Karpathy’s nanochat builds end‑to‑end LLM for $100 in 4 hours – on 8×H100
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Andrej Karpathy just open‑sourced nanochat, a from‑scratch training and inference stack that spins up a small ChatGPT‑style model for roughly $100 in about 4 hours on a single 8×H100 node. It matters because this is the first truly shared, hackable baseline that most teams can reproduce, tweak, and teach from without an enterprise‑scale budget. The posted speedrun clocks in at 3h51m and ships with an auto‑generated report card so you can watch CORE, ARC, MMLU, GSM8K, and HumanEval curves move stage by stage.
Under the hood it’s intentionally lean: a Rust tokenizer; FineWeb‑EDU pretrain; SmolTalk‑driven midtrain; supervised fine‑tuning; optional reinforcement learning via GRPO; and a KV‑cache inference engine that serves both CLI and a clean ChatGPT‑like WebUI. The repo logs ~8,304 LOC across 44 files and wires Weights & Biases for pre/mid/RL tracking out of the box. Crucially, about 30 GB of curated FineWeb‑EDU and SmolTalk provide most of the lift at this budget, and the scaling story is clear: a ~12‑hour tier reportedly tops GPT‑2 on CORE, while ~24 hours (depth‑30) reaches 40s on MMLU and 70s on ARC‑Easy. Early community ports include Hugging Face weights and even a CPU‑only macOS runner, lowering the barrier to inspection, ablations, and tokenizer swaps before you rent more GPUs.
Feature Spotlight
Feature: Karpathy’s nanochat ($100 end‑to‑end LLM stack)
nanochat shows a reproducible, $100 full‑stack LLM pipeline (Rust tokenizer, FineWeb pretrain, SFT/RL, evals, KV‑cache engine, WebUI) that trains in ~4h on 8×H100—positioning a clean baseline harness for teams and courses.
Cross‑account, high‑volume launch: a minimal, from‑scratch training+inference stack (tokenizer→pretrain→midtrain→SFT→optional RL→engine+WebUI) you can run on an 8×H100 box in ~4 hours. Highly relevant for engineers as a strong, hackable baseline.
Jump to Feature: Karpathy’s nanochat ($100 end‑to‑end LLM stack) topicsTable of Contents
🧪 Feature: Karpathy’s nanochat ($100 end‑to‑end LLM stack)
Cross‑account, high‑volume launch: a minimal, from‑scratch training+inference stack (tokenizer→pretrain→midtrain→SFT→optional RL→engine+WebUI) you can run on an 8×H100 box in ~4 hours. Highly relevant for engineers as a strong, hackable baseline.
Karpathy releases nanochat: a $100, 4‑hour, end‑to‑end LLM stack on 8×H100
Andrej Karpathy open‑sourced nanochat, a minimal, from‑scratch pipeline that trains a small ChatGPT‑style model in ~4 hours on a single 8×H100 node (~$100), with longer runs beating GPT‑2 CORE and approaching low‑tier benchmark parity as scale increases (e.g., ~24h depth‑30 reaching 40s MMLU, 70s ARC‑Easy). The repo includes a one‑command speedrun, inference engine with KV‑cache and WebUI, and an auto‑generated report card of metrics. See the full breakdown in the launch thread launch thread, with code at GitHub repo and the walkthrough at GitHub discussion.
For AI engineers, this sets a shared, hackable baseline that is cheap to replicate, easy to fork, and useful for teaching, ablations, and small‑scale research prior to scaling.
Inside nanochat’s 8k‑LOC stack: Rust tokenizer → FineWeb pretrain → SmolTalk midtrain → SFT → GRPO → KV‑cache engine
The stack is deliberately small and dependency‑light: a new Rust tokenizer, pretraining on FineWeb, midtraining on SmolTalk conversations and MCQ/tool‑use, SFT with evals across ARC/MMLU/GSM8K/HumanEval, optional RL on GSM8K with GRPO, and an inference engine (KV‑cache, prefill/decode, Python tool sandbox) serving both CLI and a ChatGPT‑like WebUI. It ships with a single‑script bootstrap and a markdown report card to audit runs launch thread. The demo chat UI and links are here repo links.
This end‑to‑end “strong baseline” is framed as the capstone for LLM101n and a fork‑friendly research harness, making it a good target for custom data, tools, or planner/RL swaps.
Community ports arrive: HF weights build and a CPU‑only runner for macOS
Early adopters are already extending the stack: Sam Dobson published a nanochat build on Hugging Face; Simon Willison’s notes document training data and provide a CPU‑only script that runs the model on macOS without CUDA (a minimal GPT in pure Python/Torch for testing and inspection) notes post, with details and the gist here blog post and CPU script. This lowers the friction to test outputs, eval harnesses, or tokenizer choices off‑GPU before renting time.
Expect more forks (e.g., alt tokenizers, schedulers, and eval wiring) as the community hardens the speedrun into repeatable tiers.
Run report card: ~3h51m speedrun with code stats and staged CORE/ARC/MMLU/GSM8K curves
Nanochat auto‑writes a report card summarizing codebase stats (~8,304 LOC across 44 files) and staged performance (BASE → MID → SFT → RL) on CORE, ARC‑E/C, MMLU, GSM8K, and HumanEval; the posted $100 run logged ~3h51m wall‑clock and shows how midtraining/SFT lift knowledge and reasoning metrics over the base pretrain report card image. The staged display helps teams spot where extra midtraining, SFT, or RL budget buys the most improvement before scaling up.
