Gemini 3.1 Pro hits 77.1% ARC-AGI-2 – $2/$12 MTok pricing holds
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
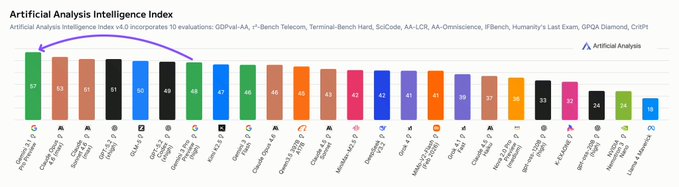
Google/DeepMind shipped Gemini 3.1 Pro as a global rollout across Gemini app, AI Studio (preview API), Vertex AI, and NotebookLM tiers; launch framing is reasoning-first with a claimed 77.1% on ARC-AGI-2 and broad distribution via third-party pickers (Perplexity, OpenRouter). AI Studio cards show pricing unchanged at $2/$12 per 1M input/output tokens up to 200k context (then $4/$18), plus a Jan 2025 knowledge cutoff; Artificial Analysis ranks the preview #1 on its Intelligence Index at 57, saying the harness run consumed ~57M tokens and cost $892, with a reported hallucination-rate drop ~88%→50% on AA-Omniscience, but these are harness-dependent and not yet corroborated by independent end-to-end task suites.
• Builder UX/capacity: early testers report “Canvas” gating for runnable code in the web UI; launch-day latency shows up as ~5-minute generations plus capacity errors.
• Claude Code 2.1.49: adds --worktree isolation and background-agent kill controls; prompt footprint reportedly down 15,248 tokens.
• OpenAI surfaces: ChatGPT Code Blocks adds in-chat editing + live previews; separate UI leaks hint at “Codex Security” malware-analysis workflows, details still thin.
Top links today
- Gemini 3.1 Pro launch blog post
- Google AI Studio for Gemini API
- Gemini 3.1 Pro Preview on OpenRouter
- Claude in PowerPoint announcement
- ChatGPT interactive Code Blocks update
- Artificial Analysis model page for Gemini 3.1 Pro
- OpenClaw GitHub repository
- pi_agent_rust agent harness repository
- Cursor agent sandboxing technical writeup
- Next.js version-matched docs for agents
- Gemini 3.1 Pro Preview on Replicate
- State of Generative Media report by fal
- Jina embeddings v5 text announcement
- Team of Thoughts multi-agent paper
- Vercel AI Gateway video generation docs
Feature Spotlight
Gemini 3.1 Pro ships: big reasoning jump + rollout across developer surfaces
Gemini 3.1 Pro’s jump in reasoning + agentic coding (e.g., 77.1% ARC-AGI-2) and rapid rollout across AI Studio/Vertex/app surfaces reshapes default-model choices for builders, especially at $2/$12 per Mtok pricing.
High-volume story today: Google/DeepMind shipped Gemini 3.1 Pro/Preview and pushed it across AI Studio, Vertex, Gemini app/NotebookLM, and multiple third-party gateways—plus lots of early “does it actually code” smoke tests. Excludes non-Gemini tool updates which are covered elsewhere.
Jump to Gemini 3.1 Pro ships: big reasoning jump + rollout across developer surfaces topicsTable of Contents
🧠 Gemini 3.1 Pro ships: big reasoning jump + rollout across developer surfaces
High-volume story today: Google/DeepMind shipped Gemini 3.1 Pro/Preview and pushed it across AI Studio, Vertex, Gemini app/NotebookLM, and multiple third-party gateways—plus lots of early “does it actually code” smoke tests. Excludes non-Gemini tool updates which are covered elsewhere.
Gemini 3.1 Pro ships and starts rolling out across app + API surfaces
Gemini 3.1 Pro (Google DeepMind/Google): Following up on launch watch—imminent-drop chatter—Google says Gemini 3.1 Pro is now rolling out globally in the Gemini app with higher limits on Google AI Pro/Ultra plans, with developer access via Gemini API in AI Studio (preview) and enterprise availability via Vertex AI, per the rollout note in rollout post and the launch blog post.

The release framing is reasoning-first, anchored by 77.1% on ARC-AGI-2 (claimed as >2× Gemini 3 Pro) in the announcement thread DeepMind thread.
• Access points: Gemini app model picker now exposes a dedicated “Pro” option for 3.1 Pro, as shown in model picker UI; the model is also showing up across third-party surfaces like Perplexity Pro/Max in their picker Perplexity model picker and OpenRouter listings for gemini-3.1-pro-preview OpenRouter model page screenshot.
• API specs: AI Studio’s model card indicates the same pricing tiers as Gemini 3 Pro—$2/$12 per 1M input/output tokens (≤200k context) and $4/$18 (>200k)—and a Jan 2025 knowledge cutoff, as shown in pricing screenshot and AI Studio model card.
Launch messaging emphasizes “preview” / validation via real usage; early reports of capacity constraints show up elsewhere in today’s feed (see separate topic).
Artificial Analysis ranks Gemini 3.1 Pro Preview #1 on its Intelligence Index at lower run cost
Gemini 3.1 Pro Preview (Artificial Analysis): Artificial Analysis says Gemini 3.1 Pro Preview tops its Intelligence Index at 57, 4 points ahead of Claude Opus 4.6 (max), while keeping pricing at $2/$12 per 1M input/output tokens (≤200k), as summarized in index breakdown and reiterated in cost comparison.
Their writeup emphasizes token/cost efficiency: Gemini 3.1 Pro Preview used ~57M tokens to run the index and cost $892 vs $2,486 (Opus 4.6 max) and $2,304 (GPT-5.2 xhigh), per the cost details in index breakdown and cost comparison.
• Hallucination reduction signal: multiple posts cite a major drop in AA-Omniscience hallucination rate (reported ~88% → 50%), framed as “competitive with Claude,” as shown in hallucination chart and discussed again in index breakdown.
• Benchmark mix caveat: builders are already pointing out that “agentic real-world task” rankings don’t fully match the index ordering (e.g., GDPval-AA), so treat leaderboard deltas as harness-dependent, as suggested by the commentary in index breakdown and critiques elsewhere today.
Net: today’s most repeated engineering-relevant claim is not only raw scores, but that Gemini 3.1 Pro’s improvements arrived without a pricing jump and with fewer tokens consumed at high reasoning settings.
Early Gemini 3.1 Pro usage: Canvas is the switch for runnable code, and launch-day latency is real
Gemini 3.1 Pro (Builder experience): Early hands-on usage reports cluster around (a) a UI toggle that changes whether Gemini will actually build/run code, and (b) launch-day throughput issues (multi-minute generations, capacity errors) despite strong outputs when it does run.

