Higgsfield Sora 2 Enhancer deflickers footage – 200 credits in 9‑hour trials
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Higgsfield just shipped a universal deflicker Enhancer for Sora 2 alongside new MAX‑quality models, and that’s a practical win: flicker is the artifact that ruins otherwise usable shots. To get hands on, the team is handing out 200 credits via DM to anyone who RT+replies inside a 9‑hour window, with Upscale Preview and an Unlimited promo making it cheap to pressure‑test the pipeline.
This lands a day after Sketch‑to‑Video’s debut; today’s delta is finish and throughput — steadier temporal consistency, cleaner plates, and upscales without round‑tripping. The rollout isn’t drama‑free: creators flagged a promo clip’s shot attribution, and the original artist backed them, a reminder that provenance has to be explicit when you’re pitching process.
Meanwhile, Veo 3.1 looks imminent: Model Finder now lists two endpoints dated Oct 15, and a “Try Now” banner is live in Gemini and Vids. Even the official Gemini App account says it’s coming. Runway is also shipping one‑click Apps like Remove from Video and Reshoot Product, and Luma published Ray3 evals — billed as the first HDR video model — showing tighter camera‑prompt adherence and fewer temporal warps.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Feature Spotlight
Higgsfield Sora 2 Enhancer + MAX models
Higgsfield ships a universal Sora 2 Enhancer to kill flicker, plus new Sora 2 MAX/Pro MAX tiers and a limited Unlimited promo—unlocking cleaner, production‑grade video for directors and editors now.
Big creative tooling drop centered on Sora 2: a universal deflicker Enhancer, new MAX‑quality models, and a temporary Unlimited promo. Multiple creator threads explain usage and perks in today’s feed.
Jump to Higgsfield Sora 2 Enhancer + MAX models topicsTable of Contents
🎞️ Higgsfield Sora 2 Enhancer + MAX models
Big creative tooling drop centered on Sora 2: a universal deflicker Enhancer, new MAX‑quality models, and a temporary Unlimited promo. Multiple creator threads explain usage and perks in today’s feed.
Sketch‑to‑Video promo faces pushback over shot attribution
Creators challenged a Higgsfield promotional example, saying a featured shot wasn’t actually made via Sketch‑to‑Video; the original artist echoed the concern after it was cited as theirs creator critique, clarification, artist confirm. This lands the day after the tool’s debut, following up on initial launch, and underscores the need for precise provenance in marketing as adoption ramps source note.
200‑credit DM giveaway opens 9‑hour window to trial Enhancer and models
To jump‑start testing, Higgsfield is offering 200 credits via DM to anyone who retweets and replies within a nine‑hour window, positioned as a quick on‑ramp to try the Sora 2 Enhancer, MAX models, and Upscale Preview on the platform launch thread.
🎬 Veo 3.1 watchlist (imminent rollout signals)
Multiple accounts spot Veo 3.1 banners and model IDs across Google properties. Excludes Higgsfield Enhancer (feature). Focus is on what’s visibly changing for Gemini/Vids creative workflows.
Gemini/Vids shows 'Veo 3.1' Try Now banner
Creators are seeing a "New! Video generation just got better with Veo 3.1" banner with a Try Now CTA inside Google Vids/Gemini, indicating the rollout gates are opening; following up on sample clips, which hinted a Fast 720p path. Multiple screenshots corroborate the banner in-product Vids banner capture, with additional sightings earlier today Banner capture.
Veo 3.1 and 3.1 Fast endpoints appear in Model Finder
Model Finder surfaced two new Google endpoints — veo-3.1-generate-preview and veo-3.1-fast-generate-preview — dated Oct 15, signaling a staged preview with distinct latency/quality tiers for creatives to target next. See the capture for the exact IDs and "NEW Google Models" card Model IDs screenshot.
Official Gemini app account acknowledges Veo 3.1 is coming
A user post showing the Veo 3.1 banner drew a reply from the official Google Gemini App account confirming it is coming, adding weight to the imminent rollout signals beyond community screenshots Official reply. The same capture shows the "Try Now" banner live in the interface.
