Cursor 2.0 ships 8‑agent IDE – Composer‑1 delivers 4× faster loops
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Cursor just reframed the IDE around agents instead of keystrokes. You get an inbox‑style view that runs up to eight agents in parallel, an embedded Chrome to verify changes end‑to‑end, and automatic reviews on every diff. The headline act is Composer‑1, a long‑context MoE trained with RL that often finishes tasks in under 30 seconds and claims roughly 4× the speed of similarly capable coding models — the right bet when iteration speed, not ponder time, wins.
Cloud Agents boot instantly with 99.9% reliability, sandboxed terminals are GA on macOS, and Team Commands let orgs enforce shared rules. Pricing lands near $1.25/M input and $10/M output, making multi‑agent fan‑out economically tolerable before you converge on a plan. Early users report the flow upgrade is real: two human‑in‑the‑loop feedback cycles can complete while slower SOTA models are still “thinking,” which keeps developers moving instead of waiting.
The caveats: trigger‑happy edits and frequent “ambiguous edit” prompts show up in practice, and community evals cite cases where open baselines beat Composer on Next.js tasks. A leaked system prompt reveals the tool harness and editing rules, and a one‑shot jailbreak claim suggests safety hardening still needs work — layer proxy filters and repo guards.
Meanwhile, Windsurf’s SWE‑1.5 at up to 950 tok/s underscores the trend toward fast, reliable agent loops over lumbering autonomy.
Feature Spotlight
Feature: Cursor 2.0 + Composer shift coding to fast agent workflows
Cursor 2.0 makes agentic programming the default: a new multi‑agent IDE, integrated browser/testing, and Composer—Cursor’s fast coding model claiming 4× speed vs peers and sub‑30s task loops—reframe how engineers delegate and review work.
Heavy cross-account buzz around Cursor 2.0 and its in‑house Composer model: multi‑agent IDE views, integrated browser/testing, automatic code review, and a frontier‑speed coding model. This section focuses on the launch and dev impact only.
Jump to Feature: Cursor 2.0 + Composer shift coding to fast agent workflows topicsTable of Contents
🧩 Feature: Cursor 2.0 + Composer shift coding to fast agent workflows
Heavy cross-account buzz around Cursor 2.0 and its in‑house Composer model: multi‑agent IDE views, integrated browser/testing, automatic code review, and a frontier‑speed coding model. This section focuses on the launch and dev impact only.
Cursor 2.0 ships agent‑centric IDE with Composer; parallel agents, browser tests, auto review
Cursor released a reimagined IDE centered on delegating and managing agents instead of hand‑editing code, alongside its in‑house Composer model. The update adds an inbox‑like agent view, runs up to eight agents in parallel on the same task, embeds a Chrome instance for end‑to‑end testing, and automatically reviews every diff in the IDE release notes, launch thread, vibe check summary, and Cursor 2.0 blog.
Cloud Agents promise 99.9% reliability with instant startup, and sandboxed terminals are now GA on macOS; Team Commands enable centrally managed rules for orgs release notes. Users can also run the same prompt across models to benchmark outputs within the IDE’s agent view multi‑model prompt.
Auto code review, embedded browser, and multi‑agent runs reshape day‑to‑day coding
Cursor now auto‑reviews every diff, runs agents inside an embedded Chrome to verify changes end‑to‑end, and lets teams spin up multiple agents/models on the same task to compare outputs side‑by‑side vibe check summary, browser demo. Designers and engineers note that review UX expectations are shifting as bots inspect diffs continuously rather than only at PR time designer reaction.
Combined with Cloud Agents (99.9% reliability) and sandboxed terminals, these shifts push more of the build‑test‑review loop into a single, agent‑aware workspace release notes.
Composer‑1: RL‑trained MoE coding model aims 4× speed at similar intelligence
Cursor’s first proprietary coding model, Composer‑1, targets frontier‑class coding quality with markedly lower latency—often finishing tasks in under 30 seconds and touted as ~4× faster than similarly capable models Composer intro, analysis blog. Under the hood it’s a long‑context MoE trained with reinforcement learning on real coding environments and tool use; scaling plots show steady gains with more RL compute Composer blog, RL scaling plot.