Pair this with the main overview for scale/time targets (12h surpasses GPT‑2 CORE; ~24h depth‑30 reaches 40s MMLU, 70s ARC‑Easy) launch thread.
Data matters: ~30 GB FineWeb‑EDU + SmolTalk supply most of the lift in the $100 tier
Karpathy emphasized the project is “~8KB of Python and ~30GB of FineWeb/SmolTalk” at the $100 tier—underscoring that clean, accessible corpora drive capability even for tiny stacks author reply. The repo defaults to FineWeb‑EDU shards for pretraining and SmolTalk/MMLU/GSM8K for midtraining/SFT, with the public dataset hosted on Hugging Face dataset note, see Hugging Face dataset. For practitioners, this is a ready recipe to swap in domain‑specific shards without retooling the pipeline.
Tight coupling between small, well‑filtered pretraining and focused midtraining appears to be the main lever at these budgets.
Weights & Biases logging is wired in across pre, mid and RL stages
Weights & Biases confirmed nanochat ships with W&B instrumentation for the pretrain, midtrain and RL loops, giving teams immediate run tracking, comparisons across budgets, and metric curves out of the box W&B note. This is useful for hill‑climbing (e.g., tokenizer changes, data mix, schedulers) before paying for longer 12–24h tiers.
🏗️ Compute buildouts and energy math
Infra news is dense today: OpenAI–Broadcom 10 GW custom accelerators (term sheet, 2026–2029 timeline), regional DC plans, and power/water economics. Excludes the nanochat feature.
OpenAI–Broadcom 10 GW custom accelerators to roll out 2026–2029
OpenAI and Broadcom signed a term sheet to co‑develop and deploy 10 GW of OpenAI‑designed accelerators on racks scaled entirely with Broadcom Ethernet, with first installs in H2’26 and completion by end‑2029 term sheet details, OpenAI blog. Following up on power bottlenecks, this locks in a multi‑year, non‑NVIDIA path to meet surging demand while embedding model learnings directly into hardware.
Beyond capacity, the rack‑level Ethernet design signals a bet on scale‑out fabrics for frontier clusters, reducing vendor concentration risk and potentially pulling forward energy and real‑estate planning across partner DCs.
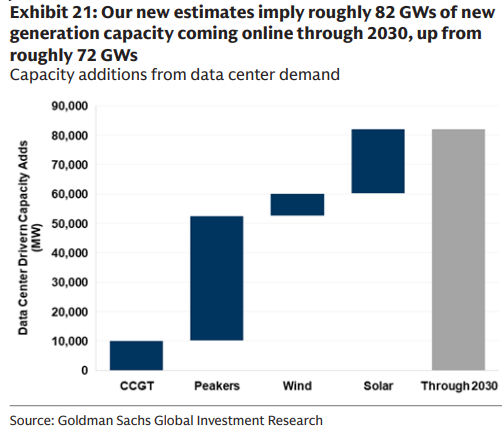
Goldman: U.S. needs ~82 GW new generation for data centers by 2030
Goldman Sachs now models ~82 GW of new U.S. generation tied to data center demand by 2030 (up from ~72 GW), with a build mix leaning to solar first, then peakers, combined‑cycle gas, and wind capacity mix.
This reframes grid planning from incremental upgrades to a generational buildout, with dispatchable capacity (peakers/CCGT) needed to firm AI‑heavy, 24/7 loads as renewables scale.
OpenAI targets 500 MW “Stargate Argentina” under new investment regime
Argentina says OpenAI and Sur Energy signed a letter of intent for “Stargate Argentina,” a ~$25B project targeting 500 MW of AI compute capacity under the RIGI incentive framework (import tax breaks, faster depreciation, FX stability) project details. If built, the site would host tens of thousands of accelerators and anchor a Latin America AI cluster alongside TikTok’s $9.1B Brazil build.
The package underscores the shift to multi‑region AI capacity, where sovereign incentives and power availability drive placement as much as chip supply.
Altman and Brockman outline chip rationale and compute demand on OpenAI Podcast
In Episode 8, Sam Altman and Greg Brockman argue that every capability gain and cost drop unlocks massive new demand—"even 30 GW with today’s models would saturate fast"—and that Ethernet‑scaled racks encode frontier learnings into silicon podcast trailer, YouTube episode, demand quote. The remarks contextualize the 10 GW Broadcom plan as a floor, not a ceiling, for near‑term compute needs.
Goldman models ~175% global DC power growth by 2030
Goldman Sachs Research projects global data center electricity use to climb ~175% by 2030, pushing U.S. electricity growth to ~2.6% CAGR—the fastest since the 1990s global projection.
They frame drivers as the “Six Ps” (pervasiveness, productivity, prices, policy, parts, people), implying parallel investment in generation, transmission, and skilled labor, not just GPUs.
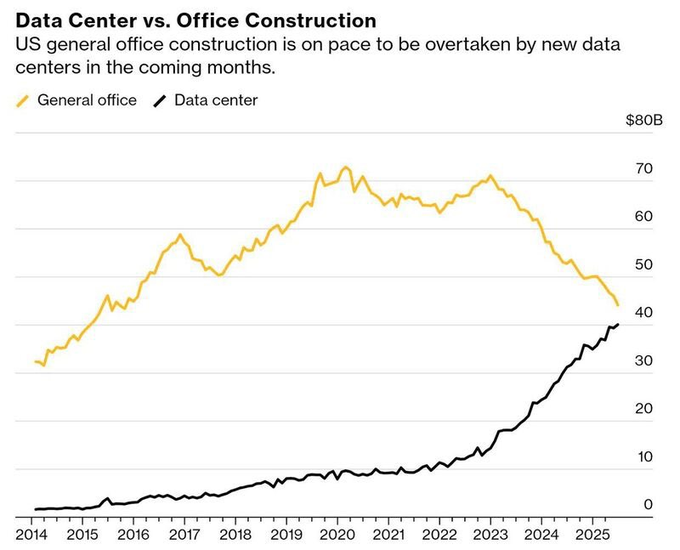
Data center construction set to surpass office spend in the U.S.
