Anthropic Claude Skills roll out across 3 surfaces – Microsoft 365 search goes org‑wide
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic just flipped on Claude Skills, and it’s a real shift from “prompt soup” to modular agents. Skills are packaged instruction folders that Claude auto‑loads only when relevant, and they land simultaneously across claude.ai, Claude Code, and the API—three surfaces that matter if you want the same playbook in chat, IDEs, and production. The other shoe: a Microsoft 365 connector and org‑wide Enterprise Search, so Claude can ground answers in SharePoint, OneDrive, Outlook, and Teams without duct tape.
The design is pragmatic. Progressive disclosure keeps latency steady by reading just the Skill name/description first, then pulling SKILL.md and assets on demand, so you can ship a single ZIP with deep procedures, scripts, and templates without bloating the system prompt. Claude Code now has a Skills marketplace you can install with one command, plus per‑skill toggles and code execution controls; authoring still feels “build ZIP → upload → enable,” but the primitives are sound and the engineering playbook for SKILL.md is thorough. For leaders, the 365 connector rides Anthropic’s Model Context Protocol (MCP), which means auditable tool wiring and cleaner governance as Skills become org‑curated catalogs.
If you’re betting on agentic dev, the ecosystem’s moving in parallel: Cognition’s SWE‑grep hits 4‑turn codebase searches in under ~3 seconds at 2,800+ TPS, pointing to faster plan→fetch→edit loops once Skills are in the mix.
Feature Spotlight
Feature: Claude Skills + Microsoft 365 search land for agents
Anthropic’s Skills and Microsoft 365 Enterprise Search move agents from prompts to reusable workflows and org context—standardizing “how we work” and letting Claude pull SharePoint/OneDrive/Outlook/Teams into answers.
Cross‑account launch: Anthropic ships Skills (packaged instruction folders auto‑loaded by Claude) across claude.ai, Claude Code, and API, plus new Microsoft 365 connector and Enterprise Search. Heavy dev docs, UX, and marketplace chatter in this sample.
Jump to Feature: Claude Skills + Microsoft 365 search land for agents topicsTable of Contents
🧩 Feature: Claude Skills + Microsoft 365 search land for agents
Cross‑account launch: Anthropic ships Skills (packaged instruction folders auto‑loaded by Claude) across claude.ai, Claude Code, and API, plus new Microsoft 365 connector and Enterprise Search. Heavy dev docs, UX, and marketplace chatter in this sample.
Anthropic ships Claude Skills across claude.ai, Code and API
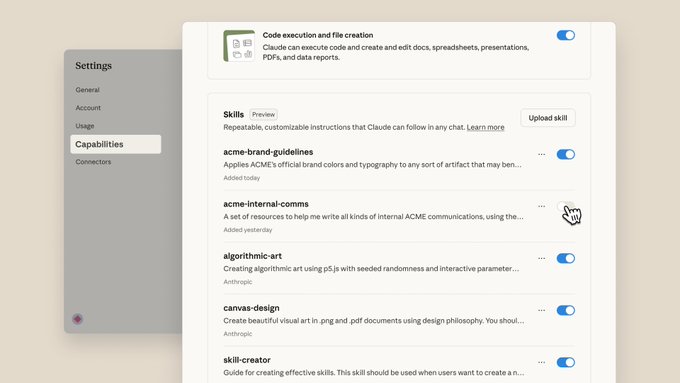
Anthropic introduced Skills—packaged instruction folders that Claude auto‑loads as needed and can stack for complex tasks—now available across claude.ai, Claude Code, and the API release note, with a visible UI for enabling/disabling individual skills and code execution settings screenshot. Developers can read the launch post and docs for SKILL.md format, metadata, and runtime behavior Anthropic blog, and implementation details plus API usage examples Claude docs.
Early tests highlight that Skills encapsulate domain know‑how and scripts into a single ZIP, letting general agents pick up specialized workflows on demand without prompt bloat or bespoke fine‑tunes.
Claude adds Microsoft 365 connector and org‑wide Enterprise Search
Anthropic rolled out a Microsoft 365 connector (via MCP) and a new Enterprise Search project for Team/Enterprise: Claude can now search SharePoint/OneDrive, summarize Outlook threads, and pull signal from Teams chats—then compose grounded answers across sources feature brief, with a follow‑up outlining setup and availability for paid org plans release recap. Product details and examples are on the launch page Anthropic page.
For leaders, this moves Claude from chat helper to knowledge front‑door, reducing swivel‑chair across apps and centralizing search governance.
