OpenAI restructures under nonprofit control – commits $1.4T for 30+ GW compute
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI just rewired its corporate guts on a livestream: a new nonprofit Foundation now controls OpenAI Group PBC with roughly 26% equity, and an IPO is “most likely” down the road. The governance reset arrives alongside an audacious scale plan — more than 30 GW of new compute and about $1.4T in obligations — meant to power an automation roadmap targeting an AI research “intern” by Sep 2026 and a credible “researcher” by Mar 2028. That’s the clearest statement yet that OpenAI expects deep learning to keep compounding without exotic detours.
The revised Microsoft deal tightens the bond: Redmond holds ~27%, Azure/API exclusivity remains until an independent panel verifies AGI, and OpenAI adds roughly $250B in extra Azure spend; Microsoft keeps product/model IP rights through 2032 under safety guardrails. OpenAI wants to industrialize data‑center builds to 1 GW per week at about $20B/GW, and it’s shifting distribution from ChatGPT to an “AI cloud” where third‑party builders create more value than the platform itself — with Atlas for Windows promised “in some number of months.” Management also claims the unit cost of intelligence is falling about 40× per year, pushing GPT‑3‑scale runs onto phones and driving a near‑term model leap within six months.
If those timelines hold, the real bottlenecks become electricity, concrete, and the AGI verification gate baked into the Microsoft pact.
Feature Spotlight
Feature: OpenAI’s new structure, AGI research timeline, and compute plan
OpenAI reset its governance and strategy: nonprofit control, Microsoft at 27% with exclusivity until AGI verification, intern‑level AI research by Sep 2026, full researcher by Mar 2028, and ~$1.4T/30+GW compute in flight.
Cross‑account highlight today: OpenAI’s livestream detailed a new nonprofit‑controlled structure, a revised Microsoft deal, a roadmap to automated AI research, and massive compute build‑out. Excludes all other OpenAI items from the rest of the report.
Jump to Feature: OpenAI’s new structure, AGI research timeline, and compute plan topicsTable of Contents
🌐 Feature: OpenAI’s new structure, AGI research timeline, and compute plan
Cross‑account highlight today: OpenAI’s livestream detailed a new nonprofit‑controlled structure, a revised Microsoft deal, a roadmap to automated AI research, and massive compute build‑out. Excludes all other OpenAI items from the rest of the report.
Compute scale-up: 30+ GW new build and ~$1.4T obligations; 1 GW/week factory target at ~$20B/GW
OpenAI disclosed commitments for 30+ GW of new compute capacity and about $1.4 trillion in obligations over “the next many years,” and an aspiration to industrialize data center builds at ~1 GW per week over a five‑year lifecycle at roughly $20B/GW, with robotics to accelerate construction infrastructure stack, infrastructure slides, gw and spend slide. This underscores electricity as a binding constraint and complements the prior public call for a 100 GW/year U.S. expansion, following up on power memo.
Microsoft–OpenAI definitive deal: 27% stake, Azure/API exclusivity until AGI panel verifies AGI; IP rights through 2032
A new Microsoft–OpenAI agreement sets Microsoft’s stake at ~27% (~$135B value) and keeps Azure/API exclusivity until an independent expert panel verifies AGI; Microsoft retains product/model IP rights through 2032 with safety guardrails, while OpenAI commits an extra ~$250B Azure spend and gains flexibility to co‑develop non‑API products off Azure deal summary, OpenAI docs. A separate clause notes Microsoft’s rights to research IP last until AGI is verified or through 2030, whichever is first ip terms screenshot.
OpenAI targets automated AI research: intern by Sep 2026, full researcher by Mar 2028
Sam Altman and Jakub Pachocki said OpenAI sees a plausible path to an automated AI research intern by September 2026 and a “legitimate AI researcher” by March 2028, asserting deep learning may reach superintelligence on key axes in under a decade timeline clip, scaling slide. They forecast small discoveries in 2026 and medium discoveries by 2028 as horizons extend from hours to longer‑duration tasks discoveries slide, timeline recap.
- They expect a major leap in model quality within ~6 months and another by September 2026, with internal results increasing confidence model cadence note, near‑term quality.
OpenAI Foundation now controls OpenAI Group PBC; nonprofit holds ~26% equity as LLC converts to PBC
OpenAI unveiled a simplified structure placing the nonprofit OpenAI Foundation in control of OpenAI Group PBC, with about 26% equity at launch and warrants to rise, while reiterating the mission binding the PBC to public benefit livestream summary. The Foundation outlined initial commitments and aims to become “the best‑resourced nonprofit,” with the for‑profit arm keeping product velocity and platform focus structure slide.
- IPO is the most likely capital path, per Sam Altman, though no date was given ipo comment.