• Canvas requirement for runnable artifacts: Ethan Mollick reports that on Gemini web UI you need to select the “Canvas” tool for code execution and interactive builds—otherwise it “doesn’t even want to write code,” per Canvas tip.
• Launch-day latency/capacity: Simon Willison reports an “excellent” animated SVG result but it took ~5 minutes and came with capacity errors, as described in SVG latency note and expanded in his writeup.
• Smoke tests builders are using: posts repeatedly probe Gemini 3.1 Pro with “one-shot” UI/code generation tasks (animated SVGs, webOS clones, shader-heavy 3D scenes) as fast capability checks, e.g. an animated ghost-hunter SVG example in SVG demo and a photorealistic ocean shader prompt in ocean sim demo.
The dominant mood is excited but operationally cautious; representative phrasing includes “you have to select the ‘Canvas’ option” in Canvas tip and “took over 5 minutes… capacity” in SVG latency note.
🧰 Claude Code CLI 2.1.49: worktrees, background control, and prompt/system changes
Today’s Anthropic-side tooling news is centered on Claude Code CLI 2.1.49: new isolation mechanics, background-agent controls, and substantial system prompt diffs. Excludes Gemini 3.1 Pro story (feature).
Claude Code 2.1.49 adds git worktree isolation for sessions and subagents
Claude Code CLI 2.1.49 (Anthropic): The CLI adds a new --worktree / -w flag to start Claude inside an isolated git worktree, and extends subagent isolation to support a worktree mode as well, according to the system prompt changes. This is aimed at reducing “agent touched my repo” risk by defaulting work into a throwaway branch/worktree rather than your main checkout.
This also tightens the mental model for multi-agent runs: each worker can operate in a clean, bounded workspace with a normal git boundary instead of ad-hoc temp directories, as described in the system prompt changes.
Claude Code 2.1.49 adds ConfigChange hook for auditing or blocking settings edits
Claude Code CLI 2.1.49 (Anthropic): A new ConfigChange hook event fires when configuration files change during a session, enabling enterprise audit/controls around live settings edits, as described in the CLI changelog.
The same drop also strengthens managed-settings enforcement: disableAllHooks now respects the managed settings hierarchy, so non-managed settings can’t disable managed hooks set by policy, per the CLI changelog.
Claude Code 2.1.49 adds Ctrl+F to kill background agents, fixes Ctrl+C/ESC edge cases
Claude Code CLI 2.1.49 (Anthropic): Background agent control gets a new Ctrl+F keybinding to kill background agents with a two-press confirmation, and the long-standing “Ctrl+C/ESC ignored while idle” behavior is addressed by making a double-press within 3 seconds kill all background agents, per the CLI changelog.
This is a workflow fix, not a model fix. It reduces the cost of spawning background work because you can reliably regain control when a background run goes sideways.
Claude Code 2.1.49 rewrites tool policy and removes some prior injection-handling rules
Claude Code CLI 2.1.49 (Anthropic): Tooling rules in the system prompt were reworked: the “tool permission + injection-handling system rules” are removed, and tool usage policy is rewritten to prefer Task for search, as summarized in the system prompt changes.
One concrete behavior-level change called out is WebFetch guidance: authenticated URLs should require ToolSearch first, per the system prompt changes.
Claude Code 2.1.49 system prompt pushes “professional objectivity” and bans time estimates harder
Claude Code CLI 2.1.49 (Anthropic): The system prompt gets explicit tone policy changes: a new “professional objectivity” directive (“prioritize technical accuracy… disagree when necessary”) and a strengthened “no time estimates” rule, as shown in the system prompt changes.
It also reinforces “CLI voice” constraints (no emojis unless asked, concise answers, and “don’t use tools as communication”), per the same system prompt changes.
Claude Code 2.1.49 cuts prompt tokens by 15,248 and changes prompt composition
Claude Code CLI 2.1.49 (Anthropic): ClaudeCodeLog reports a material prompt footprint reduction—total prompt tokens down 15,248—alongside notable prompt/string churn (+263/-233 files), as detailed in the prompt token diff.
The same breakdown notes a big composition shift (system tokens up; “system-data” removed), plus model-selection guidance narrowed to Opus 4.6, per the prompt token diff.
Claude Code 2.1.49 lets plugins ship default settings via settings.json
Claude Code CLI 2.1.49 (Anthropic): Plugins can now include a settings.json to provide default configuration, which changes how plugin authors can distribute “works out of the box” experiences, as noted in the CLI changelog.
Related quality-of-life: plugin enable/disable now auto-detects scope when --scope isn’t specified, instead of always defaulting to user scope, per the same CLI changelog.
Claude Code 2.1.49 patches long-session WASM memory growth in parsing and layout
Claude Code CLI 2.1.49 (Anthropic): The release calls out multiple long-running-session fixes where WASM memory would grow without bound, including periodically resetting the tree-sitter parser and addressing Yoga WASM linear memory not shrinking, as listed in the CLI changelog.
This is a stability patch that matters most for “leave it running all day” agent workflows. It’s also one of the few changes here that directly targets crash/OOM dynamics rather than UX.
Claude Code 2.1.49 reduces startup overhead with MCP auth caching and batched token counts
Claude Code CLI 2.1.49 (Anthropic): Startup performance is tuned by caching authentication failures for HTTP/SSE MCP servers (avoiding repeated connection attempts) and batching MCP tool token counting into a single API call, as outlined in the CLI changelog.
It also reduces unnecessary API calls during -p non-interactive startup, per the same CLI changelog.
Claude Code 2.1.49 adds “did you mean” path suggestions for file-not-found errors
Claude Code CLI 2.1.49 (Anthropic): A practical reliability tweak: when the model “drops the repo folder” and produces a wrong path, file-not-found errors now suggest corrected paths, as called out in the CLI changelog.
This doesn’t eliminate hallucinated paths. It shortens the recovery loop by turning a dead-end error into a likely-fixable edit/read retry path.
🧩 OpenAI surfaces: interactive Code Blocks, Codex packaging, and product signals
OpenAI-related chatter is mostly about developer UX and product surface area: interactive Code Blocks in ChatGPT, Codex plan/limits discussions, and security/product UI hints. Excludes Gemini 3.1 Pro story (feature).
ChatGPT adds interactive Code Blocks for editing and previewing code in chat
ChatGPT Code Blocks (OpenAI): Code Blocks in ChatGPT are now interactive—users can write, edit, and preview output in-place, including split-screen review and a full-screen editor, as shown in the feature demo and reiterated in the game example. This pushes ChatGPT closer to a lightweight “REPL + renderer” for shipping small UI prototypes and debugging snippets.

