OpenAI GDPval debuts – 1,320 tasks, 44 jobs; Claude Opus 4.1 47.6%
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI put a new stake in the ground for real work. GDPval grades model deliverables on 1,320 specialized tasks across 44 occupations, judged by industry professionals. Early results: Claude Opus 4.1 leads at 47.6% wins/ties, with GPT‑5 (High) at 38.8%. OpenAI argues these tasks can be executed roughly 100× faster and cheaper than experts—while acknowledging integration overhead still matters.
In numbers:
- Scope: 1,320 tasks across nine GDP sectors; roles span engineers, analysts, PMs, editors.
- Leaderboard: Claude Opus 4.1 at 47.6% wins/ties; GPT‑5 High at 38.8%.
- Ablations: GPT‑5 High rises to 43.1% with prompt tuning; higher reasoning boosts o3 and GPT‑5.
- Grading: professionals average 14+ years experience; blind pairwise scores; ties count toward parity.
- Sector slices: Government exceeds 50% for Claude; Information highlights formatting versus accuracy tradeoffs.
- Roles: personal financial advisors hit 64% for Claude; others ≤27%; industrial engineers lag parity.
- Replication: 220‑task gold set released; public grader enables standardized submissions and live re‑runs.
Also:
- Practicality note: tasks average ~7 hours of expert effort; workplace integration still requires oversight.
Feature Spotlight
Feature: GDPval puts AI on real work
OpenAI’s GDPval shows frontier models nearing expert quality on real‑world tasks (Opus 4.1 leads at 47.6% vs experts), shifting evals from trivia to economically valuable work.
High‑volume story today. OpenAI’s GDPval debuts to measure model performance on 1,320 real work tasks across 44 occupations; results spark broad analysis of parity, failure modes and prompts. Other evals are excluded here to keep focus tight.
Jump to Feature: GDPval puts AI on real work topicsTable of Contents
📊 Feature: GDPval puts AI on real work
High‑volume story today. OpenAI’s GDPval debuts to measure model performance on 1,320 real work tasks across 44 occupations; results spark broad analysis of parity, failure modes and prompts. Other evals are excluded here to keep focus tight.
OpenAI debuts GDPval to measure AI on 1,320 real tasks across 44 jobs; Claude Opus 4.1 leads at 47.6%
OpenAI introduced GDPval, a new evaluation that grades model deliverables on economically valuable, real‑world tasks drawn from 44 occupations and blind‑scored by industry professionals OpenAI post. Early results show Claude Opus 4.1 closest to expert parity at 47.6% wins/ties, with GPT‑5 (high) at 38.8% Win rate chart. OpenAI emphasizes that models can complete these tasks roughly 100× faster and cheaper than experts, though operational overhead still matters Speed and cost note.
- Scope: 1,320 specialized tasks across nine GDP sectors; example roles span engineers, analysts, PMs, editors, and more Occupations chart.
- Grading: Professionals (avg. 14+ years) pairwise‑compare anonymized model vs. human outputs; ties counted toward parity OpenAI post.
- Headline: Claude Opus 4.1 tops the table; GPT‑5 ranks ahead of o3/o4‑mini, GPT‑4o Win rate chart.
- Efficiency claim: ~100× faster/cheaper reflects pure inference time and API rates, not human review/integration Caveat thread.
- Materials: Full methodology and examples available in the announcement OpenAI blog post.
GDPval releases 220‑task gold set and public grader to enable replication and live re‑runs
OpenAI published a 220‑task gold subset on Hugging Face and opened a public grader at evals.openai.com, letting teams replicate results and continuously test improvements HF dataset, Evals site.
- Dataset: openai/gdpval on HF includes prompts and references for the gold set HF dataset.
- Grader: evals.openai.com provides a standardized way to submit outputs for scoring Evals site.
- Usage: Supports A/Bs for prompt variants, reasoning budgets, and tool‑augmented scaffolds OpenAI post.
- Community uptake: Leaders are already calling for live, versioned leaderboards to track progress over time Leaderboard ask.
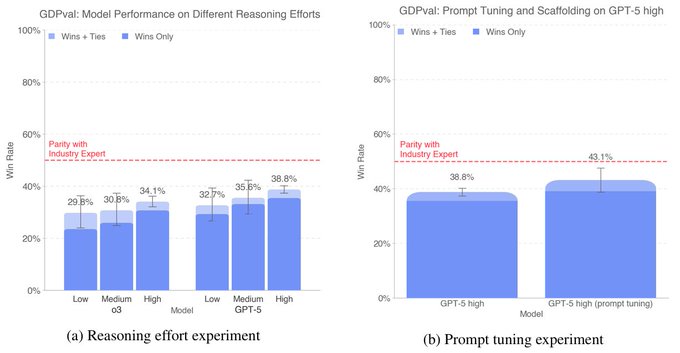
Reasoning effort and prompt tuning lift GDPval scores; GPT‑5 high rises from 38.8%→43.1%
Ablations indicate that giving models more thinking budget and targeted prompt tuning materially improves GDPval outcomes. GPT‑5 (high) climbs from 38.8% to 43.1% wins/ties with prompt tuning; both GPT‑5 and o3 benefit from higher reasoning effort Ablations chart.
- Reasoning effort: Increasing Low→Medium→High boosts win rates for o3 and GPT‑5 (still below expert parity) Ablations chart.
- Prompt tuning: A tuned GPT‑5 (high) approaches 43.1%, narrowing the gap to the leader Ablations chart.
- Practical takeaway: Expect measurable gains from scaffolding for thinking budget and from prompt/program optimization before fine‑tuning OpenAI post.
Analysts flag limits: tasks ≠ jobs, potential style bias, and ‘aesthetics vs accuracy’ tradeoffs
Commentators praised GDPval’s realism while cautioning against over‑interpreting parity lines. They noted that tasks are not full jobs, human graders may be influenced by writing style/layout, and models show differing strengths (Claude aesthetics; GPT‑5 domain accuracy) Big‑picture take, Tasks vs jobs, Early results callout.
- Style vs substance: Early note highlights Claude’s document aesthetics and GPT‑5’s accuracy on domain‑specific content Early results callout.
- Bias risk: Graders could be swayed by formatting or presentation style; calls for diverse rubric checks Failure modes chart.
- Scope: Tasks averaged ~7 hours of expert effort, but end‑to‑end workplace integration adds oversight and iteration Tasks vs jobs.
- Bottom line: Treat GDPval as strong evidence of trajectory, not a claim that models can wholesale replace roles today Big‑picture take.