Claude Code gets a Skills marketplace; one command adds capabilities like DOCX
Claude Code now supports a first‑party Skills marketplace. You can add it with /plugin marketplace add anthropics/skills, then install skills (e.g., a DOCX creator) to let Claude generate Word documents and more inside your repo workflow marketplace commands. The install flow and examples are documented, including quick /plugin discovery and per‑skill toggles install steps.
This shifts Code from a monolithic agent to a modular platform—teams can curate a standard pack of Skills that enforce format, style, and tools across projects.
Claude Code looks like a general agent now—Skills make it explicit
Developers argue Claude Code is effectively a general computer‑use agent once Skills are enabled, not just a coding tool—Skills auto‑scope workflows, enforce formats, and call scripts, elevating breadth of tasks it can autonomously execute developer note, with early write‑ups suggesting Skills may be a bigger deal than MCP for many use cases deep dive. This lands in context of Explore subagent, where Anthropic formalized Code’s plan/execute loop the day prior, and today’s Settings UI shows Skills alongside code execution settings screenshot.
Implication for teams: treat Code as the orchestrator, and Skills as the portable unit of process that travels across repos and projects.
Engineering playbook for Agent Skills: SKILL.md schema, examples and best practices
Anthropic published an engineering deep‑dive on Agent Skills—how to structure SKILL.md (YAML front‑matter + instructions), bundle scripts/resources, and apply “progressive disclosure” so agents only load what they need engineering blog. A companion post summarizes developer tips and links out to code samples blog plug.
For AI engineers, this is the reference for capturing tacit procedures (e.g., PDF filling, brand style, spreadsheet formulas) into reusable, composable agent capabilities.
Progressive disclosure: Skills load tiny first, expand only when relevant
Anthropic designed Skills to minimize context overhead: Claude first reads only name/description, then pulls in SKILL.md and referenced assets (code, images, templates) if and when they’re relevant—allowing effectively unlimited procedural context without bloating the system prompt dev explainer, with workflow described step‑by‑step in the docs thread docs thread.
For agents, this keeps latency predictable and avoids “context rot,” while still giving access to deep, file‑backed instructions when a task demands it.
Skill builder and per‑skill toggles land; some UX friction called out
Anthropic added a Skill Builder assistant and a UI to upload ZIPs and toggle Skills on/off, exposing code execution and file creation controls in Settings settings screenshot. Early users praise the power but want a smoother design flow than ‘build ZIP → upload → enable’, noting extra steps compared to inline edits ui feedback; the docs thread covers iterative authoring patterns to tighten the loop docs thread.
Net effect: the primitives are in place for org‑curated Skill catalogs, even if authoring ergonomics are still maturing.
⚡ Agentic coding gets fast: SWE‑grep, Codex in IDEs, Cline CLI
Focus on coding agents performance and ergonomics—new subagent search models, IDE integrations, and scriptable CLIs. Excludes Anthropic Skills launch (covered in Feature).
Cognition’s SWE‑grep models make agentic code search near‑instant
Cognition introduced SWE‑grep and SWE‑grep‑mini, purpose‑built subagents that run 4‑turn codebase searches in under ~3 seconds and exceed 2,800 TPS, enabling coding agents to fetch the “right files” without long‑context bloat. The rollout includes a Fast Context mode now shipping to Windsurf users and a public playground for side‑by‑side comparisons. See the announcement launch thread and the performance plot showing Pareto‑leading F1 at low latency latency chart.
By design, SWE‑grep leans on limited‑agency parallel tool calls (≈7–8 in flight) and clean contexts instead of massive windows, which Cognition argues yields predictable cost and end‑to‑end latency launch thread. A hosted playground lets teams trial Fast Context against popular agents before wiring it into their IDEs and CI launch thread.
Cline debuts a scriptable CLI: headless reviews and IDE‑spawned subagents
Cline released a preview CLI that turns its coding agent into a shell‑first primitive: run headless tasks (e.g., git diff … | cline -o … -F json), orchestrate multiple agents in parallel, and let IDE Cline spawn CLI subagents to preserve the main context window. The team frames it as a composable “agent loop” you can wire into CI, bots, or scripts, with docs and examples covering Plan/Act mode, approvals, and structured outputs cli preview, plus a getting‑started guide docs overview.
This closes a common ergonomics gap: developers can keep their editor agent focused while delegating file crawls, code reviews, or variant generation to fresh‑context subprocesses cli preview.
