Thinking Machines Tinker ships managed fine‑tuning – 235B MoE, 2 training primitives
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Thinking Machines launched Tinker in private beta, a managed post‑training API that hands researchers low‑level control while deleting distributed‑systems busywork. It exposes two core primitives—forward_backward() and sample()—so you write the loop and Tinker schedules, scales, and recovers jobs across clusters. It’s MoE‑ready out of the gate, with one‑line switches up to Qwen‑235B‑A22B, and LoRA multiplexing lets many adapter runs share the same GPUs to push throughput up and costs down.
The pitch lands because it meets teams where research really happens: SFT, preference/GRPO‑style tuning, and RL arrive as cookbook recipes you can fork today. Early users already have real workloads running—Princeton on theorem proving, Stanford on chemistry reasoning, Berkeley on multi‑agent RL, and Redwood fine‑tuning Qwen3‑32B for hard control—without bespoke infra. Andrej Karpathy calls it the sweet spot—roughly 90% creative control over data, loss, and algorithm with infra toil pushed well under 10%—and John Schulman labels it the right abstraction for post‑training R&D. Skeptics of FTaaS aren’t wrong, but MoE flexibility plus adapter multiplexing changes the economics enough that owning tuned models beats hiding behind black‑box inference APIs.
If Perplexity’s 1.3 s trillion‑param weight swaps become common, Tinker’s tight RL loops could hum at production cadence.
Feature Spotlight
Feature: Tinker fine‑tuning API (Thinking Machines)
Thinking Machines’ Tinker brings researcher‑controlled fine‑tuning with infra handled for you—MoE support up to Qwen‑235B, LoRA multiplexing, and early wins from Princeton/Stanford/Berkeley/Redwood—bridging DIY and “upload & pray.”
Large cross‑account coverage today: a managed post‑training API that keeps algorithmic control with researchers while abstracting distributed infra. Threads detail MoE support, LoRA multiplexing, cookbook recipes, and early results.
Jump to Feature: Tinker fine‑tuning API (Thinking Machines) topicsTable of Contents
🛠️ Feature: Tinker fine‑tuning API (Thinking Machines)
Large cross‑account coverage today: a managed post‑training API that keeps algorithmic control with researchers while abstracting distributed infra. Threads detail MoE support, LoRA multiplexing, cookbook recipes, and early results.
Tinker debuts: researcher‑controlled fine‑tuning with managed distributed training
Thinking Machines launched Tinker (private beta), a managed post‑training API that exposes low‑level training primitives while abstracting distributed clusters, scheduling, and failure recovery. Following up on LoRA recipe (full‑tune parity), it operationalizes adapter‑centric workflows at scale with LoRA multiplexing and MoE readiness. See the design and examples in the launch write‑ups feature rundown and the official post announcement blog.
- Primitives forward_backward() and sample() let researchers write custom loops while Tinker handles scheduling, scaling, and error recovery feature rundown.
- One‑line switches span small to very large models, including MoE such as Qwen‑235B‑A22B feature rundown.
- LoRA adapter multiplexing shares GPUs across many jobs to cut cost and increase experiment throughput feature rundown.
- The open‑source Tinker Cookbook ships ready‑to‑use post‑training recipes (SFT, preference/GRPO‑style, RL loops) announcement blog.
- The product is in private beta with invites open; Mira Murati confirmed the launch founder note.
Real workloads already running on Tinker: theorem proving, chemistry and multi‑agent RL
Early users report complex post‑training loops running out‑of‑the‑box on Tinker, indicating production‑grade infra for research teams feature rundown.
- Princeton trained theorem provers; Stanford built chemistry reasoning models; Berkeley ran multi‑agent RL loops; Redwood fine‑tuned Qwen3‑32B for hard control problems feature rundown.
- A beta user notes plans to integrate Tinker with their RL environments, citing the API’s simplicity for wiring up training runs beta feedback.
- Additional community coverage reiterates adapter sharing and automatic distributed recovery as practical unlocks for iteration speed overview recap.
Karpathy and Schulman call Tinker the “right abstraction” for post‑training
Veterans frame Tinker as keeping creativity with researchers while deleting infra toil. The guidance: prefer scoped finetunes with abundant examples over ever‑larger prompts.
- Karpathy: retain ~90% creative control (data, loss, algorithm) while cutting infra to “≪10%”; finetuning shines for narrow tasks vs “stylizing” a giant model karpathy take.
- John Schulman: “the right abstraction layer” for post‑training R&D—exactly the infra he’s wanted schulman view.
- Ecosystem read: some expect Tinker to kick‑off the “API‑ification” of finetuning the way OpenAI did for inference ecosystem take.
Fine‑tuning‑as‑a‑service returns—and why this time might stick
Skeptics asked “why FTaaS in 2025?”—but practitioners argue the combination of stronger bases, MoE flexibility, and adapter multiplexing lowers cost and risk enough to make it compelling.
- Community skepticism: “Fine‑tuning as a service in 2025? What did they see?” skeptic take.
- Counterpoint: teams should own tuned models rather than rely on black‑box APIs; long‑term value in differentiation and better products open‑source view.