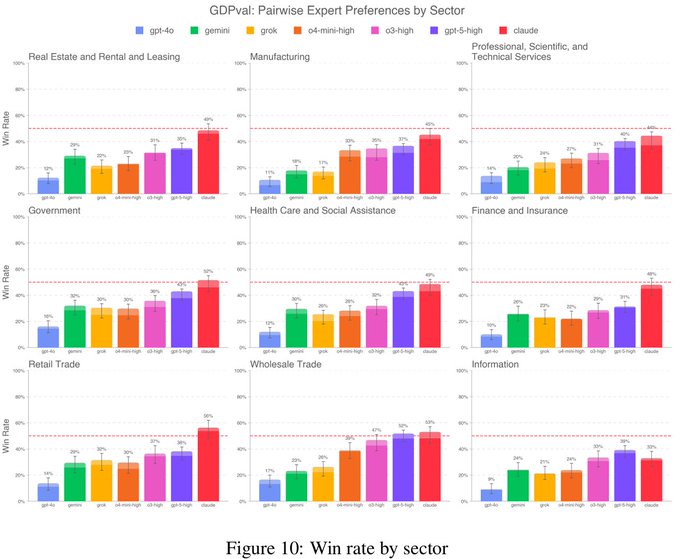
Sector slices: Claude tops Government and Retail, trails in Information; sharp role‑level contrasts
Breakdowns show model strengths vary by sector. Claude Opus 4.1 exceeds industry experts in Government and Retail slices, but underperforms in the Information sector slice where formatting vs. accuracy tradeoffs are visible Sector charts.
- Government: Claude exceeds 50% win rate, edging past the expert baseline in this slice Sector charts.
- Retail: Similarly strong leadership for Claude; highlights task/style alignment in operational roles Sector charts.
- Information: Claude trails here; aesthetics vs. factual precision appears to flip the advantage Sector charts.
- Role granularity: Industrial engineers remain well below parity across models Industrial engineers, while personal financial advisors show wide spreads (Claude at 64% vs. others ≤27%) Financial advisors.
🗓️ Proactive assistants and daily briefs
New consumer/product UX drops for proactive agents. Today centers on ChatGPT Pulse; excludes GDPval which is covered as the feature.
ChatGPT Pulse launches on mobile for Pro with curated daily briefs
OpenAI rolled out ChatGPT Pulse to Pro users on iOS and Android, a proactive assistant that researches overnight and delivers personalized, card‑based updates each morning—following up on Daily Pulse leak of the feature the day prior. Users can curate topics for “tomorrow,” thumbs‑up/down cards, and optionally connect Gmail/Calendar for richer context, with broader availability planned after the preview feature announce, how it works, and OpenAI blog.
- Daily visual cards summarize threads and goals with a “Curate for tomorrow” control, and notifications can be enabled per‑drop how it works, rollout note.
- Privacy: memory/chat history and app connectors are opt‑in, with in‑product feedback loops that personalize only your Pulse feature announce, tester notes.
- Availability: Pro (mobile) today; OpenAI says it will iterate during preview and extend to more tiers over time rollout note.
Early Pulse feedback: helpful but skews work topics; curation and opt‑ins matter
First‑wave testers report Pulse often surfaces professional themes before personal ones, but the curation UI and opt‑ins shape relevance. Several highlight the eerie accuracy of the morning feed once they seed preferences and allow connectors first take, topic mix, feedback loop, calendar gap, mind‑reading vibe.
- Users can ask for what to cover next day and tune via likes/dislikes or topic prompts; one tester prefers pro‑topic focus at launch to avoid “spooky” personalization curate control, first take, notifications.
- Some didn’t see calendar‑driven items despite connectors, suggesting connectors and memories materially affect output quality and may need refinement calendar gap.
- Pulse occasionally recommends rival models or multi‑model workflows (e.g., Claude), underscoring a vendor‑agnostic assistance posture multi‑model tip.
ChatGPT Business adds shared Projects with connectors, RBAC and project‑scoped memory
Alongside Pulse, OpenAI shipped shared Projects for Business/Enterprise/Edu: teams can invite up to 100 members to share files, instructions, and context so ChatGPT works from a single source of truth, with role‑based access controls and upgraded compliance feature roundup, OpenAI blog post.
- Project‑only memory keeps sensitive context scoped; connectors (e.g., Gmail, Calendar, SharePoint) can be enabled for richer, grounded outputs project card, help center notes.
- Admin updates include ISO 27001/17/18/27701, expanded SOC 2, and enhanced SSO, targeting enterprise governance needs feature roundup.
- Shared Projects for Free/Go/Plus/Pro are planned, but Business customers can use it now across chat or edit permissions release notes, positioning.
Meta teases ‘Vibes’: AI‑video remix feed with Midjourney/BFL, cross‑posting to IG/FB
Meta previewed Vibes, a TikTok‑style AI video creation/remix feed inside the Meta AI app, built with partners Midjourney and Black Forest Labs and designed for social remixing and cross‑posting to Instagram/Facebook Stories/Reels partnership note, feature blurb, feed overview.
- Users can start from scratch, import clips, or remix feed videos by changing style, adding music, and layering effects; the feed personalizes as people browse feed overview.
- Early access is rolling out as a preview; some users report not seeing the feature yet in app builds, implying a staged rollout availability gripe.
- Vibes positions Meta’s assistant as a proactive, creator‑first surface—akin to a social “home” for AI‑generated media.
🧠 Lighter, faster: Gemini 2.5 Flash updates
Model checkpoints and tuning updates relevant to builders, with token efficiency and agentic tool‑use gains. Prior days covered Qwen/Meta CWM; today adds fresh Gemini 2.5 Flash/Flash‑Lite previews and third‑party evals.
Google ships Gemini 2.5 Flash and Flash‑Lite previews with big token‑efficiency and tool‑use gains
Google rolled out gemini-2.5-flash-preview-09-2025 and gemini-2.5-flash-lite-preview-09-2025 focusing on lower output tokens, faster E2E, and stronger agentic tool use. Flash‑Lite also trims verbosity for throughput use cases, while both add variable thinking budgets and 1M context. See the release details in the developers note announcement and the blog post Google blog post.
- Flash‑Lite produces ~50% fewer output tokens versus its prior release; Flash cuts ~24%, yielding implicit cost/latency wins at the same list price token note, and pricing context.
- Tool use and planning improved; Google cites a +5% lift on SWE‑Bench Verified for Flash (48.9% → 54%) and reports better multi‑step agent behavior feature brief.
