Gemini 2.5 Computer Use public preview – 79.9% WebVoyager, 69.7% AndroidWorld
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google DeepMind’s Gemini 2.5 Computer Use is now in public preview, and it’s the clearest step yet from chatbots to software‑operating agents. In real browsers and Android apps, it posts 79.9% on WebVoyager, 69.0% on Online‑Mind2Web, and 69.7% on AndroidWorld—credible numbers that make UI agents feel less like a demo and more like a tool you can actually wire into workflows.
You can try it free on Browserbase today, complete with head‑to‑head run visualizations to sanity‑check reliability and speed before you integrate. The API is live in AI Studio and Vertex AI with guardrails you actually want: you set allowed actions (click, type, drag, keypress, shortcuts), require per‑step confirmations for risky moves, and keep the model stateless while the client executes. The loop is simple and production‑friendly—send a screenshot and action history, get back a structured step, execute, then re‑observe—and the preview model ID (gemini‑2.5‑computer‑use‑preview‑10‑2025) is already showing up in third‑party browsers. One caveat: OS‑level control isn’t supported yet.
Also worth noting amid the launch buzz: early claims that Gemini solved CAPTCHAs were wrong. Browserbase handled the CAPTCHA, not the model—treat bot‑detection as an environment or human‑in‑the‑loop concern unless a provider explicitly supports compliant handling.
Feature Spotlight
Feature: Gemini 2.5 Computer Use goes public
Google’s Gemini 2.5 Computer Use ships with state‑leading web control accuracy and lower latency, creating a credible baseline for production browser agents and raising the bar for OpenAI/Anthropic.
Cross‑account story: Google DeepMind’s new Computer Use model runs browser/Android tasks via click/scroll/type loops, with external measurements and hands‑on demos across the feed.
Jump to Feature: Gemini 2.5 Computer Use goes public topicsTable of Contents
🖱️ Feature: Gemini 2.5 Computer Use goes public
Cross‑account story: Google DeepMind’s new Computer Use model runs browser/Android tasks via click/scroll/type loops, with external measurements and hands‑on demos across the feed.
Gemini 2.5 Computer Use launches with strong browser/Android benchmarks
Google DeepMind’s new Computer Use model can click, type, scroll and navigate real UIs, posting 69.0% on Online‑Mind2Web (official), 79.9% on WebVoyager (Browserbase), and 69.7% on AndroidWorld; OS control is not yet supported release thread.
Compared to alternative agents, Google emphasizes both higher accuracy and lower latency in Browserbase measurements, framing this as a move from answer‑bots to software‑operating agents rollout summary, analysis thread.
API and docs live: Build loops in AI Studio or Vertex AI with safety gates
Developers can call the Computer Use API from Google AI Studio or Vertex AI and control allowed actions (click, keypress, drag, type, shortcuts), with per‑step safety checks and user confirmation for risky moves Google blog post, API docs. The API patterns mirror a classic agent loop—send a screenshot and action history, get a structured action back, execute, then repeat—so it drops cleanly into existing orchestrators docs link, how‑to docs.
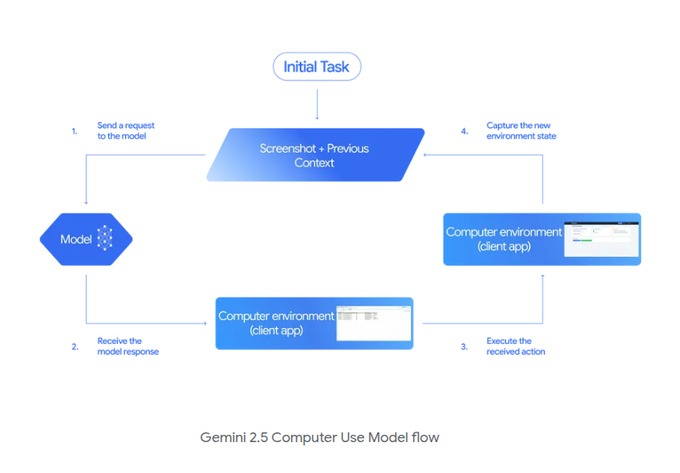
How the loop works: screenshot → propose action → execute → re‑observe
Under the hood, the client captures a screenshot and past actions, the model returns a structured step (e.g., click with coordinates, type with content), the client executes it, then sends back the updated state to iterate until the task completes flow explainer, API docs. This contract keeps the model stateless per step while enabling tool‑ and policy‑controlled execution.