- The launch details show practical unlocks (LoRA multiplexing, infra‑free distributed loops) that address past pain points for iteration speed and operational burden feature rundown.
💻 Agentic coding stacks & dev tooling
Active day for coding agents, CLIs, and IDEs (Zed, OpenCode Zen, Imbue Sculptor, Verdent, Netlify Agent Runner, Taskmaster). Excludes Tinker (covered as the feature).
Agent Runner + Codex: orchestration from CI without bespoke infrastructure
Netlify’s Agent Runner can coordinate many agents from CI—now including Codex—so teams can push agentic refactors and tests through the same pipelines used for builds and deploys launch note.
🧩 MCP, connectors & enterprise chat surfaces
Interoperability and enterprise entry points advanced: Claude in Slack, ChatGPT Slack connector traces, Anthropic Skills, Azure’s agent framework, MCP best practices. Excludes Tinker.
Claude lands in Slack with DMs, thread mentions and workspace search
Anthropic’s Claude now runs natively inside Slack, enabling direct messages, @mentions in threads with draft‑before‑send, and an assistant panel. Team and Enterprise admins can authorize Claude to search channels, DMs, and files, scoped to each user’s existing permissions Slack integration details, and full feature notes are on Anthropic’s site Anthropic news.
- Includes web search, document analysis, and connected tools so teams can prep meetings, gather updates, and draft docs inside Slack Launch post.
- Workspace access is opt‑in and admin‑gated; Claude can only see what a user can see, and searches respect channel/DM visibility Slack integration details.
Azure AI Foundry previews an Agent Framework; SK and AutoGen converge
Microsoft demoed a sequential Agent Framework in Azure AI Foundry (e.g., PII extractor → anomaly flagger → report generator), indicating first‑party tooling for designing agent chains with connectors and logs Workflow demo. In parallel, a new diagram shows an umbrella “Agent Framework” with MCP and broad connector targets, and community chatter says Semantic Kernel and AutoGen are merging under this banner Framework diagram.
- The visualizer runs tasks on gpt‑4.1‑mini in the example and captures step inputs/outputs for observability Workflow demo.
- The connectors map spans OpenAPI, Bedrock, databases, serverless functions, browsers, and MCP endpoints Framework diagram.
ChatGPT Android adds Direct Messages; Slack bot traces hint a connector
Strings in the ChatGPT Android beta (“Calpico Rooms”) show a new Direct Messages surface with join/leave notices, profile updates, and DM notifications; early notes say personal memories won’t be accessible in DMs to preserve privacy Android beta strings. Separately, code references in the web app point to a Slack bot and a Slack Codex connector, suggesting a forthcoming Slack integration for ChatGPT Connector traces.
- The Android build exposes username controls and profile image rules visible to message recipients Android beta strings.
- Slack connector traces align ChatGPT with enterprise chat surfaces already shipping from competitors Connector traces.
Anthropic tests ‘Skills’: uploadable SKILL.md packs reusable across chats
Anthropic is experimenting with “Skills” — repeatable, customizable instruction bundles that users can add to Claude by uploading a .skill file or a zip containing SKILL.md; Skills can then be invoked in any chat Skills preview.
- The UI copy describes Skills as reusable instructions Claude can follow, with an “Add skill” flow for custom and prebuilt packs Skills preview.
- Early documentation suggests potential for a community standard around portable instructions Feature write-up.
Microsoft readies Copilot connectors and a ‘Coco’ chat mode
UI strings uncovered show new Copilot connectors (including Gmail, Google Calendar, and Contacts) and an experimental “Coco” chat option billed as “warm and intuitive,” alongside an email assistant Feature leak. Early write‑ups compile the changes and connector toggles in one place TestingCatalog post.
- Outlook‑style inbox/calendar assistance and granular connector controls are mentioned, pointing to deeper personal+work graph access from Copilot Feature leak.
OpenEdison: an OSS firewall to stop MCP agents from leaking data
OpenEdison debuts as an open‑source “agent firewall” that deterministically blocks data exfiltration and dangerous actions, even under jailbreaks, by tracking per‑session tool usage and cutting off writes under a “lethal trifecta” condition Project launch. The one‑command start (uvx open‑edison) ships with a Discord, blog, and GitHub repo for teams to trial today Community Discord, Blog post, and GitHub repo, following up on Exploit playbook that documented poisoned tools and cross‑server shadowing.
- Designed for MCP/TCP tool ecosystems where agents can hit internal systems of record; the firewall adds deterministic guardrails without removing autonomy Roadmap note.
Building lean, reliable MCP servers: Stainless’ field-tested patterns
Stainless shared MCP design practices from production work: keep toolsets small with precise names and minimal I/O, add a JSON filter to strip noise, and use a 3‑tool dynamic mode (list → inspect → execute) to tame large APIs. Longer‑term, they expect most power from a simple code‑execution tool plus a doc search tool Best practices talk, with full discussion available via the interview links Spotify episode and YouTube interview.
- They also describe using Claude Code to build a shared company “brain,” saving high‑value snippets (SQL, feedback) into GitHub for retrieval in future sessions Best practices talk.