• Diagram + mini-app rendering: OpenAI highlights preview support for diagrams (including Mermaid) and “mini apps” directly in chat, as described in the feature demo and the Mermaid preview clip.
• Release note confirmation: The rollout is also reflected in the ChatGPT release notes referenced by release notes link.
Early examples are heavily HTML/visualization-oriented; there’s no detail here yet on sandbox limits or persistence.
OpenAI’s Aardvark appears to rebrand to Codex Security with malware analysis UI
Codex Security (OpenAI): The agentic security researcher previously referred to as “Aardvark” appears to be rebranded as Codex Security, with a new “Malware analysis” section that supports uploading an archive, kicking off analysis, and retrieving structured reports/artifacts from a single timeline, as shown in the product UI leak.
The UI implies a job-based pipeline (status, verdict, SHA256, runtime, artifacts). The tweets don’t include model details or access requirements, but it’s a clear product-surface expansion beyond coding into security workflows.
ChatGPT web code hints at “Citron Mode” and 18+ gating for sensitive shared chats
ChatGPT web app (OpenAI): Strings in the web client reference a citronModeEnabled setting and a “Sensitive content” warning on shared chats that “may need to verify they’re 18+ to view this,” as surfaced in the code screenshot and echoed via a sharing UI example in the share warning UI. It’s being interpreted as an “adult mode” gate, but the tweets only show UI/strings—not an actual public toggle.
A practical engineering implication is that ChatGPT share links may gain viewer verification flows or restricted visibility flags (the “citron-only” hint), if these strings ship as-is.
Codex usage complaints prompt hints of a plan change beyond the $200 tier
Codex plans (OpenAI): Codex users are reporting hard usage ceilings on the $20 Plus plan (“~1.5 days of work and then blocks you for 3 days”), with the sharpest critique aimed at the $200/month Pro plan, as described in the Plus throttle complaint.
A response from a Codex team member says they’re “working on fixing this” and that users will get the usage they need “in something that is not the current $200 pro plan,” according to the plan response.
No concrete SKU, rate-limit numbers, or timing are in the tweets. It reads like an impending packaging change rather than an immediate limit lift.
Debate flares: “ChatGPT subscription includes Codex” vs observed throttles
Codex access (OpenAI): A pricing/packaging claim says “you only need your ChatGPT subscription to use Codex” and that even Plus has “very generous usage,” attributing this to gpt-5.3-codex being cheaper for SoTA than competitors, as asserted in the subscription claim.
Another thread pushes back on real-world limits and plan economics; one user reports Plus gets blocked after ~1.5 days of work and argues the $200 Pro plan is poor value relative to Claude’s Max tier, per the Plus throttle complaint.
This is still unresolved from the tweets alone; the statements conflict on actual usable weekly throughput for Plus.
OpenAI’s Atlas browser adds “Auto Organize” for extreme tab clutter
Atlas browser (OpenAI): A new “Auto Organize” feature groups and sorts 100+ open tabs using AI categorization, as shown in the browser demo. It’s positioned as a workflow fix for people who use ChatGPT/agents while drowning in research tabs.

The clip shows one-click consolidation into grouped sets. There’s no detail on whether grouping is purely local, synced, or agent-triggerable, but it’s a concrete browser UX change aligned with “research assistant” usage patterns.
Signals point to a Codex Windows app, alongside working Codex CLI on Windows
Codex on Windows (OpenAI): A Windows screenshot of the Codex CLI shows “OpenAI Codex (v0.104.0)” running with model selection set to “gpt-5.3-codex xhigh,” including a note about “2x rate limits until April 2,” as shown in the Windows CLI screenshot. Separate chatter speculates that a dedicated Windows app may be imminent, per the Windows app speculation.
This is mostly signal, not a release note. But it does indicate that Windows is a first-class target for the Codex “app” surface, not only the CLI.
OpenAI commits $7.5M to fund independent AI safety mitigations research
AI Security Institute Alignment Project (OpenAI): OpenAI announced a $7.5M commitment to the AI Security Institute’s Alignment Project to fund independent research on safety mitigations, as stated in the funding commitment.
No program structure (RFP vs direct grants), timelines, or evaluation criteria are in the tweets provided here. The notable part is that it’s framed as support for independent mitigations research rather than an internal-only effort.
🧪 Agent runtime platforms: isolated compute, sandboxes, and always-on sessions
A set of operational products and infra patterns show up today: isolated cloud compute per agent session, local-agent sandboxing, and parallel environment management. Excludes tracing/observability UI (covered separately).
Airtable launches Hyperagent with per-session isolated compute environments
Hyperagent (Airtable): Airtable announced Hyperagent, positioning it as an “agents platform” where every agent session gets an isolated, full computing environment in the cloud—real browser, code execution, image/video generation, data warehouse access, and “hundreds of integrations,” with one-click deployment into Slack as proactive coworkers, according to the launch post.

• Runtime model: Each session runs in its own cloud environment (explicitly “no Mac Mini required”), which is the core primitive for long-running agents that need deterministic execution and state isolation, as described in the launch post.
• Operational angle: Hyperagent also frames “skill learning” as how teams encode domain methods (e.g., due diligence) so outputs reflect internal process rather than generic templates, per the launch post.
Airtable says they’re onboarding early users now, but details like pricing and resource limits weren’t specified in the tweets.
Cursor ships agent sandboxing across macOS, Linux, and Windows
Agent sandboxing (Cursor): Cursor says it rolled out agent sandboxing across macOS, Linux, and Windows over the last three months—agents can run freely inside a controlled environment and only request approval when stepping outside it, as described in the build post and detailed in the Cursor blog via sandboxing write-up.
• Workflow impact: Cursor reports sandboxed agents “stop 40% less often” than unsandboxed ones (less approval fatigue), per the build post.
• Security posture: The implementation is framed as balancing convenience with limiting blast radius for terminal actions, with OS-specific enforcement under a uniform API, per the sandboxing write-up.
Ramp details its “Inspect” coding agent built on Modal Sandboxes
Modal Sandboxes (Modal + Ramp): Modal published a case study on Ramp’s internal coding agent, Ramp Inspect, claiming it now writes “over half” of merged PRs and runs on Modal Sandboxes, with full dev environments spun up in seconds and “hundreds of sessions in parallel,” per the case study thread and the full write-up in case study.

This is a concrete data point for the “agent runtime platform” category: the differentiator isn’t only model quality, but how quickly you can provision isolated, reproducible environments at scale while keeping execution close to production-like services (DBs, queues, browsers) as described in the case study.
Modal documents Sandbox Snapshots for saving and restoring agent environments
Sandbox Snapshots (Modal): Modal’s sandbox “snapshots” capability was highlighted as a way to capture and restore sandbox state—useful for agents that need persistence or fast resume across runs—via the snapshots docs in snapshots guide.
This is distinct from “run a command in a fresh container”: snapshots imply stateful checkpoints for long-running or iterative agent workflows, including debugging and experiment replay, as described in the snapshots guide.
📊 Claude in PowerPoint + connectors: LLMs move into office artifacts
Anthropic/Claude product updates today focus on office workflows—PowerPoint generation/editing plus connectors to pull context from enterprise data tools. Excludes Claude Code CLI releases (covered separately).
Claude in PowerPoint expands to Pro and adds connectors for data-backed slides
Claude in PowerPoint (Anthropic): Anthropic is rolling Claude in PowerPoint out to the Pro plan and adding connectors so Claude can pull context from other tools directly into slide creation/editing, as announced in the Launch note and detailed on the [feature page] Feature page. This is a step toward “agent inside office artifacts” workflows: instead of pasting data into chat, the model can fetch portfolio/market data (or other connected sources) and generate or modify specific slides in place.
• Pro plan availability: The same PowerPoint-native editing loop (generate a deck, then iteratively revise specific slides/objects while keeping layout/style) is now explicitly available to Pro users, per the Launch note and echoed by the Pro plan confirmation.
• Connector-driven slide pipelines: The example UI shows Claude offering to “Read portfolio data” before creating a “biggest movers” slide, with connectors toggled for sources like S&P Global, Moody’s, LSEG, PitchBook (and Daloopa), as shown in the Launch note.
A common reaction framing this as “stop hand-authoring decks” shows up in the User reaction, but there’s no technical detail yet on which connector APIs are supported beyond what’s visible in the in-product panel.
🦞 OpenClaw + agent harness engineering: releases, runtimes, and security hardening
OpenClaw-adjacent engineering shows up as concrete shipping work: new beta releases, watch companion work, and a Rust re-architecture of an agent harness emphasizing capability-gated extensions. Excludes OAuth policy debate (covered in ecosystem/policy).
OpenClaw iOS gateway can wake backgrounded nodes via APNs
OpenClaw (openclaw/openclaw): The v2026.2.19 beta adds iOS gateway logic to wake disconnected iOS nodes via Apple Push Notifications (APNs) before invoking commands, aiming to reduce background-mode failures; this is called out in the beta announcement with implementation notes in the GitHub release notes.
This is a practical reliability improvement for “always-on” agent deployments where the phone app isn’t foregrounded when a job needs to run.
pi_agent_rust ships a capability-gated agent harness with big perf claims
pi_agent_rust (doodlestein): A Rust “version” of Mario Zechner’s Pi Agent is released, aiming to keep extension ecosystem compatibility while rebuilding the runtime substrate for performance and security; the announcement includes claims like 4.95× faster than Node and ~8×–13× lower RSS at million-token session scales in the release thread, with code and details in the GitHub repo.