Try Gemini 2.5 Computer Use free on Browserbase, with head‑to‑head tests
Browserbase opened a free public preview so teams can run full click/scroll/type loops with Gemini 2.5 in the cloud, no setup required public preview. Their head‑to‑head page lets you compare runs across models and tasks to validate reliability and speed before integrating head‑to‑head page. The benchmarks Google shared list Browserbase‑measured scores of 65.7% (Online‑Mind2Web) and 79.9% (WebVoyager) for Gemini 2.5 release thread.
CAPTCHA capability clarified: Browserbase solved it, not Gemini
Early claims that Gemini 2.5 solved its own CAPTCHA were corrected: the CAPTCHA step was handled by Browserbase’s environment, not the model correction note. Engineers should treat CAPTCHAs and similar bot‑detection as environment or human‑in‑the‑loop concerns unless a provider explicitly supports compliant handling in‑model Google blog post.
Live demo: Gemini agent finds discounted boots, checks rush delivery, tweaks color
A hands‑on demo shows the model navigating to find pink Merrell hiking boots on sale, validating rush shipping, and changing the color—illustrating end‑to‑end browser operation under supervision shopping demo. This is the new normal for UI agents: reason over pixels, act with structured steps, and keep state across page transitions.
Model ID spotted: gemini‑2.5‑computer‑use‑preview‑10‑2025 appears in tools
Third‑party model browsers list the preview name "gemini‑2.5‑computer‑use‑preview‑10‑2025," helping teams wire the exact model ID in test harnesses and gateways model finder shot. This aligns with Google’s staged rollout across Studio and Vertex, where preview tags frequently change during public trials API docs.
🧑💻 Agent coding workflows and IDE tooling
Cursor, Claude Code, Codex, LlamaIndex, CopilotKit, Sculptor updates and tips. Excludes Gemini Computer Use (covered as the feature).
Droid now runs any open‑source model; GLM 4.6 leads Terminal‑Bench
Factory’s Droid agent framework added broad support for open‑source models; in their Terminal‑Bench, GLM 4.6 tops at 43.5% with multiple Qwen and DeepSeek variants close behind benchmarks chart. A CLI snapshot shows GLM 4.6 wired through Factory Core in practice terminal run, following up on Spec mode practice where teams preferred Droid for precise multi‑step edits.
LlamaIndex ships code‑first LlamaAgents with LlamaCloud deployment
LlamaIndex is pushing a code‑centric approach to agentic workflows: author agents in Python with state management, checkpointing and human‑in‑the‑loop, then deploy end‑to‑end on LlamaCloud. Examples include legal‑doc processing with approval gates and structured outputs over large files product thread. This complements low‑code builders by letting teams fall back to full programmability when workflows get complex.
Replicate’s MCP server plugs Codex, Cursor, Claude and Gemini into one model hub
Replicate released an MCP server that exposes its model catalog to popular agent clients (Codex CLI, Claude, Cursor, Gemini, VS Code), so teams can discover, compare, and run models via a single endpoint product blog, with setup guides for each client MCP server. OpenAI also spotlighted MCP in its keynote, underscoring momentum for a common tool/protocol layer product blog.
Chrome DevTools releases MCP server to let coding agents drive the browser
The Chrome DevTools team open‑sourced an MCP server that exposes DevTools to coding agents, enabling automated inspection and manipulation of pages during debugging and tests—ideal for workflow agents that need DOM‑aware tooling in CI GitHub repo. This pairs well with MCP‑capable IDE agents and gateways already landing across the ecosystem.
