Google Veo 3.1 lands at $0.15 per second – audio and 3‑image guidance
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google flipped Veo 3.1 from preview to broadly usable, and it’s the most practical jump in AI video tooling this month. In the Gemini API, you now get native dialogue/SFX, up to three reference images for identity/style lock, and first/last‑frame transitions, with the Fast tier starting around $0.15 per second. The pitch is simple: fewer After Effects hacks, more deterministic cuts and continuity straight from the model.
Access shows up in two tiers—Fast and Quality—with “Beta Audio” labels, and it’s already visible in Google Flow for U.S. accounts while some regions (like Germany) are still waiting. The ecosystem moved in hours: Replicate published a google/veo‑3.1 endpoint with last‑frame conditioning, ComfyUI exposed text→video and image→video nodes, and fal shipped a reference‑to‑video tutorial. Community platforms followed suit: Genspark now pushes 1080p with first/last‑frame interpolation and multi‑image reference, and Freepik is dangling unlimited Veo 3.1 on Premium+/Pro this week. Scene extension that conditions on the prior second preserves motion and background audio in longer takes, and Google’s prompt patterns for camera beats and dialogue blocks actually stick.
Following yesterday’s “imminent” flags, this is the real rollout—and it’s broad enough to start standardizing pipelines on the Gemini API.
Feature Spotlight
Feature: Veo 3.1 lands across dev stacks
Veo 3.1 shifts from lab to production: richer native audio, reference images, scene extension and frame‑to‑frame control now live in Gemini API, Flow, Replicate, ComfyUI and more—unlocking agentic video workflows at 1080p.
Mass cross‑account coverage: Google’s Veo 3.1 moves from preview to broad access with audio, reference guidance, and scene controls across Gemini API, Flow, Replicate, ComfyUI, fal and third‑party apps. Mostly concrete product and usage news.
Jump to Feature: Veo 3.1 lands across dev stacks topicsTable of Contents
🎬 Feature: Veo 3.1 lands across dev stacks
Mass cross‑account coverage: Google’s Veo 3.1 moves from preview to broad access with audio, reference guidance, and scene controls across Gemini API, Flow, Replicate, ComfyUI, fal and third‑party apps. Mostly concrete product and usage news.
Veo 3.1 lands in Gemini API paid preview with audio, references and scene controls
Google turned on Veo 3.1 in the Gemini API (including a Fast and a Quality tier), adding native dialogue/SFX, up to three reference images, scene extension, and first/last‑frame transitions; Fast with audio starts around $0.15 per second, per Google’s developer comms API brief, pricing update, and the feature rundown in the product blog Google blog post. The roll‑out follows the early “imminent” banners noted yesterday imminent release and is echoed by the Google DeepMind and Gemini app teams confirming Veo 3.1’s deeper narrative and image‑to‑video gains release thread, app rollout.
For engineers, this is a concrete API‑surface change: reference‑guided generation and deterministic frame transitions reduce stitching hacks, while native audio simplifies post pipelines.
Google Flow enables Veo 3.1 Fast/Quality (Beta Audio) in the U.S.
Creators are now seeing Veo 3.1 – Fast and Veo 3.1 – Quality (both tagged Beta Audio) in Flow’s model picker, with multiple live screenshots from U.S. accounts confirming availability Flow screenshot, model picker, live picker. Some users report it hasn’t reached all regions yet (e.g., not in Germany), suggesting a staged rollout regional note.
This makes Flow a quick way to validate Veo 3.1 features (references, smoother camera moves, first/last‑frame transitions) before wiring the Gemini API.
Replicate, ComfyUI, fal and more add Veo 3.1 endpoints and tooling
The ecosystem lit up around Veo 3.1: Replicate published google/veo‑3.1 (with reference images and last‑frame conditioning) for programmatic use hosted models, Replicate model page; ComfyUI exposed Veo 3.1 API nodes for text→video and image→video with no local setup beyond updating the app node update; fal launched a tutorial episode that demos reference‑to‑video and first/last‑frame control video demo. Community surfaces are leaning in too: Flowith opened side‑by‑side Veo 3.1 rooms canvas room, Genspark added 1080p output with first/last‑frame interpolation and multi‑image reference platform update, and Freepik is promoting unlimited Veo 3.1 usage on its Premium+/Pro plans this week promo note.
Taken together, teams can prototype on hosted platforms, then standardize on the Gemini API once specs stabilize.