Zed adds native Codex via ACP; adapter open‑sourced for other editors
Zed shipped a first‑class Codex agent that speaks the Agent Client Protocol, so developers can plan/edit with OpenAI’s agent inside the editor and across ACP‑aware clients. Building on yesterday’s Codex CLI planner preview Plan mode, Zed also open‑sourced a codex‑acp adapter to bring the agent to JetBrains, Neovim, Emacs and more, while routing terminal commands in a separate process to avoid PTY deadlocks. Details in Zed’s write‑up release blog and the adapter repo github adapter.
For engineering leaders, ACP means one agent protocol across tools, with Zed positioning Codex as a drop‑in for existing ACP setups and a cleaner escape hatch for long‑running terminal steps release blog.
AI SDK v6 beta teases Anthropic MCP connector for tool calls
A preview snippet shows Vercel’s AI SDK 6 gaining Anthropic MCP connector support, configuring remote MCP servers (e.g., an echo tool) inside provider options so agents can call tools over MCP without bespoke wiring. The example uses Sonnet 4.5 with a URL‑based server entry, hinting at simpler, portable toolchains across stacks code snippet.
For agent platform teams, a first‑party MCP bridge in the SDK reduces per‑tool integration code and standardizes permissions/streams across Anthropic‑backed plans as MCP proliferates code snippet.
🧮 Inference runtimes: TPU unification, KV routing, caching & APIs
Serving/runtime engineering updates dominate: vLLM’s TPU backend revamp, production routing wins with NVIDIA Dynamo, Groq prompt caching + price cuts, and OpenRouter’s stateless Responses API Beta.
vLLM unifies TPU serving for PyTorch and JAX with 2–5× throughput gains
vLLM shipped a new TPU backend that runs PyTorch models on TPUs via a single JAX-to-XLA lowering path, adds native JAX support, and reports nearly 2–5× higher throughput than its first TPU prototype. It also defaults to SPMD, debuts Ragged Paged Attention v3, and supports Trillium (v6e) and v5e TPUs release brief, with full details in the engineering write‑up vLLM blog post.
Following up on Qwen3‑VL support that signaled a production serving path, this release reduces framework friction (PyTorch↔JAX) and broadens hardware coverage. The TorchAx interop docs help explain how PyTorch code can ride JAX/XLA without major rewrites torchax docs.
Baseten adopts NVIDIA Dynamo KV‑cache routing: ~50% lower latency, 60%+ higher throughput in prod
Baseten says production inference for large‑context LLMs got ~50% lower latency and 60%+ higher throughput after adopting NVIDIA Dynamo with KV cache‑aware routing (reuse of prefix states + smarter replica selection). The post also describes disaggregated prefill/decode and a radix‑tree KV map used by the LLM‑aware router blog teaser, with implementation details and benchmarks in the write‑up Baseten blog post.
Implication: serving stacks that understand cache locality and prompt overlap materially trim tail latency and cost for chat and RAG workloads without model changes.
Groq cuts GPT‑OSS prices and adds prompt caching with 50% discount on cached tokens
Groq rolled out prompt caching on GPT‑OSS (20B now, 120B next) that bills cached input prefixes at 50% price, exempts cached tokens from rate limits, and lowers latency—no code changes required. The announcement also includes across‑the‑board price reductions for the GPT‑OSS family pricing update, with more specifics in the provider blog Groq blog post.
For teams with stable system prompts or repeated headers (RAG, tools), this can deliver immediate serving savings while increasing effective TPS.
OpenRouter debuts stateless Responses API Beta with tools, reasoning controls and web search
OpenRouter introduced a stateless Responses API Beta: each call is independent, with built‑in function/tool calling (parallel), reasoning effort controls, and optional web search that returns citations. The beta also refines ID schemas across messages, reasoning and image generation beta announcement, with full reference and examples in the docs API docs and follow‑up notes on revamped fields feature notes.
Why it matters: statelessness simplifies horizontal scaling and multi‑region routing, while built‑in search/tooling reduces glue code for common agentic patterns.
📊 Evals: ARC‑AGI, Terminal‑Bench, arenas and legal AI studies
Mostly eval releases and live leaderboards across AGI puzzles, terminal tasks, chatbot arenas, and domain studies. Excludes gen‑media rankings (see Generative Media).