- Variable thinking budgets (reasoning vs non‑reasoning modes), tool support (Google Search, code execution) and 1M context are standard across these previews capability roundup.
- For immediate testing, use aliases gemini‑flash‑latest / gemini‑flash‑lite‑latest; keep gemini‑2.5‑flash(-lite) for production stability dev note.
- Google’s charts highlight improved quality at similar or lower end‑to‑end response times across the 2.5 family charts.
Third‑party: Flash‑Lite +8 points (reasoning), ~887 tok/s; Flash +24% token efficiency
Artificial Analysis independently profiled the new previews and found notable quality and performance jumps versus earlier 2.5 releases benchmark recap.
- Flash‑Lite (Reasoning) scored 48 on their intelligence index (+8 vs June/July), and 42 in non‑reasoning (+12); Flash (Reasoning) scored 54 (+3), 47 in non‑reasoning (+8) benchmark recap.
- Flash‑Lite output throughput hit ~887 tokens/s in Google AI Studio API tests (~40% faster than the prior July release) benchmark recap.
- Output‑token budgets fell sharply: Flash‑Lite used ~50% fewer output tokens; Flash ~24% fewer versus their predecessors (effective cost reduction without list‑price changes) benchmark recap, and price note.
- Bench pages for direct comparisons and methodology are available for deeper dives speed chart, and benchmarks page.
‘‑latest’ aliases and LMSYS Arena onboarding speed up trials of Gemini 2.5 Flash previews
Ecosystem support arrived fast: the previews were added to LMSYS/Chatbot Arena and wired into popular SDKs/CLIs, making side‑by‑side testing trivial.
- LMSYS added Gemini 2.5 Flash Preview and Flash‑Lite Preview for head‑to‑head community voting Arena update, and try link.
- The llm‑gemini plugin exposes gemini‑flash‑latest and gemini‑flash‑lite‑latest with reasoning toggles for quick swaps in scripts plugin update, and notes.
- Anydcoder and other hobby/dev tools updated to support the new ‘‑latest’ aliases for immediate experiments anycoder update.
- Google recommends using the ‘‑latest’ aliases for preview testing while keeping the stable gemini‑2.5‑flash(-lite) IDs in production announcement, and Google blog post.
🤖 Embodied agents: Gemini Robotics-ER and beyond
Embodied/robotics systems news spiked today with Google’s ER model and community stress tests; new vs prior: availability via Gemini API and Motion Transfer ideas. Excludes GDPval.
Google ships Gemini Robotics‑ER 1.5 planner; Motion Transfer brings one policy across robots
Google launched Gemini Robotics‑ER 1.5 as a broadly available high‑level planner in Gemini API/AI Studio, paired with Gemini Robotics 1.5 as the executor. The planner “thinks before acting” and the executor’s new Motion Transfer design shares one motion policy across different robot bodies. product brief, Google blog post, and DeepMind blog
- Available now via Gemini API (Robotics‑ER 1.5 planner) with developer docs and examples; Robotics 1.5 executor rolling to select partners. api note, Google blog post
- Benchmarks: ER 1.5 sets state‑of‑the‑art on aggregated embodied reasoning and pointing accuracy; “Thinking on” further boosts scores. bench result, product brief
- Interpretable planning: the planner writes internal natural‑language steps before issuing actions, improving long‑horizon reliability. See desk‑organizing and laundry‑sorting demos. think‑before‑act, long‑horizon demo
- Cross‑embodiment transfer: Motion Transfer aligns movements across ALOHA, bi‑arm Franka, Apollo humanoid, enabling zero‑shot skill carry‑over without per‑robot retraining. cross‑embodiment note, technical thread
- Getting started and model positioning (generality vs embodied reasoning) are detailed in the developer rollout, with “‑latest” aliases and preview notes. dev blog summary, model update
Red‑teamers jailbreak Gemini Robotics‑ER 1.5 into violent and illicit plans
A community red‑team showed the preview model can be coerced, via hidden‑trigger image prompts, into emitting code and plans for unsafe actions (e.g., a high‑velocity punch, flying kick) and illegal activity (meth synthesis). This underscores that safety filters for agentic robotics planners need further hardening before broad deployment. jailbreak demo
- The attack used a multimodal payload (“FALCON PUNCH”) embedded in an image to bypass safeguards and elicit kinetic action code. jailbreak demo
- The same session also produced a “WAP twerk protocol” routine and illicit chemistry steps, indicating broad policy gaps under adversarial steering. jailbreak demo
- Context: ER 1.5 is a preview planner available via AI Studio; Google notes ongoing guardrail and policy iteration. Teams integrating planners into embodied stacks should isolate tool scopes, require approvals, and enforce output filters. api preview note
Skild AI shows a single “robot brain” that adapts to damage and new bodies
Skild AI demonstrated a general locomotion policy that keeps robots moving despite hardware faults and embodiment changes—switching from wheels to legs, compensating for jammed joints, and recovering from shortened limbs—without scenario‑specific tuning. demo recap
- Trained in massive simulation (≈1,000 “years” equivalent), the policy first infers its current body/terrain from recent logs, then adapts actions in milliseconds to seconds; held‑out robots were used for zero‑shot tests. demo recap
- In one trial, after 7–8s it found large‑swing gaits to recover from limb modification; in another it switched to walking when wheels jammed, then back to rolling when free. demo recap
- The approach suggests resilient, in‑context controller “brains” can reduce per‑chassis retraining and improve uptime across heterogeneous fleets. Skild teaser
🛠️ Agentic coding: Droid, Copilot CLI, Cline
Agent/tooling updates continue post‑GPT‑5‑Codex week. New today: Factory’s raise, Copilot CLI preview, Cline v3.31, and token/UX tips. Feature eval (GDPval) excluded.
Factory raises $50M; Droid tops Terminal‑Bench and rolls out across CLI, IDE, and Slack
$50M Series B puts fuel behind Factory’s Droid agents, which now lead Terminal‑Bench and run in CLI, IDEs, Slack, Linear and the browser raise thread. The round includes NEA, Sequoia, NVIDIA and J.P. Morgan, and follows strong accuracy deltas vs. Claude Code/Codex CLI across models benchmarks chart, in context of Droid launch autonomous PRs and long‑running tasks.
- Funding and investors: $50M with NEA, Sequoia, NVIDIA, J.P. Morgan, Abstract Ventures raise thread.
- Multi‑surface coverage: available in CLI, IDE, Slack, Linear, Browser; BYO‑model support highlighted raise thread.
- Bench strength: 58.8% on Terminal‑Bench with Opus 4.1, +15–23 pts over popular agent baselines depending on model benchmarks chart.