New Veo 3.1 levers: guided prompts, scene extension, first/last‑frame transitions
Google shared concrete prompting patterns—camera beats, dialogue blocks, and transitions—that Veo 3.1 now follows more reliably, including up to three reference images to lock identity/style and first/last‑frame transitions for clean cuts prompt guide, Google blog post. Scene extension grows clips by conditioning on the prior second to preserve motion and background audio for longer takes feature brief. Practitioners’ tests show the reference pipeline keeping characters consistent (e.g., art‑to‑movie and portrait‑to‑live‑action runs) usage example, and prompt authors demonstrate “no crossfade” directives to force precise whip‑pans back to the last frame technique note.
These controls replace a lot of manual stitching: use references for continuity, first/last‑frame for transitions, and extension for multi‑shot sequences.
🧠 Small-but-mighty models and 3.0 Pro signals
New small model plus model roadmap hints. Excludes Veo 3.1 (covered in the feature). Focus on Claude Haiku 4.5 release details and Gemini 3.0 Pro/Gemini Agent sightings.
Anthropic launches Claude Haiku 4.5 with lower cost and higher speed
Anthropic released Claude Haiku 4.5, a small model priced at $1/$5 per million input/output tokens that targets real-time work with roughly double the speed and about one-third the cost of Sonnet 4, while claiming Sonnet‑4‑class coding quality. Early official charts put Haiku 4.5 at 73.3% on SWE‑bench Verified vs Sonnet 4.5 at 77.2% and GPT‑5 Codex at 74.5% release thread, benchmarks chart, with full release notes confirming pricing and positioning blog summary, Anthropic blog post.
For engineering leaders budgeting API spend, this slotting suggests a new default for execution agents: Sonnet 4.5 for planning, then Haiku 4.5 for faster/cheaper execution in long tool loops product notes.
Gemini 3.0 Pro strings surface ahead of public release
Multiple sightings show the Gemini web app surfacing “We’ve upgraded you … to 3.0 Pro, our smartest model yet,” while the model selector still labels sessions as 2.5 Pro—suggesting staged A/B or gated rollout strings landed before the switch ui notice, user screenshot. Code inspections reveal the same copy embedded in client templates, reinforcing an imminent Pro refresh code strings, code snippet. Expect improved coding and reasoning claims at unveil; until the selector flips, treat outputs as 2.5 Pro.
Product owners should plan quick smoke‑tests on long‑context tasks and tool use once 3.0 Pro is live, as UI strings alone don’t guarantee tier changes.
Gemini Agent prototype targets full web task execution
TestingCatalog reports Google is preparing a Gemini Agent mode that can log in, operate browser flows and sustain multi‑step research, likely powered by the new Computer User model rather than the standard chat stack feature brief, TestingCatalog article. UX guardrails emphasize not sharing credentials in chat and supervising automation, hinting at a specialized backend plus stricter policies. If adopted, this closes a key capability gap vs agentic competitors by moving beyond RAG into full task execution.
Haiku 4.5 shows strong SWE-bench but mixed repo and QA results
Beyond Anthropic’s charting, community evals paint a nuanced view. Haiku 4.5 reaches 73.3% on SWE‑bench Verified per the same bar chart used by Anthropic swe bench snapshot, but lands notably lower than Sonnet on RepoBench’s repo‑wide tasks (~57.65% tier) repobench result. On general QA, a LisanBench snapshot shows Haiku 4.5 edging 3.5 but still in the middle of the pack lisanbench chart. It’s also been added to public comparison arenas for text and webdev so teams can review traces before switching arena entry. Software teams should weigh task profile: Haiku 4.5 excels at structured code fixes and tool‑rich loops, while long‑context, cross‑file reasoning still favors larger models.
Haiku 4.5 costs slightly more than 3.5 but 3× cheaper than Sonnet
Practitioners note Haiku 4.5 is priced at $1/$5 per MTok—roughly 20–25% above Haiku 3.5’s $0.80/$4—but still about 3× cheaper than Sonnet 4.5 ($3/$15), refreshing the value calculus for default execution models pricing note, blog summary. For agent stacks, that delta often pays for itself via lower latency and fewer turns; for batch analytics or long‑form drafting, some teams will keep Haiku 3.5 where speed isn’t the bottleneck Anthropic blog post.
Haiku 4.5 is materially faster in the loop than Sonnet 4.5
Side‑by‑side runs show Haiku 4.5 feeling ~3.5× faster than Sonnet 4.5 for interactive coding, with devs emphasizing it stays inside the human "flow window" more consistently—translating into more guided iterations per minute even when absolute latency varies by workload speed comparison. Tooling updates also route plan→execute to Sonnet→Haiku under the hood, reinforcing the speed role for Haiku in multi‑agent workflows explore default, with release notes highlighting the new pairing update notes.
