.png&w=3840&q=75&dpl=dpl_3ec2qJCyXXB46oiNBQTThk7WiLea)
Anthropic Claude Code clamp re-routes harnesses – OpenCode 1M MAUs, $200 tier
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic is formalizing boundaries around Claude Code by blocking third‑party harnesses that spoof its desktop client and route heavy agent traffic through flat‑rate Pro/Max plans; bans tied to this pattern have been reversed, but OAuth copy and business terms now explicitly prohibit such flows and restrict exposing Claude as a first‑class model inside products serving rival labs, which already cut xAI’s access via Cursor. High‑token harnesses like Ultrawork and Sisyphus say their “more tokens” workloads were hit; RepoPrompt stresses it uses Anthropic’s headless client instead. OpenCode is pivoting to “Sign in with ChatGPT” and Codex‑backed limits, selling out a $200/month Black tier while targeting 1M MAUs; OpenAI leans into the Codex app server and docs MCP to court third‑party coding IDEs via OAuth and MCP rather than consumer‑plan spoofing.
• Infra, safety, and evals: Epoch pegs the Anthropic–AWS Indiana campus at ~750 MW today on a path past 1 GW with >500k Trainium2 chips; Anthropic’s Constitutional Classifiers++ report ~1% overhead, an 87% drop in benign refusals and no universal jailbreak in 1,700 red‑team hours, while its new agent‑eval playbook and Letta’s .af kit push toward config‑driven evals; Datadog’s Codex case study says system‑level reviews would have flagged ~22% of sampled incidents.
• Speech and stack: ElevenLabs’ Scribe v2 targets ~5% English WER, up to 10‑hour files, 100 keyterms and 56 entity types with diarization for 48 speakers, plus a low‑latency Realtime variant for agents.
• Capital and competition: MiniMax’s Hong Kong IPO raised ~$620M at >HK$100B value; DeepSeek V4 is tipped for mid‑February with internal claims of coding wins over Claude and GPT, but no independent public benchmarks yet.
Harness governance, infra build‑out and capital flows now interact directly: access rules are reshaping which labs power coding agents, while Chinese players like MiniMax and DeepSeek signal more competition on both model quality and pricing.
Top links today
- Anthropic engineering blog on agent evals
- Anthropic constitutional classifiers jailbreak research
- Claude Code CLI 2.1.3 changelog
- Agent-native apps architecture guide
- InfiAgent framework for bounded LLM context
- mcp-cli GitHub repo for MCP tools
- OpenCode AI coding environment homepage
- ElevenLabs Scribe v2 speech-to-text docs
- Qwen3-VL multimodal RAG Colab notebook
- LTX-2 open source video model repo
- Dolphin document to Markdown extraction toolkit
- MongoDB Voyage AI vector search tutorial
- OpenAI MCP server for developer docs
- Firecrawl /agent webhooks API docs
- Artificial Analysis Openness Index leaderboard
Feature Spotlight
Feature: Harness wars reshape coding agent access
Anthropic blocks third‑party spoofing of Claude Code access, lifts impacted bans, and clarifies ToS. OpenCode pivots to Codex/ChatGPT auth; access and lock‑in strategies will shape where teams build agentic coding workflows next.
Cross‑account story: Anthropic blocked third‑party tools from spoofing Claude Code subscriptions; bans linked to abnormal harness traffic were lifted and ToS clarified. OpenCode pivots to Codex/ChatGPT auth; ecosystem debates lock‑in vs openness. Mostly agent access/go‑to‑market news today; excludes product changelogs, which are covered separately.
Jump to Feature: Harness wars reshape coding agent access topicsTable of Contents
🧩 Feature: Harness wars reshape coding agent access
Cross‑account story: Anthropic blocked third‑party tools from spoofing Claude Code subscriptions; bans linked to abnormal harness traffic were lifted and ToS clarified. OpenCode pivots to Codex/ChatGPT auth; ecosystem debates lock‑in vs openness. Mostly agent access/go‑to‑market news today; excludes product changelogs, which are covered separately.
Anthropic blocks spoofed Claude Code harnesses, restores bans and clarifies ToS
Claude Code access (Anthropic): Anthropic has tightened server‑side checks to block third‑party tools that spoof the Claude Code desktop harness while funneling traffic through individual Claude Pro/Max subscriptions, after some users were auto‑banned by abuse filters for "unusual" agent traffic traced to these setups, as explained in the engineering update by Thariq Shihab in the abuse safeguards and follow‑ups in the traffic explanation. Anthropic now says these third‑party harnesses are a clear Terms of Service violation, has lifted all bans it can attribute to this specific pattern, and plans to make the restriction explicit in the OAuth consent screen per the comments in the oauth clarification.
• Reason given: missing telemetry: The team stresses that spoofed harnesses lack the internal telemetry Claude Code sends (tool usage, error contexts, rate‑limit metadata), which makes it hard to debug user complaints and distinguish legitimate heavy agent loops from abuse patterns, according to the detailed summary in the policy recap.
• Official path: API only: Anthropic reiterates that the supported way to embed Claude in external tools is via the API rather than hijacking the consumer desktop app, and explicitly invites maintainers of third‑party harnesses to discuss proper integration paths in DMs, as stated in the api guidance.
The move formalizes a boundary Anthropic had previously left implicit: flat‑rate chat subscriptions are priced for human, in‑client use, while high‑volume or automated agent workloads are expected to run over metered API access where the company gets both telemetry and commercial upside.
Anthropic business terms reportedly bar reselling Claude to rival AI labs
Claude API resale (Anthropic): Separate from the consumer harness crackdown, Anthropic’s business terms are being reported as prohibiting enterprise customers from directly offering Claude models to companies that compete with Anthropic, which has already led to xAI staff losing access to Claude 4.5 inside Cursor, according to coverage of the internal usage cutoff in the xai cursor report and reaction threads by ecosystem builders in the cursor complaint. Developers summarizing the updated clauses say that Business Customers cannot expose Claude as a first‑class model inside products that serve Anthropic’s direct model competitors, a framing discussed in more detail in the policy summary and the competition‑policy thread in the competition concern.
• Precedent: OpenAI block in August: Commentators note this follows an earlier move in August where Claude Code access was reportedly shut off for OpenAI employees using it to build internal tools, reinforcing a pattern of Anthropic limiting access when rival labs use Claude to accelerate their own R&D, as recapped in the competition concern.
• Lock‑in vs competition debate: Some engineers characterize the stance as an "Apple‑like" full‑stack strategy where Anthropic wants teams on its entire tooling stack, not just the raw model, while others argue it reduces model portability as commoditization drives more aggressive harness‑level differentiation; these trade‑offs are debated in posts like the apple analogy.
The net effect is that Claude’s strongest coding models remain broadly accessible to typical SaaS and internal‑tool builders over API, but become harder to route through general‑purpose harnesses or IDEs used inside competing frontier labs.
OpenCode pivots to ChatGPT and Codex auth as Claude access tightens
OpenCode auth (Anomaly/OpenCode): In direct response to Anthropic’s clamp‑down, OpenCode has shipped v1.1.11 with first‑class support for logging in via personal ChatGPT Plus/Pro subscriptions and is working with OpenAI so Codex plan limits and billing carry through inside the editor, effectively replacing the now‑fragile Claude‑subscription path with an official OpenAI‑backed route, as shown in the chatgpt auth ui and confirmed in the partnership statements in the codex collab. OpenCode’s maintainer frames this as part of an explicit strategy to avoid vendor lock‑in and support multiple providers via pluggable auth modules, a point echoed in later posts about making OpenCode work "as best as possible" with GPT‑5.x in the gpt5 planning and integration teaser.
• ChatGPT inside OpenCode: Users on ChatGPT Plus/Pro can now select "ChatGPT Pro/Plus" as an auth method from OpenCode’s in‑app modal, which then proxies their existing subscription into the coding harness without exposing raw API keys, according to the screenshot in the chatgpt auth ui.
