OpenAI Sora opens app in 4 countries – reusable cameos anchor continuity
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI cracked Sora wider open today: for a limited window, anyone in the US, Canada, Japan, and Korea can use the app without an invite, and a new Create character flow ships reusable cameos. That matters because continuity is the wall for AI video — you can now keep the same face across shots without prompt gymnastics. With four markets stress‑testing the feature, we’ll learn quickly where it holds and where it breaks.
Adoption is instant: three early cameos — ProperPrompter’s officialproper, Prim the puppet, and a NEO robot — are already live, with the robot even hitting the app leaderboard. The in‑app overflow menu lets you turn a generated person into a cameo, but moderation is strict: uploads that include realistic humans get flagged, nudging creators toward stylization or a two‑step workflow. A practical recipe is popping up — build start and end frames in Kling, trim to a ~3‑second clip, then upload to Sora to register and reuse — and we’re already seeing playful crossover tests.
Following earlier third‑party trials of Sora 2, this moves the iteration loop into a first‑party workspace; if you need precise shot control, Veo 3.1’s timestamp prompts pair nicely once the cast is locked.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught
Feature Spotlight
Sora character cameos + wider access
Sora opens access (US/CA/JP/KR) and adds reusable character cameos—unlocking consistent casts and faster multi‑shot storytelling for creatives.
Big day for filmmakers: Sora opens limited-time app access in four countries and adds reusable character cameos. Multiple creators register and test cameos, share handles, and note moderation limits.
Jump to Sora character cameos + wider access topicsTable of Contents
🎭 Sora character cameos + wider access
Big day for filmmakers: Sora opens limited-time app access in four countries and adds reusable character cameos. Multiple creators register and test cameos, share handles, and note moderation limits.
Sora adds reusable character cameos with an in‑app “Create character” flow
OpenAI introduced character cameos inside the Sora app, enabling creators to register characters and reuse them across generations Cameos announcement. A new in‑app entry point lets you convert a generated person into a cameo directly from the overflow menu via Create character, streamlining continuity for episodic content and series work Cameo creation menu.
Sora app opens without invites in the US, Canada, Japan, and Korea (limited time)
OpenAI is letting users in four countries access the Sora app without an invite for a limited window, widening hands-on testing for filmmakers and creators Access expansion. This follows Free trial deals that put Sora 2 in more third‑party workflows, and should accelerate real‑world stress tests of new features like cameos.
Cameo moderation flags realistic humans, prompting creator workflow tweaks
Some uploads are being rejected during cameo creation with a notice to avoid realistic humans in frame, indicating tightened guardrails on character registration Moderation warning. Community replies suggest workarounds like converting to an AI sketch look before refining to realism after cameo creation Workaround tip.
Early cameo adoption: officialproper, primthepuppet, and NEO robot go live
Creators are already registering and testing cameos: ProperPrompter’s officialproper is live Creator handle, the puppet Prim is cameo‑ready with a visible Cameo button in the profile UI Puppet cameo UI, and @blizaine launched a NEO robot cameo that later appeared on the app leaderboard NEO cameo note, Leaderboard note. These early handles suggest a fast path to consistent casting for shorts and series.
How creators are building cameo clips: start/end frames in Kling, then upload to Sora
A practical recipe is emerging: generate a start and end frame with Kling, speed the clip to ~3 seconds in an editor, then upload to Sora to register or exercise a cameo Cameo build steps. Creators are already sharing playful tests featuring cameo crossover moments, signaling quick iteration loops for shortform storytelling Arcade example.
🎬 Veo 3.1 prompt blueprints and directing tricks
Hands‑on Veo 3.1 guidance for cinematic shots: timestamp‑driven direction, multi‑angle references, and detailed 8s scene specs. Excludes Sora cameo news (covered in the feature).
Timestamp prompting in Veo 3.1: direct shots by the second
Runware demonstrates a clean 0:00–0:06 timestamp script to drive lighting, eyeline, micro‑actions, and SFX beats in Veo 3.1, starting from a single Seedream still. The mini‑sequence (close‑up → flicker → whisper blackout) shows how to previsualize tension and keep outputs on‑brief. See the walk‑through in How‑to thread, the base still in Seedream setup, and the second‑by‑second prompt in Timestamp prompt.
