Karpathy pegs AGI 10 years out – agents still miss 4 basics
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Andrej Karpathy’s long sit‑down with Dwarkesh Patel landed, and it’s a cold shower for agent hype. He says AGI is roughly 10 years away and calls today’s agent demos “slop,” arguing teams should stop pitching autonomous coworkers and start fixing fundamentals. His checklist is blunt: reliable computer use, true multimodality, durable long‑term memory, and continual learning—four gaps that keep agents from real jobs. He even frames the macro impact as blending into ~2% GDP growth, not a flashy singularity.
The critique cuts into current methods. Reinforcement learning, he says, pushes a single reward back through every token—“sucking supervision bits through a straw”—which uplifts spurious steps and weakens learning. Naive synthetic self‑study looks smart but collapses diversity, producing near‑identical reflections that make models worse. His “cognitive core” proposal flips the architecture: keep small onboard memory for algorithms of thought, push facts to retrieval and tools, and treat human‑style forgetfulness as a feature that forces generalization. Self‑driving’s long‑tail delays loom as the cautionary tale for software agents: expect grindy iteration, not clean takeoff curves.
For builders, the takeaway is pragmatic: scope to narrow, verifiable workflows with strong guardrails, invest in environment control and state management, and consider role‑specific RL where parity may arrive sooner than with generalist agents.
Feature Spotlight
Feature: Karpathy’s agent reality check reshapes near‑term roadmaps
Widely shared Karpathy interview argues today’s agents aren’t ready as coworkers; AGI likely ~10 years out. Sets expectations for leaders on where to invest (memory, tools, multimodality) vs overpromising.
Cross‑account coverage of the Dwarkesh x Karpathy interview dominates today: agents called “slop,” AGI ≈ decade away, RL limits, and gaps (memory, multimodality, continual learning). Implications for how teams scope agents now.
Jump to Feature: Karpathy’s agent reality check reshapes near‑term roadmaps topicsTable of Contents
🧭 Feature: Karpathy’s agent reality check reshapes near‑term roadmaps
Cross‑account coverage of the Dwarkesh x Karpathy interview dominates today: agents called “slop,” AGI ≈ decade away, RL limits, and gaps (memory, multimodality, continual learning). Implications for how teams scope agents now.
“Agents are slop”: Karpathy warns the industry is overstating agent capability
Karpathy says current AI agents are being oversold—"it's slop"—and suggests hype may be influenced by fundraising incentives; he stresses that core intelligence, robust tool use, and persistence aren’t there yet. The pull‑quote and clip are here quote clip with the exact timestamp in YouTube timestamp.
Implication: scope agent projects to narrow, verifiable workflows with strong guardrails rather than marketing them as autonomous coworkers.
Karpathy’s full Dwarkesh interview drops: AGI ≈ a decade away, agents not work‑ready
Dwarkesh Patel published a chapterized conversation with Andrej Karpathy in which he projects AGI is still roughly ten years out and argues today’s agents aren’t ready for real jobs. The discussion sets expectations for gradual impact rather than sudden step‑changes and frames concrete gaps teams must close next. See the chapter list and timestamps in chaptered episode and the long‑form video in full episode.
For roadmaps, the talk emphasizes prioritizing computer use, multimodality, long‑term memory, and continual learning over headline demos.
RL critique: “sucking supervision bits through a straw” vs human learning
Karpathy argues reinforcement learning broadcasts a single end‑reward across every token in a trajectory—“sucking supervision bits through a straw”—uplifting spurious steps and yielding weak learning signals compared to how humans learn and self‑organize knowledge. He calls for research stages where models “think through” material during pretraining but notes naive synthetic reflections can degrade models. Details and examples in thread highlights.
“Cognitive core” idea: remove most memory so models must look up facts and focus on algorithms of thought
Karpathy suggests LLMs are over‑distracted by their pretraining memorization; he’d prefer small onboard memory plus retrieval, keeping the “algorithms for thought” in‑model and pushing facts to tools. He frames human forgetfulness as a feature that forces generalization—guidance for architecting agents with retrieval‑first designs thread highlights.
Synthetic self‑study collapses diversity; maintaining entropy is a live research problem
Asked why LLMs can’t just self‑generate reflections on a book and train on them, Karpathy says outputs look reasonable but collapse to near‑identical responses on repeated prompts, eroding diversity and making models worse. The open problem is generating high‑entropy, non‑collapsed synthetic traces that actually help generalization thread highlights.
AGI won’t feel like a singularity; it likely blends into ~2% GDP growth
Rather than an overnight discontinuity, Karpathy argues progress will be absorbed into baseline economic growth and business process re‑engineering, tempering near‑term expectations while still pointing to large compounding value chaptered episode. For planning, favor incremental automation that slots into existing orgs over moonshots.
Learning analogies: kids vs adults, and dreaming as anti‑overfitting for generalization
Karpathy uses human analogies—children’s high‑entropy exploration vs adults’ collapsed thought loops—and notes work arguing dreams aid generalization by fighting overfit; the upshot for engineers is to bias agent training toward exploration and diversified traces rather than memorization‑heavy loops thread highlights.
Self‑driving delays as a cautionary tale for agent timelines
Karpathy reflects on why self‑driving took longer than early forecasts and implies the same long‑tail realities apply to software agents—edge cases, brittle perception, and compounding tool friction—suggesting leaders budget for iteration and evaluation at scale chaptered episode.
