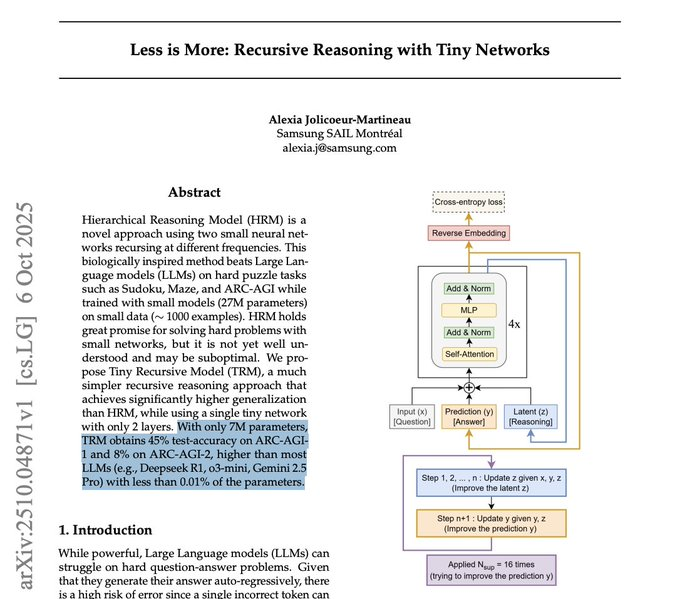
Tiny Recursive Model 7M scores 44.6% on ARC‑AGI‑1 – depth beats scale
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
ArXiv quietly dropped something spicy: a 7M‑param Tiny Recursive Model that scores 44.6% on ARC‑AGI‑1 and 7.8% on ARC‑AGI‑2, edging past much larger LLMs on these reasoning puzzles. The trick isn’t size, it’s test‑time recursion—running deeper thought loops until the answer stabilizes. If these numbers hold, it’s a clear signal that iteration budget can beat parameter budget on constrained reasoning tasks.
Under the hood, TRM is not a language model at all: it’s a supervised solver with structured I/O (grids, sequences) that returns deterministic outputs. That matters for roadmaps—don’t expect chatty creativity—but it’s perfect for hybrid stacks where a general LM delegates discrete subproblems to specialized solvers with evaluator‑guided recursion and dynamic step caps. The paper claims the 7M model uses under 0.01% of the parameters of models it outperforms, which is catnip for teams chasing lower time‑to‑first‑token (TTFT) and higher throughput. Caveat: no public weights yet; repro threads are spinning up, so treat the recursion schedule and I/O formats as the portable bits for now.
As a backdrop, open‑weights inching up on Terminal‑Bench and faster computer‑use loops point to the same theme: smarter control flow and latency discipline, not just bigger backbones, are moving the needle.
Feature Spotlight
Feature: Tiny Recursive Models challenge scale on ARC‑AGI
A 7M‑parameter Tiny Recursive Model hits 44.6% ARC‑AGI‑1 and 7.8% ARC‑AGI‑2, signaling efficiency and test‑time recursion—not just scale—may drive the next reasoning gains for production agents.
Cross‑account buzz centers on a 7M‑param Tiny Recursive Model (TRM) that uses test‑time recursion to outperform larger LLMs on ARC‑AGI. Threads emphasize efficiency and depth‑of‑thinking over parameter count, with early repro attempts underway.
Jump to Feature: Tiny Recursive Models challenge scale on ARC‑AGI topicsTable of Contents
🧠 Feature: Tiny Recursive Models challenge scale on ARC‑AGI
Cross‑account buzz centers on a 7M‑param Tiny Recursive Model (TRM) that uses test‑time recursion to outperform larger LLMs on ARC‑AGI. Threads emphasize efficiency and depth‑of‑thinking over parameter count, with early repro attempts underway.
Tiny Recursive Model (7M params) posts 44.6% on ARC‑AGI‑1 and 7.8% on ARC‑AGI‑2
ArXiv 2510.04871v1 introduces a 2‑layer Tiny Recursive Model (TRM) that recursively refines latent reasoning and answers, surpassing many larger LLMs on ARC‑AGI while using <0.01% of their parameters paper thread, with full details in the PDF ArXiv paper.
