OpenAI PostgreSQL scales to 800M users – nearly 50 read replicas
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI published a detailed Postgres scaling write-up for ChatGPT’s backend: a single-primary architecture paired with nearly 50 global read replicas; the system absorbed >10× load growth over the last year; incident patterns include write storms, cache-miss cascades, and MVCC-driven write amplification that can spiral into latency/timeouts. The notable design signal is what’s not there: no “multi-primary everywhere” narrative; instead, replica-fleet engineering to keep core product surfaces alive under bursty, multi-tenant traffic.
• vLLM/UCX leak: vLLM traced unexplained RSS growth to UCX mmap hooks via BPFtrace+gdb; merged mitigation sets UCX_MEM_MMAP_HOOK_MODE=none.
• Enterprise storage pricing: a circulated datapoint claims 30TB TLC SSDs rose ~257% to ~$11,000 and SSDs sit ~16.4× HDD $/TB; directional signal is clear, but procurement multiples are time-sensitive.
• Comfy Cloud: ComfyUI cut unit pricing ~30% (0.39 → 0.266 credits/sec), a rare user-visible infra renegotiation artifact.
Net: infra bottlenecks are shifting from “model choice” to state, storage, and long-tail failure modes; several claims land as operator notes rather than independently benchmarked results.
Top links today
- How Codex agent loop works
- Claude in Excel getting started
- FrontierMath Tier 4 GPT-5.2 Pro result
- vLLM memory leak fix PR
- vLLM infra debugging write-up
- Qwen3-TTS models on Hugging Face
- Qwen3-TTS official blog post
- Qwen3-TTS online demo
- Epoch AI trends dashboard
- LLM-in-sandbox agentic intelligence paper
- AgencyBench paper
- ABC-Bench backend coding benchmark paper
Feature Spotlight
Codex: agent-loop deep dive + next-week launches with “Cybersecurity High” gating
Codex is getting a month of launches starting next week, with OpenAI moving to “Cybersecurity High” and adding cyber-abuse blocks. The agent-loop deep dive reveals the reliability/caching/compaction mechanics behind long-running coding agents.
High-volume cross-account focus on Codex: OpenAI’s technical breakdown of the Codex CLI agent loop, plus Sam Altman signaling a month of Codex launches starting next week alongside tighter cyber-abuse restrictions and a move to “Cybersecurity High.”
Jump to Codex: agent-loop deep dive + next-week launches with “Cybersecurity High” gating topicsTable of Contents
🧰 Codex: agent-loop deep dive + next-week launches with “Cybersecurity High” gating
High-volume cross-account focus on Codex: OpenAI’s technical breakdown of the Codex CLI agent loop, plus Sam Altman signaling a month of Codex launches starting next week alongside tighter cyber-abuse restrictions and a move to “Cybersecurity High.”
OpenAI publishes a deep dive on the Codex CLI agent loop mechanics
Codex CLI (OpenAI): OpenAI published a technical walkthrough of what happens between your prompt and Codex’s output—prompt assembly → model inference → tool execution → feeding observations back into context—framed explicitly as an “agent loop,” as introduced in the Agent loop thread and detailed in the linked Deep dive post. The write-up highlights practical harness details that directly affect long-running coding reliability, including exact-prefix prompt caching to avoid quadratic slowdowns and /responses/compact to keep sessions within the context window, as summarized in the Implementation notes.
• Prompt caching: The post emphasizes cache-friendly prompt construction—especially “exact-prefix” reuse—to keep repeated loop turns from getting disproportionately expensive as tool outputs accumulate, as described in the Implementation notes.
• Compaction semantics: The compact flow is described as producing a replacement item list including an opaque encrypted_content carryover state that “preserves the model’s latent understanding,” which surfaced in the HN compaction excerpt and is echoed in the Implementation notes.
The engineering details here are unusually specific, and they explain why two agent harnesses can feel wildly different even with the same model behind them.
OpenAI says it’s nearing “Cybersecurity High” and will add cyber-abuse restrictions
Preparedness framework (OpenAI): Sam Altman said OpenAI expects to reach the Cybersecurity High level on its preparedness framework soon, describing cybersecurity as inherently dual-use and stating the first mitigations will be product restrictions aimed at blocking explicit cybercrime intent (example phrasing like “hack into this bank and steal the money”), as written in the Altman risk note. Ethan Mollick flags an operational readiness gap—he’d be surprised if most orgs are anticipating the implications—while noting guardrails are presumably part of the plan in the Org readiness comment.