Claude Code tip: run long jobs in a separate terminal and monitor them
A practical Claude Code workflow: have the agent open long‑running, log‑heavy commands in a new terminal window, then check progress by screenshot or a hook—avoids losing visibility while keeping interactive control afterward how‑to tip, recap note. This simple pattern reduces copy‑paste churn and helps keep agents accountable during extended runs.
Codex CLI 0.45.0 lands with smoother task loops
OpenAI’s Codex CLI bumped to v0.45.0, with users highlighting a more comfortable loop for planning, approvals, and reviews in longer coding sessions changelog notice. Side‑by‑side workflows show model selection, status, approvals, and review as first‑class commands for agentic coding on local repos cli screen.
CopilotKit’s useCopilotAction lets UIs expose safe, approvable actions
CopilotKit introduced useCopilotAction so frontend apps can define natural‑language‑callable actions that an agent can execute programmatically, with a needsApproval hook to require human consent for risky calls docs link. A companion example shows gating local shell commands so only safe operations run without approval, aligning tool use with enterprise guardrails code example.
Imbue’s Sculptor runs multiple coding agents in isolated containers
Sculptor lets you spin up several Claude Code agents in parallel, each in its own container, then review and merge diffs with Pairing Mode—useful for exploring multiple fixes simultaneously without branch gymnastics product page. The team also shipped binaries for older Macs, expanding reach beyond Apple Silicon release note.
ElevenLabs open‑sources 22 UI blocks for audio and voice agents
ElevenLabs UI offers MIT‑licensed, customizable components for chat, transcription, music, and voice agents (including a stateful voice‑chat block), giving engineering teams ready‑made frontends to pair with back‑end agent loops release note, component demo. This can shorten the path from prototype to production for voice‑first copilots.
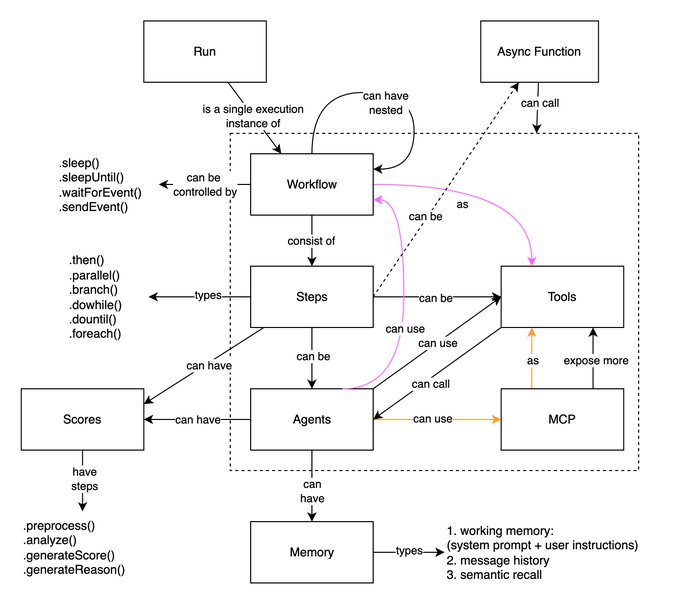
Mastra framework gets an in‑playground Agent Builder and clean mental model
Mastra’s community shared a mental model diagram for its agent workflows (steps, tools, MCP, memory, scoring) and a prototype Agent Builder inside the Mastra playground inspired by recent agent canvases framework diagram, builder preview. It aims to balance declarative orchestration with programmable escape hatches.
📊 Evals: terminal agents and creative leaderboards
Fresh eval results focused on agentic/coding and creative text tasks. Excludes Gemini Computer Use metrics (feature).
GLM 4.6 tops Terminal‑Bench among open models in FactoryAI Droid (43.5%)
FactoryAI’s Terminal‑Bench snapshot shows GLM 4.6 leading open‑source models at 43.5%, ahead of Qwen3 Coder 480B A35B (39.0%) and DeepSeek V3.1 (37.2%). The team adds that GLM 4.6 in Droid "beats Sonnet 4 in Claude Code" on their metric, and Droid now lets you plug in any OS model open models chart. Following up on GLM‑4.6 CC‑Bench, where it neared Claude on agentic coding, this reinforces its terminal‑agent credentials across harnesses. Practitioners are already wiring GLM 4.6 through Factory Core at the CLI, confirming serving readiness in real workflows cli demo.