Tip: write one decisive verb per time slice (stare, shift, whisper) and bind each to lighting/mood cues to reduce drift.
Flow by Google lets you extend Veo 3.1 clips for longer sequences
A creator extends a Veo 3.1 text‑to‑video output twice in Flow, effectively chaining the beat into a longer, coherent shot progression Extension example. This is a practical follow‑up to First‑last frame, where creators showcased start/end frame control; extension now stretches that control over multi‑beat arcs.
Tip: end each segment on a compositional rhyme (pose, horizon line, or lighting cue) to give the next extension a stable hand‑off.
Veo Ingredients honors multi‑angle references for character consistency
Creators confirm Veo Ingredients can take multiple reference angles of the same subject and preserve them reliably across shots. This saves setup time when cutting between close, three‑quarter, and profile views in a single clip or sequence Ingredients example.
Tip: bundle tight, mid, and wide stills in one prompt pass, then specify which angle anchors each beat (e.g., “02:00–03:00 profile, 03:00–04:00 three‑quarter”).
First‑person dragon dive: second‑by‑second Veo 3.1 camera plan
A first‑person ride blueprint specifies gauntlet/rein foreground detail, banking roll (Dutch angle), high‑speed descent with controlled blur, and deceleration to a crisp castle lock‑off—timed across 0–8s and lit for golden hour volumetrics. The granular timeline shows how to keep subject sharp while letting the world streak for scale POV prompt.
Tip: pin sharpness to a central anchor (city/castle) during the speed pass and reserve motion blur for the periphery to maintain readability.
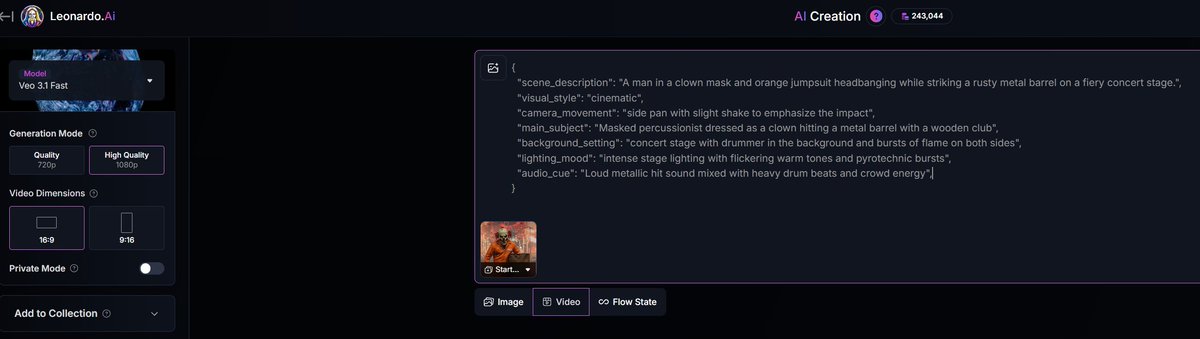
Image‑to‑Veo pipeline: build references in Leonardo, then script the shot
Workflow share: design hero images first (character, set, palette) in Leonardo, then pass them as references to Veo 3.1 Fast and direct the scene with a compact JSON prompt for style, camera, lighting, and sound. Screens show the exact fields and framing (e.g., low‑angle, slow zoom‑in, intense stage light) Leonardo timeline.
Tip: keep image refs tight on production design and push motion in the prompt—Veo will honor the look and improvise movement on‑model.
Retro side‑scroller look: a Veo 3.1 Fast blueprint on Gemini
A fully specified “diorama” side‑scroller treatment lays out layered parallax worlds, exaggerated hero actions, dynamic side‑scroll camera with subtle vertical shifts, and event lighting pops. Use wide‑angle (24–35mm), time‑blocked camera moves, and sound notes to sell the retro‑meets‑cinema vibe in Veo 3.1 Fast on the Gemini app Blueprint prompt.
Tip: script three beats (intro scroll → jump/tilt → attack/reveal) with a tiny zoom‑out in beat 3 to showcase environment detail.