Creators tease Veo 3.1 as “dropping today” amid banner sightings
Community posts lean into timing, with creators saying Veo 3.1 is "dropping today" alongside the new banner captures, framing expectations for immediate hands-on tests once access toggles propagate Dropping today teaser.
🧰 Runway Apps: task‑focused creative workflows
Runway starts rolling out an “Apps” collection on web: one‑click, use‑case flows for creators (remove elements, reshoot products, restyle, upscale). Excludes the Higgsfield feature.
Remove from Video lets you delete objects with plain language—no rotoscoping
Runway’s Remove from Video app simplifies clean‑up: upload a clip, describe what to remove, and the system handles masking and tracking—no rotoscoping or complex prompting required Remove app details. It’s available directly via the Apps rollout on the web Remove app page, and is highlighted in the broader Apps launch thread Apps rollout.
Runway rolls out Apps on the web for one‑click creative workflows
Runway introduced Apps, a growing collection of task‑focused workflows now rolling out on the web, with new apps planned weekly and an open call for ideas in comments Apps rollout. The launch collection spotlights use cases like removing elements from video, reshooting products by description, restyling images, and one‑click upscale to 4K Launch brief.
Reshoot Product turns a street mural motif into a car decal in a single pass
Runway showcased the Reshoot Product app with a concrete before/after: a shark‑themed alley mural becomes a cohesive decal treatment on a red Porsche, illustrating product “reshooting” via descriptive guidance rather than manual comps Reshoot example.
Runway frames Apps as a new foundation to make AI creation broadly accessible
Runway leadership positions Apps as more than one‑click shortcuts—calling them a foundational layer that lowers friction and opens AI creativity to more people, with more app types on the way Vision thread.
🌈 Luma Ray3 SOTA evals (first HDR video model)
Luma posts a detailed evaluation series for Ray3 covering physics, instruction following, artifacts, aesthetics, temporal consistency, and image→video adherence. A concrete read for filmmakers assessing model fit.
Luma publishes Ray3 evaluation series, billed as first HDR video model
Luma released a structured evaluation of Ray3 covering physics, instruction following, motion artifacts, aesthetic quality, temporal consistency, and image‑to‑video adherence—positioning it as a fit for high‑fidelity, color‑accurate production work model overview, with methodology and comparisons detailed on their site blog post. This arrives following up on scribble control that added a new control mode for Dream Machine.
Ray3 physics and motion tests focus on plausible dynamics under complex moves
The Physics & Motion module highlights how Ray3 handles action and demanding camera paths while keeping movement believable, a key check for fabric, hair, and contact forces reading true on screen module card.
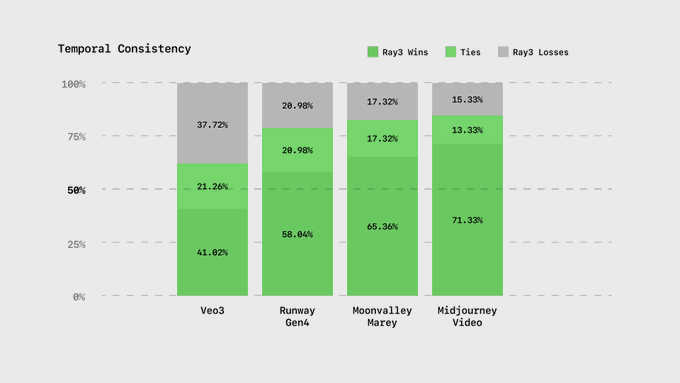
Temporal consistency: identity and lighting stability over multi‑second shots
Luma’s Temporal Consistency module checks whether characters, props, and lighting remain stable shot‑to‑shot, which directly impacts editability and continuity in narrative workflows module card.
Aesthetic quality: Ray3 targets consistent grade, composition, and mood
The Aesthetic Quality module evaluates global look—grading, composition, and shot cohesion—so cinematographers can gauge whether Ray3 maintains a coherent visual identity across cuts module card.
Image‑to‑video adherence: faithful motion from a single still reference
The Image‑to‑Video Adherence module assesses how closely Ray3’s motion honors an input still’s identity and art direction—critical for previz, boards‑to‑motion, and brand look‑lock adherence card.