🧠 Reasoning training: RLP, mid‑training RL, and data‑free loops
Busy research day on training recipes that improve reasoning with less data: NVIDIA RLP, Apple mid‑training RL, SALT, Socratic‑Zero, ALoRA, RL composition, and VLM self‑play.
Nvidia RLP rewards thinking before tokens, boosting accuracy with tiny data
A new pretraining objective from Nvidia treats short chains of thought as actions and rewards them only when they improve next‑token prediction, delivering a 35% average accuracy lift on a 12B hybrid model using ~0.125% of pretraining data paper overview.
- The reward measures additional information contributed by a thought (no human judges), sampled across multiple thoughts for stability paper overview.
- Training updates only the special "thought" tokens, with clipped objectives and a lagging baseline to prevent reward hacking paper overview.
- Gains persist after identical SFT and verifier‑reward phases versus equal token/compute baselines (math and science suites) paper overview.
Data‑free curriculum grows itself from 100 seeds
A teacher critiques a solver’s answers and spawns new, targeted problems; a generator learns the teacher’s distribution so the curriculum scales without human labels, driving large gains on math benchmarks from a tiny starting set paper thread.
- The loop alternates propose→test→refine, rewarding diverse difficulty rather than overfitting to narrow templates paper thread.
- Smaller models trained on the generated data match or beat larger proprietary systems on select reasoning tasks, indicating strong data efficiency paper thread.
Mid‑training RL learns reusable actions, improving code and math
Apple’s "Learning to Reason as Action Abstractions" adds a short RL phase between pretraining and post‑training to learn a compact set of reusable reasoning actions, raising code scores by +8 on HumanEval and +4 on MBPP; this complements Microsoft’s efficiency recipe reported earlier, following up on 3x efficiency which added thinking during pretraining paper overview.
- The method tags when to "think" and penalizes unnecessary steps so the model expends effort only when it helps paper overview.
- Framing reasoning as high‑level actions shortens search during RL, accelerating convergence with modest extra compute paper overview.
SALT: Compute‑efficient video SSL with a static teacher
Apple argues V‑JEPA’s moving teacher is unnecessary: train a teacher once with pixel reconstruction, then freeze it and train a student to predict its features on masked regions, yielding comparable or better downstream results with simpler tuning and budgeting paper brief.
- Decoupling sizes makes model selection easier (student loss mirrors accuracy) and avoids EMA collapse risks paper brief.
- Small teachers still produce strong students; fewer hyperparameters reduce iteration time while matching V‑JEPA‑2 on standard video tasks paper brief.
Share the right LoRA half to scale reasoning fine‑tunes
New evidence shows LoRA A matrices look similar mostly due to identical initialization, while B matrices carry learned task knowledge. Sharing only B reduces conflicts and slashes communication in federated setups, with better accuracy on hard tasks paper abstract.
- Fed‑ALoRA splits B for safe aggregation across clients with different ranks, avoiding gradient dilution seen when sharing A paper abstract.
- Reported savings: ~50% comms in same‑rank and ~75% in mixed‑rank settings, with balanced performance across math, commonsense, and NLP suites paper abstract.
Compact verifier with short chains reduces false flags
A cross‑disciplinary benchmark (math, physics, chemistry, biology) shows an 8B verifier trained with short reasoning traces and RL (with a length penalty) matches closed alternatives on tricky equivalences like unit changes and algebraic rewrites paper summary.
- Balanced training across correct and incorrect cases avoids label priors; the checker focuses on meaning equivalence, not string match paper summary.
- Provides a lightweight, scalable way to grade reasoning outputs in pipelines without hand‑crafted rules paper summary.
RL on easy chains transfers to longer compositions
Training with rewards on 2‑step synthetic transformations (function names obfuscated) induces a reusable pass‑through rule that lifts zero‑shot accuracy to ~30% on 3‑step and ~15% on 4‑step chains; plain rejection SFT barely helps paper summary.
- The learned composition rule also benefits external puzzles (e.g., Countdown arithmetic) when atomic skills exist, indicating cross‑task transfer paper summary.
- Rewarding structure rather than finals alone encourages the model to preserve intermediate results correctly across steps paper summary.
VLMs learn by playing “Who’s the spy” across images
Vision‑Zero sets up competitive, multi‑role games from any two images, using iterative self‑play plus RL with verifiable rewards (RLVR) to improve reasoning over charts, CLEVR scenes, and real photos without manual labels paper highlight Hugging Face paper page.
- Iterative self‑play policy optimization alternates between game generation and reward‑grounded updates to sustain gains over time paper highlight.
- The framework generalizes beyond narrow datasets by constructing games from arbitrary images, sidestepping curated supervision paper highlight.
⚙️ Runtime & training systems efficiency
Two substantial systems updates for speed and thermals: sub‑secondish trillion‑param weight transfers and in‑silicon microfluidic cooling.
Perplexity hits 1.3‑second trillion‑param weight transfer using RDMA point‑to‑point
1.3 seconds to swap a trillion‑parameter model’s weights across machines is now real. Perplexity’s inference engineers combined RDMA WRITE, a static transfer schedule, and pipelining to shrink update latency for Kimi‑K2 from multi‑seconds to near‑instant, unblocking tight RL post‑training loops at scale Perplexity research blog.
