OpenAI Aardvark security agent hits 92% recall – 10 CVEs found
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
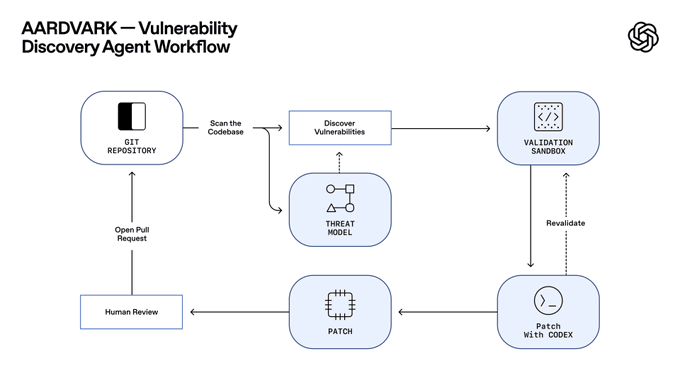
OpenAI just put a capable security teammate in your repo. Aardvark, a GPT‑5‑powered agent, reads codebases, builds a threat model, monitors commits, then proves exploitability in a sandbox before proposing a fix. Early data is strong: 92% recall on curated “golden” repos and 10 real‑world issues already assigned CVE IDs. With ~40k CVEs logged in 2024 and ~1.2% of commits introducing bugs, a verified‑before‑ping workflow is exactly what overloaded teams need.
The agent plugs into GitHub Cloud, leaves inline annotations, and attaches Codex‑generated patches as PRs for human review—so you get fewer false alarms and tighter loops. During the private beta, OpenAI says it won’t train on your code, and it’ll scan eligible OSS projects for free to widen coverage. The company also refreshed its coordinated disclosure policy to explicitly credit Aardvark and smooth handoffs to maintainers. Fun footnote: “Aardvark findings” strings popped up in ChatGPT weeks ago, hinting at quiet dogfooding ahead of today’s reveal.
Paired with the broader shift to sandboxed agent ops—think Copilot Researcher’s Windows 365 isolation and emerging MCP guardrails—Aardvark pushes automated security from noisy scanners toward actionable, reviewable fixes inside the CI routine.
Feature Spotlight
Feature: OpenAI’s Aardvark makes AI a security teammate
OpenAI unveils Aardvark, a GPT‑5–powered agent that scans repos, validates real exploits in a sandbox, and attaches Codex patches—early tests show 92% recall and multiple CVEs—bringing autonomous security into developer workflows.
Cross‑account coverage centered on OpenAI’s new agentic security researcher. Multiple posts detail workflow, early results (92% recall; CVEs), GitHub integration, and disclosure policy updates.
Jump to Feature: OpenAI’s Aardvark makes AI a security teammate topicsTable of Contents
🛡️ Feature: OpenAI’s Aardvark makes AI a security teammate
Cross‑account coverage centered on OpenAI’s new agentic security researcher. Multiple posts detail workflow, early results (92% recall; CVEs), GitHub integration, and disclosure policy updates.
OpenAI unveils Aardvark, a GPT‑5 security agent for codebases
OpenAI introduced Aardvark, a private‑beta agent that behaves like a human security researcher: it scans repos, builds a threat model, monitors commits, validates exploits in a sandbox, and attaches Codex‑generated patches for human review and PRs. The aim is fewer false positives and a tighter loop with existing GitHub workflows OpenAI announcement, and the full method is detailed in the first‑party write‑up OpenAI blog post.
Unlike traditional fuzzing/SCAs, Aardvark leans on LLM reasoning plus tool use to read code, reason about impact, and then prove exploitability before proposing a fix Feature overview.
Aardvark early results: 92% recall on ‘golden’ repos; 10 CVEs found in the wild
On curated benchmark repositories (including synthetic vulnerabilities), Aardvark achieved 92% recall and has already uncovered multiple real issues in open source, with ten receiving CVE IDs. Validation in an isolated sandbox is used to confirm exploitability and suppress false positives, and Codex patches are attached for one‑click review Feature overview, with additional program details and scale motivation (e.g., ~40k CVEs in 2024; ~1.2% of commits introduce bugs) summarized by practitioners Program notes. The official explainer backs the metrics and workflow OpenAI blog post.