Fresh spend charts show U.S. data center construction (~$38B) rapidly approaching and set to pass general office (~$40B), marking a structural capex shift from human workplace to compute infrastructure spend chart.
For operators, this signals tighter competition for power, land, and contractors in DC‑dense metros, plus growing municipal scrutiny over zoning and utilities.
Putting U.S. data‑center water use in context
Best‑available ranges place U.S. DC water at ~50M gallons/day for cooling alone, ~200–275M when including power (sans dam evaporation), and up to ~628M/day if counting hydro reservoir evaporation—figures that are material but below golf’s footprint nationally water recap, LBNL report, analysis post.
Takeaway for AI builders: water impact depends heavily on site design and grid mix. Closed‑loop cooling and siting in cooler climates can materially lower consumptive use.
🔌 Chips, memory and interconnect stack
Hardware updates that shape model throughput/efficiency: Samsung’s HBM4 process bets, NVIDIA Spectrum‑X Ethernet adoption, GB200 perf metrics, and MGX/800 VDC rack direction. Excludes OpenAI chip collaboration details (covered under Infra).
Meta and Oracle adopt NVIDIA Spectrum‑X Ethernet to push AI fabric utilization toward ~95%.
NVIDIA says Meta and Oracle are integrating Spectrum‑X Ethernet to interconnect million‑GPU‑scale AI clusters, targeting ~95% effective throughput versus ~60% on typical Ethernet via congestion control and adaptive routing adoption note, with details in the first‑party announcement NVIDIA news.
For AI infra leads, this points to Ethernet fabrics closing the gap with proprietary interconnects at hyperscale while preserving tooling and operations already built around IP networking.
NVIDIA MGX Vera Rubin NVL144 racks pivot to 800 VDC and cable‑free midplanes for dense AI factories.
NVIDIA and 50+ MGX partners spotlight NVL144 compute trays (100% liquid‑cooled, PCB midplane, ConnectX‑9 800 GB/s bays) and 800 VDC distribution to cut copper, conversion losses, and heat, with Foxconn showing a 40 MW site built for 800 VDC blog summary. Following up on power limits, the shift targets density and grid efficiency as constraints move from chips to power and floor space.
Practically, 800 VDC plus midplane designs mean higher rack kW, simpler service, and faster scale‑out—at the cost of tighter facility safety envelopes and liquid loop reliability.
Samsung leans on 1c DRAM and 4 nm logic die to raise HBM4 speed targets.
Samsung is pitching higher‑clock HBM4 built on 1c (6th‑gen 10 nm‑class) DRAM with a 4 nm logic base die, aiming to reset the spec upward after rivals optimized for thermals; the move counters SK Hynix (TSMC 12 nm logic) and Micron (DRAM‑node logic) and could shift GPU memory binning and bandwidth ceilings analysis thread.
If NVIDIA buys into higher official speeds, expect board/power delivery and cooling headroom to become the next bottlenecks rather than raw memory frequency.
SemiAnalysis: GB200 leads on tokens/sec, tokens per dollar and tokens per megawatt.
Fresh InferenceMAX comparisons chart GB200 ahead of H100 and AMD MI355X/MI300X across throughput, price‑performance, and energy efficiency, implying better utilization under power‑constrained buildouts benchmarks chart.
For capacity planners, GB200’s tokens/MW advantage is the standout metric when siting is gated by feeders and substations rather than capex alone.
NVFP4: NVIDIA details 4‑bit pretraining that matches FP8 quality with 2–3× math throughput on Blackwell.
NVIDIA’s NVFP4 format (4‑bit blocks with 8‑bit block scales and a 32‑bit tensor scale) reports pretraining accuracy near FP8 (e.g., MMLU‑Pro 62.58 vs 62.62) while cutting memory ~50% and running ~2× on GB200 and ~3× on GB300 versus FP8; support lands in Transformer Engine and Blackwell hardware paper thread.
If productionized, FP4 math could lower training TCO and rack power per token—so long as late‑stage BF16 fallbacks remain to close the small loss gap.
🛠️ Coding with agents: workflows, CLIs and usage tooling
Practitioner signals on agent workflows (Codex vs Claude Code), plan/rewind patterns, terminal/browser loops, and platform usage dashboards. Excludes nanochat (feature).
Google AI Studio ships live Rate Limit/Usage dashboard with RPM/TPM/RPD and per‑model filters
AI Studio now exposes a first‑party rate‑limit and usage view: peak Requests per Minute, Tokens per Minute, and Requests per Day with time‑series breakdowns, plus model‑level filtering and real‑time headroom—huge QoL for teams watching spend and throttles dashboard screenshot, feature thread. Multiple confirmations show the same UI and metrics, with links inline for projects feature recap, and more screenshots of limit charts and tables another screenshot. Try it from the project usage page AI Studio usage.