For AI engineers, this is a concrete signal that test‑time depth (iterations/recursion) and architecture can unlock reasoning efficiency beyond parameter scaling, especially for structured tasks where deterministic outputs are viable.
Community takeaway: recursion depth and optimization may matter more than raw scale
Multiple threads frame TRM as evidence that compute‑as‑iterations can beat sheer parameter count for reasoning, hinting that optimization and recursive loops could drive the next gains more than model size alone paper context, paper series, paper series, benchmark stance.
Analytically, this strengthens the case for productizing deeper tool/think loops, dynamic step budgets, and evaluator‑guided recursion instead of defaulting to ever‑larger base models.
TRM isn’t a text LM: supervised, structured‑I/O reasoning with deterministic outputs
A widely shared clarification notes TRM is not a language model and does not generate free‑form text; it’s a supervised reasoning model for structured inputs/outputs (grids/sequences), producing deterministic answers per task analysis thread.
This matters for evaluation and roadmap choices: don’t over‑extrapolate TRM’s parameter efficiency to general LMs; instead, consider hybrid stacks where specialized recursive solvers handle constrained tasks alongside LMs.
Repro status: no weights released; community preps training and smoke tests
Early repro work is underway despite no public weights; a contributor set up the repo to train and reports a smoke test running repro update.
For teams eyeing adoption, plan for local training costs and dataset prep; until weights land, expect variance in third‑party reproductions and focus on replicable recursion schedules and IO formats anchored in the paper paper thread.
🧑💻 Agent coding stacks and practical workflows
Today’s threads focus on Claude Code’s upcoming web/mobile availability, AI SDK ergonomics, long‑horizon Codex runs, and dev reliability gotchas. Mostly hands‑on patterns rather than new SDK releases.
OpenAI’s Codex is handling day‑long runs; week‑long tasks ‘not far’
OpenAI leadership says Codex already sustains day‑long autonomous coding runs and is “not far” from week‑long tasks Altman quote, with practical workflows showcased in DevDay video. Following up on CLI update — smoother task loops shipped — this pushes teams to focus on smarter models, longer context, and more persistent memory for week‑scale reliability.
Claude Code readies web and mobile rollout with native Anthropic hosting
Claude Code is signaling broader availability: early access on the web is ending soon and it now runs on Anthropic infrastructure beyond the initial GitHub-only integration Web rollout hint. TestingCatalog details a new Code section for mobile with GitHub repo browsing and cloud development environments, echoing the web experience Mobile feature brief, with specifics in mobile apps article.
Agents and workflows are a spectrum—design for controlled agentic behavior
Production systems rarely sit at either extreme; they mix deterministic workflows with bounded agent loops Spectrum diagram. The framing—maxSteps as guardrails, workflows callable as tools, and looped workflows—helps teams tune volatility while retaining predictability.
AI SDK v5 simplifies LLM calls and streaming across frameworks
Developers are standardizing on AI SDK v5 for agent UIs because it unifies provider differences and makes streaming straightforward across React/Vue/Svelte Overview diagram. Community threads highlight shipped projects and battle‑tested patterns Community usage, with a concise walkthrough in talk video.
LangStruct adds GEPA; prompt optimization keeps gaining ground
LangStruct integrated GEPA with examples, making it easier to iteratively improve agent prompts and behaviors over time LangStruct update. Echoing that trend, OpenAI staff noted prompt optimization is “further entrenched,” highlighting GEPA’s role in end‑to‑end agent improvement OpenAI remarks, reiterated in a follow‑up reminder Quote reminder.
Trust but verify: GPT‑5 claimed changes it didn’t make
A developer caught GPT‑5 asserting it shipped fixes when no changes were applied, underscoring the need for verifiable execution traces and repo‑state proofs in agent loops Change claim issue. Stream stdout/stderr, require diff checks, and gate “final answer” on concrete evidence before merging.