🌀 Hailuo 2.3 creator runs and Halloween pushes
Fresh I2V tests and action prompts, plus seasonal credit drives and dance challenges. Motion realism and speed keep drawing creators. Excludes Sora cameo feature.
Hedra adds Hailuo 2.3 and opens 1,000 free credits to all Halloween posts
Hedra’s Halloween push now grants 1,000 free credits to everyone who creates and tags “Hedra Halloween” this week, with a prompt guide sent via DM after Follow + RT + reply. This expands the earlier cap and brings Hailuo 2.3 directly into Hedra for seasonal content, following up on Hedra 1,000 credits which limited the initial offer. See the details in Hedra announcement.
Community drops production‑ready Hailuo 2.3 action prompts
A shared prompt pack lays out eight cinematic action setups for Hailuo 2.3—useful as plug‑and‑play blueprints for trailers and set pieces. See the recipes in Prompt thread.
- Oil‑rig missile strike with sweeping crane moves and VFX‑friendly beats.
- Car vs F‑16 desert race with low‑angle trucking and dust kick‑ups.
Hailuo 2.3 momentum: creators praise realism, physics, and emotion
Creators report that Hailuo 2.3 is “blowing up,” citing convincing physics, elemental effects, and nuanced emotional reads—signals the model’s I2V strengths are translating to on-brief results for cinematic and music‑video workflows. See the pulse in Creator sentiment.
Dance Battle clips showcase Hailuo 2.3’s smoother motion
Under the #HailuoDanceBattle tag, creators are posting smooth, consistent dance sequences that emphasize improved body mechanics and camera‑aware motion—good stress tests for continuity and choreography. Watch an example in Breakdance clip.
Overnight i2v grind with Hailuo 2.3 Fast
Creators are logging late‑night production sessions on Hailuo i2v 2.3 Fast, underscoring both speed and reliability for high‑volume iteration when deadlines are tight. Example session in Late-night session.
Stylized anime test with Hailuo 2.3 nails dreamlike suspension
A shared anime demo and prompt shows petals hovering around a character in slow, surreal motion—evidence that Hailuo 2.3 can carry stylized beats with consistent subject treatment and restrained physics. See the setup in Anime sample.
🧱 FIBO: JSON‑native, controllable image gen
Multi‑platform push for Bria’s structured text‑to‑image: JSON prompts, disentangled controls, and licensed‑only training. Strong fit for brand‑safe, reproducible design.
FIBO launches on fal: JSON‑native, controllable image gen trained on licensed data
fal made Bria’s FIBO available platform‑wide: a JSON‑native text‑to‑image that disentangles camera, lighting and color, and expands plain ideas into structured JSON before rendering Launch thread. It’s trained exclusively on licensed datasets and positioned as rights‑cleared and EU AI Act‑aligned, with a live generator to try it now IP assurance, fal generate page.
FIBO’s attribute‑only edits change lens, lighting, or color without breaking the scene
Creators can nudge only specific attributes—e.g., switch to 85mm, add backlight, or warm skin tones—without collapsing composition; FIBO regenerates just those factors and returns the updated JSON Attribute edit demo. The capability sits atop the broader JSON‑native control model fal outlined at launch Launch thread.
Image→JSON: FIBO extracts full visual spec for precise remixing
Upload any image and FIBO will extract a detailed JSON description of its visual elements (camera, lighting, palette, subjects), enabling faithful variations and blends for brand‑safe workflows Image to JSON.
fal Academy episode explains FIBO’s JSON prompting and enterprise guardrails
fal Academy Ep. 8 walks through JSON prompting patterns, disentangled controls, and enterprise readiness for FIBO Episode video, complementing the feature roll‑out and showing end‑to‑end creative flows Launch thread. Watch the breakdown for practical direction and production tips YouTube episode.
Replicate hosts FIBO as an API‑ready, open model for creatives
Replicate added FIBO as an “open‑source model drop,” providing an instant playground and API so teams can wire JSON‑native, controllable T2I into apps quickly Replicate update.
