Higgsfield Popcorn locks exact‑match 8‑frame storyboards – 250‑credit DM offer
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Higgsfield just dropped Popcorn, an AI storyboarder that finally solves character drift. It keeps identity, wardrobe, lighting, and environments perfectly consistent across 8 frames by reusing exact references, not “close enough” look‑alikes. Access is wide open with free daily generations, plus a 250‑credit DM promo for folks who retweet and reply during the launch window.
The workflow is refreshingly practical: generate eight shots from a single prompt, build sequences from uploaded references, or mix references and write per‑frame notes when you need precision. You can upload up to four references for characters, settings, or props, choose aspect ratios, jot simple beats, and get a cohesive board in minutes. The headline feature is the exact‑match lock—faces don’t drift, outfits don’t morph, and lighting stays true—so your board reads like a single production, not eight almosts. You can also continue any of the eight images to extend the board without breaking continuity, and multi‑input edits make restyling faithful to the original look.
With stills locked, teams are already pushing them into animation tools—Veo 3.1 for surgical inserts, or fal’s Kling 2.5 Turbo at $0.21 per 5s for quick image‑to‑video—turning consistent boards into cuttable motion fast.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Feature Spotlight
Higgsfield Popcorn: exact‑match AI storyboards
Higgsfield Popcorn lands for AI storyboards: upload refs, get 8 perfectly consistent frames with exact face/clothing/environment lock, extend scenes, and free daily gens—creators post guides and promos within hours.
Cross‑account launch buzz around Popcorn, a storyboard tool that locks characters, lighting, and setting across 8 frames with stronger reference matching. Multiple creator guides and promos; this is today’s dominant creative story.
Jump to Higgsfield Popcorn: exact‑match AI storyboards topicsTable of Contents
🍿 Higgsfield Popcorn: exact‑match AI storyboards
Cross‑account launch buzz around Popcorn, a storyboard tool that locks characters, lighting, and setting across 8 frames with stronger reference matching. Multiple creator guides and promos; this is today’s dominant creative story.
Higgsfield Popcorn launches with exact-match 8‑frame storyboards and 250‑credit promo
Higgsfield unveiled Popcorn, a storyboard tool that keeps characters, lighting, and setting perfectly consistent across 8 frames, with free daily generations and a limited 250‑credit DM offer for users who RT and reply within the promo window Launch thread. Creators can jump in now via the product page and start stitching sequences that hold continuity shot‑to‑shot Product page.
Three creation modes and “exact” reference lock define Popcorn’s workflow
Beyond the launch, Higgsfield clarified how Popcorn works: generate 8 shots from a single prompt, build sequences from uploaded references, or mix multiple references and prompt per frame for full creative control Modes overview. They also explained why faces and outfits don’t drift—each frame reuses the exact uploaded character/environment as a hard reference rather than a loose interpretation Consistency explanation.
Hands-on: a fast Popcorn storyboard workflow you can replicate
A creator walkthrough shows how to upload up to four references (characters, setting, props), pick number of scenes, jot simple beat notes, then generate a cohesive 8‑frame storyboard in minutes—before taking those stills into video in a later step Tutorial thread. The thread includes concrete scene notes, intermediate stills, and a signup link for new users Stills set, Partner signup.
Creator guide: Popcorn sequences, multi‑input edits, and extendable boards
A detailed creator thread walks through Popcorn’s end‑to‑end flow: upload references, set aspect ratios, and generate up to eight shots that keep identity, wardrobe, lighting, and environments locked Creator walkthrough. It also highlights add‑ons that matter in production: continue any of the 8 outputs to extend the board while preserving continuity Extend storyboard, and use multiple inputs to edit or restyle with high fidelity to the original look Multi‑input edits. Start creating from the official page Product page.
🎞️ Veo 3.1 in the wild: extends, inserts, and tests
Creators push Veo 3.1 with one‑image animations, frame‑to‑frame extend/insert, and physics/light experiments; includes critiques on mirror and freezing behavior. Excludes Popcorn feature coverage.
One-image animation in Veo 3.1 using Scenebuilder insert
Diesol showcases a Veo 3.1 animated short—“Bloom”—built entirely from a single hero still, using Scenebuilder plus the new Insert function to extend scenes from one image One‑image short. For creatives, this validates the one‑image‑to‑multi‑shot pipeline while keeping identity and environment stable.