Claude Code adds /rewind checkpoints to recover a session after something breaks
Claude Code’s new /rewind lets you restore prior checkpoints within the same session, making it far easier to undo a bad tool run or broken local state feature callout. The official docs now describe how checkpointing works and when to use it to roll back safely docs link, with setup details in Claude docs.
Cursor Plan Mode prompts teams to track usage and spin off background jobs for minor refactors
Adopters say Plan Mode is good enough that they’re checking their consumption and refining workflows to keep costs predictable usage review. Feature requests include auto‑kicking background jobs from plans for smaller refactors and tighter GitHub issue integration feature request, with reports of sustained 24‑hour agent runs passing 200 tests in real projects 24h run results.
Langfuse adds Gemini observability so you can see per‑run input/output token costs and traces
Langfuse integration now captures Gemini runs with detailed telemetry and cost breakdowns by input/output tokens—useful for auditing agent chains and catching regressions integration note. Quickstart code shows how to instrument the Google GenAI SDK and stream traces into Langfuse how‑to guide, with setup steps in Langfuse docs.
Practitioners split duties: Claude 4.5 for front‑end structure, Codex‑High for backend, refactors and long runs
Working teams are converging on a simple playbook: use Claude 4.5 when shaping front‑end logic/structure and Codex‑High for backend tasks, large refactors, or when you want to step away for 30 minutes without interruptions tool choice tip, with a clarification that "front end" here means structure/logic, not UI clarification note. Builders also report Codex excels when specs are precise (I/O formats, edge cases, error handling) while Claude is more forgiving and explains steps better for non‑programmers skill guidance, and that Codex is a reliable daily driver for extended autonomous coding sessions daily driver claim.
tmux + Chrome DevTools keeps agent loops alive during local dev servers, avoiding stalled cycles
Developers are closing the loop by launching their local server in tmux and attaching Chrome DevTools control so the agent keeps making progress while pnpm run dev stays alive—no more event‑loop stalls mid‑session tmux capture, devtools loop. This builds on the two‑command DevTools MCP hookup reported earlier, following up on DevTools MCP which enabled live browser control in the first place.
Vercel AI adds pruneMessages to trim agent/tool‑inflated histories and control prompt budgets
A new helper in the Vercel AI SDK prunes ModelMessage arrays so agentic loops with heavy tool calls don’t overrun context windows or cost budgets; drop it into prepareStep or after UI→model message conversion feature shipped, with the implementation and examples in the merged PR GitHub PR. The idea originated from a community proposal and quickly landed upstream proposal image.
‘bd’ proposes an agent‑native, git‑versioned issue tracker for mixed human/agent workflows
An emerging CLI called bd pitches a Taskwarrior‑style, agent‑native issue tracker: JSONL records stored in git, ready‑work detection (no blockers), rich dependency graphs, and --json flags for programmatic use so both humans and agents can coordinate from the same repo features overview. Screens highlight commands for updating issues, modeling dependencies, and querying ready work in a way that agents can consume.
Pin Claude Code’s python to a uv virtualenv using PATH or hooks to avoid polluting globals
Builders recommend forcing Claude Code’s python -c invocations to run from a dedicated uv environment by manipulating PATH before launch or using hooks, rather than activating venvs ad‑hoc inside the session env question, PATH approach. Others echo that PATH‑first and hook‑based isolation keeps global Python clean during agent runs PATH tip, use hooks.
🧩 Enterprise connectors and MCP surfaces
Agent interoperability and enterprise surfaces: Slack×ChatGPT app/connector, Grok GitHub linking, plus a roundup of real MCP servers. Excludes coding‑agent workflow specifics (captured elsewhere).
OpenAI ships ChatGPT for Slack and a Slack connector for enterprise context
OpenAI rolled out two Slack integrations: a ChatGPT app that lives in a sidebar for 1:1 chats, thread summaries, and reply drafting, and a Slack connector that securely injects channel/DM context into ChatGPT chats, Deep Research, and Agent Mode (paid Slack required). See capabilities, access, and plan eligibility in the release notes release overview and OpenAI release notes, with Slack’s own announcement reinforcing the launch Slack highlight.
For AI platform owners, this is a material surface: it standardizes Slack as both a retrieval source and an execution venue, reducing glue code for enterprise pilots and making agent outputs auditable against messages/files the user already has permissions for feature tease.
MCP momentum: database, network, IDE and workflow surfaces ship across the stack
Multiple real MCP endpoints and guides landed, signaling a fast‑maturing integration layer for enterprise agents:
- Cisco publishes a how‑to to build an MCP server that grants LLMs safe, scoped access to network devices, including a code walkthrough Cisco guide.
- Oracle brings MCP Server to SQLcl so MCP clients can query Oracle Database with secure chat flows Oracle SQLcl.
- Visual Studio hits general availability for MCP, enabling AI‑driven workflows in .NET shops VS availability.
- LlamaIndex documents official MCP servers (e.g., LlamaCloud) for connecting AI apps to data/tools LlamaIndex docs.
- TypingMind adds Make.com MCP linking for chat‑based automations TypingMind integration.
- 450+ MCP servers get containerized images to simplify secure self‑hosting Docker images.
Takeaway: with vendors standardizing on MCP for permissions and transport, teams can swap tools without reprompting agents and move toward auditable, least‑privilege execution across IDEs, data, and SaaS.
xAI lights up GitHub ‘Connect’ in Grok’s web UI for external calls
Grok’s Connected Apps now shows a GitHub “Connect” button; a note clarifies only Grok Tasks can chat with or call external connections at this stage settings UI, integration screenshot. This follows GitHub test where an earlier build exposed the first signs of the integration; today’s UI means OAuth and scope wiring are near‑ready for broader agent workflows.