Instruction following: Ray3 aims for tighter adherence to camera and action prompts
Luma’s Instruction‑Following module examines whether Ray3 matches specified framing and beats (e.g., camera directives and action cues) so directors can trust shot specs to translate into motion module card.
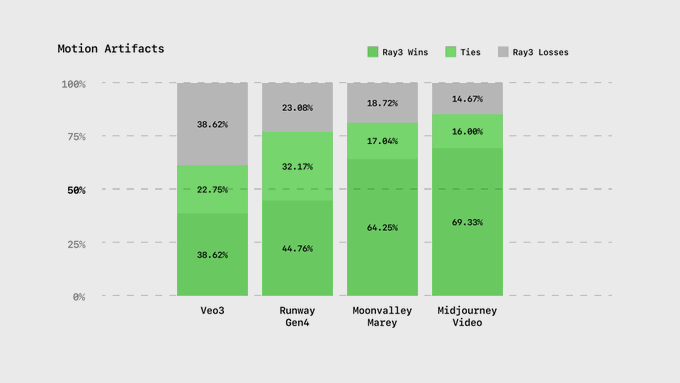
Motion artifacts audit: reduced seams, morphs, and warps across frames
The Motion Artifacts module catalogs common failure modes (morphing, seams, temporal warps) and where Ray3 mitigates them, offering creators a realistic sense of when to expect cleanup needs module card.
🎨 Grok Imagine cinematics: prompts, styles, and tips
A fresh round of Grok Imagine direction for creatives: day↔night transitions, underwater mood pieces, horror anime, retro 80s OVA space, and prompt packs via ALT text. Excludes the Higgsfield feature.
ALT‑text prompt pack: anime OVA looks for Grok
A creator dropped ALT‑text prompts for Grok anime OVA aesthetics—rebirth via water reflections, luminous fish close‑ups, serene starfields, and identity‑mirror mosaics—giving plug‑and‑play recipes for mood‑driven sequences Prompt pack.
Cinematic micro‑prompts for Grok faces: pulse and lash blinks
Creators are codifying facial camera moves into compact prompts—e.g., “Neckline Pulse” (macro, 8 cm dolly‑in, 2% exposure lift on heartbeat) and “Lower Lashes Blink” (ECU, micro‑dolly during rise)—to get editorially precise beats in Grok Prompt example, Second prompt, following up on DP prompts that mapped crash‑zooms and rotating reveals.
One image → 20 Grok videos: instruction following holds up
A workflow thread shows Grok Imagine spinning a single starting image into 20 distinct videos with strong prompt adherence, using Midjourney/Nano Banana for seed images and Grok for motion with native audio Creator thread, Feature rundown. Useful for building coverage from a limited shoot or style board.
Day‑to‑night transition trick elevates Grok shots
Creators are getting striking lighting shifts in Grok Imagine by prompting a day→night transition, yielding cinematic mood swings in a single clip Tip demo. Use it to sell time passage or emotional beats without cutting.
Grok Imagine nails horror‑anime tone and motion beats
Horror anime tests show Grok handling suspenseful pacing, reveal timing, and stylized FX well—useful for teasers and title sequences where tone control matters Horror anime clip. Lean into constrained camera moves and selective light to keep frames readable.
Underwater scenes shine in Grok for poetic mood
Underwater compositions are resonating with Grok Imagine—soft light, refraction and slow motion give “beyond the image” vibes ideal for lyrical edits and music visuals Underwater praise. Think color‑graded blues, gentle parallax, and minimal action to let ambience lead.
‘City that never sleeps’ shows Grok’s urban loop vibe
A short city animation underscores Grok’s knack for rhythmic loops and ambient motion—great for backgrounds, brand idents, and socials where subtle kinetic energy carries the frame City animation clip.
Retro 80s OVA space launch works beautifully in Grok
A retro 80s OVA anime treatment on a Starship‑style launch proves Grok can carry nostalgia, grain, and cel‑like shading across multi‑shot sequences Space launch homage. It’s a strong direction for sci‑fi bumpers and lyric videos.