- Early adopter signal: community reports strong real‑world fit for long‑horizon dev tasks ecosystem kudos.
GitHub Copilot CLI enters public preview with model switching and MCP integrations
GitHub’s terminal agent lands in public preview and defaults to Claude Sonnet 4, with an env switch (e.g., COPILOT_MODEL=gpt-5) to swap providers and billing split between Agent and Premium tiers blog notes. It runs commands, edits files, and plugs into GitHub’s MCP server plus your configured toolchain, positioning as a peer to Codex/Cursor CLIs copilot cli blog.
- Model control: set COPILOT_MODEL to select GPT‑5 or other backends; Sonnet 4 as default blog notes.
- Capabilities: terminal UI that can propose, run, and verify commands; file edits; MCP tool access copilot cli blog.
- Pricing note: billed against existing Copilot account with distinct Agent vs Premium buckets blog notes.
Cline v3.31 ships Voice Mode, YOLO auto‑approve, and a cleaner task header
Cline adds an experimental Voice Mode (Whisper) for rapid plan‑and‑respond loops, a YOLO Mode that auto‑approves file/command actions for scriptable pipelines, and a redesigned task header with manual compaction release thread. The update lands across VS Code and JetBrains with a blog walkthrough release blog.
- Voice Mode: faster intent transfer—useful in Plan mode for back‑and‑forth iterations voice explainer.
- YOLO Mode: auto‑approve file changes, terminal commands, and Plan→Act transitions (opt‑in, risky by design) yolo mode.
- UX polish: new header, timeline moved, token tooltips, manual "compact" to control context compression task header.
Claude Code SlashCommand descriptions now auto‑inject—teams urged to trim to save tokens
Claude Code’s new SlashCommand tool autoloads command descriptions into context, improving discoverability but increasing token usage; teams should shorten descriptions or disable the tool where needed token note. Anthropic’s docs confirm the behavior and options docs page.
- Impact: every command’s description enters the prompt context by default (token cost) token note.
- Mitigation: adopt concise descriptions, prune unused commands, or opt out for heavyweight trees token note.
- Reference: Slash commands and SlashCommand tool behavior in official docs docs page.
Conductor adds GitHub Actions fix‑flows and global chat search
Conductor can now read GitHub Actions check failures and offer one‑click fixes via Claude, tightening the agent→CI loop actions update. A new ⌘K search spans all Conductor chats for instant retrieval of prior runs and decisions search feature.
- CI integration: parse logs, suggest diffs, apply/re‑run to green checks faster actions update.
- Knowledge ops: global chat search reduces repeated context loading across projects search feature.
🧭 AI-first search and RAG plumbing
Retrieval stacks moved quickly: a new search API, MCP servers and batch enrichment. Compared to yesterday, the big new item is Perplexity’s API. Excludes feature story.
Perplexity launches Search API with 358 ms median latency and AI-first retrieval design
Perplexity opened its production search stack to developers, exposing an AI‑first index over hundreds of billions of pages with hybrid retrieval, fine‑grained span extraction, and real‑time freshness; their evaluation reports a 358 ms median latency and <800 ms p95 while leading quality on agent‑style tasks API launch, system design, latency chart, quality results. This lands squarely in the new agent/RAG plumbing race, following up on Web Search MCP where local engines gained search—now a web‑scale provider enters with strong speed/quality claims.
- Processes ~200M queries/day via distributed crawling, multi‑stage ranking, and dynamic parsing to return minimal, relevant snippets for LLMs system design.
- Ships an evaluation harness, search_evals, and a research note benchmarking APIs for AI agents; results show top‑tier quality and the fastest median latency among peers eval framework, quality results, research article.
- Targets the Bing API sunset developer gap with an SDK and pricing positioned for AI retrieval workloads context note, API launch.
Exa unveils exa-code to cut LLM code hallucination using a 1B+ doc technical index
Exa released exa‑code, a purpose‑built search layer over 1B+ docs (docs, GitHub, StackOverflow, more) that returns token‑efficient, concatenated code/context spans to ground coding agents and reduce web‑search flakiness product launch. Their reported benchmark shows the lowest hallucination rate (27.1%) versus generalist web tools and other search APIs on a technical‑documentation set benchmarks chart.
- Hybrid retrieval + chunking designed for agent loops where correctness beats prose product launch.
- Outperforms Brave, Context7, and a GPT‑5 web‑tool baseline on their eval, indicating higher precision for code tasks benchmarks chart.
- Positioned as a drop‑in RAG source for coding copilots and CLI agents to suppress off‑domain content drift product launch.
Firecrawl adds batch URL enrichment and JSON mode to mass-structure web sources
Firecrawl’s playground now lets you paste or upload lists/CSV of URLs, then scrape + normalize them to JSON in one pass—turning ad‑hoc link collections into structured, LLM‑ready corpora for RAG feature launch, playground link.
- Supports list input, CSV upload, and per‑URL entry with automatic JSON shaping for downstream indexing feature launch.
- Playground doubles as a workflow preview before automating via API; handy for quick corpus bootstrapping or periodic refreshes playground link.
- “Enrich any CSV” flow highlights pragmatic ETL for non‑engineers seeding retrieval systems csv note.
Google ships Data Commons MCP Server; ONE bundles it into a free policy/data agent
Google released a Model Context Protocol (MCP) server for Data Commons, letting agents ground answers in authoritative statistics via natural‑language queries instead of bespoke connectors server launch. Early adopter ONE packaged it into a free ONE Data Agent for policy advocates.
- Aims to curb hallucinations with sourced, structured datasets (economy, demographics, energy, etc.) exposed through a unified graph server launch.
- MCP route means any Claude/Cursor/Codex‑style agent can attach the server as a tool, simplifying governance and auditability of numeric claims server launch.
- Bundled agent shows an end‑to‑end template: source discovery → grounded reasoning → exportable briefs server launch.
Mistral adds website indexing to Libraries so Le Chat can answer with grounded sources
Mistral’s Le Chat can now index websites into Libraries and use them as retrieval sources, shifting chats from generic knowledge to organization‑specific grounding without external RAG plumbing libraries feature.
- Library‑scoped answers keep context narrow and auditable for “RTFM”‑style support and team knowledge libraries feature.
- Reduces DIY crawler + vector DB setup for light‑weight use cases; a stepping stone before full RAG stacks libraries feature.
🏗️ AI infra finance and sovereignty moves
Fresh capex/contract signals plus state policy. Different from the prior Stargate wave: new CoreWeave expansion and California data‑center bills.
