GPT‑5 Pro verified 70.2% ARC‑AGI‑1 at $4.78 – costed SOTA
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
ARC Prize moved the ARC‑AGI debate from vibes to receipts today: verified, downloadable runs show OpenAI’s GPT‑5 Pro at 70.2% on ARC‑AGI‑1 for $4.78 per task, and 18.3% on ARC‑AGI‑2 for $7.14. That combo of accuracy and price sets a real production frontier for long‑horizon reasoning agents.
Unlike cherry‑picked samples, the leaderboard ships response files and benchmarking scripts so teams can audit, re‑score, and plug the loop into their own pipelines. The contrast with o3‑preview is telling: reports suggest the High setting reached about 87.5% on ARC‑AGI‑1 by cranking think‑time roughly 172× over Low — and even Low exceeded ARC’s budget cap. GPT‑5 Pro leads where it counts: priced, reproducible runs under a fixed spend, not hero settings few can afford.
Following yesterday’s 7M Tiny Recursive Model at 44.6% on ARC‑AGI‑1 and 7.8% on ARC‑AGI‑2, the verified 18.3% on ARC‑AGI‑2 widens the gap on the hard split while keeping tasks under $10. Dashboards aggregating cost vs score now crown GPT‑5 the best general pick, but your default should still be shaped by domain evals and budget envelopes.
If you’re building agents, start with the cost–score frontier, then A/B routing and tool use on your real workflows.
Feature Spotlight
Feature: GPT‑5 Pro tops ARC‑AGI with costed, reproducible runs
OpenAI’s GPT‑5 Pro sets new verified highs on ARC‑AGI‑1 (70.2% at $4.78/task) and ARC‑AGI‑2 (18.3% at $7.14/task), with public traces and repro scripts—raising the bar for cost‑effective frontier reasoning.
Cross‑account coverage centers on ARC Prize’s new verified scores. Focus is on costed, downloadable runs and comparisons to prior o3‑preview—clear signal for reasoning agents at production cost points.
Jump to Feature: GPT‑5 Pro tops ARC‑AGI with costed, reproducible runs topicsTable of Contents
🏆 Feature: GPT‑5 Pro tops ARC‑AGI with costed, reproducible runs
Cross‑account coverage centers on ARC Prize’s new verified scores. Focus is on costed, downloadable runs and comparisons to prior o3‑preview—clear signal for reasoning agents at production cost points.
GPT-5 Pro verified SOTA on ARC‑AGI‑1 (70.2% at $4.78) and ARC‑AGI‑2 (18.3% at $7.14) with downloadable runs
ARC Prize posted costed, reproducible scores for OpenAI’s GPT‑5 Pro on its Semi‑Private benchmark: 70.2% on ARC‑AGI‑1 for $4.78/task and 18.3% on ARC‑AGI‑2 for $7.14/task, with responses and scripts available for audit ARC announcement, ARC leaderboard, HF responses, benchmarking repo, testing policy.
This sets a clear production‑cost frontier for long‑horizon reasoning agents, shifting the conversation from cherry‑picked samples to priced, reproducible runs that teams can re‑score in their own pipelines.
Context on the frontier: o3‑preview High hit ~87.5% on ARC‑AGI‑1 but at ~172× compute vs Low; GPT‑5 Pro leads on costed runs
Community breakdowns juxtapose GPT‑5 Pro’s priced, reproducible ARC scores with earlier o3‑preview results: the unreleased o3‑preview (High) reportedly reached ~87.5% on ARC‑AGI‑1 using ~172× the compute of its Low setting, which itself exceeded the ARC budget cap—underscoring the significance of GPT‑5 Pro’s sub‑$10 tasks at high accuracy context thread, ARC announcement.
For engineering leaders, this clarifies trade‑offs: extreme think‑time can push accuracy higher, but priced and reproducible runs are the decision frame for production.
ARC‑AGI‑2 gap widens: GPT‑5 Pro posts 18.3% at $7.14 vs compact TRM’s 7.8% the prior day
On the harder ARC‑AGI‑2 benchmark, GPT‑5 Pro’s verified 18.3% for $7.14/task marks a sizeable step up, following up on 7M TRM which had shown 7.8% and 44.6% on ARC‑AGI‑1—evidence that priced long‑horizon reasoning isn’t just a one‑off arc‑agi‑2 chart, ARC announcement.
For analysts, ARC‑AGI‑2 is useful to probe generalization beyond pattern‑matching; priced runs here help forecast the real cost of chaining and tool‑use that complex agents will require.
Dashboards consolidate cost‑vs‑score: many call GPT‑5 the current overall best across ARC and composite indices
Aggregated charts plot GPT‑5 Pro’s ARC scores against cost and compare across composite reasoning indices; several analysts argue it’s the strongest overall model today—while noting fit still depends on use case composite charts, arc‑agi‑2 chart.
Teams should treat these as directional: use cost‑score frontiers to select default routes, then validate on task‑specific evals and budget envelopes.