• Mitigation direction: Altman frames an eventual shift toward “defensive acceleration” (helping patch bugs faster) as the primary mitigation once supported by evidence, per the Altman risk note.
The public text doesn’t describe enforcement mechanics (policy filters vs. model fine-tunes vs. tool restrictions), so it’s still unclear how much will land in Codex CLI vs the underlying coding models vs API policy.
Sam Altman signals a month of Codex launches starting next week
Codex (OpenAI): Sam Altman said OpenAI has “exciting launches related to Codex” coming “over the next month,” with the first starting next week, as announced in the Altman teaser and recapped in the Screenshot recap. This is an explicit product cadence signal, not a vague roadmap.
The public details stop at timing and intent in the Altman teaser; there’s no concrete list of features yet, which leaves open whether the first drop is CLI, cloud, IDE integrations, policy gating, or something else.
Codex CLI adds /fork to branch a session without disrupting the main thread
Codex CLI (OpenAI): Codex CLI now supports /fork to branch the current chat so you can try alternatives or ask side questions without changing the main session, as shown in the Fork feature note. This is a small UX addition that directly reduces “try something else” friction in long agent runs.
The screenshot in the Fork feature note shows the command surfaced as an in-CLI suggestion, which implies it’s intended to be used frequently rather than as a hidden power-user feature.
Warp ships first-class setup for GPT-5.2 Codex as a default coding agent
Warp (Warp.dev): Warp announced a partnership to make it easier to set up GPT‑5.2 Codex as the default coding agent in their terminal harness, with explicit tuning for long-running tasks, as stated in the Warp integration post. The integration is positioned as harness-level work (not just model selection), and it points users to the Codex page for getting started.

The visible demo in the Warp integration post centers on terminal-driven execution and testing loops, reinforcing that this is meant for sustained agent runs rather than one-shot completions.
Codex CLI endpoint behavior changes depending on auth mode and local OSS runs
Codex CLI (OpenAI): A surfaced configuration detail shows Codex CLI uses different Responses endpoints depending on how you authenticate: ChatGPT login uses chatgpt.com/backend-api/codex/responses, API keys use api.openai.com/v1/responses, and --oss local runs default to http://localhost:11434/v1/responses (for Ollama/LM Studio), as captured in the Endpoint behavior screenshot. This matters for debugging proxies, routing, and environment parity when moving between local and hosted setups.
The same screenshot in the Endpoint behavior screenshot also calls out that Codex CLI can target other hosted Responses endpoints (e.g., via cloud providers), implying the harness is designed to be endpoint-pluggable rather than tightly coupled to a single OpenAI URL.
Conflicting speculation on whether next week is a model launch or “something else”
OpenAI release speculation: There’s conflicting chatter about what arrives “next week”: one post claims “new OpenAI model(s) next week,” as stated in the Model next week claim, while another asserts OpenAI is not releasing a new model next week and that it’s “something else,” per the Not a model claim. Both claims are being interpreted through Sam Altman’s Codex roadmap tease in the Altman teaser, but neither rumor includes verifiable product artifacts.
The only primary-source statement in this cluster remains the Altman teaser, which is explicit about “Codex” launches but non-specific about whether any involve new model weights.
🧑💻 Claude Code 2.1.19: CLI stability + task-system knobs get reshaped
Continues the Claude Code churn, but today’s concrete delta is v2.1.19: new flags/env vars, crashes fixed (incl non‑AVX CPUs), and task/termination tooling changes. Excludes Codex (covered in feature).
Claude Code 2.1.19 adds an env-var escape hatch for the new Tasks system
Claude Code (Anthropic): v2.1.19 introduces CLAUDE_CODE_ENABLE_TASKS; setting it to false keeps the pre-Tasks behavior, as spelled out in the changelog thread. This is a rollback lever.
The change is framed as temporary, but it’s a practical way to isolate whether new Tasks are behind regressions in long sessions, per the same changelog copy.
Claude Code 2.1.19 reshapes the Task tool around allowed_tools scoping
Claude Code (Anthropic): v2.1.19 changes the Task tool API from naming/teaming/mode controls to explicit tool scoping via allowed_tools, removing fields like name, team_name, and mode, as summarized in the Task schema note. This is a contract change.