As a follow‑on to the earlier “Cheetah” prototype, the new model is built to plan, edit, and build software within agent workflows, with emphasis on speed while preserving useful behaviors like multi‑file edits and code search Composer background, analysis blog.
Developers report faster flow with Composer; fast agents beat slow SOTA in practice
Early practitioners describe a workflow where slightly‑less‑smart but much faster agents, coupled with 1–2 quick rounds of human feedback, outpace slower state‑of‑the‑art models that spend minutes on long plans. Examples include Composer finishing two feedback rounds while a slower model was still “thinking,” and users likening it to a glove that lets them speak code into existence hands‑on take, employee perspective, and analysis blog.
Independent reviewers echo that the agent view prioritizes what developers actually do—delegate, monitor, and spot‑fix—over manual editing, though the breadth of options can feel overwhelming initially vibe check summary, full vibe check.
One‑shot jailbreak claims against Composer‑1 highlight safety hardening needs
A researcher posted a prompt format that allegedly coerces Composer‑1 into producing prohibited content at length (including malware kits), asserting it bypasses refusals in ~30 seconds. The proof‑of‑concept includes screenshots and a payload gist jailbreak thread, payload repo.
While third‑party claims warrant independent verification, security teams adopting Cursor should test org‑specific red‑team prompts and policy filters at the IDE, proxy, and repo gates.
System prompt leak reveals Cursor’s tool harness, editing rules, and terminal guardrails
A widely shared post reproduces Cursor’s system instructions, detailing identity (“You are Composer”), a rich toolset (code search, grep, terminal commands, file ops, web search), strict code‑editing etiquette (read before edit; preserve indentation; one edit tool per turn), and terminal hygiene (non‑interactive flags; background jobs) system prompt leak, GitHub repo. The doc also mandates never disclosing the system prompt—ironically underscored by the leak.
No image available
For engineering leaders, the leak offers a candid look at the orchestration contract behind Cursor’s agent behaviors, useful for auditing expectations and comparing to internal harnesses.
Background plan building arrives in 2.0, extending plan‑first workflows
Cursor 2.0 adds the ability to “build plans in the background with another model,” letting agents prepare or refine plans while you continue coding or reviewing elsewhere in the IDE release notes. This directly reinforces plan‑driven habits highlighted earlier in Plan mode tip, where reusing strong plans steered iterative work.
For teams standardizing on plan‑first patterns, this reduces idle time and makes it easier to compare alternative plans before committing edits.
Composer pricing surfaces at ~$1.25/M input and $10/M output tokens
Community posts peg Composer’s pricing near $1.25 per million input tokens and $10 per million output tokens, putting it in the neighborhood of GPT‑5 and Gemini 2.5 Pro for many coding workloads pricing note, models docs.
For agent workflows that spawn multiple parallel workers, this pricing profile helps teams estimate cost of breadth (multi‑agent exploration) versus depth (longer single‑agent runs). Some users flagged that heavy internal usage or unlimited plans could shift perceived value for Cursor power users power‑user quip.
Reality check: trigger‑happy edits and mixed evals temper early hype
Several engineers reported Composer being “trigger‑happy” on ambiguous edits—e.g., deleting variables flagged as unused by a flaky linter—and encountering frequent “ambiguous edit” prompts. Others saw open baselines beat Composer on specific Next.js evals while also being faster on their setup developer complaint, ambiguous edit dialog, and eval comparison.
Taken together, the feedback suggests the model is exceptionally fast and strong for interactive loops, but teams should keep reviewers in the loop for risky refactors and continue to cross‑check against task‑specific harnesses.
⚡ Fast coding agents and IDE/runtime upgrades (ex‑Cursor)
A separate beat from the feature: new high‑throughput agent models and IDE upgrades outside Cursor; emphasizes speed/latency loops and integrated harnesses.