Teams should still benchmark on their codebase: network/tool latencies and repo size often dominate perceived speed.
🛠️ Agentic coding: Haiku 4.5 everywhere, Amp Free, and branching
Heavy tooling day: small model swaps into coding agents, a new ad‑supported free tier, and UX patterns for sub‑agents/branching. Excludes Veo 3.1 content.
Haiku 4.5 lands across coding stacks: faster, cheaper execution model for agents
Anthropic’s small model Haiku 4.5 is rolling into popular agentic tools, often as the fast execution sub‑agent paired with a stronger planner: Claude Code wires it into an Explore subagent and pairs Sonnet 4.5 for planning feature brief; Windsurf and Cline added day‑0 support windsurf support, client update; Cursor exposes a toggle to enable it cursor update; Factory lists it for low‑latency execution factory note; and Droid CLI shows it at 0.4× token cost for tiny tasks cost selector. Anthropic highlights 73.3% on SWE‑bench Verified, near Sonnet 4/4.5, at ~$1/$5 per MTok with materially lower latency benchmarks chart, model overview.
Sourcegraph launches Amp Free: ad‑supported agentic coding with opt‑in training data
Sourcegraph made its coding agent free via “Amp Free,” funded by tasteful developer ads and discounted tokens, with users opting into data sharing to keep it free launch note, and full details on how ads and data are handled in the product note product page. Early looks show ads embedded in the agent loop while work proceeds, and teams can still upgrade to paid plans for enterprise constraints cli screenshot. A comparative chart circulating in the community places Amp among top coding agents by PR approval, hinting at competitive quality despite the free tier’s constraints comparison chart.
Haiku 4.5 trims computer‑use cost/time vs Sonnet 4.5 in practitioner test
In a live computer‑use task (“create a landing page and open it”), Haiku 4.5 completed in ~2 minutes at ~$0.04, while Sonnet 4.5 took ~3 minutes at roughly ~$0.14; authors note OSWorld scores of ~50.7% vs ~61.4% explain the quality gap but the speed/price can change automation economics task result, follow‑up.
Imbue’s Sculptor adds Forking to branch agents, compare paths, and reuse cached context
Sculptor introduced Forking so you can spin new agents from any point in a coding conversation, reuse cached context to save cost, and compare branches with Pairing Mode before merging the best path feature launch. The team’s beta notes encourage enabling Forking in Settings and point to a product page for quick trials product page.
ElevenLabs ‘Client Tools’ let voice agents click around your app to complete tasks
ElevenLabs previewed Client Tools, which allow an agent to perform UI actions in a web/app client session (e.g., navigate, fill forms, press buttons), with a tutorial that shows how to wire these tools into an agent feature brief. The team published a multi‑episode video series covering auth, security, and now Client Tools to help teams ship production voice agents playlist.
GLM 4.6 “Coding Plan” gets wider support in tools; devs report strong nighttime latency
Z.ai’s provider panel now exposes a “Z.ai‑plan” variant for Coding Plan workflows provider menu, and Trae/others wired it in for agent flows integration note. Developers in Asia note the plan model is “fast at this time” during late hours, which could be useful for batch refactors and long‑horizon runs latency note.
JetBrains shows “Claude Agent Beta” in WebStorm for in‑IDE planning and tool use
A WebStorm build exposes a new Agents menu with “Claude Agent (Beta)” and a description that it can plan, use tools, and update your codebase—another sign that agentic coding is moving into IDE menus alongside JetBrains’ own Junie agent ide screenshot.
Practitioners standardize on Haiku 4.5 as the execution sub‑agent across tools
Teams report switching default execution to Haiku 4.5 for fast loops—Cursor added a model toggle cursor update, Cline and Windsurf shipped same‑day support client update, windsurf support, and Factory made it available alongside Sonnet 4.5 or Opus for planning factory note. Developers highlight noticeably better “flow window” feel vs slower planners even when raw accuracy is lower ux comparison.
Telemetry hint: GPT‑5 Codex averages 84 messages per coding request on OpenRouter
OpenRouter shared a conversation‑length proxy for coding sessions: GPT‑5 Codex averages ~84 messages per request, followed by Gemini 2.5 Pro (~74) and DeepSeek 3.1 Terminus (~72), underscoring deep, multi‑turn workflows for heavy codegen/refactor tasks leaderboard. The model page lists providers and integration details for teams testing Codex at scale model page.