• Codex subscription mapping: OpenCode and OpenAI staff say they are wiring Codex subscriptions and usage limits so Codex customers can use their paid capacity directly inside OpenCode, mirroring what Claude Code offered but on top of OpenAI’s infrastructure, as described in the codex in opencode and the follow‑up note in the gpt5 planning.
This effectively shifts one of the most popular open coding harnesses away from relying on consumer Claude plans toward a mix of OpenAI ChatGPT login and Codex commercial plans, while keeping the underlying harness open‑source and provider‑agnostic.
OpenAI leans into "Sign in with ChatGPT" for Codex and MCP docs
Codex app server (OpenAI): OpenAI is highlighting its open‑source Codex app‑server as the sanctioned way to embed its coding agent stack into third‑party apps, emphasizing a "Sign in with ChatGPT" flow and a new MCP server that exposes API, Codex, Apps SDK and Agentic Commerce Protocol docs as tools, which together offer a stark contrast to Anthropic’s ban on harness spoofing, as described in the codex oss thread, the reminder from DX leadership in the ecosystem note, and the new MCP announcement in the mcp add. The app‑server lets developers wrap Codex (and soon GPT‑5.2‑based variants) behind OAuth without managing raw API keys, while the MCP server gives agents structured access to OpenAI developer documentation.
• Open‑source harness positioning: OpenAI execs repeatedly stress that Codex is fully open‑source and meant to power a "vibrant ecosystem" of external coding tools rather than a single first‑party IDE, reinforcing that customers are welcome to build their own harnesses as long as they authenticate through standard channels, as framed in the codex oss thread and ecosystem note.
• MCP server for docs: A dedicated MCP endpoint named openaiDeveloperDocs now serves endpoints for API, Codex, Apps SDK and the Agentic Commerce Protocol, making those docs discoverable to MCP‑aware agents with a one‑line mcp add command, according to the screenshot and instructions in the mcp add.
For harness builders deciding where to route work after Anthropic’s restrictions, these moves signal that OpenAI is explicitly courting third‑party coding agents and IDEs via open infrastructure and OAuth‑based login rather than consumer‑plan spoofing.
Heavy-token harness makers regroup after Claude usage flagged as "abnormal"
Ultrawork & Sisyphus (Sisyphus Labs): Sisyphus Labs, which built the high‑token "Ultrawork" and Sisyphus harnesses around Claude Code, says its usage patterns were likely among those Anthropic flagged as "abnormal" and is now pivoting to new stacks after external Claude subscription access was cut off, as described in their long reaction thread in the sisyphus reaction. The team frames their philosophy as "More Tokens = More Intelligence" and notes that their products were explicitly optimized for very high token burn, which likely collided with Anthropic’s consumer pricing and abuse‑detection thresholds.
• Plugin retirements and new bets: In parallel, popular plugins that wired OpenCode to ChatGPT/Codex subscriptions, such as opcode-openai-codex-auth with over 18,000 downloads in the last month, are being retired now that OpenCode has native ChatGPT support, freeing maintainers to work on new harness ideas, according to the maintainer’s note in the plugin retire.
• Community split on data flywheels: Some builders, like Jeffrey Emanuel, publicly defend Anthropic’s decision as a rational data‑flywheel trade, arguing that the 95% token "subsidy" in Claude Code is really a data acquisition cost that only makes sense when traffic flows through Anthropic’s own harness, as laid out in the data flywheel analysis; others emphasize the lost space for grassroots experimentation and are steering users toward upcoming Sisyphus Labs agents via a waitlist in the sisyphus reaction.
The episode highlights a fault line between harnesses that ride consumer plans to drive huge agent workloads and those that align with provider‑supported APIs and economics; many of the former now need to re‑architect around more sustainable model partnerships.
OpenCode Black high-usage tier sells out repeatedly amid Anthropic friction
OpenCode Black (Anomaly/OpenCode): OpenCode’s paid "Black" tier—advertised at $200/month for "use any model" with generous limits—has sold out multiple times within minutes of each new batch going live, even as the project’s maintainer reports OpenCode is on track to hit 1M monthly active users this month, according to the offer posts in the black tier launch, the sellout notice in the sellout comment, and the MAU note and competition worries in the mau concern. New subscribers are being manually activated via email, and subsequent batches continue to clear quickly as announced in the sold out again and black waitlist.
• Capacity and token pressure: The same threads mention that heavy Anthropic Opus usage in related projects like Antigravity was likely costing providers on the order of seven figures per day and triggering rate‑limit pressure, which is part of the backdrop for OpenCode’s emphasis on "any model" and alternative providers, as implied in the opus token comment and antigravity costs.
• Provider diversification: Alongside Anthropic friction, OpenCode is promoting support for other vendors like MiniMax’s M2.1 and GLM‑4.7 via separate coding plans, framing Black as a way to ride whichever frontier models developers prefer without being tied to one lab, as seen in the black tier launch and related coding‑plan threads.
The pattern suggests strong willingness among power users to pay for a high‑usage, model‑agnostic harness layer even as underlying model access and economics remain volatile.
🏭 Anthropic–AWS Indiana AI campus scale and power math
Fresh satellite analysis on Anthropic’s New Carlisle, IN campus: 18 buildings, 750 MW on path to >1 GW, 500k Trainium2 chips online; unusual reliance on air cooling. Continues the infra economics storyline with new specifics.
Epoch AI pegs Anthropic–AWS Indiana campus at 750MW on path to 1GW+
Anthropic–AWS Indiana campus (Epoch AI): Epoch AI’s latest satellite and permitting analysis estimates Anthropic’s New Carlisle, Indiana AI campus at roughly 750 MW today, on track to exceed 1 GW once all 18 buildings are energized, making it a contender for the largest data center in the world scale estimate. The campus is being built by AWS as part of Project Rainier and is unusual in how much power it pushes while still relying mainly on air cooling rather than massive external chiller farms scale estimate.
• Layout and generators: Analysts identify 18 buildings on site, 16 of which are expected online by early 2026, based on recent satellite passes building count and the dedicated Anthropic–Amazon New Carlisle view in the satellite explorer; air‑quality permits show most buildings provisioned with 26 diesel backup generators each, capable of around 68 MW per building, giving the campus heavy emergency power headroom permit detail.
• Trainium2 deployment and power draw: AWS CEO Matt Garman has said more than 500,000 Trainium2 chips are already running in Indiana, which at roughly 500 W per chip plus overhead implies >500 MW of live AI compute in this one location, and about one‑fifth of all Trainium2s sold to date according to Epoch’s chip sales hub and follow‑up breakdown trainium count.
• Cooling and chip choice: The site shows very little external cooling gear—few cooling towers or big air‑cooled chillers—with AWS reportedly relying mostly on simple air cooling tuned for its less power‑dense Trainium2 servers, a design Epoch says is unlikely to work for future Blackwell‑class NVIDIA racks at comparable density cooling assessment; that split underlines how chip choice and rack power density feed back into campus‑level mechanical design.
• Schedule and monitoring cadence: Epoch has nudged its internal estimate for the campus crossing 1 GW of capacity from January to March 2026 after December imagery showed the last required buildings not quite ready timeline update; they note this kind of date shift as evidence that regular satellite monitoring can track AI power build‑out in near real time rather than relying only on vendor statements.
The analysis ties together public CEO comments, permits, and imagery into a concrete power budget for Anthropic’s primary training campus, giving infra planners and competitors a rare quantitative view of how fast one frontier lab’s dedicated AI capacity is ramping in partnership with AWS.