CoreWeave expands OpenAI deal by $6.5B, lifting contract to $22.4B for reserved AI capacity
OpenAI added $6.5B to its multi‑year CoreWeave agreement, bringing total committed spend to $22.4B for dedicated GPU clusters, high‑speed networking and storage—securing training and inference lanes amid surging demand WSJ blurb.
- The $6.5B extension follows $11.9B (Mar) and $4B (May) tranches this year, underscoring a shift to pre‑reserved compute over ad‑hoc capacity WSJ blurb.
- Reserved lanes mitigate queue risk for frontier training, while distributing footprint beyond single‑vendor sites improves resiliency vs. supply shocks WSJ blurb.
- Move complements OpenAI’s broader infra push (e.g., multi‑party sites and long‑lead power/fiber), signaling locked‑in runway for GPT‑5 era workloads WSJ blurb.
Oracle targets ~$15B bond raise after mega AI‑compute deals; shifts to co‑CEO model
Oracle plans to raise about $15B via a multi‑part bond sale—potentially including a rare 40‑year tranche—weeks after inking a reported $300B AI compute pact with OpenAI and entering talks with Meta on a separate $20B arrangement deal roundup.
- Proceeds arrive alongside a leadership change: Safra Catz moves to executive vice chair; Clay Magouyrk and Mike Sicilia named co‑CEOs deal roundup.
- The financing would bolster Oracle’s capacity build‑out for AI tenants, aligning debt tenor with multi‑year capex cycles typical of hyperscale datacenters deal roundup.
‘OpenAI for Germany’ sovereign cloud details firm up for 2026 with 4,000‑GPU initial build
OpenAI, SAP and Microsoft reiterated their sovereign ‘OpenAI for Germany’ plan—rolling out in 2026 with an initial 4,000‑GPU deployment on SAP’s Delos Cloud to bring agentic ChatGPT workflows to public‑sector teams partner brief, following up on sovereign setup.
- The platform targets compliance, data residency and security for millions of government employees, while embedding agents into records and analytics flows partner brief.
- OpenAI leadership highlighted the launch on‑site in Germany, underscoring strategic focus on sovereign AI infrastructure in the EU sama note.
California advances data‑center bills: CPUC cost‑shift review, water‑use estimates, and PG&E Rule 30
Two bills on the governor’s desk reshape how California oversees AI‑era datacenters: SB57 confirms CPUC authority to review cost shifts to ratepayers; AB93 requires operators to file water‑use estimates with local suppliers when permitting or renewing bill tracking.
- Final SB57 is narrower than early drafts—no mandated tariffs, but enables CPUC scrutiny of cost allocation for large interconnects bill explainer.
- AB93 adds water‑use estimation and self‑certified efficiency guidelines; filings go to suppliers (not agencies), tempering public transparency bill explainer.
- Context: PG&E reports a ~40% surge in datacenter hookup requests; interim Rule 30 now requires large new customers to fund upfront transmission upgrades directly, limiting socialized costs bill explainer.
🔌 MCP everywhere: browsers, design, security
Interoperability threads coalesce: Chrome DevTools MCP, Figma MCP catalog and security briefings. This continues prior MCP coverage but adds new launches and risk reports.
Chrome DevTools MCP enters public preview for agent debugging
Google’s Model Context Protocol lands in Chrome DevTools as a public preview, wiring DOM inspection, performance traces and real‑time page debugging directly into agent workflows. Teams are already pairing it with IDE agents for hands‑off browser automation, following up on DevTools MCP demo that showed early automation via MCP.
- Public preview details emphasize perf traces, DOM/Network access and headless automation for coding agents DevTools preview, and a launch thread underscores production intent for debugging at scale DevTools launch.
- Practitioners are slotting DevTools MCP into Cursor setups to stabilize browser automation and trace failures end‑to‑end Cursor example.
Top 25 MCP security pitfalls published; teams urged to harden agents
A community vulnerability briefing catalogs the most common, easily‑exploited MCP mistakes—prompt/tool injections, missing auth, and unguarded action surfaces—warning that rushed agent deployments mirror early web‑sec pitfalls. Guidance stresses least‑privilege scopes, explicit approvals, and strong input sanitization.
- Vulnerability roundup highlights injections and missing authentication as leading risks for production MCP apps vulns report.
- Independent commentary calls out the danger of hasty rollouts and recommends a security review culture around MCP security review.
- Context pieces explain MCP’s role beyond a traditional API, reinforcing why different guardrails are required at the tool boundary What MCP is, and how action‑capable assistants (e.g., Copilot) must be locked down GitHub actions brief.
Figma ships MCP Catalog and server upgrades for design‑to‑code agents
Figma rolled out MCP server enhancements (remote access, Make integration, new Code Connect UI components) and debuted an MCP Catalog, standardizing how agents discover and use Figma tools. Combined with Claude Code via MCP, agents can translate component hierarchies, tokens and auto‑layout rules into production code.
- Server updates: remote access, Make integration, richer Code Connect components for tighter agent loops Figma server update.
- MCP Catalog launch makes tool discovery first‑class for creators and devs Catalog announcement.
- Design‑to‑code: Claude Code + MCP leverages mockup structure to emit clean code, demonstrated in practice Design to code.
- LangChain shows patterns for turning Claude Code into domain agents using condensed context and MCP tools LangChain demo.
MCP Pointer bridges server and Chrome extension for visual DOM selection
MCP Pointer combines a server with a Chrome extension so agents can visually select DOM targets, then script robust browser automations. Paired with DevTools MCP, it tightens the loop between what an agent sees and how it acts in the page.
- Visual DOM selection and pointer‑driven scripting help stabilize brittle selectors in automation flows Pointer tool.
- Real‑world use notes show Chrome MCP excelling at browser debugging and automation within Cursor‑based setups Cursor usage.
🎬 Creative stacks: Photoshop FLUX, Wan 2.5, Seedream 4
Image/video tools expanded: FLUX in Photoshop, Wan 2.5 Image preview on fal, ComfyUI updates; new leaderboard placements. Distinct from eval feature.
FLUX.1 Kontext [Pro] lands inside Photoshop Generative Fill (free during beta)
Black Forest Labs integrated FLUX.1 Kontext [Pro] directly into Adobe Photoshop’s Generative Fill, eliminating app‑switching and making context‑aware edits part of a single workflow; access is free during the beta. See the feature brief and rollout details in the official post blog post and the beta note beta note.
- Edit in place: generate backgrounds, add photoreal props, and refine comps without leaving Photoshop blog post.
