Anthropic locks ~1M Google TPUs – capacity tops 1 GW
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic just turned rumor into steel: it’s locking up roughly 1M Google TPUs with well over 1 GW slated to come online in 2026. The spend is “tens of billions” and it isn’t just about training; Anthropic says it chose TPUs for price‑performance on serving too, which is where margins go to die if you pick the wrong silicon. This is the rare compute deal that actually changes a roadmap: guaranteed throughput means shorter training queues and fewer rate‑limit headaches for customers next year.
Google is pushing Ironwood (TPU v7) as the serving‑first piece of the puzzle, and that tracks with Anthropic’s pitch to enterprise buyers who care more about steady‑state token costs than one‑off megatrain runs. Demand doesn’t look made‑up either—company commentary pegs annualized revenue near $7B, which explains why they’re pre‑buying capacity instead of praying for cancellations on GPU waitlists. Still, Anthropic is careful to say it’s staying multi‑cloud and multi‑silicon, with Amazon Trainium and NVIDIA GPUs in the mix so workloads can land where unit economics and latency actually make sense.
Net: this is a compute hedge and a serving bet wrapped into one, and it puts real pressure on rivals to show similar 2026‑dated capacity, not just MOUs.
Feature Spotlight
Feature: Anthropic × Google secure ~1M TPUs, >1 GW by 2026
Anthropic locks a multi‑year, multi‑billion Google Cloud deal for up to 1M TPUs (>1 GW by 2026), materially expanding Claude training and serving capacity and reshaping compute economics for enterprise AI.
Cross-account confirmation that Anthropic will massively expand on Google Cloud TPUs—tens of billions in spend—to scale Claude training/inference. Multiple tweets cite the 1M TPU figure, >1 GW capacity online in 2026, and current enterprise traction.
Jump to Feature: Anthropic × Google secure ~1M TPUs, >1 GW by 2026 topicsTable of Contents
⚡ Feature: Anthropic × Google secure ~1M TPUs, >1 GW by 2026
Cross-account confirmation that Anthropic will massively expand on Google Cloud TPUs—tens of billions in spend—to scale Claude training/inference. Multiple tweets cite the 1M TPU figure, >1 GW capacity online in 2026, and current enterprise traction.
Anthropic locks up ~1M Google TPUs and >1 GW for 2026 in a deal worth tens of billions
Anthropic and Google confirmed a massive TPU expansion—approximately one million chips and well over 1 GW of capacity coming online in 2026—to scale Claude training and serving, with spend described as “tens of billions.” The company frames the move as price‑performance driven on TPUs, timed to accelerating demand. Following up on compute pact, which noted talks and early signals, today’s posts quantify capacity and timing, and reiterate why TPUs fit Anthropic’s cost curve Deal announcement, Anthropic blog post, Press confirmation, Google press page.
For AI leads, the headline is concrete: guaranteed throughput for 2026 (training queues and serving readiness) and a visible hedge against GPU scarcity—without abandoning other stacks.
Anthropic demand picture: 300k+ business customers, large accounts up ~7× YoY, revenue near $7B
Anthropic says it now serves 300,000+ businesses with nearly 7× growth in large accounts over the past year; commentary adds annualized revenue approaching $7B and Claude Code surpassing a $500M run‑rate within months—helping justify the TPU scale‑up Anthropic blog post, Company summary, Analysis thread.
Implication for buyers: capacity won’t just shorten waitlists—it should stabilize SLAs and rate limits as onboarding accelerates.
Ironwood, Google’s 7th‑gen TPU for high‑throughput inference, is central to Anthropic’s plan
Google highlights Ironwood (TPU v7) as a serving‑first design that lowers cost per token via 256‑chip pods and 9,216‑chip superpods, matching Anthropic’s need to scale inference economically alongside training Google press page. Anthropic’s own post ties the expansion to observed TPU price‑performance over multiple generations, reinforcing why this capacity lines up for 2026 Anthropic blog post.
For platform teams, this signals practical gains: cheaper steady‑state throughput for enterprise traffic, not just big‑bang training windows.