• Security model shift: Instead of ambient Node/Bun filesystem access, JS extensions run in embedded QuickJS behind typed hostcalls with capability gating, policy profiles, quotas, and audit telemetry, as described in the release thread.
• OpenClaw relevance: The author notes Pi is used as the core harness inside OpenClaw, so this release is effectively a “drop-in harness substrate” option for OpenClaw-style long-running agent systems, per the release thread.
OpenClaw v2026.2.19 beta focuses on security hardening and fixes
OpenClaw (openclaw/openclaw): A new beta release (v2026.2.19) is out with a tight scope—“mostly security hardening and fixes,” per the beta announcement, with the concrete change list in the GitHub release notes.
This is a maintenance-style release: fewer new surfaces, more reliability and security baseline work. Some of the notable functional additions (Watch + iOS gateway) are called out separately below.
OpenClaw’s “Gateway control plane + markdown state on disk” design gets documented
OpenClaw (architecture pattern): A detailed “how it’s built” explanation frames OpenClaw as a stateful AI control plane: a workspace directory of Markdown files for identity/memory/skills/tool policy, JSONL session transcripts, and a single long-running Gateway process that everything flows through; WhatsApp/Slack/etc. are treated as channel adapters, as summarized in the architecture thread.
This is a concrete reference design for teams building multi-agent systems where “state on disk” is the source of truth and the orchestrator is a durable daemon rather than a per-request wrapper.
OpenClaw adds paired-device management and push notification configuration
OpenClaw (openclaw/openclaw): v2026.2.19 adds new Gateway/CLI commands for managing paired devices (e.g., removing paired entries and handling pending requests), plus updates around push registration and notification-signing configuration; the release framing is in the beta announcement and the full checklist lives in the GitHub release notes.
For teams running multiple endpoints (phone, desktop, watch), this is the unglamorous but necessary device-hygiene layer.
OpenClaw v2026.2.19 includes an early Apple Watch companion app
OpenClaw (openclaw/openclaw): The v2026.2.19 beta includes an early Apple Watch app “if you wanna go digging,” as flagged in the beta announcement and detailed in the GitHub release notes.
The Watch work appears to be in “companion plumbing” territory (inbox UI + notification/command handling), which is the kind of foundation you need before Watch-first agent control loops become realistic.
OpenClaw maintainer recruitment emphasizes security mindset and process-based onboarding
OpenClaw (project ops): The project is looking for maintainers with “running larger projects” experience and a security mindset; the maintainer explicitly asks candidates to follow the documented process rather than replying/DMing, as stated in the maintainers call.
This is a governance signal: the project’s operational scaling is being treated as part of the security posture, not a side quest.
📱 Vibe-coded native apps: Rork Max replaces Xcode (and triggers “App Store flood” discourse)
Rork Max dominated the app-building chatter: browser-based SwiftUI app generation across Apple devices, quick deploy/publish flow, and a wave of demos/tutorials. Excludes Gemini feature story.
Rork Max launches as a browser Swift builder with 1‑click install and App Store publish claims
Rork Max (Rork): Rork announced Rork Max as a web app that generates native Swift apps for iPhone/ Watch/iPad/ TV/ Vision Pro and positions itself as “a website that replaces Xcode,” with “install on device in 1 click” and “publish to App Store in 2 clicks” claims in the launch post launch thread.

The technical bet is that a prompt-driven Swift pipeline can cover not just CRUD apps, but AR/3D experiences—Rork explicitly name-checks “Pokémon Go with AR & 3D” and shows rapid code generation plus multi-device previews in the launch montage launch thread.
• Stack and positioning: The launch frames Max as “Powered by Swift, Claude Code & Opus 4.6,” anchoring it to a top-tier coding model plus an agentic harness rather than “template + snippets” generation launch thread.
• Proof points used in marketing: Rork’s examples include a Minecraft clone and a prompt-to-world generator, used as evidence that Max can produce playable 3D content rather than static UI launch thread.
Early reactions from investors/early testers amplify autonomy claims (e.g., “build almost any app idea… completely autonomously”) in the early-access post early access reaction, but there isn’t an independent eval of build correctness or App Store submission reliability in these tweets.
Rork Max walkthrough frames “Pokémon Go in hours” as a repeatable build recipe
Rork Max (Rork): Rork followed the launch with a longer walkthrough that tries to make the headline claim concrete: a recorded tutorial on rebuilding Pokémon Go mechanics (AR/3D) quickly, positioned as compressing a multi-year mobile build into hours tutorial clip.