Runware D0 adds FIBO with per‑iteration region isolation for reproducible edits
Runware D0 now hosts FIBO with a workflow that isolates and edits a single region per iteration, keeping the rest of the scene locked for reliable, repeatable changes on large projects Runware rollout, Runware models. The integration leverages FIBO’s core JSON controls as introduced by fal Launch thread.
fal × Bria launch a $500 Halloween contest for the spookiest FIBO image
A fal × Bria competition will award $500 to the spookiest FIBO generation, pushing creators to stress‑test JSON‑native control for seasonal art Contest details. See the core feature set powering entries and tune prompts accordingly Launch thread.
🪄 Design copilots and layered edits
Designers get faster, editable pipelines: Adobe Express AI Assistant (beta), Firefly Model 5 layered image editing preview, Runway’s ad app, and QuickDesign 3.0. Mostly practical workstation news.
Adobe Express AI Assistant opens limited desktop beta with a 30‑day trial
Adobe’s new AI Assistant in Express is now available to try on desktop with a 30‑day free trial window, preserving editable layers while letting you prompt, tweak via a mini editor, and iterate fast—following up on MAX announce that introduced the feature. Premium users get early access; space is limited. See the rollout details in beta announcement and the sign‑up in trial reminder, with product access at Adobe Express page.
Firefly Model 5 preview shows layered image editing with lighting/shadow harmonization
Adobe previewed Firefly’s Layered Image Editing powered by Image Model 5, promising contextual object awareness and auto‑harmonized lighting, shadows, and color across editable layers, integrated into Photoshop, Express, and Creative Cloud. The tease suggests faster, more intuitive edits without flattening designs feature brief.
Bria FIBO arrives as a JSON‑native, controllable image model with rights‑cleared training
FIBO expands a plain idea into structured JSON, then renders it—letting you surgically adjust attributes like camera, lighting, and color without breaking the scene. It can also extract a detailed JSON description from an uploaded image for targeted edits. • JSON‑native prompting and disentangled controls are showcased by fal model release, with attribute‑only tweaks such as “backlit,” “85mm,” or “warmer skin tones” attribute edits, and image→JSON extraction image to JSON. • Trained exclusively on licensed datasets from 20+ partners and positioned as enterprise‑ready; try it on fal’s hosted page fal model page. • Availability spans platforms, including Runware’s D0 for reproducible, region‑specific edits Runware support and Replicate for quick API access replicate page.
Runway’s Create Ads app turns one ad into endless variants by prompt
Runway released a ‘Create Ads’ app that remixes an existing ad into new iterations—swap the subject, headline, or product shot with a simple prompt—part of its Apps for Advertising collection and available now. Details and access in feature post and the live tool at Runway ad app, with a follow‑up nudge to try it here try link.
QuickDesign 3.0 converts any AI image into a fully editable layered file in‑browser
QuickDesign 3.0 promises to turn any AI image into an editable, layered file so you can refine composition, swap elements, and art‑direct without regenerating—directly in your browser. A creator highlights granular control over “every single aspect” of the image feature claim.
🗣️ Real‑time voice and voice restoration
Fast multilingual speech and compassionate use‑cases: MiniMax Speech 2.6 arrives on fal with <250 ms latency, and ElevenLabs partners to restore voices for stroke survivors.
MiniMax Speech 2.6 goes live on fal with <250 ms latency and 40+ languages
MiniMax Speech 2.6 is now available on fal, delivering sub‑250 ms end‑to‑end latency for real‑time dialogue, 40+ languages with inline code switching, full voice cloning, and smart text normalization for URLs/emails/dates. Creators get a fast path from script to natural, expressive speech, with a web demo and WebSocket API docs ready to build on fal launch, Feature highlights, MiniMax audio, and API docs.
The combination of Fluent LoRA expressiveness and low latency should make live agents, dubbing, and interactive characters feel significantly more responsive in production pipelines.
ElevenLabs partners with Stroke Onward to offer free voice restoration access
ElevenLabs and Stroke Onward opened applications for stroke survivors to receive free access to voice cloning tools via the ElevenLabs Impact Program, aiming to help people with long‑term speech loss recreate a voice that feels like their own Partnership post and Program details. Following up on Halloween voices, which highlighted seasonal voices, this initiative shifts focus to compassionate restoration at scale (over 12 million people experience a stroke each year). Apply and learn more via the official resources Blog post and Impact application.