🧩 WAN 2.2 in ComfyUI: animation workflows
Hands‑on WAN 2.2 Animate in ComfyUI with a compact tutorial, character replacement, example reels, and tooling repos. Good for shot control and consistent motion. Excludes Higgsfield feature.
WAN 2.2 Animate gets a 3‑minute ComfyUI tutorial you can copy today
ComfyUI published a concise 3‑minute WAN 2.2 Animate walkthrough covering character animation basics and shot setup tutorial thread, with the full video available to replay YouTube tutorial. An accompanying reel shows practical outputs from the exact workflow so you can gauge motion quality before building your own examples reel, following up on ComfyUI run, which stress‑tested WAN 2.2 end‑to‑end.
Character Replacement in ComfyUI swaps leads while preserving motion beats in WAN 2.2
A focused demo shows Character Replacement running on WAN 2.2 inside ComfyUI, maintaining timing and movement while swapping the on‑screen character—a handy path to iterate casting without re‑animating the shot feature demo.
ComfyUI‑WanVideoWrapper repo adds longer‑clip handling and utilities for WAN 2.2
The ComfyUI‑WanVideoWrapper GitHub release brings extended video wrapping capabilities for WAN 2.2 workflows—including VRAM management and cache methods—making it easier to push longer or more complex shots without manual plumbing GitHub repo.
Official WAN 2.2 Animate workflow JSON posted for reproducible ComfyUI setups
Creators can now import the WAN 2.2 Animate workflow JSON directly into ComfyUI to mirror the tutorial’s node graph and settings 1:1, speeding up onboarding and shot consistency across teams workflow json.
Alibaba Wan underscores WAN 2.2’s cinematic fidelity and emotional continuity
The Alibaba Wan team highlighted how WAN 2.2 preserves high detail and emotional shifts across shots, noting that black‑and‑white variants can intensify mood while retaining fidelity—useful guidance for grading and tone decisions in post b/w take, and a nod to how delicately the model handles fluid, nuanced motion emotion note.
📽️ Shot recipes beyond Grok: Sora & Kling prompts
Practical prompt formulas for non‑Grok engines: analog VHS realism in Sora, animated end‑credits design, and high‑energy Kling 2.5 action sequences. Excludes the Higgsfield Enhancer launch.
Sora recipe: authentic early‑2000s VHS camcorder look
Creators shared a detailed Sora prompt that nails raw VHS tape aesthetics—soft analog blur, chroma drift, scanline flicker, handheld jitter, and a perfectly stable timestamp locked bottom‑right (e.g., OCT 28 2004 11:46:09 PM). The formula emphasizes magnetic‑tape artifacts over digital filters to sell the era and works especially well for horror or found‑footage moods VHS prompt share.
Kling 2.5 Turbo action prompt: low‑angle convoy flip and slow‑mo debris
A high‑energy Kling 2.5 Turbo spec calls for a low‑angle dolly racing alongside an armored convoy on a war‑torn road; a near‑miss explosion flips a vehicle as dust and shrapnel scatter in slow motion. The framing and motion cues yield convincing cinematic chaos for trailers and stings Action prompt.
Sora end‑credits design prompt: kinetic red/black/white role cards
A compact Sora 2 prompt produces stylized, fast‑cut end credits where each role has a minimal red/black/white card and a matching character icon; the sequence dynamically switches views rather than a single roll. It’s a useful template for polished outros and title cards; typography timing benefits from a manual pass in edit End credits example.
Kling 2.5 city prompt: aerial tracking through neon megacity with jetpacks
An aerial tracking prompt for Kling 2.5 paints a futuristic skyline of neon towers, floating billboards, and sky bridges, with commuters weaving on personal jetpacks as sunrise haze glows across the scene. It’s a clean recipe for sweeping city openers and logo fly‑ins City prompt share.
🏭 Studio pipelines: Promise opens The Generation Company
Promise spins up a new division to produce AI VFX and custom sequences for studios; leadership, site, and trade press coverage circulate. Excludes today’s model/tool features.