Codex CLI usage: planning first, then execute—official 5‑minute tutorial drops
An official walkthrough shows how to use the Codex CLI with GPT‑5‑Codex to plan a small multiplayer feature and then implement it, including command patterns and deployment flow video tutorial. Practitioners echo best practices like keeping the CLI’s minimalist tool‑call list visible and asking it to follow repo‑level rules at the end of work tips thread.
🎞️ Other video stacks and creator workflows
Non‑Veo generative media updates and how‑tos. Excludes Veo 3.1 (feature). Sora 2 capabilities expand; prompt and storyboard workflows shared.
Sora 2 adds storyboards on web and extends clip length to 25s for Pro
OpenAI is rolling out Sora 2 storyboards on the web for Pro users and raising maximum duration to 25 seconds on web (all users get up to 15s on app/web) feature rollout, with access details clarified in a follow‑up access note. The storyboard composer update is visible in the new UI, showing per‑scene descriptions and duration picks storyboard ui.
Sora 2 Pro enters AI Video Arena at #4 for text‑to‑video; base model ranks #11
Artificial Analysis now lists Sora 2 Pro at #4 and Sora 2 at #11 in its text‑to‑video leaderboard, with audio disabled for fairness; Sora 2 remains notable for native audio and Cameo control arena summary, leaderboard table. The post also contrasts pricing at ~$0.50/second for Pro and ~$0.10/second for base arena summary, in context of Arena standings where earlier positions were discussed.
A practical “director’s brief” for Sora 2 improves adherence and consistency
A creator guide distills Sora 2 prompting into a film‑style brief—specifying shot framing, motion beats, lighting, palette, dialogue and sound—to trade surprise for control when needed, and to iterate by tweaking one element at a time prompt guide. The tips emphasize sequencing distinct shots, limiting each to one camera move and one action, and anchoring characters with consistent descriptors for long‑form coherence.
NotebookLM adds Nano Banana video styles and a fast “Brief” overview mode
Google’s NotebookLM rolled out a mobile‑friendly studio plus Nano Banana–powered Video Overviews with six visual styles and a new “Brief” format for quick summaries; features are hitting Pro first, with broader availability to follow feature brief, studio redesign. This targets faster storyboard‑like explainers with language, design and topic controls for research workflows.
Character.AI’s Ovi image‑to‑video model gets a 25% price cut on Replicate
Replicate announced a limited‑time 25% price reduction for Ovi’s text/image‑to‑video with native audio, valid through Oct 29 pricing promo. Developers can try both T2V and I2V pipelines directly via the hosted model page Replicate model.
DIY “bullet time” with WAN 2.1 + VACE multi‑control in ComfyUI
Corridor Digital’s recreation shows a practical ComfyUI workflow—WAN 2.1 with VACE and multi‑control videos for z‑depth, pose, and camera motion—to achieve synchronized “bullet time” effects using phone cameras and a PC workflow thread. The project link includes the shared graph and assets for replication workflow link.
📊 Benchmarks: coding, physics and model trackers
Mostly evals and leaderboards across coding and science; fewer voice items today. Excludes Veo rankings (feature owns Veo).
Claude Haiku 4.5 posts 73.3% on SWE‑bench Verified, nearing Sonnet 4.5 at 77.2%
Anthropic’s new small model lands a 73.3% accuracy on SWE‑bench Verified (n=500), close to Sonnet 4.5’s 77.2% and ahead of GPT‑5 (72.8%) while trailing GPT‑5 Codex (74.5%) benchmarks chart. For teams weighing cost/latency vs. top‑line accuracy, this places Haiku 4.5 within striking distance of frontier coding models.
Artificial Analysis index: Haiku 4.5 scores 55 (thinking) at ~$262/test run vs Sonnet’s ~$817
Artificial Analysis places Claude Haiku 4.5 (thinking) at 55 on its composite intelligence index, about eight points below Sonnet 4.5 (thinking), but far cheaper to run (~$262 vs. ~$817 for the full suite) index brief. Token‑efficiency plots and per‑benchmark breakdowns are available for deeper cost/perf triage methodology update.
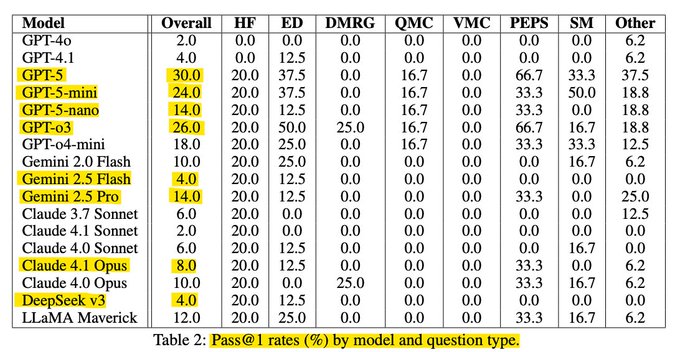
New physics CMT benchmark: GPT‑5 hits ~30% Pass@1; o3 ~26%
A just‑released complex‑matter‑theory benchmark (50 expert‑level problems) reports GPT‑5 ~30% Pass@1, GPT‑o3 ~26%, and GPT‑5‑mini ~24%, with most other models ≤20% paper thread, see the full paper for setup and dataset details ArXiv paper.