Creators push Veo 3.1’s frame‑to‑frame and extend flow
Hands‑on tests praise Veo 3.1’s frame‑to‑frame and Extend features as “insane,” suggesting smoother continuity when inserting new beats between shots Extend demo. The emerging workflow: rough a sequence, then surgically add cutaways and transitions without breaking look or motion.
Mirror optics test highlights reflection inaccuracies in Veo 3.1
An optics experiment comparing a laser‑at‑mirror setup to Veo 3.1 output shows reflection geometry errors relative to a reference rig Mirror test. For ads and motion graphics, expect occasional post‑fixes where precise ray behavior matters.
Veo 3.1 struggles on a water‑freezing time‑lapse test
A creator’s cold‑weather timelapse prompt causes Veo 3.1 to misinterpret freezing water (often inserting ice cubes) and diverge from expected thermodynamics Freezing test, following up on Frame tests where first/last‑frame control looked strong. Physical plausibility remains a watch‑item for educational, product, and FX‑heavy briefs.
Storyboard‑to‑Veo flow: stills first, then JSON prompts for motion
A production thread outlines a clean pipeline: generate key stills first, then animate them in Veo 3.1 using ALT‑embedded JSON prompts to steer emotions, dialogue, and scene beats Stills before animation, Prompt control tip. This reduces re‑rolls and preserves intent when moving from boards to motion.
🎬 Drawn camera paths and text‑driven performance
Shot direction tools to shape motion and acting: Luma’s Ray3 visual annotations for camera/action and BytePlus OmniHuman 1.5 text‑driven scene control. Excludes the Popcorn feature.
Luma Ray3 sketches camera moves and ad beats from a single frame
Luma’s Ray3 visual annotation flow lets creators draw camera paths and storyboard action directly over a frame, then explore multiple ad variations (e.g., product lifts, bursts, motion synced to energy) inside Dream Machine Luma showcase. Following up on Ray3 launch, this demo emphasizes creative direction fidelity rather than new knobs, useful for packaging alternate cuts fast for clients.
OmniHuman 1.5 lets you direct scenes, actions, and camera with text
BytePlus positions OmniHuman 1.5 as a text‑driven director: describe scene beats, performer actions, and camera moves, and it executes with tight audio sync, enabling vlog‑style monologues, interactive character stories, and brand performances without manual keyframing Feature overview. The pitch targets rapid iteration for narrative and commercial pieces where timing and delivery matter.
Seedance brings native multi‑shot sequencing for coherent, 1080p storytelling
BytePlus frames Seedance as a fit for studios needing coherent multi‑shot sequences on tight budgets, highlighting native sequencing and 1080p output for lore and character backstories Use case thread.
- Positioned as a “chef’s recommendation” for game narratives, with multi‑character scenes and cinematic expectations handled in seconds Use case thread.
Seedance‑1‑pro prompt yields a cinematic push‑in tracking shot
A creator shares a concise Seedance‑1‑pro prompt that produces a push‑in tracking shot into a forest clearing, complete with reactive performance cues (birds scatter, growl, stance) and atmospheric elements (mist), demonstrating text‑level shot direction in practice Prompt example. This is a practical recipe for narrative beats without hand‑animating camera or actors.
✂️ Edit by description: remove anything from video
Post tools that speed edit time for filmmakers. Runway’s Remove from Video deletes elements via text—no roto or complex prompting. Excludes Popcorn.
Runway launches Remove from Video: text-describe objects to delete, no rotoscoping
Runway introduced Remove from Video, a text-guided tool that deletes unwanted elements from footage without manual rotoscoping—just upload a clip and describe what to remove Feature overview, with the tool live now via the app entry point App page. A follow-on post underscores the same “describe it and go” flow and direct access link for immediate trials Launch reminder.