The change is also called out at a higher level in the prompt changes, with the underlying diff in the schema diff.
Claude Code 2.1.19 swaps KillShell for TaskStop in task termination
Claude Code (Anthropic): v2.1.19 removes the KillShell tool and adds TaskStop, shifting termination to task IDs (with shell_id still accepted but marked deprecated), as described in the prompt changes and expanded in the TaskStop detail. This changes how harnesses and wrappers should stop long-running work.
A diff view is available in the diff view.
Claude Code 2.1.19 fixes dangling processes on terminal close
Claude Code (Anthropic): v2.1.19 patches “dangling” Claude Code processes when a terminal is closed, by catching EIO from process.exit() and using SIGKILL as a fallback, as noted in the changelog thread. This reduces stuck background agent work.
The same operational fix is reiterated in the changelog copy.
Claude Code 2.1.19 fixes non-AVX CPU crashes
Claude Code (Anthropic): v2.1.19 fixes crashes on processors without AVX instruction support, as listed in the changelog thread. This matters for older laptops and some CI runners.
It’s a straight stability fix, repeated in the changelog copy.
Claude Code 2.1.19 changes indexed arguments to bracket syntax
Claude Code (Anthropic): v2.1.19 changes indexed argument access from $ARGUMENTS.0 to $ARGUMENTS[0], as listed in the changelog thread. This is a breaking-ish change for custom commands.
It’s also captured in the changelog copy.
Claude Code 2.1.19 fixes /rename and /tag across worktree resumes
Claude Code (Anthropic): v2.1.19 fixes /rename and /tag not updating the correct session when resuming from a different directory (including git worktrees), as recorded in the changelog thread. This is a real footgun for multi-worktree workflows.
The bugfix is echoed in the changelog copy.
Claude Code 2.1.19 reduces approval friction for low-risk skills
Claude Code (Anthropic): v2.1.19 changes approval behavior so skills without additional permissions or hooks can run without requiring approval, as stated in the changelog thread. This narrows the “constant approve” loop.
The same line item is repeated in the changelog copy.
Claude Code 2.1.19 fixes prompt stash restore dropping pasted text
Claude Code (Anthropic): v2.1.19 fixes a prompt stash (Ctrl+S) restore issue where pasted content could be lost, per the changelog thread. This is small, but it prevents silent prompt corruption.
The same item shows up again in the changelog copy.
Claude Code 2.1.19 rotates internal flags, including file-write optimization
Claude Code (Anthropic): v2.1.19’s flag set adds tengu_cache_plum_violet and tengu_file_write_optimization, while removing ccr_plan_mode_enabled and preserve_thinking, as enumerated in the flag diff. This suggests ongoing tuning around caching and write paths.
No public behavioral spec is attached to these flags today. That’s it.
🧩 Cursor: Skills go live (dynamic context, capture/reuse, and migration off “commands”)
Cursor chatter shifts from yesterday’s subagents to Skills shipping now: reusable prompts/code blocks, dynamic context discovery, and team reuse patterns. Excludes Codex (feature) and Claude Code versioning (separate category).
Cursor ships Agent Skills with dynamic context discovery
Agent Skills (Cursor): Cursor has shipped Agent Skills, a mechanism for agents to discover and run specialized prompts and code, with a focus on keeping context tight via dynamic context discovery, as shown in the Skills launch and reinforced by the Dynamic context note.

• Practical workflow change: instead of copying/pasting long “how to do X in this repo” instructions into every session, Skills become reusable, invocable building blocks that can fetch only the relevant context for the current task.
• Adoption signal: Cursor is actively soliciting how teams are using Skills in the wild, per the Request for usage feedback thread.
Capture what you taught the agent as a reusable Cursor skill
capture-skill (Cursor workflow): A concrete team pattern is emerging around “capture-skill”: after you correct an agent repeatedly in a session, you snapshot those learnings into a named skill so the next run starts aligned, as described in the Capture-skill workflow.
• Example: debugging tool-call errors with a Datadog MCP by coaching queries/tags, then saving the stabilized workflow as a skill for re-use, per the Capture-skill workflow and the follow-up Captured skill prompt.
This reads like turning ad-hoc prompt steering into a maintained artifact (similar to internal runbooks), but wired directly into the agent UX.