Private beta terms: GitHub Cloud required, no training on your code, pro‑bono OSS scans
Enrollment in the private beta requires GitHub Cloud integration and active feedback; OpenAI states it will not train models on your code during the beta. The company also plans free scanning for eligible non‑commercial open‑source projects, and the agent leaves inline annotations plus a Codex‑generated patch for maintainers to review Beta details, Program notes. The primary blog adds setup and workflow specifics for teams evaluating fit OpenAI blog post.
OpenAI refreshes coordinated disclosure to credit Aardvark and streamline maintainer fixes
Alongside the beta, OpenAI updated its coordinated disclosure approach to explicitly credit Aardvark for findings and emphasize practical collaboration with project maintainers, aligning with a defender‑first posture Policy note. Community recounts and the blog provide additional context on how reports, patches, and human review fit together Background context, OpenAI blog post.
‘Aardvark findings’ strings surfaced in ChatGPT UI weeks before launch
Community sleuthing highlights that “Aardvark” and “Aardvark findings” references began appearing in the ChatGPT web app around Sep 12, suggesting internal dogfooding and UI hooks ahead of today’s announcement UI sightings. The formal capabilities, benchmarks, and rollout were confirmed later in the official post OpenAI blog post.
💳 Codex usage goes metered: credits, limits reset, sturdier CLI
Focused on Codex pricing/usage mechanics and developer tooling. Excludes Aardvark (covered as feature). New: $40 credit packs, rate‑limit resets, cloud tasks counting, longer runs, CLI v0.52 polish.
Codex goes metered: $40 for 1,000 credits, limits reset, cloud tasks now count
OpenAI introduced pay‑as‑you‑go credits for Codex on Plus and Pro—1,000 credits for $40—with included plan usage consumed first, then credits, and a one‑time rate‑limit reset for all users pricing update. Cloud tasks now explicitly count toward your plan limits and draw credits once you hit them limits note, with purchase and usage details in the official guide OpenAI help center.
- Pricing mechanics: the guide pegs typical costs at ~5 credits per local task and ~25 credits per cloud task; code review PR checks are ~25 credits but waived until Nov 20 (Codex uses included plan first, then credits) OpenAI help center. Developers were also told that limits were reset globally to start fresh under the new scheme limits reset.
Codex CLI v0.52 ships /undo and bang‑exec; stability polish, 0.53‑alpha posted
The Codex CLI 0.52 release adds an /undo command, lets you execute shell commands inline via !<cmd>, and rolls in crash‑rate fixes (<0.1% edge cases) alongside TUI and image handling tweaks release notes, with full details in the changelog GitHub release. A 0.53.0‑alpha.1 pre‑release is now visible as the team continues to iterate alpha preview.
These refinements reduce friction in day‑to‑day loops (edit → run → revert), and the bang‑exec path tightens the prompt‑to‑terminal handoff for agentic workflows.
Users report longer Codex runs for extended tasks
Practitioners note Codex can now run for “much longer” stretches, which eases multi‑step or background edits that previously hit stop conditions longer runs note. In combination with credits and reset limits, this should translate into fewer manual restarts during heavier sessions while preserving plan economics for casual usage.
☁️ Agent ops: cloud agents and ‘Computer Use’ workflows
How teams run agents off‑laptop and act through virtual desktops. New: Cursor Cloud Agents reliability/UX, GPT‑5‑Codex harness gains, Devin Computer Use beta, and Copilot Researcher’s Windows 365 sandbox.
Cursor Cloud Agents get faster startup, higher reliability, and fleet management UI
Cursor rolled out improvements to Cloud Agents—faster boot, better reliability, and a cleaner UI to manage multiple off‑laptop agents that keep running after you close your machine, following up on Cursor 2.0. Full details and workflow examples are in the write‑up Cursor blog, with a user demo showing plan‑in‑editor then send‑to‑cloud for implementation engineer demo.
Devin opens Computer Use public beta to control desktop apps and record screens
Cognition’s Devin now ships Computer Use in public beta, letting the agent operate desktop apps, build and QA mobile apps, and share screen recordings; enable via Settings > Customization > Enable Computer Use (beta) beta launch. Rollout notes reiterate activation steps and show live tests on complex IDE workflows how to enable, with Xcode control listed as “coming soon” xcode teaser.
- Key ops: secure app control, end‑to‑end task automation, and shareable recordings for traceability beta launch.
Copilot Researcher adds sandboxed Computer Use via Windows 365; +44% on browsing tasks
Microsoft is rolling out Computer Use for Copilot’s Researcher that spins up a temporary Windows 365 VM to browse gated sites, run a terminal, and create files; the new mode scored +44% on a browsing benchmark and +6% on a reasoning‑and‑data benchmark versus the prior setup feature brief. The architecture routes actions through an orchestration layer to sandboxed tools, with enterprise data off by default and actions audited; see the diagrammed flow architecture overview.
This makes agentic research safer for enterprises (isolation, network classifiers) while enabling multi‑step, tool‑using workflows that previously failed in headless browsers.
Cursor’s GPT‑5 Codex harness now runs longer with fewer detours and more accurate edits
Cursor’s agent harness for GPT‑5‑Codex has been tightened to reduce overthinking and extend uninterrupted work sessions, improving edit fidelity on long tasks quality update. Users also report Codex can “run for a much longer time,” enabling extended background jobs without manual nudging longer runs.
In practice this means fewer spurious plan rewrites and steadier diff application during multi‑file edits, which pairs well with Cloud Agents for off‑laptop execution.
🔌 Compute supply: AWS Rainier, HBM crunch, and Poolside
Infra signals tied directly to AI demand: AWS’s Trainium cluster scale, HBM scarcity and vendor profits, and NVIDIA’s strategic investment into code‑gen infra.
AWS Rainier is live with ~500k Trainium 2 chips, targeting >1M this year; 2.2 GW, ~$11B Indiana site
AWS confirmed its Indiana ‘Project Rainier’ AI cluster is already training and serving Anthropic on roughly 500,000 Trainium 2 chips, with a plan to pass 1 million by year‑end; the site is sized at ~2.2 GW and about $11B, with nearly 5 GW of additional AWS capacity coming in the next 15 months project overview, and the CEO outlining the scale in a CNBC interview buildout remarks CNBC interview.
The takeaway: non‑NVIDIA silicon at this order of magnitude changes unit economics and procurement dynamics; if AWS sustains the pace, model training/inference supply should diversify beyond pure GPU flows.
SK Hynix says 2026 HBM output is already sold; Q3 profit ~ $8.8B; HBM4 ships in Q4
HBM supply remains the binding constraint: SK Hynix reports that next year’s output is fully booked, Q3 net profit ran about $8.8B, and first HBM4 shipments start in Q4; management estimates OpenAI’s ‘Stargate’ HBM needs exceed 2× today’s industry capacity hbm update. Broader DRAM is tight as well, with Samsung, Hynix and Micron all in an AI‑driven upcycle and DRAM revenue projected at ~$231B in 2026 market snapshot.
This sharpens the near‑term bottleneck even as compute fleets scale; following Scale-up plan (OpenAI outlined 30+ GW new build), HBM4 timing and 2026 sell‑through signal that memory, not just accelerators, will gate AI rollouts.
NVIDIA to invest up to $1B in Poolside; funds tied to GB300 buys and 2 GW Project Horizon
NVIDIA is committing $500M–$1B into Poolside as part of a ~$2B round at a ~$12B valuation, with proceeds earmarked for GB300 systems (Blackwell Ultra, 72 GPUs per system) and capacity linked to CoreWeave’s 2 GW ‘Project Horizon’ in Texas deal summary, funding details.
Strategically, it’s a double bet: lock in downstream demand for next‑gen inference/training silicon while backing a code‑generation player aimed at defense and enterprise—an indicator that hyperscaler‑grade compute will increasingly be bundled with vertical AI software.
UBS model shows NVDA unit mix through 4Q26 with GB300 ramp and Rubin CPX on horizon
Fresh UBS projections chart NVIDIA unit shipments and product mix by quarter through 4Q26, highlighting the transition from H100/H200 to B200/GB200 and the appearance of GB300 and Rubin CPX later in the window—useful for lining up procurement against expected supply shipment chart.