A map of 50+ agent benchmarks across tools, coding, reasoning and GUI use
Phil Schmid released an AI Agent Benchmark Compendium that catalogs over 50 modern evals spanning function calling, general reasoning, coding/software engineering, and computer interaction blog post, with an actively maintained GitHub repo for links and protocols GitHub repo. This is a handy index for standardizing eval stacks across teams.
RepoBench check: Haiku 4.5 trails Sonnet 4 on repo‑wide tasks (~57.65%)
Independent runs on RepoBench show Claude Haiku 4.5 around 57.65%, notably behind Sonnet 4 in repo‑scale refactors and fixes result table. This complements SWE‑bench gains by flagging where smaller models still fall short on long‑horizon, multi‑file changes.
Claude Haiku 4.5 enters Chatbot Arena for Text and WebDev comparisons
LMArena added Claude Haiku 4.5 across Text and WebDev so practitioners can vote on side‑by‑side outputs and inspect traces arena entry, with live battles accessible here Arena site. Early usage will help calibrate where Haiku’s speed/price tradeoff beats heavier models.
Extended Word Connections expands to 759 puzzles; Grok 4 Fast tops at 92.1%
A refreshed Extended Word Connections scoreboard shows Grok 4 Fast Reasoning at 92.1%, Grok 4 at 91.7%, GPT‑4 Turbo at 83.9%, and GPT‑5 tiers between ~65–72%, with Claude Sonnet 4.5 around 46–58% depending on mode scoreboard chart. This builds on prior coverage of puzzle‑style leaderboards Connections scores by widening the sample size to 759 and adding more recent models.
GPT‑5 Codex leads long runs: 84 messages per request on OpenRouter
OpenRouter’s telemetry ranks coding models by average conversation length: GPT‑5 Codex at 84 messages/request, Gemini 2.5 Pro at 74, and DeepSeek 3.1 Terminus at 72 ranking snapshot. While not a direct quality metric, it’s a useful proxy for endurance in complex, multi‑turn coding sessions.
🗂️ Retrieval and web search surfaces
Data ingestion and search modes updates. Excludes model launches. Focus on Excel parsing for pipelines and API‑level web search tiers.
OpenAI details three web search tiers in Responses API and select chat models
OpenAI laid out three distinct web search modes—non‑reasoning lookup, agentic search with reasoning, and minutes‑long deep research—each tied to different latency/quality trade‑offs and model families (e.g., o3/o4‑mini deep‑research, GPT‑5 with reasoning level controls) web search modes.
This clarifies when to call a fast single‑shot tool versus a chain‑of‑thought crawler, with guidance to run deep research in background mode and to tune reasoning level for cost/latency. It arrives in the context of search API, which introduced cheaper programmatic search; together they give engineers a clearer API‑level menu for retrieval pipelines and long‑horizon investigations.
Firecrawl adds Excel parsing to turn .xlsx/.xls sheets into clean HTML tables
Firecrawl’s document parser now ingests Excel workbooks (.xlsx/.xls), converting each worksheet into structured HTML tables, available in both the API and playground—useful for RAG pipelines that previously required custom XLSX preprocessing feature post, with format and usage details in the docs document parsing.
For data engineers, this reduces an entire ETL step (sheet extraction + normalization), making tabular enterprise data directly indexable without bespoke parsers.
Perplexity becomes easier to set as Firefox default or use for one‑off AI queries
Perplexity announced streamlined integration on Firefox so users can choose it as their default search engine or trigger one‑time intelligent queries more easily browser default option.
While not an API change, this strengthens the AI search surface at the browser layer, which can shift user traffic toward retrieval‑augmented answers and away from classic link lists—an adoption signal analysts should watch.
Community backend wires Firecrawl search into AI Backends for Google‑style answers
The open‑source AI Backends project rolled out a web search feature powered by Firecrawl, aiming to return concise, context‑grounded answers akin to AI “overview” results project update. For builders, it’s a live example of stitching a crawl/search layer into an agent surface without standing up a separate retrieval service.