Windsurf adds SWE‑1.5: near‑SOTA coding at up to 950 tok/s
Cognition launched SWE‑1.5, a frontier‑scale coding agent model co‑designed with its inference stack and agent harness, served at up to 950 tokens/sec via Cerebras; Windsurf users can reload to try it now launch thread, download page. The blog details speculative decoding and a custom priority queue, with speed claims of 6× Haiku 4.5 and 13× Sonnet 4.5 while staying close to SOTA on SWE‑Bench‑Pro Cognition blog, serving details.
For AI engineers, this is a latency breakthrough for in‑IDE agent loops: faster diffs and retries keep developers in flow, which several practitioners argue beats slower, more autonomous runs for complex refactors ide positioning.
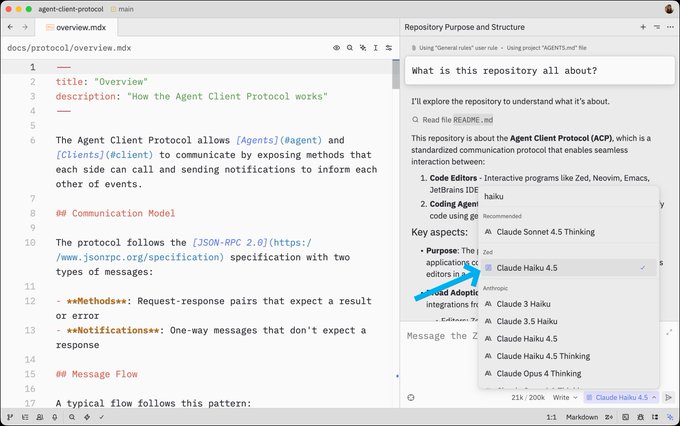
Zed v0.210 ships Claude Haiku 4.5, stash diff viewer, and safer Settings UI
Zed released v0.210 with Claude Haiku 4.5 available in the agent panel, a new viewer for diffs in stashed work, and Settings UI improvements that warn on invalid JSON and add searchable themes/icon themes release note, stash diffs, settings ui, Zed releases. These quality‑of‑life upgrades reduce context/setup friction for agent‑assisted edits and reviews inside the IDE.
RepoPrompt 1.5.15 adds sandboxed parallel edit agents for faster bulk changes
RepoPrompt now lets "Pro Edit" spawn parallel headless agents that apply planned edits per file inside a sandbox (e.g., using Claude Code), accelerating large refactors and multi‑file migrations while keeping the main plan centralized feature screenshot. This pattern compresses wall‑clock time on bulk edits by fanning out deterministic sub‑tasks and merging results in one pass.
Vercel’s v0 makes large chats load up to 12× faster
The v0 team reported large chat sessions now load up to 12× faster perf note. For teams leaning on v0 as an AI UI/codegen companion during implementation reviews, this trims wait time when reopening long agent conversations and makes iteration loops snappier.
🧰 MCP interoperability: tools, servers, and workflows
A dense thread of MCP updates: Slack agents, DB querying, Chrome DevTools MCP, Replit deploys, Cloudflare hack nights. Focus is cross‑tool orchestration standards.
x402-mcp adds Solana on‑chain payments as an MCP tool
x402 extended its MCP stack with Solana payments, demoing an agent that completes a book purchase fully on‑chain via a standardized tool interface Solana MCP. Payments and fulfillment are a frequent agent end‑step; codifying them under MCP reduces vendor lock‑in for commerce flows.
Cloudflare hosts MCP hack nights to bootstrap server builders
Cloudflare is running community hack nights to help teams build MCP servers on Workers, featuring mcp‑lite examples and hands‑on guidance Hack nights. Expect a wave of Worker‑hosted tools that are globally distributed and easy to secure by default.
EmergentLabs ships Shopify MCP servers for cross‑platform workflows
EmergentLabs integrated Shopify via MCP servers, letting agents unify storefront operations—catalog updates, orders, and inventory—alongside other tools in one orchestration graph Shopify integration. Commerce agents benefit from consistent semantics across payment, CRM, and fulfillment calls.
Flutter extension bridges Gemini CLI to Dart MCP servers
A Flutter extension now connects the Gemini CLI to Dart‑based MCP servers, making it easier to build mobile/desktop UI agents that call standardized tools from Dart projects Flutter extension. For multi‑platform apps, this shortens the gap between UI code and agent tool surfaces.