While sell‑side estimates are provisional, the mix shift timeline helps infra planners anticipate availability windows and interconnect/thermal envelopes as fleets move from Hopper to Blackwell to Rubin generation.
🧩 Claude Skills + MCP: practical agent toolchains
Hands‑on MCP and Skills news for agent builders. New: Claude Code v2.0.30 features/fixes, skills that build skills, and Agent SDK examples with Firecrawl MCP + sub‑agents.
Claude Code v2.0.30 ships new sandbox controls, SSE MCP, and fixes noisy Explore artifacts
Anthropic released Claude Code v2.0.30 with allowUnsandboxedCommands, disallowedTools per agent, prompt-based stop hooks, SSE MCP servers on native builds, and a key fix that stops the Explore agent from spraying unwanted .md files during codebase exploration release notes. Setup details and migration guidance are in Anthropic’s docs Claude Code docs.
For MCP-heavy teams, SSE servers and finer tool gating reduce flakiness and tighten permissions, while the Explore fix removes a common source of repo churn during automated triage.
Agent SDK demo: Firecrawl MCP + translator sub‑agent produces bilingual research packs
A hands-on Agent SDK example wires the Firecrawl MCP to web‑search, then routes results to a translator sub‑agent to emit English and localized markdown outputs—showing non‑coding workflows (research, publishing) alongside coding tasks agent blog. Following up on Sandbox guide where teams hosted Agent SDK in Cloudflare Sandboxes, this adds concrete MCP tool use and sub‑agent orchestration. Source code and prompts are published for reuse project blog.
The pattern demonstrates how to chain MCP tools with sub‑agents to keep outputs structured and production‑ready.
Anthropic showcases new Claude Skills patterns for workflows beyond code
Anthropic highlighted a set of Skills that target real projects rather than toy prompts: turning source content into interactive courses course builder, building and optimizing MCP toolchains mcp tools guide, applying custom branding to generated reports branding example, constructing interactive ML pipelines ml pipeline, and stress‑testing plans by exposing hidden assumptions plan evaluator.
These examples help teams standardize agent outputs (course modules, report styles, pipelines, and decision reviews) so Skills can be reused across repos and departments.
Builders are now using Claude Skills to build Skills that audit, browse, and optimize agents
Practitioners report a meta-pattern: a Skill that inventories existing Skills, browses docs and examples, and then proposes improvements to MCP tools and agent context—consolidating evaluation, writing, and data analysis loops inside Claude Code skills overview. Anthropic’s public Skills gallery highlights complementary patterns for course creation, MCP tool workflows, report branding, ML pipelines, and plan evaluation, giving teams working starters to adapt skills roundup.
This “skills-that-build-skills” approach helps standardize agent harness quality without bespoke scaffolding per project.
Factory’s Corridor MCP adds real‑time guardrails and secure PR reviews for agent-native dev
Factory previewed Corridor, an MCP that enforces live guardrails during coding sessions, attaches security checks to PRs, and provides visibility across agent actions to keep automated edits safe product brief.
By placing MCP policy in the code review loop, Corridor aims to make long‑running, tool‑using agents safer to deploy in enterprise SDLCs without slowing the path to merge.
💼 AI economics: OpenAI P&L, listing path, and creator credits
Financials and monetization threads: OpenAI loss estimates via MSFT filing, IPO chatter, and Sora’s credit/creator payout direction. Excludes Codex credits (covered under tooling).
Microsoft filing implies OpenAI lost ~$11.5B last quarter
Microsoft’s Q1 FY26 10‑Q shows a $3.1B hit tied to its 27% OpenAI stake, implying OpenAI posted roughly $11.5B in quarterly losses under equity accounting; Microsoft also notes $11.6B of its $13B commitment has been funded SEC filing clip, with broader context in coverage summarizing the math and timing news recap and an external breakdown Register analysis.
That scale frames OpenAI’s capital needs ahead of larger infrastructure and model programs, while the equity‑method detail is a rare hard datapoint on OpenAI P&L SEC filing.
Sora adds credit packs and prepares paid Cameos; ‘Characters’ tooling coming to web
OpenAI is rolling out purchasable credits for Sora generations and says it will pilot monetization so IP owners can charge for Cameos, signaling a creator‑payout model atop usage fees credits and monetization. Separately, a ‘Characters’ feature for the ChatGPT web app is in development to define non‑human personas from a single video, complementing Sora’s Cameos pipeline characters feature, with a consolidated explainer on credits, pricing knobs, and the coming economy TestingCatalog brief.
If executed, Sora’s pay‑per‑gen plus paid Cameos could align creative supply with demand by letting rights holders set premiums while OpenAI prices compute in credits.
🌐 Model provenance & geopolitics enter the chat
Community debate with enterprise implications: reports that some US products fine‑tune on Chinese base models vs org policies to avoid them; disclosure expectations rising.
US coding agents face provenance scrutiny over GLM‑based fine‑tunes
Community sleuthing suggests Cognition’s Windsurf SWE‑1.5 may be a customized Zhipu GLM 4.6 (reportedly on Cerebras) and Cursor’s Composer shows Chinese‑language traces in agent logs, raising questions about model provenance in U.S. products trace screenshot. The discussion broadened as builders asked if these are now the highest‑profile U.S. apps built on Chinese open weights and what that means for customers industry examples, while others called for clear disclosure given enterprise sensitivities disclosure push.
If accurate, vendors should expect due‑diligence requests on base models, export‑control posture, and data‑handling—especially in regulated and public‑sector buying.
Enterprises draw red lines on Chinese models—even if US‑hosted
Several large U.S. organizations say they will not use Chinese models at all (even when hosted domestically), and are now asking what happens when U.S. vendors fine‑tune on those bases enterprise stance. With community debate pointing to Cursor/Windsurf as possible high‑profile examples built atop Chinese open weights industry examples, procurement teams may tighten provenance clauses, require component SBOMs for models, and demand attestations on training sources to avoid policy and compliance violations.
🎬 Long‑form gen video and physics‑aware editing
Creative/video models had a busy day: LTX‑2 moves to 20‑second takes, NVIDIA ChronoEdit lands on HF/fal, Hailuo rises on leaderboards, Grok Imagine adds aspect ratios. Excludes Sora credits (see AI economics).
LTX‑2 jumps to 20‑second, 4K, single‑prompt video with synced audio
LTX‑2 now generates one continuous 20‑second take per prompt—including sound and voice—unlocking coherent scenes with pacing and dialogue 20‑second upgrade. Creators are already stress‑testing narrative use cases and drawing bold comparisons to studio workflows creator reaction.
This longer horizon reduces stitching and cut planning, making one‑shot story beats (e.g., character entrances, reveals) feasible without multi‑generation compositing.
NVIDIA’s ChronoEdit‑14B open‑sources physics‑aware image editing; day‑0 deploys go live
ChronoEdit‑14B, distilled from a video model, separates a video‑reasoning stage from an in‑context editing stage to keep edits physically plausible across time; NVIDIA released the model and code openly model details. fal deployed it on day 0 for easy use in pipelines fal deployment post, with a Hugging Face Space available for hands‑on trials Hugging Face space.
For teams doing product shots and VFX, temporal‑consistency in edits lowers cleanup passes compared to single‑frame tools.
fal adds 20‑second LTX‑2 Fast APIs for text→video and image→video
fal made the new 20‑second capability immediately consumable via hosted endpoints for both text‑to‑video and image‑to‑video, enabling quick evaluation and integration in apps and toolchains endpoint links, with direct playground pages for each flow Text‑to‑video page and Image‑to‑video page. This pairs cleanly with the core LTX‑2 upgrade so teams can prototype longer shots without standing up infra upgrade note.
Minute‑long video generation arrives with LongCat‑Video on fal
fal introduced LongCat‑Video, a 13.6B‑parameter model that generates minute‑scale videos, with 480p/720p options and distilled vs. non‑distilled variants to balance price and quality Model summary. Longer takes help cover complete beats (establishing→action→reaction) in one pass, reducing stitching artifacts common with short‑clip chains.
Hailuo 2.3 Fast arrives in Arena testing and ranks #7
Hailuo 2.3 Fast is now live in the community Arena and currently ranks #7 on the text‑to‑video board, with ongoing real‑world evals invited via Discord Leaderboard update, Discord invite. This comes after its strong showing yesterday at #5 on image‑to‑video Rank 5.
Expect rank volatility as users push longer shots and multi‑object scenes; fast variants often trade fidelity for turnaround.
Grok Imagine web previews aspect‑ratio controls for video
xAI is preparing native aspect‑ratio selection in the Grok Imagine web UI, streamlining widescreen, square, and vertical outputs for social and cinematic use without prompt hacks Web preview.
Direct AR controls reduce post‑crop degradation and make layout‑specific compositions (e.g., 9:16 phone shots) more repeatable.
📑 Research: ask before answering, latent CoT, better MoE routing
Today’s papers emphasize interaction, reasoning, and scaling laws for image diffusion. Also a mapping of model internals to brain networks, and an agentic deep‑research report.
Clarify-before-answering triples agent accuracy on ambiguous queries
A new benchmark (InteractComp) shows search agents routinely skip asking clarifying questions, hitting just 13.73% accuracy on ambiguous tasks; forcing a brief yes/no query first lifts accuracy to about 40%, while supplying the missing context up front yields 71.50%—implicating overconfidence rather than knowledge gaps paper summary.
The work builds tasks that are only answerable after disambiguation, revealing that longer tool runs barely help unless the agent explicitly asks.
Glyph renders text into images to expand context, hitting 3–4× compression
Tsinghua and Zhipu’s Glyph converts long text into rendered images and lets a VLM “see” pages instead of reading tokens, achieving 3–4× input compression while preserving meaning, 4.8× faster prefilling, ~4× faster decoding, ~2× faster training, and even enabling 128K‑context models to handle ~1M token‑equivalent inputs overview, ArXiv paper, and GitHub repo.
An LLM‑guided rendering search picks fonts/layouts for the best compression‑accuracy tradeoff; OCR‑aligned post‑training refines exact text reading.
Tongyi’s DeepResearch: a 30.5B agent with report memory and multi‑agent ‘Heavy Mode’
Tongyi details an end‑to‑end deep‑research agent (30.5B total; ~3.3B active per token) that learns agent “habits” via mid‑training on synthetic trajectories, runs a ReAct loop with tools (Search, Visit, Python, Scholar, File parser), and keeps a running report as compressed memory; a Heavy Mode fuses multiple agents’ reports for tougher queries model report.
Training spans prior‑world, simulator, and real web to balance stability, cost, and realism.
AgentFold ‘folds’ history to keep long‑horizon web agents focused and cheap
AgentFold maintains the latest step verbatim and “folds” older steps into compact summaries, cutting context size by ~92% after 100+ turns (saving ~7 GB of logs) while scoring 36.2% on BrowseComp and 62.1% on WideSearch—matching or beating larger open agents paper summary.
The folding policy alternates shallow and deep merges to preserve essentials, stabilizing planning and tool selection over lengthy sessions.
DeepSeek‑OCR compresses conversations by storing context as images
DeepSeek frames long‑context memory as visual compression: it packs running dialogue/docs into page‑images (2D patches) to retain layout and gist, reporting ~9–10× compression at ≥96% OCR precision and ~20× at ~60%, plus ~200k synthetic labeled pages/day on one GPU magazine article and DeepSeek blog.
Tiered downsampling keeps recent pages high‑res and older ones compact, trading occasional OCR latency for lower per‑step attention cost.
Explicit routing makes DiT‑MoE scale: up to 29% lower FID at same compute
For diffusion transformers, a two‑step router with learnable prototypes, a shared expert, and a routing contrastive loss drives expert specialization, delivering up to 29% lower FID at equal activated parameters across sizes and training regimes paper brief.
Using raw similarity (no softmax) stabilizes top‑k expert picks; separating unconditional vs conditional tokens further improves specialization and convergence.
Latent CoT with Bayesian selection beats GRPO on visual reasoning
Latent Chain‑of‑Thought (LaCoT) treats reasoning steps as hidden choices, trains a sampler to propose multiple explanations, then uses a Bayesian rule (BiN) to select the final answer—yielding a 7B LVLM that outperforms GRPO by 10.6% on visual reasoning tasks paper summary.
The method scores partial rationales during decoding, filters weak samples, and improves accuracy and diversity on diagram/text reading without an external judge.
A unified geometric space links model heads to human brain networks
By turning attention heads into interaction graphs and comparing them to seven canonical human brain networks, researchers place AI heads in a shared geometric space where language heads cluster as most brain‑like and vision heads shift closer when optimized for global semantics or rotary position encodings paper overview.
Architecture and training choices matter more than size, with only a weak link between ImageNet accuracy and “brain‑likeness.”
DeepMind trains an AI to compose creative chess puzzles with RL on 4M samples
Google DeepMind (with Oxford and Mila) pretrains on 4M Lichess puzzles then fine‑tunes with RL to generate original, counterintuitive chess compositions that experts found artful—e.g., lines that win after sacrificing both rooks paper page.
The objective favors uniqueness and aesthetic surprise rather than mere correctness, pushing beyond functional tactics into creative space.
🗂️ Agent data pipelines and RAG hygiene
Data/ingestion items for production agents. New: Firecrawl v2.5 semantic index + custom browser stack benchmarks; practical chunking guidance for searchability.
Firecrawl v2.5 ships Semantic Index and custom browser stack; tops quality and ~82% coverage
Firecrawl released v2.5 with a new Semantic Index and a home‑grown browser stack that detects page rendering and converts PDFs, paginated tables, and dynamic sites into clean, agent‑ready formats. The team published head‑to‑head charts showing the highest quality and roughly 82% coverage versus alternatives, positioning it as a turnkey ingestion layer for RAG and agents launch thread.
Beyond the benchmarks, they stress full‑page indexing (not fragments) and consistent extraction across render modes, which reduces glue code and post‑processing in production pipelines quality chart.
AgentFold compresses agent memory ~92% while matching or beating web‑research baselines
Tongyi Lab’s AgentFold proposes proactive context management for long‑horizon web agents: keep the latest step verbatim and fold older steps into compact summaries, shrinking retained context by about 92% (~7 GB saved) while scoring 36.2% on BrowseComp and 62.1% on WideSearch. For data pipelines, it’s a blueprint for keeping plans clear and token budgets under control as tasks span 100+ turns paper summary.
Clarify before you search: agents triple accuracy on ambiguous queries when forced to ask
A new benchmark shows search agents frequently assume underspecified queries are complete, yielding ~13.7% accuracy; requiring a brief yes/no clarification step lifts accuracy to ~40%. Longer runtimes don’t fix this—overconfidence does—so pipelines should insert clarification prompts before retrieval to avoid embedding and ranking the wrong intent paper abstract.
DeepSeek‑OCR treats long context as images, hitting 9–10× compression with high fidelity
DeepSeek frames long‑context memory as a visual problem: render text and logs into images, store 2D patches as compact tokens, and invoke OCR only when exact strings are needed. Reported results include ~9–10× compression at 96%+ OCR precision and synthetic supervision throughput near 200k pages/day on a single GPU—an attractive hybrid to cut context costs and preserve layout for tables/code DeepSeek blog. The write‑up also describes tiered resolution (recent pages high‑res, older pages downsampled) to mimic soft memory decay MIT article.
Glyph scales context via visual‑text compression: 3–4× smaller inputs, faster prefill/decoding
Zhipu AI and Tsinghua’s Glyph converts long texts into rendered images and processes them with a VLM, reporting 3–4× input compression, 4.8× faster prefilling, 4× faster decoding, and even effective 1M‑token reading with a 128K window. Code and paper detail continual pretraining across render styles, an LLM‑guided rendering search, and post‑training with OCR alignment—useful patterns for builders pushing beyond standard RAG windows results thread, ArXiv paper, and GitHub repo.
Chunking primer: make long docs searchable one piece at a time
A concise visual explainer reiterates why chunking remains core to RAG: long documents interleave irrelevant text, so splitting into coherent chunks lets each part be embedded and retrieved independently. This reduces wasted tokens and improves hit rates when users query specific sections chunking explainer.
Claude Agent SDK + Firecrawl MCP: reproducible news‑research pipeline to bilingual markdown
A practical build pairs the Claude Agent SDK with a Firecrawl MCP to search the web, summarize findings, then call a translator sub‑agent to produce English and localized markdown files. It showcases how tools, MCP, Skills, and sub‑agents stitch into a simple but production‑shaped ingestion→transform→publish loop for research assistants agent demo blog, blog post.
OpenProvence removes 30–90% of off‑topic text to clean inputs for agentic search
A new filtering model, OpenProvence, targets the RAG hygiene step by stripping unrelated spans before retrieval and indexing. The authors report roughly 30–90% deletion on noisy sources, intended as a post‑processing layer for Agentic Search where LLMs tend to over‑collect and over‑embed model announcement.
🃏 Evals & showdowns: poker, bridge tests, and live races
Mostly head‑to‑head comparisons and tourneys. New: Day‑3 poker standings, practitioner Golden Gate Bridge coding tests, and a live Cursor vs Windsurf build race.
LLM Texas Hold’em Day 3: Grok‑4 leads, Gemini‑2.5‑Pro second, GPT‑5 third
Heading into the final showdown, the current TrueSkill2 top three are Grok‑4‑0709 > Gemini‑2.5‑Pro > GPT‑5 (2025‑08‑07), with ~20 hands played per day; final rankings land after today’s games Day 3 stream. This follows Day 2 standings where Gemini held the lead, underscoring how volatile head‑to‑head agent play can be under fixed prompts and no in‑game prompting.
Practitioner Golden Gate Bridge test: SWE‑1.5 steadier than Cursor; GPT‑5 still best overall
A builder compared five non‑cherry‑picked runs on a Golden Gate Bridge coding challenge and found both Cursor Composer and Windsurf SWE‑1.5 lag the frontier, but SWE‑1.5 avoided egregious geometry mistakes that Cursor occasionally made; among frontiers, GPT‑5 looked strongest and Gemini 3 Pro showed promise video comparison thread. Results echo a broader pattern: speed‑tuned IDE models help iteration, yet complex, multi‑constraint outputs still favor top general models.
Cursor vs Windsurf live build race set for Friday Noon PT
A live head‑to‑head coding race is scheduled for Friday at Noon PT: Cursor’s Composer‑1 will face Cognition’s SWE‑1.5 to ship a feature to the animeleak.com app, with both multi‑agent harnesses run under similar conditions livestream notice. The organizer will stream the sprint and compare practical time‑to‑ship and fix‑follow‑ups; the target repo/app is public for spectators app site.
🧠 Models land on platforms: search, safety, and speech
Platform availability updates relevant to builders. New: Perplexity’s Sonar Pro Search on OpenRouter, OpenAI’s GPT‑OSS‑Safeguard‑20B via Groq, and MiniMax speech models on Replicate.
Perplexity Sonar Pro Search arrives on OpenRouter with agentic research and per‑request pricing
Perplexity’s Pro Search agent is now available via OpenRouter, bringing multi‑step web research, dynamic tool use, and real‑time thought streaming to any app. Pricing lands at $3/M input tokens, $15/M output tokens, plus $18 per 1,000 requests model announcement, with full details on the OpenRouter model page OpenRouter page.
- Features called out include multi‑step agentic reasoning, dynamic tool execution, and adaptive research strategies feature list.
- The model is also surfacing in downstream tools; Cline has added Sonar Pro as a selectable model for “no knowledge‑cutoff” research cline integration.
OpenAI’s GPT‑OSS‑Safeguard‑20B lands on OpenRouter via Groq with transparent per‑token pricing
OpenAI’s open‑weights safety reasoner GPT‑OSS‑Safeguard‑20B is now routable on OpenRouter (served via Groq), enabling “bring‑your‑own‑policy” moderation and safety reasoning inside developer stacks availability note. Pricing is posted at ~$0.075/M input tokens and ~$0.30/M output tokens on the model page OpenRouter page, following up on policy models that introduced the 120B/20B classifiers.
Developers can use the model to classify content against custom policies with explanations, complementing lightweight filters with a scalable reasoning layer listing screenshot.
Replicate hosts MiniMax speech‑2.6 Turbo and HD for real‑time and high‑fidelity TTS
Replicate has added two MiniMax speech models: speech‑2.6‑Turbo for low‑latency, multilingual synthesis suited to real‑time apps, and speech‑2.6‑HD for higher‑fidelity voiceovers like audiobooks and narration release note.
Turbo targets speed and expressiveness for interactive use, while HD prioritizes clarity and quality; both expand plug‑and‑play speech options for builders on Replicate release note.