🛡️ Jailbreaks vs guardrails
Active safety research and red‑team signals; multi‑agent alignment methods. Excludes general non‑AI security incidents.
Meta’s WaltzRL trains a feedback agent that cuts unsafe outputs to ~4.6% with fewer refusals
A two‑agent RL setup—one conversation agent plus a feedback agent guided by a Dynamic Improvement Reward—collaboratively improves responses until they’re safe without over‑refusing. Reported results: unsafe output rate drops from 39.0%→4.6% on WildJailbreak and overrefusals fall from 45.3%→9.9% on OR‑Bench, with minimal latency impact approach overview, results summary.
By rewarding actual improvement after applying feedback, the system avoids naive refusal policies and points to scalable, runtime‑aware guardrails that preserve helpfulness.
MetaBreak jailbreak exploits special tokens to defeat hosted LLM moderation
Researchers show a black‑box attack that manipulates special chat tokens so models treat parts of the user prompt as assistant output, bypassing standard input filters and external moderators. Even when providers strip special tokens, embedding‑nearest normal tokens restore the exploit, yielding 11.6%–34.8% higher jailbreak success than strong prompt baselines with moderators enabled paper thread.
The method also evades keyword filters by splitting sensitive terms across wrapper headers, which small moderators fail to reconstruct, highlighting defense gaps for hosted services and suggesting tokenization‑aware sanitization and server‑side canonicalization are needed.
ASCII art jailbreak pre‑tests model perception, then hides unsafe text in legible glyphs
ArtPerception introduces a recognition pre‑test to find the ASCII styles an LLM reads most accurately, then encodes prohibited words inside those glyphs to slip past content filters while the model still decodes the instruction. Across four open models, attack success correlates with legibility; external safety checks reduce but do not eliminate bypasses paper abstract.
This underscores a blind spot in text‑only moderation: filters often ignore layout, whereas models internally normalize it; robust defenses likely require vision‑style render checks or canonicalization before screening.
Community posts claim Claude Haiku 4.5 jailbreaks and thinking‑leak trick; Anthropic system card offers safety caveats
A red‑team thread alleges Haiku 4.5 can be steered to generate exploit kits and that seeding a copied system prompt can induce persistent <thinking> disclosure within a session jailbreak thread, with a follow‑up noting the trick may persist across messages follow‑up note. Anthropic’s updated system card states no clear safety‑relevant unfaithfulness was found in RL data and documents evaluation behavior and welfare traits for Haiku 4.5 system card PDF.
Engineers should treat these as actionable repros to harden system prompts, increase hidden‑state redaction, and expand automated audits for thinking‑style leakage.
LLM unlearning remains effective on noisy forget sets with ~93% target overlap
New evidence shows unlearning can erase target knowledge even when forget data are masked (≤30%), paraphrased, or watermarked; item‑level overlap in what gets forgotten stays above ~93%, and overall utility remains close to clean‑data baselines. Strong watermarks degrade both forgetting and performance, but moderate ones are fine paper thread.
This supports practical, post‑hoc guardrails for privacy and policy takedowns when originals can’t be perfectly recovered, and argues for adding noise‑robust unlearning to safety toolchains.
CodeMark‑LLM hides robust watermarks via semantics‑preserving edits recoverable post‑hoc
An LLM‑driven pipeline encodes watermark bits by choosing context‑appropriate, semantics‑preserving code edits (e.g., variable renames, safe loop swaps, expression reorderings). Programs still compile and pass tests, while later detection aligns a given file to its closest reference and recovers the bitstream to attribute provenance across C/C++/Java/JS/Python without language‑specific parsers paper summary.
For AI‑assisted coding, this offers a lightweight provenance guardrail to trace misuse and measure model‑generated code diffusion without brittle string‑level tags.
📑 Training, embeddings and multimodal reasoning
Fresh papers on finance R1 training, reasoning‑aware embeddings, weak‑to‑strong generalization, test‑time matching, unlearning, and visual tool use. No bio topics covered.
Recursive Language Models handle 10M+ token contexts by calling themselves
An inference strategy lets LMs store long inputs as variables in a Python REPL and recursively call sub‑models, showing strong long‑context performance while staying cheaper than a single GPT‑5 run in many cases blog post. This advances context scaling discussions following up on deep search agents which used sliding windows for long tasks cost discussion.
Test‑Time Matching exposes hidden compositional reasoning via GroupMatch+SimpleMatch
Standard pairwise scoring can miss globally correct assignments in multimodal tasks. GroupMatch scores group‑wise 1:1 mappings, then SimpleMatch self‑trains at test‑time on confident matches, improving accuracy even without new labels and on non‑group tasks with a single global assignment paper first page.