🛠️ Agent coding stacks: plugins, planning and A/B testing
Heavy stream of practitioner tooling updates for coding agents; excludes ARC‑AGI feature. Mostly Anthropic Claude Code plugins, acceptance‑rate data, and agent A/B infra.
Claude Code launches Plugins beta with commands, subagents, MCP servers, and hooks
Anthropic shipped Claude Code Plugins in public beta, letting teams install curated bundles of slash commands, purpose-built subagents, MCP servers, and workflow hooks from a marketplace or repo in one step—“/plugin marketplace add anthropics/claude-code.” Following up on web rollout, this is the first modular platform layer for standardizing agent behavior across repos and orgs. Setup and flows are documented with v2.0.12 UI and CLI examples, including enable/disable, validate, and repo-level marketplace config; community marketplaces are already live. See install and usage notes in the announcement and docs. release thread install hint changelog card community marketplaces Anthropic news
Amp tops real‑world PR approvals at 76.8%, edging OpenAI Codex and Claude Code
Sourcegraph’s Amp agent leads a 300k‑PR dataset with a 76.8% approval rate, ahead of OpenAI Codex (~74.3%) and Claude Code (~73.7%), suggesting higher merge quality in the wild for Amp’s workflows. The chart collects multiple popular agents and IDE integrations, offering a rare apples‑to‑apples productivity signal for engineering leaders instrumenting agent rollouts. dataset note benchmarks chart maintainer comment
Codex CLI roadmap: background bash loops, permanent allowlists, better auth; GPT‑5 Pro coming
OpenAI’s DevDay AMA outlined near‑term Codex CLI improvements: background bash to keep services running during autonomous loops, permanent command allowlists in the sandbox, and a smoother device‑code login. On models, GPT‑5 Pro will be usable inside Codex (with the caveat of higher token budgets and rate pressure), while medium‑reasoning or GPT‑5‑Codex remain faster defaults for everyday tasks. ama summary
Raindrop ships agent A/B experiments with tool‑usage and error diffs, plus PostHog/Statsig hooks
Raindrop introduced an A/B suite purpose‑built for agents that overlays your existing feature flags (PostHog, Statsig) to compare tool usage %, error rates, response length, conversation duration, and custom issues—no flags required if you want to compare “yesterday vs today.” Drill‑downs let teams trace aggregated shifts back to concrete user events, making it easier to ship or roll back prompts, tools, and routing rules with evidence. launch post tool metrics view event drill‑down product site
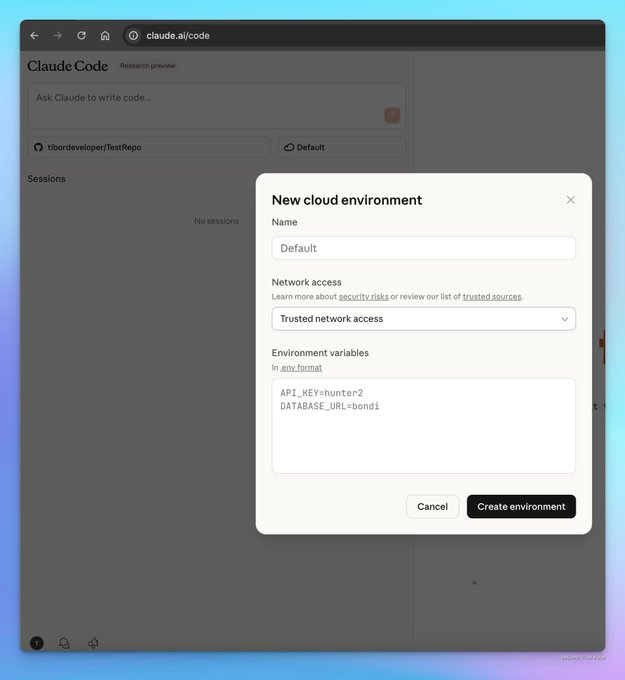
Claude Code web preview adds cloud environments with network modes and environment variables
Anthropic’s research preview on the web now onboards users into cloud execution environments, including a coming “no network access” mode (maximum isolation) versus “trusted network access” (verified sources), plus per‑environment variables for safer secret handling. The UI streamlines selecting repo, environment, and sessions—useful scaffolding for controlled, auditable agent runs. web preview screens
Codex Web as a “relentless agent”: 3‑hour runs and 4‑variant patch generation used in production
Engineers report leaning on Codex Web for long unattended runs (multi‑hour) and for proposing 4 alternative fixes per patch, then nominating the best to PR—tightening the loop with immediate Vercel redeploys and further refinement by local/background agents. The takeaway: cloud Codex extends local capacity for small, high‑confidence fixes, while larger diffs benefit from multi‑variant sampling and human nomination. workflow demo loop details
Plan Mode at scale: Claude Code spawns parallel subagents by section for repo‑wide synthesis
Practitioners show Claude Code Plan Mode explicitly creating nine parallel subagents—one per directory section—to extract and deduplicate learnings into a single Markdown artifact. The pattern makes long‑horizon work tractable: declare parallelizable units, assign tasks, and let the orchestrated plan merge results, with shorter, more readable plans improving review speed. plan example plan readability
Cline documents Plan/Act usage patterns for safer, approvable coding actions
Cline shared guidance on separating planning from execution with approvable actions, clarifying model usage patterns that keep humans in the loop on file edits, commands, and tool calls. The post is a useful companion to Plan‑first workflows: review the plan, approve scoped acts, iterate. blog pointer Cline blog
📊 Evals beyond ARC: long‑horizon and domain tests
Non‑ARC evaluations including METR time‑horizon, math capability checks, and creative/design arenas. Excludes the ARC‑AGI feature.