ARC Prize verifies Tiny Recursion Model: 40% on ARC‑AGI‑1 at ~$1.76/task
ARC Prize confirmed Tiny Recursion Model (TRM) results: 40.0% on ARC‑AGI‑1 for ~$1.76 per task and 6.2% on ARC‑AGI‑2 for ~$2.10, with reproducible checkpoints and instructions released. This places a 7M‑param bespoke approach within striking distance of much larger systems on cost‑constrained AGI puzzles results update, Hugging Face repo, ARC leaderboard.
For engineers, the key is the run‑cost and replicability knobs published alongside scores; for analysts, it’s evidence that narrow, compute‑efficient architectures can push the ARC front without massive model size repro notes.
Legal research study: AI tools average 77% vs. lawyers’ 69% across 200 questions
A Vals evaluation across 200 real legal research questions found AI products averaging 77% versus practicing lawyers at 69%, with Counsel Stack leading and ChatGPT competitive on accuracy in many categories study summary, full report.
For buyers, the nuance matters: legal AI led on sourcing/citations, but humans still outperformed on some complex question types—implying hybrid workflows and careful QA remain prudent.
Claude Haiku 4.5 posts 14.33% on ARC‑AGI‑1 and 1.25% on ARC‑AGI‑2; longer thinking boosts to 47.6%/4.0%
ARC semi‑private results for Anthropic’s small model show base Haiku 4.5 at 14.33% (AGI‑1) and 1.25% (AGI‑2), with extended “Thinking 32K” runs reaching 47.6% and 4.0% respectively. Base costs land at ~$0.03–$0.04 per task; 32K‑thinking runs at ~$0.26–$0.38 eval thread, cost breakdown, ARC leaderboard.
This quantifies the value‑for‑latency tradeoff many teams are probing: deeper budgeted reasoning improves pass rates markedly, but with predictable cost/latency growth useful for eval planning.
New AGI definition benchmark pegs GPT‑5 at 58% and GPT‑4 at 27% toward ‘well‑educated adult’ target
A multi‑author paper proposes an AGI definition grounded in ten CHC cognitive domains and reports composite “AGI scores”: GPT‑5 at 58% and GPT‑4 at 27%, citing persistent deficits in long‑term memory (near 0%) and modality gaps paper link, radar chart, AGI paper.
Engineers should treat this as a directional, domain‑balanced yardstick rather than a product KPI, but it’s a useful lens to prioritize investments in durable memory, retrieval fidelity, and speed.
Terminal‑Bench record: ‘Ante’ with Claude Sonnet 4.5 hits 60.3% ±1.1 accuracy
A new high watermark on Terminal‑Bench shows agent ‘Ante’ using Claude Sonnet 4.5 at 60.3% ±1.1 accuracy, with submissions required to target terminal‑bench‑core 0.1.1 leaderboard screenshot.
For agent teams, this suggests maturity in command‑line task execution under standardized harnesses, and offers a concrete target for shell‑based reliability work.
Agents Arena: Factory AI (+ Codex 5) tops Elo at 1376 ahead of Devin, Cursor, Claude Code, Gemini CLI
The latest Agents Arena snapshot shows Factory AI (+ Codex 5) leading with an Elo of 1376, ahead of Codex 5 (1362), Devin (1173), Cursor Agent (GPT‑5) (1143), Claude Code (1131), and Gemini CLI (800) arena chart.
While Elo isn’t a substitute for app‑level SLAs, it’s a useful relative signal on complex, multi‑step tasks—especially for leaders deciding which stacks to pilot.
Claude Haiku 4.5 lands #22 on LMArena Text; strong in Coding and longer queries
LMArena’s Text leaderboard now shows Claude Haiku 4.5 at #22 overall, with category strengths in Coding and Longer Query (tied 4th) and Creative Writing (tied 5th) leaderboard update, in context of arena entry where the model was first added.
This positions Haiku as a high‑value option for text workloads where latency and cost sensitivity dominate, while leaving top‑tier spots to larger, slower systems category highlights, LMArena leaderboard.
Vals Index: Claude Haiku 4.5 (Thinking) places 3rd overall; excels at coding, lags on medical and GPQA
Vals reports Claude Haiku 4.5 (Thinking) ranks 3rd on its composite index, with strong coding performance (including Terminal‑Bench) but middling results on CaseLaw, MedQA, GPQA, MMLU‑Pro, MMMU, and LiveCodeBench index result, weak areas.
For evaluation planners, this separation underscores that small, fast models can anchor dev tooling while bigger models or tools may still be required for expert‑level QA domains.
🏗️ AI infra capex and economics
Capital formation and infra economics tied to AI demand: revenues, DC M&A, GPU leases, and power‑backed buildouts with concrete MW/GW targets. Excludes runtime/kernel updates (see Inference).