Why it matters: native GitHub access (issues, PRs, code search) is a top‑tier enterprise ask for agentic CI and repo Q&A. Limiting initial access to Tasks helps stage rollouts while xAI hardens permissions and action audit trails.
ChainAware debuts a Portfolio Construction MCP for math‑driven crypto rebalancing
ChainAware introduced a Portfolio Construction MCP that lets agents optimize and rebalance crypto portfolios using quantitative strategies inside a unified MCP workflow product note. For analysts, this adds a domain‑specific tool to automate constraints, turnover, and benchmark tracking while preserving MCP’s auditability and pluggability across agent stacks.
🎙️ Native speech reasoning hits SOTA
Dedicated speech‑to‑speech reasoning news: Gemini 2.5 Native Audio Thinking leads Big Bench Audio with details on latency tradeoffs and thinking budgets.
Gemini 2.5 Native Audio Thinking tops speech-to-speech reasoning with 92% on Big Bench Audio
Google’s Gemini 2.5 Native Audio Thinking set a new state of the art at 92% on Artificial Analysis’ Big Bench Audio, beating prior native S2S systems and even a Whisper→LLM→TTS pipeline baseline benchmark summary.
The model trades speed for quality in “thinking” mode with ~3.87s time‑to‑first‑audio, while its non‑thinking variant leads latency at ~0.63s; GPT Realtime sits near ~0.98s, underscoring a clear accuracy‑latency tradeoff by task latency notes. Beyond scores, the system natively ingests audio, video and text and returns natural speech or text, with function calling, search grounding, configurable thinking budgets, a 128k input / 8k output context, and a Jan‑2025 knowledge cutoff feature summary. For selection guidance and providers, see the live leaderboard and vendor comparison pages model comparison page.
🎬 Generative media stacks and creative tooling
A busy day for video/image generation: Sora 2 sketch‑to‑video workflows, new NotebookLM “Nano Banana” video styles, Kandinsky 5 on fal, Kling 2.5 Turbo 1080p costs/leaderboard moves.
NotebookLM adds Nano Banana video styles and “Explainer vs Brief” formats; Pro now, wider rollout soon
Google’s NotebookLM Video Overviews now support six Nano Banana‑powered styles (Whiteboard, Watercolor, Retro print, Heritage, Paper‑craft, Anime) and two formats (“Explainer” for depth, “Brief” for speed), rolling to Pro first and then all users feature image, rollout note. This extends Google’s push into templated, on‑brand video summaries, following up on Veo playbook where creators mapped consistent looks across tools. The UI exposes a clear style picker and focus hints to steer hosts and visuals feature notes.
Kling 2.5 Turbo 1080p enters LMArena Top‑5 for text‑to‑video and ties #3 in image‑to‑video; ~$0.15/5s
The community‑run Video Arena now lists Kling 2.5 Turbo 1080p among the leaders: tied at #5 for text‑to‑video and tied at #3 for image‑to‑video, with generation priced around $0.15 per 5 seconds at 1080p leaderboard update. A separate leaderboard view confirms its positions as votes roll in leaderboard detail. This puts Kling squarely in the value tier versus Veo/Sora on cost while closing quality gaps in common prompts.
Higgsfield ships Sketch‑to‑Video on Sora 2 with 1080p motion and limited‑time 200‑credit promo
Higgsfield’s new Sketch‑to‑Video turns hand drawings into cinematic 1080p clips, emphasizing physicality (weight, momentum, emotion) and storyboard‑to‑scene coherence. The team hosted a live how‑to with prompts and offered a short window of bonus credits to spur trials release thread, livestream invite, and the product page details workflow and examples product page. This pushes Sora 2 into a creator‑first pipeline—storyboards become final scenes without leaving the tool narrative coherence.
Kandinsky 5.0 arrives on fal with cinematic text‑to‑video at ~$0.10 per 5‑second clip
fal is hosting open‑source Kandinsky 5.0 for text‑to‑video, emphasizing realistic performances, strong cinematic motion, and better prompt adherence at an aggressive price point (~$0.10 per 5s at 1080p) release note. A public playground makes it easy to test prompt variations and fidelity before integrating into pipelines playground.
Wavespeed lists Google Veo 3.1 text‑to‑video+audio endpoint; community asks for Google confirmation
Third‑party platform WaveSpeed AI now shows a Veo 3.1 endpoint supporting text‑to‑video with audio, stirring calls for an official acknowledgment from Google listing page, model page. If verified, this offers another path to test 3.1’s motion and sound sync prior to wider first‑party rollout.
📊 Leaderboards and provider comparisons
Fresh leaderboard movements beyond speech/video: Microsoft’s MAI‑Image‑1 enters LMArena’s top‑10; provider‑level speed comparisons for DeepSeek variants.