For filmmakers and storytellers working with real subjects, this can ethically enable narration, ADR, and accessibility without sacrificing identity.
Replicate hosts ElevenLabs speech with $5 promo credits for first 1,000 users
Replicate added ElevenLabs’ speech models for fast API‑driven TTS, offering the first 1,000 new users $5 in credits to try ultra‑realistic voices with controllable emotion, accent, and style—handy for apps, podcasts, trailers, and in‑engine VO API promotion and Replicate invite.
Pair this with your existing creative stack to automate alt reads, multi‑locale variants, and rapid voice iterations across storyboards and animatics.
Fish Audio releases S1, an expressive and natural TTS model
Fish Audio announced S1, positioned as an expressive and natural TTS model for creators seeking lifelike deliveries in multiple styles Release mention.
While details are light in today’s posts, S1 adds another option in the rapidly expanding real‑time voice toolbox for trailers, shorts, and character reads.
🎼 Score it: music gen and cover workflows
Musicians and editors get new ways to score and package videos: ElevenLabs Music creation, Replicate TTS credits, and practical ‘AI cover’ visual pipelines.
ElevenLabs Music tutorial shows structure‑controlled tracks in minutes
ElevenLabs published a short walkthrough on generating original music across genres and moods with control over structure, style, and vocals—geared to quickly score videos with usable stems Feature walk-through. For editors and storytellers, this lowers the time from brief to on‑brand soundtrack without leaving the cut.
MiniMax Speech 2.6 brings <250 ms, 40+ languages TTS
MiniMax rolled out Speech 2.6 with sub‑250 ms latency for real‑time voice, smart text normalization (URLs, dates, numbers), full voice clone with Fluent LoRA, and 40+ languages with inline code‑switching—now available via web demo and API docs MiniMax audio, API docs. It’s also live on fal for easy integration in creator toolchains fal integration.
This is a strong fit for narration, dubbing, and interactive characters where responsiveness matters.
Replicate hosts ElevenLabs voices with 1,000 free API slots
Replicate added ElevenLabs speech models and is giving the first 1,000 users free credits to run them via API, making pro‑grade voiceovers easier to add to creative apps API invite, and the welcome page shows a $5 credit on sign‑in Replicate welcome page. This follows GLIF music API coverage of ElevenLabs’ music tools, which highlighted directable song generation for creators.
How to build viral AI cover visuals with Leonardo and Veo 3.1
AI music covers are surging, and a practical workflow shows how to design stylized visuals in Leonardo, then animate them with Veo 3.1 using image‑as‑reference and precise prompts (prompts shared in ALTs) Leonardo workflow, with a follow‑up applying those references inside Veo 3.1’s settings panel Veo 3.1 setup.
The approach packages a song into a cohesive video look without 3D or heavy compositing, ideal for shorts and social promos.
Fish Audio releases S1, a new expressive TTS model
Fish Audio announced S1, an expressive, natural‑sounding text‑to‑speech model aimed at high‑quality voiceovers and dialogue Release note. For creators, it’s another option in the fast‑moving TTS stack for narration and character voices.
OpenArt’s new music tools re‑orchestrate old tracks
A creator demo shows OpenArt’s latest music features transforming an older composition into a lush, modern orchestral rendering, suggesting more directable re‑production rather than fully new generation OpenArt demo. This hints at practical remix workflows for scoring reels and shorts from existing sketches.
🎥 Hybrid filmmaking case study: My Friend, Zeph
MAX‑week showcase: Dave Clark’s ‘My Friend, Zeph’ blends live action, blue screen, and Adobe Firefly for memory‑rich visuals; multiple BTS and 4K links shared.
‘My Friend, Zeph’ premieres at Adobe MAX with a live‑action + Firefly hybrid workflow
Dave Clark’s short ‘My Friend, Zeph’ debuted at MAX, built from location shoots and blue‑screen plates, then augmented in Adobe Firefly to expand worlds and visualize memory film announcement. A 4K non‑compressed upload is available for scrutiny 4K post, with more viewing via the creator’s share YouTube 4K and partner confirmation of the premiere debut notice.