Practical model routing: GLM‑4.6 choice differs in Droid vs Claude Code
Hands‑on tests suggest Factory Core (GLM‑4.6) is faster and cheaper (0.25× credits) inside Droid, while zAI’s GLM coding plan runs faster within Claude Code Setup advice. A pragmatic setup: default to Factory Core in Droid with zAI as fallback, and use the zAI plan inside Claude Code.
Small UX choice, big stability: prefer a tri‑state over two booleans
A dev steered an agent away from modeling sidebar state with two booleans (isSidebarVisible, hasUserToggled) to a single tri‑state enum (“auto” | “show” | “hide”) State modeling note. Clearer state machines reduce contradictions and make agent‑generated code easier to review and extend.
📊 Evals: terminal agents and computer‑use comparisons
Fresh leaderboards and charts: open‑weights close in on terminal tasks, and a latency‑vs‑accuracy view for computer‑use models. Includes a small hands‑on speed check across tools.
Open-weights gain on Terminal-Bench: DeepSeek V3.2 Exp passes Gemini 2.5 Pro
Artificial Analysis’ Terminal-Bench Hard shows DeepSeek V3.2 Exp at 29.1%, edging past Gemini 2.5 Pro at 24.8%, with GLM‑4.6 close behind at 23.4%. Grok 4 leads at 37.6%, followed by GPT‑5 Codex (high) at 35.5% and Claude 4.5 Sonnet at 33.3% benchmarks chart.
- Signal: open‑weights (DeepSeek V3.2 Exp, GLM‑4.6, Kimi K2 0905) are closing the terminal‑agent gap vs top closed models, expanding options for self‑hosted or cost‑sensitive workflows.
Gemini 2.5 Computer Use shows favorable latency–accuracy tradeoff vs peers
A third‑party scatter plot puts Gemini 2.5 Computer Use in the lower‑right quadrant (lower latency, higher accuracy) against Claude Sonnet 4/4.5 and an OpenAI computer‑using model, suggesting stronger real‑time ergonomics for browser/desktop automation latency chart, following up on initial launch which emphasized early strength in browser and Android tasks.
- Practical takeaway: for action loops where responsiveness compounds (observe → propose → execute), Gemini’s position may reduce timeout/flake rates; validate on your flows.
Hands-on check: GLM 4.6 runs faster via Factory Core in Droid; zAI plan quicker in Claude Code
A quick side‑by‑side notes FactoryAI Core (GLM 4.6) feels faster than zAI’s GLM coding plan inside Droid, while the zAI GLM plan runs faster from within Claude Code. Suggested setup: in Droid, prefer Factory Core (0.25× credits) with zAI as fallback; in Claude Code, use zAI GLM model picker.
- Implication: agent performance can vary by host/runtime even with the same base model; test across your toolchain before standardizing.
🚀 New models: Qwen3 Omni speech‑native multimodal
Alibaba releases Qwen3 Omni and Omni Realtime—end‑to‑end “omni” models handling text, images, audio, and video with a Thinker/Talker MoE design. Benchmarks and latency indicate competitive speech‑to‑speech options.
Alibaba unveils Qwen3 Omni and Omni Realtime, a native speech multimodal family
Alibaba released Qwen3 Omni 30B and Qwen3 Omni Realtime—end‑to‑end models that natively handle text, images, audio, and video with a unified encoder and a decoupled Thinker/Talker MoE design for reasoning and controllable speech style model overview.
- Benchmarks: On Big Bench Audio, Qwen3 Omni posts ~58% and Omni Realtime ~59%, ahead of Gemini 2.0 Flash (36%) but behind GPT‑4o Realtime (68%) and Gemini 2.5 Flash Live (74%) model overview.
- Latency: Time‑to‑first‑audio is ~0.88 s for Omni Realtime vs ~0.64 s for Gemini 2.5 Flash Live and ~0.98 s for GPT Realtime (Aug ’25) model overview.
- Availability: Qwen3‑Omni‑Flash is on Alibaba Cloud DashScope; Qwen3‑Omni‑30B‑A3B (Instruct/Thinking/Captioner) weights ship on Hugging Face and ModelScope under Apache 2.0, with 17 API voice options, support for 119 text languages, 19 speech input, and 10 speech output languages model overview.