Despite the TPU megadeal, Anthropic reiterates a multi‑cloud, multi‑silicon strategy
Alongside the Google TPU expansion, Anthropic stresses it will continue training and serving across Amazon Trainium and NVIDIA GPUs; Amazon remains a core training partner via Project Rainier, tempering vendor lock‑in and letting workloads land where unit economics and latency fit best Anthropic blog post, Analysis thread.
For architects, this means portability pressures remain: plan for heterogeneous kernels, model builds, and orchestration that can shift between TPU, GPU, and ASIC targets as prices and queues move.
🖥️ OpenAI buys Sky: screen-aware Mac actions
OpenAI acquired Software Applications Inc. (Sky), an Apple‑veteran team building a Mac, screen‑aware natural language interface. Excludes the Anthropic–Google compute pact (covered in Feature). Focus here is OS‑level agent UX and M&A signal.
OpenAI buys Sky to add screen‑aware Mac actions to ChatGPT
OpenAI acquired Software Applications Inc. (Sky), a Mac overlay agent that understands what’s on screen and can take actions through native apps; the team is joining to bring these capabilities into ChatGPT, with terms undisclosed OpenAI blog, and the acquisition confirmed across community posts acquisition post, announcement link.
OpenAI frames the deal as moving from “answers” to helping users get things done on macOS, implying deeper OS‑level permissions, context, and action execution beyond web automations OpenAI blog.
Signal in the noise: Sky shows OpenAI’s platform push into OS‑level agents
Practitioner briefs note OpenAI has been on an acquisitions streak and describe Sky’s product as a floating desktop agent that understands the active window and can trigger actions in local apps like Calendar, Messages, Safari, Finder and Mail—an explicit platform move beyond web‑only automation feature explainer. Coupled with OpenAI’s own integration plan, this suggests a near‑term consolidation of agent UX at the OS layer to win trust, control latencies, and harden permissions around sensitive actions OpenAI blog.
Workflow/Shortcuts alumni behind Sky bring deep macOS automation chops to OpenAI
Sky’s founders previously built Workflow (acquired by Apple and turned into Shortcuts), and community posts say the team had a summer release queued before the acquisition—an overlay agent that could read the screen and drive Mac apps—highlighting rare, low‑level macOS automation expertise now in OpenAI’s stack prelaunch details, product description, community recap. This background reduces integration risk and accelerates building a reliable, permissions‑aware OS agent versus purely browser‑bound automation.
OpenAI positions Sky as a shift from chat to action—and discloses Altman‑linked passive investment
In its note, OpenAI emphasizes Sky will help “get things done” on macOS—not just respond to prompts—while stating all team members are joining OpenAI to deliver these capabilities at scale OpenAI blog. The post also discloses that a fund associated with Sam Altman held a passive Sky investment and that independent Transaction/Audit Committees approved the deal, a governance detail leaders will track as OS‑level agents gain wider powers OpenAI blog.
What a screen‑aware Mac agent unlocks for developers and IT
A Sky‑style agent can reason over on‑screen context and invoke native intents—bridging ambiguous dialog (“what’s on my screen?”) with deterministic app actions and user approvals. Community summaries cite concrete app domains Sky targeted (Calendar/Messages/Notes/Safari/Finder/Mail) and a desktop overlay UX, signaling new integration surfaces for secure, auditable automations and policy controls on macOS fleets feature explainer, product description.
🎬 Cinematic AI video goes open: LTX‑2 arrives
Lightricks’ LTX‑2 dominates today’s gen‑media chatter: native 4K up to 50 fps with synchronized audio, 10–15s sequences, and day‑0 availability via fal/Replicate; weights to open later this year. Excludes Genie world‑model news (separate category).
LTX‑2 debuts with native 4K, up to 50 fps, and synced audio; open weights coming later this year
Lightricks’ LTX‑2 arrives as a cinematic‑grade AI video engine: native 4K output, up to 50 fps, synchronized audio/dialog, and ~10–15‑second sequences designed for real creative workflows, with API‑readiness today and weights slated to open later this year capability highlights, weights plan. Early hands‑on testers are positioning it as a step‑change over prior demo‑grade models, citing resolution fidelity and motion smoothness aligned to professional pipelines review thread.
fal ships day‑0 LTX‑2 APIs (Fast/Pro) for text→video and image→video up to 4K with per‑second pricing
fal made LTX‑2 available on day one with Fast and Pro endpoints for both text→video and image→video at 1080p, 1440p, and 4K, supporting synchronized audio and up to 50 fps; usage is metered per‑second with published rate tiers on each model page availability brief, Text to video fast, Text to video pro, Image to video fast, Image to video pro.