Arena updates: Sora 2/Pro added to Video Arena; Ling Flash 2.0 enters LM Arena at #60
Arena boards saw multiple updates: OpenAI’s Sora 2 and Sora 2 Pro are now available in the Video Arena for head‑to‑head comparisons video arena update. On the LM side, two open models from AntLing joined with solid placements—Ling Flash 2.0 at #60 overall (#27 among open) and Ring Flash 2.0 at #85 overall (#44 among open) LM Arena ranks, with quick access via the public site Arena site.
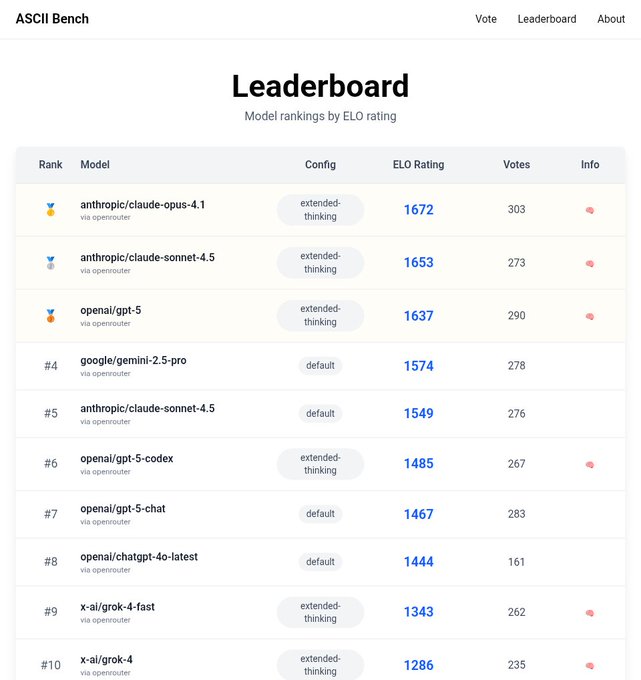
Claude Opus 4.1 leads ASCII Bench with 1,672 Elo (extended thinking enabled)
A new ASCII Bench leaderboard snapshot places Anthropics’s Claude Opus 4.1 at #1 with an Elo of 1,672 using an extended‑thinking configuration, edging out other frontier models on structured ASCII tasks leaderboard shot. The result underscores how chain‑of‑thought or “thinking” modes can materially shift creative‑format leaderboards even without parameter changes.
🎬 Video/image stacks: Sora 2 pipelines and creator tools
Large share of posts cover Sora 2 usage, integrations, and prompting at scale; includes Arena updates and reliability reports.
“Sora Extend” open sources infinite‑length chaining beyond 12‑second cap
A new open‑source tool, Sora Extend, chains Sora 2 clips into effectively infinite videos by enhancing prompts and feeding last‑frame context—bypassing OpenAI’s 12‑second limit Release note, Launch teaser. This lands following up on Longer clips rumor (rumored 288‑second extensions), giving teams a practical workaround today.
ComfyUI ships Sora 2/Sora 2 Pro API node with 720p/1080p and no watermarks
ComfyUI added a first‑party Sora 2 API node that supports 720×1280 and 1280×720 for Sora‑2, plus 1024×1792 and 1792×1024 for Sora‑2 Pro, with clip lengths of 4/8/12s and no watermarks API node details. The team also notes desktop availability, broadening local workflows for creators Desktop note.
OpenAI publishes Sora 2 Prompting Guide; community ships prompt builder with styles
OpenAI’s new Sora 2 Prompting Guide details model selection, clip length, resolution, and shot‑level direction; a community tool auto‑generates style‑rich prompts (nearly 100 styles) with Sora‑2 vs Sora‑2 Pro options Prompting tool, with specifics in the official guide OpenAI guide.
This helps standardize the “cinematographer brief” approach for more predictable results across iterations.