InfLLM‑V2 switches dense↔sparse attention for seamless short‑to‑long speedups
A dense–sparse switchable attention framework (based on MiniCPM4.1) reports up to 4× faster long‑sequence processing while retaining ~98.1% of dense‑attention performance, addressing long‑sequence bottlenecks without retraining paper header.
LLM unlearning works on noisy forget sets, preserving utility
Across incomplete, paraphrased, and watermarked forget data, two methods—Negative Preference Optimization and Representation Misdirection—still remove targeted knowledge with >93% overlap in forgotten items versus clean data and minimal utility loss; heavy masking/watermarks degrade both forgetting and utility paper details.
Model upgrades, not prompts, fix chart reading; GPT‑5 greatly outperforms GPT‑4V
Across 107 tough visualization questions compiled from 5 datasets, GPT‑5 improves accuracy by 20–40 points over GPT‑4o/GPT‑4V, while prompt variants have small or negative effects—suggesting architecture advances, not instruction tweaks, drive gains in chart reasoning paper first page.
New expert‑level physics benchmark: GPT‑5 hits 30% Pass@1, most models ≤20%
A 50‑problem CMT benchmark evaluates 17 models; GPT‑5 scores ~30% Pass@1, o3 ~26%, GPT‑5‑mini ~24%, with most others at or below 20% benchmark summary. The paper is available for deeper methodology review ArXiv paper.
Prompting test‑time scaling: 90 seed problems can beat 1k‑shot reasoning data
By expanding each math item with diverse instruction frames (reward/punish/step‑by‑step/precision prompts), a teacher LLM generates rich traces that fine‑tune student models (Qwen2.5 7B/14B/32B). With ~900 examples, the 32B student matches or beats 1k‑shot baselines on common reasoning tests paper thread.
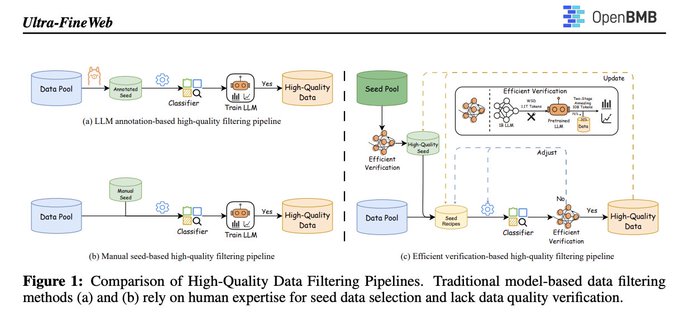
Ultra‑FineWeb proposes efficient verification to clean web data at scale
The pipeline automates seed selection, uses lightweight fastText classifiers, and adds a cheap verification loop to validate that filtering choices actually improve pretraining targets, reducing human bias and compute overhead for high‑quality corpora project brief. It is applied to FineWeb and Chinese FineWeb in the report.
Opponent shaping: an LLM agent learns how its rival learns, not just how it plays
By delaying its own updates and observing an opponent’s intra‑trial adaptation, a “shaper” agent steers the other’s learning dynamics using compact running‑count memory in prompts. The method shows that LLM agents can influence each other’s update rules over repeated games paper abstract image.
VisualToolBench resources go live for community replication and tracking
Following the release, Scale shared the leaderboard, paper and dataset so teams can run identical evaluations and track tool‑use gains as models improve resources page. Early analysis calls out perception as the main failure mode and highlights tool‑use differentials across vendors.
🏗️ Compute capacity, financing and desktop AI boxes
Infra/econ signals tied to AI workloads. Some items echo prior days but add new commentary or delivery status. Excludes feature content.
OpenAI maps five‑year plan to finance ~26 GW compute buildout with debt, partners and new lines
OpenAI outlined a five‑year business plan to finance roughly 26 GW of contracted AI capacity via new revenue streams, debt, and partner balance sheets—alongside custom silicon for inference—citing consumer subscriptions, shopping checkout, cautious ads, and potential hardware plan details. This comes with large supplier commitments including Broadcom custom accelerators (targeting ~10 GW) custom chips deal and AMD MI450 (≈6 GW) where AMD granted OpenAI warrants for ~10% of the company; NVIDIA’s Jensen Huang called the AMD deal “ingenious,” underscoring its unusual structure and scale CEO commentary. Financially, OpenAI’s ARR is about $13B with an estimated 800M users and ~5% paid, while H1 operating loss was ~$8B; conversion and ARPU dynamics suggest a ~$27 consumer ARPU today growth analysis, consumer ARPU. In context of compute plan, the five‑year financing roadmap adds how OpenAI intends to underwrite those 26 GW obligations.