📹 Fast, cheaper clips: Kling 2.5 Turbo on fal
Model access and pricing moves relevant to production budgets. fal offers Kling 2.5 Turbo Standard at $0.21 per 5s, with 720p image‑to‑video and speed‑focused endpoints. Excludes Popcorn.
fal debuts Kling 2.5 Turbo Standard at $0.21 per 5s with fast 720p image-to-video
fal is offering day‑0 access to Kling 2.5 Turbo Standard at $0.21 per 5 seconds (about $2.52 per minute), positioning it as a fast, high‑quality option with 720p image‑to‑video for budget‑conscious productions Pricing and features. A follow‑on post underscores the speed‑first endpoints for dynamic generation, signaling a push for rapid iteration workflows Endpoint highlight.
Kling’s current showcases include solid image‑to‑video fidelity, useful for turning storyboard stills into moving shots without blowing through credits I2V showcase.
🧩 ComfyUI for consistent characters and scenes
Node workflows for consistent looks across stills: ComfyUI pairs Gemini Flash text + image APIs; example boards show singer, frog miniatures, and toon model sheets. Also Cloud access invites. Excludes Popcorn.
ComfyUI unveils Gemini Flash + Image workflow for consistent characters across scenes
ComfyUI published a node workflow that pairs Gemini Flash’s LLM with its Image APIs to maintain character identity while varying setting, outfit, and pose, enabling creators to iterate in natural language without losing continuity Workflow overview.
- Example boards show a punk character across environments, a cozy frog miniature series, a singer performing in multiple venues, and a toon turnaround/model sheet—demonstrating multi‑scene consistency from shared references Output examples.
Comfy Cloud access accelerates via invite codes and shared link
ComfyUI is pushing easier onboarding to its managed environment: community members report immediate access via cloud.comfy.org, while ComfyUI is offering instant invite codes with a one‑month free period to those who engage with the call Comfy Cloud and Invite code offer.
🌍 Open 3D: feed‑forward video‑to‑world in seconds
3D tools for worldbuilding: Tencent open‑sources Hunyuan World 1.1 with video/multi‑view to 3D, outputting point clouds, depth, normals, cameras, and 3D Gaussians on a single GPU.
Tencent open-sources Hunyuan World 1.1 for feed‑forward video/multi‑view to 3D on a single GPU
Tencent released Hunyuan World 1.1 (WorldMirror), a universal feed‑forward 3D reconstruction model that turns video or multi‑view inputs into full scene assets in seconds on a single GPU, and it’s open‑sourced for creators. It fuses priors like camera intrinsics, poses, and depth to resolve structure, and simultaneously outputs point clouds, multi‑view depth, normals, calibrated cameras, and 3D Gaussian splats for downstream worldbuilding open‑source thread.
- Flexible inputs and priors: text, image, video, or multi‑view with optional geometry signals for higher fidelity open‑source thread
- Multi‑representation outputs in one pass: dense point cloud, per‑view depth/normal maps, camera parameters, and 3D Gaussians (ready for fast rendering/editing) open‑source thread
- Creator impact: single‑GPU, seconds‑level inference makes previsualization, layout, and asset capture feasible in everyday pipelines; project page, GitHub, demo, and report are linked inside the announcement open‑source thread
🌀 Motion prompt tricks: aging, impact, mood
Practical video prompt recipes creators shared today: Grok Imagine aging timelapse, comedic salmon‑punch face warp, romance/close‑up mood control; plus a Seedance push‑in tracking shot prompt.
Grok Imagine nails mood and close‑ups across four new tests
Four fresh clips showcase nuanced romance, poetic night scenes, and unsettling close‑ups, following up on Mood tests which highlighted Grok’s expressive tone control. Today’s posts emphasize light–shadow staging and micro‑emotion readability in tight framings Romance clip, Night scene, Eerie close‑up, Light and shadow.
Grok Imagine prompt: instant rapid‑aging timelapse
Creators shared a one‑line Grok Imagine recipe that morphs a subject from young to very old as a fast timelapse, great for dramatic reveals or passage‑of‑time beats Aging prompt.
- Try: “Subject rapidly aging, ultra‑fast transition to extremely old, rapid time‑lapse effect” Aging prompt
Comedic impact gag in Grok: salmon‑punch face warp
A slapstick motion recipe times a facial deformation to a punch on beat—useful for comedic beats or reaction inserts without stunt footage Punch effect prompt.