Reliability watch: users flag Sora 2 quality regressions and API instability
Creators report that Sora output quality appears to be getting worse over consecutive days Quality complaint, while others say the API has begun failing on most attempts—especially in back‑to‑back runs API failures. One user also notes the API currently blocks cameos, limiting some meme or family‑video use cases Cameo limit.
Opera Neon integrates Sora 2 in ‘Make’ mode for in‑browser video generation
Opera Neon users can now generate videos via Sora 2 directly from the Make mode UI—type a prompt and render inside the browser Browser integration.
This adds a consumer‑facing surface to Sora workflows alongside pro tools and pipelines.
Replicate exposes Sora 2 and Sora 2 Pro endpoints, billed via OpenAI API keys
Replicate added Sora 2 and Sora 2 Pro as hosted endpoints; usage is billed directly to OpenAI via your API key, making it straightforward to slot Sora into existing Replicate pipelines Replicate links, with model pages for Sora 2 Sora 2 page and Sora 2 Pro Sora 2 Pro page. This widens access alongside MCP‑based model routers and agent stacks.
Video Arena adds Sora 2 and Sora 2 Pro to head‑to‑head leaderboards
The Arena introduced Sora 2 and Sora 2 Pro into its Video Arena, enabling side‑by‑side comparisons against other state‑of‑the‑art video models Arena update. This gives teams a neutral venue to test narrative coherence, motion quality, and prompt faithfulness across vendors.
💼 Enterprise traction and usage signals
Customer adoption, geographic expansion, and usage volumes. Today includes India expansion, mass deployments, and token usage stats.
ChatGPT reaches 800M+ weekly users
OpenAI disclosed 800M+ weekly users for ChatGPT during DevDay, a step‑change in distribution for AI apps inside ChatGPT and a central channel for third‑party app reach DevDay slide. This follows 700M WAU mentioned previously, and cements ChatGPT as the de facto consumer‑to‑enterprise funnel for agents and workflows.
Deloitte to roll out Claude across ~470,000 employees
Deloitte is deploying Anthropic’s Claude across its 470k‑person workforce, signaling one of the largest enterprise AI rollouts to date and underscoring rapid agent adoption in professional services rollout note. The move lands as enterprises intensify investments in agentic workflows and internal tooling to standardize AI‑assisted knowledge work.
GPT‑5 Codex serves 40T+ tokens in under a month
OpenAI reports gpt‑5‑codex has already served 40T+ tokens since launch less than a month ago, making it one of the fastest‑growing models by usage volume usage update. This pace reinforces developer pull for long‑running code agents and suggests rising spend on reasoning‑heavy inference.
OpenAI’s “1T token club”: 30 customers surpassed a trillion tokens
A new leaderboard highlights 30 startup and enterprise customers that have each processed 1T+ tokens on OpenAI, spanning firms like Duolingo, Shopify, Notion, Zendesk, Datadog, and Perplexity leaderboard image. A follow‑up correction adjusts one company mapping, underscoring the scale nonetheless correction note. For AI leaders, this is a concrete signal of sustained production‑grade usage across sectors.
Anthropic to open Bengaluru office in early 2026
Anthropic will open a second APAC hub in Bengaluru in early 2026 to tap India’s developer and enterprise ecosystem, citing heavy Claude usage and social‑impact deployments in education, healthcare, and agriculture announcement. The company notes India ranks second globally in consumer usage of Claude and highlights fast growth in Claude Code adoption among local enterprises such as CRED Anthropic blog.
Hugging Face adds 1M new repos in 90 days
The Hugging Face Hub saw 1,000,000 new repositories created in the last 90 days—now one repo every ~8 seconds—with 40% private and all backed by Xet storage; enterprise hub subscriptions are its fastest‑growing revenue line growth note. For AI leaders, this is a leading indicator of developer activity and internal adoption.
Anthropic tests Claude Excel add‑in for enterprise actions
An authorization flow for a “Claude Excel Add‑in” surfaced, showing account linking and subscription usage—pointing to in‑sheet actions and copilots inside Microsoft 365 auth screen. Bringing Claude into Excel would streamline data tasks and analysis where many enterprises already live.