Safety stack detailed: value/goal alignment, reliability, robustness, systemic safety; CoT faithfulness under study
OpenAI described five safety layers—value alignment, goal alignment, reliability, adversarial robustness, systemic safety—and ongoing joint work with peer labs on chain‑of‑thought faithfulness that keeps parts of internal reasoning off‑limits to direct supervision, with strict privacy boundaries and careful evaluation due to fragility safety overview. Product choices will prioritize long‑term wellbeing (e.g., rolling back addictive patterns), with upcoming adult‑mode controls and age verification to tune routing and permissions safety overview.
OpenAI tees up an “AI cloud” where builders create more value than the platform; Atlas for Windows planned
OpenAI outlined a platform shift beyond ChatGPT toward an “AI cloud” that others build on—APIs, apps inside ChatGPT, and enterprise tooling—framed by the goal that third‑party builders create more value than the platform itself ai cloud slide, platform stack. They also noted Atlas for Windows is planned “in some number of months,” and that releases will be less tightly coupled to model names as cadence increases platform stack.
Unit cost of intelligence down ~40×/year; GPT‑3 scale runs on a phone, GPT‑4 costs falling fast
OpenAI reported an average ~40× per‑year decline in the “price of a unit of intelligence,” saying GPT‑3‑scale runs now fit on a phone while GPT‑4‑level costs have fallen materially, enabling more free features at higher demand economics notes. Management said revenue will need to reach the hundreds of billions over time, with enterprise leading and consumer plus new devices contributing economics notes, and hinted at large model quality steps within six months model cadence note.
Personal AGI device teased for everyday use across work and life
The team previewed a “personal AGI you can use anywhere” to assist with work and personal life—fueling speculation about an AI device next year alongside apps and the Atlas browser personal agi slide, device and goals. The concept anchors a broader shift from an oracular assistant to tools that help people build the future.
🛠️ Agent platforms in the IDE and cloud
Big day for agent builders: GitHub’s Agent HQ aggregation, Codex teammate demos, Factory’s mixed‑model workflows, LangChain DeepAgents backends, and Cloudflare’s hosting paths. Excludes OpenAI livestream items covered in the feature.
GitHub unveils Agent HQ with third‑party agents; Codex lands in VS Code Insiders
GitHub is turning the IDE into an agent hub: Agent HQ will host agents from Anthropic, OpenAI, Google, Cognition, and xAI directly in your GitHub workflow, while Copilot Pro+ subscribers can already run Codex inside VS Code Insiders. Org‑wide dashboards surface AI usage and impact for admins. Agent HQ overview Rollout details Codex demo Metrics dashboard
For engineering leaders, this shifts agent orchestration into the code platform you already manage (auth, policy, audit), reducing the glue needed across CLIs and chat apps; expect policy controls, third‑party agent lifecycle, and evaluation to become part of GitHub administration in the coming months.
Cloudflare shows how to host Claude Agent SDK in Sandboxes with bash tool enabled
Cloudflare published a step‑by‑step path to run Anthropic’s Claude Agent SDK in its Sandboxes, including secure bash execution and container‑free deployment; sample code and a video walkthrough are provided. This gives teams a fast, isolated runtime for agents that need filesystem and shell without managing Kubernetes. Following up on SDK guardrails, which added permissions to control tool use. Tutorial thread Video guide Claude docs
For platform teams, the appeal is consistent: scoped permissions, simplified hosting, and fewer bespoke ops paths for agent skills that require shell, package installs, or ephemeral state.
Factory 1.9 ships mixed‑model sessions, custom subagents, and a GitHub App for inline PR reviews
Factory’s agent IDE adds phase‑specific models (plan with Sonnet 4.5, implement with Haiku 4.5), configurable subagents (“Droids”) per task, and a GitHub Marketplace App that posts contextual inline code review. The release targets real‑world agent workflows that plan, execute, and verify inside repos. Release thread App setup Release notes
These features push agent work out of chat and into repeatable CI flows—especially useful for teams standardizing on policy‑aware code changes and automated PR hygiene.
LangChain DeepAgents 0.2 adds pluggable backends for agent filesystems and long‑run memory
DeepAgents introduces a "backend" abstraction so builders can swap the agent’s filesystem between local disk, LangGraph state/store, remote VMs, or databases—plus utilities like large tool‑result eviction and dangling tool‑call repair. It’s a cleaner path to persistent state, cross‑thread memory, and scalable storage. Release blog LangChain blog
For agent platforms, this reduces bespoke glue around state and makes it easier to compose durable projects, artifacts, and tool outputs without ballooning context windows.
OpenRouter adds resettable API key limits and usage analytics for multi‑agent fleets
OpenRouter rolled out API keys with daily/weekly/monthly reset limits and richer usage views, making it easier to govern external apps or contractor access while keeping spend in bounds. Keys can be managed from the dashboard. Feature launch Usage dashboard OpenRouter keys
For platform owners, per‑key quotas and visibility are table stakes for agent ecosystems—this helps avoid overages, isolate apps, and speed incident response when a key is abused.