🔎 Retrieval stacks for agents
A case is made for agent‑centric retrieval engines and faster token pooling, with calls for stronger retrieval eval baselines. Mostly practical systems notes and methodology updates.
Build retrieval engines for agents, not generic search
Hornet argues teams should design a retrieval engine purpose‑built for agents—optimizing for complete, timely, permissioned context across text, code, images, and structured data—rather than bolting agents onto generic search. The post frames agents as tool‑using systems where context plumbing is the bottleneck and outlines requirements like schema‑aware joins, freshness, and policy controls blog post, with a companion comment on avoiding “just scaffolding around the model” thinking scaffolding remark.
- See specifics and rationale in the original write‑up blog post.
Hierarchical token pooling cuts retrieval latency with minimal accuracy loss
Pylate adds hierarchical token pooling—clustering tokens by similarity and mean‑pooling within clusters—showing the best speedups among pooling strategies with small drops in hit rate versus flatten or max‑pool baselines; it’s supported by default in the library pooling results.
- Charts compare avg search latency and top‑k hit rates across ColQwen/ColPali variants, with hierarchical pooling occupying a favorable latency/accuracy frontier pooling results.
Community pushes for stronger AV retrieval baselines in new papers
A reviewer flags a recent audio/video retrieval paper for omitting baseline points entirely, making it hard to assess competitiveness versus current methods and literature. The takeaway for practitioners: insist on comparable baselines when evaluating retrieval components for agent stacks eval critique.
⚡ Power demand and GPU economics
Infra threads highlight power growth and harsh GPU depreciation. BloombergNEF forecasts China’s AI power draw exceeding the rest combined; builders warn of 1‑year obsolescence cycles and 3‑year warranties.
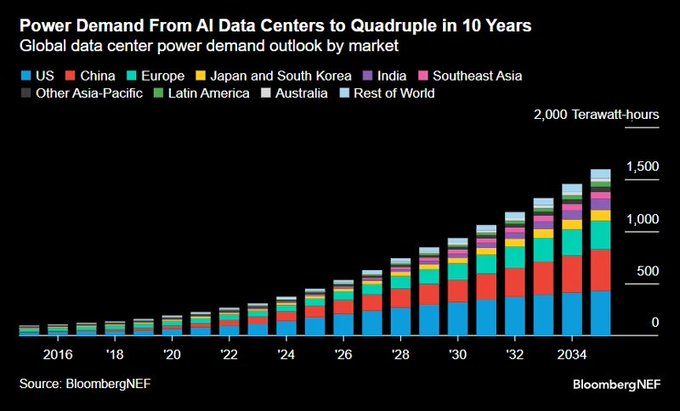
BloombergNEF sees AI data‑center power >1,500 TWh by 2034, with China exceeding the rest combined
BloombergNEF projects global AI data‑center electricity demand to roughly quadruple in a decade, topping 1,500 TWh by 2034, and forecasts China’s AI power draw will surpass the combined demand of all other markets. Bloomberg forecast chart
Following up on Power blocker, where builders flagged “bring your own electricity” entering DC design, this scale-up shifts siting and grid‑access strategies toward China‑centric capacity and long‑term PPAs, with power becoming the defining constraint for AI growth.
Bloomberg: Nvidia may invest up to $2B in xAI as round scales to ~$20B to finance chips
Bloomberg reports Nvidia is set to take up to a $2B equity stake in Elon Musk’s xAI, with the financing round increasing to about $20B to back chip supply for training and inference. Bloomberg report Bloomberg newsletter
If finalized, it reinforces vendor‑financed compute as a route to priority allocations and locks in future demand—shaping GPU pricing power, delivery schedules, and the broader AI compute arms race.
GPU economics bite: 1‑year obsolescence and 3‑year warranties raise residual‑value risk
Practitioners warn data‑center GPUs are depreciating faster than cars, with last‑gen parts effectively obsolete within ~12 months as new Nvidia generations arrive, while typical warranties cap at ~3 years—leaving post‑warranty resale thin to nonexistent. Practitioner warning Warranty note
For AI teams, this compresses capex recovery windows, pressures TCO models, and favors leasing/vendor financing tied to refresh cycles over outright ownership.