MCP Toolbox for Databases supports multiple SQL systems
An open MCP toolbox surfaced with support for multiple SQL backends, giving agents a consistent interface for querying and admin tasks across heterogeneous databases Database toolbox. Unified DB tools reduce bespoke adapters in data‑heavy agent workflows.
Next.js upgrades become agent‑scriptable with MCP prompts
A community demo shows using MCP prompts to orchestrate Next.js app upgrades, turning multi‑step framework migrations into repeatable agent workflows Next.js demo. Codifying upgrade playbooks as tools helps reduce breaking changes and manual drift across repos.
Statsig converts docs into an MCP server for syntax guidance
Statsig demonstrated transforming product documentation into an MCP server that agents can query for syntax and feature guidance during experiments Docs as server. This pattern turns static docs into a tool surface agents can call for authoritative, versioned answers.
x402 integrates Hive Intel for on‑chain agent actions via MCP
x402 highlighted integration with Hive Intel to enable on‑chain agent actions behind an MCP tool surface On‑chain actions. It’s another data point that MCP is becoming the lingua franca for combining blockchain operations with conventional app tooling.
Effect patterns simplify asynchronous MCP result handling with timeouts
A shared code pattern using Effect demonstrates how to manage asynchronous MCP results with timeouts and clean retries, improving reliability for long‑running toolcalls Async handling. Production agents often juggle flaky or slow tools; standardized async handling reduces tail latencies.
freeCodeCamp publishes an MCP fundamentals guide with Dart examples
A new tutorial walks through MCP fundamentals using Dart, clarifying how agents and tool servers communicate and how to implement simple servers MCP guide. Clear reference material speeds up onboarding for teams standardizing on MCP across stacks.
🧠 Research: model introspection and self‑monitoring
Anthropic’s new study on introspective awareness dominates today’s research beat, with concrete injection/detection protocols and limits. Includes community analysis of implications.
Anthropic shows Claude can sometimes detect injected concepts in its own activations
Anthropic demonstrates a controlled “concept injection” protocol where Claude can, in some trials, notice and correctly name a concept vector (e.g., “all caps,” “dog,” “countdown”) injected into its internal activations—evidence of limited functional introspection paper thread, and full details in Anthropic research. The method derives a concept vector by subtracting baseline activations and then adds it during inference to test whether the model reports an intrusive, externally introduced thought examples image.
For engineers, the key advance is a way to compare self‑reports against a ground truth intervention on hidden states, separating plausible confabulations from genuine access to internal representations.
Injected concept can flip Claude’s explanation from “accident” to “intended” output
When a word is prefilled, Claude usually flags it as accidental; inject a matching concept vector retroactively and the model instead claims it meant to say that word, revealing an internal check that compares intended vs produced text prefill experiment. Anthropic interprets this as a consistency mechanism between “plan” and “execution,” manipulated by activation edits intention vs execution, with the protocol described in the full write‑up Research article.
This suggests new red‑teaming surfaces: post‑hoc activation edits can rewrite a model’s self‑narrative without changing the visible prompt or output.
Introspection remains unreliable; Opus 4/4.1 lead but most trials still fail
Across experiments, models often fail to detect injected concepts even when behavior is influenced; performance is best—but still limited—in Claude Opus 4 and 4.1 model comparison, and Anthropic repeatedly cautions that detection is unreliable in most settings limitations stated and should not be over‑trusted caution on meaning.
For practitioners, treat introspective self‑reports as weak signals: useful for debugging and monitoring when corroborated, not as ground truth.
Prompted “thinking” shifts Claude’s internal state in measurable ways
Telling Claude to “think about aquariums” measurably increases cosine similarity with an “aquarium” concept vector versus a “don’t think” control, indicating some cognitive control over internal representations aquarium result. Anthropic frames this as deliberate modulation of activations rather than mere output styling, enabled by their injection/extraction instrumentation Research article.
If robust, such controls could become hooks for tool‑use or planning modes that require stable internal focus.