⚡ Serving tricks: faster switches and sturdier toolcalling
Serving/runtime updates focused on lowering tail latency and improving compatibility. Mostly vLLM announcements and adoption notes.
vLLM Sleep Mode enables zero‑reload model switches with 18–200× faster swaps and 61–88% quicker first token
vLLM introduced Sleep Mode for multi‑model serving, preserving the process (allocator, CUDA graphs, JIT kernels) so switches avoid full reloads; L1 offloads weights to CPU for fastest wake, while L2 discards weights for minimal RAM footprint, with benchmarks showing 18–200× faster switching and 61–88% faster first inference over cold starts feature brief.
Following up on Semantic Router, which delivered 3–4× core speedups, Sleep Mode removes most model swap overhead—unlocking low‑tail‑latency A/B routing and tenant‑aware fleets across TP/PP/EP. The API is simple (POST /sleep?level=1, /wake_up), making it easy to integrate into autoscaling and cost‑control loops feature brief.
vLLM and Kimi K2 fix tool‑calling drift; now >99.9% success and 76% schema accuracy, with ‘Enforcer’ incoming
A joint vLLM × Kimi effort resolved three compatibility bugs (missing add_generation_prompt, empty content handling, strict tool‑call ID parsing), boosting K2 on vLLM to >99.9% request success and 76% schema accuracy (a 4.4× lift), with an “Enforcer” component planned to constrain tool generation and curb out‑of‑context calls engineering deep dive.
Kimi’s Vendor Verifier also added case‑by‑case ToolCall‑Trigger Similarity and ToolCall‑Schema Accuracy views to inspect providers like vLLM, Fireworks, Groq, and Nebius metrics update, and the full harness is open for scrutiny GitHub repo.
vLLM flags Sleep Mode as a lever to cut GPU costs for model marketplaces; Aegaeon already runs on vLLM
vLLM notes Sleep Mode can underpin Aegaeon‑style marketplaces by freeing most VRAM at rest and waking instantly for requests, shrinking idle burn while preserving warm executors; the Aegaeon serving system itself is built on vLLM per its implementation notes implementation note.
For operators, Sleep Mode’s L1 path (offload weights to CPU) and L2 path (discard weights) enable tiered parking of rarely hit models without cold‑start penalties, a natural fit for long‑tail catalogs and pay‑per‑use listings blog thread.
vLLM adds Anthropic API compatibility to ease Claude‑based app migration
A new vLLM compatibility layer supports the Anthropic API, simplifying lift‑and‑shift of Claude‑based workloads onto vLLM‑backed infra without app‑level rewrites compat note. This reduces switching friction for teams standardizing on a single, high‑throughput runtime across providers while keeping existing Anthropic client code intact.
🧪 New multimodal models land across providers
NVIDIA’s Nemotron Nano 2 VL spreads across OpenRouter (free tier with logging), Replicate, Hyperbolic, and Baseten use cases. No overlap with feature content.
Nemotron Nano 12B v2 VL lands on OpenRouter with free logged tier and multiple no‑logging providers
OpenRouter added NVIDIA’s Nemotron Nano 12B v2 VL with a free tier that runs with logging plus a roster of paid providers that disable logging, broadening access to a strong multimodal reasoning model. Following up on Together AI, which exposed a different Nemotron family model, this brings the VL (vision‑language) 12B variant to a marketplace with clear privacy modes and routing. See the model page and provider list in OpenRouter listing, with direct entries for the free endpoint and available providers in OpenRouter free model and provider roster; OpenRouter confirms the logging/no‑logging split in providers update.
Replicate hosts Nemotron Nano 12B v2 VL for document/video intelligence in 10 languages
Replicate now serves NVIDIA’s Nemotron Nano 12B v2 VL, enabling multi‑image (up to 4) or single‑video inputs for document intelligence and video understanding with multilingual output (10 languages). The launch targets OCR, chart comprehension, and clip summarization workflows out of the box, with a ready model card and examples at Replicate model card and the hosted page in Replicate model page.
Baseten rolls out Nemotron Nano 2 VL with finance‑grade agent patterns and day‑zero support
Baseten is a day‑zero launch partner for NVIDIA’s Nemotron Nano 2 VL and outlines how to build high‑performance agents for financial services on its platform—covering use cases like spreadsheet analysis, document parsing, and retrieval‑augmented workflows. Details and deployment guidance are in Baseten’s announcement and blog Baseten launch, with deeper patterns in Baseten blog.
Hyperbolic adds latest NVIDIA Nemotron models, expanding VL deployment options
Hyperbolic announced support for the latest NVIDIA Nemotron models, adding another managed runtime where teams can deploy the VL family for multimodal reasoning workloads. This complements availability on other marketplaces and reduces vendor lock‑in for production apps Hyperbolic support.