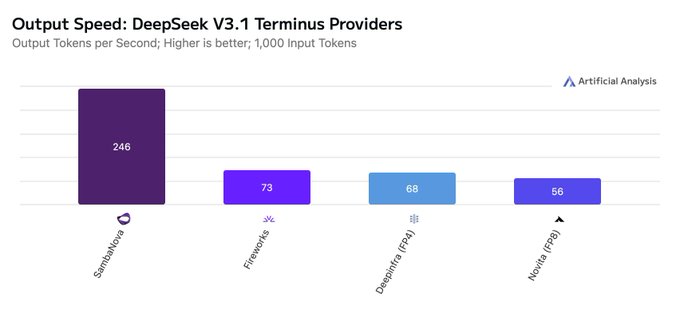
DeepSeek V3.1 Terminus and V3.2 Exp: fastest providers and tokens/sec across vendors
Artificial Analysis published provider comparisons for DeepSeek’s hybrid reasoning models, showing V3.1 Terminus served by SambaNova, DeepInfra, Fireworks, GMI and Novita, with SambaNova around ~250 tokens/sec (≈10× faster than DeepSeek first‑party inference) provider comparison, while V3.2 Exp is on DeepSeek’s API, DeepInfra, GMI and Novita, with DeepInfra up to ~79 tokens/sec provider comparison. See the live provider pages for specifics on throughput and availability V3.2 providers, and Terminus providers.
Both releases are positioned to replace the earlier V3 and R1 lines; Terminus edges V3.2 by one point on the Artificial Analysis Index, but vendor choice and serving stack materially affect real‑world latency and cost.
Microsoft’s MAI‑Image‑1 debuts in LMArena’s top 10 (tied #9), open for community voting
Microsoft’s first in‑house image model, MAI‑Image‑1, has entered LMArena’s Image leaderboard tied at #9 with Seedream 3 and is available in Direct Chat for early testing and votes image arena ranking, with the team saying commercial availability is expected in the coming weeks image arena ranking. You can try it and vote in LMArena’s interface to influence placement direct chat access, and follow the board at the source LMArena homepage.
This puts Microsoft directly into a community‑rated image stack alongside open and closed competitors; watch for fast movement as early votes accumulate and prompts diversify.
🧠 Reasoning, RL and training recipes
Multiple new methods and datasets on agent planning, reward‑free learning, and cost‑efficient fine‑tuning; plus infra notes for RL scaling. Excludes nanochat’s training specifics (feature).
HERO hybrid RL blends verifier bounds with dense RM scores for more stable reasoning
By stratifying reward‑model scores within verifier‑defined groups and weighting by variance, HERO preserves the stability of verifiers while capturing partial credit and heuristic nuance—consistently outperforming verifier‑only or RM‑only baselines on math reasoning release summary, with details in ArXiv paper.
LightReasoner finds the hard tokens with a weaker model; cuts tuned tokens ~99% and time ~90%
An “expert–amateur” contrast pinpoints steps where next‑token predictions diverge; training only on those selective steps matches or beats full SFT on math while slashing compute and data paper abstract.
Works best when the amateur differs in domain skill (not just size), suggesting a practical path to targeted reasoning upgrades.
MM‑HELIX trains reflective, backtracking MLLMs; +18.6% on a 100k‑task long‑chain benchmark
A new multimodal benchmark (1,260 tasks) exposes weak long‑chain reasoning; the authors introduce a 100k reflective trace set and an Adaptive Hybrid Policy Optimization (AHPO) recipe combining offline supervision and online learning to close the gap (+18.6% accuracy, +5.7% general reasoning) paper overview.
The recipe teaches models to iterate, verify and revise rather than emit a single brittle chain.
Webscale‑RL: Salesforce releases 1.2M‑example, 9+ domain pipeline to scale RL data to pretrain levels
An automated pipeline and public dataset aim to remove the RL data bottleneck, bringing reinforcement signals to the same order of magnitude as pretraining corpora dataset brief.
For teams exploring verifier/RM‑driven post‑training at scale, this offers a starting point to standardize sources, processing and quality controls.
Agent‑in‑the‑Loop: Airbnb turns live support ops into a continuous training flywheel
A production framework logs four signals per case (reply choice, adoption, grounding quality, missing knowledge) and feeds them into joint retrieval/ranking/generation training; a 5k‑case pilot improved retrieval accuracy, source citation and human adoption while cutting retrain cycles from months to weeks paper overview.
A virtual judge filters noisy labels; spot audits catch drifts the judge misses.
AI‑driven research (ADRS) discovers faster systems algorithms—up to 5× runtime or 26% cost wins
A loop that generates candidates, simulates them and keeps a verifier in the middle finds better policies for MoE expert placement, database plans, and schedulers; reliable simulators enable rapid iteration and measurable gains paper abstract.
The template—clear specs, diverse tests to avoid overfitting, and reward‑hacking guards—is broadly reusable for agentic optimization.
R‑Horizon probes breadth and depth limits; query composition stresses long‑horizon reasoning
A controllable benchmark composes queries to measure how far reasoning models go in depth and breadth, revealing where long‑horizon performance collapses and how steering signals can recover it paper abstract.
Useful as a sanity‑check before deploying agent loops that require multi‑phase plans.
RL infra notes: inflight updates and continuous batching to fix long‑tail stalls
Frontier shops are moving to fully async loops—continuously generating completions while applying model updates during generation—to reduce idle GPUs and the “one long sample blocks all” tail slides diagram.
Practitioners also call out inflight KV reuse and continuous batching as key enablers for scalable GRPO‑style training infra note.
BigCodeArena: judge code by execution, not source—capturing real user preferences
A new arena compares code generations via their run results, not just reading the text; side‑by‑side execution makes it easier for users to pick better outputs and yields more reliable preference data for training project overview.
Expect cleaner reward signals for code RLHF/RLAIF pipelines and fewer stylistic biases in labels.
Measuring emergent coordination: information‑theoretic synergy separates teams from crowds
A framework tests whether a group’s output predicts outcomes better than any agent alone, decomposing shared vs unique vs synergistic information; adding personas and theory‑of‑mind prompts induces stable roles and complementary actions, while smaller models fail to coordinate paper summary.