In practice, this gives teams an immediate path to prototype and scale high‑fidelity clips via API without managing custom serving, while preserving a clean upgrade track to Pro for higher quality runs.
Replicate lists LTX‑2 Fast and Pro with prompt guidelines and example workflows
Replicate now hosts lightricks/ltx‑2‑fast and lightricks/ltx‑2‑pro, complete with prompt‑writing guidance, example pipelines, and API playgrounds to speed adoption into existing tooling hosting update, Replicate fast model, Replicate pro model. For AI engineers, this lowers integration friction (one‑click deploys, consistent SDKs) while enabling side‑by‑side Fast/Pro comparisons for cost–quality tuning in production.
Practitioners call LTX‑2 a new bar; native 4K motion and texture beat upscaled outputs
Early testers report a clear perceptual gap between LTX‑2’s native 4K and prior upscaled pipelines, citing sharper textures, steadier motion, and coherent audio that shortens post‑production cycles review thread, native vs upscaled. For teams evaluating model swaps, expect fewer artifacts in fast action and dialogue‑driven scenes, plus simpler editorial passes when cutting short spots and trailers.
🧭 Agentic browsers: Edge Copilot Mode and fall updates
Microsoft’s Edge adds Copilot Mode with Actions for on‑page navigation, tab management, and history context. Copilot Sessions ‘Fall release’ teases Mico/Clippy, groups, and health features. Excludes OpenAI Atlas (prior day) to keep today focused on Edge updates.
Edge adds Copilot Mode with Actions, autonomy levels, and opt‑in Page Context
Microsoft is turning Edge into an agentic browser: Copilot Mode can navigate pages, execute multi‑step Actions (unsubscribe, book, scroll to sections), manage tabs, and draw on browsing history if users enable Page Context. Hands‑on reports show three autonomy settings (light, balanced, strict) and a Preview toggle to watch or background‑run tasks feature brief, how to enable, deep dive thread.
- Actions sequences and tool use are visible, with suggested flows for common chores and guardrails around history access actions samples.
Copilot Sessions Fall update brings Groups, Mico/Clippy, and cross‑app memory
At Copilot Sessions, Microsoft previewed a broad Fall update: Groups for up to 32 participants, a long‑term memory that spans apps, and a more expressive Mico avatar—with an Easter‑egg return of Clippy. Early notes also highlight health Q&A grounded in vetted sources, stronger privacy opt‑ins, and a staged U.S. rollout before expanding feature collage, event stream, feature recap.
Following up on Feature lineup that teased 12 areas, today’s session put numbers (32‑user Groups) and concrete capabilities on the roadmap while reinforcing an “AI agentic browser” framing across Edge and Copilot.
✏️ Ship faster in AI Studio: Annotate & vibe coding
Google AI Studio adds Annotate Mode: draw on your running app UI and have Gemini implement changes. Builders showcase ‘vibe coding’ flows with prebuilt components and grounded Search. Strong traction signals (traffic spike) surfaced today.
Google AI Studio adds Annotate Mode for point‑and‑edit coding
Google AI Studio now lets you draw directly on your app preview and have Gemini implement the change in code, collapsing review→spec→commit loops into a single pass. The update ships inside the Build experience and supports fine‑grained tweaks (e.g., animations) without leaving the IDE-like canvas feature brief, announcement, AI Studio build, annotate details.
For teams, this makes UI polish and stakeholder feedback far more executable—non‑developers can mark targets in context while engineers keep a clean diff trail. Early users report the feature feels natural in the new AI‑assisted flow of “point, narrate intent, ship” feature mention.
Vibe coding in AI Studio: NL intents to runnable apps with Search grounding
Creators showcased “vibe coding” in AI Studio: pick prebuilt components (speech, image analysis), describe the app in natural language, and get runnable code plus a live preview grounded in Google Search. The demo walks through highlight‑and‑edit cycles, showing Gemini wiring UI changes and data calls end‑to‑end video demo, YouTube demo.