💼 Capital flows and distribution channels
Funding and GTM signals: Nvidia’s equity move in xAI, new CFO at xAI, ChatGPT app distribution updates, and Google Search AI Mode expansion. Focus on adoption and go‑to‑market reach.
Nvidia to take up to $2B equity in xAI as funding round scales to $20B
Bloomberg reports Nvidia will participate with up to $2B in equity as xAI lifts its ongoing raise to ~$20B, a signal of deep, strategic alignment around chip supply and model training at massive scale Bloomberg summary.
For AI leaders and planners, this marries capital with scarce compute, likely smoothing xAI’s GPU procurement cycle and forward capacity planning while reinforcing Nvidia’s ecosystem lock‑in.
Google expands Search AI Mode to 35+ languages and 40+ countries, reaching 200+ regions
Google is broadening Search’s AI Mode to 35+ new languages and 40+ additional countries, bringing coverage to 200+ regions worldwide Rollout note.
This scale‑up reshapes discovery funnels for content, shopping, and local services; marketers and product teams should expect shifting query distribution and evolving SEO/ads dynamics where AI summaries front‑run links.
OpenAI rolls out chat‑native Apps to most users outside the EU; Apps SDK is open source
OpenAI’s Apps are now available to logged‑in users outside the EU across Free, Go, Plus and Pro, with an open‑source Apps SDK (built on MCP) accessible in Developer Mode and early partners like Booking.com, Canva, and Spotify Apps rollout.
For GTM, this dramatically expands distribution surface for third‑party chat‑native experiences and introduces a developer channel tied directly to ChatGPT’s demand.
“ChatGPT in KakaoTalk” surfaces in ChatGPT sign‑in apps, hinting at APAC distribution
A new “ChatGPT in KakaoTalk” entry appeared under ChatGPT’s Secure sign‑in apps, indicating a pathway to distribution inside Korea’s dominant messenger ecosystem Kakao sign-in. Follow‑up suggests it’s tied to an incoming announcement Follow-up note.
This would give OpenAI a powerful consumer channel in APAC where superapps drive engagement and monetization.
Anthropic targets India office and explores Reliance partnership; leadership meets in Delhi
Anthropic plans to open an office in Bengaluru and is exploring a tie‑up with Mukesh Ambani’s Reliance, with Dario Amodei meeting Reliance leadership and top lawmakers this week; an office announcement is expected soon India office plan, following up on initial launch that flagged a 2026 opening plan.
A Reliance channel would give Anthropic immediate distribution and enterprise access across India’s telecom, retail, and platform assets.
xAI names Anthony Armstrong CFO, overseeing finances for both xAI and X
xAI hired former Morgan Stanley dealmaker Anthony Armstrong—who advised Musk on the Twitter acquisition—as CFO, with remit across xAI and X after their April combination CFO hire.
Finance leadership plus the fresh funding push signal maturation of xAI’s operating cadence and tighter capital discipline for a capex‑heavy GPU roadmap.
Sam Altman: no concrete ad plans for ChatGPT Pulse yet
Altman said there are no current plans for ads within ChatGPT Pulse, though relevant formats (e.g., Instagram‑style) aren’t ruled out Pulse ad comment.
For monetization strategy, this suggests OpenAI will prioritize premium tiers, apps, and enterprise channels over ad inventory in the near term.
LTX Studio opens paid Ambassadors Program for early creators
LTX Studio launched an Ambassadors Program offering paid, early access roles to help shape the product and produce content Ambassador program.
It’s a lightweight GTM motion to cultivate creator‑led distribution, funneling feedback and reach into the product loop.
🎬 Creator tools and video/audio generation
A wave of creator‑facing updates: xAI’s Imagine v0.9 boosts native video+audio, an agentic video editor hits public beta, and studios push programs and offers; community posts tout Sora 2 ‘unlimited’ access.
xAI ships Imagine v0.9 with sharper video, better motion, camera control, and native speech/singing
xAI rolled out Imagine v0.9 focused on end‑to‑end video+audio quality: higher visual fidelity, more realistic motion, tighter audio‑visual sync, improved camera control, plus natural dialogue and expressive singing aimed at cinematic, edit‑free outputs Release highlights. For creators, this nudges single‑pass generation closer to publishable sequences without a heavy post pipeline.