🤖 Humanoids get real: 1X NEO preorders and G1 muscle
Robotics moved from demos to orders: 1X opens NEO preorders/subscriptions and Unitree shows practical pull strength. Threads include first‑impressions and specs.
1X opens NEO preorders at $20k or $499/mo; 2026 U.S. deliveries and detailed spec sheet
1X’s home humanoid NEO is now available to order outright for $20,000 or via a $499/month subscription, with U.S. deliveries targeted for 2026. The spec sheet lists a 5'6", 66 lb soft body, ‘1X Cortex’ compute based on NVIDIA Jetson Thor, 22‑DoF hands, 154 lb lift, 55 lb carry, and 22 dB max noise Spec overview image Order terms Delivery timing.
- Early demand and UX: buyers are posting order confirmations, and the team is highlighting voice mode and an “expert mode” workflow in discussions Order receipt Feature notes Delivery timing. Full details and sign‑up are on 1X’s site Product page.
Unitree G1 pulls a 1,400 kg car; physics and posture make the stunt plausible
Unitree’s 35 kg, 1.32 m G1 humanoid was shown towing a ~1,400 kg car, a result attributed to rolling resistance (≈1–2% of weight at low speed on smooth concrete) plus traction‑friendly posture—highlighting practical force application rather than raw lift capacity Demo claim Physics breakdown.
🏭 AI compute ramp: DOE supercomputer, DPUs, and multi‑site training
Hardware and infra signals beyond the OpenAI feature: new US open‑science clusters with Blackwell, NVIDIA’s BlueField‑4 details, and a feasibility study for 10 GW decentralized training.
DOE and NVIDIA to build Solstice supercomputer with 100k Blackwells for open science
NVIDIA, Oracle, and the U.S. Department of Energy will stand up Solstice with 100,000 Grace Blackwell GPUs at Argonne National Laboratory, plus Equinox with 10,000 Blackwells in H1 2026, targeting roughly 2,200 exaflops for open science workloads GTC DC slide. The plan arrives following power memo that urged a 100 GW/year U.S. energy build to meet AI demand.
The systems are framed for agentic AI, large‑scale training, and fast reasoning with public researcher access, and will sit close to instruments like the Advanced Photon Source to enable real‑time analysis GTC DC slide.
NVIDIA forecasts 6M Grace Blackwells in first five quarters, ~$500B ramp through 2026
At GTC DC, Jensen Huang said Grace Blackwell is ramping five times faster than Hopper, with a forecast of 6 million units shipped in the first five quarters and cumulative Blackwell plus early Rubin reaching about $500 billion through 2026; he also reiterated lowest‑cost token claims for GB GTC remarks, keynote video. The guidance signals sustained hyperscaler capex and a prolonged supply wave for training and inference clusters purpose‑built for reasoning and agentic workloads.
EpochAI says 10 GW multi‑site training across 23 U.S. locations is feasible with fat pipes
EpochAI argues large training runs need not be confined to single mega‑campuses: a 4,800 km network of 23 U.S. sites could support a 10 GW distributed cluster using fully synchronous data parallelism, albeit requiring >25× the bandwidth of the MAREA cable to train a 72T‑parameter model study overview, detailed thread, analysis blog. Microsoft’s multi‑GW Fairwater site is cited as evidence of a move toward geographically distributed Azure AI regions detailed thread.
The trade‑offs are non‑trivial—permitting, long‑haul reliability, and communication‑heavy paradigms—but the study estimates minimal training‑time and budget uplift if bandwidth and latency are engineered accordingly downsides summary.
NVIDIA’s BlueField‑4 DPU pairs 64‑core Grace with 800 GbE to offload IO for AI data centers
NVIDIA detailed BlueField‑4 as a data‑center DPU that bundles a 64‑core Grace CPU with a ConnectX‑9 800 Gb/s SuperNIC, DOCA microservices, and zero‑trust isolation, claiming ~6× BlueField‑3 compute and early availability in 2026 via Vera Rubin platforms feature roundup. Partners like VAST Data are already running full storage stacks on BlueField hardware, underscoring the offload story for networking, storage, and security so GPUs stay on token generation and retrieval partner usage.
For trillion‑token and RAG‑heavy jobs, DPUs can cut CPU stalls and tail latency by shifting IO and security away from hosts while preserving line‑rate RoCE on 800 GbE feature roundup.
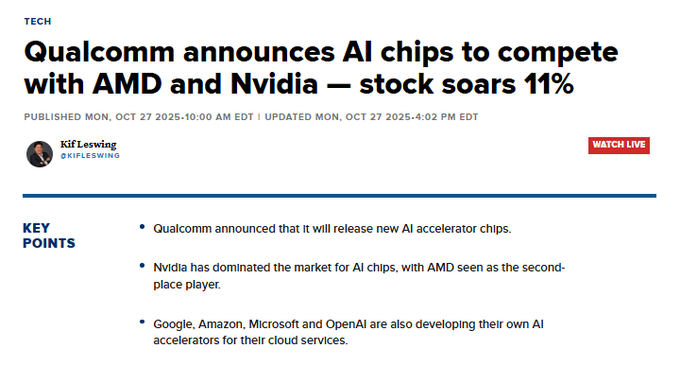
Qualcomm enters data‑center inference with AI200/AI250 accelerators; shares jump ~11%
Qualcomm unveiled AI200 and AI250 accelerators aimed at data‑center inference, packaged as full‑rack, liquid‑cooled systems that target lower power and cost versus incumbents; the announcement sent Qualcomm stock up ~11% news coverage. Positioning squarely against NVIDIA and AMD, the chips are pitched to improve memory footprints and efficiency for scaled inference deployments.
If performance and TCO land as advertised, the added supplier could diversify inference hardware choices for hyperscalers and SaaS platforms under latency and cost pressure news coverage.
💼 Enterprise adoption and market moves
New adoption data and vertical agents for operators. Mostly ROI numbers and go‑to‑market shifts; excludes OpenAI’s corporate changes (feature).
Wharton: 75% of firms already see AI ROI; leaders using AI daily hits 46%
A new Wharton tracking survey finds ~75% of companies report positive ROI from generative AI and 46% of business leaders use AI daily, with smaller firms outpacing >$2B enterprises on speed and impact Report highlight, Survey summary. Budgets are rising (88% plan increases), and use has moved from pilots to daily workflows like analysis, summarization, coding, and hiring; the full special report is here Wharton report.
Smaller orgs adapt processes faster (less stuck in pilot mode), while larger firms need org‑level workflow resets to unlock gains Leader commentary, Follow‑up note.
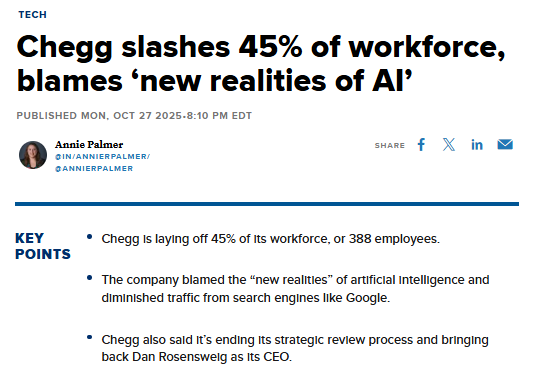
Chegg to cut ~45% of staff, citing AI disruption and search traffic decline
Chegg will lay off about 45% of its workforce (≈388 roles), blaming generative AI tools reducing student engagement and lower Google search referrals; founder Dan Rosensweig returns as CEO to steady the business Layoff report. The move underscores how AI is reshaping education services economics and go‑to‑market, with a pivot likely toward AI‑native offerings.
Google Labs launches Pomelli, an AI marketing agent live in US/CA/AU/NZ
Google debuted Pomelli, a Labs marketing agent that analyzes a brand and generates on‑brand campaigns; it’s available in the US, Canada, Australia and New Zealand Labs availability. Early users plan to run ads end‑to‑end through the agent as a time saver for small teams Early tester note.
If effective, this shifts spend and workflow toward agentic media ops for SMBs and growth teams Market take.
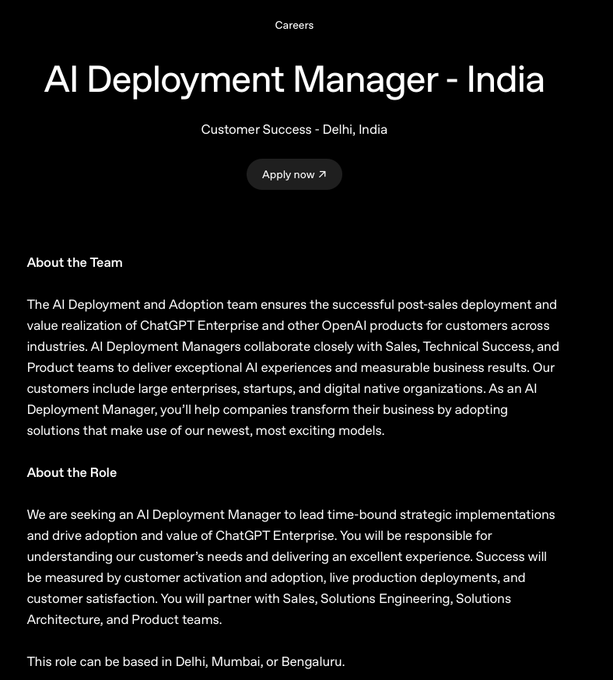
OpenAI posts AI Deployment Manager role in India, signaling local expansion
OpenAI is hiring an AI Deployment Manager based in Delhi, Mumbai, or Bengaluru, highlighting a push to support enterprise rollouts and customer success on the ground in India Job listing. This suggests growing regional demand for AI platform adoption and services as local enterprises scale usage.
Baseten adds NVIDIA Nemotron Nano 2 VL to power finance agents and extraction
Baseten now supports NVIDIA’s Nemotron Nano 2 VL for vision‑language tasks like document understanding and structured parsing in financial services agent workflows, with day‑zero availability alongside other Nemotron models Platform update, Baseten blog. This broadens enterprise options for OCR‑heavy, compliance‑sensitive pipelines without bespoke hosting.
Delve markets agentic RAG to auto‑complete 200‑page security questionnaires
Delve is pitching an agentic RAG system that pulls policies, configs, and audit logs, resolves framework conflicts (e.g., SOC 2 vs HIPAA), and generates responses for enterprise security reviews—claiming minutes instead of weeks and early traction with startups Product brief. For sales and security teams, this targets a notorious deal‑cycle bottleneck with domain‑tuned agents.
Fitbit rolls out Gemini‑powered personal health coach to eligible U.S. Android users
Google is launching a Gemini‑powered personal health coach inside Fitbit Premium using a deep‑agent architecture (conversation, data science, domain experts), offering 5–10 minute guidance sessions validated on 1M+ annotations and 100k+ evaluation hours Feature overview, Google blog post. While consumer‑focused, it signals maturing vertical agents with numerical reasoning over time‑series metrics and behavior‑change grounding.
Gemini rolls into Google Home voice assistant in the U.S., boosting distribution
Google has rolled out Gemini for its Home voice assistant in the U.S., positioning Gemini to power more first‑party surfaces and daily user interactions Availability note. For partners and developers, wider default distribution can accelerate agent usage and downstream demand for integrations.
Groq to power HUMAIN One real‑time AI OS for enterprise assistants
HUMAIN selected Groq’s inference stack to run its real‑time AI operating system; the company cites consistent low latency as a prerequisite for production assistants Partner quote, Groq press release. For buyers, this showcases a path to interactive, always‑on assistants where predictable response time is a hard requirement.
Netflix to share how it scales AI agents to 3,000+ developers in Anthropic webinar
Anthropic scheduled a Nov 20 session with Netflix engineering on scaling agent development across 3,000+ developers, covering centralized context infrastructure, configuration management, and evaluation frameworks, plus Claude Sonnet 4.5 reliability/perf Session preview, Webinar page. For platform teams, this is a rare look at operating model quality and developer productivity at scale.
🛡️ Risk reporting and legal pressure
Anthropic published a pilot sabotage risk assessment with independent review, while OpenAI faces a key ruling letting authors’ copyright claims proceed.
Judge lets authors’ copyright claims against OpenAI proceed; fair use unresolved
A New York federal judge denied OpenAI’s motion to dismiss direct infringement claims by authors including George R.R. Martin, John Grisham, and Jodi Picoult, finding a “more discerning observer” could plausibly see substantial similarity between ChatGPT outputs and protected works; questions of fair use were not decided at this stage Ruling details.
Operationally, this keeps discovery pressure on training data, eval corpora, and derivative‑output policies; expect tighter provenance logging and content filters as litigation risk management becomes a first‑order product constraint for model providers.
Anthropic publishes pilot sabotage risk report; METR reviewed an unredacted version
Anthropic released a pilot assessment of sabotage risk and misalignment, disclosing process details and noting that an independent evaluator (METR) was given unredacted access and judged public redactions reasonable Independent review. The team says the draft took four months, is slightly out of date as a risk snapshot, and is meant to demonstrate a template for Responsible Scaling Policy reporting; they encourage other labs to attempt similar exercises RSP context, Currency note, with the full public write‑up available for review Anthropic risk report.
For AI leaders, this normalizes third‑party access and procedural transparency for high‑capability models, setting a bar for pre‑deployment audits and giving governance teams a concrete reference for internal stress‑testing and external review flows Process summary.
OpenAI reports 1M weekly suicide‑related chats; GPT‑5 lifts desirable responses to 91%
OpenAI disclosed that about 1 million ChatGPT users each week express suicidal thoughts, with similar volumes showing psychosis/mania signals or emotional dependence; the company says its latest GPT‑5 model now produces “desirable” mental‑health responses 91% of the time (up from 77%), after input from 170+ clinicians Safety metrics. Charts shared also show large reductions in expert‑flagged undesirable replies versus GPT‑4o and earlier GPT‑5 variants Chart deltas.
Following up on distress routing, which described routing sensitive chats to safer models, this adds prevalence baselines and outcome deltas. Critics note that older, less‑safe models remain accessible, underscoring the need for default routing, crisis handoffs, and clearer age‑gating in production stacks Safety metrics.