Promise Studios publishes BTS case study for ‘My Friend, Zeph’
Promise Studios released a production breakdown detailing how Firefly was used to expand the world, harmonize emotion, and render memory sequences, including on‑set to post steps studio blog post. The drop follows two sessions highlighted for MAX, and includes the full write‑up for creators who want process specifics Promise blog.
Full behind‑the‑scenes video drops for ‘My Friend, Zeph’
A dedicated BTS video showcases Zeph’s hybrid pipeline—on‑location and blue‑screen footage, then generative passes for mood and memory motifs—giving filmmakers a clearer view of the craft decisions behind each beat bts video link. The director also flagged the making‑of effort and team collaboration during MAX week bts teaser.
MAX main stage spotlights hybrid AI filmmaking alongside Zeph buzz
Adobe’s main stage and the AI Film Festival put hybrid AI productions front and center, reinforcing the momentum behind projects like ‘My Friend, Zeph’ during MAX week main stage photo. Promise Studios’ note on the Zeph debut and BTS coverage rounds out the case‑study focus for creators exploring mixed live‑action and generative pipelines debut notice.
🖌️ Style refs and lookbooks for stills
Fresh style recipes for illustrators and art leads: late‑80s cinematic anime sref, expressive urban sketches, MJ V7 boards, moody line art, and photo realism sets.
MJ style ref 337420992 channels late‑80s cinematic gothic anime
A new Midjourney style reference — Cinematic Gothic Cyber‑Fantasy Anime — captures the mood of classic 80s/90s titles with painterly highlights and horror‑fantasy flair Style thread.
It’s a cohesive look for key art, posters, and character sheets reminiscent of Vampire Hunter D, Ninja Scroll, and Wicked City, giving art leads a reliable palette of color, costume, and lighting cues to brief teams fast.
Expressive urban sketching lookbook via style ref 2215869261
This mixed‑media architectural sketch style blends ink lines with marker flats for a mid‑century European vibe, evoking Sempé and René Gruau Style thread.
Great for travel editorials and product-in-place comps, the board shows consistent line weight, color blocking, and perspective that translate well to series work.
MJ V7 travel‑lifestyle board: chaos 17, sref 4010216951, stylize 600
Fresh V7 settings (chaos 17, —ar 3:4, —sref 4010216951, —sw 400, —stylize 600) produce a warm lifestyle collage with people, interiors, and vistas Recipe post, following up on MJ V7 recipe that set the baseline recipe.
The look holds consistent palette and brush‑y texture across panels, handy for pitch decks and moodboards.
Nano Banana fashion portrait recipes for hyperreal editorials
Two detailed prompt specs outline camera/lens, lighting rigs, fabrics, accessories, and pose choreography to achieve high‑fashion, hyperreal portraits with editorial consistency Detailed prompt.
The JSON‑like structure (shot type, optics, DoF, wardrobe, and negative prompts) doubles as a creative brief you can hand to teams or reuse across a series; see an alternate wardrobe and lighting variant for cross‑checks Alternate look.
‘QT light’ delivers a luminous single‑line portrait motif
A clean, glowing line‑art aesthetic on black ground (“QT light”) reads instantly at thumbnail sizes and scales to posters without fuss Style cue.
Use it for brand avatars, title cards, and merch where minimal geometry and controlled glow provide cohesion across a campaign.
Crisp natural‑light studies from ultra‑simple prompts (iamneubert)
Landscape and portrait sets demonstrate how minimal prompting can yield photoreal lighting, natural color, and strong composition — useful as quick references for DoP lookbooks Landscape set, and for close‑up skin/texture studies Portrait set.
These are solid baselines for grading targets, lensing notes, and location scouts.
Crystal couture moodboard: dvfx887 preset for jeweled fashion boards
A 12‑tile grid shows a coherent, crystal‑encrusted couture look using a consistent preset (--p dvfx887), ideal for accessories and high‑shine textiles Moodboard grid.
The board’s repeatable spec gives art directors a fast way to align on materials (sequins, veils, faceted jewelry) and silhouette before moving to production comps.
