. M2.7 ranked #19. Overall 88.1. UI dropped from 76.6 to 61.9. Refactor from 97.3 to 90.7. Gen from 94.3 to 89.2. #1 on Multi-SWE Bench. #19 on BridgeBench. That's a 18 rank difference Show more

MiniMax has released MiniMax-M2.7, delivering GLM-5-level intelligence for less than one third of the cost MiniMax-M2.7 from @MiniMax_AI scores 50 on the Artificial Analysis Intelligence Index, an 8-point improvement over MiniMax-M2.5, which was released one month ago. This is Show more

Building a self-evolving intelligent agent model - MiniMax M2.7 "M2.7 is our first model which deeply participated in its own evolution" - We believe that future AI self-evolution will gradually transition towards full autonomy, coordinating data construction, model training, Show more

MiniMax M2.7 is out "Beginning the journey of recursive self-improvement" Benchmark scores: - On the SWE-Pro benchmark, M2.7 scored 56.22%, nearly approaching Opus’s best level - This capability also extends to end-to-end full project delivery scenarios (VIBE-Pro 55.6%) -