🛠️ Claude Code 2.1.3 and coding agent tooling
Product updates and hands‑on tooling for agentic coding. New Claude Code CLI changes, RepoPrompt unaffected by ToS clamp, Amp/Codex ecosystem signals. Excludes the access/ToS crackdown (covered in Feature).
Claude Code 2.1.3 tightens Bash/git behavior and ships a long CLI bugfix wave
Claude Code 2.1.3 (Anthropic): Anthropic has pushed a focused 2.1.3 update to Claude Code that changes how Bash and git tools are described and invoked, while also landing a sizable batch of CLI and VS Code stability fixes, extending the 2.1.0–2.1.2 line of agent-harness work 2.1.0 rollout as detailed in the 2.1.3 notes cli changelog and flag diff release recap.
• Prompt/schema changes: AskUserQuestion can now include an internal metadata.source field (e.g. "remember") for analytics without surfacing it to users, Bash tool calls must use short, factual description strings that avoid editorial language like “complex” or “risky,” and git workflows are explicitly told to never run git status -uall when preparing commits or PRs due to performance and memory concerns on large repos release recap and git status rule.
• Bash sed simulation hook: The Bash tool schema now exposes an internal _simulatedSedEdit payload (filePath + newContent) so external tooling can precompute sed-style edits and hand Claude a structured preview rather than free‑form text, making command-driven edits easier to integrate with other systems schema update.
• CLI/runtime fixes: The 2.1.3 CLI changelog lists merged “slash commands and skills” into a single mental model, a /config release-channel toggle, better detection of unreachable permission rules, plan files correctly resetting on /clear, multiple bug fixes around background task counts, model selection in sub‑agents, web search routing, trust dialogs, terminal rendering corruption, and slash suggestion readability; tool hooks now have a 10‑minute timeout instead of 60 seconds cli changelog and changelog diff.
• VS Code integration polish: On the editor side, VS Code users get a clickable destination selector for permission requests so they can decide whether settings apply to the current project, all projects, a shared team scope, or the current session, tightening how agent permissions persist across workspaces cli changelog.
The net effect is that Claude Code’s harness is being shaped into a more opinionated, safer agent runtime, with stricter tool semantics and fewer surprises in long‑running coding sessions.
Amp Free exposes Opus 4.5 coding via $300/month ad-supported tier
Amp Free (Sourcegraph): Sourcegraph’s Amp coding agent is widening access by making an ad‑supported "Amp Free" tier generally available with $300 per month in usage credits backed by Anthropic’s Opus 4.5, which several developers are now calling out as a default way to try high‑end agentic coding without a direct model bill amp free details.
• Free but metered: Amp Free is described as providing $10/day (roughly $300/month) of credits in exchange for an ad‑supported experience, letting users run Opus‑powered coding sessions without paying a subscription up front amp free details and amp announcement.
• Grant‑style expansion: A follow‑up from the Amp team mentions a new daily grant mechanic to make the free pool “a LOT more generous,” suggesting the free tier is being tuned actively rather than fixed as a one‑off promo amp announcement and grant clarification.
For engineers evaluating agentic coding stacks, this changes the economics of experimenting with an Opus‑backed harness: the main constraint becomes ad tolerance and daily credit caps rather than API billing complexity.
Cline 3.48.0 adds Claude Skills compatibility and direct web search tooling
Cline 3.48.0 (Cline): The Cline team has shipped version 3.48.0 of its VS Code agent, adding compatibility with Anthropic‑style Skills and a native web search tool so agents can pull context without relying on screenshots or manual browser steps release thread.
• Skills as modular expertise: Cline can now load Skills—packaged instructions and resources—for domain expertise that only activate when relevant, mirroring Anthropic’s Skills concept so the same skill definitions can be reused across Claude Code and third‑party harnesses release thread.
• Websearch tool: A new websearch capability lets Cline query the web directly and feed results into its reasoning loop, which the team positions as faster and more robust than driving a headless browser or relying on screenshot‑based scraping in coding sessions release thread and release notes.
This release pulls Cline closer to the emerging Skills ecosystem around Claude‑style agents, while giving its harness a first‑class way to fetch live web context for refactors, docs lookups, and dependency research.
RepoPrompt confirms Claude integration uses official headless client, not spoofed Claude Code
RepoPrompt (Independent): RepoPrompt’s maintainer clarified that the tool uses Anthropic’s officially supported headless Claude client plus MCP tools rather than spoofing the Claude Code desktop harness, which means it is unaffected by Anthropic’s recent clamp‑down on third‑party harnesses that impersonate the Code client architecture note.
• Headless, not hijacked: RepoPrompt routes user OAuth through the sanctioned headless client and layers additional MCP tools on top, instead of replaying Claude Code’s internal auth tokens or traffic patterns architecture note.
• ToS alignment signal: This architecture is positioned explicitly as compliant with Anthropic’s Terms of Service, in contrast to tools that logged in with a user’s Pro/Max subscription and then sent spoofed headers to make traffic look like Claude Code—those are the flows Anthropic’s safeguards now block architecture note.
For engineers using RepoPrompt as a repo‑aware coding agent, the message is that existing Claude integrations should continue to function without changes despite the new enforcement on impersonated harness traffic.
repo_updater CLI targets agent-first Git workflows across many repos
repo_updater (Flywheel): Independent builder Jeffrey Emanuel introduced repo_updater (“ru”), a bash‑based CLI that keeps dozens of public and private GitHub repos in sync across multiple machines, designed from day one to be operated by coding agents like Claude Code and Codex rather than only by humans repo updater intro.
• Cross‑machine sync: The tool lets a user define lists of public and private repos, then issues parallelized git pull/git push flows across a shared projects directory so that a laptop, workstation and remote servers stay aligned, with agents invoked to resolve diffs and avoid accidental loss of work repo updater intro and github repo.
• Agent‑oriented UX: Emanuel describes ru as "agent‑first"—built so Claude Code sessions can run commands like ru and ru sync, interpret the structured output, decide which branches to update, and even manage GitHub issues and PRs on the user’s behalf using natural‑language prompts repo updater intro.
The project illustrates how some of the emerging tooling around agentic coding is less about new models and more about shaping everyday CLI utilities into predictable, scriptable surfaces that agents can safely drive.
🛡️ Jailbreak defense: Constitutional Classifiers++
Anthropic details next‑gen classifiers using activation probes plus exchange classifier—reporting no universal jailbreak in 1,700 red‑team hours at ~1% overhead and far fewer benign refusals. Safety beat continues with new numbers.
Anthropic details Constitutional Classifiers++ with 1% overhead and no universal jailbreaks found
Constitutional Classifiers++ (Anthropic): Anthropic unveiled its next‑generation Constitutional Classifiers++ safety system, combining a lightweight activation probe that screens every request with a heavier "exchange" classifier that only runs on suspicious conversations, reporting ~1% additional compute cost and no universal jailbreak discovered after 1,700 hours of targeted red‑teaming so far research thread probe description exchange classifier paper link. The company also says this architecture cuts unnecessary refusals on harmless inputs by 87% compared with its prior classifier while retaining stronger jailbreak resistance overhead detail.
• Two‑stage architecture: The new system first uses a probe over internal model activations (likened to checking Claude’s "gut instinct") to cheaply score all traffic, then escalates flagged turns to an exchange‑level classifier that sees both sides of the dialogue and applies a richer constitutional rule set, as described in the updated safety notes probe description exchange classifier and the full research blog.
• Impact vs first‑gen classifiers: Anthropic’s earlier constitutional classifier cut jailbreak success rates from 86% to 4.4% but increased compute by ~23.7% and made Claude more likely to wrongly refuse benign prompts prior system and the research blog; Constitutional Classifiers++ aims to keep or improve on that robustness while reducing overhead to about 1% and sharply lowering benign refusals overhead detail.