Nvidia–Microsoft–xAI group to buy Aligned Data Centers for ~$40B
A consortium including Nvidia, Microsoft, xAI, MGX and BlackRock’s GIP agreed to acquire Aligned Data Centers for about $40B, the largest data‑center deal to date, signaling a land‑and‑power race to secure AI‑ready capacity deal summary.
Scale implications: pre‑assembled campuses, power interconnects, and faster time‑to‑rack for GPU clusters reduce execution risk vs greenfield, while shifting returns toward infra owners that can package power, cooling and long‑term contracts.
OpenAI reportedly budgets ~$450B for servers through 2030
OpenAI has reportedly earmarked roughly $450B in server infrastructure spend through 2030, a figure that—if realized—would anchor multi‑GW of new power and thousands of GPU racks across partners and owned sites budget report.
Such a runway would force novel financing (supplier credits, JV campuses, long‑dated power PPAs) and intensify competition for grid interconnects, land, and skilled construction labor—further bifurcating AI haves and have‑nots.
Nvidia and Firmus to build $2.9B Australia AI data centers, scaling to ~1.6 GW by 2028
Nvidia is partnering with Firmus on Project Southgate: a $2.9B, renewables‑backed AI data‑center build in Melbourne and Tasmania targeting 150 MW online by Apr ’26, scaling to ~1.6 GW by 2028 with up to ~$73.3B of total capex project details.
The plan ties GB300‑class accelerator deployments directly to new wind/solar + storage, adding ~5.1 GW of generation. It’s a template for localizing AI compute while aligning with grid‑additive power builds and permitting realities.
OpenAI ARR surges to ~$13B; Anthropic hits ~$5B
Epoch estimates OpenAI’s annualized revenue climbed from ~$2B (Dec ’23) to ~$13B by Aug ’25, while Anthropic reached ~$5B by late July, underscoring the revenue flywheel behind AI infra builds revenue snapshot. The update lands as a fresh datapoint following compute roadmap that charted a ~26 GW capacity plan; sustained ARR strengthens financing for that build-out data insight.
Expect more aggressive capex and financing structures (debt + partner capex) as leaders convert usage into long‑dated compute and power contracts.
Oracle’s AI cloud margins under the microscope: −220% on B200 leases vs 35% project case
Two snapshots paint a wide spread in Oracle’s AI cloud unit economics. A breakdown of leasing Nvidia B200s shows an implied −220% gross margin in certain lease structures cost table. In contrast, Oracle touts a scenario of ~35% gross margin on a hypothetical $60B AI project and projects $166B infra revenue by 2030 if executed at scale margin scenario.
Taken together, near‑term lease arbitrage can be brutal, while vertically planned, power‑secured projects with owned assets and longer contracts can normalize margins—highlighting how deal structure and depreciation drive AI infra P&L.
xAI lines up ~$20B lease-to-own GPUs and a 1‑GW power plant
The Information reports xAI is finalizing a ~$20B lease‑to‑own deal for Nvidia GPUs and partnering with Solaris Energy to build a dedicated 1‑GW power plant, bundling compute with firm power to de‑risk capacity deal overview.
This pairing mirrors a broader shift: hyperscale‑style power procurement (or ownership) coupled with financing that amortizes GPUs over multi‑year model iterations, trading higher upfront complexity for predictable training/inference throughput.
🧰 Agent orchestration and SDK surfaces
Interoperability and workflow tooling: MCP connectors in SDKs, open agent builders, and UI kits. Excludes Anthropic Skills and M365 connector (covered as Feature).
Vercel AI SDK v6 beta shows Anthropic MCP connector support
A preview snippet for AI SDK 6 adds first‑class MCP connector config (with an echo server URL), enabling SDK‑level tool calls via Anthropic’s Model Context Protocol MCP connector code. This lands alongside prior SDK state features, strengthening a unified agent loop across providers Anthropic memory.
Mastra workflows add built‑in state to pass data across steps
Mastra introduced native workflow state (StateSchema + setState) so multi‑step agents can share intermediate values without custom plumbing, improving reliability and readability of orchestration graphs feature screenshots.
Open Agent Builder ships: n8n‑style, open‑source workflow app for agents
Firecrawl released a 100% open‑source, n8n‑style workflow builder that wires agents together with Firecrawl, LangChain, Convex, and Clerk—useful for orchestrating multi‑tool automations and data‑to‑action pipelines example app, app mention.