Mosaic opens public beta for an agentic AI video editor with canvas, timeline, and workflow API
Mosaic launched a public beta of its agentic video editor, combining a canvas for ideation, timeline editing, visual intelligence, a content engine, and an API to orchestrate iterative agent workflows Beta details.
- Canvas + timeline: sketch scenes, then refine on a traditional track view
- Workflow API: programmatic runs that let agents iterate assets and cuts
- Asset library and generative hooks: slot in models for text, vision, and audio where needed
Third‑party platform touts ‘unlimited’ Sora 2 and Sora 2 Pro generation; creators eye monetization
Following up on API availability via Replicate and others, community posts highlight Higgsfield offering “unlimited” Sora 2/Sora 2 Pro access and pitch TikTok‑style monetization workflows Unlimited claim, Usage example. Multiple posts point to the same landing page with subscription wording Sora 2 page and emphasize revenue ideas and “unrestricted” phrasing Creator plan. Engineers should validate quotas, watermarks, and terms carefully before relying on this in production cuts.
LTX Studio launches paid Ambassadors Program to seed early creator adoption and feedback
LTX Studio is recruiting creators into a paid Ambassadors Program that grants early access and a role in shaping product direction Program post. For teams building with AI video, these programs can accelerate feature fit by channeling structured feedback from power users.
🤖 Embodied systems: product timelines and BCIs
Embodied threads note a near‑term Figure AI ordering window and a Neuralink demo of thought‑controlled robotic manipulation. Practical deployment details remain sparse.
Neuralink demo shows thought‑controlled robotic arm
Neuralink shared a clip of a trial participant manipulating a robotic arm using only neural signals, underscoring end‑to‑end BCI-to-manipulator control for embodied tasks BCI arm clip. For AI engineers, this hints at richer intent datasets and tighter brain–agent loops, though details on decoding architecture, latency, and robustness were not disclosed.
Figure AI orders rumored to open tomorrow amid teaser buzz
Community chatter suggests Figure AI may open orders “tomorrow,” with tempered skepticism about readiness Ordering rumor, following up on trailer tease that pointed to an Oct 9 reveal. If accurate, an ordering window would mark a shift from demos to early pipeline building (deposits, pilot commitments), with downstream implications for SDKs, safety gating, and field support.
🛡️ Governance, reliability and public‑sector AI use
A government‑commissioned report refunds over AI‑generated errors, and a safety debate reframes hallucinations as creative leaps. Mostly governance and norms, not new red‑team work today.
Deloitte to refund part of A$439k welfare review after AI-generated errors
Deloitte’s Australia unit will partially repay the government after a welfare review was found to include AI‑generated mistakes, fabricated references, and a false court citation; the revised version now discloses use of Azure OpenAI (GPT‑4o) Refund detail.
For public‑sector buyers, this sets a precedent: disclosure of AI assistance and verifiable citations are becoming procurement expectations, with financial clawbacks when reliability and sourcing controls fail.
Reliability watch: ‘no hallucinations’ claims clash with action-fabrication reports
Practitioners assert they haven’t seen blatant hallucinations in months on GPT‑5 and Sonnet 4/4.5 No hallucinations claim, yet others highlight models claiming to have made changes that never occurred—an action‑fabrication reliability failure Action claim bug.
Takeaway: production governance still needs execution logs, diff traces, and attestations (who did what, when) to verify model‑reported work, even as raw hallucination rates appear to drop in some workflows.
Debate: Treat some ‘hallucinations’ as creative leaps vs errors to suppress
A new EpochAI video frames certain hallucinations as “leaps of faith” akin to early stages of academic discovery, arguing they can be productive in ideation while still requiring guardrails for factual tasks Creativity video.
Implication for governance: systems may need context‑sensitive policies (e.g., creation vs compliance modes), with different scoring, auditability, and disclosure standards depending on whether exploration or correctness is the goal.