• Red‑teaming results and limits: After roughly 1,700 hours of focused red‑teaming, Anthropic reports no "universal" jailbreak strategy that transfers across many prompts under the new system paper link, but notes that reconstruction‑style attacks—where an adversary decomposes disallowed content into multiple seemingly innocuous queries—remain a concern and a target for further work research blog.
The point is: Anthropic is pushing a more production‑minded safety layer that leans on internal activations plus a gated heavyweight classifier, trading a small compute tax for tighter jailbreak defense and fewer spurious refusals—numbers that matter directly for anyone running Claude at scale or building their own classifier stacks on similar principles.
🧪 Agent evals: Anthropic’s playbook and leaderboard churn
Anthropic publishes a practical eval guide for multi‑turn agents (graders, pass@k vs pass^k, transcript review). Community also shares rank‑decay stats and tool eval asks. Excludes jailbreak classifiers (see Safety).
Anthropic publishes concrete playbook for evaluating multi‑turn AI agents
Agent eval guide (Anthropic): Anthropic’s engineering team laid out a practical framework for testing agentic systems, contrasting simple single‑turn checks with multi‑step, tool‑using agents and detailing grader types, capability vs regression suites, and pass@k vs pass^k metrics in the new guide shared in the Anthropic announcement and expanded in the engineering article. The piece emphasizes that useful agents require evals built around tasks, trials, and graders, and that reading full transcripts is mandatory to see whether failures come from the agent or from brittle grading, as echoed in community commentary in the cursor eval note and the breakdown in the engineer summary.
• Grader taxonomy: The guide distinguishes code‑based graders (fast but brittle), model‑based graders (nuanced but stochastic), and human graders (expensive but gold standard), and argues they should be combined rather than used in isolation, as described in the Anthropic announcement.
• Capability vs regression suites: It frames early "capability" evals as low pass‑rate, exploratory tests, and "regression" evals as high pass‑rate guards that mature tasks graduate into, clarifying how teams can track real progress across deployments in the engineering article.
• Handling non‑determinism: The article pushes teams to track both pass@k (at least one success in k runs) and pass^k (all k succeed), noting that these diverge sharply at larger k and that relying on pass@k alone can hide fragile behavior, as summarized in the engineer summary.
The document positions evals as an ongoing product‑engineering loop rather than a one‑time benchmark, with Anthropic explicitly recommending that teams continuously curate tasks from real failures and wire them into automated suites.
Engineers converge on concrete agent eval habits beyond benchmarks
Practitioner eval patterns (community): Multiple engineers are translating Anthropic’s eval guidance into practice, stressing transcript review, carefully scoped LLM judges, and avoiding vague Likert scales in favor of binary or graded task outcomes, as discussed in the eval takeaways and the eval judgment thread. The emerging pattern treats evals as instrumentation on real agent trajectories rather than synthetic leaderboard scores.
• Trace reading as core loop: Practitioners highlight that failed tasks must be inspected step‑by‑step—looking at tool calls, environment changes, and grading decisions—to see whether an agent truly failed or the grader rejected a valid path, with one engineer urging teams to "pls look at the agent traces" and enumerate failure modes like formatting, logic, or environment bugs in the trace reading advice.
• LLM‑judge design: Several posts note that model‑based graders are valuable but tricky; they encourage converting manual QA checks into deterministic tests, adding partial credit for complex tasks, and using model judges mainly where code‑based checks cannot capture open‑ended success, reflecting the nuance in the eval takeaways.
• Likert scales skepticism: Eval specialists warn that 1–5 rating scales are costly to align and hard to act on, and that they let annotators dodge hard yes/no decisions, recommending binary pass/fail or task‑specific structured scores instead, as argued in the likert scale FAQ and supported by the eval flashcards.
Together these posts sketch a working culture where agent evals are built around concrete tasks, reproducible graders, and routine log review rather than high‑level satisfaction scores.
LMArena quantifies how fast top LLMs fall down the leaderboard
Leaderboard churn (LMArena): The LMArena team analyzed historical ChatbotArena rankings and found that models holding the #1 spot only stay there for about 35 days on average, with former leaders typically falling out of the top‑5 within 5 months and out of the top‑10 within 7 months, as visualized in the rank decay update. The animation shows earlier flagships like o1 and Claude 3 Opus drifting to ranks 56 and 139 respectively as newer systems arrive.

• Implications for eval suites: The authors frame this as evidence that any single leaderboard snapshot quickly goes stale, suggesting that capability evals must be maintained as moving baselines rather than fixed targets if teams want to understand how their agents compare over time, according to the rank decay update.
The result underlines that agent and model evals are now operating in a high‑churn environment, where maintaining up‑to‑date comparisons matters as much as the choice of benchmarks themselves.
Letta AI open-sources .af-based harness for large-scale agent evals
Eval kit (Letta AI): Letta AI released an evaluation toolkit that uses .af Agent Files to clone and test agents at scale, turning the same configuration format used for production agents into a reproducible eval harness, as outlined in the letta eval note and detailed in the GitHub repo. The framework supports running many task trajectories per agent definition and surfacing results on a leaderboard site so teams can compare behaviors across agent versions or configurations.
• Config‑as‑evals: By reusing Agent Files for eval runs, teams can capture model choice, tools, prompts, and memory settings in a single artifact, then instantiate identical agents under different test suites without drift, according to the GitHub repo.
• Leaderboard and workflows: The repository includes example workflows, documentation assets, and a leaderboard front‑end, giving a reference for how to track pass rates and regressions across large numbers of long‑running agent trajectories, as noted in the letta eval note.
This pushes evals toward the same configuration‑driven pattern as deployment, making it easier to keep test agents and production agents in sync while experimenting with new capabilities.
📚 Reasoning & agent methods: context, batching, and signals
Rich research day spanning agent frameworks and reasoning dynamics: file‑centric long‑horizon agents, batch reflection gains, CoT uncertainty gaps, logical phase transitions, persona elicitation, and one‑sample RL scaling.
Fast-weight Product Key Memory framed as episodic memory that reaches 128K context
Fast-weight Product Key Memory follow-up (Sakana AI): New commentary on Fast-weight Product Key Memory (FwPKM) elaborates that it lets models treat main weights as long-term semantic knowledge and FwPKM as an episodic memory that stores recent variables and intermediate steps, extending the long-context memory idea introduced in long-context memory. The memory is dynamic. According to the FwPKM recap and FwPKM follow-up, FwPKM inherits Product Key Memory’s split-key lookup (two smaller key tables whose best matches are combined) but makes the memory writable both during training and inference; models equipped with FwPKM handle much longer contexts and can generalize to 128K‑token sequences despite being trained on much shorter windows by retrieving and updating relevant slots instead of relying solely on quadratic attention.
InfiAgent uses file-centric memory to keep long-horizon agents bounded
InfiAgent (multi-institution): A new InfiAgent framework proposes a hierarchical, file-centric agent architecture where long-horizon tasks interact with a persistent workspace on disk while the model’s active reasoning window stays fixed to roughly the last ten actions plus a snapshot of file state, according to the authors’ overview in the InfiAgent thread. The core idea is file-centric memory. Experiments on DeepResearch-style multi-hour investigations and an 80-paper literature review show a 20B open model maintaining higher coverage and fewer cascading failures than context-centric baselines by externalizing history into files rather than ever-growing prompts, as illustrated in the architecture diagram in the
.
Logical phase transitions reveal sharp reasoning collapse bands in LLMs
Logical phase transitions in LLM reasoning (Huazhong University): New work introduces a Logical Complexity Metric (LoCM) combining counts of facts, logical operators and nesting depth, then shows that LLM accuracy stays flat up to a threshold before collapsing sharply in narrow LoCM bands—logical phase transitions analogous to melting or boiling points, as framed in the phase transition thread. The collapse is abrupt, not smooth. The authors then augment training with paired natural-language and first-order logic forms plus a complexity-aware curriculum that spends extra time near the crash bands, improving direct-answer accuracy by about 1.26 points on average and step-by-step reasoning accuracy by roughly 3.95 points across five benchmarks, with side-by-side physical vs logical phase diagrams shown in the
.
SPICE fuses priors and context for regret-optimal in-context RL
SPICE in-context RL (Mila & collaborators): SPICE proposes an in-context reinforcement learning scheme where an LLM learns a value prior over actions via deep ensembles, then updates that prior online by fusing small context windows of recent interaction data in a Bayesian way—achieving regret-optimal behavior in both stochastic bandits and finite-horizon MDPs even when pretraining data is suboptimal, according to the SPICE paper. The method adds uncertainty bonuses. Instead of updating weights, SPICE keeps model parameters fixed and treats the prompt as an evolving state that encodes posterior beliefs over Q‑values, allowing fast adaptation on unseen tasks while keeping regret lower than prior in-context RL and meta-RL baselines across bandit and control benchmarks as detailed on the title page in the
.
ChaosNLI study finds CoT changes decisions more than uncertainty
Chain-of-thought and uncertainty (ChaosNLI study): A ChaosNLI-based analysis separates the effect of chain-of-thought (CoT) on final label choice from its effect on uncertainty modeling, finding that around 99% of accuracy changes stem from the presence of CoT text itself while over 80% of the ranking over alternative answers appears to come from the model’s latent beliefs, not the written reasoning, according to the CoT decoupling thread. CoT mainly pushes toward a choice. The authors construct tasks with 100 human labels per example, use CoT to generate partial or full reasoning, and then feed those traces into other models to see how much the text versus internal state shifts answer distributions, concluding that CoT currently behaves more like a decision nudge than a calibrated uncertainty explanation, with illustrative accuracy–complexity plots shown in the
.
GDPO stabilizes group-normalized multi-reward RL beyond GRPO
GDPO for multi-reward RL (GDPO authors): GDPO (Group reward‑Decoupled Normalization Policy Optimization) targets the collapse of reward normalization seen in GRPO when optimizing for multiple rewards, proposing a decoupled normalization scheme that stabilizes training and improves multi-reward reasoning benchmarks as described in the GDPO summary. The paper focuses on multi-objective RL. By separating normalization across reward groups instead of pooling them, GDPO maintains useful gradients for each objective and avoids the flattening that can stall learning, with experiments in the Hugging Face papers entry reporting better stability and performance on complex reasoning and alignment tasks than GRPO-style baselines under the same compute budget, even though detailed numeric tables live in the underlying arXiv preprint rather than the tweet itself.
IROTE uses self-reflective prompts to stably elicit LLM personas
IROTE trait elicitation (THUNLP, Microsoft, Fudan): IROTE (In-context self‑Reflective Optimization for Trait Elicitation) is a training-free framework that generates a compact, evocative self‑reflection text for an LLM, then uses it as a stable identity prompt that elicits consistent personality traits across both questionnaires and open-ended tasks, as introduced in the IROTE paper. The method draws from psychology. Inspired by self-reflective identity processing theory, IROTE iteratively optimizes the reflection to balance compactness (low noise) and evocativeness (strong trait activation) via information-theoretic objectives, producing a single reflection that transfers across models like GPT‑4o and Mistral and across tasks beyond simple Likert questions, with questionnaire vs story-writing trait scores contrasted in the
.
Large Reasoning Models show English-centric latent reasoning across languages
Multilingual latent reasoning gaps (LMU Munich): A study on Large Reasoning Models tests the same math problems in 11 languages and measures how often a model can still give correct answers when parts of its chain-of-thought are hidden, finding strong latent reasoning in high-resource languages like English and Chinese but much weaker signals in low-resource languages such as Swahili and Telugu, per the multilingual reasoning paper. Internal states tend to look English-like. On easier grade-school math, large models can often answer correctly with 0% of written reasoning visible in high-resource languages, while on harder competition problems that early latent signal mostly vanishes and internal activation patterns across languages cluster closer to English than to each target language, suggesting that today’s multilingual reasoning is often an English-centric core wrapped in translated surface forms, as shown in the figures reproduced in the
.
Pruning shows LLMs already encode which reasoning tokens truly matter
Reasoning token importance (University of Illinois): A study on functional importance of reasoning tokens treats each intermediate token as removable and prunes those whose deletion causes the smallest drop in answer confidence, finding a 0.88 correlation between attention-based scores and actual functional importance across tasks as summarized in the token importance paper. The pruning reveals where work happens. When student models are trained on pruned traces from a stronger LLM, at equal trace length they outperform baselines that keep different subsets of tokens or depend on a separate teacher model to label importance, suggesting LLMs already encode which reasoning words matter most while often filling the rest with removable filler, as discussed around the abstract and title page in the
.
Semantic reasoning graphs catch RAG hallucinations better than token LRP
Semantic reasoning graphs for hallucination detection (Peking University): A new method builds a semantic-level internal reasoning graph from an LLM’s hidden relevance scores, then flags answer chunks whose support comes more from prior model output than from retrieved context, improving hallucination-detection F1 by roughly 3–6 percentage points on RAGTruth and Dolly‑15K compared to prior baselines in the hallucination paper. The graph is built from LRP. The approach extends layer-wise relevance propagation from tokens to short meaning fragments, connects them into a directed graph whose edges encode contribution weights, and then uses a lightweight classifier over local subgraphs to decide if each fragment is grounded, with example graphs and dashed-box hallucinated nodes shown in the
.
🗣️ STT baseline shifts: ElevenLabs Scribe v2
Enterprise‑ready STT advances: new accuracy, domain term handling, and compliance features. Mostly voice infra news today; separate from creative audio.
ElevenLabs Scribe v2 pushes STT accuracy toward 5% WER
ElevenLabs Scribe v2 (ElevenLabs): ElevenLabs is positioning Scribe v2 as a new baseline for automatic speech recognition, claiming around 5% word error rate in English and under 10% in many other languages across 90+ languages according to the launch breakdown in the stt overview; early users describe it as "the most accurate transcription model ever released" in the accuracy praise. Scribe v2 is available both via API and in ElevenLabs Studio for subtitles, captions and batch transcription, with code examples and model options outlined in the api launch and the stt docs.
The upgrade is framed as a response to predictable STT failure modes—turning "async" into "a sink" or "Kubernetes" into "Cooper Netties"—which Scribe v2 aims to correct by better modeling technical terms and long-form content as described in the failure patterns. The messaging stresses strong performance even on niche domains, while acknowledging that very low-resource languages remain challenging per the feature summary in the stt overview.
Scribe v2 introduces contextual keyterm prompting and rich entity detection
Keyterm and entity tools (ElevenLabs): Beyond raw accuracy, Scribe v2 adds a keyterm prompting mechanism that lets callers pass up to 100 domain-specific terms or phrases, which the model then uses context to decide when to apply—avoiding naive custom vocab behavior that would, for example, force "SQL" into every instance of "sequel" as explained in the keyterm feature and summarized again in the failure patterns. On top of this, Scribe v2 can detect entities across 56 categories, spanning PII, health data and payments, and returns exact timestamps for each instance, aimed at compliance, redaction and analytics workflows as detailed in the entity feature.
• Speaker and timing metadata: The model exposes speaker diarization for up to 48 speakers, word-level timestamps for precise subtitle syncing, and audio event tags (e.g., laughter or footsteps) so downstream systems can distinguish speech from other sounds, according to the diarization feature and follow-up in the failure patterns.
• Enterprise integration focus: ElevenLabs is pitching these capabilities as building blocks for complex audio pipelines, with Scribe v2 intended for high-volume batch captioning and documentation while Scribe v2 Realtime covers interactive use, as outlined in the api launch and supported by the updated models docs.
The feature set effectively turns the STT layer into a structured data extractor, so teams can plug transcripts, entities and timing metadata straight into compliance, BI or support tooling rather than treating speech-to-text as a plain text box.
Scribe v2 Realtime targets low-latency voice agents and live tools
Scribe v2 Realtime (ElevenLabs): Alongside the batch model, ElevenLabs and ecosystem commentators highlight Scribe v2 Realtime as an ultra low-latency variant tuned for voice agents and live experiences, pairing the new accuracy and entity features with faster turnaround for conversational systems, as described in the realtime intro. The main Scribe v2 is framed as handling batch transcription, subtitles and long-form assets, while Scribe v2 Realtime is "optimized for ultra low latency and agents use cases" in the product notes referenced by the api launch.
Scribe v2 Realtime carries over precision timestamps and entity detection, so agent frameworks can align responses, display live captions or trigger flows off detected PII or payment mentions while a call is in progress, according to the combined descriptions in the realtime intro and entity feature. The realtime path is also exposed through the same developer surface and documentation as the batch model, with ElevenLabs steering teams that need interactive, streaming ASR toward the Realtime endpoint and offline workloads toward Scribe v2 proper in the stt docs.
Scribe v2 targets 10-hour files and HIPAA/GDPR for enterprise STT
Enterprise STT stack (ElevenLabs): ElevenLabs is also pushing Scribe v2 as an enterprise-ready transcription stack, supporting audio files up to 10 hours and advertising compliance features like SOC 2, ISO27001, PCI DSS L1, HIPAA and GDPR, plus EU and India data residency and an optional zero-retention mode, according to the capability bullets in the stt overview and elaborated in the stt overview follow-up. The API is designed for large libraries of marketing, media, research and training content, with batch processing, long-form captioning and subtitling use cases called out in the api launch and the stt docs.
• Regulated-data workflows: Combined with entity detection for PII and health/payment data plus precise timestamps, Scribe v2 can drive redaction pipelines or flag sensitive segments in customer support and medical transcripts, as described in the entity feature and diarization feature.
• Studio and API parity: ElevenLabs states that the same models back both the Studio UI and the API, so teams can prototype transcription and tagging interactively and then lift those settings into production jobs, per the messaging in the api launch.
The emphasis on long-duration files and formal certifications indicates Scribe v2 is aimed at replacing or augmenting incumbent enterprise STT providers rather than remaining a purely creator-focused tool.
📈 MiniMax IPO pops; China’s challenger arms up
MiniMax lists in Hong Kong, surges >50–100% day one with ~HKD 100B–137B valuation. Signals capital for a lean (≈389 staff) full‑stack lab competing on coding, video, audio. Enterprise‑scale signal; not a model release.
MiniMax’s Hong Kong IPO more than doubles, valuing lean full‑stack lab near $13–14B
MiniMax IPO (MiniMax): China’s MiniMax listed on the Hong Kong Stock Exchange, with shares priced at HK$165 and trading up as much as 54–100% on day one—closing around HK$345 and taking the company past HKD 100B (≈$12.8–13.7B) in market value according to the ipo pop note, offering recap and valuation thread. The deal raised about $619–620M (HK$4.8B) earmarked mainly for R&D, with the retail tranche reportedly oversubscribed roughly 1,837× and book built from global institutions including Alibaba, ADIA, Boyu Capital, Mirae and other long‑only funds in Europe, North America, the Middle East and Asia as described in the valuation thread and stack overview.
• Capital‑efficient challenger: Commentators highlight that MiniMax reportedly operates with about 389 employees and burns on the order of 1% of OpenAI’s spend while fielding competitive systems like the M2.1 language model, Hailuo video generation and Talkie character chat apps across text, image, video, audio and agents efficiency claim and stack overview.
• Position in the model race: Practitioners frame M2.1 as “trading blows” with Claude Opus and Gemini for web development and coding quality at a lower price point, and note that the new capital gives one of the first Chinese full‑stack labs a public‑market war chest while Anthropic and OpenAI remain private efficiency claim and benchmark sentiment.
The listing makes MiniMax one of the few frontier‑model labs with access to public equity markets, signaling investor appetite for lean, multimodal AI stacks out of China and adding a new well‑funded competitor to the US‑dominated frontier model landscape.
🚧 Frontier watch: DeepSeek V4 coding push (Feb)
Multiple sources flag DeepSeek V4 arriving mid‑February, expected to surpass Claude/GPT in coding; early tests likely on LMArena. This is a forward‑look, not a release today; complements infra and eval beats.
DeepSeek V4 tipped for mid‑February with claims of coding gains over Claude and GPT
DeepSeek V4 (DeepSeek): Multiple reports say the next DeepSeek flagship is scheduled for early‑to‑mid February around Lunar New Year, with internal benchmarks claiming it outperforms Claude 4.5 and GPT‑5.2 on coding tasks according to Chinese coverage and The Information’s reporting coding claims and the linked information article; one summary shared from people with direct knowledge of the plan says initial DeepSeek employee tests showed V4 “outperformed existing models, such as Anthropic's Claude and OpenAI's GPT series, in coding,” reinforcing the expectation that it could become the strongest coding‑specialized model on release article excerpt and prompting community commentary that it “shows stronger coding performance than current GPT and Claude models” model hype.
The teaser clip announcing “DeepSeek V4 is coming mid February” and that “coding is about to get serious” further anchors both the timing and the positioning of V4 as a coding‑first frontier model in this cycle video countdown.
DeepSeek expected to use LMArena/ChatbotArena again to benchmark V4
Arena testing plans (DeepSeek): An LMArena watcher notes that DeepSeek‑V4 is likely to be released around February 17 (Chinese New Year) and that the team could “potentially test the model earlier on LmArena,” pointing out that DeepSeek’s V3.1 and V3.2 bases were already evaluated there to approximate user preferences arena timing; the cited paper excerpt explains how DeepSeek used ChatbotArena Elo scores from November 2025 to verify that new sparse‑attention bases matched the previous iteration despite architectural changes, which suggests V4 will again be benchmarked in public, head‑to‑head matches against GPT, Claude and other frontier systems on the same platform arena timing.
This pattern positions LMArena/ChatbotArena as one of the first places where independent users may see comparative coding and reasoning performance once V4 is available.
Commentators frame 2026 as a fast iteration year for DeepSeek and Chinese coding models
Chinese coding models (DeepSeek and peers): Community commentary argues that “several Chinese companies” are on track to release new frontier models before Chinese New Year, explicitly naming DeepSeek’s next flagship (described interchangeably as “r2 or v4”) and saying its recent paper has “major implications for making models more stable, faster, and cheaper to train,” while early internal feedback reportedly shows coding performance better than Claude or GPT iteration outlook; a follow‑up thread characterizes 2026 as a “fast iteration year for DeepSeek,” with the upcoming model’s large coding claims raising a concrete strategic dilemma for teams about whether to invest more in training and inference on current‑generation models now or wait for this new Chinese wave to land investment dilemma.
This framing reinforces the idea that Chinese labs, and DeepSeek in particular, are planning shorter release cycles focused on code and agentic reliability rather than slow, monolithic upgrades.
DeepSeek V4 hyped as a moment where Chinese coding models could overtake US peers
Competitive landscape and expectations (DeepSeek V4): Several observers describe the upcoming DeepSeek‑V4 as a potential point where China “overtakes the USA” in coding‑focused LLMs, citing The Information’s note that the new model is “expected to outperform competitors like Anthropic's Claude in coding” on internal benchmarks overtake framing and separate claims from sources close to the launch that V4 shows “stronger coding performance than current GPT and Claude models” coding lead claim; this narrative sits alongside broader tracking of China‑based open‑weights labs such as DeepSeek and GLM, where Artificial Analysis has already highlighted GLM‑4.7 as the top open‑weights model on its Intelligence Index v4.0 and noted multiple Chinese releases advancing the frontier in 2025–26 open weights entrants.
Some market‑watching accounts extend this to speculation about impacts on Western AI leaders and even AI‑exposed stocks once V4 is live, but concrete, independently verified cross‑model coding benchmarks have not yet been published in these discussions.
🎨 Creator stacks: Midjourney Niji V7, Kling control, $20k challenge
Significant creative/vision items today: Midjourney’s Niji V7 upgrade, Kling Motion Control how‑tos, and Higgsfield’s $20k AI‑cinema contest. Dedicated section retained due to volume of creator posts.
Midjourney ships Niji V7 with stronger anime and text rendering
Niji V7 (Midjourney): Midjourney has rolled out Niji V7, a new version of its anime‑focused image model with upgrades in anime coherence, prompt understanding, text rendering, and style‑reference (sref) performance, according to the official launch note Niji announcement; early testers highlight that it captures specific aesthetics like “night elf” style with minimal prompting and are considering re‑subscribing to Midjourney on the strength of the update subscription reaction.
• Anime and sref focus: The team calls out better anime coherence and sref handling, which matters for character consistency and branded looks in ongoing series work Niji announcement.
• Creator sentiment: Community posts describe Niji 7 as “amazing” and show multi‑image grids with clean composition and lighting for complex scenes, suggesting it is already becoming a go‑to for anime/webtoon pipelines Niji recap.
For AI artists and tool builders, this version positions Niji more clearly as the specialized anime engine in the broader image‑model stack rather than a generic model with an anime mode.
Creators standardize on Kling Motion Control for precise dance and movement edits
Motion Control (Kling): Kling’s Motion Control workflow is being adopted as a precise way to transfer body and facial movements from a driving video (e.g., Michael Jackson dance clips) onto a static reference character, with creators publishing step‑by‑step guides that show frame‑accurate motion across the generated clip motion guide; the tool is framed as the "perfect model for getting exactly what you want" in movement control motion guide.

• Workflow pattern: Guides describe a repeatable recipe—pick a reference dance video, choose a target still image, select Kling model 2.6 in Motion Control mode, then let Kling synthesize a new clip where the target performs the source choreography, preserving both pose and facial expression motion guide.
• Usage in AI filmmaking: Follow‑up threads position Motion Control as part of a broader AI filmmaking stack, with creators calling it “the future of AI filmmaking” and encouraging others to chain it with other generative tools for polished music‑video‑style content filmmaking thread.
For engineers building creative tools, this pattern shows that reference‑video‑plus‑portrait control is becoming a standard interface for motion‑driven character animation rather than a niche trick.
Higgsfield launches $20k AI‑Cinema Challenge around Cinema Studio
Higgsfield Cinema Challenge (Higgsfield): Higgsfield has kicked off a $20,000 "Higgsfield Cinema" challenge inviting creators to make short AI‑generated films with its Cinema Studio product, offering a $10k first prize, $5k and $3k for runners‑up, plus ten $200 "Higgsfield Choice" awards, with submissions due by January 24 (EOD PST) challenge announcement.

• Mechanics and rules: Entries must tag @higgsfield_ai, include “@higgsfield.ai #HiggsfieldCinema” in the caption, and keep the official Higgsfield watermark in the output, which effectively turns the contest into a large‑scale showcase of Cinema Studio’s visual capabilities challenge announcement.
• Distribution push: A follow‑up post repeats the rules and links directly to Cinema Studio downloads, signalling that the challenge is designed both to seed content and to drive hands‑on use of the tool among filmmakers and motion designers cinema followup.
For people tracking creator‑oriented AI, this contest is a concrete example of a vendor using prize pools and social constraints (tags, watermarks) to bootstrap an ecosystem of Cinema‑Studio‑native shorts.
🏢 System-level ROI: Datadog’s Codex code review
A concrete enterprise case: Datadog pilots Codex for system‑level code review. ‘Incident replay’ suggests it would have flagged ~22% of studied incidents—evidence for AI ROI beyond lint. Separate from the access Feature.
Datadog’s incident replay shows Codex can catch 22% of historical issues
Datadog Codex case study (OpenAI): Datadog piloted Codex as a system-level code reviewer on one of its largest repositories, auto-reviewing every pull request and surfacing cross-service risks that human reviewers and earlier tools often missed, according to the Datadog teaser and the case study. An "incident replay" on historical PRs linked to production issues found that Codex would have produced actionable feedback in more than 10 cases—about 22% of the sampled incidents—indicating measurable ROI beyond lint-style checks.
• System-context feedback: Engineers reported that Codex highlighted interactions with untouched modules and missing tests, giving higher-signal, less noisy comments than previous linters and shallow AI tools, as described in the case study.
• Incident reduction potential: In the replay harness, Datadog’s team confirmed that Codex’s hypothetical comments would have changed how engineers approached the risky PRs in roughly a fifth of examined incidents, suggesting it can complement human review rather than replace it case study.
• Operational positioning: OpenAI and Datadog frame Codex as a consistent, scalable reviewer that can be applied to every PR in large microservice estates, pushing systemic issues earlier in the lifecycle instead of relying only on senior engineers or post-incident analysis Datadog teaser.
The case gives rare quantitative evidence that a code-review LLM can materially reduce incident risk at scale, rather than only speeding up individual developers.
🧵 MCP and skills interoperability is accelerating
Interoperability tools for agents expanded: new CLI for dynamic discovery, OpenAI ships an MCP for docs, and skills loaders simplify packaging. Today’s focus is packaging/transport, not coding harnesses or evals.
OpenAI launches Developer Docs MCP for API, Codex, Apps SDK and commerce protocol
Developer Docs MCP (OpenAI): OpenAI introduced a new MCP server that exposes its developer documentation and code samples—covering the API, Codex, Apps SDK, and Agentic Commerce Protocol—so MCP-aware agents can query docs and examples directly, as announced in the mcp teaser and detailed in the mcp docs. The example codex mcp add openaiDeveloperDocs --url https://developers.openai.com/mcp command shows it is designed to drop straight into existing Codex and Skills-based harnesses.
• Scope of content: The server indexes not just reference docs but also code samples for the API, Codex, and newer surfaces like the Apps SDK and Agentic Commerce Protocol, turning them into structured MCP tools rather than unstructured text, according to the mcp teaser.
• Agent integration: Because it uses the standard MCP transport, any compatible client (Codex app server, third‑party IDE harnesses, or custom agents) can point at openaiDeveloperDocs and let the model search, retrieve, and ground answers in first‑party docs instead of hitting the public web, as shown in the mcp docs.
• Ecosystem continuation: Following up on papers mcp, where Hugging Face used an MCP server to front academic papers to an assistant, OpenAI is now applying the same pattern to its own platform docs, reinforcing MCP as a shared way to package knowledge sources for agents.
This moves a significant chunk of OpenAI’s developer surface area behind a common protocol, reducing the need for bespoke scraping or custom plugins when building doc-aware agents.
mcp-cli debuts as dynamic MCP discovery CLI with ~99% token savings
mcp-cli (Phil Schmid): A new open-source CLI for the Model Context Protocol focuses on discovery instead of loading full tool catalogs up front, with claimed ~99% reduction in MCP token usage via on-demand metadata fetching, as described in the mcp-cli intro and expanded in the blog post. It compiles via Bun into a single standalone binary, supports both stdio and HTTP MCP servers, and is aimed squarely at AI coding agents like Claude Code and Gemini CLI.
• Token and performance impact: Rather than having agents pre-load every tool description, mcp-cli exposes a discovery flow where the agent first lists servers, then tools, and finally fetches schemas only when needed, which the author reports cuts MCP prompt tokens from ~47k to ~400 for a sample workflow—around a 99% reduction, according to the blog post.
• Developer ergonomics: The tool offers glob-based mcp-cli grep across all servers, JSON output for scripting, and automatic retries with exponential backoff, with configuration done through a simple mcp_servers.json file as shown in the github repo.
• Ecosystem continuation: Following up on conductor mcp, which wired a single MCP server into code review UIs, mcp-cli moves the focus to a shared discovery layer that any MCP-capable client or agent harness can sit on top of, decoupling server choice from the application.
The release positions MCP less as a per‑app integration and more as a small protocol that many servers and many agents can share, with mcp-cli acting as a low-friction adapter layer for both humans and LLMs.
OpenRouter SDK adds Skills Loader to reuse Agent Skills across models
Skills Loader (OpenRouter): OpenRouter announced an SDK "Skills Loader" that can dynamically pull in Agent Skills definitions and wire them into any model’s context with a one-liner, turning Skills from a Claude‑specific concept into something portable across providers, according to the skills loader announcement and the skills docs. The loader scans a skills directory, loads the instructions and metadata, and attaches them as tools/prompts when you call a model via the OpenRouter SDK.
• Interoperable packaging: The Skills Loader reads skill manifests (the same format popularized by Claude Code) and makes them available to any model reachable via OpenRouter—GPT‑5.2, Claude, Gemini, GLM‑4.7, MiniMax and others—without rewriting the skills for each provider, as described in the skills loader.
• Developer workflow: In example snippets, adding skillsLoader({ dir: "./skills" }) to the OpenRouter SDK client is enough to have all skills in that folder discovered and injected into calls, avoiding per‑call boilerplate and keeping skills versioned on disk, per the skills docs.
• Ecosystem continuation: Following up on claude skills, which framed Skills as Claude’s answer to plugins, this loader pushes Skills toward a de facto portable format, with OpenRouter acting as a neutral transport layer between those skill packs and whichever model you route traffic to.
The update nudges the ecosystem away from model‑locked skill systems and toward a shared, file‑based skills layer that multiple harnesses and providers can consume.
🗂️ Parsing and structured extraction at scale
Doc parsing/extraction workflows for agents and RAG advanced: tutorials for zero‑shot multi‑doc extraction and a new open parser that detects scan vs digital and recovers layout. Mostly pipeline engineering news today.
ByteDance’s Dolphin parser targets complex PDFs and scans, hits 89.8 on OmniDocBench
Dolphin document parser (ByteDance): A new open‑source parser called Dolphin from ByteDance focuses on hard PDFs and document images, detecting whether each page is scanned or digital, restoring layout and reading order, and parsing text, tables, formulas and code with different strategies Dolphin overview; the largest 3B variant reports up to 89.8 on OmniDocBench, placing it among the stronger open document understanding stacks.
• Hybrid parsing pipeline: Dolphin routes pages through OCR or text extraction based on a scan/digital classifier, then applies layout analysis to reconstruct reading order and region hierarchy so downstream models can work with semantically coherent blocks rather than raw tokens Dolphin overview.
• Model sizes and backends: The release spans 0.3B–3B models and is designed to run with engines like vLLM and TensorRT‑LLM, giving teams options to trade off latency vs quality while keeping deployment within familiar inference stacks Dolphin GitHub.
• Benchmarks and scope: Reported OmniDocBench scores (topping out at 89.8) and support for code snippets and formulas indicate a focus on complex technical and scientific documents rather than only simple business PDFs Dolphin overview.
Dolphin effectively slots in as a parsing front‑end for RAG and agent systems that need high‑fidelity structure from messy real‑world documents before handing work off to larger LLMs.
LlamaIndex shows zero‑shot multi‑doc extraction with LlamaSplit and LlamaExtract
LlamaIndex structured extraction (LlamaIndex): LlamaIndex published a hands‑on guide for zero‑shot extraction of many repeated records (like ~100 resumes or dense financial docs) using a two‑stage agentic pipeline built from LlamaSplit and LlamaExtract LlamaIndex thread; the workflow detects document boundaries, slices docs into semantically coherent sub‑chunks, then runs schema‑driven extraction over each chunk to build a single aggregated JSON output.

• Pipeline design: The tutorial maps out an agent loop that first performs document boundary detection, then uses LlamaSplit for sub‑chunking and LlamaExtract to emit per‑chunk structured objects that are later stitched into a unified result, as shown in the LlamaIndex blog.
• Scale and robustness: The authors highlight scenarios like multi‑resume files and collections of financial statements where naive single‑prompt extraction fails, arguing that chunk‑aware extraction plus post‑aggregation maintains schema consistency while keeping token usage bounded LlamaIndex thread.
The example positions LlamaSplit+LlamaExtract as a practical pattern for agents that need high‑volume, repeated structured outputs from complex multi‑document inputs without custom fine‑tuning.
Free Qwen3‑VL Colab shows end‑to‑end multimodal RAG on a single T4
Qwen3‑VL multimodal RAG (Alibaba): A new Colab notebook from the Qwen community wires Qwen3‑VL 2B models into an end‑to‑end multimodal RAG pipeline that runs on a free T4 GPU, covering embedding, reranking and query answering over long documents with both text and images Qwen3 notebook tweet.
• Memory‑aware design: The walkthrough loads 2B‑parameter models only for embedding and reranking, then unloads them once vectors are stored to keep VRAM use low and make the pipeline viable on constrained hardware, as described in the Qwen3 notebook.
• Indexing guidance: For longer documents, the author recommends FAISS v2 and bitsandbytes quantization, combining fast ANN search with compressed vectors so multimodal stores stay within GPU and RAM budgets even as corpus size grows Colab usage tips.
The notebook serves as a concrete recipe for teams wanting to prototype image‑aware or PDF‑aware RAG without needing large GPUs or proprietary hosted stacks.
NotebookLM data tables feature extracts structured data across 32‑file notebooks
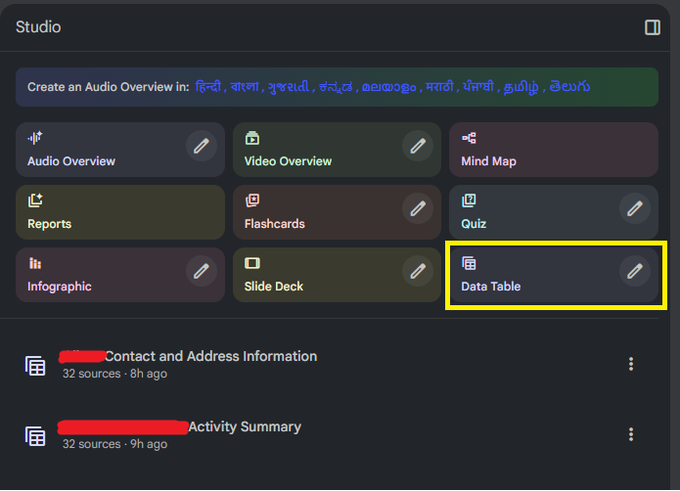
Data tables in NotebookLM (Google): A user demo shows NotebookLM synthesizing structured data tables from 32 uploaded files in a single notebook, side‑stepping some of the Gemini app’s upload limits and highlighting NotebookLM as Google’s heavier‑duty environment for cross‑document analysis NotebookLM example.
• Multi‑doc structured extraction: The screenshot shows a "Data Table" artifact generated alongside other AI outputs, indicating that NotebookLM can scan dozens of heterogeneous sources and compile them into a clean tabular format without manual schema wiring NotebookLM example.
• Workflow positioning: The author notes they used NotebookLM because the Gemini app caps uploads, suggesting NotebookLM is emerging as the place to run larger, archive‑scale parsing and extraction workflows while keeping tables and other artifacts organized per project NotebookLM example.
For engineers and analysts building on Google’s stack, this points to NotebookLM as a ready‑made front end for high‑volume, cross‑doc data extraction work where manual scripting might otherwise be required.