ElevenLabs open‑sources React UI kit for agents and audio, hits 1,000★
ElevenLabs’ UI component library for agent and audio apps reached 1,000 GitHub stars; the kit is open source (built on shadcn/ui), customizable, and comes with a live demo for rapid agent UX assembly release note, component site, GitHub repo.
RepoPrompt 1.5 adds automated Context Builder for repo‑aware prompts
RepoPrompt’s new Context Builder auto‑constructs the best context for a given token budget—assembling relevant files and summaries so coding agents can operate with higher signal and predictable costs feature summary. The release ships with a temporary lifetime/yearly discount to drive trials discount note.
🧠 Training recipes and reasoning science
New papers emphasize scalable RL, collaborative agents, symbolic regression, formal proof agents, and reasoning geometry; several with concrete compute or accuracy deltas.
Meta’s ScaleRL maps a predictable sigmoid for RL on LLMs and ships a stable recipe
Meta reports that RL progress for LLMs follows a saturating sigmoid that can be forecast from small pilot runs, then confirms the fit up to 100k GPU‑hours. The recommended ScaleRL stack (CISPO loss, FP32 logits at the final layer, prompt averaging, batch norm, no‑positive‑resampling, and interrupting long thoughts) stabilizes training and lifts pass rates (e.g., CISPO+FP32 logits ≈52%→≈61%) while guiding where to spend compute (raise the ceiling first, then tune efficiency) key recipe, and the paper release details the A, B, Cmid parameters that define the curve ArXiv paper. A separate plot contrasts ScaleRL against other RL variants, showing higher and later‑flattening returns with more compute comparison chart.
On‑policy AT‑GRPO trains collaborating LLMs to 96–99.5% planning accuracy
Intel and UC San Diego propose AT‑GRPO, an on‑policy RL method for multi‑agent LLM teams. By sampling candidates per role and per turn (true like‑for‑like comparisons) and blending team‑level with role‑level rewards, planning accuracy jumps from ~14–47% baselines to ~96.0–99.5% across tasks spanning planning, games, coding, and math paper page.
Ax‑Prover uses MCP tools to produce Lean‑checked proofs across math and quantum domains
Ax‑Prover is a multi‑agent framework that wires an LLM into Lean via MCP tools (open files, inspect goals, search lemmas) and a verifier loop that accepts only compilable, sorry‑free proofs. On a new QuantumTheorems set it solves ~96% in single‑run attempts, while generalizing across algebra and quantum benchmarks without per‑domain re‑training paper page.
LLM traders avoid bubbles humans create; lab markets show prices stick to fundamentals
Two experimental‑finance studies suggest LLMs act closer to textbook rationality than humans. In a classic bubbles setup, Claude 3.5 Sonnet and GPT‑4o price near fundamental value (~14) and mixing models stabilizes prices; humans show large run‑ups and crashes market lab study. A Federal Reserve Richmond paper finds AI agents reduce herding cascades from ~20% to 0–9% and make rational choices 61–97% vs. 46–51% for humans, implying more stable price discovery at scale fed study.
SR‑Scientist: an agentic symbolic regression loop that discovers equations and beats baselines by 6–35 points
SR‑Scientist makes an LLM act as a scientist: analyze data, propose a closed‑form, fit constants, evaluate, cache best attempts, and iterate with RL on error‑reduction rewards. Across chemistry, biology, physics, and materials tasks it delivers 6–35 percentage‑point gains over strong baselines, commonly targeting <0.1% MAPE per run paper page.
Hallucination is inevitable under open‑world inputs; distinguish false memory vs false generalization
A theory paper reframes hallucinations as generalization errors under the open‑world assumption: Type‑1 (false memory) can be fixed with updates, but Type‑2 (false generalization) arises from extending patterns to novel inputs and cannot be fully eliminated by refrain‑policies or detectors. The authors argue for tolerating some errors while keeping systems adaptive and reasoning legible paper page.
Microsoft’s TiMi separates planning from execution to cut trading agents’ latency ~180×
TiMi (Trade in Minutes) decouples LLM “thinking” from minute‑level trading by compiling a strategy offline (analysis, pair tuning, bot coding, math) and then executing CPU‑side with mechanical rules, yielding ~180× faster action latency vs continuous inference agents. Failures feed back as math constraints for the next plan paper summary, with full details in the preprint ArXiv paper. This extends the theme opened by Trading‑R1 (analyst‑thesis→trades) with a latency‑first agentic design.