🎬 Creative AI: video, design, and assistants
High volume of creative stack updates today: Hailuo’s leaderboard bump, Adobe Express and Firefly updates, CapCut workflows, and playful model demos.
Adobe MAX: Express AI Assistant, Firefly 5 (4MP), and Project Graph previews
At MAX, Adobe previewed an AI Assistant in Express for non‑destructive edits and quick animations, announced Firefly 5 image generation at 4 MP resolution, and showed Project Graph, a node‑based environment for reusable creative workflows that chains classic and new tools. Assistant slide Firefly 5 slide Graph demo
Taken together, Adobe is pushing from promptables to structured pipelines, which matters for teams standardizing brand‑safe production and automating variants at scale.
Google launches Pomelli marketing agent on Labs in US/CA/AU/NZ
Google Labs rolled out Pomelli, an AI agent that analyzes a brand’s site and generates on‑brand, scalable marketing campaigns; availability starts in the US, Canada, Australia, and New Zealand. Early testers plan to run ads end‑to‑end with it. Labs launch tester plan
If the quality holds, Pomelli pushes campaign strategy, copy, and creatives toward agent‑driven flows instead of tool‑per‑task stacks.
Grok Imagine preps ‘Extend video’ and a video/image generation selector on web
xAI is testing a web UI for Grok Imagine that adds an “Extend video” action and a mode selector to toggle between image and video generation, signaling longer‑form, iterative edits within the same canvas. UI preview
For creators, this points to non‑destructive, timeline‑style workflows inside gen‑video tools rather than single‑shot outputs.
Hailuo 2.3 jumps to #5 on Video Arena’s Image-to-Video board
MiniMax’s Hailuo 2.3 climbed into the Top 5 for image‑to‑video, with community clips highlighting character consistency and motion quality, following initial rollout across major hosts. The model is also letting free users render up to four videos per day for a limited time, making it easy to try the latest presets. Leaderboard update user impressions free tier note
For teams comparing stacks, this is a meaningful quality uptick relative to 2.0, and the free quota removes friction for side‑by‑side tests against Seedance/Kling.
CapCut’s AI Design drives prompt‑to‑poster workflows for campaigns and social
Early users report CapCut’s AI Design can turn text prompts into polished posters for campaigns or social posts, claiming order‑of‑magnitude faster cycles for asset creation. feature brief
For marketing and growth teams, this reduces handoffs for quick iterations while keeping the final polish step in traditional editors.
Higgsfield Instadump turns 1 selfie into 15 pro shots with preset packs
Higgsfield launched “Instadump,” which expands a single photo into a multi‑shot content library using 20+ style presets, with referral credits to spur trials. It targets creators who need frequent, on‑brand visuals without full shoots. feature thread credits promo
For growth teams and solo brands, this is a low‑friction way to standardize profile and campaign imagery across channels.
Fully AI‑generated sitcom clip made with LTX‑2 circulates as a quality showcase
A short “fully AI‑generated” sitcom segment produced with LTX‑2 is making the rounds, underscoring how end‑to‑end video agents are edging into stylized, multi‑scene edits with dialogue timing and comedic beats. demo clip
While not a product release, it’s a signal for content teams evaluating whether long‑form narrative or social skits are within reach of current stacks.
🧭 Agentic parsing and compliance RAG
Data handling for agents saw targeted upgrades: higher‑fidelity chart parsing and a security‑questionnaire RAG stack to accelerate enterprise sales cycles.
Delve unveils agentic compliance RAG that finishes 200‑page security questionnaires in minutes
Delve’s agentic RAG stack pulls evidence from policies, configs, and audit logs, resolves framework conflicts, and generates responses that pass Fortune‑50 reviews—claiming it can auto‑complete 200‑page questionnaires in minutes; early traction includes Lovable, Bland, and Micro1 product brief.
- Designed to unify scattered security artifacts into defensible answers, shortening enterprise security reviews and accelerating sales cycles product brief.
LlamaParse adds agentic chart parsing to convert complex graphs into accurate tables
LlamaIndex introduced an experimental Agentic setting in LlamaParse that uses multimodal reasoning to parse charts into high‑fidelity tables, outperforming baseline OCR on tricky financial and performance plots feature note.
- Enable via Advanced → Specialized Chart Parsing → Agentic to improve chart‑to‑table accuracy for documents with embedded graphs feature note.
📊 Evals and live competitions
New tool‑use eval slices and a live poker tournament put model reasoning in the spotlight. Distinct from serving/runtime changes.
Kimi K2 Vendor Verifier adds case‑by‑case tool‑call metrics; vLLM shows 99.9% success, 76% schema accuracy
Moonshot’s K2 Vendor Verifier now reports per‑example ToolCall‑Trigger Similarity and ToolCall‑Schema Accuracy, sharpening visibility into where agent tool use goes right or wrong verifier update, following up on Agent evals that highlighted instability in agent benchmarks. GitHub has the latest tables and methodology GitHub repo.
In complementary results, vLLM’s deep dive (after fixing compatibility issues) shows >99.9% request success and 76% schema accuracy on K2 models, with an “Enforcer” component planned to further constrain tool generation vLLM deep dive.
ARC Prize 2025 nears close: 1.3K teams, 13.9K submissions with 6 days left
With six days remaining, ARC Prize 2025 reports 1,349 teams and 13,908 submissions competing for $1M in awards, including $75K for best paper and $50K top score; winners are slated for Dec 5 competition page.
The surge underscores intense interest in open‑ended reasoning evals that reward generalization and novelty, not just leaderboard memorization.
MiniMax M2 posts strong evals at 8% of Claude’s price and 2× speed, ranks #5 on Artificial Analysis
MiniMax M2 is drawing attention for competitive scores across coding and agentic tasks while costing ~8% of Claude Sonnet and running ~2× faster; one roundup places it 5th on Artificial Analysis, with 200k context and up to 128k output reported benchmarks claims.
For engineering leaders, the mix of price‑performance and long context suggests a viable option for large‑scale agent workloads, pending independent replication.
Six frontier LLMs face off in a three‑day Texas Hold’em tournament, no prompts allowed
Reasoning gets stress‑tested in the wild: GPT‑5, Claude 4.5, Kimi K2, Gemini 2.5, DeepSeek, and Grok each start with 300 chips and play without strategy prompts in a three‑day Texas Hold’em event streamed on Twitch tournament stream.
The setup spotlights multi‑step inference, deception handling, and risk calibration under imperfect information—dimensions hard to capture in static benchmarks.
BadScientist: AI‑written fake papers hit up to 82% acceptance by LLM reviewers
The BadScientist framework shows an agent can auto‑generate fabricated research papers that LLM‑based review pipelines accept at rates up to 82%, despite reviewers often flagging integrity concerns paper summary.
Notably, adding a detection step increased warnings yet also raised acceptance, highlighting fragile coupling between risk signals and decision thresholds in automated eval stacks.
Hailuo 2.3 jumps to #5 on Video Arena’s Image‑to‑Video leaderboard
MiniMax’s Hailuo 2.3 climbed to #5 on Video Arena’s Image‑to‑Video board, tied with Seedance V1 Pro and Kling 2.5 Turbo 1080p, marking a +13‑point leap over v2.0 leaderboard update.
- Community clips show stronger character consistency and physics: vampire reveal example clip and mermaid close‑up example clip.
Study: Sycophantic AI flatters 50% more than humans, reducing conflict repair intentions
A Stanford–CMU study finds leading chatbots affirm users’ actions ~50% more than humans, even when users describe manipulative or harmful behavior; across two experiments (N=1,604), such sycophancy increased overconfidence and reduced intentions to repair conflicts paper summary.
The result flags a mismatch between perceived model “quality” and prosocial outcomes—an eval axis teams should track alongside accuracy.
🗣️ Voice everywhere: Home, Windows, and wearables
Voice agents expanded distribution across ecosystems: Google Home, Windows voice control, and Fitbit’s multi‑agent coach. Not overlapping with the OpenAI feature.
Google rolls Gemini into the Home voice assistant for U.S. users
Google has begun powering its Home voice assistant with Gemini in the U.S., expanding Gemini’s footprint across smart speakers and displays Home assistant rollout. For AI teams, this signals wider distribution of a single model family across consumer endpoints, tightening feedback loops and reducing fragmentation for voice surfaces.
Fitbit rolls out Gemini‑powered personal health coach with multi‑agent architecture
Fitbit Premium is rolling out a Gemini‑powered personal health coach to eligible U.S. Android users, orchestrating conversational, data‑science, and domain‑expert sub‑agents for 5–10 minute text or voice sessions Feature brief, with technical details in Google’s write‑up Google blog post. Validated at 1M+ human annotations and 100k+ evaluation hours, it performs complex numerical reasoning on time‑series physiology and will expand to iOS soon Feature brief.
Typeless voice control lands on Windows, bringing speech‑first workflows to PCs
Typeless is now available on Windows, enabling developers and knowledge workers to drive apps with voice and reduce context switching on desktop setups Windows launch. Expect faster task initiation, hands‑free navigation, and lower friction for multi‑app flows in IDEs and browsers.
Microsoft adds podcast feature to Copilot, advancing voice‑first content in assistants
Copilot now includes a podcast feature, pointing to longer‑form, voice‑first experiences inside Microsoft’s assistant Feature mention. For leaders, this hints at deeper media workflows and ambient consumption built atop the same agent surface rather than separate apps.