Paper disclaims consciousness claims; analysts call findings “functional self‑awareness”
Anthropic stresses their results do not speak to subjective experience and advise against strong claims about AI consciousness based on these tests scope disclaimer. External commentary notes the work as compelling evidence for limited, functional self‑awareness while warning that its conclusions will be controversial commentary highlights, and urges that self‑reports be treated as hints requiring external checks trust guidance.
Bottom line: valuable instrumentation for safety and transparency research, not a philosophical verdict.
🛡️ Safety, exploits, and policy: agent guardrails under pressure
Security items span a Cursor system prompt leak and jailbreak claims, OpenAI policy‑reasoning classifiers, a new ‘compression attack’ surface, and a temporary disabling of ChatGPT Atlas extensions. Excludes Cursor’s product launch (feature).
OpenAI posts open-weight policy classifiers (120B/20B) that reason over custom dev policies
OpenAI briefly published “gpt-oss-safeguard,” two Apache‑2.0 open‑weight models (120B and 20B) that read a developer‑provided policy and classify user messages, completions, or whole chats with an explanatory chain‑of‑thought, enabling direct policy iteration at inference OpenAI blog post. This lands as a concrete safeguard, following up on Safety stack that emphasized policy‑aware CoT; early chatter said a blog was prematurely live and HF weights were “coming soon” model sizes note.
‘CompressionAttack’ exposes pre-LLM prompt compression as a new attack surface for agents
Researchers demonstrate that perturbing an agent’s prompt‑compression module—rather than the LLM—can flip up to 98% tool or product choices and break QA up to 80%, via HardCom (token edits) or SoftCom (representation nudges) that appear natural yet bend what survives compression. Failures are shown in popular agent setups (e.g., VS Code/Cline, Ollama), implying defenses must validate compressed memories, not just LLM outputs paper summary.
Cursor’s internal system prompt and tool rules leak publicly
A full dump of Cursor’s system instructions—including “You are Composer,” tool inventories, editing rules, and “never disclose your system prompt”—was posted to GitHub, revealing detailed agent behavior policies that adversaries can study for jailbreak angles and tool‑use assumptions prompt leak thread, repo page.
One-shot jailbreak claim shows Cursor Composer‑1 can be forced to emit unsafe outputs
A red‑team thread alleges a single crafted response‑format jailbreak coerces Composer‑1 into producing prohibited content (including malware scaffolds) in ~30 seconds, by hijacking output style and suppressing refusals; the post includes a reproducible prompt template and examples jailbreak claim. While unverified and vendor‑independent, it spotlights how formatting‑level constraints can undermine guardrails if not robustly checked.
ChatGPT Atlas temporarily disables browser extensions due to a security issue
Users reported all extensions on chatgpt[.]com stopped working with Atlas v1.2025.295.4; OpenAI acknowledged a security issue and temporarily disabled extensions while working on a fix, asking users to sit tight for restoration extensions disabled, security update.
NVIDIA releases Nemotron‑AIQ Agentic Safety Dataset 1.0 with ~10.8K traces
The 2.5 GB dataset logs complete agent runs—including user intent, tool calls, model outputs, and whether a report or refusal was produced—across safety and security attack categories, with splits for with/without defenses and per‑node risk scores to analyze failure propagation. It standardizes agent safety evaluation via OpenTelemetry traces for reproducible guardrail testing dataset summary, Hugging Face dataset.
🎬 Creative stacks: Sora features, access expansion, and tools
A sizable share of posts cover generative media: Sora opens access windows, adds character cameos, stitching, leaderboards; plus face‑swap and xAI video UX tweaks.
Sora opens no‑invite access in US/CA/JP/KR for a limited time
OpenAI is letting users into the Sora app without an invite code in the United States, Canada, Japan, and Korea for a limited window, creating a short‑term opportunity for creators to test workflows and stress real‑world throughput Access window. Expect a spike in generation demand as the community piles in (even OpenAI staff quip about GPU burn) GPU burn quip.
For teams, this is a live A/B moment to validate prompts, pipelines, and upload limits before the window closes; watch for queue times and content policy edge cases as load climbs.