Promise launches The Generation Company for AI VFX and custom sequences
Promise unveiled The Generation Company, a studio-facing division delivering AI-driven VFX and bespoke cinematic sequences for filmmakers and media partners, led by generative filmmaker Nem Perez Division launch. Trade press framed the move as bringing GenAI workflows to legacy media buyers, landing alongside a refreshed Promise site and a mission post on “storytelling without limits” Trade press story, Website teaser, Blog announcement.
For creatives, this signals a shift from solo demos to production-grade pipelines: a dedicated team, studio service model, and clearer buying path for AI-enhanced sequences in film/TV and brand work.
🏆 Creator contests, grants, meetups
Active opportunities and showcases for creatives today: PolloAI’s global contest, OpenArt MVA billboards/judges, Leonardo’s Imagination Fund, Hailuo x Chroma Awards, plus SF/LA meetups.
Leonardo Imagination Fund: $10k grants for five creators, deadline Oct 17
Leonardo will award $10,000 each to five creators pushing the limits of AI-driven storytelling, design, or art; applications close Oct 17 so this is a last‑call week Grant call. Full criteria and submission details are on Leonardo’s site Grant page.
OpenArt MVA lights up Times Square and SF billboards; submissions live
OpenArt’s Music Video Awards campaign is now visible on Times Square and across the SF Bay Area, signaling that entries are open and discoverability will be high for winners Billboards live. Creators can review categories, rules, and submit via the official program hub Program page.
Hailuo sponsors Chroma Awards with a $1,500 Hailuo Prize, entries due Nov 3
Hailuo AI joined the Chroma Awards as a Silver Sponsor and will give a $1,500 cash prize to the project that best showcases the cinematic power of its tool; creators must tag Hailuo and submit by Nov 3 to be considered Prize details. Learn more and enter via the Chroma site Chroma site.
Krea hosts AI Talks in SF on Oct 17 with Runway, BFL, and Snap
Krea’s in‑person AI Talks return this Friday in San Francisco, featuring speakers from Runway, BFL, Snap, and Krea; seats are limited and RSVP is open Event poster. Reserve a spot if you want research and product insights straight from the teams building the tools RSVP page.
PolloAI opens Echoes of Myth & Faith contest with $4k cash pool and credits
PolloAI kicked off a global challenge running Oct 13–Nov 7 inviting short AI videos inspired by myths, religion, or faith, with a prize pool exceeding $4,000 cash plus substantial credits Contest announcement. • Prizes include $1,000 (1st), $800 (two 2nd), $500 (three 3rd), ten Excellence Awards (credits), and five Popularity Awards; submissions require posting on PolloAI and sharing on social with #polloai, then completing the entry form Submission form.
FAL teams up for a PyTorch‑week creative mixer in SF; RSVP now
If you’re in town for PyTorch events next week, FAL is co‑hosting an evening mixer in San Francisco with BFL and Krea, offering a low‑key space to meet other creative technologists over food and drinks Mixer invite. Attendance is limited; register via the event page RSVP page.
🧪 Creator platforms & utilities roundup
Smaller but useful platform updates for creatives today: Google AI Studio UI refresh, Qwen3‑VL app on HF, NotebookLM Video Overview presets via Nano Banana, and Krea’s new Topaz‑powered upscalers.
NotebookLM Video Overviews add Nano Banana for richer auto‑edits
NotebookLM now integrates Nano Banana to power Video Overviews, improving generated explainers with stronger visual beats and style cohesion, following up on Video Overviews styles and format switch overview screenshot.
Creators can customize format (e.g., Explainer) and pick a visual theme directly in the generator, tightening the brief‑to‑cut loop for moodboards, recaps, and pitch videos overview screenshot.
Google AI Studio gets a cleaner homepage with Playground, Build, Dashboard and a live “What’s new” rail
Google’s AI Studio homepage has been refreshed to foreground core workflows (chat/playground, build, dashboard) and surface updates like image generation and URL context in a prominent news feed, streamlining prompt‑to‑production for teams UI screenshot.
The layout also highlights “Generate media” and monitoring entry points, reducing clicks for creatives moving from prototyping to telemetry UI screenshot.