- Trillion‑param case study: 256 training GPUs (BF16) → 128 inference GPUs (FP8) in 1.3 s for Kimi‑K2, delivering ~10× faster cross‑machine updates Weight transfer details.
- Mechanism: RDMA point‑to‑point with static scheduling avoids collective bottlenecks; pipelined chunks keep NICs and NVLink fully utilized Perplexity research blog.
- Why it matters: Faster weight handoffs mean more frequent policy refreshes in RL post‑training and lower serving staleness without overprovisioning Weight transfer details.
Microsoft debuts in‑silicon microfluidic cooling; 65% lower temperature rise enables denser AI racks
Cooling moves inside the die: Microsoft etched micro‑channels directly into silicon and used AI‑designed branching (leaf‑vein‑like) flows to pull heat where it’s generated, cutting temperature rise by 65% vs. cold plates and enabling safe short overclocks and tighter rack density Cooling explainer.
- Thermal headroom: Liquid hits on‑die hotspots; system tolerates up to ~158°F while maintaining reliability, lifting burst performance and utilization Cooling explainer.
- Architecture enabler: In‑chip liquid paths make 3D die stacking more viable by preventing thermal throttling between layers Cooling explainer.
- Data center impact: Higher power density per rack lowers capex per token; Microsoft pairs this with hollow‑core fiber work to keep I/O from becoming the next bottleneck Cooling explainer.
🏗️ AI infra economics, capex & government ties
Fresh signals on capital flows and public partnerships: OpenAI valuation, Stargate chip & datacenter push in Korea, Japan gov use, and a Meta–CoreWeave capacity pact.
OpenAI completes $500B share sale as losses mount
OpenAI has closed an employee share sale that values the company at roughly $500 billion, even as the firm reports heavy burn to scale AI infrastructure and products. The raise extends runway while leadership guides to strong topline growth.
- Valuation: ~$500B via employee tender, per Bloomberg coverage Bloomberg headline.
- Financials: ~$4.3B H1’25 revenue, ~$7.8B operating loss, ~$2.5B cash burn; guiding to ~$13B 2025 revenue, with Microsoft rev‑share moving from ~20% to ~8% by 2030 (savings path) FT summary.
- Strategic lens: Validates investor appetite for frontier AI despite capex‑heavy model training/serving and rising power constraints FT summary.
Meta locks $14.2B GPU capacity from CoreWeave through 2031
Meta has signed a multi‑year agreement with CoreWeave worth up to $14.2B for GPU cloud capacity, signaling long‑term diversification of suppliers and demand visibility for AI training and inference—following up on Meta–CoreWeave deal announced yesterday.
- Term and scope: Capacity through 2031; broadens CoreWeave’s customer mix beyond Microsoft/OpenAI and helps Meta secure GB300‑class access Reuters coverage.
- Market signal: Reinforces multi‑vendor strategies and pre‑buys as scarcity persists for leading accelerators Reuters coverage.
Samsung and SK join OpenAI’s Stargate to scale AI capacity in Korea
OpenAI announced a strategic partnership with Samsung and SK under its Stargate initiative to expand critical AI infrastructure in Korea, spanning memory supply and potential data centers outside the Seoul Metro.
- Memory ramp: Samsung and SK plan to increase advanced DRAM wafer starts to ~900,000 per month to serve frontier model needs OpenAI Korea post.
- Data centers: OpenAI signed an MoU with the Korean Ministry of Science and ICT to explore sites beyond Seoul for next‑gen AI data centers OpenAI Korea post OpenAI blog post.
- Enterprise adoption: Samsung and SK will deploy ChatGPT Enterprise and the OpenAI API internally to improve workflows and innovation velocity OpenAI Korea post.
Brookfield CFO: AI buildout will need ~$7T in capital over the next wave
Brookfield Asset Management’s Hadley Peer Marshall estimates ~$7 trillion of capital will be required to stand up AI compute, power, and land—underscoring the scale of data center and grid expansion ahead.
- Commitments to date: Brookfield has already committed ~€20B in France and up to SEK 95B in Sweden over 10–15 years for AI‑adjacent infrastructure Bloomberg interview.
- Why it matters: Bundled land‑power‑building deals de‑risk hyperscaler projects and accelerate time‑to‑capacity amid tight power markets Bloomberg interview.
Japan’s Digital Agency pilots ‘Gennai’ with OpenAI for government use
Japan’s Digital Agency and OpenAI are collaborating on a government‑grade tool dubbed Gennai, with OpenAI also pursuing ISMAP certification to meet Japan’s public‑sector security bar.
- Government deployment: Gennai is aimed at government employees to improve public services while respecting guardrails from the Hiroshima AI Process OpenAI announcement OpenAI docs.
- Security posture: OpenAI says it will support secure deployments and seek ISMAP certification, a prerequisite for many Japanese government workloads OpenAI announcement.
Nvidia bankrolls the AI stack with OpenAI pact, CoreWeave backstops, and chip bets
A detailed look at Nvidia’s cash‑loop strategy shows it financing demand and supply across the stack—from a staged OpenAI investment to capacity guarantees—tightening its grip on AI infrastructure economics.
- OpenAI buildout: Reports describe up to ~$100B staged investment to help construct multi‑site 10GW data centers under the Stargate umbrella The Information analysis.
- Capacity safety net: $6.3B CoreWeave backstop for unsold GPU time; ~$700M into Nscale; ~$5B stake in Intel (co‑developed chips) The Information analysis.
- Demand flywheel: Nvidia renting back GPUs (e.g., ~$1.5B multi‑year) to run its own research, reinforcing utilization and recurring demand The Information analysis.
OpenRouter offers 1M free BYOK requests/month, resetting inference cost curves
Aggregator economics are shifting: OpenRouter now grants all customers 1,000,000 free Bring‑Your‑Own‑Key requests per month, letting teams burn existing provider credits while retaining failover and routing controls.
- Pricing change: Automatic for new and existing BYOK users; overage at 5% handling fee on additional requests Pricing announcement OpenRouter post.
- Operational upside: Organizations can pool negotiated rates/credits, keep spend controls, and route across 60+ providers without vendor lock‑in Feature follow‑up.
🤖 Embodied AI: world models, control, and sim stacks
Notable movement on training agents in imagination and preserving VLM skills during control learning; plus a new physics engine path to sim‑to‑real.
Dreamer 4 mines diamonds from 2,541h video using ~100× less data
Trained purely in a fast video world model from ~2,541 hours of Minecraft, DeepMind’s Dreamer 4 learns long‑horizon behavior and can mine diamonds offline, requiring about 100× less labeled interaction than prior agents paper summary.
- World‑model learning keeps sampling cheap while sustaining accurate long rollouts, enabling 20k+ action chains paper summary.
- See the technical report for architecture, tokenizer, shortcut forcing and offline→policy transfer details ArXiv paper.
NVIDIA debuts Newton physics engine and Cosmos Reason to speed sim‑to‑real
NVIDIA introduced Newton, a GPU‑accelerated physics engine built on OpenUSD and Warp that plugs into MuJoCo Playground and Isaac Lab, plus GR00T N1.6 with the open 7B ‘Cosmos Reason’ VLM for physical common‑sense planning blog overview. Following up on safety framework for embodied agents, this pushes the sim stack toward safer, faster transfer.
- Isaac Lab 2.3 (early developer build) adds whole‑body control, improved locomotion/imitation, and broader teleop (Meta Quest, Manus) blog overview.
- OpenUSD scene consistency reduces asset duplication and friction in multi‑tool workflows; Cosmos Reason helps turn fuzzy instructions into step‑wise plans blog overview.
VLM2VLA: Preserve VLM skills while learning robot control via actions‑as‑language
Instead of full fine‑tuning that erases perception, VLM2VLA aligns robot actions to natural language and uses LoRA to keep a VLM’s general capabilities intact while learning control—mitigating catastrophic forgetting in VLAs project brief.
- Representing actions as text makes robot data match the VLM pretraining distribution, unlocking parameter‑efficient adapters project brief.
- The team reports strong zero‑shot transfer and sustained VQA performance alongside real‑robot results; see setup and demos on the site project page.
Vision‑Zero: Gamified self‑play scales VLM reasoning without labels
Vision‑Zero trains VLMs through competitive image games (“Who is the Spy”‑style), generating curriculum and rewards from arbitrary image pairs to improve strategic reasoning without human annotations paper page.
- Iterative self‑play alternates with RL using verifiable rewards, sustaining gains across charts, CLEVR‑like scenes, and real images paper page.
UniVid unifies video generation and understanding with stronger prompt faithfulness
UniVid connects a multimodal LLM to a video denoiser via a lightweight adapter to unify video understanding and generation, emphasizing prompt faithfulness with an early‑focus attention schedule paper note.
- Reports a +2.2% lift on VBench‑Long and gains on two video QA suites at 7B, while caching keyframe features to keep inference efficient ArXiv paper.
📊 Leaderboards & eval snapshots
New placements across arenas and bespoke tests. Mostly media and efficiency metrics today; fewer agent terminal evals than earlier this week.
Kling 2.5 Turbo tops AI video arenas at lower cost
Kuaishou’s Kling 2.5 Turbo jumped to #1 on Artificial Analysis for both text‑to‑video and image‑to‑video, edging out Google’s Veo 3 and Luma’s Ray 3 while undercutting them on price leaderboard post. The shift comes one day after Luma Ray 3 climbed to #2, showing a rapidly moving pecking order in video models Ray 3 rank #2.
- Leaderboard shows Kling 2.5 Turbo at ~1,252 ELO on Text‑to‑Video with 5–10s at up to 1080p leaderboard post.
- Price: ~$4.20/min on fal vs Hailuo 02 Pro ~$4.90/min and Seedance 1.0 ~$7.32/min (quality cited as superior at lower cost) leaderboard post.
RTEB adds private splits to MTEB to measure real retrieval generalization
Hugging Face introduced RTEB, a multilingual retrieval benchmark with hidden, private test sets embedded in MTEB to curb overfitting and surface true generalization gaps benchmark blog. It spans 20 languages and multiple domains (general, legal, healthcare, code) and is already live.
- Blog outlines hybrid open/private evaluation so models can’t merely memorize public sets blog post.
- Analysis threads show how public vs private deltas reveal over‑tuned systems analysis thread.
- Explore scores and submit results on the live board RTEB leaderboard.
Anthropic reports a 10× drop in sycophancy for Sonnet 4.5
Anthropic’s system card data shows Sonnet 4.5 reduces needless agreement (“sycophancy”) to 6.5% on hand‑written prompts vs 79% for Sonnet 4; on synthetic prompts it falls to 11% vs 31–46% for earlier models sycophancy chart. This should cut flattering but wrong outputs in judgment‑heavy workflows.
- Chart compares Sonnet 4, Opus 4/4.1, and Sonnet 4.5 across both handwritten and synthetic evals, highlighting the magnitude of the drop sycophancy chart.
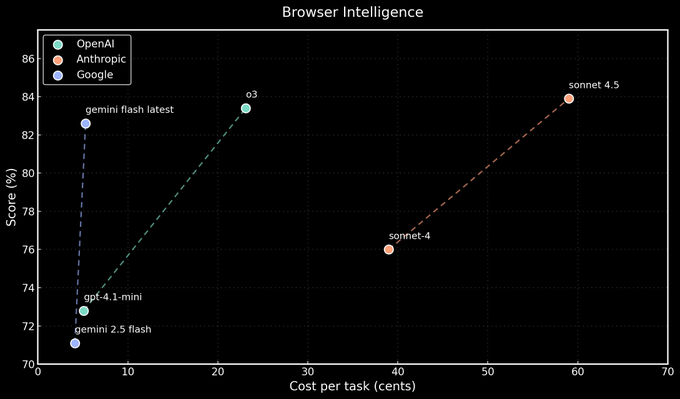
Browser sprint: Gemini Flash finishes steps ~2–3× faster than o3 and Sonnet 4.5
In a head‑to‑head browser task sprint, Gemini Flash completed a step in about 7.7 seconds versus ~12.1 seconds for o3 and ~21 seconds for Claude Sonnet 4.5, with similar accuracy across models browser chart. The scatter also suggests lower cost per task for Flash at comparable scores.
- Plot shows accuracy vs cost (cents per task) with Flash at the efficient frontier, while o3 and Sonnet 4.5 cluster at higher cost envelopes browser chart.
Claude Sonnet 4.5 Thinking 32k lands in LMSYS Arena
Claude Sonnet 4.5 Thinking 32k is now selectable in Chatbot Arena, opening it up to community voting and head‑to‑head matchups that will determine its standing. See the announcement and model picker, and cast votes to shape the ranking Arena update, and try it live on the site Arena site.
- Voting‑driven placement means early usage can materially move the leaderboard Arena update.
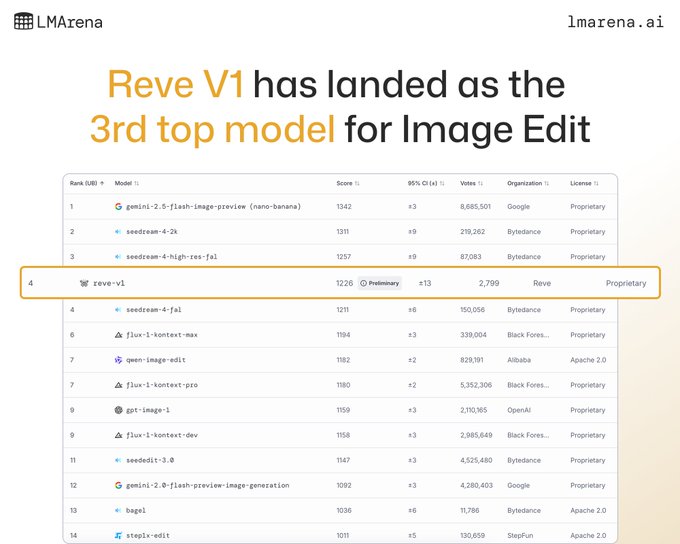
Reve V1 debuts at #3 on Image Edit Arena
Reve AI’s first editing model, Reve V1, entered the Artificial Analysis Image Edit leaderboard at #3, behind Gemini‑2.5‑Flash‑Image (Nano Banana) and Bytedance’s Seedream 4 arena note. It supports single and multi‑image edits, including combining multiple reference images into one output model overview.
- Access options: Web app (free daily limit), $20/month Pro, and a beta API priced at ~$40/1k images model overview.
- Compare results and vote in the public arena Image arena.
🔍 Retrieval & private‑split evals
Evaluation evolves for search/embedding systems with private splits to curb overfitting; a new search stack opens in beta with OSS credits.
Hugging Face launches RTEB to measure real retrieval generalization with private splits
RTEB adds private, held‑out test sets to the MTEB family so embedding/search systems can’t overfit public corpora while still reporting comparable scores across 20 languages. See the launch write‑up for methodology and examples in the official post Hugging Face blog, and author follow‑ups explaining how to read public vs private gaps author notes.
- Private splits: Hidden test data evaluates zero‑leak generalization and penalizes test‑set tuning benchmark blog.
- Multilingual scope: 20 languages, with domains spanning general, legal, healthcare, code and more blog follow‑up.
- Leaderboard live: Results are already flowing to the dedicated board; compare public vs private differentials to spot overfit Leaderboard page.
- Practical takeaway: Expect rank reshuffles; models that popped on open sets but generalize poorly will drop, while robust systems should hold steady author guidance.
Mixedbread Search enters beta with OSS‑free tier for production semantic search
Mixedbread is opening its production semantic search stack in beta and pledging free usage for open‑source projects’ docs, MCP tools, and similar use cases, lowering the barrier to ship high‑quality retrieval in real apps beta announcement, open source offer. Early adopters report strong relevance on real docs, hinting at a credible alternative to DIY RAG backends case study.
- Production focus: A managed search layer for hybrid retrieval so teams can ship without maintaining their own indexers beta announcement.
- Community boost: Open‑source projects can power documentation search and agent tool discovery at no cost open source offer.
- In‑the‑wild signal: Effect’s docs have been running on Mixedbread‑powered search, citing improved outcomes over prior setups case study.
🎬 Sora 2 in the wild: physics, UX and feed dynamics
Continuation of yesterday’s launch coverage with hands‑on tests and app behavior (not the launch itself). Excludes Tinker. Focus on failure cases, diagnostics, invites, and feed mechanics.
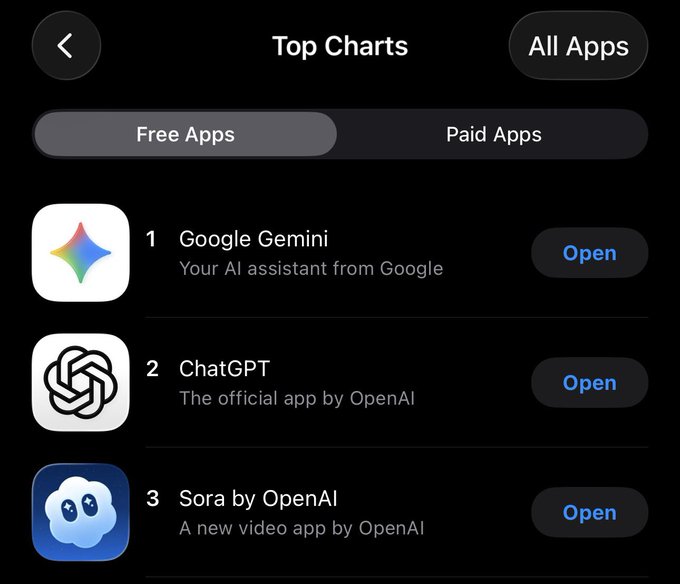
Sora app climbs to #3 on iOS Free Apps as invites scale; staged Pro rollout continues
Trajectory is steep: Sora ranks #3 among free iOS apps in the U.S., while OpenAI signals a larger invite wave with adjusted daily gen caps as more users come online—following invite rollout from yesterday’s debut.
- App Store chart: Gemini #1, ChatGPT #2, Sora #3 (Free Apps) top charts screenshot.
- “We’re scaling‑up invites tomorrow; gens/day will decrease to support volume” invites scaling note.
- Docs indicate "Sora 2 is now available to all ChatGPT Pro users" but access is still being enabled gradually; Sora 2 Pro and API remain forthcoming pro availability doc, and OpenAI help center.
- Broad codes are circulating (e.g., 10k code drops), reflecting widening access pressure testing the backend 10k code post, invite code post.
Community stress tests expose Sora 2 gaps in counting, speech overlap, and audio sync
Hands‑on probes are mapping early failure modes. Sora 2 stumbles on basic temporal reasoning (finger counting), struggles with simultaneous speakers, and sometimes desynchronizes narration and visuals.
- Finger counting 1→10 goes off the rails despite a simple prompt counting test.
- Two people talking at once yields garbled results that miss the intent overlapping speech test.
- A “Happy Birthday” chorus matches the tune but morphs the lyrics, signaling brittle audio‑text alignment birthday song test.
- Physics/causality illusions (e.g., water staying in an inverted glass) are inconsistent across seeds, helpful for edge‑case triage rather than production physics trick test.
- You can reproduce the counting test path via the shared test thread entry point test entry point.
Personalization signals and cameo drafts spark UX and safety debate
Sora reportedly tailors outputs based on IP geolocation and past ChatGPT history, while Cameos bring consented deepfakes—and a safety twist: the cameo owner can see drafts where their likeness was used even if the video wasn’t published.
- Tech press highlights feed personalization via location and prior chats, and documents the flood of consented Sam Altman cameos showcasing the mechanic’s reach TechCrunch summary.
- Cameo owners can review unpublished drafts that used their face, helping detect misuse or low‑quality remixes early cameo draft note, drafts view link.
- Net: rich personalization boosts engagement but raises expectations for transparency and granular privacy controls for both viewers and cameo creators.
Engagement hacks flood Sora feed while creators call out missing Sora‑1 features
Early feed dynamics skew toward virality tricks (e.g., "double‑tap for emoji" easter eggs) as power users note the absence of Sora‑1 power tools like storyboards, recuts, and extend—making serious production harder on day one.