- Try: “He gets hard punched with a massive salmon right in the cheek. Face hit. His face warps from the impact” Punch effect prompt
Seedance‑1‑pro prompt: push‑in tracking to tense reveal
A concise Seedance‑1‑pro recipe delivers a cinematic push‑in into a forest clearing as a warrior reacts to an ominous growl—handy for trailers, mood pieces, and game‑style cutscenes Prompt details.
- Try: “Push‑in tracking shot: The camera moves closer into a forest clearing where a warrior sharpens a blade. Birds scatter as an ominous growl echoes, the warrior stands ready. Mist swirls between the trees. Epic fantasy scene” Prompt details
🖼️ Still looks: MJ v7 params, tees, and child‑book srefs
Image‑first prompt recipes and style refs: MJ v7 parameter sets, a print‑ready B&W tee prompt, a Nordic watercolor children’s illustration sref, and creator style‑ref archives.
MJ v7 recipe: chaos 10 with sref 1367149754 yields a cohesive 3:4 set
A fresh Midjourney v7 parameter combo—--chaos 10 --ar 3:4 --sref 1367149754 --sw 500 --stylize 500—produces a tight, stylized collage with consistent palette and framing MJ v7 collage, following up on MJ v7 recipe where a chaos‑7 variant proved reliable.
- Exact params: --chaos 10 --ar 3:4 --sref 1367149754 --sw 500 --stylize 500 MJ v7 collage
Children’s illustration sref 984570117 captures Nordic watercolor look
A Midjourney style reference (--sref 984570117) pins a contemporary children’s illustration vibe—poetic realism with Nordic watercolor and colored pencil influences—ideal for storybook pages and soft narrative scenes Style reference.
Plug‑and‑play B&W tee prompt for print‑ready cartoon graphics
A reusable prompt template delivers high‑contrast black‑and‑white cartoon art with strong outlines, gritty shading, plain background, and no text—ready for T‑shirt printing straight from the generator Prompt template.
- Fill‑in slots include [emotion], [character], [clothes], and optional [pose/prop] to quickly iterate styles while keeping print‑safe composition Prompt template
Community archive style ref --sref 2813586012 invites riffs
An archived Midjourney style reference (--sref 2813586012) is back in circulation, showcasing anime‑leaning portraits, gallery scenes, and transit vignettes for the community to remix and extend Archive sref.
🛡️ Agentic browser safety: injections and Chrome plans
Security caveats for AI browsers: Atlas jailbroken via clipboard injection; Brave warns on prompt risks; Chrome docs hint agentic Gemini in a future release. Excludes Popcorn.
Clipboard injection jailbreak hits ChatGPT Atlas; treat agent mode as high risk
A public demo shows ChatGPT Atlas can be jailbroken via clipboard injection to insert malicious phishing links that the agent follows without awareness Clipboard attack demo. Following up on agent mode, which highlighted Atlas’s autonomous actions, Brave’s guidance flags prompt‑injection and DOM‑side traps as core risks for agentic browsers Brave warning. Creators should treat agent sessions as untrusted automation and keep sensitive accounts out of scope while vendors harden defenses Safety checklist.
- Isolate agent browsing to separate profiles or VMs; do not co‑mix with banking/health logins.
- Require human approval for each action; disable auto clipboard use and sandbox downloads until mitigations land.
A practical safety checklist emerges for Atlas/Comet-style AI browsers
A creator compiled a concise safety playbook for AI browsers like Atlas and Perplexity Comet—profile isolation or VMs, explicit human approvals, and avoiding high‑stakes accounts—based on current exploits and risk models Security checklist. The recommendations align with Brave’s write‑up on prompt injections, clipboard hijacking, and hidden page instructions that can steer agents off‑task Threat model.
- Review and approve queued agent actions; block auto‑form‑fills and auto‑purchases in agent contexts.
- Audit clipboard/extension permissions regularly and keep software updated to shrink the attack surface.
Chrome 143 to add agentic Gemini features with enterprise policies at launch
A Chrome 143 help pane screenshot indicates upcoming agentic capabilities for Gemini directly in Chrome, with enterprise policies available at launch Chrome 143 hint. For creative teams, native page‑aware assistance in the default browser could streamline research and on‑page edits—but it also raises the bar for built‑in safety and admin controls versus third‑party AI browsers.
🛠️ Production helpers: OCR/Markdown and image edits
Backend helpers for creative ops: Replicate hosts Datalab’s Marker + OCR (fast, $2–$6 per 1k pages) and runware ships Riverflow 1 Pro for tougher image edits with higher success rates.