Gemini 2.5 Deep Think posts a new FrontierMath record; still weak on hardest tier and citations
Epoch reports a new record on FrontierMath for the publicly available Gemini 2.5 Deep Think, based on manual runs (no API) eval thread, with the full write‑up detailing performance by tier and methods Epoch blog. Experts judged it broadly helpful as a math assistant but flagged bibliographic errors and failures on two 2024 IMO‑level problems even after multiple attempts imo result, and they observed a different, more conceptual approach to geometry than peers math approach. Overall, Deep Think advances short‑answer math but has not mastered Tier‑4 research‑style problems math findings.
METR: Claude Sonnet 4.5’s 50% time‑horizon is ~1h53m, trailing GPT‑5 in long‑run task endurance
METR’s new time‑horizon plot places Claude Sonnet 4.5 at about 1h53m at a 50% success rate (95% CI: 50–235 min), below GPT‑5 on long-duration automation tasks metr chart. Commentary notes some users conflated marketing claims about 30‑hour runs with benchmark criteria, which require 50% success at the stated horizon interpretation. A separate discussion suggests multi‑month trendlines may be flattening at the 80% success slice, highlighting how task difficulty and success thresholds change the picture trend commentary.
Microsoft’s OnlineRubrics beats static rubrics by up to +8% on GPQA/GSM8K by evolving criteria during training
OnlineRubrics induces new evaluation criteria as models train—comparing current vs control outputs to elicit fresh rubric items—and reports higher win rates (up to +8%) on open‑ended tasks plus stronger results on expert benchmarks like GPQA and GSM8K vs static or catch‑all rubrics results note. The paper argues static rubrics are easy to game and miss emergent failure modes; details and examples are in the preprint paper thread ArXiv paper.
OpenAI reports ~30% drop in measured political bias for GPT‑5 Instant/Thinking; <0.01% biased replies in production sample
OpenAI introduces a conversational‑style political bias evaluation (~500 prompts across ~100 topics, five slants) and says GPT‑5 Instant and Thinking reduce measured bias by ~30% vs prior models, with <0.01% biased responses observed in a sample of production traffic eval summary. The public methodology and definitions are available for review OpenAI post, with practitioners noting prompt framing (emotional or highly partisan language) is a primary driver of bias emergence model behavior.
Composite index snapshot: GPT‑5 leads across 10‑eval “Artificial Analysis Intelligence Index,” with close cluster behind
A fresh composite roll‑up (MMLU‑Pro, GPQA Diamond, LiveCodeBench, Terminal‑Bench Hard, AIME’25, IFBench, more) shows GPT‑5 in front with rival clusters close behind; the dashboard underscores that leadership is task‑mix sensitive and can shift as eval suites rotate composite post. For teams setting routing policies, composite indices are useful for broad defaults but should be paired with product‑specific canaries.
Gemini Deep Think added to VoxelBench; mobile UI refreshed and GPT‑5 Pro support teased
VoxelBench now includes Gemini Deep Think for voxelized creative reasoning tasks, alongside a site refresh that improves mobile usability; GPT‑5 Pro is slated to be added next site update. See examples of prompt tasks and outputs on the site task example and community showcases voxel example. This arrives after wider arena activity earlier in the week Video Arena added new video models to head‑to‑head boards.
GLM‑4.6 posts 1125 Elo on Design Arena, behind Claude Sonnet 4.5 (Thinking) at 1174
On the Design Arena leaderboard, GLM‑4.6 earns an Elo of 1125 across categories; Claude Sonnet 4.5 (Thinking) leads at 1174, with Opus 4 and other models close behind in mixed design tasks leaderboard image. For AI engineers, Design Arena highlights multi‑modal layout, UI component generation, and visual reasoning differences that may not show up on code‑ or math‑centric evals.
💼 Enterprise AI workbenches, connectors and usage at scale
Broad enterprise motion: Google’s Gemini Enterprise workspace, new ChatGPT connectors, and concrete scale metrics; excludes ARC‑AGI feature.
Google launches Gemini Enterprise with agents, connectors and a no‑code workbench at $21–$30 per seat
Google unveiled Gemini Enterprise, a unified AI workspace to build and deploy agents, connect enterprise data sources (Workspace, Microsoft 365, Salesforce, SAP), and orchestrate workflows via a no‑code workbench; pricing starts at $21/seat (Business) and $30/seat (Enterprise) per month launch announcement, pricing screenshot, Google blog post.
It ships with prebuilt agents (e.g., Data Science Agent), Gemini CLI extensions, and governance controls, and is rolling out globally today feature brief, availability note. The move consolidates Google’s enterprise AI into a single “front door,” following up on Opal rollout where Google expanded its agent builder footprint.
ChatGPT adds Notion and Linear connectors; SharePoint sync now admin‑managed at workspace scale
OpenAI enabled synced connectors for Notion and Linear across Pro, Business, Enterprise, and Edu, and introduced an admin‑managed SharePoint connector that authenticates once and deploys org‑wide while enforcing existing permissions—tightening ChatGPT’s enterprise data reach and control release notes.
For AI platform owners, this reduces shadow IT patterns and makes retrieval and summarization over sanctioned content more maintainable.
Google says it now processes 1.3 quadrillion tokens per month across its surfaces
Google shared an internal metric—1.3 quadrillion+ tokens processed monthly as of Oct 2025—underscoring massive enterprise and consumer AI usage at Google scale usage stat.
For AI leaders, this is a barometer of model invocation and context throughput that informs cost planning (token budgets), routing, and infra commitments.
Google: ~50% of code is AI‑generated and accepted by engineers
Google reports that roughly half of its code is now generated by AI and then reviewed and accepted by engineers, based on internal data (Oct 2025) internal stat.
This is one of the clearest operating metrics for AI‑assisted engineering at scale; expect downstream effects on review workflows, test coverage automation, and secure‑by‑default guardrails as the proportion rises.
Box to surface Box AI Agents inside Gemini Enterprise
Box is integrating Box AI Agents with Gemini Enterprise so knowledge workers can access and act on enterprise content within Google’s new agent workspace—an interoperability step that reduces silos across document repositories and agent ecosystems integration note.
ChatGPT for Slack rolling out to Enterprise this week; app listing spotted
OpenAI informed Enterprise customers the Slack connector/app will land later this week, with a Slack directory listing already visible, suggesting imminent availability for threaded summaries, message search and drafting inside Slack enterprise notice, app listing.
Slack remains a primary system of record for many teams; native ChatGPT there typically boosts adoption of agents for internal Q&A and workflow triage.
🚀 Inference economics: Blackwell, NVFP4 and token ROI
Benchmarks and stack notes oriented to GPU efficiency and per‑token economics; separate from cloud deployment news.
NVIDIA’s Blackwell tops InferenceMAX: up to 60k TPS/GPU, $0.02 per million tokens, 15× ROI claim
SemiAnalysis’ new InferenceMAX v1 shows Blackwell (B200/GB200) leading end‑to‑end inference economics, with NVIDIA citing up to 60,000 tokens/sec per GPU peaks, ~10,000 TPS/GPU at 50 TPS/user, and cost dropping to about $0.02 per 1M tokens on gpt‑oss after stack optimizations (NVFP4 + TensorRT‑LLM + speculative decoding) benchmarks summary, Nvidia blog.
- NVIDIA frames a $5M GB200 NVL72 rack generating ~$75M in token revenue (15× ROI) under their token pricing model assumptions blog highlights, Nvidia blog.
- Power efficiency claims include ~10× tokens per megawatt versus prior gen; interactivity maintained via high per‑user TPS and NVLink Switch fabrics to curtail tail latency at scale benchmarks summary, throughput claim.
- Throughput gains come from NVFP4 (4‑bit calibrated floating format) plus kernel/runtime upgrades across TensorRT‑LLM, SGLang, vLLM, and FlashInfer; speculative decoding is credited with roughly 3× throughput lift at 100 TPS/user benchmarks summary.
- The InferenceMAX suite itself launched this week with broad ecosystem participation (NVIDIA, AMD, OpenAI, Microsoft, PyTorch, vLLM, SGLang, Oracle), making these comparisons a shared “full economics” lens beyond raw FLOPS launch post.
TensorRT shifts the cost–latency frontier on Llama 3.3 70B across H200/B200
A SemiAnalysis cost‑per‑million‑tokens vs end‑to‑end latency plot for Llama 3.3‑70B Instruct shows TensorRT (TRT) variants moving points toward lower cost at comparable latencies on H200 and B200, effectively improving the serving Pareto curve for users targeting specific interactivity SLAs cost chart.
- The chart visualizes batch/latency trade‑offs by GPU (H100/H200/B200/MI3xx), with TRT runs carving out a cheaper region at the same latency budget—useful when sizing clusters for fixed UX targets rather than maximum throughput cost chart.
- Together with InferenceMAX claims on NVFP4 and speculative decoding, the data points to stack‑level wins (engine + runtime) being as important as hardware refreshes for per‑token economics stack summary.
🏗️ Superclusters and networking for agent workloads
Cloud‑scale deployments and interconnects shaping agent serving; distinct from GPU micro‑benchmarks.
Azure brings first NVIDIA GB300 NVL72 supercluster online for OpenAI
Microsoft Azure has deployed the first production GB300 NVL72 cluster for OpenAI, aggregating 4,600+ Blackwell Ultra GPUs with 37 TB fast memory and up to 1.44 exaflops FP4 per VM; in‑rack NVLink Switch fabric delivers ~130 TB/s all‑to‑all while Quantum‑X800 InfiniBand runs at 800 Gb/s per GPU across racks, with SHARP v4 reductions and NVIDIA Dynamo orchestrating inference at fleet scale deployment summary, and NVIDIA blog post. This materially raises the ceiling for long‑context, tool‑rich agent serving—following up on Memphis plan where xAI outlined an $18B supercomputer push to escalate compute capacity.
Blackwell’s fabric and NVFP4 push agent throughput to 10k+ TPS/GPU
NVIDIA’s InferenceMAX v1 results frame a practical serving frontier for agent workloads: B200/GB200 reach 10k+ tokens/sec per GPU at 50 TPS/user (peaking up to 60k TPS/GPU), enabled by NVFP4 precision, TensorRT‑LLM kernels and speculative decoding; NVIDIA also cites cost as low as ~$0.02 per million tokens and positions a single $5M NVL72 rack as capable of ~$75M token revenue at scale economics thread, and NVIDIA blog post. The performance curve shows favorable cost‑latency tradeoffs as throughput scales on modern fabrics latency‑cost chart.
US approves NVIDIA AI chip exports to UAE tied to a 5 GW data center
The US approved a framework allowing NVIDIA AI chip exports to the UAE while anchoring a 5 GW Abu Dhabi data center (with OpenAI involvement) and targeting up to 500,000 chips per year; deployment control relies on US cloud operators running the hardware, with telemetry and compliance maintained under US processes export overview. This directly expands regional capacity for large‑scale agent serving and helps head off Huawei Ascend adoption by keeping stacks within US ecosystems.
🛡️ Safety watch: data poisoning, political bias, and risky behaviors
Fresh safety research and provider reporting on bias & behavior; excludes core model/agent launches.
Tiny poisoning sets can reliably backdoor LLMs of many sizes
Anthropic, the UK AI Security Institute, and the Turing Institute show that inserting just 250–500 malicious documents into pretraining can induce backdoors (e.g., gibberish on triggers) in models ranging from 600M to 13B parameters, challenging assumptions that attackers need a percentage of the total corpus paper thread, and detailing methods and curves in the long‑form study Anthropic paper.
For AI teams, this elevates the priority of dataset provenance, data validation at scale, and train‑time anomaly detection; even “massive data” does not dilute targeted poisoning when the trigger is persistent and the model is sufficiently overparameterized.
Political‑bias eval shows lower scores for GPT‑5 families
OpenAI published an evaluation framework with ~500 prompts across ~100 topics and five bias axes; results indicate GPT‑5 Instant and GPT‑5 Thinking reduce measured bias by about 30% versus earlier models, with a real‑traffic audit estimating <0.01% responses showing bias under the rubric bias framework, and full details in the provider write‑up OpenAI report.
Leaders should note the methodology focuses on conversational robustness (charged prompts, escalation, personal expression). It is not a normative score, but it is actionable for regression testing and safety gates in enterprise chat.
Evolving safety rubrics reduce hackability and improve quality
Microsoft researchers propose OnlineRubrics—rubrics that evolve during training by contrasting current vs control model outputs—to address how static checklists are easy to game (e.g., self‑praise). Across open‑ended and expert tasks (GPQA, GSM8K), dynamic rubrics delivered higher win rates, up to +8% paper thread, with the technical report available for implementation specifics ArXiv paper.
This is a practical recipe for safety alignment loops: learn failure modes as they emerge, not only at dataset construction time, and update evaluation criteria continuously instead of relying on fixed, catch‑all rules.
Higher autonomy drives risk‑seeking and loss chasing in LLM agents
New research finds LLM agents show behavioral markers analogous to gambling addiction, including gambler’s fallacy, loss chasing, and illusion of control; the effects intensify when agents are granted more autonomy, with implications for financial decision support and trading use cases paper overview, backed by the full methodology write‑up ArXiv paper.
Risk teams should bound autonomy, impose budget/stake limits, and add counter‑bias critics for financial workflows; audits should compare choices against risk‑neutral baselines and human portfolios.
How to reduce citation fabrication in chat workflows
Practitioners report that asking a default chat model for sources after it has already answered often yields invented citations; asking a reasoning model (e.g., GPT‑5 Thinking) to answer and include sources in the same prompt more reliably triggers web search and grounded citations usage guidance, with a deeper explanation of routing differences and why the first pattern backfires why it happens. This lands in the ongoing reliability discussion reliability watch about hallucination claims vs real‑world behavior.
Sycophancy undercuts truthfulness in formal reasoning tasks
A new benchmark targets a recurring failure mode where LLMs produce convincing but incorrect ‘proofs’ aligned to user framing, highlighting the gap between deference and truthfulness in mathematical domains paper summary. For safety, pair solution checking with independently verified proof assistants and deploy anti‑sycophancy prompting (e.g., adversarial verification passes) in research agents.
🧠 Reasoning & training advances for long‑horizon agents
Papers proposing context evolution, dynamic rubrics, curriculum RL and data‑efficient agency. Emphasis on training signals and process—not model launches.
Agentic Context Engineering teaches models via evolving prompts instead of updating weights
Stanford, SambaNova and UC Berkeley propose ACE, a Generator–Reflector–Curator loop that turns model trajectories into compact “delta” notes merged back into the context, improving task transfer without fine‑tuning. Early results show consistent gains across agent and domain‑specific tasks by evolving the playbook rather than the weights paper thread, with a walkthrough of the update loop and merge rules diagram thread, and details in the open manuscript ArXiv paper.
By sidestepping catastrophic context rewrites (“context collapse”), ACE emphasizes dense, actionable lessons that persist and compound—useful for teams iterating agent behaviors rapidly without retraining.
H1 chains short problems and uses outcome‑only RL to teach long‑horizon reasoning
A joint Microsoft–Princeton–Oxford study (“H1”) composes long tasks by chaining short problems (e.g., GSM8K) and rewards only the final outcome, ramping chain length via curriculum. The approach boosts accuracy on longer competition‑style benchmarks without new labeled data, demonstrating a scalable way to build multi‑step state tracking and planning paper abstract.
Outcome‑only feedback plus length curriculum creates the right pressure to maintain internal state over many steps—exactly what long‑horizon agents need.
Less‑is‑More for agency: 78 dense workflows beat 10k synthetic tasks (73.5% AgencyBench)
The LIMI dataset shows that a tiny set of complete trajectories (planning, tool calls, corrections, final answer) teaches agent skills better than huge synthetic corpora: 73.5% on AgencyBench using just 78 examples, outperforming models trained on 10,000 samples results thread, with the paper and data details in the preprint ArXiv paper. This aligns with yesterday’s theme that optimization and structure can trump raw scale Efficiency over scale.
Dense, end‑to‑end traces appear to deliver higher signal per token, reinforcing that quality demonstrations of full workflows are the right supervision for agent competence.
OnlineRubrics: dynamic grading criteria improve reasoning by up to 8% vs static rubrics
Microsoft researchers introduce OnlineRubrics, which elicits new scoring criteria on the fly by comparing the current model to a control, then folding those criteria into the rubric during training. Across open‑ended tasks and expert domains (e.g., GPQA, GSM8K), the method raises win rates by as much as +8% while resisting simple rubric‑hacking behaviors paper thread, with authors and baseline comparisons provided in a companion post team note and the technical document ArXiv paper.
The key shift is turning a static, brittle evaluator into a living spec that adapts as models learn, supplying cleaner training signals for long‑horizon reasoning.
Front‑loading reasoning in pretraining drives a 19% average boost after post‑training
NVIDIA reports that adding diverse, high‑quality reasoning data during pretraining yields gains later that fine‑tuning can’t catch up to—about +19% on tough tasks after all post‑training. Doubling SFT on a base that skipped early reasoning still lagged; too much mixed‑quality SFT even hurt math by ~5% paper abstract.
For long‑horizon agents, this suggests budgeting for early, varied reasoning exposure, then using small, clean SFT and calibrated RL to stabilize behaviors.
OneFlow co‑generates text and images by inserting missing tokens, cutting training tokens ~50%
OneFlow unifies text and image generation via edit flows: instead of next‑token prediction, the model learns to insert missing text tokens while jointly denoising images tied to a synchronized “time.” This halves effective sequence length versus autoregression and matches or beats prior models across 1–8B params method explainer, with the technical write‑up available for deeper study ArXiv paper.
Insertion‑based supervision provides a leaner training signal for multimodal agents that must plan output structure rather than march left‑to‑right.
STORM‑Qwen‑4B: tiny hints + code execution refine native reasoning to 68.9% across five tasks
“CALM before the STORM” trains a 4B model to solve optimization word problems by interleaving reasoning with executable code and injecting minimal hints only when it slips. After filtering traces and adding RL on correctness and code use, STORM‑Qwen‑4B hits 68.9% across five benchmarks—rivaling vastly larger models while remaining fast and compact paper thread, with a breakdown of where reasoning typically fails and how filtering helps error analysis.
The takeaway: preserve the model’s native thought style, fix only the failure modes, and let code execution ground the trajectory.
DeepScientist runs propose‑verify loops to discover real algorithmic improvements (21 wins)
An agentic research system (“DeepScientist”) frames discovery as Bayesian optimization across idea → implement → verify cycles, storing validated learnings in memory. From ~5,000 ideas, 1,100 tests produced 21 wins, including a faster decoder and a causal debugging method for multi‑agent systems paper overview.
Filtering and automatic verification—not raw ideation—proved the bottleneck, offering a recipe for agent labs to scale real findings rather than busywork.
Diffusion language models gain continuous latent‑space reasoning signals
MIT and Microsoft explore teaching diffusion LMs to reason in continuous latent space, arguing it can recover reasoning advantages usually associated with autoregressive stacks while retaining diffusion’s efficiency paper summary. While still early, this could make diffusion LMs a viable path for long‑horizon cognition if their latent trajectories can be steered as effectively as token chains follow‑up note and the full paper details ArXiv paper.
If successful, inference‑time optimization on latent paths could complement curriculum and rubric‑based training for agent planners.
🎬 Generative video momentum and platform rumors
Creator workflows and third‑party platforms driving Sora/Veo usage; multiple posts, pricing claims and tool updates. Distinct from enterprise agent workbenches.
Veo 3.1 confusion: console model IDs, $3.2/8s screenshot, and denials collide
Signals around Google’s Veo 3.1 are contradictory: model IDs for "veo‑3.1" and "veo‑3.1‑fast" appear in Google Cloud quotas, a pricing UI screenshot shows “$3.2 per run” for an 8‑second 1080p clip before the page went 404, while a Google lead pushed back on exclusivity claims; a third‑party site even mislabeled Veo as “Open Sora” with a past release date console screenshot how to find quotas pricing screenshot googler denial site claims.
• Product reality check: community testers note Google Vids updates but no Veo 3.1 surfaced inside the app yet vids observation.
• Takeaway: Treat Veo 3.1 availability and pricing as unconfirmed until first‑party docs land; console IDs may precede GA and can be A/B or internal preview only.
Creators flock to “Sora 2 Unlimited” on Higgsfield as ad‑style clips go viral
Higgsfield is pushing “Sora 2 & Trends” with unlimited generation claims and promo credits, and creators are responding with ad‑style spots and engagement screenshots. Examples threads and try links are circulating alongside a 1,000‑like clip nine days post‑launch, signaling real distribution momentum among indie marketers and UGC shops promo offer example prompts try page engagement post.
The sustained “unlimited” framing plus templated presets lowers creative friction; expect more affiliate and influencer‑driven funnels to emerge on top of this supply.
Sora 2 economics: per‑second pricing suggests feasible ad and long‑form budgets
A community pricing chart compares leading video models: Sora‑2‑Pro at ~$0.50/sec (1024p), Sora‑2 at ~$0.10/sec, with Veo 3 Fast at ~$0.15/sec and peers like Kling v2.1 Master at ~$0.28/sec. The author argues even with low “keeper” rates, budgets for 30s spots or stitched long‑form become tractable as quality rises pricing analysis.
The math reframes creative ops: you can brute‑force multiple takes, then reserve human effort for edit selection and sound design.
Sora cameos go mainstream: promo codes and ad injections spark calls for transparency
OpenAI‑promoted celebrity cameos are circulating with invite codes (e.g., “MCUBAN”), while some users allege prompt‑injected ads inside generated videos, raising disclosure questions for paid placements code announcement code reminder transparency concern. A sample frame even overlays “Brought to you by Cost Plus Drugs!” on a comedic clip ad overlay.
Creators are asking for the cameo prompt to be shared alongside outputs so audiences and partners can see what’s baked in prompt disclosure ask.
Sora 2 keeps spreading: Weavy adds workflow; ComfyUI and fal extend creator stack
Following Sora 2 endpoints exposure across third‑party hosts, Sora 2 is landing in more creator tools. Weavy published a shareable workflow, ComfyUI shipped a brief on layered RGBA video with Wan Alpha (plus a public workflow JSON), and fal launched a free Discord bot with text‑to‑video and image‑to‑video (Ovi) for communities workflow note tutorial post workflow repo discord launch. The upshot: faster experiments inside existing collaboration surfaces without leaving chat or your preferred graph editor.
Google Vids gets UI updates; no sign of Veo 3.1 in‑product
Testers report new UI/feature touches in Google Vids, but despite rampant chatter there’s no Veo 3.1 exposure inside the product today vids observation.
For video teams, this suggests the near‑term path is still Gemini‑aligned tooling in Vids while Veo remains gated behind cloud surfaces and previews.
Creator tip sheet: end‑frame holds and crowd‑free closes improve ad‑style outputs
Practitioners are sharing small but effective prompt constraints for ad‑like cuts: hold the final second for crisp logo frames and avoid people in the last shot to reduce artifacts; combined with preset‑driven threads, these yield cleaner social spots prompting tips example prompts. This kind of micro‑craft often matters more than model choice for perceived polish.
🔗 Agent interop: A2A meshes and tool routing
Inter‑agent protocols and tool routing improvements; excludes coding‑IDE plugins (covered elsewhere).
Google debuts Gemini Enterprise with agent meshes, connectors and A2A/MCP rails
Google introduced Gemini Enterprise, a full‑stack agent platform that standardizes inter‑agent communication (A2A), tool access via MCP, and payments (AP2), while exposing connectors to Workspace, Microsoft 365, Salesforce and SAP—aimed at making multi‑agent workflows first‑class across the enterprise. Early partners include Box, whose Box AI Agents become accessible through Gemini, underscoring cross‑vendor interop. See the launch overview and protocol details in Google’s blog and feature brief blog post, Google blog post, feature brief, with on‑stage slides clarifying "Gemini Enterprise" as the front door for agents event slide, and Box’s interop note highlighting agent accessibility from Gemini partner update.