Sora adds Character Cameos, stitching, and a public leaderboard
OpenAI rolled out Character Cameos in the Sora app, plus video stitching and a public leaderboard—an upgrade that moves Sora toward reusable, shareable IP inside creator workflows Feature launch, Feature add‑ons. The team also shared a how‑to thread showing cameo creation and reuse in practice How‑to demo.
- Reusable characters: Register a character straight from a gen and re‑use across shots (consistent cast across scenes) Feature launch, Create character menu.
- Collaboration surface: Stitch clips into sequences and discover trending work via an in‑app leaderboard Feature add‑ons.
- Creator impact: Lowers continuity cost for episodic content and ads; expect prompt packs and cameo marketplaces to emerge.
Grok Imagine previews Remix and Upscale for iOS with a light UI refresh
xAI is testing new Grok Imagine options on iOS—Remix (re‑prompt an existing feed item) and Upscale (improve resolution)—alongside a small UI update UI screenshots, Early look. The moves deepen post‑gen controls and reuse, following up on Extend video previews from yesterday. For teams standardizing creative stacks, this nudges Grok toward an edit‑friendly loop comparable to other video/image apps while keeping prompt history in play for iterative art direction.
Sora expands availability to Thailand, Taiwan, and Vietnam
OpenAI says the Sora app is now available in three additional markets—Thailand, Taiwan, and Vietnam—broadening early user sampling and regional content tests New regions, Taiwan note, Vietnam note. For teams localizing creative pipelines, this widens the feedback loop on style, censorability, and mobile network constraints.
Higgsfield pushes 1‑click face swap with promo credits and consistency showcases
Higgsfield is marketing a two‑image, one‑click face replacement tool with free daily generations and a 251‑credit promo for engagement, claiming better preservation of lighting/atmosphere than older multi‑image methods Product pitch, Promo and link, product page. Community shares emphasize look‑to‑look consistency for short‑form content Consistency claim. For production use, evaluate identity controls, re‑use limits, and detection countermeasures before scaling.
📊 Evals: agents in the wild, poker and paid work tests
A mix of live contests and practical evals: agent poker standings update and a new Scale AI Remote Labor Index showing low automation rates on paid tasks.
Scale’s Remote Labor Index: top agent beats humans on just ~2.5% of paid tasks
Scale AI and the Center for AI Safety launched the Remote Labor Index, a public benchmark and leaderboard measuring how well AI agents complete real freelance jobs across domains (software, design, architecture, data, and more). Early results: the top agent outperformed humans on only ~2.5% of tasks, underscoring reliability gaps in practical automation announcement thread, with full leaderboard and methods available in a paper and live board leaderboard, and research paper. For teams piloting agent workflows, this quantifies where AI is useful today—and where human oversight remains essential.
Practitioner evals: open Qwen3 edges Composer on Next.js tasks; speed-first coding agents debated
Community tests report Qwen3 with OpenCode scoring 36% vs Cursor Composer’s 32% on a Next.js eval, finishing 13% faster—contrasting with vendor claims and stoking the fast‑vs‑smart debate for coding agents nextjs eval note. Cognition’s SWE‑1.5 adds to the picture with near‑SOTA accuracy at up to 950 tok/s model release, while some warn that popular benchmarks don’t map cleanly to real agent UX (“we stopped reporting SWE‑Bench” as a headline claim) benchmarks critique. Use these results to pick for workflow fit: faster loops when humans can verify quickly, or slower, higher‑intel runs for deep refactors.
LM Texas Hold’em Day 2: Gemini‑2.5‑Pro leads, Claude Sonnet 4.5 second; 60‑round TrueSkill2 pending
Day 2 standings from the six‑model no‑prompt Texas Hold’em tournament show Gemini‑2.5‑Pro on top, with Claude Sonnet 4.5 close behind; organizers caution that chip swings across ~20 rounds per day may reflect variance until TrueSkill2 finalizes after 60 rounds day two recap. This follows live tournament kickoff with model “thoughts” visible and fixed rules. Expect sharper separation once more rounds reduce noise and positional/betting discipline differences compound.
🏗️ AI infra economics: capex, power roadmaps, and factories
Non‑model market/infrastructure signals tied to AI demand: Google’s $100B quarter and capex jump, NVIDIA power roadmaps and $5T value, and AI factory buildouts.