In the same thread, Rork stacks additional “can it do X?” examples—Apple Watch, Vision Pro games, AR push-up tracking via on-device Vision, and “screen-blocking” apps—trying to show breadth across Apple-specific frameworks (widgets, Live Activities, Siri intents) as part of the same prompt-to-Swift workflow expanded examples.
• Demos as capability probes: The original launch post also points to a Minecraft clone where a prompt generates a world you can play, used as a stress test for 3D state + rendering rather than UI layout launch thread.
The tutorial is the closest thing in this tweet set to an implementation pattern (“here’s how to do it”), but it still leaves open questions engineers will care about—signing, entitlements, privacy prompts, and “what breaks when you go off the happy path.”
Rork Max triggers “Apple will sherlock this” and App Store flood predictions
Rork Max adoption signal: The community reaction quickly moved from demos to platform dynamics—one widely shared take predicts Apple will “acquire this or sherlock it within 18 months,” explicitly framing the product as “the fastest path from idea to app” acquire or sherlock claim.
A second cluster of reactions focuses on supply-side consequences: that low-friction native app generation could “flood” the App Store and compress the advantage of traditional Swift/Xcode expertise, as voiced in the “App Store is about to be FLOODED” repost flood prediction.
These are directional signals, not measurements—no tweet here quantifies actual submission volume or review throughput changes—but they explain why Rork Max is getting treated as more than “another app generator” in today’s discourse.
🧭 Coding workflow patterns: context discipline, “apps are dead”, and prompt-caching-first design
Practitioner discourse today is heavy on workflow: bespoke software replacing app stores, context engineering tactics, and the ergonomics problems that show up with agentic coding. Excludes specific product release notes.
Karpathy argues the app store model breaks when agents can improvise custom apps
Bespoke personal apps: Andrej Karpathy describes a shift from “download an app” to “generate the tool you need right now,” after vibe-coding a custom cardio experiment dashboard that pulled treadmill data from a reverse‑engineered API and shipped as ~300 LOC in about an hour, per the Cardio dashboard thread. The claim is not that everything is easy today (he lists unit bugs and calendar mismatches), but that the iteration loop is collapsing from hours to minutes, and the app itself becomes disposable.
He frames the engineering consequence as a new default: “highly custom, ephemeral apps” assembled by LLM glue, where the limiting factor is less app discovery and more integrating your own context/data/services into something the agent can wire up quickly, as laid out in the Cardio dashboard thread.
“AI-native CLI” becomes the bottleneck for agentic integration
AI-native CLIs: A recurring workflow claim today is that integration friction—not model quality—is the blocker, captured by the line “99% of products/services still don't have an AI-native CLI yet,” as quoted in AI-native CLI quote and argued in detail by Karpathy in the Cardio dashboard thread. The point is that agents are forced to scrape HTML docs, click UIs, or reverse engineer APIs, which turns “1 minute” automations into “1 hour” debugging.
Karpathy’s framing is that vendors should re-orient around “sensors & actuators with agent-native ergonomics,” where the UI is optional and the canonical interface is an API/CLI that an agent can call reliably, as described in the Cardio dashboard thread.
A Claude Code contributor says agents must be designed for prompt caching first
Prompt caching as a design constraint: A Claude Code contributor claims “you fundamentally have to design agents for prompt caching first,” because “almost every feature touches on it,” per the Caching-first claim. This is a workflow-level point: the harness architecture (what goes in stable prefixes, what changes per turn, where you branch subagents) determines whether you get cache hits—or pay full-price every turn.
That framing lines up with the “automatic caching” docs pattern Anthropic is now pushing—set caching at the request level and let the system apply the breakpoint, as shown in the Docs screenshot and detailed in the Prompt caching docs.
Automatic prompt caching lands, shifting effort to prompt template structure
Automatic prompt caching: An API-side change means developers “no longer have to set cache points” manually, according to the API caching update. The operational implication is that caching becomes less about per-request plumbing and more about maintaining stable prompt prefixes so the cache can actually hit.
The matching doc pattern is “single cache_control at the top level” with the system placing the breakpoint automatically, as shown in the Docs screenshot and spelled out in the Prompt caching docs.
Builders describe losing codebase familiarity as prompting becomes the default
Distance-from-code risk: One developer describes a cycle where prompting replaces navigation because it’s lower friction, but that “distance… between you and the codebase” accumulates until you “can’t even reliably @ a precise file,” as written in the Agentic programming reflection. It’s a productivity win, but it changes how ownership and debugging feel.
A concrete failure mode shows up in the “parallel agent psychosis” anecdote: a feature was effectively lost because work happened in a transient location, then recovered by extracting it from agent session logs, as described in the Lost feature recovery. The common thread is that the agent adds throughput, while humans become more dependent on traceability artifacts (sessions, logs, worktrees, reproducible state).
🧷 Skills & MCP plumbing: turning docs into reusable agent capabilities
Today’s “extensibility” content is about packaging repeatable capabilities: skills generators, structured skill graphs, and repo-local workflows. Excludes general SDKs and model launches.
Firecrawl ships a docs-to-skill generator for Claude Code workflows
Firecrawl (Firecrawl): Firecrawl introduced a Skill Generator flow that converts a tool’s documentation URL into an agent Skill, positioned as a way to make “any tool with docs” usable by agents without manual skill authoring, as shown in the Skill generator demo.

The mechanism is exposed as a Claude Code plugin command—install the plugin, then run /firecrawl:skill-gen <docs_url> per the Skill generator demo—and it also supports bundling multiple generated skills together (they call out examples like Polar and Resend) in the same workflow, as described in the Skill generator demo.
HyperGraph proposes “skill graphs” instead of one giant SKILL.md
HyperGraph (Hyperbrowser): HyperGraph is being pitched as a way to turn technical topics into navigable, linked skill graphs so agents can focus on relevant nodes rather than ingesting a single large skill file, as described in the HyperGraph overview.

This is framed as a context-control primitive: the graph structure is meant to reduce “dump everything into one skill file” behavior and instead route the agent through smaller skill nodes, per the HyperGraph overview.
Repo-local /do-work skills as a lightweight alternative to bloated AGENTS files
Repo workflow packaging: A practical pattern is to keep a repo-local /do-work skill that encodes the author’s default loop—Plan → Explore → Build → Run tests/types → Commit—and then hang optional sub-routines off separate markdown files so they don’t crowd context, as laid out in the Repo skill pattern.
The operational detail that matters is the division of responsibilities: the repo’s AGENTS file stays nearly empty, while the skill file becomes the reusable entrypoint for consistent agent behavior across tasks, according to the Repo skill pattern.
🛠️ Dev tooling upgrades: agent-friendly docs, model switching UX, and editor integrations
Assorted developer tooling updates that help teams ship with agents: version-matched docs, unified gateways, editor integrations, and terminal UX improvements. Excludes AI model releases.
Next.js canary installs now include version-matched docs for agents
Next.js (Vercel): Next.js canary installs will ship with version-matched docs embedded alongside the project, explicitly to give coding agents accurate context on new/changed APIs; the team reports ~20% higher success rates in evals when agents have those docs locally, per the canary install demo.

• How you get it: the rollout is via npx create-next-app@canary, as shown in the canary install demo.
This is a direct “agent context drift” mitigation: fewer failures from reading stale online docs or guessing API shapes.
Vercel AI Gateway adds video generation and a generateVideo API in AI SDK 6
AI Gateway (Vercel): Vercel added video generation support to AI Gateway alongside a new generateVideo API in AI SDK 6, positioning it as a model-swap surface for apps/agents that want to route across providers, as announced in the gateway video support and shown in the generateVideo demo.

• Promo window: Grok Imagine Video and Grok Imagine Image are free through Feb 25 via AI Gateway, per the gateway video support and the Grok on gateway note.
This lands as an infra/UX change more than a model release: it’s about unifying “text ↔ media” calls behind one gateway surface.
keep.md pushes “markdown bookmarks as an API” for feeding agents saved context
keep.md (keep.md): keep.md is being used as a “bookmarks → markdown → API” pipeline so agents can ingest saved sources (including YouTube transcripts and comments) for recurring research automation, as shown in the YouTube ingestion demo and described in the product page.

• Agent-facing use cases: the pitch is competitor tracking, finding unsolved problems, and automating content research, per the YouTube ingestion demo and the follow-on feature ideas thread.
The key idea is not “another bookmarking app”; it’s making saved context addressable and readable by tools without screen scraping.
Warp adds /models fuzzy switching for faster model swaps
Warp (Warp.dev): Warp added /models to fuzzy-find and switch LLMs without using the mouse; the UI also includes comparison charts and supports binding a custom keyboard shortcut for “Spotlight-style” swapping, as shown in the model switching demo.

This is a workflow-speed improvement for teams that are constantly swapping between “fast” and “thinking” models while iterating in terminals.
Zed adds Gemini 3.1 Pro support for subscribers and BYOK users
Zed (Zed Industries): Zed added Gemini 3.1 Pro support; Pro subscribers are told to restart Zed, while BYOK users need to update to Stable v0.224.7 or Preview v0.225.2, as described in the Gemini support note.
This is a practical “model availability in-editor” change: it reduces friction to standardize on a new model across a team that already lives in Zed.
Zed gets official GitHub Copilot support through a partnership
Zed (Zed Industries): Zed announced official support for GitHub Copilot via a partnership, formalizing Copilot integration in the editor as stated in the partnership announcement.
This is a distribution and maintenance signal: fewer “best-effort” integrations and more vendor-supported behavior for Copilot users inside Zed.
Warp improves terminal tab density and contrast
Warp (Warp.dev): Warp updated terminal tabs to be larger (more detail visible) and increased color contrast for colored tabs, as shown in the tab UI demo.