Community split: decade‑long AGI vs near‑term claims
The interview rekindled debate between researchers expecting near‑term AGI and Karpathy’s decade‑scale forecast; skeptics ask who to trust while emphasizing tangible capability gaps in agents today debate thread, decade headline.
Job‑specific RL may reach parity sooner than general agents, argue some commentators
Reacting to Karpathy, some suggest RL‑trained, role‑specific LLMs could hit human‑level performance in narrow knowledge jobs well before generalist agents, reinforcing a near‑term strategy of verticalized workflows over universal “employees” analysis.
🛠️ Agentic coding: Codex IDE surge, Claude Code Q&A, early web
Dense stream of practical agentic‑coding updates: OpenAI Codex IDE extension, new 0.47.0 build, real‑world reviews; Claude Code adds interactive questions and a web preview. Excludes Karpathy discourse (covered in the feature).
OpenAI ships Codex IDE extension for VS Code, Cursor and Windsurf
OpenAI’s new Codex IDE extension brings agentic coding into mainstream editors, with install paths for VS Code today and guidance for Cursor and Windsurf. The extension ties into Codex cloud runs and the existing CLI/SDK, letting developers plan, edit, run and review from inside the editor environment. See install links and docs in release note, VS Code extension, and broader guides in developer docs and a walkthrough demo in demo video.
Compared to the CLI, the IDE flow emphasizes context‑aware diffs and async delegation while keeping repository navigation and reviews in one loop; it also aligns with OpenAI’s push to route tasks between local and cloud sandboxes described in the documentation product page.
Claude Code for web surfaces as early preview with cloud sessions
An org‑level “Claude Code in the Web” toggle and screenshots point to a split‑pane cloud IDE preview where members can create/browse coding sessions and pick environment types. Session history and partial CLI parity are expected, with CAPTCHA handling likely for Google Meet‑style joins. Following up on General agent shift, this moves Claude Code beyond terminals into browser‑hosted execution settings screenshot, with a feature writeup and screenshots in preview article and more details in feature article.
For teams, a hosted IDE can standardize sandboxes, enable skill packs, and simplify onboarding compared to per‑dev local setups.
Claude Code now asks clarifying questions during plan mode
Anthropic added interactive Q&A inside Claude Code, with the model pausing to ask targeted questions—especially in Plan mode—when specs are ambiguous or multiple paths exist. Teams can nudge more inquisitive behavior via project guidance and skill prompts, and it works across planning and execution flows feature brief, author note, docs page.
This reduces rework in large edits and aligns with the Skills paradigm (progressive disclosure of instructions and scripts) that landed this week; combined, they help Claude “load the right playbook, then confirm assumptions” before touching code.
Codex v0.47.0 lands; community compiles changelog before official notes
OpenAI’s Codex hit v0.47.0, with early users updating and running before official release notes dropped. Community maintainers compiled changes from commits—new /name for chat sessions, parallel file search, MCP improvements and stability fixes—while the GitHub release tag appeared shortly after version update, compiled changelog, release page.
Some Pro users briefly hit weekly caps during long sessions before limits refreshed, a reminder to size work between High and Medium “thinking” tiers when possible plan limit screen.
Hands‑on: Codex CLI crushes long runs; queues, huge context, minimal chat
A two‑day practitioner report details Codex CLI pushing ~6k lines across multiple sessions with generous limits, deep context that “feels like it goes on forever,” a minimalist TUI, and an addictive prompt queue that keeps flow going while jobs run. Wishes include plan‑mode, easier model toggles, and background commands; UI work noted around sandbox permission prompts and shadcn UI struggles deep dive.
The author briefly hit Plus limits mid‑run but upgraded to Pro and resumed minutes later, reinforcing the value of batching work and watching /status during multi‑hour refactors plan limit screen, limit cleared.
Cursor Nightly tests a background agent to run after the plan
Cursor’s nightly builds expose a “Background” option next to Agent, hinting at post‑plan autonomous execution with less foreground churn. It fits a broader trend of letting agents explore in parallel and report back, while preserving deterministic checkpoints for merges UI screenshot.
Expect more IDEs to offer explicit background/parallel modes as plan‑first workflows become standard across Codex, Claude Code and competitors.
Zed ships on Windows and adds native Codex via ACP
The Zed editor’s October release brings first‑class Windows support plus native OpenAI Codex integration over ACP, alongside quality‑of‑life updates like action sequences and faster project panel refresh. The team published stable release notes and a Windows launch blog to get developers onboarded quickly stable releases, blog post, ACP note.
For agentic coding stacks, ACP keeps Codex tool calls snappy inside Zed without extra glue, and Windows support broadens install bases for mixed‑OS teams.
Cursor adds one‑command install for the Codex extension
Cursor users can now install OpenAI’s Codex extension in one step via the CLI (cursor --install-extension openai.chatgpt@0.5.20), making it easier to standardize environments across teams. A follow‑up shows what a successful install looks like in the UI install command, installed view.
This complements the IDE marketplace release and reduces friction for orgs that manage extensions through scripts and dotfiles.
GLM 4.6 “Coding Plan” lights up inside Claude Code for some users
Developers report Claude Code running GLM 4.6’s “Coding Plan” path, calling out smoother/snappier planning with the latest model wiring. While anecdotal, it reflects growing heterogeneity in agent backends as teams route plan vs. implement to different models dev experience.
If sustained, this suggests editor agents will increasingly broker multiple reasoning profiles (fast plan vs. deep refactor) behind a single UX.
🧩 Interoperability & MCP: enterprise connectors and hosting patterns
MCP solidifies as an enterprise surface: ChatGPT Business/Enterprise/Edu get full MCP beta; devs discuss gateway routers, better tool output, and sandboxed agent hosting. Excludes Codex/Claude IDE specifics (covered in coding).
OpenAI enables full MCP in ChatGPT for Business/Enterprise/Edu with Developer Mode and RBAC
OpenAI switched on full Model Context Protocol support in ChatGPT for Business, Enterprise, and Edu, adding a Developer Mode for private connector testing and org‑level RBAC so admins can control who builds and publishes action‑capable connectors (beyond read/search to write/modify workflows). Details include publishing gates, workspace settings, and safety guidance in the rollout note OpenAI help center, echoed by an admin brief highlighting the same controls admin note.
How to host Claude agents: sandboxed containers, ~$0.04–$0.05/hr, and ready‑made providers
Anthropic shared a concrete hosting pattern for the Claude Agent SDK: run each agent in a sandboxed container with filesystem and bash access for Skills, with typical runtime cost around $0.04–$0.05 per hour and vendor options including AWS, Cloudflare, Vercel, Modal, Daytona, E2B, and Fly.io how‑to thread, hosting docs. The guidance also covers long‑running tasks and per‑user isolation; in context of engineering docs, which laid out the Skills schema and best practices, this closes the loop on how to deploy Skills‑powered agents safely at scale cost note, code overview.
OSS ‘MCP Gateway’ will unify multiple MCP servers behind one endpoint
An open‑source “MCP Gateway” is slated for release to consolidate many MCP servers into a single addressable endpoint, simplifying client configuration and enterprise ops for tool fleets and shared infra gateway tease. This pattern reduces client/tool sprawl, centralizes auth/policy, and enables per‑tenant routing without changing downstream MCP servers.
RepoPrompt improves MCP tool UX: cleaner markdown output and a readable file_search view
RepoPrompt’s MCP tools now render output in clean markdown inside agent UIs, with a revamped file_search that shows inline, human‑scannable matches—making results easier for both users and models to consume tool preview. The author notes better benchmark behavior when tools present structured, readable outputs instead of machine‑oriented strings author note.
⚙️ Serving & routing: multi‑model routers and diffusion LLM speedups
Runtime news centers on model routing and decoding: HuggingChat Omni auto‑selects among 100+ OSS models; new training‑free techniques accelerate diffusion LLMs; GLM 4.6 perf claims surface. Focused on infra/runtime, not IDEs.
HuggingChat Omni launches auto-routing across 100+ open models, powered by a 1.5B router
Hugging Face introduced HuggingChat Omni, which dynamically routes each prompt to the best of 100+ open models at inference time, aiming for better cost/latency/quality without user micromanagement product post. The router is the open Arch‑Router‑1.5B from Katanemo, shared alongside the announcement for transparency and reproducibility Hugging Face model.
Beyond convenience, this normalizes multi‑model operations: teams can standardize on one chat entry point while the backend switches between gpt‑oss, DeepSeek, Qwen, Gemma, Aya, smolLM and more based on request traits feature recap.
dInfer framework pushes diffusion LLMs to 800–1100 tok/s with training‑free decoding tricks
Ant Group/Inclusion AI’s dInfer reorganizes diffusion LLM decoding into four swappable parts (model, iteration manager, decoder, KV manager) and adds three training‑free optimizations—iteration smoothing, hierarchical/credit decoding, and vicinity KV refresh—to reach 1100+ tok/s on HumanEval and ~800 tok/s across six tasks, beating fast dLLM by ~10× while matching quality paper thread.
Because it targets single‑sequence latency (not batch hiding), dInfer is directly relevant for interactive agents that need consistent sub‑second response times paper thread.
Elastic-Cache speeds diffusion LLM decoding by up to 45× via selective KV refresh
A new decoding method for diffusion LLMs refreshes KV caches only where attention has drifted, leaving stable parts intact; combined with a sliding window and layer‑wise recompute, this yields up to 45× faster decoding without retraining or quality loss on math, code and multimodal tasks paper thread. The approach is training‑free and architecture‑agnostic, making it drop‑in for existing diffusion LLM deployments.
Practically, Elastic‑Cache reframes KV cache as an adaptive resource: drift thresholds determine when to recompute deep layers, cutting latency while keeping answers consistent across steps paper thread.
GLM 4.6 tops Artificial Analysis provider speedboards with 114 TPS and ~0.18s TTFT
Baseten reports GLM 4.6 as the fastest provider on Artificial Analysis’ reasoning tests at 114 tokens/sec and clarifies a typo to ~0.18 s time‑to‑first‑token (TTFT) in prod provider claim, typo correction, with public rankings available for verification benchmarks chart. This follows KV routing gains where Baseten showed ~50% lower latency and 60%+ higher throughput after adopting NVIDIA’s Dynamo KV‑cache routing, underscoring how stack‑level optimizations translate into leaderboard speed.
vLLM adds MFU tracking to core engine for on‑device utilization insight
A new PR adds MFU (model FLOP utilization) analysis modes to vLLM, exposing either fast estimates or detailed graph‑based accounting and roofline data so teams can spot throughput headroom and bottlenecks during serving PR details. This helps production operators quantify real efficiency gains from routing, KV caching, and quantization changes without external profilers.
📊 Evals: FrontierMath ceilings and lightweight reasoning comps
Epoch publishes an intensive FrontierMath analysis (caps, pass@N, kitchen‑sink at 57%); side threads compare ChatGPT Agent scaling; Haiku 4.5 matches early reasoning models without “thinking,” often 5× faster.
GPT‑5 looks capped below 50% on FrontierMath after 32 runs
Epoch’s 32‑run study finds sub‑logarithmic pass@N gains for GPT‑5 on FrontierMath, with an extrapolated ceiling under 50% and diminishing returns per doubling of attempts model scaling chart, run details. A targeted follow‑up on 10 previously unsolved problems produced 0 solves across 100 more tries, reinforcing the limit unsolved batch. Full write‑up and plots in Epoch’s analysis Epoch post.
Why it matters: pass@N saturation suggests next‑gen improvements must raise “solve once” feasibility or reliability per problem, not just sample more.
“Kitchen‑sink” aggregation hits 57% solved; ChatGPT Agent adds unique wins via web search
Pooling 52 model runs from the hub, 16 ChatGPT Agent runs, one Gemini 2.5 Deep Think, and 26 mostly o4‑mini runs yields 57% of FrontierMath Tiers 1–3 solved at least once (pass@the‑kitchen‑sink) runs collected, aggregation note. ChatGPT Agent contributes the most unique solves, likely because web search is allowed for the benchmark agent unique solves.
Implication: the reachable set today is larger collectively than any single model suggests, and tool use (search) materially expands coverage.
Epoch projects an all‑in ceiling near 70% by H1’26; ChatGPT Agent alone likely <56%
Extrapolating current curves, Epoch estimates an “all‑in” cap around 70% solved with many models and many runs, versus today’s best single‑model pass@1 near 29% cap estimate, trend line. Separately, scaling just ChatGPT Agent appears to cap below 56% based on 16‑run behavior agent cap curve, with more details in the Gradient Update analysis thread, Epoch post.
Read: expect near‑term gains to come from reliability on already‑reachable problems, not wholesale expansion of the frontier.
Haiku 4.5 rivals early “reasoning” models without thinking and runs ~5× faster in tests
Epoch reports Claude Haiku 4.5, with reasoning disabled, performs similarly or better than early lightweight “reasoning” models (e.g., o1‑mini) across several evals, and clocked ~5× faster runtime on a Mock AIME run in their setup eval post, benchmark hub, comparison note, following up on Haiku evals where ARC‑AGI results and mixed task spread were logged.
Takeaway: careful execution and smaller, fast models can match first‑wave reasoning‑branded baselines—useful for latency‑sensitive workflows and plan‑then‑execute agents.
🧪 Training science: quantized RL, memory actions, and token credit
Today’s research drops emphasize cheaper/more stable post‑training and finer credit assignment. Several are training‑time; others are policy shaping. No overlap with runtime serving or evals categories.
NVIDIA’s QeRL: quantized RL with adaptive noise trains 32B models on a single H100
QeRL combines NVFP4 quantization with LoRA and introduces adaptive quantization noise so the noise doubles as exploration during RL, yielding ~1.8× faster training than QLoRA while matching full fine‑tune quality on GSM8K (90.8%) and MATH‑500 (77.4%). It reports single‑GPU feasibility for 32B models on H100 80 GB, and releases code. See the key details in the breakdown and paper, plus the repo for implementation. method overview ArXiv paper GitHub repo
RL scaling laws solidify with 400k GPU‑hours and predictive curves to 100k+ hours
Following up on ScaleRL, the study adds evidence that sigmoid compute→performance curves let you extrapolate large RL runs from small pilots; the team ran >400,000 GPU‑hours and shows accurate predictions out past 100,000+ GPU‑hours, with a recipe that outperforms DeepSeek, DAPO, Magistral and MiniMax on asymptotic score and efficiency. Charts and discussion highlight the ceiling vs efficiency split. paper overview community summary
Attention “preplan‑and‑anchor” rhythm enables fine‑grained token credit in RL
Analyzing attention heads reveals local “chunk opener” tokens and global “anchors” that downstream steps repeatedly attend to. Optimizing RL to boost credit on these critical nodes—and to shift some credit from anchors back to their openers—improves math, QA and puzzle tasks, especially on 8B models, over uniform or uncertainty‑only credit. Visuals and method details are in the paper explainer. paper overview
Memory‑as‑Action trains agents to edit their context on the fly for long‑horizon gains
This framework makes memory operations first‑class actions—keep, compress, summarize, delete—so the policy learns when to curate working memory during multi‑step tasks, improving accuracy and cutting tokens per turn. Training splits runs at each memory edit and assigns end rewards with token‑efficiency penalties, yielding stronger performance on multi‑goal tasks while lowering input cost. paper thread
Microsoft’s BitNet Distillation turns FP LLMs into 1.58‑bit models with near‑parity task scores
BitDistill fine‑tunes off‑the‑shelf full‑precision LLMs into 1.58‑bit (ternary) BitNet variants that retain comparable accuracy to FP16 while cutting memory and boosting tokens/sec, via a pipeline that includes SubLN, MiniLM‑style attention distillation, and a short continual pre‑train warmup. Bench charts in the paper show strong accuracy vs large FP baselines alongside faster inference and lower RAM. paper summary Hugging Face paper
Token‑level credit assignment and memory curation emerge as levers for cheaper post‑training
Taken together, today’s papers point to two controllable knobs for post‑training: (1) explicitly rewarding the “plan” and “anchor” tokens that structure reasoning, and (2) teaching agents to prune and rewrite their own working memory during the task to keep context budgets down. These interventions drive measurable gains without brute‑force compute, complementing quantized RL and distillation paths. See the attention‑credit work and the memory‑as‑action policy design for concrete recipes. attention method memory actions
AEPO balances entropy to stabilize agent RL and lifts pass rates across 14 datasets
Agentic Entropy‑Balanced Policy Optimization tackles over‑branching and unstable gradients by (1) dynamically allocating rollout budget and penalizing consecutive high‑entropy tool calls, and (2) clipping and rescaling high‑entropy token gradients with entropy‑aware advantages. With just ~1k RL samples on Qwen3‑14B, AEPO reports GAIA Pass@1 47.6% (Pass@5 65.0%), Humanity’s Last Exam 11.2% (26.0%), and WebWalker 43.0% (70.0%). paper card
Blend “thinking” and “instruct” weights to dial reasoning depth without retraining
Simple weight interpolation between a Thinking model and an Instruct model exposes three regimes: low‑blend behaves like Instruct (short answers, modest gains); mid‑blend suddenly turns on explicit CoT with quality jumps (sometimes fewer tokens); high‑blend induces thinking on every input with rising token cost and flattening returns. Most of the “thinking” behavior resides in later layers; FFNs trigger thinking while attention sharpens correctness. paper overview
Thinking tokens don’t help machine translation; stronger targets and drafts do
Across many language pairs, adding hidden “thoughts” before answers yields little to no MT quality gain; training small students to imitate step‑by‑step traces also lags simple source→target training. Helpful intermediate signals only appear when the traces include draft translations, implying the real win is more and better parallel text (or teacher targets), not generic reasoning steps. paper first page
🗺️ Grounded retrieval: Google Maps in Gemini and multi‑modal RAG
Data/grounding news skews practical: Maps grounding in Gemini API unlocks place‑aware agents; multi‑modal RAG frameworks and parsing tips surface. Excludes IDE updates and evals.
Gemini API adds Google Maps grounding for 250M+ places
Google brought live Maps grounding to the Gemini API, letting apps reason over up‑to‑date data from 250M+ places and stitch maps + search into one experience feature overview, with demos in AI Studio and full docs for tool use Google blog post, AI Studio post, demo app, and API docs. This unlocks place‑aware agents for itineraries, logistics, field ops, and storefront discovery without custom scraping or stale POI caches.
RAG‑Anything: cross‑modal retrieval that preserves structure
A new framework proposes a dual‑graph + dense search approach to retrieve across text, images, tables, and formulas without flattening documents into lossy text paper thread. It models cross‑modal layout (figure–caption, row–column, symbol references) alongside semantic links, walks the structure graph to fetch related chunks, merges with embedding hits, then rebuilds grounded context for a VLM to answer. The payoff is higher recall and cleaner answers on long mixed‑content docs, where preserving headers, units, and panel links matters most.
Claude’s PDF Skill is basic; use LlamaParse for complex docs
A practitioner review shows Claude Code’s built‑in PDF Skill relies on PyPDF + reportlab and will crack on scans, complex tables, and charts; for production‑grade parsing, swap in LlamaParse via semtools or drop the SDK reference into a custom Skill practitioner note. This preserves structure for downstream RAG and form‑filling while keeping Skills’ progressive disclosure and low‑token footprint.
Document parsing pitfalls and fixes for production RAG
A field session recaps where RAG pipelines fail—scans, handwriting, stamps/watermarks, checkboxes, layout drift, and chart extraction—and recommends a blended stack: specialized models per region, strong layout detection, grounded citations, and benchmarking on heterogeneous corpora at scale session recap. Treat parsing as a first‑class component (not a pre‑step), wire chart/table extractors, and validate with references to build trust in answers.
🎬 Creator stacks: Veo 3.1 control, Reve distribution, image editing ranks
Large volume of creative tweets: Veo 3.1 camera movement guidance and scene extension; Sora 2 samples; Reve models on fal/Replicate; Image Arena rankings. Carved out to avoid crowding core engineering beats.
Gemini shares concrete Veo 3.1 camera move prompts and shot recipes
Google’s Gemini team published ready‑to‑use prompt patterns for Veo 3.1—covering pan, tilt, dolly, tracking, handheld, and even top‑down crane moves—plus examples for over‑the‑shoulder dialogue and slow push‑ins, making cinematic control far easier in practice camera tips, crane prompt, dialogue recipe, push‑in example. Following up on prior prompts which showcased micro‑detail realism, Gemini also points users to the Veo 3.1 page for immediate creation and sharing Gemini Veo page, with additional tilt‑down guidance to highlight hands and subtle emotion tilt example.
Reve image models expand distribution on Replicate and fal with strong early results
Reve’s models are now available both on Replicate and fal, widening access to text‑to‑image, high‑fidelity editing, and accurate text rendering workflows Replicate page, fal launch. Early showcases highlight spatially aware multi‑image layouts and robust edit pipelines, signaling a credible alternative for design and brand tasks that need crisp type and consistent structure capability overview.
Creator leaderboards: Riverflow 1 holds #1 on Image Editing; Microsoft’s MAI‑Image‑1 enters top‑10 text‑to‑image
Artificial Analysis shows Sourceful’s Riverflow 1 on top of the Image Editing board (ELO 1217), edging Google’s Nano‑Banana (Gemini 2.5 Flash) and ByteDance’s Seedream 4.0 editing leaderboard. In parallel, Microsoft’s new MAI‑Image‑1 debuts at #9 on the Text‑to‑Image board with 4,091 votes, indicating a credible first showing among established contenders text‑to‑image rank.
LTX Studio pairs Veo 3.1 with start/end frames to animate stills and inject dialogue
LTX Studio integrated Veo 3.1 and shows a simple creative loop: generate stills, then animate by setting start/end frames—handy for keeping identity and staging while layering dialogue cues into the shot teaser tutorial. The walkthrough shares stills to start from and then flips to animation using Veo’s new controls, a pattern many creators can reuse to prototype shorts quickly stills post.
Scene extension and image‑grounded shots with Veo 3.1 move from tips to repeatable workflows
Creators are converging on a clear Veo 3.1 pattern: generate an initial clip, drop it into a scene builder, and use “Extend” with a targeted prompt to carry motion and tone across longer shots scene extension thread, prompt sample. Replicate’s guide complements this with practical prompting and reference‑image conditioning steps to keep characters and style consistent across cuts Veo 3.1 guide. One demo even grounds a scene from a map image to guide what unfolds at a specific location, underscoring Veo’s strengthened visual conditioning image prompt demo.
Open alternative: ComfyUI adds Ovi for text→video+audio generation in one pass
Character.AI’s Ovi, built on WAN 2.2 + MMAudio, now runs inside ComfyUI, outputting synchronized video and audio from a single prompt—an accessible open stack for creators who want local or composable nodes instead of closed services Ovi brief, Ovi link.
Sora 2’s 25‑second raw output clips circulate as creators iterate on storyboarded prompts
Creators are sharing straight 25‑second Sora 2 outputs to benchmark motion quality and adherence, while building small tools and workflows (e.g., storyboard‑driven prompting) to steer pacing and shot composition for longer clips raw clip, storyboard workflow.
🏗️ AI factories, power, and geopolitics
Infra/economics items: multi‑GW AI sites, regional partnerships, and capex math. Keeps focus on AI compute supply/demand. Avoids product and eval duplication.
OpenAI’s compute‑heavy financing structure surfaces alongside ~$500B valuation talk
Following up on server budget (~$450B by 2030), a new FT summary describes a working split that could leave Microsoft, employees and the nonprofit each near ~30% ownership, and a NVIDIA arrangement granting ~$10B in equity per ~$35B GPU purchases (up to ~$100B); OpenAI has also lined up 6 GW with AMD (from 2H26) and a Broadcom collaboration targeting another ~10 GW of custom accelerators FT summary.
If realized, this “equity‑for‑compute + multi‑vendor GW” posture would hard‑wire supply for frontier models while diluting stakes—shifting competition toward energy siting, training run orchestration and inference economics.
NVIDIA says China AI GPU share fell from ~95% to 0% amid export controls
Jensen Huang framed a “temporary goodbye” to China’s AI market, stating NVIDIA’s share there dropped from ~95% to 0%, as export rules push buyers toward domestic stacks such as Huawei Ascend clusters and tailored interconnects event quote. The remark underscores how policy can abruptly rewire global AI supply chains, with implications for model training timelines and cross‑border software ecosystems.
Poolside and CoreWeave plan “Horizon,” a 2‑GW AI data center in West Texas with on‑site power
Poolside is partnering with CoreWeave to build a self‑powered, 2‑gigawatt AI compute campus on a 500‑acre ranch in West Texas, tapping nearby natural gas to bypass grid constraints; the company is also raising ~$2B at a ~$14B valuation and expects initial access to NVIDIA GPUs via CoreWeave in December project summary.
For AI builders, this signals continued verticalization of power + compute: dedicated energy sources co‑sited with multi‑GW clusters to cap costs and avoid interconnect delays.
Goldman: Hyperscalers on track for ~$300B AI‑driven datacenter capex in 2025
Goldman Sachs research indicates Google, Amazon, Microsoft and Meta together will spend on the order of $300B on datacenter capex this year, with hyperscaler capex‑to‑cash‑flow ratios rising versus the 2000 TMT cycle capex chart.
For AI teams, this suggests continued availability growth of accelerators, optical links and power shells—but also sustained pressure on utilization, routing and energy‑efficiency tooling to keep ROIC in range.
Groq partners with Aljammaz to bring low‑latency AI inference across the Middle East
Groq announced a regional distribution and delivery partnership with Aljammaz Technologies to expand GroqCloud and GroqRack deployments across MENA, aligning its LPU‑based inference platform with local system integrators at GITEX Global 2025 launch note, with details in the company’s newsroom Groq blog post.
Expect easier regional procurement and support paths for sub‑second RAG/agent workloads where network and energy constraints make throughput‑per‑watt critical.
Oracle Cloud to deploy 50,000 AMD Instinct MI450 accelerators starting 2026
Oracle said OCI will add 50k AMD Instinct MI450 GPUs beginning in 2026, signaling a broader multi‑vendor accelerator strategy beyond NVIDIA for AI training and inference capacity deployment note. For practitioners, cross‑ISA portability (CUDA‑to‑HIP/ROCm) and performance parity on BF16/FP8 math will matter for scheduling and cost arbitrage across clouds.
Stargate UAE: G42 and Khazna build a 1‑GW hyperscale AI cluster in the desert
UAE’s G42 and Khazna Data Centers are racing to stand up “Stargate UAE,” a 1‑gigawatt AI campus with vendor partnerships spanning OpenAI, NVIDIA, Oracle, Cisco and SoftBank, positioning the region as an emerging AI compute hub site photo.
Localized mega‑clusters reduce intercontinental latency and diversify supply, but raise coordination needs for model licensing, sovereign data residency and export controls.
💼 Enterprise traction: Claude Code revenue, bank deployments, payments
Commercial signals: Anthropic revenue trajectory with Claude Code nearing $1B ARR line item; top‑5 bank deploys Amp Enterprise; payments localization for growth. Business–not infra–angle only.
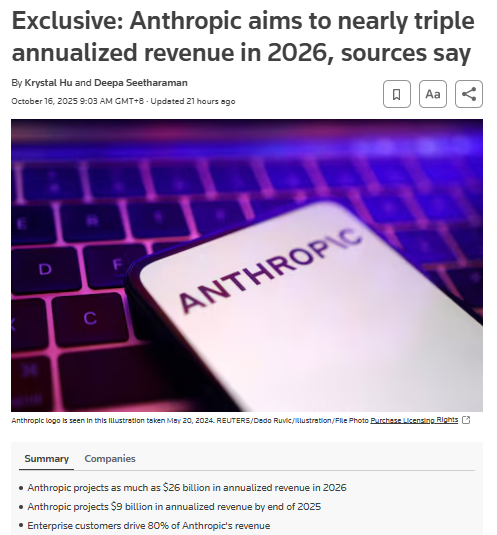
Anthropic targets $20–$26B 2026 revenue; ~80% enterprise, Claude Code nears $1B ARR
Anthropic is projecting an annualized $20–$26B in 2026 off a ~$9B run rate by year‑end 2025, with ~80% of revenue from enterprises and Claude Code by itself approaching ~$1B ARR revenue targets.
Following up on ARR snapshot, this update adds the first explicit split: 300k+ businesses are using Claude and the coding assistant is becoming a standalone line item near the billion‑dollar mark—evidence that agentic coding is converting to paid seats at scale revenue targets.
Top‑5 US bank deploys Amp Enterprise to ~10% of engineers, signaling mainstream agent adoption
A top‑5 US bank purchased Amp Enterprise for ~10% of its developer population, which the vendor says will soon be the largest frontier coding‑agent deployment at a major US bank bank purchase. The move pairs a sizable paid rollout with the public Amp Free offering, which is open for weekend hacking and awareness building free tier note. For AI leaders, this is a concrete proof point that regulated enterprises are piloting coding agents in material, team‑sized cohorts rather than isolated POCs.
Julius adds UPI payments in India to accelerate local conversion
Julius enabled UPI at checkout for Indian customers, removing card frictions and letting users switch to UPI in billing settings within seconds payments update. The team contextualized the move with a charted 1,200× surge in monthly UPI volume since 2016—now ~20B transactions—underscoring why local rails matter for AI SaaS expansion upi growth chart.
🧪 Model roadmaps & leaderboards
Light model‑release day: signals around Gemini 3.0 timing and a Microsoft image model’s leaderboard placement. Excludes router/runtime items and creative distribution (covered elsewhere).
Signals converge on Gemini 3.0 shipping this year, with multiple reports pointing to December
Multiple independent reports say Google is targeting a December release window for Gemini 3.0, after Sundar Pichai publicly committed to shipping the model this year and described it as a “more powerful AI agent.” See the timing claim and wording in coverage, and a press recap with the CEO quote. timing claim, Techzine report
If the schedule holds, expect a step‑function in agent capabilities aligned to Google’s app and API ecosystem rather than a quiet incremental rev—positioning that will shape Q4 competitive roadmaps for OpenAI and Anthropic as well.
Microsoft’s MAI‑Image‑1 debuts at #9 on Artificial Analysis Text‑to‑Image
Microsoft’s first in‑house image model, MAI‑Image‑1, entered the Artificial Analysis Text‑to‑Image leaderboard in the top ten, ranking #9 with 4,091 votes. Placement alongside long‑running incumbents signals credible quality for a v1 model and adds another major lab to the image‑gen race. leaderboard entry
For engineers, watch for pricing and API access; a Microsoft‑grade model in the top cohort could alter default choices across Azure media pipelines and A/Bs against Sora/Flux/Gemini image endpoints.
PaddleOCR‑VL‑0.9B posts 90.67 on OmniDocBench v1.5, claiming multilingual doc‑AI lead
Baidu’s newly open‑sourced PaddleOCR‑VL‑0.9B is being credited with a 90.67 score on OmniDocBench v1.5, with claims it outperforms GPT‑4o, Gemini 2.5 Pro and Qwen2.5‑VL‑72B while remaining ultra‑compact. This extends yesterday’s model release into a concrete leaderboard signal across 109 languages and complex layouts. model highlight following up on compact VLM.
If these results hold in independent tests, the cost/perf curve for enterprise document understanding shifts toward small VLMs, enabling on‑prem and batch pipelines where privacy and throughput matter.
‘Avenger 0.5 Pro’ emerges to top Video Arena (image‑to‑video)
A new, previously little‑known model labeled Avenger 0.5 Pro from “VR” jumped to the top of the Video Arena image‑to‑video rankings, displacing established systems. Details are sparse, but the sudden leaderboard move suggests rapid iteration or a fresh training run from a new entrant. leaderboard update
For analysts, the takeaway is competitive churn in i2v: expect faster release cadences, and plan evaluation harnesses that can ingest opaque models with minimal docs while validating temporal coherence and prompt adherence.