Krea Enhance adds Topaz‑built Bloom, Astra and Starlight upscalers for images and video
Krea introduced three new upscalers—Bloom, Astra and Starlight—developed with Topaz Labs tech, available now inside Krea Enhance to clean and sharpen AI renders and footage in a single pass feature rollout.
These options give motion designers and photographers quick A/B routes for grain retention vs crispness, helping finalize deliverables without round‑tripping to separate apps feature rollout.
Qwen3‑VL‑4B‑Instruct app lands on Hugging Face with benchmark snapshot
Alibaba’s Qwen3‑VL‑4B‑Instruct is now available as a Hugging Face app, with a posted table comparing scores across STEM, OCR/docs, grounding, multi‑image, video and agent tasks—useful for quick creative QA and pick‑the‑right‑tool decisions HF app card.
For designers and filmmakers testing multimodal pipelines, the lightweight 4B variant offers an approachable way to prototype VQA and layout‑aware tasks before scaling models HF app card.
🖼️ Stills: product looks, MJ v7, Riverflow tease
Image‑first updates and recipes relevant to designers: luxury product photography prompt sets, Midjourney v7 params, Runware’s Riverflow editor tease, and a new anime model in ComfyUI.
Runware teases Riverflow, an intent‑aware image editor
Runware previewed Riverflow, an image editing model that "understands your intent" to handle complex edits like text swaps, color changes, and perspective‑aware adjustments; it will drop exclusively on RunwareAI tease thread, with early chatter emphasizing competitive performance in the Artificial Analysis arena feature tease.
If the intent parsing holds up, it could cut prompt trial‑and‑error for brand and product composites.
Krea Enhance adds Bloom, Astra, Starlight upscalers from Topaz Labs
Krea rolled out three new image/video upscalers—Bloom, Astra, and Starlight—developed by Topaz Labs, now available inside Krea Enhance for one‑click quality lifts upscaler launch.
These models expand finish‑stage options for sharpening, detail recovery, and upscale consistency in stills workflows.
Midjourney v7 settings deliver cohesive neon wireframe looks
A new six‑frame collage confirms the v7 combo (--chaos 8, --ar 3:4, --sref 2821743200, --sw 500, --stylize 500) locks a stylized neon‑tech aesthetic across faces, vehicles, and props, following up on param pack that introduced the recipe param example.
Useful when you want one visual language to bind diverse subjects in a set or campaign.
NetaYume Lumina anime model lands in ComfyUI with workflow
ComfyUI added NetaYume Lumina, a Luma‑Image‑2.0 fine‑tune that produces sharp anime outlines, vibrant colors, and crisp accessory detail; a ready workflow was shared to reproduce results end‑to‑end model post, workflow link.
Great for stylized key art, character sheets, and poster‑grade stills.
Luxury product photo prompt nails EOS R5 look
A reusable prompt recipe for high‑end product shots (EOS R5 look, hyper‑real textures, crisp studio lighting) shipped with clean ATL examples across pens, scarves, watches, and clutches prompt recipe.
The template yields consistent composition and materials fidelity for 3:2 frames, making it a fast starting point for brand‑ready stills.
ImagineArt 1.0 prompt shows precise portrait and lighting control
A detailed JSON‑style prompt demonstrates how ImagineArt 1.0 can stage a cinematic fashion portrait on a red sport bike, specifying lens (85–135mm), high‑contrast key/ambient mix, atmosphere, and Ultra‑HD texture goals prompt demo.
It’s a solid template for art‑director‑grade control over pose, wardrobe, and lighting.
🤝 AI deals and infrastructure shaping creative pipelines
Two notable business moves with downstream creative impact: a $15B Google AI hub in India and WPP’s $400M, 5‑year deal with Google to use Gemini/Veo/Imagen in marketing ops.
Google to invest $15B in India’s first AI hub with gigawatt-scale datacenter and new subsea cable
Google will build its first AI hub in Visakhapatnam, India, investing $15B from 2026–2030 to stand up a gigawatt‑scale AI datacenter with AdaniConneX and Airtel, plus a subsea cable landing that links India into Google’s global network Google hub details.
- Full AI stack deployment is promised to accelerate AI adoption in India’s creative and enterprise sectors, and Google calls it its largest investment in the country to date Google hub details.
WPP signs five‑year, $400M deal to embed Gemini, Veo and Imagen across global marketing ops
WPP inked a $400M, five‑year partnership with Google to bring Gemini, Veo, and Imagen into its campaign workflows, aiming for faster creative development and scaled personalization across clients FT headline.
- The deal signals deeper AI standardization in agency pipelines, with direct impact on video generation and asset production speed for brands FT headline.
📣 Community pulse: moderation, attribution, feed quality
The discourse is the story: creators vent on Sora moderation false‑positives, a marketing misattribution flare‑up, algorithmic feed quality dips, and one filmmaker’s resilience after backlash.
Sora 2 flags “kittens in a bouncy castle” again, stoking moderation backlash
A fresh screenshot shows Sora 2 blocking a harmless prompt as a Content Violation, reinforcing creator complaints about over‑zealous filters; this lands following up on benign overblock where similar false positives were reported. See the UI evidence in violation screenshot.
Creators call out misattribution in a Higgsfield promo clip
A marketing shot tied to Higgsfield’s Sketch‑to‑Video triggered an attribution dispute, with creators saying the showcased piece wasn’t made the way it was implied and urging clearer credits and process notes to avoid misleading the community misattribution claim. Follow‑ups from the filmmaker and peers reinforced the correction and concern about trust in promo reels clarifying reply, peer agreement.
“For You” feed quality dips as fresh posts flood timelines
Creators report X’s “For You” surfacing too many sub‑hour posts with low personal relevance, making discovery noisier and less tailored feed gripe. For artists iterating on cuts and drafts, a noisier feed can slow feedback loops and reduce signal on what to ship next.
After 10M‑view debut and threats, filmmaker urges persistence over pile‑ons
A year after receiving death threats following a 10M‑view first AI film, PJ Accetturo says it became the best 12 months of his career and encourages others to keep creating despite backlash creator reflection. The post resonated as a counterweight to today’s pile‑ons, reminding teams to separate noisy discourse from the work.
📚 Papers to watch: efficient RL, multimodal captioning, diffusion
Mostly methods posts relevant to creative AI systems: quantization‑enhanced RL for large LLMs, RL in flow environments, audiovisual captioning, and improved diffusion backbones. Lighter day for benchmarks.
QeRL trains 32B‑param LLMs with RL on a single H100 via quantization
NVLabs’ QeRL combines NVFP4 quantization with LoRA and an adaptive noise schedule to run full‑model RL for 32B LLMs on one H100, reporting >1.5× faster rollouts while matching full‑precision fine‑tuning on math benchmarks paper page. In context of Webscale-RL, which highlighted a 1.2M RL pretraining corpus, this directly attacks the compute bottleneck for scalable policy tuning GitHub repo.
Diffusion Transformers with Representation Autoencoders tighten the latent bridge
A new backbone pairs Diffusion Transformers with Representation Autoencoders (RAEs) to better align compressed latents with the denoiser, promising higher fidelity and stability at similar budgets—useful for image/video editors and upscalers paper page. Authors share a community thread for Q&A around training and integration paths Discuss invite.
AVoCaDO claims SOTA audiovisual video captioning with temporal orchestration
AVoCaDO is an audiovisual captioner that uses a two‑stage post‑training pipeline to improve temporal coherence and dialogue accuracy, with reported SOTA across several video captioning benchmarks—handy for auto‑narration, logging, and edit search Paper card.
RLFR proposes a Flow Environment to extend RL for LLMs
RLFR introduces a flow‑based training environment that structures multi‑step interactions for LLM reinforcement learning, aiming to improve credit assignment and stability in long‑horizon tasks paper page. Discussion invites suggest a broader push toward richer, program‑like trajectories for reasoning agents Discuss invite.
Shanghai AI Lab’s VPPO spotlights token‑perception RL for better LVLM reasoning
VPPO introduces a multimodal RL method centered on token perception to boost vision‑language reasoning, part of a growing trend to move beyond scalar rewards toward signal‑rich training for LVLMs VPPO retweet.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught