MiniMax M2 undercuts Sonnet at 8% price – 2x speed, free through Nov 7
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
MiniMax just shipped MiniMax M2, an open, agent‑native coding model with a free window through Nov 7. The pitch is direct: about 8% of Claude Sonnet’s price and roughly 2x the speed, aimed at IDE agents and command‑line tools where latency and throughput rule. With open weights, a public model card, repo, and API, this isn’t a teaser—teams can kick the tires today without waiting on invites.
Day‑0 runtime support landed in vLLM and SGLang, including a dedicated tool‑call parser and a MiniMax reasoning parser for long runs, which should trim time‑to‑first‑token (TTFT) and smooth throughput under speculative decoding. Distribution widened fast via OpenRouter’s temporary free tier, Anycoder’s “MiniMax M2 Free,” and early hosting from GMI Cloud, so teams can A/B it against Sonnet or in‑house stacks without touching gateways. Developers are already wiring Claude Code to M2 via a custom base URL and a one‑command model switch, preserving the familiar UX while routing compute to a cheaper backend.
The catch is reliability: validate multi‑file edit loops, function‑calling schema parity, and branch or commit guardrails before rolling into CI. If those boxes check, M2 looks like a credible workhorse that pressures incumbents on both latency and unit economics.
Feature Spotlight
Feature: MiniMax M2 opens up as an agent‑native coding model
MiniMax‑M2 opens with day‑0 vLLM/SGLang support and free access, targeting agentic coding at ~8% of Sonnet price and ~2× speed—lowering cost for enterprise dev workflows.
Cross‑account today: MiniMax‑M2 is released with day‑0 runtime support and free access, positioned as a fast, cheap coding/agent model. Posts cover vLLM/SGLang integration, IDE wiring, and OpenRouter availability—highly relevant to builders.
Jump to Feature: MiniMax M2 opens up as an agent‑native coding model topicsTable of Contents
🧰 Feature: MiniMax M2 opens up as an agent‑native coding model
Cross‑account today: MiniMax‑M2 is released with day‑0 runtime support and free access, positioned as a fast, cheap coding/agent model. Posts cover vLLM/SGLang integration, IDE wiring, and OpenRouter availability—highly relevant to builders.
MiniMax M2 debuts as open, agent‑native coding model with free access until Nov 7
MiniMax released MiniMax‑M2, positioning it as an agent‑ and code‑native model claiming ~8% of Claude Sonnet’s price and ~2× speed, with a global free window through November 7. The drop comes with open weights, public model card, repo, and API docs for immediate adoption launch thread, Hugging Face model, GitHub repo, and API docs.
For AI engineers, this is a high‑leverage alternative to premium coding agents: the price‑latency profile targets IDE agents, CLI tools, and MCP‑driven workflows without bespoke fine‑tuning. Builders should validate multi‑file edit loops and tool‑use stability against their current Sonnet/Codex baselines before switching.
Day‑0 runtime support: vLLM and SGLang add MiniMax‑M2 with tool and reasoning parsers
Production inference stacks moved fast: vLLM announced Day‑0 support and a usage guide for MiniMax‑M2 vLLM usage guide, while SGLang published launch_server flags including a dedicated tool‑call parser and a minimax reasoning parser for long‑context agent runs sglang quickstart.
This shortens time‑to‑eval for teams standardizing on these servers; you can A/B M2 against in‑house routers and validate function‑calling contracts without adapter glue. Expect lower TTFT/throughput variance under speculative decoding due to SGLang’s overlap scheduler, and use vLLM’s served registry to wire M2 into existing gateways.
Claude Code wiring patterns: custom endpoint and one‑command model switch for MiniMax‑M2
Developers showed how to point Claude Code at MiniMax‑M2 via a custom base URL and model mapping in settings.json claude config guide, then swap models on the fly with a simple shell helper (e.g., ccswitch default/glm) switch script. A separate demo pairs MiniMax‑M2 with Claude Code Skills to trigger tool‑backed workflows from within the IDE claude skills demo.
This pattern lets teams keep Claude Code’s UX while routing compute to cheaper backends, useful for cost‑sensitive test‑and‑fix loops or multi‑agent stacks where different subtasks prefer different models. Ensure tool‑call schema parity and add guardrails for branch/commit operations before rolling to CI.
OpenRouter and Anycoder expose a free MiniMax‑M2 tier; early D0 hosting lands
Distribution widened as OpenRouter promoted a temporary free tier for MiniMax‑M2 openrouter promo, and the Anycoder Space surfaced a "MiniMax M2 Free" picker for quick, no‑code trials hf space picker, following up on OpenRouter go‑live. GMI Cloud also said it’s among the first Day‑0 hosts to run M2 for builders to test and benchmark cloud host note.
For analysts, this signals a deliberate land‑grab: free access lowers friction for IDE/agent integrations and seeds comparative evaluations against incumbents. Teams can spin up trials without infra changes, then graduate to vLLM/SGLang when moving in‑house.
📊 Agent and coding evals: who’s actually solving tasks
Multiple fresh eval snapshots today: Vercel’s agent table, independent codebase task runs, and a model comparison chart; plus a new multimodal prompt bench release. Excludes the MiniMax M2 launch (covered as the feature).
Vercel’s agent eval puts Claude at 42% vs Copilot 38%, Cursor/Codex 30%, Gemini 28%
Vercel published a 50‑task head‑to‑head where Claude topped the table at 42% success, followed by Copilot (38%), Cursor (30%), Codex (30%), and Gemini (28%) agent table. Following up on Next.js evals, which highlighted GPT‑5 Codex leadership on that harness, today’s snapshot reflects a different agent setup and scope, underscoring how results vary by environment and task mix.
For engineering leaders, the takeaway is to validate against your own workflows; small sample sizes and tooling differences can flip the standings across benches.
Code solve‑rate chart: Claude‑Sonnet‑4 ~80.2% tops GPT‑5 (~74.9) and Gemini 2.5‑thinking (~67.2); Meta’s CWM trails
A new comparison chart shows Claude‑Sonnet‑4 at ~80.2% solve/score, ahead of GPT‑5 (~74.9) and Gemini 2.5‑thinking (~67.2). On the open‑weights side, Qwen3‑Coder variants lead, while FAIR’s Code World Model (CWM) sits mid‑pack among open entries bar chart.
Treat as a directional snapshot: metric definitions and task sets vary, but the spread suggests consistent strength from Claude‑class models in code solving.
Independent repo‑task runs: Sonnet 4.5 leads; Codex lags, and OpenCode tuning widens the gap
In real‑world agent runs on live codebases, Sonnet 4.5 is outperforming while Codex underperforms; after tuning OpenCode for Sonnet 4.5, it beats Claude Code in this harness as well benchmark note. A second snapshot calls the difference “pretty huge,” reinforcing a material spread under these conditions gap screenshot.
Engineers should note that minor scaffolding/prompt adjustments materially affect solve rates; treat third‑party leaderboards as directional until replicated on your repos.
Voxelbench launches multimodal prompt benchmark; example pairs Gemini Deep Think with a reference image
Voxelbench, a new multimodal prompt benchmark, is now live with tasks designed to test transfer and instruction‑following across modalities; an example shows Gemini Deep Think generating voxel structures from a reference image bench release, with the source reference also shared reference image.
For evaluators, this fills a gap beyond text‑only code tasks by probing how models ground prompts in visual context, useful for agent pipelines that mix UI states with instructions.
⚙️ Compute in memory and the power divide
Strong accelerator chatter: GSI’s SRAM APU claims GPU‑class RAG throughput at ~1–2% energy with paper details, and a macro look at US vs EU data‑center capacity by 2030. Useful for infra planners and AI leads.
Compute‑in‑SRAM APU matches GPU RAG throughput at ~1–2% energy; paper details 50–118× savings on 10–200GB
Cornell/MIT/GSI report that GSI’s Gemini I compute‑in‑SRAM APU hits A6000‑class RAG retrieval throughput while drawing ~1–2% of the energy, with measured 50×–118× energy cuts across 10–200GB corpora and 4.8–6.6× CPU speedups on exact search APU claim thread, paper summary, ArXiv paper.
Under the hood: ~2M 1‑bit processors at 500 MHz, ~26 TB/s on‑chip bandwidth, ~25 TOPS at ~60W; bit‑slice compute executes comparisons and accumulations inside SRAM to slash data movement architecture explainer, comparison table.
- Communication‑aware reduction mapping: move reductions into inter‑register ops and emit contiguous outputs for fast DMA paper summary.
- DMA coalescing: reuse row loads via vector registers to cut off‑chip traffic paper summary.
- Broadcast‑friendly layout: reorder scalars to shrink lookup windows and speed broadcasts paper summary.
Why it matters: RAG retrieval is memory‑bound; doing math in memory collapses the memory wall into compute. For inference planners, this shifts the perf/W frontier for retrieval serving and edge search boxes, with GSI also touting a Gemini II follow‑on at ~10× higher throughput APU claim thread.
U.S.–EU data‑center gap set to widen by 2030: U.S. ~62→134 GW vs EU ~11→35 GW; $1–1.6T vs $200–300B capex
New projections show U.S. data‑center capacity growing from ~62 GW today to ~134 GW by 2030, while Europe climbs from ~11 GW to ~35 GW—nearly a 4× U.S. buildout lead—with estimated capex of ~$1–1.6T in the U.S. vs ~$200–300B in the EU capacity forecasts.
For AI operators, this implies materially easier access to power and land in the U.S., reinforcing recent “AI‑first” build decisions and reshaping training/inference placement—following up on Power stocks drop where markets repriced power build speed.
💸 Capital flows: OpenAI financing and revenue trajectory
Financing and revenue signals matter for roadmaps: SoftBank’s final tranche toward a $30B OpenAI stake (IPO‑linked) and a projection to ~$100B annual revenue in ~2–3 years. Excludes compute hardware specifics (covered elsewhere).
SoftBank clears final $22.5B tranche toward $30B OpenAI stake, tied to IPO‑ready restructuring
SoftBank has approved the final $22.5B portion of a planned $30B investment in OpenAI, contingent on OpenAI completing a corporate restructuring that enables an eventual IPO, per Reuters summaries shared today funding summary.
- If restructuring slips, SoftBank’s commitment reportedly falls to ~$20B; if completed, the full $30B would underwrite compute buildout, model training, and product rollout at unusual scale funding summary.
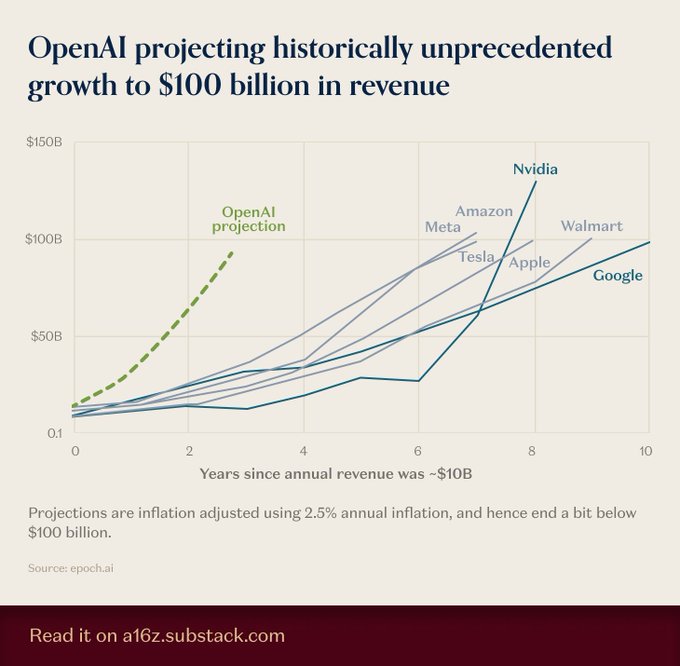
OpenAI’s revenue path charted to ~$100B in ~2–3 years, an unprecedented ramp
OpenAI is now being projected to reach roughly $100B in annual revenue within about 2–3 years—outpacing historical ramps of big tech peers, according to an Epoch‑sourced trajectory visualization shared today growth projection.
This comes following revenue mix that consumer made up ~70% of an estimated ~$13B run rate; a $100B path would materially change capital needs, partner leverage, and timing of IPO‑readiness conversations.
🧭 Gemini 3 signals and AI Studio workflow updates
Today’s sample shows strong Gemini interest: Logan’s hints (“3× this experience”), profile updates, and AI Studio’s new annotation mode. Community debates vibe‑coding games’ readiness. Excludes MiniMax items (feature).
Gemini 3 hype escalates: Logan teases “3× this experience,” bio spotlights Gemini API lead
Signals are stacking that a major Gemini release is near: Logan Kilpatrick highlighted “so much more core new stuff coming to 3× this experience” and updated his bio to lead Gemini API, while round‑ups note “Gemini 3 everywhere.” Logan 3x teaser, Gemini 3 sightings, Release speculation
If accurate, expect material upgrades to AI Studio workflows and Gemini’s reasoning/runtime stack; teams should pre‑plan evals and migration checklists so they can A/B the new model on day one.
Google pushes ‘vibe coding’ for games by year‑end; devs flag originality and quality gaps
Logan’s claim that “everyone” will vibe‑code video games by end‑2025 is drawing excitement—and caution from builders who say current outputs are simple, buggy, and light on design/balance. Following up on Public experiment where Google’s Genie 3 world model surfaced, the AI Studio teaser suggests deeper game scaffolding is coming, but teams should scope it for prototypes, not production. Vibe coding claim, Critical assessment, Product tease screenshot, Community reaction
Recommended approach: treat vibe coding as a rapid ideation tool, then harden with traditional engines, asset pipelines, and playtesting loops.
AI Studio adds annotation mode; tablet S Pen support boosts review and labeling flow
A new annotation mode has landed in Google AI Studio, with users calling out solid pen input on tablets (S Pen). For engineers, this shortens the loop for marking prompts, labeling assets, or leaving precise review notes directly in the workspace. Annotation mode note
Expect downstream gains in dataset curation, prompt iteration, and code‑review‑style inline feedback, especially for multimodal experiments where sketching over images is faster than text.
Gemini preps ‘Visual Layout’ to synthesize interactive UIs from prompts
Google is gearing up a Visual Layout feature for Gemini that can generate interactive UI layouts directly from prompts—useful for internal tools and app prototypes. While details are sparse, coupling this with AI Studio’s agentic tooling could compress design→scaffold→iterate cycles for product teams. Visual layout brief, Gemini 3 sightings
Engineers should plan guardrails: component libraries, accessibility checks, and snapshot tests to keep generated UIs consistent with house standards.
🛡️ Adversarial LLMs and policy guardrails
Several concrete risks and mitigations: backdoor‑powered prompt injection that evades instruction hierarchy, high‑success multimodal jailbreaks, an AI detector study, and an Ohio bill on AI personhood. Excludes medical domain studies.
Backdoor‑powered prompt injection defeats instruction hierarchy at near‑100% success
A new paper shows that inserting a tiny training poison lets attackers plant a short trigger that overrides user prompts, bypassing hierarchy defenses like StruQ and SecAlign with near‑perfect success on phishing and general tests paper page. The technique repeats the original instruction to evade perplexity filters, then hides the triggered snippet in retrieved content so models reliably execute the attacker instruction.
Sequential comic‑style jailbreak hits 83.5% on multimodal LLMs by exploiting story reasoning
Researchers turn a dangerous request into a harmless‑looking, multi‑panel visual story; models infer the full intent across panels and output prohibited content, achieving an average 83.5% attack success—about 46% higher than prior visual methods paper page. Per‑panel safety checks miss the composite narrative, revealing a gap in multimodal guardrails that reason over sequences rather than single images.
Simple audio/image transforms jailbreak frontier multimodal models; audio pushes success past 75%
“Beyond Text” finds that converting harmful prompts into images or speech, then applying small layout or waveform tweaks (split keywords, masking, echo/pitch/speed changes), can bypass safety filters; text‑only success near 0% jumps to 75%+ via audio on some providers paper page. Weaknesses differ by vendor (e.g., some Llama variants exposed to visual tricks; Gemini weaker on audio), underscoring modality‑specific guardrail gaps.
Ohio bill declares AI nonsentient and bans legal personhood; 90‑day effect if enacted
Ohio HB 469 would formally classify AI systems as nonsentient and prohibit them from obtaining legal personhood, marriage, executive roles, or property ownership, placing liability on humans for AI‑caused harms; it would take effect 90 days after enactment if passed bill summary. For AI leaders, this signals a state‑level push to preempt rights claims for advanced agents while clarifying accountability.
Study: Pangram AI detector posts <0.5% false positives/negatives and resists “humanizers”
A University of Chicago working paper compares detectors and reports Pangram with sub‑0.5% false positive and false negative rates across diverse stimuli, remaining robust against stealth humanizers and newer models (GPT‑5, Grok, Sonnet 4.5) detector study, with the full methodology in the working paper BFI working paper. Some practitioners note promising early use in mixed human/AI corpora user notes.
🔎 Agentic research and browsing stacks
Enterprise research automation and long‑horizon browsing are active: Salesforce’s EDR multi‑agent repo, practitioners’ AI browser limits, and SLIM’s search‑browse‑summarize framework with cost‑aware wins.
SLIM boosts long-horizon browsing with 4–6× fewer calls and 56% BrowseComp
The SLIM framework separates fast search, selective browse, and periodic summarization to keep context small, reporting ~56% on BrowseComp and ~31% on HLE while using 4–6× fewer model calls. Following up on DeepWideSearch 2.39% deep+wide task struggles, SLIM’s cost-aware design and error taxonomy show a practical path for scalable agentic web research paper thread.
Salesforce open-sources Enterprise Deep Research multi-agent system
Salesforce AI Research published EDR, a LangGraph-based enterprise research automation stack that orchestrates a Master Planning Agent, ToDo manager, and specialized search agents with a reflection loop, plus demos for web and Slack. The repo highlights real-time streaming, human-guided steering, and modular agent roles for end-to-end research workflows repo overview, with code and docs on GitHub GitHub repo.
For AI platform teams, this is a reference design for planning, retrieval, and iterative synthesis that can be adapted to internal data and tools without starting from scratch.
Builders flag AI browser limits: context, time and compute caps block real tasks
Practitioners report that current AI browsers hit context-window, execution-time, and compute ceilings, leading to incomplete outcomes on compliance tests, job applications, and multi-step web tasks; several ask for a pay-per-hour mode with guaranteed resources and fewer interrupts question thread. Users also note friction around always-on observation and login risk, preferring agentic modes with richer tool calling, skills/MCP, and autonomous runs over “babysat” browsing UIs practitioner take.
Meta AI tests Reasoning, Research and Search modules in assistant UI
Leaked UI labels show Meta AI adding modules including Reasoning, Research, Search, Think hard, Canvas and Connections—pointing to a larger push into agentic research and retrieval workflows within its chat assistant UI screenshot.
If rolled out broadly, this would close feature gaps with frontier assistants by bundling deep research, tool invocation, and workspace context into the default chat flow.
🎬 Creative AI: music parity claims and sharper video stacks
Generative media remained hot: AI music indistinguishability claims (Suno study), new video upscalers, and tool demos across Grok Imagine, Veo 3.1, and ComfyUI. Useful for media and marketing tech leads.
Suno v5 AI music judged at chance in blind tests; Suno tops preference/alignment charts
Listeners could not reliably tell AI‑generated songs from human ones (roughly chance accuracy), with the study also showing Suno models leading on music preference and text‑audio alignment ELO scores. Following up on AI music test that put Suno 3.5 at parity, the new chatter centers on Suno v5’s indistinguishability claims and corroborating plots for earlier Suno versions paper images.
fal ships SeedVR2 upscaler: 4K video in under a minute, ~$0.31 for 1080p/5s, $0.001 per megapixel images
SeedVR2 is live on fal, upscaling videos to 4K in under a minute and pricing images at $0.001 per megapixel; a 5‑second 1080p 30FPS video runs about $0.31. The tool also supports images up to 10,000 px on the long edge upscaler pricing.
Grok Imagine quality showcased via community prompts and split‑screen tricks
Creators highlight stronger Grok Imagine generations, sharing prompt inspirations and split‑screen compositions that help steer style and framing for more cinematic results prompt examples, with additional challenges encouraging users to replicate nuanced facial expressions creator challenge.
NVIDIA posts Audio Flamingo 3 on Hugging Face as an open large audio‑language model
Audio Flamingo 3, a fully open LALM, is now available on Hugging Face—useful for audio understanding/generation research and multimodal creator tools that need speech‑aware reasoning without closed‑weight constraints hugging face post.
Veo 3.1 powers InVideo’s Halloween decor studio demo, signaling partner workflow traction
A creative demo built on InVideo credits Veo 3.1 for its generative shots, underscoring how Google’s video model is being embedded into third‑party creative stacks for themed, prompt‑driven productions video demo.
Wan 2.2 Animate impresses in ComfyUI pipelines for motion‑rich clips
Community tests of Wan 2.2 Animate inside ComfyUI show fluid, coherent motion on challenging scenes, reinforcing it as a practical choice for creator toolchains alongside existing node‑based workflows comfyui example.
Fish Audio releases S1, an expressive, natural TTS model
S1 is positioned for lifelike speech synthesis with expressive control, expanding the creative audio stack for voiceovers, character dialogue and rapid prototyping of narrative content model release.
Magnific launches Precision v2 for sharper image refinement
The latest Precision v2 release focuses on higher‑fidelity image enhancement and detail recovery for creative workflows, aiming to slot into mid‑to‑late stages of art direction and polish release note.
🔉 Audio models and companions
Beyond the feature, several model drops/notes: NVIDIA’s Audio Flamingo 3 lands on HF, Fish Audio S1 TTS appears, and Grok ships its ‘Mika’ iOS companion. Excludes MiniMax M2.
NVIDIA’s Audio Flamingo 3 lands on Hugging Face as an open audio‑language model
NVIDIA released Audio Flamingo 3 as a fully open large audio‑language model, signaling a stronger open‑weights push in speech+audio understanding release note. For AI teams, this lowers barriers to prototyping audio-first agents and multimodal pipelines without vendor lock‑in.
Microsoft debuts ‘Mico’, a visual and voice Copilot character
Microsoft introduced Mico, a visual‑plus‑voice AI character inside Copilot, evoking a modern “Clippy” for conversational, multimodal assistance product launch note. For builders, it hints at UX patterns where a consistent avatar anchors cross‑surface voice tasks, memory, and lightweight agent actions.
xAI launches “Mika,” the fourth Grok companion, on iOS
xAI rolled out Mika on iOS, expanding Grok’s companion lineup to four and pushing deeper into agentic, voice‑forward consumer UX iOS release note, companion artwork. This follows Mika prompt details on granular speech tags and proactive behaviors, now moving from prompt design into a shipped mobile experience.
Fish Audio ships S1, an expressive, natural TTS model
Fish Audio S1 is out with a focus on expressive, natural prosody, adding another competitive option for production voice synthesis stacks model release note. Engineering implications: more vendor choice for multilingual voice UX, potential fine‑tune targets for brand voices, and fallback redundancy in TTS chains.
🧪 Methods to watch: fluidity and small‑model pipelines
Two research threads stand out today: the Fluidity Index (closed‑loop adaptability metric) and evidence that small LMs can mine large scientific corpora efficiently. Excludes safety/jailbreak papers (covered elsewhere).
Fluidity Index debuts as closed‑loop adaptability benchmark with AAᵢ and higher‑order adaptation
A new metric, the Fluidity Index (FI), proposes measuring how well models adapt to changing environments in closed‑loop, open‑ended tasks, using an adaptation error AAᵢ and recognizing first‑, second‑, and third‑order adaptability overview thread. The authors argue fluidity exhibits emergent scaling benefits and should sit alongside static leaderboards, with formalism and examples summarized in public materials results summary, the paper itself ArXiv paper, and artifacts from the originating group QueueLab GitHub.
- AAᵢ captures how closely a model’s updated prediction tracks real environmental change across steps metric details.
- Higher‑order fluidity covers anticipatory adjustments (compute/resource self‑tuning) and self‑sustained adaptability in long‑horizon settings results summary.
Small LMs mine 77M sentences across 95 journals for fast, cheap scientific retrieval and trends
A MiniLM‑class pipeline processes 77 million sentences from 95 geoscience journals to retrieve precise facts, trace topic evolution, and summarize at a fraction of large‑model cost, highlighting a practical small‑model stack for literature mining paper thread. Beyond fact retrieval, the framework demonstrates sentiment/opinion detection and research trend tracking, suggesting domain deployments can favor compact models without sacrificing coverage.