Useful diagnostics before scaling multi‑agent LLM systems.
💼 Adoption and enterprise signals
How AI is reshaping orgs and spend: Slack×ChatGPT impact (covered under Orchestration), star‑worker advantage, Klarna support automation, Kimi workload shifts, and JPMorgan’s AI‑inclusive initiative.
JPMorganChase pledges $1.5T for U.S. security and resiliency with AI as a pillar
JPMorganChase launched a 10‑year, $1.5T initiative spanning supply chains, defense, energy resilience, and frontier tech including AI, cybersecurity, and quantum—signaling sustained enterprise and public‑sector demand for AI capabilities and infra financing initiative summary, and details in the bank’s press release press release.
- Focus areas include advanced manufacturing, defense tech/autonomy, grid and storage, and frontier tech (AI/cyber/quantum) initiative summary.
Klarna: AI now handles ~66% of support chats; staff down from ~7,400 to ~3,000
Klarna’s CEO says the company shrank to ~3,000 employees from ~7,400 as its AI agent took on about two‑thirds of customer support—roughly 700 human‑agent equivalents—while underwriting remains human‑heavy due to risk constraints Bloomberg interview. Expect faster margin pressure in routine knowledge roles before harder‑to‑automate, policy‑bound functions.
Study: AI adoption is “seniority‑biased,” junior hiring declines at adopters
A large résumé/postings study (~62M workers, ~285k firms) finds GenAI adoption correlates with falling junior employment versus non‑adopters, while senior employment keeps rising; drops are concentrated in high‑exposure roles and driven by slower hiring rather than separations paper abstract. Leaders should rebalance task allocation and training to avoid hollowing entry pipelines.
WSJ: AI is amplifying star workers’ advantage inside firms
AI tools are boosting high performers more than peers, widening status and pay gaps as experts adopt earlier, judge outputs better, and get more credit for AI‑assisted work WSJ analysis. For leaders, this argues for targeted enablement (training, workflows, evaluation norms) to avoid morale and coordination costs as AI scales.
Central bank field experiment: AI lifts quality 48% and cuts time 23% on generalist tasks
In a National Bank of Slovakia/Yeshiva field study, access to GenAI raised output quality by 48% and reduced time by 23% on generalist tasks; on specialist work, quality more than doubled, while high‑skill workers gained more in efficiency paper overview. The results suggest re‑tasking and skill‑mix changes can unlock outsized gains beyond tool rollout alone.
Workloads shift to Kimi K2 on cost/perf, says Chamath
Chamath Palihapitiya says a large Bedrock customer reallocated “tons” of workloads to Kimi K2 for better performance at lower cost, highlighting growing enterprise price sensitivity and model vendor diversification podcast clip. For buyers, this strengthens the case for multi‑provider routing and continuous cost–quality re‑bids as models iterate.
🤖 Embodied AI and real‑world readiness
Unitree G1 clips show faster, cleaner motion; community asks for home‑use demos and practical tasks. Smaller volume vs models/infra but notable trend.
xAI is building world models to auto‑generate games and guide robots; first full AI‑generated game targeted by Dec‑2026
xAI says it’s training causal world models—learning physics and 3D layout from video/robot data—to generate playable game worlds and eventually inform robot control; Musk targets a “great AI‑generated game before the end of next year,” with recent hires from Nvidia onto the effort news analysis.
For embodied AI, this shifts from frame prediction to dynamics‑aware simulation (object permanence, contacts, long‑horizon planning). If successful, the same models could cut robot data requirements, improve sim‑to‑real transfer, and enable task‑level policy learning with far fewer real‑world trials.
Unitree G1 ‘Kungfu Kid’ V6.0 shows cleaner, faster motions in latest clip
Unitree’s new G1 Kungfu Kid V6.0 video highlights noticeably steadier footwork, quicker transitions, and a broader routine—useful signal on locomotion/control maturity for low‑cost humanoids progress video. A separate roundup notes the cadence of G1 improvements and how each release looks more polished than the last new clip, with analysts framing the pace as part of China’s aggressive robotics push analysis thread.
For AI engineers, this suggests policy and trajectory libraries are stabilizing (shorter recovery, less drift), but readiness still hinges on manipulation robustness, autonomy under clutter, and task benchmarks—not just choreographed motion.
Developers push Unitree to demo real household tasks, not just stunts
After the latest G1 showcases, practitioners are asking for proof of value beyond martial‑arts routines—e.g., laundry pickup, dish loading, or tool use in messy homes—to evidence reliability, safety, and recovery behaviors under non‑scripted conditions home use ask. That pressure follows multiple “kung fu” clips in short succession new clip, and it’s the gap enterprise buyers will watch: can the same control stack handle occlusions, deformables, and error correction without human resets?
🗂️ Parsing, retrieval, and data pipelines
Updates to doc pipelines and execution‑aware evals: Firecrawl OSS upgrades, BigCodeArena (execution‑grounded code prefs), and production parsing talks.
Firecrawl v2.4.0 ships: PDF search, 10× semantic crawling, new x402 search endpoint
Firecrawl released v2.4.0 with a dedicated PDFs search category, roughly 10× better semantic crawling, a new x402 Search endpoint (via Coinbase Dev), an updated fire-enrich v2 example, improved crawl status and endpoint warnings, and 20+ self‑host fixes—following up on open builder where the team teased visual, n8n‑style workflows. See the feature rundown in the release summary release thread and the code in the repository GitHub repo.