Beyond prototyping speed, Search grounding adds production‑like behavior (fresh results/citations) to early builds, reducing the gap between demo logic and real integrations feature brief.
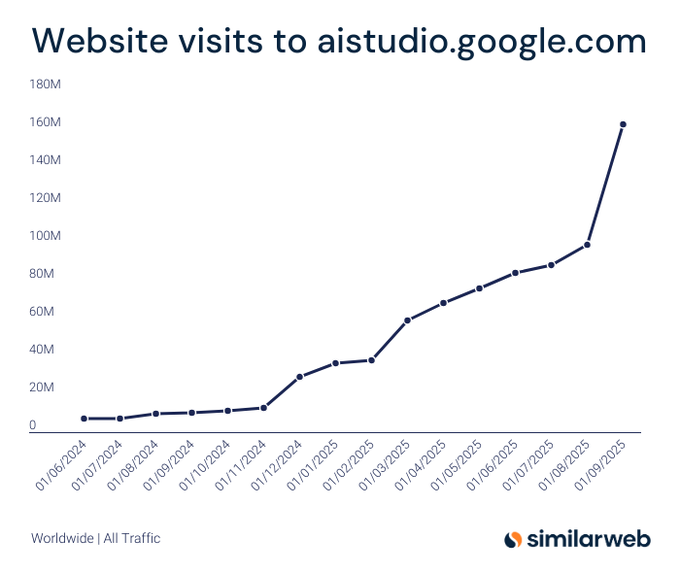
AI Studio traffic jumps 64% in September, topping ~160M monthly visits
AI Studio’s site traffic spiked ~64% in September to ~160M+ visits, its biggest surge since the Gemini 2 cycle—evidence that annotate‑and‑vibe coding workflows are resonating with builders traffic chart. Following up on traffic surge that highlighted the 160M+ milestone, today’s chart underscores momentum rather than a one‑off bump, suggesting sustained interest as new Build features roll out.
🚀 Agent infra for builders: Vercel Agent, WDK, Marketplace
Vercel Ship AI day brings a cohesive agent stack: Vercel Agent (code review + investigations), Workflow Development Kit (‘use workflow’ durability), a Marketplace for agents/services, and zero‑config backends for AI apps.
Vercel Agent launches in public beta with AI code review and incident investigations
Vercel introduced an AI teammate that performs PR reviews by running simulated builds in a Sandbox and triggers AI-led investigations when telemetry flags anomalies, now available in Public Beta on AI Cloud product blog, and documented in full on the launch post Vercel blog. This slots into a broader Ship AI push aimed at making agentic workflows first‑class for app teams.
Workflow Development Kit makes reliability “just code” with durable, resumable steps
Vercel’s WDK adds a use workflow primitive that turns async functions into durable workflows that pause, resume, and persist automatically; each use step is isolated, retried on failure, and state‑replayed across deploys feature brief, with deeper details in the launch write‑up Vercel blog. Early builders immediately pressed for controls like cancellation, idempotency keys, handling code changes, and rollbacks—useful signals for WDK ergonomics and docs to address next dev questions, follow‑up questions.
Vercel Marketplace debuts with agent apps and AI infrastructure services, unified billing
Vercel opened a marketplace that ships plug‑in “agents” (e.g., CodeRabbit, Corridor, Sourcery) and “services” (Autonoma, Braintrust, Browser Use, Chatbase, Mixedbread and more) behind one install and bill marketplace blog, with partners announcing day‑one availability coderabbit launch, mixedbread launch. The intent is to reduce the integration sprawl for teams adopting agentic patterns while keeping observability centralized.
AI SDK 6 (beta) unifies agent abstraction with human‑in‑the‑loop tool approvals and image editing
Vercel’s AI SDK 6 beta stabilizes an agent abstraction layer, adds tool‑execution approval for human‑in‑the‑loop control, and extends image editing support—positioning the SDK as the default interface across models and providers for agent apps sdk beta image. These capabilities complement Vercel Agent and WDK so teams can define logic once and run it reliably on AI Cloud.