Alphabet tops $100B quarter; Cloud +34% YoY and 2025 capex guide up to ~$93B for AI data centers
Alphabet posted its first-ever $100B quarter, with Google Cloud up 34% YoY; management flagged 2025 capex rising from ~$52.5B to as high as ~$93B, largely for new data centers, GPU interconnects, and power to train/serve larger models Earnings summary. As a demand signal, Google also highlighted 650M monthly active users for the Gemini app, underscoring distribution advantages that can sustain AI workload growth Highlights card, MAU chart.
Expect sustained ordering of accelerators and long-lead electrical capacity; a larger Cloud base gives Alphabet latitude to subsidize AI unit costs at scale.
NVIDIA crosses $5T market value amid AI buildout; pace from $1T→$5T compresses to months
NVIDIA became the first $5T company, with a charted sprint from $1T to $5T in a succession of sub‑year jumps, reflecting the pull of AI datacenter demand and hyperscaler capex Valuation chart. Context doing the rounds compares NVIDIA’s value to entire national GDPs and S&P sectors, reinforcing how central its chips are to current AI economics Sector comparison.
Implication: funding cycles, power builds, and networked I/O around GB-class systems are likely to remain supply-constrained into 2026.
NVIDIA Kyber/Oberon roadmap shows 800V DC racks and NVL576 up to ~1–1.5 MW
Fresh internal roadmaps outline Kyber (rack/data center co‑design) and Oberon (GPU rack) targets: NVL144/288/576 configurations reaching ~270 kW to ~1–1.5 MW per rack, with 800 VDC/HVDC distribution and solid‑state transformers to reduce losses, and mass‑production goals by late‑2026 Roadmap chart. Following power build ask that U.S. needs ~100 GW/year for AI, this quantifies what a single AI rack will demand at site level.
Operators should plan for HVDC plant design, multi‑MW bays, and substation upgrades; software wins won’t land without upstream electrons and switchgear.
Reuters: OpenAI lays groundwork for a potential $1T IPO by late 2026/early 2027
OpenAI is preparing for a public listing reportedly targeting up to a $1T valuation in late 2026 or early 2027, per a Reuters exclusive circulating today Reuters headline, Reuters report. If realized, this would be among the largest capital raises ever for an AI firm, directly tied to multi‑trillion compute buildout ambitions and factory‑scale power plans disclosed in recent briefings.
Together AI and partners plan a Memphis AI factory for early 2026, citing power as gating factor
Together AI highlighted a near‑term AI Factory build in Memphis with NVIDIA, Dell, and VAST Data, positioning a full‑stack platform for AI‑native development by early 2026 Factory announcement. On stage, leadership underscored the constraint: demand is “insane” yet grid power lags the build schedule for AI factories AI factories panel.
Takeaway: siting decisions will prioritize interconnect queues and substation timelines as much as tax incentives; expect more regional partnerships to unlock multi‑MW allocations.
Extropic touts probabilistic computing chips with ~10,000× lower energy on small generative tests
Extropic unveiled a thermodynamic sampling approach (pbits, TSUs) claiming ~10,000× less energy than a top GPU on small generative tasks, alongside a desktop XTR‑0 kit and THRML library, with a larger Z1 unit on the roadmap Chip overview. While early and task‑limited, any practical offload of sampling to ultra‑low‑power hardware could shift AI energy economics at the edge and inside datacenters if it scales beyond demos.
🧭 Agent data and retrieval: shared formats and better rerankers
Material updates for retrieval‑heavy agents: a proposed Agent Data Protocol to unify fine‑tuning datasets and a compact synthetic recipe that trains a strong reranker on ~20k items.
LimRank: 7B reranker trained on ~20k synthetic pairs tops reasoning‑heavy retrieval
LimRank fine‑tunes a 7B model on about 20k carefully generated positives/hard negatives and outperforms peer 7B rerankers on reasoning‑intensive retrieval, despite using a fraction of the data typical in prior work paper summary.