These upgrades push Firecrawl further into “LLM‑ready” web data pipelines (cleaner extracts, higher recall) while lowering day‑2 ops friction for self‑hosters. The x402 endpoint in particular broadens query sources developers can tap without custom glue GitHub repo.
BigCodeArena evaluates code by execution, not source style, to capture real user preferences
BigCodeArena introduces an execution‑grounded way to compare LLM‑generated programs: run both candidates and judge by outcomes rather than read the code, enabling more reliable human feedback at scale for codegen systems paper thread.
This framework helps teams reduce “pretty but wrong” biases in code evaluation, align models to runtime behavior, and A/B prompts or post‑training recipes using objective pass/fail signals.
Hugging Face debuts RTEB to measure retrieval models’ real‑world generalization
The Retrieval Embedding Benchmark (RTEB) combines open and private datasets to curb leakage and better reflect production retrieval performance, addressing inflated scores from public‑only evals benchmark blog. The methodology targets developers deploying RAG and search, emphasizing robustness on unseen data rather than leaderboard gaming benchmark blog.
Reducto to demo hybrid OCR‑VLM pipeline for multi‑page, structured extraction at production latencies
A live session will walk through Reducto’s hybrid OCR + VLM architecture aimed at parsing complex, multi‑page documents with low hallucination and production‑grade latency, including structured extraction and natural‑language automation workflows event brief, with sign‑up details in the event page event signup.
For AI teams drowning in PDFs, this approach shows how to combine deterministic OCR with VLM reasoning to improve accuracy and throughput over VLM‑only parsers while keeping latency predictable notes thread.
A practical evals loop: define task, dataset, scorers to expose regressions and drive improvements
Braintrust outlines a simple but rigorous pattern for AI evals—compose a concrete task, curate a golden dataset, then attach scorers—to catch regressions and steer iteration, with examples of applying it to model and agent workflows evals how-to. The post details getting started and instrumenting runs to move beyond intuition‑driven tuning evals blog.
🛡️ Policy, legal and platform risk
Regulatory and legal developments today: California’s SB 243 for AI companions and litigation pressure in book‑data cases. Excludes model jailbreak work (not in this sample).
Judge considers piercing OpenAI privilege in book‑data case under crime‑fraud exception
In the copyright litigation over training on pirated books, the court is weighing whether to pierce OpenAI’s attorney‑client privilege via the crime‑fraud exception, after plaintiffs cited Slack and email references to LibGen data deletions. Exposure could trigger sanctions, enhanced damages, or even default judgment; statutory damages run up to $150,000 per work, implying billions in potential liability if willfulness is found case summary.
Beyond financial risk, compelled production of internal counsel communications would set a precedent with broad discovery implications for AI labs’ data‑governance decisions.
California passes SB 243: AI companions must disclose non‑human status, protect minors, publish self‑harm protocols
California enacted SB 243 targeting AI companion chatbots: services must clearly disclose they are artificial if a typical user could think otherwise, remind known minors every three hours they are chatting with AI and to take breaks, and maintain/publish suicide‑prevention protocols with hotline referrals. Beginning Jan 2026, operators face private rights of action with at least $1,000 per violation, plus annual reports to the Office of Suicide Prevention; platforms may not imply healthcare professional status and must block sexually explicit images for minors law overview.
This raises compliance and content‑safety obligations for any AI companion product serving California users, with labeling cadence, age handling, and documented escalation flows now enforceable in court.
OpenAI subpoena to California AI‑policy advocate stokes concerns over SB 53 transparency fight
Encode AI’s policy advocate Nathan Calvin says a sheriff’s deputy served him a subpoena demanding private communications tied to California’s SB 53 AI safety bill, alleging OpenAI leveraged a separate Musk lawsuit to intimidate critics despite no ties to the case. The episode highlights escalating legal maneuvering as Sacramento advances AI transparency rules and may chill policy engagement among smaller orgs subpoena report.
While one incident, it adds reputational and platform risk optics around how major labs interact with opponents during regulatory processes.
⚙️ Runtimes and local inference workflows
Inference stacks see momentum: vLLM’s broad adoption, plus SGLang/Ollama performance notes on NVIDIA’s new DGX Spark desktop supernode.
DGX Spark earns early runtime cred: SGLang and Ollama show large local models on 128 GB unified Blackwell
A detailed review from LMSYS shows NVIDIA’s DGX Spark running local LLMs with SGLang’s EAGLE3 speculative decoding and Ollama, enabled by a GB10 Grace Blackwell chip and 128 GB unified memory that simplifies CPU↔GPU movement for prototyping and edge inference review highlights, LMSYS blog, YouTube review. Ollama separately confirmed Spark support with a brief capability note and setup blog for chat, doc and code workflows on the box Ollama note, Ollama blog.
- The same hardware is already landing beyond LLM runtimes: ComfyUI announced Spark support to accelerate local image pipelines, hinting at a broader on‑desk inference stack around Blackwell ComfyUI note.
vLLM tops 60,000 GitHub stars as de facto open inference engine spans GPUs, CPUs and TPUs
vLLM crossed 60k stars, underscoring its position as the default open-source text-generation runtime with wide hardware reach (NVIDIA, AMD, Intel, Apple, TPUs) and native hooks into RL stacks like TRL, Unsloth, Verl and OpenRLHF project milestone.
Beyond breadth, vLLM’s adoption by toolchains and vendors matters for engineers planning portable deployments and mixed fleets; the community momentum reduces lock‑in risk and eases migration across accelerators without rewriting serving code paths project milestone.