- Screens show multiple "double‑tap" bait clips dominating For You timelines feed screenshots.
- Observers argue the app is optimized for shareability, not structured editing; they also note limits like one‑at‑a‑time generations strategy take.
- Users report Sora 1 workflows (storyboards/recuts/extend) aren’t yet present; several will "wait for Sora 2 Pro" for real work feature gaps note.
- Export of videos that aren’t yours appears blocked, keeping virality in‑app vs. flowing to other platforms export limits note.
Sora 2 exposes a 2×2 diagnostic grid (depth, heat, edges, segmentation) to debug scene understanding
Beyond pure video output, Sora 2 can render interpretable overlays—depth map, heat map, edge detection, and semantic segmentation—in a single 2×2 frame, giving engineers a lens into what the model "saw" and emphasized per frame diagnostics grid demo.
- Useful for prompt‑response forensics (e.g., whether failures stem from geometry, salience, or labeling).
- A lightweight way to build regression suites around perception rather than final pixels.
🗣️ Multilingual TTS & live translation
Hume Octave 2 lands with multi‑language, latency and cost gains; ElevenLabs continues studio‑grade dubbing distribution.
Hume Octave 2 lands 11 languages, big speed/cost cuts, and a “mini” model for live translation
Hume released Octave 2, a multilingual TTS upgrade that speaks 11 languages with ~40% lower latency and ~50% lower cost vs Octave 1, plus new 15‑second voice conversion and phoneme‑level editing; the companion EVI 4 mini is tuned for live translation and conversational use feature brief, product page.
- Languages: English, Japanese, Korean, Spanish, French, Portuguese, Italian, German, Russian, Hindi, Arabic (11 total) feature brief
- New capabilities: 15‑sec voice conversion, multi‑speaker conversations, and phoneme editing (precise pronunciation control) feature brief
- Live translation: EVI 4 mini is a lightweight, low‑latency speech‑to‑speech setup for real‑time translations and chats product page
- Price/latency: ~50% cheaper and ~40% faster than v1; Hume is running a limited promotion for October feature brief
- Early usability: Testers report markedly improved cross‑language accent control (e.g., German) in practical use beta feedback
Studio‑grade multilingual dubbing goes mainstream as ElevenLabs distributes Lex Fridman × Pavel Durov in four languages
ElevenLabs’ managed dubbing service translated a Lex Fridman conversation with Pavel Durov into Hindi, French, Ukrainian, and Russian, underscoring that professional multi‑language releases are becoming turnkey for creators and studios dubbing announcement, and the service positions itself for full‑stack distribution and post‑editing workflows Eleven Productions.
🛡️ Safety, policy & trust signals
Policy and trust items clustered around avatars, IP, agent controls, and teen safeguards. Excludes Sora launch mechanics and Tinker.
OpenEdison launches an OSS ‘agent firewall’ to block data exfiltration even under jailbreaks
OpenEdison debuts as a deterministic policy layer for MCP/tool‑using agents, tracking per‑session tool use and blocking write actions when a “lethal trifecta” is detected (private data + untrusted content + external send) project brief, security diagram.
- One‑command start and docs are live, with code available for audit and contribution GitHub repo.
Sora app behavior raises transparency questions on personalization inputs
Users observe Sora tailoring outputs using IP geolocation and prior ChatGPT chats (e.g., implicitly picking local teams/landmarks), which could surprise people who didn’t expect those signals to shape results privacy analysis.
- Cameos remain consent‑gated with identity checks and explicit audience scopes, but broader personalization cues merit clearer disclosure to users.
Sora Cameos now expose unpublished drafts that use your face
Sora’s cameo workflow surfaces any unpublished drafts where someone used your likeness, giving you a built‑in way to spot and clean up misuse before it ships privacy note, and there’s a direct route to review such drafts if your cameo is enabled how to view drafts.
- Permissions matter: cameo access can be set to Only me, Approved, Mutuals, or Everyone (with liveness checks), which changes who can legally render you in clips privacy analysis.
Anthropic highlights steep drop in Sonnet 4.5 ‘sycophancy’ vs earlier models
Anthropic’s system card chart shows Sonnet 4.5 reduces needless agreement to 6.5% on hand‑written probes, down from ~79% in Sonnet 4; on synthetic probes it’s ~11% vs ~46%+ for Sonnet 4—useful for trust, safety, and compliance workflows that penalize false agreement sycophancy chart.
- Lower sycophancy should mean fewer “you’re right” answers when the user is wrong, improving moderation and regulated‑domain reliability.
Character.AI removes Disney IP chatbots after studio warning
Character.AI pulled Elsa, Darth Vader and other Disney‑themed bots following a rights‑holder warning—another clear signal that studios plan to actively police generative platforms around iconic characters Disney takedown.
- Expect spillover: the same IP scrutiny will pressure video generators and remix features that emulate protected styles and characters.
ChatGPT adds Parental Controls to iOS and Android apps
Parental Controls—linking parent/teen accounts, usage limits, and content filters—are now live on ChatGPT mobile, following up on Parental controls web launch mobile screenshots.
- The mobile UI exposes family management and teen safeguards directly in settings, strengthening age‑appropriate defaults.