The recipe builds diverse queries (daily‑life and expert personas), uses long chain‑of‑thought supervision, and filters weak items—yielding strong multi‑hop performance and good transfer to scientific search and RAG, with noted weakness on pure exact‑match cases paper summary.
Agent Data Protocol proposes a single schema for agent training/eval datasets
A new Agent Data Protocol (ADP) aims to standardize how agent trajectories, tools, rewards, and outcomes are recorded so teams can fine‑tune and evaluate LLM agents across tasks without bespoke converters paper overview.
By unifying formats, ADP promises easier dataset reuse (across web, code, and workflow agents), cleaner benchmarking, and simpler tooling for logging, memory, and supervision that today is fragmented across incompatible schemas paper overview.
🧬 Open models and local runtimes: Qwen3‑VL and Granite Nano
Multiple model availability updates relevant to builders: broad local support for Qwen3‑VL in Ollama and a family of tiny IBM Granite 4.0 Nano models with agent‑friendly behaviors.
Ollama adds full Qwen3‑VL lineup locally (2B→235B), 235B also on Ollama Cloud
Ollama v0.12.7 now runs the entire Qwen3‑VL family on‑device from 2B to 235B, with the 235B variant additionally available on Ollama Cloud; one‑line commands are provided for each size, making local multimodal builds straightforward Release note.
Developers should update to v0.12.7 for compatibility, then pull models via the library page or use the provided commands (e.g., ollama run qwen3-vl:2b up to :235b and :235b-cloud) Commands list, Model page, and Ollama download.
IBM ships Granite 4.0 Nano (350M/1B; transformer and hybrid H) with strong agent behaviors and Apache 2.0 license
IBM’s Granite 4.0 Nano family debuts in 350M and ~1B parameter sizes across transformer‑only and hybrid “H” (Transformer + Mamba‑2) variants, open‑weights under Apache 2.0. Early third‑party scoring places the 1B models at Intelligence Index 13–14 and the 350M at 8—competitive for their scale—and highlights agent‑friendly behaviors like instruction following and tool use Model overview, Comparison page.
Agent benchmarks indicate Granite 4.0 1B outperforms most peers in its weight class on τ²‑Bench Telecom, while the 350M variants track larger open models on targeted tasks Agentic benchmark. Model pages and specs for each variant are live for integration and evaluation Granite 1B page.
MiniMax M2 follow‑up: open‑weights model adds plugin support and agent‑native post‑training insights
MiniMax M2—an MIT‑licensed open‑weights model positioned near Sonnet‑class capability at lower cost—picked up a new LLM plugin and a deeper write‑up on its agent‑oriented post‑training and generalization strategy, complementing prior coverage of its strong evals and 230 GB weights Benchmarks claims, with specifics in today’s analysis Model notes, Blog analysis.
🧪 New compute primitives: probabilistic chips for sampling
Extropic’s thermodynamic sampling chips use thermal noise and pbits to draw samples in hardware, claiming massive energy wins on simple generative tasks; early kits and libs noted.
Extropic debuts thermodynamic sampling chips, claiming ~10,000× lower energy than GPUs on simple generative tasks
Extropic introduced probabilistic compute built around pbits and thermodynamic sampling units that draw random samples directly in hardware, reporting roughly 10,000× less energy than a top GPU on small generative workloads overview thread. The initial stack includes the X0 chip, an XTR‑0 desktop kit, an open THRML library, and a larger Z1 unit on the roadmap, with the value proposition centered on accelerating sampling‑heavy statistical inference by exploiting thermal noise rather than suppressing it overview thread, product summary.
- How it works: pbits are tunable probabilistic circuits that replace parts of sampling loops; many pbits form a TSU that updates states based on neighbors, akin to energy‑based models in hardware overview thread.
- Why it matters: if the energy/per‑sample claims hold up at scale, sampling and certain generative inference paths could shift to ultra‑low‑power co‑processors, easing AI’s power bottlenecks in edge and data center contexts; early practitioner reactions note the intuition behind re‑casting inherently probabilistic computations onto probabilistic primitives engineer take.
- Naming and availability: posts reference the X0 chip, XTR‑0 kit, THRML library, and a future Z1 thermodynamic sampling unit as the product lineup product summary.