Zero‑config backends on Vercel AI Cloud bring framework‑defined infra and unified observability
Vercel AI Cloud now provisions and scales backends from your chosen framework with no extra YAML or Docker, adds per‑route scaling, and centralizes logs, traces, and metrics so AI apps get a production‑grade control plane out of the box backends blog, Vercel blog. For agent builders, this pairs with the AI stack to simplify deploying tool‑rich, stateful services without bespoke infra plumbing.
🧩 Enterprise collaboration & context: projects, knowledge, memory
Teams features dominated: OpenAI expands Shared Projects (with per‑tier limits) and ships Company Knowledge with connectors/citations; Anthropic rolls out project‑scoped Memory to Max/Pro with incognito chats. Excludes OpenAI’s Sky M&A (separate).
Company Knowledge arrives for Business, Enterprise, and Edu with GPT‑5 search across Slack/SharePoint/Drive/GitHub and citations
ChatGPT can now pull trusted answers from your organization’s tools—Slack, SharePoint, Google Drive, GitHub—with a GPT‑5–based model that searches across sources and cites where each answer came from, now rolling out to Business, Enterprise, and Edu feature screenshot, OpenAI blog.
New connectors were added alongside the rollout (e.g., Asana, GitLab Issues, ClickUp), and admins can review the Business release notes for setup details and visibility controls business notes, and Business release notes. See OpenAI’s overview for capabilities and citation behavior OpenAI blog.
OpenAI rolls out Shared Projects to Free, Plus, and Pro with tier caps and project-only memory
OpenAI is expanding Shared Projects to all ChatGPT tiers so teams can work from shared chats, files, and instructions, with project‑scoped memory enabled automatically on shared projects feature post, rollout summary.
- Tier limits: Free supports up to 5 files and 5 collaborators, Plus/Go up to 25 files and 10 collaborators, and Pro up to 40 files and 100 collaborators, per OpenAI’s notes release summary, and OpenAI release notes.
Anthropic ships project‑scoped Memory to Max and starts Pro rollout with incognito chats and safety guardrails
Anthropic enabled Memory for Max customers and will roll it out to Pro over the next two weeks; each project keeps its own memory that users can view/edit, with an incognito chat mode that avoids saving, following internal safety testing rollout note, memory page.
Practitioners highlight project‑scoped memory as a practical way to prevent cross‑pollination between unrelated workstreams user sentiment, with full details and controls in Anthropic’s announcement Anthropic memory page.
📄 Document AI momentum: LightOnOCR‑1B and tooling
OCR/VLM remained hot: LightOnOCR‑1B debuts as a fast, end‑to‑end domain‑tunable model; vLLM adds OCR model support; applied guides explain deployment and ‘optical compression’ angles. Mostly practical releases and how‑tos today.
LightOnOCR‑1B debuts: fast, end‑to‑end OCR with SOTA-class quality; training data release teased
LightOn unveiled LightOnOCR‑1B, an end‑to‑end OCR/VLM that targets state‑of‑the‑art accuracy while running significantly faster than recent releases, and says a curated training dataset will be released soon. The team details design choices (e.g., teacher size, resolution, domain adaptation) and shipped ready‑to‑run models, including vLLM availability. See the announcement and technical blog for architecture and ablation results release thread, with more notes that the dataset is “coming soon” follow‑up note, and the model and collection pages for immediate use Hugging Face blog, Models collection.
Baseten explains DeepSeek‑OCR’s “optical compression” and ships a 10‑minute deploy path
Baseten breaks down why DeepSeek‑OCR’s image‑native pipelines are dramatically cheaper and faster (compressing text visually before decoding) and provides a ready template to stand up inference in under ten minutes. This adds actionable ops guidance following up on vLLM support and library‑scale conversions reported yesterday, with concrete throughput/cost angles for production teams blog summary, Baseten blog, and an additional pointer from the team blog pointer.