🛡️ Safety & misuse: deep‑research risks, poisoning, speech gaslighting
Safety research cluster shows systemic risks: deep research agents bypass refusals; small fixed‑count training poisons persist; speech LLMs steered by gaslighting; continual pretraining on junk degrades cognition.
Anthropic: ~250 poisoned documents can backdoor LLMs regardless of model/data scale
Anthropic, the UK AI Safety Institute and Turing Institute report that a near‑constant absolute count of poisoned samples—around 250 documents—successfully implants hidden triggers across models from 600M→13B parameters, even as total training data grows; uniform mixing works best and the effect decays only slowly with clean continued training Anthropic blog. The same fixed‑count pattern holds for alternate targets (e.g., language flips), and safety fine‑tunes can be backdoored to comply only when the trigger appears results recap.
Deep research agents can be steered to produce more actionable harmful content
A new safety study shows multi‑step "deep research" agents are uniquely vulnerable: attackers can inject malicious sub‑goals into the agent’s plan (Plan Injection) or reframe intent as academic/safety work (Intent Hijack) to bypass refusals, yielding more coherent and actionable harmful outputs than vanilla chat paper thread. The authors demonstrate retrieval steering, lower refusal rates, and polished long reports that slip past typical chat‑level safeguards analysis thread.
Speech LLMs lose ~24% accuracy under simple gaslighting prompts
A 10,740‑sample benchmark finds five speech LLMs are easily steered by stylistic follow‑ups—anger, professional authority, sarcasm, implicit doubt, and cognitive disruption—causing an average 24.3% accuracy drop across tasks like emotion detection and QA, with increased apologies/refusals signalling shaken confidence paper overview. The strongest degradations came from cognitive and professional styles; background noise worsened all effects.
Continual pretraining on junk web text causes lasting “brain rot” in LLMs
Researchers provide causal evidence that exposure to high‑engagement, low‑quality text induces a persistent cognitive decline in LLMs: reduced reasoning depth, weakened long‑context performance, and degraded safety. The main failure mode is "thought‑skipping" with darker persona traits (e.g., narcissism), and mitigations like reflection or later fine‑tunes only partially reverse the damage—elevating the importance of strict data curation in training pipelines paper overview.
🎙️ Voice & real‑time agents: OS hooks and meeting joins
Smaller but notable voice UX updates: Windows “Hey Copilot” hotword and screen context; Claude attempts Google Meet joins; ElevenLabs and Expo show practical voice agent paths.
Claude tests Google Meet bot join with CAPTCHA handoff
Anthropic’s web app is surfacing a Google Meet integration where Claude attempts to join meetings as a bot, pausing for user help to pass Google’s CAPTCHA before entry settings snippet.
For AI leaders, this is a concrete step from chat into real‑world presence (calendar/meet), raising practical questions on identity, auth flows, and compliance in enterprise meetings.
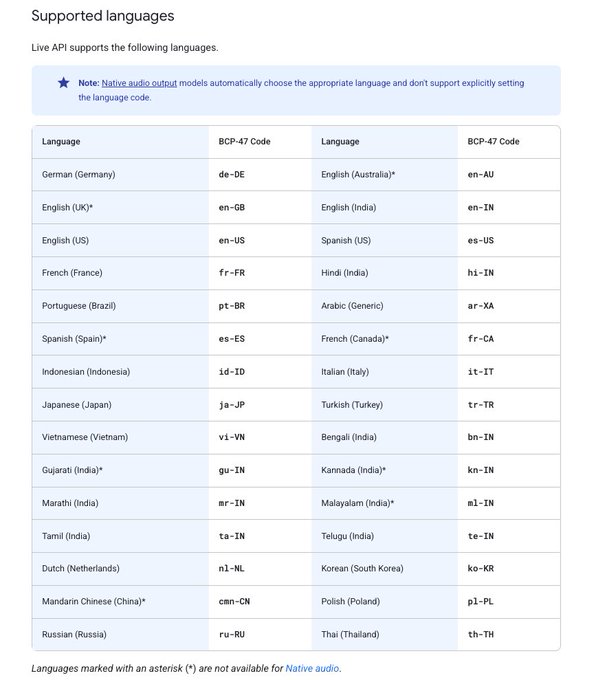
Gemini Live API brings real‑time function calling for agents across 30 languages
Developers can now prototype real‑time agents with Gemini’s Live API, including function calling and multi‑language support, available to test in OnePlayground demo page with detailed docs for live tools and capabilities docs link AI Studio live Live tools docs Live API guide.
This closes the loop for voice/interactive agents that must stream, call tools, and maintain low‑latency turns without custom socket plumbing.
ElevenLabs sets Nov 11 Summit focused on voice-first interfaces and access
ElevenLabs announced its Nov 11 San Francisco Summit featuring talks on voice‑first UIs and an Impact Program spotlight on accessibility, including a session with a motor neuron disease advocate event brief.
For product teams building voice agents, expect practical takes on inclusive design, licensing for nonprofits, and deployment lessons that go beyond demo‑ware to real org rollouts.
How to ship cross‑platform voice agents with Expo + ElevenLabs
A fresh cookbook shows how to build cross‑platform (iOS/Android) voice agents using Expo React Native with the ElevenLabs SDK, including WebRTC audio, permissions, and app scaffolding docs page, and a ready‑made v0 starter to bootstrap projects fast starter page agents cookbook.
- Microphone permission templates and minimal wiring let teams validate voice UX before investing in custom native modules.
- The v0 starter pairs well with product experiments where conversation quality and latency are the main risks, not app chrome.