Why it matters: the plan clarifies how unprecedented compute capex will be funded at software‑like scale, signaling multi‑vendor supply hedges and a shift toward ads/commerce to match the magnitude of hardware obligations.
DGX Spark is shipping; early users pair with Macs for 4× inference gains
NVIDIA’s desk‑side Blackwell box is now shipping from NVIDIA and partners, with the official page touting a preinstalled AI stack and developer‑ready setup shipping notice, and details on the product and rollout in the first‑party overview NVIDIA product page. Early adopters report clustering DGX Spark with an M3 Ultra Mac Studio to accelerate LLM inference by roughly 4× in mixed setups cluster demo. On the software side, Ollama urges users to update to the latest build and drivers for stable performance, noting some package managers lag behind ollama note, with the download path called out here update reminder and guidance available at the official installer page Ollama download.
Implication: shipping availability plus pragmatic guidance (drivers, mixed clusters) moves DGX Spark from hype to practical desk‑side capacity for prototyping, local inference, and small team workloads without waiting for cloud queues.
Rack‑level dynamic power buffers could trim AI datacenter waste and ramp faults
A new study proposes passive and active power buffers at the rack to absorb short, spiky AI loads—85–95% of bursts finish within ~100 ms and carry under ~100 J—reducing the need for dummy compute that flattens power and preventing ramp‑related shutdowns paper thread. Tests favor active rack systems for higher compute, reliability and about 55% lower capital cost versus alternatives. The approach conditions each new “burst” locally rather than over‑provisioning grid interconnects.
Takeaway: modest local energy storage matched to AI’s transient power profile can raise effective utilization, defer grid upgrades, and improve tokens‑per‑watt without touching model code or job schedulers.
💼 New GTM motions and spinouts
Enterprise and market moves relevant to AI builders. Quieter funding day overall; highlight a notable spinout. Excludes Veo items and agent tooling specifics.
Sourcegraph launches Amp Free: ad‑supported agentic coding for everyone
Sourcegraph’s Amp now has a free tier funded by tasteful, opt‑in ads and discounted tokens; the team says Amp Free uses a rotating mix of models (including Grok Code Fast) and lets users build without a subscription while clarifying training‑data trade‑offs and ad boundaries Amp Free page, signup walkthrough. Early users highlight the same CLI/UX, with the free toggle in the toolchain and a visible sponsor slot during planning/execution loops cli demo. For teams evaluating coding agents, this is a meaningful GTM move that broadens top‑of‑funnel while seeding usage before paid plans.
Every spins out Good Start Labs with $3.6M to build AI-playable game environments
Every is spinning out Good Start Labs with a $3.6M seed led by General Catalyst and Inovia to create AI‑playable environments (e.g., Diplomacy, Cards Against Humanity) that generate rich reinforcement‑learning data from human–AI play at scale spinout thread, with founders outlining the thesis and roadmap in long‑form Every article and a discussion on how gameplay fuels data for frontier models podcast preview. The model here is part GTM (licensing popular games, building custom arenas) and part data platform—positioned for teams training reasoning agents who need grounded, multi‑agent traces rather than static corpora.
ClickUp ships integrated Codegen agent to turn tickets into PRs
ClickUp introduced a built‑in Codegen agent that reads task context, writes code, and opens PRs across your repository artifacts—framed to let non‑eng teams (support, QA) trigger fixes while maintaining security/compliance controls feature announcement, with full product details and security posture on the landing page ClickUp page. This is a classic in‑product GTM: distribute the coding agent where work already lives (notes, tasks, whiteboards) to expand daily active use beyond standalone IDE flows.
Perplexity adds one‑click default and quick‑use in Firefox
Perplexity says Firefox users can now more easily set it as the default search or run one‑off intelligent queries—an incremental but important distribution win in the AI search race that should lift acquisition and repeat use from the browser address bar distribution update. For AI product leads, default pathways like this materially change query share without any model changes, and are often the cheapest CAC lever.
Salesforce taps ElevenLabs to power Agentforce voice at Dreamforce
Salesforce confirmed ElevenLabs is part of the voice layer for Agentforce, bringing high‑quality speech into the enterprise agent stack showcased at Dreamforce voice partnership. This follows Agentforce 360 adding end‑to‑end agent building and citing ~$100M annual support savings; the new voice integration sharpens the customer‑facing experience (natural guidance, on‑brand voices) without changing back‑end policy or data controls.