Google’s Opal Agent Builder rolls out to 15 new countries
Google expanded Opal Agent Builder availability to 15 additional markets including Canada, India, Japan, Brazil, Singapore, and Argentina, widening access to build and deploy agentic workflows rollout list. For platform planners, this broadens geographic coverage for pilots and early production outside the U.S.
Perplexity MAX to add GPT‑5 Pro support
Perplexity signaled incoming GPT‑5 Pro access for MAX users, with UI already showing a “Reasoning with GPT‑5 Pro…” selector in tests model selector. This elevates answer quality for power users and hints at a broader shift toward reasoning tiers in consumer research tools.
⚙️ Compute economics and power constraints
Signals on GPU rentals, margins, and power bottlenecks impacting AI supply. One non‑AI exception category justified by direct AI infra impact.
Leak: Oracle takes ~$100M hit on Blackwell rentals; GPU server margins ~16%
Internal Oracle figures suggest its Nvidia Blackwell rental push is under margin pressure, with a ~$100M quarterly hit and server rental margins around 16%, underscoring how competitive pricing and utilization risk are squeezing GPU lessors article screenshot.
For AI builders, this points to near‑term price instability (discount wars, spot capacity swings) and a premium on workload packing and reservation strategies to avoid being caught between list prices and effective margin floors.
Power becomes the blocker: ‘Bring your own electricity’ enters DC design brief
Operators are increasingly saying new AI datacenters must secure dedicated power—"bring your own electricity"—as grid interconnect queues and megawatt needs outstrip local capacity power bottleneck. This extends the partner map trend of bespoke compute and DC deals spanning hyperscalers, chipmakers, and utilities partnership map, following up on power bottleneck where execs flagged electricity as the limiting factor.
Practical takeaway: plan for on‑site generation (PPAs, thermal, storage) and site selection around GW‑scale growth, not just rack space.
H100 rental arbitrage: Azure EU ~$9.08/hr, US ~$6.98; Prime Intellect ~$1.89
Fresh spot checks show wide dispersion in H100 pricing: Azure lists NC40ads in Europe around $9.08/hr and as low as ~$6.98/hr in some U.S. regions, while Prime Intellect advertises ~$1.89/hr H100s (likely preemptible/spot) price comparison, us pricing.
Expect teams to lean harder on multi‑provider gateways and preemption‑tolerant training/inference (checkpointing, elastic batching) to exploit arbitrage without blowing SLOs.
xAI lines up ~$18B for Memphis supercomputer, escalating the compute arms race
A roundup highlights Elon Musk/xAI planning roughly $18B for a Memphis AI supercomputer, reinforcing the surge in single‑site capex commitments aimed at locking in compute, power, and land for multi‑year scaling newsletter roundup, news brief.
If realized, expect knock‑on effects in regional power procurement, component supply (HBM/network), and a fresh round of long‑term capacity pre‑buys that tighten near‑term spot markets.
🧪 New research: agents, scaling laws, training objectives
Paper drops cover context evolution, memory, scaling alternatives, and coding via diffusion. Mostly peer‑review/preprint style posts today.
UMO scales multi‑identity image fidelity, raising single‑ID to 91.6 and cutting swaps
ByteDance reframes multi‑person image customization as a global assignment problem, adding RL rewards for both per‑face similarity and across‑scene matching; built on OmniGen2, single‑person identity improves from 62.41 to 91.57 and a new confusion metric rises from 62.02 to 77.74 in group scenes paper page.
Joint matching (not per‑face) plus reinforcement signal reduces identity crossovers as the number of subjects grows paper page.
Survey maps text‑to‑video: diffusion with temporal attention dominates, gaps remain
A comprehensive survey tracks the field’s shift from GANs/VAEs to diffusion with temporal attention, outlining common components (autoencoders, cross‑frame attention, text guidance), training practice, and evaluation (FVD for realism/motion, CLIP for prompt faithfulness) paper page.
Open challenges include long-range consistency, multi‑object scenes, identity retention, and compute cost; practical tricks such as pyramidal denoising and keyframe grids are cataloged for practitioners paper page.
🛡️ Safety, legal, and capability clarifications
Policy/legal moves and misuse risk assessments. Capability corrections included. Excludes Gemini Computer Use launch details (feature).
US CAISI says DeepSeek V3.1 lags US models on cyber/software, with higher jailbreak and hijack risk
A new evaluation from the Center for AI Standards and Innovation (CAISI, within NIST’s orbit) finds DeepSeek V3.1 trails leading U.S. models on most practical tasks—especially cybersecurity and software engineering—and is more susceptible to jailbreaks and agent hijacking, while also exhibiting stronger political narrative biases. The study spans 19 benchmarks and compares downloaded DeepSeek weights against U.S. models served via API; it also reports higher security risk exposure and notes adoption patterns one month post‑release exec summary.
- The report cites greater vulnerability to adversarial prompts and weaker guardrails versus peers exec summary.
OpenAI moves to dismiss xAI trade‑secrets suit, denies inducing code theft via hires
OpenAI filed its response to xAI’s complaint, rejecting allegations it encouraged or knew of any source‑code exfiltration by former xAI employees and asking the court to dismiss for failure to state a claim. The filing argues recruiter outreach was standard, xAI lacked reasonable secrecy protections, and no OpenAI use of alleged trade secrets is plausibly pled; it also lists multiple affirmative defenses and seeks costs legal filing recap.
Study finds 5–20% of tokens and early layers drive hidden bias transfer during distillation
A new analysis shows “divergence tokens” (where teachers would choose different words) and early network layers carry most of the subliminal bias signal during knowledge distillation. Masking or rewriting these tokens, or mixing multiple teachers, substantially suppresses bias transfer while preserving accuracy—pinpointing concrete levers for safer model compression paper title page.
Why LLMs hallucinate: being graded to guess beats admitting uncertainty
OpenAI and collaborators argue that training and evaluation pipelines statistically reward confident guessing over calibrated uncertainty, making hallucinations a rational outcome of current objectives and leaderboards. The paper calls for socio‑technical fixes—changing benchmark scoring to prefer uncertainty when appropriate and aligning incentives accordingly—following up on hallucination auditor work that flagged unsupported claims with ~0.67 best accuracy paper overview.
Capability correction: Gemini 2.5 Computer Use did not solve the CAPTCHA—Browserbase did
Following initial claims that Gemini 2.5 Computer Use solved its own CAPTCHA, Simon Willison issued a retraction clarifying the CAPTCHA was actually handled by Browserbase, not by the model. This corrects an early post‑launch misconception and narrows the capability envelope for current browser‑use agents retraction note retraction post.
Google launches AI Vulnerability Reward Program to pay bounties for AI-specific flaws
Google introduced a dedicated AI VRP to incentivize discovery of AI‑specific vulnerabilities—extending bug bounties beyond classic software to model, data, and safety failures. The effort formalizes red‑team economics for AI systems and aligns with broader push toward externalized safety testing ai vrp note.
🤖 Humanoids and embodied agents inch forward
Multiple signals on general‑purpose robots moving toward commercial form factors and org investment.
Figure 03 reveal set for Oct 9 as teaser shows new feet with inductive charging
Figure confirmed a 03 announcement for Oct 9, with a trailer highlighting articulated toes and an "inductive charging" label on the foot—signals of a more production‑ready form factor and dockability debut date, trailer still. Community chatter now centers on whether preorders go live at the event buy button talk, preorder question.