Reasoning as geometry: logic emerges in velocity and curvature of hidden‑state trajectories
A Duke‑led study models LLM reasoning as smooth paths in representation space. Absolute positions encode topic/language, but the step‑to‑step changes—velocity and curvature—carry logic. Using parallel deductions across topics and languages on Qwen3 and LLaMA, flows with the same logic share similar local dynamics despite different words, yielding a concrete representation of “logic as motion” paper details.
RTFM world model renders interactive, persistent scenes in real time on a single H100
RTFM generates next video frames as you move through a scene, maintaining persistence (doors stay open) without explicit 3D reconstruction. Built as an autoregressive diffusion transformer trained end‑to‑end on large video corpora, it achieves playable framerates on one H100 and reconstructs real places from a few photos—positioning world models as learned renderers rather than geometry pipelines model summary.
Tensor Logic proposes a single tensor‑equation language to unify neural and symbolic reasoning
Pedro Domingos argues that logical rules and Einstein summation are the same operation, proposing “tensor logic” as a single construct that encodes code, data, learning and reasoning. A full Transformer is expressible in ~12 equations; setting temperature→0 yields crisp logic (lower hallucinations), while higher temperatures enable analogy via soft matches—offering a transparent, verifiable substrate for reasoning systems paper page.
🎬 Creative stacks: Veo 3.1 detail gains, Sora 2 deflicker, Riverflow
Generative media pipelines and creator tools: Veo 3.1 micro‑detail tips, Sora 2 deflicker enhancer, and a new #1 image editing entry with pricing. Excludes prior‑day Veo 3.1 rollout feature focus.
Sourceful’s Riverflow 1 debuts at #1 on Artificial Analysis Image Editing (All), priced at $66/1k images
Artificial Analysis ranks Riverflow 1 first on its Image Editing “All” leaderboard; the Sourceful‑trained VLM + third‑party diffusion stack emphasizes reasoning‑guided edits, with a mini tier at $50/1k images and full at $66/1k, trading higher quality for longer runtimes and cost versus Gemini 2.5 Flash ($39/1k) and Seedream 4.0 ($30/1k) arena announcement. You can compare edits in their arena and run the model on Runware’s GPUs via the hosted offering arena page, Runware models.
Veo 3.1: practical prompts for micro‑detail realism in hair, fabric, dust and light
Creators are sharing prompt patterns that unlock Veo 3.1’s finer rendering controls—think “defined curls,” “individual hairs,” “extreme macro close‑up of coat,” and environmental cues like “dust particles in light shafts” to add tactile texture and ambience detail tips, texture tips, surfaces detail. If you want to try these quickly, Veo 3.1 is accessible on Replicate as a paid preview with the new scene‑extension and frame‑match tools model page.
Higgsfield offers unlimited Sora 2 Enhancer through Monday to tackle video flicker
Higgsfield says its Sora 2 Enhancer applies temporal stabilization to remove flicker across frames and is opening unlimited usage through Monday; they’re also giving 200 credits for RT+reply during the promo window enhancer offer, promo details. Product details and presets are listed on their site Higgsfield site, useful if your cuts still show exposure shimmer or texture crawl—common artifacts in AI‑generated motion.
LTX Studio rolls out Veo 3.1 with sharper realism, enhanced audio and full Keyframe control
LTX Studio now supports Veo 3.1 end‑to‑end, highlighting crisper detail, richer native audio and full Keyframe timelines for finer shot‑to‑shot control—useful for storyboarded sequences or ad spots that need consistent character framing studio update. This expands the creator tooling footprint around Veo beyond raw API access toward timeline‑based direction inside a production UI.
🔎 RAG pipelines and dataset builders
Data wrangling and retrieval stacks: faster list builders, TS RAG utilities, and a blueprint to migrate legacy keyword systems to hybrid semantic search.
Weaviate publishes a concrete AWS Unified Studio → Weaviate migration to hybrid RAG
Weaviate outlined a step‑by‑step path to modernize legacy keyword search into hybrid semantic RAG using Amazon SageMaker Unified Studio for data flow, Bedrock for embeddings, and Weaviate for vector/hybrid search—addressing common bottlenecks (slow batch ETL, rigid schemas, mixed data) and positioning retrieval as an API surface for downstream apps blog post. The diagrammed reference shows S3→Iceberg→vectorization→Weaviate indexing, with hybrid search powering context‑aware queries and RAG endpoints.
Exa Websets halves p90 list-building time for web datasets
Exa’s Websets tool sped up large list creation, cutting p90 latency from 103.9s to 43.1s and p50 from 25.6s to 17.5s for assembling companies, people, or paper lists, a meaningful throughput boost for RAG dataset prep speed update, try websets. Following up on Excel parsing, teams now see both richer inputs and faster harvesting in pre‑RAG pipelines. Try the updated interface in the hosted app Websets app.
TypeScript RAG utilities coalesce around @mastra/rag and LangChain splitters
A developer hunt for a TypeScript RAG utility surfaced @mastra/rag as a focused option for chunking and retrieval pipeline helpers, while others noted that LangChain’s text splitters now have solid TS ergonomics and zero extra deps—lowering the barrier to ship TS‑native RAG library request, npm package, langchain splitters. For AI teams standardizing on TypeScript stacks, this narrows choices to two well‑trodden paths for chunking, with fewer Python‑only docs getting in the way.
🚀 Model updates: GLM‑4.6 FP8, Qwen3‑VL Flash
Smaller model updates from open ecosystems and APIs. Mostly incremental quality/perf claims and infra‑side layers; no frontier model debuts here.
Tiny 17M/32M late‑interaction retrievers top LongEmbed’s sub‑1B class
Mixedbread’s mxbai‑colbert‑edge‑v0 models (17M and 32M params, 32k seq length) land as lightweight late‑interaction retrievers that outperform ColBERT‑v2 on BEIR and set a new high for models under 1B on the LongEmbed long‑context leaderboard release note, leaderboard claim. They integrate with PyLate and ship under Apache‑2.0, with a tech report now live for replication details HF paper page.
GLM‑4.6 FP8 gets MTP layers merged on Hugging Face
Zhipu’s GLM‑4.6‑FP8 repo now includes built MTP layers, a small but meaningful serving‑readiness step that should improve inference stability and deployment hygiene model card. Following up on Coding Plan broader tool support noted yesterday, the model card also highlights a 200k‑token context, improved coding and reasoning, and agent‑oriented tool use Hugging Face model.
Qwen API adds ‘Flash’ Qwen3‑VL, faster with quality gains
Qwen’s API now serves a ‘Flash’ version of Qwen3‑VL, with the team claiming it’s both fast and higher quality than the existing 30A3 setting—positioning it for latency‑sensitive multimodal workloads API note. Engineers looking to trim VLM tail latency can trial it as a drop‑in swap while validating any distribution shifts on their own evals.
Qwen open‑sources 4B SafeRL model and a guard benchmark
Alibaba’s Qwen team released Qwen3‑4B‑SafeRL, a safety‑aligned model trained via RL from Qwen3Guard feedback, reporting a WildJailbreak score lift from 64.7 to 98.1 while preserving general task quality open source post. They also published Qwen3GuardTest (streaming moderation and intermediate‑reasoning safety classification), plus code, datasets and model weights for community research.
PaddleOCR‑VL 0.9B: compact VLM targeting on‑device OCR + vision
PaddlePaddle highlights PaddleOCR‑VL (0.9B) as an ultra‑compact vision‑language model that reaches state‑of‑the‑art accuracy for OCR‑centric multimodal tasks, aimed at lightweight and possibly on‑device deployments release blurb. Teams with mobile or edge constraints may find it useful where larger VLMs are impractical.
🎙️ Voice UX: ChatGPT composer & Windows 'Hey Copilot'
Real‑time voice UX tweaks surface in consumer apps—integrated voice in ChatGPT’s composer and a global hot‑word for Windows Copilot with screen analysis.
Windows 11 adds “Hey Copilot” and live screen analysis
Microsoft is rolling out Copilot Voice and Vision updates for Windows 11, adding a global “Hey Copilot” hot‑word and on‑screen context analysis that works system‑wide once users opt in to mic permissions feature rollout.
- Hot‑word activation, taskbar integration and full‑window context promise faster, hands‑free help in Office and desktop flows; setup lives under Copilot settings with a simple toggle how to enable.
- Privacy is opt‑in; Microsoft highlights local file actions in Labs and service connectors as the feature set broadens to more devices feature rollout.
ChatGPT tests integrated voice in the message composer
OpenAI is piloting an “integrated voice mode” directly inside ChatGPT’s prompt composer, eliminating the separate voice screen and keeping users in the current chat or dashboard composer voice test. This lowers modal friction for real‑time dictation and could increase session length and on‑the‑fly tasking for power users, while raising new UX considerations around ambient mic prompts and quick handoff between typing and speaking.