Replicate hosts Datalab’s Marker and OCR models; $2–$6 per 1k pages, fast Markdown extraction
Replicate added Datalab’s Marker and OCR so teams can extract Markdown/structured text from PDFs, images, and Word docs via simple APIs, priced roughly $2–$6 per 1,000 pages and positioned as fast for bulk pipelines Model announcement, Pricing note.
- Built on the open-source Marker and Surya stacks, with ready-to-run endpoints for immediate use Marker model card, and OCR model card; background and usage details in the overview write-up Replicate blog post.
Riverflow 1 Pro lands on Runware with longer thinking time for tougher image edits
Runware made Riverflow 1 Pro publicly available, touting better quality/stability and “longer thinking time” that raises success on difficult edits and cuts retries for production image work Release thread, Availability note.
- Browse and integrate via the models catalog; Pro slots alongside Mini and base Riverflow for different speed/quality needs Models catalog.
- Context: Riverflow 1 recently debuted atop an image-edit leaderboard, hinting at strong edit fidelity prior to this Pro upgrade Leaderboard ranking.
🎙️ Voice sessions: ElevenLabs at Google and Summit
Voice‑first learning: ElevenLabs to demo v3 TTS at Google Startup School and expands Summit lineup with will.i.am and Larry Jackson. Useful for VO, dubbing, and audio design planning.
ElevenLabs Summit adds will.i.am and Larry Jackson; registration open
ElevenLabs expanded its Nov 11 Summit lineup with will.i.am and gamma. CEO Larry Jackson, spotlighting voice‑first interfaces and creative ownership Speaker announcement.
Registration is live on the official site, with sessions promising early model previews and live demos Summit site.
ElevenLabs to demo Eleven v3 TTS at Google Startup School on Nov 12
ElevenLabs will lead a developer session at Google Startup School: GenAI Media, showcasing how to unlock highly expressive voices with Eleven v3 and integrate the API into creative workflows Session details.
The talk promises a deep dive into lifelike voices, AI music, sound effects, and practical implementation tips for interactive media and storytelling.
🏢 Industry pulse: layoffs and user scale stats
Business signals with creative impact: Meta reportedly cuts ~600 in AI, FAIR affected; PixVerse shares scale at Stanford—100M users, $40M+ ARR. Excludes product launch features.
Meta reportedly cuts ~600 roles in AI; FAIR said to be hit, senior director among exits
Axios-sourced chatter says Meta is eliminating roughly 600 roles across its AI org, with FAIR expected to be affected Layoffs report. Separate posts note FAIR research director Yuandong Tian was also laid off, underscoring senior-level impact FAIR director note.
For creative teams, a FAIR downsizing could slow open research and model releases that often trickle into creator tools; watch for near‑term hiring shifts to productized GenAI instead of exploratory work.
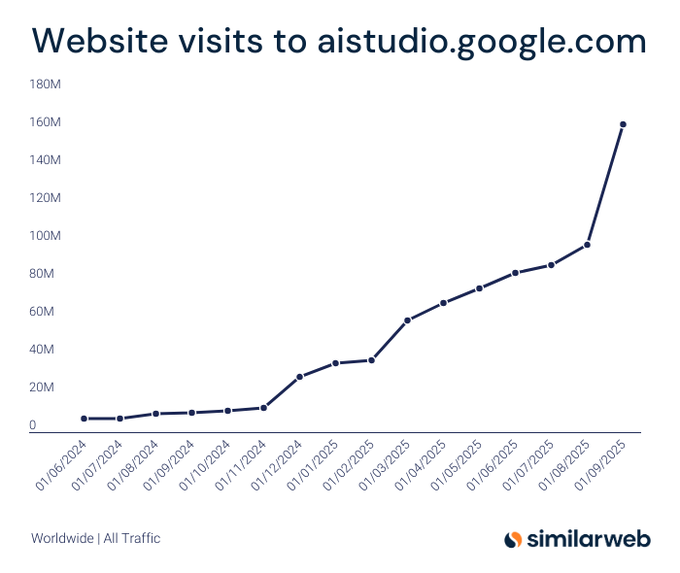
Google AI Studio traffic surges 1,453% YoY; Gemini gains share as ChatGPT slips
Similarweb charts show AI Studio’s visits jumping 1,453.34% year‑over‑year, pointing to rapid developer adoption around Google’s stack Traffic chart. A separate snapshot pegs Gemini’s generative‑AI traffic share rising from 6.4% to 12.9% while ChatGPT declines from 87.1% to 74.1% over 12 months Traffic share note.