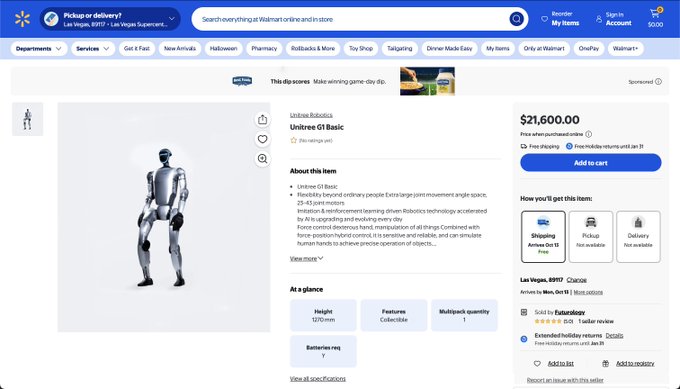
Unitree’s G1 humanoid appears on Walmart for ~$21,600 with 1‑week shipping
A retail listing for the Unitree G1 is live on Walmart at $21,600 with free shipping and a stated one‑week delivery window, marking a notable channel expansion for general‑purpose humanoids beyond direct enterprise sales Walmart listing. For AI leaders, the retail pathway hints at broader developer access and pilots outside traditional procurement.
Qwen launches robotics and embodied AI team to take foundation agents into the physical world
Alibaba’s Qwen set up a robotics/embodied AI group to turn multimodal foundation models into long‑horizon “foundation agents” with tools, memory, and reinforcement learning, explicitly aiming to bridge from virtual to real‑world control team announcement. This is a clear organizational bet that deployable agents will require RL‑grounded policies tied to devices and sensors.
Tesla’s Optimus showcases smoother, more expressive motions at Tron: ARES premiere
Optimus drew attention at the Tron: ARES premiere with fluid, kung‑fu‑style gestures, underscoring Tesla’s incremental progress in motion quality and show‑floor reliability for its humanoid platform demo summary. For analysts, consistent public demos matter as a proxy for actuation control, balance, and thermal/power stability in unconstrained environments.
🧩 MCP interop and tool discovery
Interoperability layer for agents via Model Context Protocol—servers, clients, and devtools. Compact but meaningful updates today.
Replicate launches MCP server for multi‑client model discovery and execution
Replicate released an MCP server that lets Codex, Claude, Cursor, Gemini CLI and others discover, compare, and run thousands of models through a single endpoint, with copy‑paste config for each client and API token auth detailed in the docs MCP server and Home - Replicate MCP server. The push aligns with OpenAI’s "open standard [built on MCP]" stance highlighted on stage, signaling broad client/server interoperability momentum MCP server.
Chrome DevTools ships MCP server to let coding agents introspect and automate the browser
The Chrome DevTools team open‑sourced an MCP server that exposes DevTools capabilities to agent clients, making it easier for coding agents to inspect pages and drive browser debugging workflows via a standardized interface. See the repository for setup and API surface details GitHub repo.
MCP momentum: OpenAI keynote spotlights the standard as Groq + Tavily publish an MCP cookbook
OpenAI’s DevDay keynote repeatedly called out MCP as the open standard for agent tool interop, while Groq and Tavily published a real‑time web search tutorial that implements MCP end‑to‑end—evidence that both platform and tooling ecosystems are converging on the protocol Keynote slide and Cookbook tutorial. This follows earlier signs of MCP‑first design in OpenAI’s upcoming Agent Builder MCP canvas.
🎙️ Voice agents and local STT UX
Voice/UI building blocks and local transcription ergonomics, used by agent builders and app teams.
ElevenLabs open-sources 22 UI blocks for voice agents (MIT)
ElevenLabs released an MIT-licensed UI kit with 22 customizable components spanning chat, transcription, music, and end-to-end voice agents release thread. The voice‑chat‑03 block adds a stateful multimodal chat interface where you can drop in an ElevenLabs Agent ID to ship a working voice experience quickly component demo, with details at component docs.
For AI teams, this trims weeks off building consistent, production‑grade voice UIs (session state, tool use hooks) and standardizes surface patterns for agent handoffs and live audio.
Local Parakeet STT hits ~2.8× real‑time on CPU; whisper‑quiet dictation works
Following up on Maivi STT, a practitioner demo shows Parakeet TDT running locally on CPUs at ~2.8× real‑time, accurately transcribing even whisper‑level speech with a decent mic usage notes. The workflow streams in chunks for smooth UX; the top wish‑list item is context awareness (seeing on‑screen content) to auto‑correct domain terms the user is working with, which would lift accuracy for technical vocabularies.