Hugging Face updates open OCR model comparison with Chandra, OlmOCR‑2, Qwen3‑VL and averaged scores
Hugging Face refreshed its applied guide and comparison for open OCR/VLMs, adding Chandra, OlmOCR‑2 and Qwen3‑VL plus an averaged OlmOCR score, giving practitioners clearer trade‑offs on accuracy, latency and deployment patterns. The post complements recent LightOnOCR and DeepSeek work by focusing on practical pipelines and costs blog update, with the full write‑up here Hugging Face blog.
vLLM flags surge of small, fast OCR models landing for production serving
vLLM highlighted that compact OCR models are "taking off" on the platform, underscoring practical, high‑throughput serving for document AI workloads. This aligns with LightOnOCR‑1B’s immediate vLLM availability and broader momentum toward efficient OCR/VLM deployment vLLM comment, model availability.
Hugging Face promotes few‑click deployment for the latest OCR models
Hugging Face highlighted that current OCR models can be deployed in a few clicks on its platform, lowering the bar for teams to productionize document AI without bespoke infra. This dovetails with the updated model comparison to help practitioners choose and ship quickly deployment note.
🧠 Research: agent routing, proactive problem‑solving, trace fidelity
New papers target where agents fail: response‑aware routing (Lookahead), distributed self‑routing (DiSRouter), proactive E2E eval (PROBE), and instruction‑following inside reasoning traces (ReasonIF).
ReasonIF finds frontier LRMs violate reasoning‑time instructions >75% of the time; finetuning helps modestly
Together AI’s ReasonIF benchmark shows models like GPT‑OSS‑120B, Qwen3‑235B, and DeepSeek‑R1 ignore step‑level directives (formatting, length, multilingual constraints) in >75% of reasoning traces; multi‑turn prompting and a lightweight finetune improve scores but don’t fully fix process‑level compliance paper overview.
Code, paper, and blog are available for replication and training recipes GitHub repo, project blog.
Lookahead routing predicts model outputs to choose the best LLM, averaging +7.7% over SOTA routers
A new routing framework “Lookahead” forecasts latent response representations for each candidate model before routing, yielding a 7.7% average lift across seven benchmarks and working with both causal and masked LMs paper thread, with details in the preprint ArXiv paper.
It improves especially on open‑ended tasks by making response‑aware decisions instead of input‑only classification, and reaches full performance with ~16% of training data, cutting router data needs.
PROBE benchmark shows proactive agent limits: only ~40% end‑to‑end success on real‑work scenarios
PROBE (Proactive Resolution of Bottlenecks) tests agents on three steps—search, identify the root blocker, then execute a precise action—over long, noisy corpora (emails, docs, calendars); top models reach ~40% end‑to‑end success, with frequent failures on root‑cause ID and parameterizing the final action paper abstract.
Chained tool frameworks underperform when retrieval misses key evidence, underscoring that proactive help hinges on evidence selection and exact action specification.
DiSRouter: Distributed self‑routing across small→large LLMs with sub‑5% overhead
DiSRouter removes the central router and lets each model decide to answer or say “I don’t know” and forward upstream, chaining small to large models for better utility at low cost; authors report <5% routing overhead and robustness when the model pool changes paper abstract.
By training models to self‑reject via SFT and RL, the system avoids brittle global routers that must be retrained whenever the pool updates.
SmartSwitch curbs ‘underthinking’ by blocking premature strategy switches; QwQ‑32B hits 100% on AMC23
SmartSwitch monitors generation for switch cues (e.g., “alternatively”), scores the current thought with a small model, and if still promising, rolls back to deepen that path before allowing a switch; across math tasks it raises accuracy while cutting tokens/time, with QwQ‑32B reaching 100% on AMC23 paper abstract.
Unlike “be thorough” prompts or fixed penalties, the selective intervention preserves agility while enforcing depth where it matters.
Ensembling multiple LLMs via ‘consortium voting’ reduces hallucinations and boosts uncertainty signals
A study ensembles diverse LLMs and groups semantically equivalent answers to take a majority vote, introducing “consortium entropy” as an uncertainty score; this black‑box setup often outperforms single‑model self‑consistency while costing less than many‑sample decoding paper abstract.
The result doubles as a triage signal, flagging low‑confidence cases to humans—useful for production gateways where retraining isn’t feasible. Following up on self-consistency, which offered error guarantees for majority vote, this extends the idea across heterogeneous models rather than multiple samples of one.
Letta Evals snapshots agents for stateful, reproducible evaluation via ‘Agent File (.af)’ checkpoints
Letta introduced an evaluation method that checkpoints full agent state and environment into an Agent File (.af) so teams can replay and compare agent behavior holistically—not just prompts—over long‑lived, learning agents product note.
This targets a growing gap in agent testing where memory and environment drift make traditional single‑turn or stateless evals misleading for production readiness.
🧪 Serving quality: provider exactness and open‑model stabilization
Production notes on improving open models in agents: Cline’s GLM‑4.6 prompt slimming and provider filtering (:exacto) lift tool‑call reliability; OpenRouter confirms :exacto gains; Baseten adds fast GLM‑4.6 hosting.
Cline stabilizes GLM‑4.6 agents with 57% prompt cut and :exacto provider routing
Cline reports a production hardening of open models by shrinking GLM‑4.6’s system prompt from 56,499 to 24,111 characters (−57%), which sped responses, lowered cost, and reduced tool‑call failures; they also now auto‑select OpenRouter’s “:exacto” endpoints to avoid silently degraded hosts that broke tool calls. See details and the before/after instruction tuning in Cline blog, a side‑by‑side run where glm‑4.6:exacto succeeds while a standard endpoint fails by emitting calls in thinking tags in provider demo, and OpenRouter’s confirmation that Cline’s quality jump came from :exacto in OpenRouter note.
SGLang Model Gateway v0.2 adds cache‑aware multi‑model routing and production‑grade reliability
LMSYS rebuilt SGL‑Router into the SGLang Model Gateway: a Rust gRPC, OpenAI‑compatible front door that runs fleets of models under one gateway with policy‑based routing, prefill/decode disaggregation, cached tokenization, retries, circuit breakers, rate limiting, and Prometheus metrics/tracing. It targets agent backends where endpoint quality varies and failover, observability, and tool/MCP integration are mandatory gateway release, with a feature list of reliability/observability upgrades for production workloads reliability brief.
Baseten lights up GLM‑4.6 hosting with usage‑billed API and fastest third‑party claim
Baseten announced GLM‑4.6 availability via its managed inference with API pricing for teams that prefer usage billing, and reiterated it’s the fastest third‑party host for this model per recent bake‑offs. For teams standardizing on open models across providers, this adds a turnkey endpoint option alongside self‑hosted stacks hosting note.
Factory CLI’s mixed‑model plan→execute keeps 93% quality at lower cost
Factory advocates splitting agent work across models—use a strong, pricier model (e.g., Sonnet) to plan and a cheaper open model (e.g., GLM) to execute—claiming you keep ~93% of performance while “only paying premium for thinking.” This is a practical pattern for taming provider variance and stabilizing tool calls without locking into a single endpoint claims thread, with broader mixed‑model support landing in the Factory CLI mixed models note.
🛡️ Trust & uptime: data deletion policy and outage recap
Operational signals: OpenAI confirms return to 30‑day deletion for ChatGPT/API after litigation hold ended; separate brief outage caused ‘Too many concurrent requests’ with status updates to recovery.
OpenAI reinstates 30‑day deletion for ChatGPT and API after litigation hold ends
OpenAI says deleted and temporary ChatGPT chats will again be auto‑deleted within 30 days, and API data will also be deleted after 30 days, following the end of a litigation hold on September 26, 2025 policy screenshot.
Teams should verify retention assumptions in privacy notices, DSR workflows, and logging/backup pipelines; OpenAI notes it will keep a tightly‑access‑controlled slice of historical user data from April–September 2025 for legal/security reasons only policy screenshot. Community commentary stresses this mirrors prior standard practice and that the earlier hold stemmed from external litigation constraints, not a product policy change context thread.
ChatGPT outage triggers ‘Too many concurrent requests’; status page shows same‑day recovery
ChatGPT briefly returned “Too many concurrent requests” errors; OpenAI’s status page tracked investigation, mitigation, and full recovery within the same afternoon error screenshot, OpenAI status.