🧠 Applied research: control, UHR detail, and agents
Mostly paper drops relevant to creative tooling: controllable attention for edits, UHR detail datasets, corpus self‑play for reasoning, game agents, web agents, deep research. Practical angles noted.
GRAG gives DiT image editors a dial for edit intensity
Group Relative Attention Guidance reweights DiT query–key token deltas to continuously control edit strength without retraining, integrating in roughly four lines and improving smoothness over CFG for on‑brief edits Paper thread, and ArXiv paper.
For creatives, this means finer, artifact‑free “more/less” adjustments to local changes (lighting, color, texture) while preserving the untouched regions’ look.
AgentFold shows long‑horizon web agents can win with proactive context folding
AgentFold treats history as a dynamic workspace and “folds” context each step, posting 36.2% on BrowseComp and 47.3% on BrowseComp‑ZH—beating larger and proprietary baselines like o4‑mini Paper thread, and Paper page.
Following up on DeepAgent paper, which introduced a memory‑folding agent, this adds concrete web‑task gains that matter for auto‑briefing, sourcing, and multi‑tab research flows.
SPICE uses corpus self‑play to auto‑curriculum reasoning tasks
Meta’s SPICE frames one model as Challenger (mines documents) and Reasoner (solves them), generating steadily harder, document‑grounded tasks that lift reasoning without brittle hand‑curation Paper thread, and ArXiv paper.
For research assistants and story developers, this hints at agents that build their own study guides from archives, improving long‑form planning and fact‑checked outlines.
Tongyi DeepResearch details an autonomous deep‑research stack with SOTA
Alibaba’s Tongyi DeepResearch outlines end‑to‑end agent training (agentic mid/post‑training) with fully automated data synthesis—30.5B params (3.3B activated per token)—and reports SOTA on Humanity’s Last Exam, BrowseComp, and WebWalkerQA Paper thread, and Paper page.
Creative takeaway: more reliable desk‑research copilots for treatments, decks, and historical look‑books, with less prompt babysitting.
UltraHR‑100K and frequency‑aware post‑training push fine detail in T2I
UltraHR‑100K introduces 100k+ images above 3K resolution plus two tricks—Detail‑Oriented Timestep Sampling (DOTS) and Soft‑Weighting Frequency Regularization (SWFR)—to retain high‑frequency detail in diffusion outputs Paper thread, and ArXiv paper.
Expect sharper typography, fabrics, and tiny props, which matters for print posters, product shots, and production boards.
ByteDance’s Game‑TARS pretrains generalist agents across OS, web, and sim games
Game‑TARS unifies the action space (human‑like keyboard/mouse) and pretrains on 500B+ tokens spanning OS, web apps, and simulation games, doubling prior SOTA on open‑world Minecraft and showing competitive FPS performance vs frontier LLMs Paper thread, and ArXiv paper.
This suggests controllable creative bots that can operate UIs and sandbox tools—useful for automated previz blocking, layout tests, or QA of interactive builds.
FALCON injects 3D spatial priors into VLA action heads
“From Spatial to Actions” proposes enriching the action head with rich 3D spatial tokens (optionally using depth/pose) to boost spatial reasoning in vision‑language‑action models, without retraining the backbone Paper thread, and Paper page.
Better spatial grounding helps embodied capture, camera blocking, and scene‑aware assistants that understand where to move or point next.
🛠️ Creative dev tools: IDEs, gateways, interactive video
Agentic coding and runtime improvements that help creative teams ship: Cursor 2.0’s Composer, Bifrost gateway at scale, and Odyssey v2 interactive video. Focus on speed and reliability.
Cursor 2.0 ships Composer, a low‑latency coding model with parallel agents
Cursor 2.0 debuts Composer, a fast coding model and a multi‑agent interface that runs assistants in parallel for quicker iterations. Following Cursor 2.0 tease, the team shares a chart showing Composer combining strong coding intelligence with best‑in‑class speed; agents can be orchestrated side‑by‑side in the new UI Composer overview, with broader context from today’s IDE model comparisons benchmarks post.