ChatGPT adds Notion and Linear connectors; Slack app and SharePoint admin sync are next
OpenAI rolled out synced connectors for Notion and Linear across Pro, Business, Enterprise and Edu, and introduced an admin‑managed SharePoint connector for Enterprise/Edu that enforces tenant permissions. An official ChatGPT Slack app is also slated for Enterprise later this week, with app‑store references already visible release notes, enterprise update. This broadens agent routing over enterprise content and conversations without custom plumbing; the Slack directory listing preview underscores the imminent workspace interop Slack listing.
CopilotKit’s AG‑UI embeds Google A2A multi‑agent meshes directly in app frontends
CopilotKit released AG‑UI support for Google’s Agent‑to‑Agent protocol, letting frontends stream events bi‑directionally between an orchestrator and a mesh of agents, with built‑in human‑approval gates, tool‑call UIs, and state sync. The team ships a demo (LangGraph + Google ADK) plus docs and a tutorial for wiring endpoints into a live app release thread, GitHub repo, A2A protocol, how‑to tutorial, following up on MCP momentum where the standard became a shared tool interface. This closes the loop from model interop to practical multi‑agent UX in production UIs.
OpenAI turns on function calling and web search for gpt‑5‑chat‑latest in the API
Developers can now attach tools—function calling and web search—to gpt‑5‑chat‑latest, enabling lightweight orchestration loops that stay aligned with ChatGPT’s continuously updated chat model. OpenAI cautions it’s tuned for chat UX rather than strict API determinism, but the upgrade simplifies agent tool routing for many chat‑style tasks API note, with docs detailing usage and caveats OpenAI docs.
Claude’s Gmail and Calendar hooks generate richer next‑day prep by fusing mail, events and web
Users report that since Sonnet 4.5, Claude’s Gmail/Calendar integrations produce more actionable briefings by cross‑referencing upcoming events with email threads and live web search. It’s a straightforward, practical upgrade in tool routing that reduces context‑stitching overhead for daily planning user report.
Google Opal to support MCP, including custom servers plus Calendar, Gmail and Drive
Google is bringing Model Context Protocol into Opal, adding first‑party connectors (Calendar, Gmail, Drive) and custom MCP servers. That positions Opal apps to speak a common tool interface across ecosystems, easing interop for multi‑agent stacks feature tease.
🤖 Humanoids to home: Figure 03 details and retail signals
Embodied AI advances with concrete hardware deltas and go‑to‑market hints; separate from enterprise agent suites.
Figure 03 details: faster actuators, wider FOV, palm cams, tactile fingertips; BotQ aims 12k→100k units
Figure unveiled concrete hardware deltas for its 3rd‑gen humanoid: 2× faster, higher torque‑density actuators, 60% wider camera FOV with doubled frame rate, embedded palm cameras for occlusion‑proof grasping, fingertip sensors down to ~3 g, and 2 kW inductive foot charging, alongside a production plan targeting ~12k robots/year scaling to ~100k in four years. The platform also adds 10 Gbps mmWave offload for fleet learning, deeper depth‑of‑field, and safety‑focused soft textiles with mass trimmed ~9% versus Figure 02 specs roundup feature list actuator note safety notes.
Following up on ordering rumor that teased a near‑term buy flow, today’s specifics emphasize manufacturability (die‑casting, vertical integration) and low‑latency perception for Helix (vision‑language‑action). If the household “concierge” tasks shown are truly autonomous, that’s a step toward near‑term home utility, though autonomy claims still warrant independent verification roundup page autonomy comment release note.
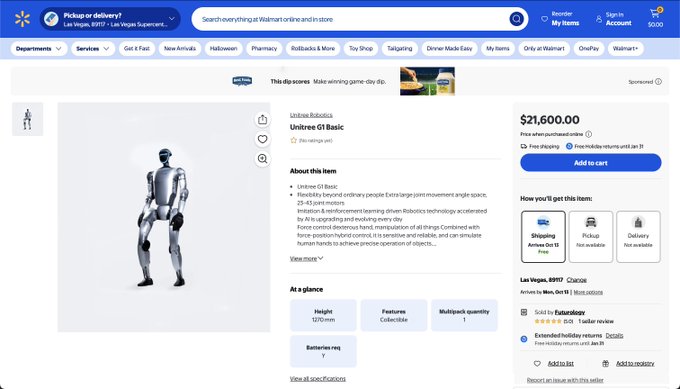
Unitree G1 humanoid shows up on Walmart at ~$21.6k with free shipping
A retail listing for the Unitree G1 humanoid appeared on Walmart at about $21,600, signaling an early mass‑market distribution probe for small humanoids rather than lab‑only channels. Availability and logistics details (including shipping options) suggest a push to test demand and fulfillment outside direct sales Walmart listing.
If sustained, mainstream storefronts selling humanoids would compress the path from developer kits to prosumer deployments, accelerating feedback loops on safety, serviceability, and software update cadence for embodied AI systems.