For creatives, this rebalances platform risk: more viable pipelines around Gemini/AI Studio mean broader access to video, image, and agent features outside OpenAI‑centric workflows.
PixVerse shares scale: 100M users and $40M+ ARR, doubles down on mobile-first creator growth
At a Stanford fireside chat, PixVerse said it has surpassed 100M users and $40M+ ARR while pushing a mobile‑first, template‑driven path from viewer to creator Stanford talk.
Why it matters: dependable revenue at this scale signals sustained demand for lightweight video creation; expect faster iteration on real‑time gen and monetization that favors short‑form storytelling.
Claude Sonnet 4.5 tops Poe’s usage leaderboard, edging out Gemini 2.5 Pro and GPT‑4o
Poe usage rankings now show Claude Sonnet 4.5 as the most used model on the platform, with Gemini 2.5 Pro and GPT‑4o in the next slots Poe leaderboard. For production teams, this hints at a swing toward Claude for drafting, editing, and planning tasks that sit upstream of video and design work.
🧪 Papers to watch: long video, alignment, trillion‑step RL
Today’s research skewed toward long‑video generation and scalable RL: MoGA sparse attention, UltraGen hierarchical attention, extracting alignment data from open models, and Ring‑1T RL training infra.
MoGA sparse attention pushes minute‑long, multi‑shot video generation
ByteDance researchers propose Mixture‑of‑Groups Attention (MoGA), a sparse routing scheme that enables end‑to‑end long‑video generation at minute scale with multi‑shot structure, targeting around 480p today paper thread.
For creators, MoGA’s efficiency promises longer coherent narratives without splitting into separate clips—watch this space for open weights or demos that could land in production tools.
Ring‑1T details trillion‑parameter RL training for “thinking” models
Every Step Evolves describes Ring‑1T, a trillion‑parameter sparse‑activated model (~50B active per token) trained with large‑scale reinforcement learning, reporting results on AIME‑2025, HMMT‑2025, CodeForces, and ARC‑AGI‑v1 paper post.
Though not video‑specific, scalable RL that improves step‑wise reasoning could power stronger storyboarders, editors, and agentic director tools that plan multi‑shot sequences with fewer retries.
UltraGen introduces hierarchical attention for high‑resolution, 4K‑ready video
UltraGen outlines a hierarchical attention design aimed at scaling video generation to higher resolutions, with examples spanning 480p to 4K and comparisons against Wan and Hunyuan Video paper thread.
If adopted in creator tools, hierarchical attention could reduce artifacts at 1080p–4K and stabilize fine detail across longer shots.
Google explores extracting alignment data from open models via embeddings
A Google study shows alignment training signals can be partially reconstructed from post‑trained open models using embedding‑based extraction, highlighting risks in data distillation and safety leakage paper post.
For creative AI pipelines, this flags caution when remixing or distilling aligned models—licensing and provenance for alignment data will matter for downstream tools and plugins.
🏆 Screenings and calls: horror votes, MAX talks
Community events for filmmakers: Leonardo’s AI Horror Film Competition voting opens; Adobe MAX session to showcase AI shorts and workflows. Excludes business metrics and launches covered elsewhere.
Adobe MAX session to debut three AI shorts and workflow breakdown
Promise Studios’ Dave Clark and MetaPuppet will premiere three new AI‑made shorts and share how they’re using Adobe’s GenAI tools at Adobe MAX on Oct 28, following up on AI in Filmmaking which earlier teased a single premiere Session preview.
Voting opens for Leonardo’s AI Horror Film Competition
Audience voting is now live for the Third Annual AI Horror Film Competition presented by Curious Refuge, Epidemic Sound, and Leonardo AI Voting opens. Cast your ballot on the official lineup and see entries before winners are announced Oct 30, with a cash pool listed at $12,000 Competition page.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught