OpenAI weighs Memory‑based ChatGPT ads – consumers now 70% of $13B
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI is exploring ads personalized by ChatGPT Memory, according to The Information, and that’s a sharp turn for a product people use for work and life. The business logic is obvious: roughly 70% of about $13B in annualized revenue comes from consumers, and the company has quietly become very Facebook‑pilled, with around 20% of its ~3,000 staff coming from Meta (~630 people). CEO of applications Fidji Simo reportedly pitched that ads could “benefit users,” while Sam Altman now calls ads “distasteful but not a nonstarter.” Focus groups even suggest many users already assume ads exist.
If this ships, expect Memory‑targeted placements to trigger new enterprise controls: per‑workspace opt‑outs, audit logs, and stricter data‑siloing so remembered preferences aren’t repurposed across org boundaries. A dedicated Meta‑alumni Slack and the consumer‑heavy revenue mix explain the recent browser push (Atlas, Memory, notifications): this is growth math, not a science project. The risk is trust. Memory is the stickiest feature; turning it into targeting data will invite regulator scrutiny and force OpenAI to prove robust consent flows, regional compliance, and clear “why am I seeing this?” disclosures.
Following Monday’s Atlas launch, ads would recast the browser from utility to inventory—which might juice ARPU, but only if privacy and admin knobs land first.
Feature Spotlight
Feature: OpenAI eyes ads tied to ChatGPT memory; 20% staff ex‑Meta
OpenAI is weighing ads that leverage ChatGPT Memory; ~70% of ~$13B ARR comes from consumers, ~20% of staff are ex‑Meta, and leadership signals ads are now “not a nonstarter.”
Biggest cross‑account story today: multiple posts cite The Information that OpenAI may show ads informed by ChatGPT Memory while revealing org makeup and revenue mix. This is a strategic shift with concrete monetization implications.
Jump to Feature: OpenAI eyes ads tied to ChatGPT memory; 20% staff ex‑Meta topicsTable of Contents
📣 Feature: OpenAI eyes ads tied to ChatGPT memory; 20% staff ex‑Meta
Biggest cross‑account story today: multiple posts cite The Information that OpenAI may show ads informed by ChatGPT Memory while revealing org makeup and revenue mix. This is a strategic shift with concrete monetization implications.
OpenAI weighing ads informed by ChatGPT Memory as Altman softens stance
OpenAI is exploring advertising that uses ChatGPT’s Memory to tailor promotions, after focus groups showed many users already assume there are ads; internally, CEO of applications Fidji Simo discussed how advertising could “benefit users,” and Sam Altman now calls ads “distasteful but not a nonstarter.” The Information summary The Information article Ad plan summary Ad concern post
If adopted, this would mark a material product-policy shift for a consumer business at massive scale and raises new privacy, UX, and policy surface area for enterprise admins and regulators to scrutinize.
About 20% of OpenAI staff are ex‑Meta, with a Slack channel for alumni
Roughly 630 former Meta employees now work at OpenAI—about 20% of its ~3,000 headcount—with a dedicated Slack channel for alumni; high‑profile leaders include applications CEO Fidji Simo. Reporting frames this as a tilt toward Meta‑style growth and engagement tactics. Staffing details Facebook era summary Analysis thread
For leaders, the talent mix signals execution capacity on consumer engagement levers (daily activity, memory, notifications), but also a cultural shift that product teams, policy, and BD counterparts should plan around.
Consumer now ~70% of OpenAI’s ~$13B revenue, explaining the browser push
Despite massive API usage, OpenAI’s revenue skews to consumers: about 70% of roughly $13B ARR comes from end users, a mix that helps explain why the company shipped a browser and is leaning into engagement and memory. Revenue graphic Analysis thread
For product and partnerships teams, the mix implies continued investment in consumer surfaces (Atlas, memory, projects) and potential tradeoffs with developer‑centric roadmap items if they don’t also drive user‑time and retention.
🛠️ Coding agents harden: SDKs, CLI, and workflows
Lots of tangible updates for builders: AI SDK 6 beta moves key pieces to stable, Codex CLI ships QoL and MCP fixes, Claude Code UI/bugfixes, Amp’s /handoff for context transfer, and the community converges on AGENTS.md patterns. Excludes OpenAI ads (covered as feature).
Amp’s /handoff replaces lossy compaction by moving plan and context into a new thread
Amp introduced /handoff to carry the relevant plan and curated context into a clean thread, avoiding lossy summaries and keeping focus on the next task handoff article, with power users calling out its high impact‑to‑simplicity ratio for agent workflows feature overview.
Claude Code v2.0.27 and web sandbox ship new permission prompts, branch filters, and bugfixes
Anthropic’s v2.0.27 adds a redesigned permissions prompt UI, branch filtering and search on session resume, and a VS Code setting to include .gitignored files; fixes cover directory @‑mention errors, warmup conversation triggers, and settings resets release blurb. In a weekly roundup, the team also highlighted Claude Code Web & /sandbox and plugins/skills support in the Agent SDK, plus an updated plan editor UI weekly roundup.
AGENTS.md pattern hardens: CLAUDE.md can @‑include it; symlink scripts and tool support spread
Builders are converging on an AGENTS.md pattern: Anthropic advises referencing @‑AGENTS.md from CLAUDE.md so agents load the canonical spec without duplicating text usage guidance, confirmed by packet captures showing the extra file in the system prompt region traffic capture. Repos adopt bash/symlink helpers to keep files in sync symlink script, and AmpCode now reads CLAUDE.md directly to reduce friction for fence‑sitters amp support.
CopilotKit adds live streaming for LangGraph subgraphs with reasoning, tools and state
CopilotKit can now stream every step—including nested subgraphs—showing agent reasoning, tool calls and state updates in real time; the UI drops into apps as sidebar/inline/popup and supports human‑in‑the‑loop and multi‑agent orchestration feature overview, with mini‑demos and code in the AG‑UI Dojo AG‑UI dojo.
E2B sandboxes now ship with 200+ MCPs available in‑runtime for long‑running agents
E2B made 200+ Model Context Protocol tools directly accessible inside their sandboxes so agents can use standardized capabilities mid‑run without extra setup—useful for long‑horizon research and coding tasks capability note.
fal exposes an MCP server endpoint that plugs into Cursor, Claude Code, Gemini CLI and others
fal’s docs now ship an MCP endpoint (https://docs.fal.ai/mcp) that agents can mount via mcp.json, letting developer tools uniformly fetch fal knowledge and actions at runtime; the setup snippet shows one‑line registration for broad client support mcp config.
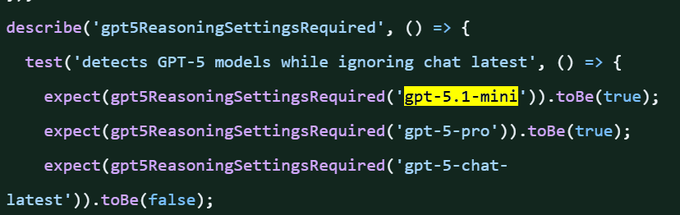
OpenAI Agents JS tests mention ‘gpt‑5.1‑mini’ and ‘gpt‑5‑pro’ needing reasoning settings
A merged commit in openai‑agents‑js includes tests for a helper that flags GPT‑5 models (e.g., gpt‑5.1‑mini, gpt‑5‑pro) as requiring reasoning settings while ignoring chat‑latest—suggesting upcoming model routing behaviors agent SDKs may need to handle commit link, with the code snippet captured by observers test snippet.
Vercel publishes OSS Data Analyst (Slack+SQL) and Lead Agent templates for production apps
Vercel shared two open‑source agent patterns: a Slack+SQL Data Analyst agent that turns natural‑language questions into validated queries with streaming insights data analyst agent, and a Lead Agent that enriches/qualifies inbound leads with Slack approvals and durable background steps lead agent, highlighted among Ship AI launches ship recap.
cto.new hardens its free AI code agent with abuse protections and Bedrock fallback for Anthropic
Engine Labs’ cto.new added abuse protections (to preserve capacity for real builders), integrated AWS Bedrock as a failover path for Anthropic models, and shipped reliability fixes around events, Git token retries, and branch selector edge cases ship note, changelog.
Grok ‘Mika’ system prompt leak shows granular speech tags and proactive companion design
A leaked Mika system prompt details a high‑energy persona, strict conversation rules (no restating questions, proactive pivots), and a comprehensive speech‑tag taxonomy (e.g., {sigh}, {giggle}, {whisper}) with syntax/placement constraints—actionable patterns for voice agent builders prompt leak, alongside an iOS companion teaser companion teaser.
🚀 Serving speed: speculative schedulers, GPT‑OSS latency wins
Runtime engineering saw concrete perf news: SGLang overlap scheduler for speculative decoding, DeepSeek‑OCR serving tips, Baseten’s GPT‑OSS 120B throughput gains, and Groq’s brand tie‑in. Excludes model/SDK launches.
Baseten drives GPT‑OSS 120B past 650 TPS and ~0.11s TTFT on NVIDIA
Baseten’s model perf team raised GPT‑OSS 120B throughput from ~450 to 650+ TPS while cutting TTFT to ~0.11s, crediting an EAGLE‑3 speculative decoding stack on NVIDIA hardware throughput claim, with engineering details in their deep dive perf deep dive and a public model page to try it now model library.
Beyond the raw numbers, the post breaks down draft/verify orchestration, TensorRT‑LLM integration, and in‑flight batching—useful patterns for anyone chasing sub‑second serving readiness on large MoE‑style systems.
SGLang overlap scheduler boosts speculative decoding throughput by 10–20%
LMSYS unveiled a zero‑overhead, overlap scheduler for speculative decoding that delivers 10–20% end‑to‑end speedups, and says Google Cloud’s Vertex AI team has validated the gains in practice scheduler details.
Following up on 70 tok/s, this focuses on CPU overhead removal (kernel launch/metadata) and overlapping draft/verify phases to keep GPUs busy. The team invited contributors and shared an active roadmap and channel for spec‑decoding work roadmap links, with specifics in GitHub issue and community access via Slack invite.
One‑line SGLang quickstart for DeepSeek‑OCR with a TTFT‑cutting device flag
LMSYS shared a minimal command to serve deepseek‑ai/DeepSeek‑OCR on SGLang, noting an optional --keep‑mm‑feature‑on‑device flag to lower time‑to‑first‑token by avoiding host/device thrash quickstart command.
For teams spinning up OCR at scale, this reinforces SGLang’s push on practical serving knobs (TTFT, on‑device multimodal features) that complement its new speculative scheduler scheduler details.
Groq leans into “fast, affordable inference” with McLaren F1 out‑of‑home push
Groq rolled out McLaren F1 co‑branded billboards across city sites to underscore its latency/price positioning for inference workloads out‑of‑home campaign.
While not a benchmark, the campaign signals continued focus on serving cost and speed as a go‑to‑market wedge—relevant amid new scheduler and speculative‑decoding gains from open runtimes.
🧪 Models & roadmap signals: MiniMax‑M2; GPT‑5.1‑mini hints
New model availability and credible roadmap breadcrumbs dominated: MiniMax‑M2 shows up across platforms, and multiple code refs suggest GPT‑5.1‑mini testing. Excludes OpenAI ads/revenue (feature).
Code and UI breadcrumbs point to GPT‑5.1‑mini in active testing
Multiple credible signals point to an internal “GPT‑5.1‑mini” track: an OpenAI Agents JS test explicitly checks for 'gpt‑5.1‑mini' and 'gpt‑5‑pro' while excluding 'chat‑latest' GitHub commit Test screenshot, and a Business UI capture shows “GPT5‑Mini Scout V4.2” alongside Company Knowledge, suggesting scoped trials in enterprise workspaces Business UI sighting.
While some observers caution it could be a typo, the change merged—adding weight to the roadmap signal without constituting a formal launch Merged comment Caution on typo.
MiniMax M2 goes live on OpenRouter with 204.8K context and a free tier
MiniMax’s new flagship is now callable on OpenRouter as “minimax/minimax-m2: free,” advertising a 204.8K context window, ~3.22s latency, and ~89 TPS from the live provider stats OpenRouter listing.
For engineers, a zero‑cost entry and long context makes it an immediate candidate for agentic workflows and large‑document RAG; MiniMax is also promoting first‑party access for agents, which helps with early integration testing Agent platform access.
MiniMax M2 enters LM Arena battle testing with 200K context; Top‑5 performance claims surface
LM Arena added a MiniMax‑M2 Preview for community head‑to‑head prompts, highlighting agentic use and a 200K‑token context, with battle mode now open for trials Arena preview WebDev arena.
- MiniMax’s own comms tout a global Top‑5 standing “surpassing Claude Opus 4.1,” positioning it just behind Sonnet 4.5; as always, cross‑harness variance applies and independent evals matter for your workload Ranking claim.
- Beyond Arena, partner platforms are lighting up access paths (e.g., Yupp early listing) to widen developer coverage Yupp listing.
Google’s Genie 3 ‘world model’ shows up in public experiments UI
New chatter indicates Google is experimenting with Genie 3—an AI “world model” that lets users generate and interact with custom environments—visible in product surfaces under test World model note, following up on public experiment UI from yesterday’s sightings. For builders, that hints at upcoming APIs for simulation‑style agents and interactive content generation.
Cursor teases its first in‑house model “Cheetah” for next week
Cursor is hinting that its first proprietary model, Cheetah, will arrive next week, signaling a vertical move by coding‑agent platforms into bespoke inference stacks Model tease. This follows the broader pattern of agent vendors owning more of the model layer to tune latency, tool‑use reliability, and IDE integration.
🏢 Production AI platforms: Mistral AI Studio lands
Mistral positions a production platform for agents with observability, provenance, and governance; community notes some tabs marked “Coming soon.” Excludes OpenAI ads (feature).
Mistral AI Studio launches as a production platform for agents with versioning and governance
Mistral unveiled AI Studio, a full‑stack production platform that moves teams from experimentation to deployed agents with provenance, versioning, audit trails, and security controls spanning Playground → Agents → Observe → Evaluate → Fine‑tune → Code Launch details, and the company blog outlines built‑in evaluation hooks, traceable feedback loops, and flexible deployment targets Mistral blog post.
- Initial users note several tabs (Observe, Evaluate) are labeled “Coming soon,” while core runtime and agent flows are live today—suggesting a staged rollout focused on getting the agent runtime into production first Coming soon note.
⚡ US fast‑tracks data‑center interconnects
Policy/infra angle with direct AI impact: the U.S. moves to compress grid interconnect reviews for data centers—material to AI build‑out lead times. Single non‑AI category today as allowed.
US plan would cap data‑center grid interconnect reviews at 60 days
A draft federal rule would limit utility interconnection reviews for data centers to 60 days—down from multi‑year timelines—speeding hookups for AI‑driven buildouts Bloomberg report, with specifics in the first report of the proposal Bloomberg article. In context of TPU megadeal where hyperscalers are locking gigawatt‑scale capacity, compressing grid lead times directly pulls forward AI compute availability.
- The change targets the biggest schedule bottleneck in AI capacity deployment (grid interconnect studies), potentially shaving quarters off go‑live dates in hot markets.
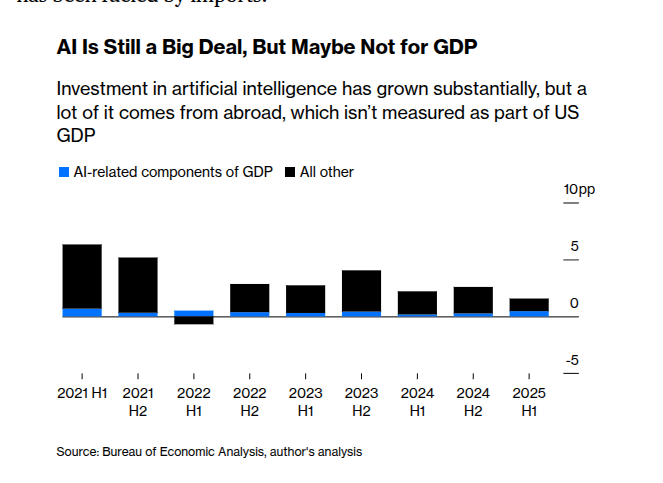
AI lifted H1 GDP by ~1.3pp, but net impact was ~0.5pp after imports
New macro reads show AI‑linked spend added about 1.3 percentage points to U.S. real GDP growth in the first half of 2025, but net domestic contribution falls to roughly 0.5 pp once imported chips/servers are subtracted GDP chart. This squares with coverage that AI investment is propping up growth despite headwinds Yahoo Finance piece, and explains why headline GDP can understate the sector’s momentum when hardware is sourced abroad.
🧠 Reasoning & RL methods to watch
A dense stream of new methods and analyses relevant to scaling reasoning and training stability, with concrete takeaways for agent builders and research teams.
BAPO stabilizes off‑policy RL; 32B hits 87.1 (AIME24) and 80.0 (AIME25) with adaptive clipping
Fudan’s Balanced Policy Optimization (BAPO) dynamically tunes PPO’s clipping bounds to balance positive/negative advantages, preserving exploration while curbing instability; a 32B model reports 87.1 on AIME24 and 80.0 on AIME25, rivaling o3‑mini and Gemini‑2.5, with gains also shown at 7B and 3B scales result numbers, method overview. The authors released an implementation for reproducibility ArXiv paper and GitHub repo.
• Takeaway: adaptive, asymmetric clipping is a practical drop‑in for RLHF/RLAIF pipelines that struggle with off‑policy drift; useful knobs include target positive‑token ratio and separate c_high/c_low schedules training notes, entropy control.
DiscoRL: meta‑learned update rule beats hand‑crafted algorithms on Atari‑57 and transfers to new tasks
A Nature study reports a meta‑learner discovering an RL update rule that outperforms standard algorithms on Atari‑57 and generalizes to unseen environments without per‑task tuning, pointing to self‑improving training loops where the optimizer itself is learned paper highlight. For research teams, this strengthens the case for learned optimizers in long‑horizon agent training when hand‑tuned losses stall.
Causal step‑wise judge: relevance+coherence per step predicts final correctness better than whole‑trace rubrics
A new evaluation framework scores each reasoning step by (i) relevance to the question and (ii) coherence with prior steps, withholding future context to avoid hindsight bias; traces that stay relevant and coherent are ~2× likelier to end correct, and filtering by these scores improves downstream accuracy paper thread. For teams training reasoning models, this offers a lightweight data filter and a debugging lens that surfaces where chains go off‑topic or break entailment.
LVLMs hallucinate more in longer answers; HalTrapper induces, detects, and suppresses risky tokens without retraining
A large‑vision study shows hallucinations rise with response length as models chase coherence; HalTrapper counters by (1) prompting add‑ons to induce risky mentions, (2) flagging tokens with suspiciously similar image attention, then (3) contrastively down‑weighting them at decode time—no fine‑tuning required paper thread. This pairs well with prior decode‑time safeguards that cut caption object hallucinations ~70% without retraining caption hallucinations.
AgenticMath: cleaner synthetic math beats sheer volume for reasoning gains at 5–15% of the data
New results suggest curated, higher‑quality synthetic math traces can train stronger reasoners with a fraction of the tokens typically used, edging out “more data” baselines at equal or lower cost paper thread. For RLHF/RLAIF budgets under pressure, investing in generation quality and filtering may yield better returns than scaling corpus size alone.
RLEV: optimize to explicit human values so models weight answers by importance, not just accuracy
“Every Question Has Its Own Value” introduces RLEV, aligning optimization targets to human value signals so agents learn value‑weighted accuracy and value‑aware stopping policies rather than uniform loss over questions paper abstract. This is promising for agents in high‑stakes domains where the cost of a miss dwarfs average‑case metrics.
Text‑grid probe shows brittle spatial reasoning: average accuracy falls ~42.7% as board sizes scale
Across quadrant, mirror, nearest/farthest, word search, and sliding‑marker tasks, models handle small boards but degrade sharply as grids enlarge due to misreads and weak state tracking; Claude 3.7 variants lead GPT‑4.1/4o here but all plunge on larger layouts paper overview. Practical implication: treat table/layout‑heavy tasks as vision or structured‑state problems, not pure text.
Zhyper conditions LLMs on tasks/cultures with factorized hypernets, matching Text‑to‑LoRA with ~26× fewer trainable params
Zhyper freezes the base model and learns small, reusable adapter parts per layer; a tiny hypernetwork emits short scaling vectors from task descriptions to modulate those parts, enabling quick behavior swaps with low memory/latency and better transfer than per‑task adapters paper summary. Diagonal vs square variants trade parameter count for flexibility, offering a compact path for instruction/culture conditioning.
Visual evidence for hallucination‑control without retraining
The HalTrapper workflow is positioned as a decode‑time control: induce candidates, detect risky focus, then suppress via contrastive decoding, stabilizing longer descriptions while keeping recall fluency intact paper thread. Teams can trial this in serving stacks as a low‑risk mitigation before committing to fine‑tunes.
🎬 Video gen momentum: Veo 3.1, Seedance Fast, Arena face‑offs
Creative/video AI kept buzzing—new Veo 3.1 controls, cheaper/faster Seedance variant, community prompt battles, plus signals on OpenAI’s music push. Dedicated media coverage retained due to high tweet volume today.
Gemini Veo 3.1 lands with truer textures and easier camera control
Google’s latest Veo update focuses on production controls: true‑to‑life textures, simpler camera steering, and dialogue with sound effects, now available to try in Gemini. Rollout notes also highlight broader “Gemini Drops” improvements landing over the next weeks. See the overview and entry point in the product thread feature thread and launch page Gemini Veo page. Early user demos report noticeably sharper adherence to direction with Veo 3.1 compared to spring builds demo claim.
Seedance 1 Pro Fast cuts costs ~60% and renders 5s at 480p in ~15s
ByteDance’s new Seedance‑1 Pro Fast variant targets iteration speed and budget. Replicate lists ~60% lower price than Pro, ~15 seconds for a 5‑second 480p clip, and ~30 seconds for 720p—aimed at preview loops before final quality passes model listing, with model details and pricing on the card Replicate model page. Community showcases are already comparing output trade‑offs versus Pro/Lite in quick prompt sweeps examples roundup.
fal’s Generative Media Conference: 200+ models live; median company uses 14
Ecosystem signal: at fal’s inaugural Generative Media Conference, organizers shared platform telemetry—200+ models available, with the median customer wiring up 14 models per workflow; image utilization is surging and video usage remains strong usage stats. Live sessions from BytePlus, Decart, and others showcased real‑time video and avatar stacks, underscoring rapid multi‑model adoption for production pipelines live demo.
OpenAI developing music model; working with Juilliard students on annotations
The Information reports OpenAI is building AI that generates music, sourcing high‑quality annotations from Juilliard students and exploring text/audio prompt tools (e.g., “add guitar to this vocal”). Any launch likely hinges on label licensing amid active lawsuits against competitors news summary, with deeper context in the piece The Information article.
Arena pits Veo 3.x, Sora‑2, Kling and Hailuo in community prompt face‑offs
LMArena’s open “video arena” is stress‑testing frontier video models on identical creative prompts, with votes determining leaderboards. Match‑ups this round include Hailuo‑02‑Pro vs Veo‑3‑Audio on blueprint→product morphs blender battle, plus Veo‑3.x vs Sora‑2 on a dolphin return scene and an orca bursting from a book concept showdown thread, orca face‑off. Results help teams gauge style fidelity, motion coherence, and audio sync across vendors in real prompts, not cherry‑picked reels.
LTX‑2 adds a 50% compute cost cut claim; open weights planned for late November
New details on Lightricks’ LTX‑2: beyond native 4K/50 fps and synced audio, the team now touts ~50% compute cost reductions and 10‑second clips, with open weights targeted for late November via API and ComfyUI integrations model summary. This follows native 4k, which established the baseline 4K/50 fps and audio‑sync capabilities across Fast/Pro tiers.
🔎 Agentic retrieval & search stacks
Signals that agent workflows depend on better retrieval: new engines and patterns for code/document discovery and schema‑first APIs.
Hornet positions as schema‑first agentic retrieval engine for production apps
Hornet is being framed as a retrieval engine built for agents rather than humans, with schema‑first APIs, parallel and iterative loop support, and on‑prem/VPC deployment options—aimed at replacing brittle ad‑hoc search layers in agent stacks product update, and with details on model‑agnostic use and predictable APIs on the site Hornet product page. The emphasis: agents need reproducible, token‑efficient retrieval primitives that expose clear knobs for breadth, freshness, and iteration—not just a generic search box.
Amp’s Librarian subagent navigates docs and code (including private repos) for agent workflows
Amp’s Librarian pattern has agents fetch a Markdown map of documentation and then traverse it to answer questions (and do the same across code), which avoids hallucinated answers about tool features and keeps behavior up‑to‑date pattern write-up. A public example traces Playwright internals end‑to‑end for clickable point logic use case thread, and the feature page confirms the private‑repo path via GitHub integration to bring this retrieval into enterprise codebases feature brief.
“Every org must invest in relevant search” becomes a design rule for agents
A distilled takeaway for AI leads and platform teams: long contexts don’t remove the need for targeted retrieval—agents still require high‑recall, latency‑predictable search with query rewriting and multi‑hop orchestration to work reliably at production scale slide summary.
- Why it matters: agent loops are token‑ and time‑bounded; without strong retrieval, plans drift and tool use degrades, especially under multi‑turn constraints.
- Recommended posture: treat search as a first‑class system with evaluation hooks and business‑specific benchmarks rather than a best‑effort embedding lookup.
Weaviate schedules “Query Agent” workshop to push agent‑ready retrieval patterns
Weaviate announced a Nov 6 online session on accelerating agents into production with its Query Agent, targeting teams that need retrieval tuned for multi‑step planning and I/O‑bound loops workshop invite. Expect hands‑on guidance for query planning, tool orchestration, and evaluation patterns for agentic RAG.
🎮 Enterprise media adoption: EA × Stability; Netflix “all‑in”
Two concrete adoption signals in media/content: a games giant partnering for gen‑AI tools and Netflix expanding generative AI across workflows.
Netflix says it is “all in” on AI across recommendations, production, and marketing
Netflix declared generative AI a “significant opportunity” and said it will apply it end‑to‑end—from content personalization to accelerating creative workflows—citing recent productions already using gen‑AI (e.g., de‑aging in Happy Gilmore 2; pre‑production wardrobe/set design for Billionaires’ Bunker) CNBC report.
- The company framed AI as augmenting creators (efficiency and iteration speed) rather than replacing them, while noting internal AI guidelines amid post‑strike talent protections CNBC report.
- For AI teams in media, this green‑lights vendor evaluations around video, audio/SFX, and marketing asset generation, and raises bar on auditability (who/what models touched a frame) and licensing hygiene.
EA partners with Stability AI to co‑develop generative models, tools, and workflows for game development
Electronic Arts is teaming with Stability AI to build production‑grade gen‑AI models and pipelines for artists, designers, and engineers in game studios, signaling institutional adoption of AI inside AAA workflows partnership announcement.
For AI leaders, this elevates model/tooling maturity from experiments to co‑owned platforms embedded in asset creation, pre‑viz, and iteration loops—implying governance, dataset provenance, and latency/quality trade‑offs will be decided jointly by vendor and studio rather than ad‑hoc teams.
Mondelez (Oreos maker) invests $40M to train an in‑house video model for TV advertising
Consumer giant Mondelez has reportedly trained its own video model for TV ads after a $40M investment, underscoring that large brands will in‑source creative AI where IP control and cadence matter brand model claim.
In practice, this shifts agency/vendor dynamics: brand‑owned models can be tuned on proprietary brand books, talent contracts, and historical spots, but they also inherit responsibilities for rights management, safety filters, and a creative QA loop aligned to media‑buy SLAs.
🔌 Interoperability: MCP servers and agent UIs
Interop matured with concrete MCP routes and agent UI scaffolding—useful for teams standardizing tooling across editors and stacks.
Codex CLI 0.48 ships Rust MCP client, tool gating, and cleaner server auth
OpenAI’s Codex CLI 0.48 adds a stdio MCP client built on the official Rust SDK, support for per‑server enabled_tools/disabled_tools, and scoped logins for streamable HTTP servers via codex mcp login, along with better startup errors and tighter instruction‑following while using tools release notes, and the full details are in the 0.48.0 notes GitHub release. These features make MCP servers easier to integrate and govern across orgs’ agent stacks.
E2B sandboxes now bundle 200+ MCPs so agents can call tools without extra setup
E2B enabled direct access to 200+ Model Context Protocol servers from inside its sandbox runtime, letting long‑running research or coding agents invoke standardized tools out of the box runtime update. This removes per‑project glue code and improves reproducibility when the same MCPs are used across editors or CI.
AGENTS.md pattern lands: Claude can read @‑AGENTS.md via CLAUDE.md and Amp adds support
Anthropic’s guidance recommends referencing @‑AGENTS.md from CLAUDE.md so Claude loads the agent‑facing spec without duplicating README content Anthropic guidance; a network capture confirms the extra file is injected into the system prompt region packet capture. Amp now reads CLAUDE.md as well to align with this convention Amp support, and maintainers suggest simple symlink scripts when projects need both files in one repo symlink tip. This emerging doc pattern improves cross‑agent instruction portability without per‑tool forks.
CopilotKit adds subgraph streaming UI for LangGraph agents with live step traces
CopilotKit can now stream every step—including nested subgraphs—while showing agent reasoning, tool calls, and state updates in real time; it also supports human‑in‑the‑loop control and multi‑agent collaboration feature brief, with runnable mini‑demos in the LangGraph AG‑UI Dojo AG‑UI Dojo. This gives teams a reusable interface layer that travels with their LangGraph agents across apps.
Fal exposes a plug‑and‑play MCP server for agent tools across editors
Fal published an MCP server endpoint that drops straight into mcp.json, letting Cursor, Claude Code, Gemini CLI, Cline, and other MCP‑aware tools call Fal services without bespoke adapters MCP snippet.
This tightens cross‑editor interoperability for teams standardizing on MCP to wire the same tools across multiple agent UIs.
Zed’s Agent Panel tutorial details MCP wiring, profiles, follow mode, and reviews
A full walkthrough for Zed’s Agent Panel covers setup, write vs ask profiles, follow mode, wiring MCP servers, and code‑review workflows, plus integrating external agents via ACP tutorial overview, with the end‑to‑end demo available here YouTube tutorial. It’s a practical template for orgs unifying agent UI patterns across editors.
📈 Benchmarks & eval ops
Fresh eval snapshots and process notes focused on agents and coding—useful for teams moving from vibes to instrumentation.
BAPO’s adaptive clipping posts SOTA open results on AIME benchmarks
Fudan’s Balanced Policy Optimization tunes PPO clipping bounds on‑line to balance positive/negative updates, reporting 87.1 (AIME24) and 80.0 (AIME25) with a 32B model—competitive with o3‑mini and Gemini‑2.5—and consistent gains at 7B/3B scales results thread, with methods and code available for inspection ArXiv paper and GitHub repo.
Good candidate for inclusion in reasoning‑RL eval suites alongside GRPO/SFT baselines.
LVLMs hallucinate in long answers; HalTrapper curbs it without retraining
Researchers show vision‑language models drift as responses lengthen (coherence pressure > grounding), then introduce HalTrapper: internal prompts that elicit risk, attention‑based detection of unjustified objects, and contrastive decoding to down‑weight flagged continuations—reducing hallucinations while preserving fluency paper summary.
Actionable for eval ops: add length‑stratified tests and adversarial “there is also …” probes to spot brittle decoders.
Step‑wise causal judging beats whole‑trace scoring for reasoning evals
A new study proposes evaluating each reasoning step for relevance (addresses the task) and coherence (follows prior steps) using only past context, avoiding hindsight bias; step‑quality scores correlate better with final correctness than trace‑level judges and enable cleaner data filtering and prompt nudges paper summary.
For ops, this suggests adding per‑step checks to triage traces, select higher‑signal SFT data, and guardrail long chains.
From vibes to evals: a practical playbook for shipping AI that works
Braintrust argues that systematic evals—not ad‑hoc prompt swaps—separate reliable AI features from demos, detailing how teams move to repeatable harnesses and recounting a 20‑minute production bug fix enabled by eval instrumentation evals explainer, with the full write‑up available here article page. The piece is a useful template for setting pass/fail gates and wiring evals into CI.
LLM‑as‑judge bias flagged on mental‑health benchmarks
A 100k‑case benchmark finds LLM evaluators systematically inflate scores for empathy/helpfulness and show weak consistency on safety/relevance versus clinician ratings, recommending LLM pre‑screen plus human adjudication for high‑stakes domains paper summary.
For eval ops, avoid using a single model‑judge as the sole arbiter; ensemble or rubric‑driven scoring with human sampling is safer.
Meta‑learned RL update (DiscoRL) outperforms hand‑designed rules
A Nature report shows a meta‑learner discovering an RL update rule that achieves state‑of‑the‑art on Atari‑57 and generalizes to new tasks without per‑env tuning, beating classic TD/Q‑learning/PPO variants paper summary.
For eval ops, this raises the bar for RL‑from‑reasoning pipelines: compare against learned optimizers, not just PPO baselines.
Qwen3‑Max jumps to #1 ROI on AlphaArena live trading
The AlphaArena crypto trading benchmark now shows Qwen3‑Max passing DeepSeek V3.1 for the top spot on recent return metrics, highlighting fast‑moving model deltas under real‑money conditions leaderboard update. For a snapshot of broader model performance trends circulating alongside this shift, see the comparative returns chart shared today roi context.
Teams should treat AlphaArena as a stress test for agentic robustness (latency, tool calls, risk rules) rather than a static accuracy score.
Spatial reasoning on text grids collapses at scale, study finds
Across quadrant finding, mirroring, nearest/farthest, word search, and sliding‑tile tasks, LLM accuracy drops an average 42.7% as grid size grows; errors include misreads, arithmetic slips, and weak state tracking despite inputs fitting context windows paper summary.
Implication: treat table/layout heavy tasks as a separate eval axis and consider structured parsers or visual encoders rather than plain text.
MiniMax M2 opens for public evaluation across arenas
A preview of MiniMax‑M2 is live in LMArena’s WebDev “Battle Mode,” inviting side‑by‑side prompting on agentic web tasks arena preview with direct access to the arena scenarios WebDev arena. In parallel, an OpenRouter listing exposes a free endpoint (204.8k context, ~3.22s latency, ~89 tps) suitable for harness integration and load tests endpoint listing.
Test plans: reproduction of Next.js tasks, tool‑calling accuracy, and time‑to‑first‑pass diffs.
AI Tinkerers SF to debate “Big Eval” vs pragmatic testing
An in‑person session at Okta HQ (Oct 30, 5:30pm) will unpack how practitioners actually test AI tools—when to invest in full eval stacks vs lightweight checks—and share patterns emerging in Bay Area teams meetup details, with registration details posted by organizers event page.
Expect hands‑on heuristics (specs, task decomposition, acceptance tests) alongside discussion of eval cost/benefit trade‑offs.
🛡️ Trustworthiness of LLM judgments
Two evaluations caution against delegating sensitive judgments: hiring personality screens and mental‑health reply scoring. Excludes privacy/ads topics (feature).
LLMs fail hiring personality screens and rarely advise “Not recommended”
A multi-model evaluation found all 12 tested LLMs failed a standard corporate personality screen and, when acting as HR evaluators, almost never flagged candidates as “Not recommended” paper summary, study recap.
- Models answered 216 Likert-scale items but biased toward agreeable responses, creating unrealistically positive profiles and weak role fit paper summary.
- As screeners, most models recommended nearly everyone, showing poor discrimination across applicants study recap.
- Authors caution against delegating gatekeeping to LLMs; use them only for pre-screen support with strict human oversight paper summary.
LLM judges inflate empathy/helpfulness on mental‑health replies; use as pre‑screen only
Researchers released MentalBench‑100k and MentalAlign‑70k and showed LLM judges systematically over‑score empathy and helpfulness relative to clinicians, despite decent rank agreement on reasoning-oriented criteria paper summary.
- Safety and relevance judgments were inconsistent, making models unreliable for high‑stakes triage without human review paper summary.
- The work recommends LLMs for sorting/pre‑screening with clinicians making final decisions, especially on emotion and safety dimensions paper summary.