This is minor on paper, but it targets the real issue in agent-heavy terminal workflows: many concurrent sessions and lots of context switching.
🧾 Tracing & debugging agents: making runs searchable, comparable, and cheaper
Observability content today centers on trace navigation UX and verification tools for agent-browser workflows. Excludes benchmark leaderboards (covered separately).
Raindrop’s Trajectory Explorer makes agent traces searchable and failure-shaped
Trajectory Explorer (Raindrop AI): Raindrop is pitching a new trace UI that treats an agent run as a “trajectory” you can search by intent (e.g., “show me traces where edit failed 5 times because it didn’t read the file”) instead of scrolling nested spans, as described in the trajectory launch RT and expanded with new visualization modes in the duration view walkthrough.
• Two visualization modes: output-size helps spot heavy tool calls; duration mode is flame-graph-like but grouped by tool so slow reads/edits jump out quickly, as shown in the duration view screenshot.
• Workflow implication: this is explicitly aimed at making “what actually happened?” answerable faster than raw trace JSON; it also frames recoveries/errors as first-class navigation targets, per the duration view walkthrough.
agent-browser adds snapshot diffs and pixel-level visual regression for cheaper verification
agent-browser (ctatedev): agent-browser added a diffing feature to compare pages via DOM-ish “snapshot diffs” and pixel-level visual regression, positioning it as a way to verify web actions with “up to 90% fewer tokens,” as announced in the diffing release post.
• Snapshot diff UX: the tool shows structural diffs like textbox value changes and disabled buttons (useful for asserting state transitions in agent runs), as shown in the CLI diff output.
• Visual regression option: pixel diffs are positioned for catching UI changes and regressions when snapshot text misses canvas/icon-only UI, per the diffing release post.
Cursor Debug Mode essay: agents should instrument the code they run by default
Cursor Debug Mode (Cursor): A writeup on Cursor’s Debug Mode argues the next step for coding agents is “always instrumenting the code they’re running,” framing observability as part of the agent UX rather than an afterthought, as described in the debug mode essay teaser.
• Core claim: treating runtime signals (traces, spans, errors) as agent-readable context could reduce the “guess, rerun, hope” loop in long agent sessions, per the debug mode essay teaser.
This is presented as a design direction more than a shipped feature spec; details beyond the thesis aren’t in the tweets.
📏 Benchmarks & eval methodology: what to trust (and what to ignore)
Evals discussion today includes new benchmark releases, methodology disputes, and domain-specific gaps (e.g., docs parsing vs reasoning). Excludes Gemini 3.1 Pro leaderboard victory (feature).
ValsAI releases MedScribe + MedCode to separate “note quality” from “coding correctness”
MedScribe + MedCode (ValsAI): ValsAI says clinical workflows need two different evals—one for narrative documentation and one for structured billing/coding—because models that write plausible notes can still fail rule-bound coding tasks, as framed in the benchmark announcement and follow-up analysis in the results summary.
• Documentation looks mature: they report SOAP-note generation accuracy hitting 88% for GPT-5.1 and 87% for Claude Opus 4.6, per the results summary.
• Coding remains brittle: they report best medical coding performance at 56% (Gemini 3 Flash), with particular weakness on mental health diagnoses, according to the results summary.
The split matters because teams can stop treating “good narrative notes” as evidence of “safe automation” for billing or downstream structured systems.
SkillsBench finds curated skills boost agents; self-generated skills don’t on average
SkillsBench (research): A new benchmark argues “skills” are only net-positive when curated—reporting a +16.2 percentage point average pass-rate lift from curated skills, while self-generated skills provide negligible or negative benefit, as summarized in the paper takeaway.
The operational implication is that “generate a skill file from docs” is not a solved step yet; the paper’s core claim is that short, human-condensed procedures beat long model-summarized instructions in practice, as argued in the paper takeaway.
GDPval-AA gets pushback: “public questions + model judge” isn’t a headline agent eval
GDPval-AA (eval methodology): A critique argues GDPval-AA shouldn’t be treated as a flagship “real-world agent” benchmark because it uses public GDPval questions with a general model as judge—missing the expert judging that made GDPval meaningful—per the benchmark rant and broader “2025 agent evals are dated” framing in the agent product comment.
The same thread notes multiple “knowledge” benchmarks are saturating while ARC-style tests remain hard to interpret, reinforcing that leaderboard movement can hide measurement problems, as stated in the benchmark rant.
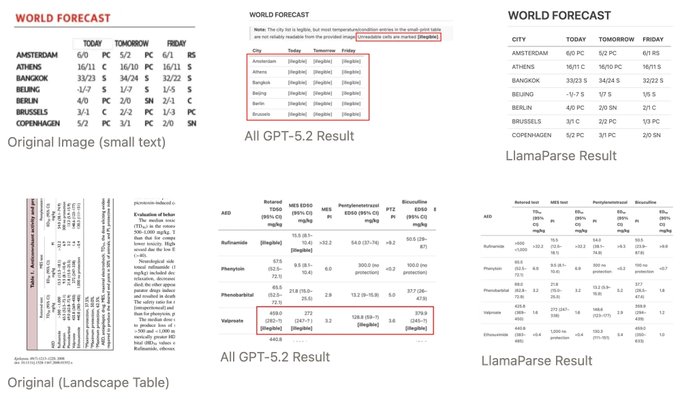
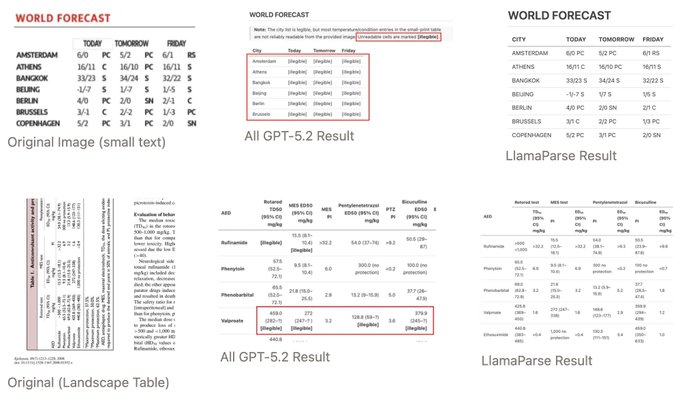
Higher “thinking” settings didn’t improve document understanding on OmniDocBench
OmniDocBench reasoning-mode experiment (LlamaIndex): LlamaIndex reports that increasing “thinking” on GPT-5.2 didn’t improve doc understanding scores, and can degrade fidelity to input structure (e.g., table extraction), as shown in the benchmark writeup.
The example contrasts GPT-5.2 outputs that hedge with “illegible” cells or drift structurally versus a dedicated parser result, reinforcing that “reasoning tokens” and “document parsing quality” are not the same knob, per the benchmark writeup.
Benchmark-heavy launches trigger skepticism about what labs optimize for
Benchmarks as product signaling: Some builders say a launch framed primarily around benchmark wins is itself a negative signal about model usefulness and lab direction, as stated in the benchmarks skepticism.
A key rebuttal is that “benchmarks don’t matter” still needs a replacement metric—otherwise it becomes “nothing”—as argued in the metric substitution reply.
🧪 Research & training methods: multi-agent test-time scaling, retrieval models, and reasoning control loops
Research threads today span multi-agent orchestration methods, retrieval model pretraining, and new reasoning strategies that trade long CoT for iterative summarize/continue loops. Excludes product announcements.
ColBERT-Zero argues full multi-vector pretraining beats KD-on-top recipes
ColBERT-Zero (LightOn + EPFL): A new paper and companion blog argue that the common recipe “take a strong dense retriever, then do a small KD step to get ColBERT” underperforms doing large-scale pretraining directly in the multi-vector (late-interaction) setting; the work is linked in the ArXiv link and discussed as an “independence day from dense vectors” moment in the Community reaction.
• Training recipe nuance: The thread claims a supervised contrastive phase before KD gets close to full pretraining at ~10× lower cost (99.4% of performance), plus that prompt alignment between pretraining and finetuning is “non‑negotiable,” as detailed in the Training phases thread.
• Ecosystem signal: The community reaction frames this as LI-first pretraining becoming practical again, per the Retrieval ecosystem note.
The tweets don’t include a canonical results table image; the only visual here is a celebratory meme, so treat performance claims as provisional until you inspect the paper artifacts directly.
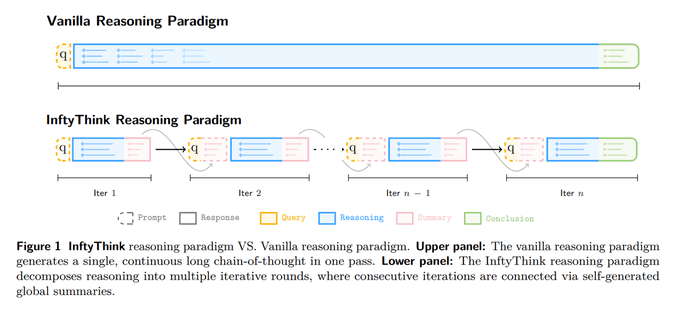
InftyThink+ trains models to reason in summarize-and-continue loops
InftyThink+ (ZJU + Ant Group): A new reasoning-control strategy replaces one long chain-of-thought with iterative “think → summarize → continue” rounds, trained with a supervised cold start followed by trajectory-level RL; the loop structure is diagrammed in the Loop diagram thread.
• Claimed trade-off: The thread reports +21% accuracy on AIME24, +9% vs long-CoT RL, and 32.8% lower reasoning latency, as stated in the Loop diagram thread.
• Key constraint: Each iteration only sees the original question plus the latest summary (not full prior reasoning), which is called out in the Mechanics note.
This sits in the same family as “compress reasoning state” approaches, but with the summary explicitly trained as the state interface rather than relying on ad-hoc self-compression.
Team of Thoughts proposes heterogeneous model teams with orchestrator calibration
Team of Thoughts (Imperial + Microsoft Research): A new multi-agent test-time scaling framework argues that “all agents the same model” is leaving performance on the table; it explicitly orchestrates heterogeneous models and adds two mechanisms—an orchestrator calibration step to pick the best coordinator model, and a self-assessment protocol where tool agents rate their own domain proficiency, as described in the Paper summary and shown in the
.
• Reported deltas: The authors claim 96.67% on AIME24 vs 80% for homogeneous baselines, plus 72.53% on LiveCodeBench vs 65.93%, per the Paper summary.
The key engineering implication is that “router policies” (who coordinates, who tools) become a first-class training-time and inference-time knob, not just a product routing layer.
Google Research separates “missing knowledge” vs “can’t recall” failures
WikiProfile + “Empty shelves or lost keys?” (Google Research): A new paper argues that frontier LLMs mostly encode facts, but often fail to recall them—so many “hallucinations” are better seen as retrieval/access failures (“lost keys”) rather than missing knowledge (“empty shelves”); this framing and the proposed WikiProfile benchmark are introduced in the Paper screenshot and available via the ArXiv paper.
• What’s new vs typical factuality evals: The paper proposes profiling at the level of facts (encoded vs recallable vs recallable-with-thinking) rather than question-level accuracy, per the Paper screenshot.
In practice, this points to a research gap: retrieval-style scaffolds and reasoning budget can improve correctness without changing the model’s underlying “knowledge,” but you need instrumentation to tell which failure mode you’re in.
⚖️ Auth & ecosystem policy fallout: subscription OAuth confusion and enforcement signals
Continues yesterday’s OAuth/tooling shock, but today’s content is about on-the-ground enforcement symptoms and developer uncertainty (denials, bans, partial walk-backs). Excludes OpenClaw technical releases (covered separately).
Anthropic docs still prohibit OAuth use outside Claude surfaces, and 401s persist
Anthropic OAuth policy (docs vs behavior): A new round of screenshots shows Anthropic documentation still stating that OAuth tokens from Free/Pro/Max are intended only for Claude Code and Claude.ai, and that using them in other tools “including the Agent SDK” is not permitted, as captured in Policy screenshot.
Enforcement symptom: despite reports of partial walk-backs, some users say they still receive HTTP 401 authentication_error: OAuth authentication is currently not supported, and that any “carve-out” doesn’t work out-of-the-box in their current toolchain, as summarized in Policy screenshot and reiterated in Follow-up note.
Anthropic OAuth fallout turns into a live status poll (denials vs unaffected vs bans)
Anthropic OAuth (consumer plans): Following up on OAuth ban, developers are now explicitly polling for operational outcomes—“Nothing happened”, “I’m getting OAuth denials”, or “My account was banned”—to map enforcement in the wild, as asked in Impact poll. One data point in-thread is that an OAuth token that had failed started working again, per Token works again.
This is still noisy, but it’s a concrete shift from policy reading to measuring symptoms (auth errors, bans, reversals) across accounts and tools.
🏢 Enterprise distribution & GTM signals: India push, revenue races, and subscription pivots
Business-side AI news today includes major enterprise distribution moves (India infra), subscription strategy pivots, and revenue-growth comparisons between labs. Excludes pure infra hardware/cooling items.
OpenAI launches “OpenAI for India” with Tata, pitching in-country capacity and mass enterprise rollout
OpenAI for India (OpenAI): OpenAI launched its OpenAI for India initiative, citing “more than 100 million weekly ChatGPT users” in India and framing the program around “sovereign AI capabilities” plus enterprise adoption, as described in the launch post linked from OpenAI for India launch. A separate report summary claims OpenAI secured 100MW of AI-ready data center capacity from Tata with plans to scale to 1GW, explicitly positioning it as a way to run advanced models within India for lower latency and data residency/regulatory constraints, per India capacity details.
• Enterprise distribution hook: The initiative calls out deploying ChatGPT Enterprise across “hundreds of thousands” of TCS employees and using Codex to standardize AI-native software development, as stated in OpenAI for India launch.
Operationally, this reads like a GTM move where distribution (Tata/TCS) and locality (in-country inference) are being treated as product features, not procurement footnotes.
Epoch projects Anthropic could surpass OpenAI’s annualized revenue by mid‑2026
Revenue race (Epoch AI): Epoch AI published a projection that Anthropic has been growing faster since both firms hit $1B annualized revenue (labeled 10×/year vs 3.4×/year) and “could overtake OpenAI by mid‑2026,” while explicitly flagging that extrapolating short trends is aggressive, as shown in ARR crossover chart.
• New nuance: Epoch adds that Anthropic’s growth rate may already be slowing—“since July 2025… 7×/year rather than 10×,” per Growth slowdown note.
This is mainly an analyst signal about how quickly frontier-lab revenue concentration can flip, which tends to ripple into hiring, pricing power, and enterprise contracting strategy.
Perplexity says it’s moving away from ads and doubling down on subscriptions and enterprise
Perplexity (Perplexity AI): Perplexity executives say they’re pivoting away from advertising—arguing ads in AI answers “damage user trust”—and are instead prioritizing subscriptions and enterprise sales, with reported revenue growth of 4.7× last year to about $200M ARR by Oct 2025, per the strategy summary in Business strategy summary.
The clear GTM implication is that “answer quality + trust” is being treated as incompatible with ads inside responses, while enterprise search positioning (competing with internal tools like Glean) becomes the main expansion vector.
LangChain launches “LangSmith for Startups” with $10k credits and VC distribution
LangSmith for Startups (LangChain): LangChain launched a startup program offering $10,000 in LangSmith credits plus technical sessions and community programming, and it’s explicitly tied to a long list of partner VCs (eligibility: partner‑backed, Series A or earlier), as laid out in Program announcement.

This is a GTM pattern: turning evaluation/observability tooling into a VC‑amplified default, similar to how cloud credits bootstrap early infra choices.
Perplexity opens iOS pre-orders for Comet, its AI assistant browser
Comet (Perplexity AI): Perplexity put Comet up for iOS pre‑order, per App Store pre-order and the linked App Store listing in App Store listing, with the listing indicating a release date of March 11, 2026.
This is a distribution move toward making “AI assistant” a default browsing surface (and a funnel for subscriptions), rather than a separate chat product.
🗣️ Voice agents: experimentation, liability/insurance, and sales automation
Voice-agent updates today are about operating voice systems safely and improving them with controlled experiments, plus enterprise sales automation claims. Excludes creative music generation (covered in gen media).
ElevenLabs adds A/B testing workflow to ElevenAgents with Experiments
ElevenAgents (ElevenLabs): ElevenLabs introduced Experiments, an A/B testing feature for iterating on production voice agents by running controlled traffic splits across agent variants and promoting the winner with version control, as shown in the feature demo.

• What’s testable: The product framing explicitly calls out prompt structure, workflow logic, voice, and personality as experiment dimensions, with the workflow spelled out in the feature demo.
• Ops mechanics: Teams create a new variant, route a slice of traffic, measure impact on business metrics, then promote to production; ElevenLabs ties this to outcomes like CSAT/containment/conversion in the follow-up details and the accompanying feature blog post.
This is a concrete step toward treating voice agents like continuously optimized production systems, rather than “prompt tweaks” done ad hoc.
Cartesia and Simple AI push “autonomous sales” voice agents with conversion claims
Sales voice agents (Cartesia + Simple AI): Cartesia positioned its voice stack as a production-grade foundation for enterprise sales agents, with Simple AI cited as a reference customer and partner in the partnership post.

The concrete claims being circulated: 30% higher conversion/upsell vs human reps, 100× scalability during peak traffic, and millions of production calls; these are presented as vendor metrics in the partnership post rather than as independently audited results. The integration emphasis is on voice naturalness and low time-to-first-token (TTFT) as the main failure mode for sales deployments (robotic voices → drop-off).
Tavus ships Phoenix-4 for real-time “active listening” human avatars
Phoenix-4 (Tavus): Tavus launched Phoenix-4, a real-time human rendering model aimed at making interactive agents feel responsive while listening (not just while speaking), as described in the launch summary.

• Realtime spec: Tavus claims 40fps at 1080p for head-and-shoulders generation, with emotional transitions and micro-expressions, per the launch summary.
• Stack integration: Phoenix-4 is positioned as part of a multi-model “behavior stack” alongside perception (Raven-1) and timing (Sparrow-1), with use cases named as higher-stakes interactions like healthcare/coaching in the launch summary.
For teams building voice agents with a face, the key technical bet here is that “listening reactions” are a first-class model output, not a UI animation layer.
🎬 Generative media & creative tooling: music, video style transfer, and marketing assets
Generative media chatter is still strong today: Google’s music generation, video style-transfer workflows, and AI marketing asset creation. Excludes voice-agent operational tooling (covered in voice agents).
Seedance 2.0 style transfer how-to: reference frames + “All-round reference” prompting
Seedance 2.0 (ByteDance/Jimeng): Following up on v2v tests—the new actionable detail is a reproducible workflow: extract 1–2 frames from a source video, restyle those frames first (they mention Nano Banana Pro), then run Seedance v2v with those images + video as “All-round reference,” using a prompt that explicitly demands frame-by-frame consistency, per the step-by-step in Workflow prompt recipe.
• Reference strategy: Two restyled frames become the “style anchor,” then the full video gets overhauled “including characters and environment,” as described in Workflow prompt recipe.
• Prompt wording to preserve identity: The recipe repeats “character details remain consistent” and “focus on each individual frame,” which is the practical hedge against drift noted in Workflow prompt recipe.
fal’s “State of Generative Media” says infra became the differentiator in 2025
State of Generative Media Volume 1 (fal.ai): fal published its first “State of Generative Media” report, arguing 2025 was defined by release velocity across image/video/audio/3D rather than a single breakout model, as announced in Report launch.
• Infra as the bottleneck: fal’s own slide highlights that teams prioritize cost optimization (58%), model availability (49%), generation speed (41%), reliability/uptime (37%), and security/compliance (34%), as shown in Decision criteria chart.
• Why this matters to builders: the report frames serving readiness—latency, uptime, and cost—as the main differentiator once multiple models are “good enough,” matching the framing in Decision criteria chart.
You can skim the full report directly via the report page.
Lyria 3 early users say non-English vocals finally sound native
Lyria 3 (Google DeepMind): Following up on Lyria 3 rollout—Gemini-integrated music generation—one of the clearest new signals today is multilingual vocal quality: a user reports generating a German song “with no accent” and “perfect” German, calling the lyrics-to-music fit unusually strong for a non-English prompt in the German song example.

This is still anecdotal (not a benchmark), but it’s a concrete capability claim that matters for teams building localized creative tools and ad pipelines, where accent artifacts have been a reliability blocker.
Google Labs adds “Photoshoot” to Pomelli for product-shot generation
Pomelli Photoshoot (Google Labs): Google is now publicly pushing a “Photoshoot” feature inside Pomelli that turns a single product image into multiple brand-style marketing assets, with an initial free rollout limited to the US, Canada, Australia, and New Zealand per the availability callout in Availability clip and the SMB positioning in Early access demo.

The practical implication is that the UI is being packaged as an SMB workflow (product photo → variants) rather than a general image editor, which usually changes how teams should evaluate it: output consistency and template controllability matter more than raw aesthetics.
Netflix threatens “immediate litigation” over Seedance 2.0 outputs
Seedance 2.0 (ByteDance) legal pressure: Following up on studio pressure around copyright blowback, today’s new datapoint is Netflix specifically threatening “immediate litigation” and labeling Seedance 2.0 a “high-speed piracy engine,” with examples cited like Stranger Things finale clips and “Bridgerton Season 4 costumes” in the reporting summarized by Legal threat summary.
From a builder’s standpoint, this is less about who’s right legally and more about product risk: it increases the odds of sudden capability gating, takedowns, or platform-level filtering for workflows that depend on these generators.