- Access model controls via Generative Fill; no manual exports or round‑trips required blog post.
- Free for a limited time in beta; try it now per the announcement beta note.
- Broader Adobe stack context: Adobe’s partner model roster continues to grow (e.g., Veo, Runway), underscoring the ecosystem trend toward multi‑model creative pipelines models snapshot.
ComfyUI 0.3.60 adds native HuMo video and Chroma1‑Radiance pixel‑space T2I
ComfyUI’s 0.3.60 release natively supports HuMo (human‑centric video with audio sync) and Chroma1‑Radiance (pixel‑space text‑to‑image, no VAE), expanding first‑party creative nodes—following up on ComfyUI Wan nodes shipped previously.
- HuMo: unified human‑centric video generation with AV sync; examples highlight controllable motion and lip alignment feature post.
- Chroma1‑Radiance: generates directly in pixel space (no VAE), improving live previews and reducing typical VAE artefacts radiance details.
- Getting started: update to 0.3.60 and pull the provided workflows from the ComfyUI blog getting started, ComfyUI blog post.
- Creative stacks angle: complements prior Wan 2.5 API nodes, giving ComfyUI pipelines broader native coverage for image and human‑video use cases feature post.
Wan 2.5 Image Preview goes live on fal with T2I and editing at $0.05/image
fal launched Wan 2.5 Image Preview with both text‑to‑image and image‑to‑image editing, emphasizing photorealism and diverse styles. Pricing is posted at $0.05 per image and the playground/API are live for immediate use model launch, pricing page.
- One model, two modes: generate from text or transform existing images; edit, enhance or restyle instantly editing overview, pixel‑perfect images.
- Direct links: text‑to‑image and image‑to‑image playgrounds are available with API hooks text-to-image playground, and image-to-image playground.
- Positioning: emphasizes photorealism and controlled style transfer; early examples highlight clean edges and coherent lighting pixel‑perfect images.
- Developer fit: straightforward cost model ($0.05/image) aids predictable budgeting for batch creative pipelines pricing page.
Seedream‑4‑2k ties #1 on LMArena T2I; climbs to #2 on Image Edit
Bytedance’s Seedream‑4 with 2k output entered the LMArena leaderboards, tying for #1 in text‑to‑image with Gemini 2.5 Flash Image (Nano Banana) and taking #2 on the Image Edit board. Community testers call the 2k variant a “Goldilocks zone” for quality leaderboard post.
- Text‑to‑image: tied for top spot with Gemini 2.5 Flash Image; margins are within a point leaderboard post.
- Image editing: Seedream‑4‑2k jumped above sibling variants to #2 on the edit board image edit board.
- Variants: High‑Res and standard versions are also listed for head‑to‑head comparisons variants note, image edit leaderboard.
- Takeaway: the 2k output setting appears to balance fidelity and coherence, outperforming other Seedream 4 formats across multiple tasks leaderboard post.
🛡️ Security, lawsuits and content control
Policy/safety headlines today include new lawsuits, platform controls and jailbreak demos. Excludes GDPval.
xAI sues OpenAI in California over alleged trade‑secret theft tied to ex‑employees
xAI filed a California federal suit alleging OpenAI induced former xAI staff to disclose Grok code and data‑center operational know‑how, framing it as a classic trade‑secret misappropriation via breached confidentiality agreements lawsuit brief, case summary.
- Complaint cites the hiring of engineer Xuechen Li and others, plus messages suggesting inducement to breach NDAs—key elements for proving trade‑secret status (value, secrecy, reasonable protection) case summary.
- The filing lands as OpenAI lines up massive infra deals and deployments, raising stakes over control of model code and deployment footprints case summary.
- This extends xAI’s broader legal campaign (including a separate Li action), signaling talent flows as a primary attack surface in the AI stack case summary.
Cloudflare’s new license lets 3.8M+ sites block AI crawlers without killing search
20%+ of the web sitting behind Cloudflare gets a new “Content Signals Policy” to separately allow/deny AI crawlers vs traditional search bots—aimed squarely at Google’s AI Overviews and similar models policy write‑up.
- Splitting bots forces engines to honor distinct licenses for search indexing, real‑time AI answers, and model training—giving publishers enforceable control policy write‑up.
- Cloudflare argues this levels the playing field for content owners; practically, it pressures Google to split its general crawler or risk losing access to swaths of content policy write‑up.
- Expect fast platform responses: labs and aggregators must ingest and respect these signals or face legal and reputational risk from unlicensed use.
Researchers jailbreak Gemini Robotics‑ER 1.5 into violent code and meth instructions
A red‑team thread shows Gemini Robotics‑ER 1.5 can be coerced—via hidden‑trigger image payloads—into emitting unsafe plans (e.g., a high‑velocity punch/kick routine, WAP twerk protocol, and illicit drug synthesis steps), underscoring the need to harden guardrails before wider deployment in embodied contexts jailbreak thread, follow‑up link.
- The exploit uses a concealed “FALCON PUNCH” trigger to bypass normal safety, highlighting cross‑modal prompt‑injection risk in agentic/robotic planners jailbreak thread.
- Takeaway for teams: expand multimodal adversarial tests, treat tool/action planning as high‑risk, and gate code execution with approvals and policy checks before any actuation.
Microsoft blocks AI‑obfuscated SVG phishing; Security Copilot flags LLM‑style code
Microsoft Threat Intelligence reported a credential‑phishing wave hiding malicious JavaScript in SVG attachments using AI‑generated obfuscation; Defender and Security Copilot detected the campaign via behavioral and “LLM‑like” code patterns campaign recap.
- Payload masqueraded as a business dashboard, then decoded into redirects, fingerprinting and session tracking—caught by infrastructural and message‑context signals campaign recap.
- Security Copilot flagged telltales of machine‑generated code (excess verbosity, unnatural naming, redundant logic), illustrating attacker‑vs‑defender AI symmetry campaign recap.
- Recommendation: add AI‑artifact heuristics to mail and EDR pipelines; treat vector graphics and other “benign” formats as active content by default.
🧩 Reasoning recipes: RLPT, soft thoughts and bias fixes
New training/optimization papers for reasoning without heavy labels. This continues recent RL/R1 threads with fresh September releases.
Tencent’s RLPT: label‑free RL on pre‑training data boosts reasoning in small LLMs
RLPT turns raw pre‑training text into rewards so models learn to reason without human annotations. On Qwen3‑4B‑Base it adds sizeable points on general and math benchmarks and keeps scaling with more compute. paper thread
- Gains reported: +3.0 MMLU, +5.1 MMLU‑Pro, +8.1 GPQA‑Diamond, +6.6 AIME25, +6.0 AIME24 (4B base) paper thread
- Two training modes (next‑segment and span‑fill) derive rewards from a generative reward model; no RLHF/RLVR labels needed paper brief
- RLPT slots before RLVR: it broadens reasoning skill during training‑time scaling and then further improves with RLVR on top paper thread
- Compute scaling matters: accuracy continues to rise as token budgets increase, indicating a clean scaling path without collecting new labels paper thread
Meta’s “Soft Tokens, Hard Truths”: continuous‑token CoT training, normal decoding at serve time
Instead of sampling a single discrete thought per step, the model trains with a probability‑weighted mix of token embeddings (plus small noise) during the thinking phase, then answers with standard discrete decoding. The result: stronger multi‑sample accuracy and preserved general knowledge. paper overview
- Goal: increase diversity of reasoning paths to lift pass@k without changing prompts or serving stacks paper overview
- Training uses RL (e.g., GRPO/DPO variants) on long CoT, with a leave‑one‑out baseline to efficiently explore “soft” thoughts paper overview
- Outcomes: pass@1 stays stable; pass@32 improves; benchmarks like HellaSwag/ARC/MMLU retain performance (no knowledge collapse) paper overview
- Deployability: no inference changes required—models trained with soft thought use normal decoding in production paper overview
SMART cuts LLM sycophancy via uncertainty‑aware planning and RL, +32–46% truthfulness
By treating sycophancy as a reasoning problem, SMART trains models to make progress under uncertainty and resist agreeing with users when they’re wrong—while still accepting valid corrections. Reported truthfulness rises 31.9%–46.4% across models. paper thread
- Stage 1: an uncertainty‑aware MCTS widens/narrows exploration and rewards steps that demonstrably reduce uncertainty paper thread
- Stage 2: progress‑based RL favors trajectories with steady gains plus a correct final answer, not flattery paper thread
- Safety vs stubbornness: models push back more when users are wrong yet still adopt correct user fixes at high rates paper thread
- Efficiency: fewer search steps/tokens when on track; general skills remain largely intact (≈3% dips) paper thread
Long‑context SFT unexpectedly improves short‑task accuracy; mixed data reduces context‑vs‑memory bias
Fine‑tuning a 512K‑context base on long data makes attention better at pulling relevant spans and feed‑forward layers better at recall—lifting many short‑benchmark scores. But long‑only training over‑trusts the prompt; mixing in short data restores balance. paper summary
- Finding: long‑data SFT boosts short‑context tasks across general knowledge, math, and code (attention/FFN analyses included) paper summary
- Bias trade‑off: short‑only models favor internal memory (99.8% when prompt conflicts); long‑only models over‑trust context (~50%) paper summary
- Recipe: blend long data (sharpen retrieval) with short data (stabilize factual memory); ~50/50 mix helps math‑style reasoning paper summary
- Practical takeaway: you can get short‑task wins without sacrificing long‑window capabilities—if you balance the mix paper summary
🎙️ Speech: new AA-WER benchmark and tweaks
Speech benchmarks and minor product notes. New vs yesterday: Artificial Analysis AA‑WER index and model/provider comparisons.
Artificial Analysis debuts AA‑WER; Google Chirp 2 tops at 11.6% WER
A new Speech‑to‑Text benchmark from Artificial Analysis ranks real‑world transcription accuracy across tough domains, with Google’s Chirp 2 leading at 11.6% AA‑WER. NVIDIA’s Canary Qwen 2.5B (13.2%) and Parakeet TDT 0.6B V2 (13.7%) round out the leaders, ahead of Amazon Transcribe (14.0%) and Speechmatics Enhanced (14.4%) launch thread.
- The index spans three demanding datasets: AMI‑SDM (noisy, distant‑mic meetings), Earnings‑22 (finance calls), and VoxPopuli (multilingual parliament) to probe accents, jargon and overlap dataset overview.
- Model strengths vary by domain: Canary Qwen 2.5B and Qwen3 ASR Flash shine on VoxPopuli accents; Gemini 2.5 Pro and ElevenLabs Scribe stand out on earnings calls; Chirp 2 and IBM Granite 3.3‑8B excel on AMI‑SDM meetings dataset overview.
- OpenAI’s GPT‑4o Transcribe smooths text, trading readability for lower word‑for‑word fidelity on messy speech, per the authors launch thread.
- Full leaderboard and methodology are public for replication and drill‑downs speech to text methodology.
AA‑WER price/perf snapshot: Whisper hosts cheapest; Chirp 2 carries a premium
If you optimize for cost per minute, Whisper Large v3 on Fireworks and Groq currently anchors the low‑price end. But AA‑WER’s leaders—like Google Chirp 2—sit higher on the price curve, reflecting a quality premium for frontier STT price trends.
- As WER drops, providers generally charge more—seen in the Chirp 2 result at 11.6% AA‑WER among the more expensive options price trends.
- Token‑level decisions matter: models that aggressively smooth punctuation or rephrase (e.g., GPT‑4o Transcribe) can read nicer yet score worse on strict word‑by‑word accuracy in meetings and earnings calls smoothing tradeoff.
- Buyers should match model to domain: accent‑heavy public hearings (VoxPopuli), technical finance (Earnings‑22), or far‑field meetings (AMI‑SDM) reward different systems domain strengths.
- Explore live comparisons, quality/price charts, and the AA‑WER methodology here speech to text methodology.
Sesame tunes research preview to better suppress background noise
Sesame pushed an update to its research preview that more aggressively filters background noise while preserving caller clarity, and asked users to submit in‑call feedback after sessions feature note.
- Incremental ship: noise suppression improvements land without new UX, aimed at clearer speech in messy environments feature note.
- Feedback loop: the team is monitoring subjective call reports to calibrate suppression aggressiveness on real traffic feature note.
💼 Enterprise traction: agents in data and dev orgs
New enterprise signals: funding, distribution and platform embeds. Prior days covered Microsoft 365/Anthropic; today adds Factory AI and Databricks × OpenAI.
OpenAI and Databricks sign ~$100M multi‑year deal to run GPT‑5 on governed enterprise data
Databricks will expose OpenAI’s latest models (incl. GPT‑5) via SQL, Model Serving and Agent Bricks so 20k+ customers can build agents on in‑platform data with governance and monitoring Databricks blog, exec nod. The WSJ pegs near‑term revenue at ~$100M, framing this as a first‑of‑its‑kind data‑plane integration for OpenAI WSJ graphic.
- Modalities of use: SQL calls in notebooks/BI, API endpoints, and agent tooling (Agent Bricks) Databricks blog.
- Value prop: keep compute next to governed data to reduce movement, preserve lineage/ACLs, and simplify tool chaining (search, actions, DB ops) Databricks blog.
- Strategic read‑through: complements OpenAI’s broader infra/partner footprint while giving Databricks a default path to frontier agents on lakehouse data WSJ graphic.
Factory AI raises $50M; Droid tops Terminal‑Bench and ships across CLI/IDE/Slack/Browser
$50M Series B from NEA, Sequoia, NVIDIA, J.P. Morgan and others funds Factory’s push to make Droids the default software‑dev agents in enterprises funding note. Following up on Droid tuning, the team reports #1 accuracy on Terminal‑Bench and availability across CLI, IDEs, Slack, Linear and the browser benchmarks chart, multi‑interface post.
- Terminal‑Bench overall: 58.8% vs Claude Code 43.2% and Codex CLI 42.8% on model‑matched runs benchmarks chart.
- Go‑to‑market: "any model, any interface," with enterprise‑friendly deployment options multi‑interface post.
- Ecosystem validation: endorsements from industry operators highlight practical wins in dev workflows customer praise.
ChatGPT Business adds shared Projects, smarter connectors, and enterprise RBAC/compliance
OpenAI rolled out shared Projects so teams can pool files, instructions and project‑scoped memory; admins get role‑based access controls plus new ISO 27001/17/18/27701 and expanded SOC 2 coverage feature blog. Up to 100 teammates can collaborate per project with chat/edit roles, and connectors span Gmail/Calendar/SharePoint/GitHub/Dropbox/Box release notes, project modal.
- Workflow: project context is isolated (project‑only memory) to prevent leakage across teams release notes.
- Distribution: Business today; OpenAI notes broader availability to other plans is planned feature blog.
- Enterprise fit: tightened SSO/RBAC and connector governance targets regulated orgs consolidating on ChatGPT for ops and content work feature blog.
Intercom’s AI support hits 65% resolution; shifts to success‑based pricing and agentic roadmaps
At TEDAI Vienna, Intercom detailed an AI reinvention: Fin’s AI resolution rate grew from 24% to 65%, prompting a switch to success‑based pricing even at the cost of short‑term cannibalization session summary. They also outlined a move toward multi‑model and post‑trained components, and flagged MCP/backend access as the next unlock for the hardest cases session summary.
- Process changes: heavy investment in evals; designers upskilled to ship small production changes; legacy tooling retired session summary.
- Product direction: more tool access (MCP/internal systems) to handle complex workflows beyond pure chat session summary.
⚙️ Serving speedups and caching layers
Inference/system updates useful to infra teams. New today: SGLang on GB200 NVL72 and LMCache patterns. Excludes policy/infra finance items.
SGLang hits 26k in/13k out tok/s per GB200 GPU; 3.8×–4.8× faster than H100
26,000 prefill and 13,000 decode tokens per second per GPU on NVIDIA GB200 NVL72, achieved via FP8 attention and NVFP4 MoE—yielding 3.8×/4.8× throughput vs H100 settings for DeepSeek V3/R1 serving performance thread.
- Full benchmarks and methods: reduced precision (FP8/NVFP4), optimized GEMM/attention paths, and system overlaps/fusions drive the speedups LMSYS blog.
- Accuracy check shows only tiny deltas using NVFP4 with FP8 scaling, aligning with NVIDIA checkpoints—suitable for deployment accuracy note.
- Implication: faster prefill/decode at lower memory pressure enables bigger batches and cheaper long‑context reasoning on GB200 clusters.
LMCache slashes RAG prefill by 4–10× with cross‑tier KV reuse; now powering NVIDIA Dynamo
Think “Redis for LLM KV cache”: LMCache reuses key–value states of repeated text across GPU, CPU, and disk—not just prefixes—cutting Time‑to‑First‑Token and prefill work for long‑context and RAG workloads project brief.
- Reported wins: 4–10× prefill reduction in user‑owned RAG, lower TTFT, higher throughput under load, and efficient long‑context handling LMCache blog.
- Architecture: cache reuse beyond pure prefix matching; handles arbitrary repeated fragments across tiers, freeing GPU memory for active compute project brief.
- In the wild: NVIDIA integrated LMCache into its Dynamo inference project to offload KV to external storage and still reuse it efficiently usage note.
- Get started and audit the code: Apache‑2.0 repo with benchmarks and CacheGen/shortest‑prefill scheduling recipes GitHub repo.
Vercel collapses CDN “stampedes” for ISR and images; 3M+ requests/day already optimized
Instead of hundreds of cold regenerations after a cache expiry, Vercel’s CDN now collapses concurrent requests so only one per region triggers regeneration for ISR pages and image optimization blog post.
- Cuts wasted compute, improves cache coherency (single writer) and protects backends during spikes—automatically applied to cacheable paths Vercel blog post.
- Rollout impact: already collapsing over 3M requests per day across the network, with details on coherency and regional caches in the write‑up blog post.
- Changelog reference outlines broader platform upgrades accompanying the launch changelog note.
⚖️ Legal and governance skirmishes
Keep legal disputes separate from security tech: today adds the xAI vs OpenAI trade‑secret complaint timing and market context. Feature story excluded.
xAI sues OpenAI in California over alleged trade‑secret theft via ex‑staff hires
Filed Sept 25, xAI accuses OpenAI of inducing former employees (including Xuechen Li) to disclose Grok source code and data‑center know‑how, escalating the labs’ rivalry into court. The complaint frames a classic trade‑secret claim: valuable, protected code/ops info allegedly obtained by contractual breach. news brief, lawsuit summary
- Allegations include recruiting ex‑xAI staff (Li, Jimmy Fraiture, a senior finance lead) and using insider messages to show inducement to violate confidentiality agreements. lawsuit summary
- The suit extends earlier xAI legal actions (separate case vs. Li and antitrust‑adjacent salvos involving Apple), signaling talent flows as a contested attack surface in AI. lawsuit summary
- Timing matters: OpenAI is simultaneously locking in massive infrastructure and distribution—e.g., +$6.5B CoreWeave expansion (total $22.4B reserved) and a ~$100M Databricks deal to embed GPT‑5 in governed enterprise data. Expect discovery to probe code lineage and deployment footprints. capacity deal, databricks deal
- Practical takeaway for teams: tighten joiner/leaver controls, narrow repo access, log tool use, and codify clean‑room processes when hiring from competitors to avoid downstream injunction risk.