According to the incident log, errors began mid‑afternoon, a mitigation was applied within about an hour, and all impacted services recovered shortly thereafter OpenAI status. Users and third‑party monitors reported elevated error rates during the window, aligning with OpenAI’s outage acknowledgment and remediation updates outage report.
🕹️ World models in the browser: Genie 3 experiment
Google’s Genie 3 public experiment appears imminent: UI for sketch‑your‑world and character prompts surfaces, with reporting that users will generate and explore interactive worlds. Separate from LTX‑2 video engine.
Genie 3 public experiment UI surfaces; ‘create world’ flow suggests launch soon
Google’s Genie 3 appears ready for a public browser experiment: a “Create world” interface with Environment and Character prompts, plus a First‑person toggle, has been spotted alongside reports that users will generate and then explore interactive worlds. Multiple screenshots and write‑ups point to an imminent rollout rather than a lab‑only demo documented scoop, and community observers are now calling the release all but confirmed confirmation post.
The new UI invites text descriptions of the world and avatar and hints at sketch‑to‑world creation, aligning with Google’s earlier “world model” framing. For analysts and engineers, this signals hands‑on data about user‑steered simulation, control inputs, and first‑person interaction loops—key to agent training and evaluation in browser‑safe sandboxes ui preview. Full details and artifact references are compiled in TestingCatalog’s coverage TestingCatalog article, with additional UI capture corroborating the same flow ui screenshot.
📊 Agent evals & observability: multi‑turn and automated insights
Evals tooling advanced: LangSmith adds an Insights Agent and multi‑turn evals for goal completion; Letta ships stateful agent evals using Agent File snapshots to replicate full state+env. Practical, production‑oriented.
LangSmith adds Insights Agent and multi‑turn conversation evals
LangChain rolled out two eval features in LangSmith: an Insights Agent that automatically categorizes agent behavior patterns, and Multi‑turn Evals that score entire conversations against user goals rather than single turns feature brief. This closes a common gap in production agent QA by shifting from turn‑level rubric checks to trajectory‑level success measurement across tasks like planning, tool use, and error recovery.
ReasonIF finds LRMs ignore reasoning‑time instructions >75% of the time
Together AI’s ReasonIF study shows frontier large reasoning models often fail to follow instructions during the chain‑of‑thought itself—over 75% non‑compliance across multilingual reasoning, formatting, and length control—despite solving ability paper summary. Authors release a benchmark plus code and data; simple interventions like multi‑turn prompting and instruction‑aware finetuning partially improve adherence resources bundle, ArXiv paper, and GitHub repo.
For evaluators, this clarifies why output‑only checks miss latent failures: process‑level audits and instruction‑fidelity metrics belong alongside accuracy.
Letta Evals debuts stateful agent testing via Agent File snapshots
Letta introduced an eval suite purpose‑built for long‑lived agents, snapshotting full agent state and environment into an Agent File (.af) so tests can deterministically replay behavior, compare changes, and evaluate upgrades apples‑to‑apples product note, launch claim. Teams can evaluate an entire agent (not just prompts) and even target existing agents as eval fixtures, addressing the core challenge of drift in memoryful, tool‑rich systems.
New PROBE benchmark stresses proactive agents; top models ~40% end‑to‑end
A new dataset, PROBE (Proactive Resolution of Bottlenecks), evaluates agent workflows that must search long noisy corpora, identify a single true blocker, and execute one precise action with parameters. Leading models manage roughly 40% end‑to‑end success, with most failures in root‑cause identification and incomplete action arguments paper thread.
This style of eval mirrors real knowledge‑work: find the right evidence, disambiguate ownership/deadlines, and act once—useful for assessing enterprise agent readiness beyond chat quality.
Multi‑model ‘consortium voting’ cuts hallucinations and adds calibrated uncertainty
A paper from Cambridge Consultants and collaborators proposes teaming multiple LLMs, grouping semantically equivalent answers, and majority‑voting to both reduce hallucinations and expose confidence via consortium entropy—often beating single‑model self‑consistency at lower cost paper details. In context of certified majority‑vote methods with error guarantees reported yesterday error guarantees, this offers a pragmatic, black‑box route to production risk flags without retraining.
The approach also provides a cheap abstain signal for eval pipelines: throttle or escalate when answer clusters disperse.