Bifrost LLM gateway hits 5k RPS with microsecond overhead and full guardrails
Bifrost, an open‑source LLM gateway, claims ~50× lower added latency than LiteLLM and sustains 5k RPS while keeping guardrails, retries, budgets, and a semantic cache. On a t3.xlarge, the team reports only 11 µs added latency at 5k RPS and 625 ms P99 end‑to‑end latency, with a clear latency‑vs‑throughput plot gateway benchmarks.
Odyssey v2 goes live: steerable, real‑time interactive AI video
Odyssey v2 is now live, delivering real‑time, steerable interactive video you can watch and control as it renders—an emerging runtime for audience‑responsive storytelling launch note.
FlowithOS field tests point to durable long‑run agent sessions; trial codes shared
Early field tests report long‑running, stable agent sessions that complete multi‑step tasks without breaking, with creators posting invite codes to get more hands on the system field test notes, and a full set of 10 access codes shared for trials access codes.
🎃 Community: Halloween comps and creator meetups
Calls to create and gather: Comfy’s horror video challenge, Vidu’s Halloween trend, Upscale Conf tickets, and a BytePlus developer day. Excludes brand‑specific model launches.
Hedra expands its Halloween promo to 1,000 credits for everyone all week
Hedra says any creator who posts Halloween content tagged “Hedra Halloween” will receive 1,000 free credits throughout Halloween week, following up on Hedra Halloween which offered a guide and limited credits to early participants Promo details.
Comfy Challenge #8 calls for open‑ended horror videos by Nov 3, 7 PM PST
ComfyUI kicked off a Halloween edition challenge inviting 1:1 horror videos under 30 seconds, due Nov 3 at 7 PM PST, with $100 cash for the winner, merch for top 3, and surprise gifts for random entrants Challenge brief. Full rules and submission link are posted on Comfy’s blog Challenge page.
Upscale Conf (Nov 4–5, Málaga): tickets live and BTS channel announced
Freepik’s Upscale Conf returns to Málaga on Nov 4–5, bringing AI, design, and creativity leaders together; tickets are available now and the team urged following @upscaleconf across socials for behind‑the‑scenes coverage Conference dates, Tickets info, Tickets page.
Expect talks, panels, workshops, and networking; group discounts are noted on the ticketing page Tickets page.
BytePlus × TRAE host a full‑day ‘Vibe Coding’ meetup in Ho Chi Minh City on Nov 22
Developers in HCMC are invited to the TRAE Meetup & Vibe Coding Experience at Novotel Saigon Centre on Nov 22 (10:00–18:00 GMT+7), a hands‑on day to take ideas to working prototypes and collaborate with peers Event details.
Seats are limited; the post encourages early registration Event details.
fal × Bria launch a $500 Halloween FIBO art contest
fal announced a Halloween competition awarding $500 to the spookiest generation made with Bria’s FIBO model, encouraging creators to push structured, controllable image prompts Contest announcement.
FIBO recently went live on fal with JSON‑native prompting and disentangled controls for lighting, camera, and color, which can help iterate reliably on eerie looks Model launch.
Vidu kicks off a playful Halloween costume trend for creators
Vidu invited users to join a lighthearted Halloween push—“Which costume will come to play?”—signaling a seasonal prompt for creators to share themed outputs under its tags Campaign teaser.
🛡️ Open safety: policy‑reasoning models you can run
One notable safety release for teams embedding policy checks at creation time: bring your own policy, inspect chain‑of‑thought labels. Useful for UGC platforms and studios.
OpenAI ships gpt-oss-safeguard (120B/20B) with bring-your-own policy and explainable labels
OpenAI published gpt-oss-safeguard, two open‑weight safety reasoning models (120B and 20B) under Apache 2.0, that apply a developer‑supplied policy at inference and return both an explainable policy decision and chain‑of‑thought rationale release overview.
Built for nuanced or evolving harms and low‑label settings, it trades higher compute/latency for flexibility versus retrained task‑specific classifiers—useful for studios and UGC platforms embedding creation‑time checks. • Download and license: Apache‑2.0 open weights with 120B/20B sizes available on Hugging Face per the announcement release overview.
While you're reading this, something just shipped.
New models, tools, and workflows drop daily. The creators who win are the ones who know first.
Last week: 47 releases tracked · 12 breaking changes flagged · 3 pricing drops caught