Cursor is migrating commands into Skills
Commands vs. Skills (Cursor): Cursor’s team says it plans to migrate existing “commands” into Skills, per the explicit note in the Commands to skills plan.
The shift implies Skills aren’t only a packaging format for prompt snippets; they’re being positioned as the durable interface for repeatable agent operations, which also lines up with the ecosystem joke that “calling them Skills” nudges teams to write real documentation, as framed in the Skills as docs joke.
Cursor Skills support project and global paths, including Claude/Codex-compatible dirs
Skills loading paths (Cursor): Cursor documents a concrete adoption surface for Skills: it will auto-load from six locations spanning project-level and user-level directories, including .claude/skills/ and .codex/skills/ for compatibility, as shown in the Skills paths screenshot.
The compatibility directories suggest teams can standardize on one “skills repo layout” while still letting different agent runners share the same artifacts.
Skills as codebase onboarding: a “teach me this repo” skill template
Codebase tutor skill (Cursor): An early “skill as onboarding” pattern is showing up: a shared Skill that can explain how the codebase works and guide navigation, demonstrated in the Codebase teaching skill.

This effectively makes “how this repo works” portable—so the agent can re-run the same onboarding flow across new engineers, new subagents, and new tasks without re-deriving the same mental model each time.
📊 AI inside work apps: Claude in Excel + Cowork/Chrome improvements; ChatGPT UI leaklets
Workplace agents move from demos to default surfaces: Claude in Excel rollout and Cowork updates (project mentions, live screenshots). Also includes ChatGPT web UI leaklets (temporary chat personalization + cart/merchant feeds). Excludes coding-agent launches (Codex feature).
Claude in Excel rolls out to Pro with multi-file drop, safer edits, and auto-compaction
Claude in Excel (Anthropic): Claude is now available inside Excel for Pro plans; it supports multi-file drag-and-drop, avoids overwriting existing cells, and can sustain longer sessions via auto-compaction, as announced in the launch post and reflected in the install prompt.

• Workflow changes: The experience is positioned as workbook-aware (nested formulas, multi-tab dependencies) and oriented toward “write results into Excel” without clobbering existing work, with feature detail summarized on the install page.
• Long-session behavior: The mention of auto-compaction in the launch post is the practical signal for analysts doing iterative spreadsheet work (scenario sweeps, reconciliation, error-fixing) where context length typically degrades over time.
ChatGPT temporary chat leaks a “Personalize replies” toggle
ChatGPT web (OpenAI): Temporary chats appear to have a hidden option allowing personalization (memory, chat history, style/tone prefs) even when the session is marked temporary, based on UI screenshots shared in the temporary chat toggle leak.
• Privacy semantics: This is a meaningful distinction for enterprise/security teams—“temporary” may no longer imply “no personalization inputs,” if the toggle shown in the temporary chat toggle leak ships broadly.
• Product direction: The UI language suggests personalization is treated as a configurable input channel rather than a strictly session-scoped behavior, though there’s no official announcement yet beyond the temporary chat toggle leak.
Claude Cowork adds project @-mentions and live screenshots in Chrome
Claude Cowork (Anthropic): Cowork is now available for Team and Enterprise plans; new updates include @-mentioning projects to pull in context and Claude in Chrome showing live screenshots while it works, per the availability update and the feature post.
• Context injection: The project @-mention flow in the feature post is a concrete mechanism for “bring the right folder/context into the session” without manually re-uploading artifacts.
• Operator visibility: Live screenshots in Chrome, as stated in the availability update, are a practical auditability upgrade for browser-driven work where “what it clicked” matters as much as the final answer.
ChatGPT web surfaces carts and merchant product-feed uploads
ChatGPT commerce surfaces (OpenAI): The ChatGPT web app is showing breadcrumbs for a Cart feature (saving items to buy later) plus a merchant self-serve page to upload compressed product feeds, as captured in the commerce UI leak.
• What’s new in UI: Screens in the commerce UI leak show a “Cart” sidebar entry with multiple saved carts and a merchant settings route for feed uploads (accepting .jsonl.gz or .csv.gz up to 8192 MB).
• Why it matters: If these surfaces ship, they imply a shift from “answering shopping questions” to maintaining stateful purchase intent and ingesting third-party catalogs—both of which change how agents integrate with retail systems and how attribution/revenue sharing could work downstream.
Claude in Excel vs Microsoft’s Excel agent: analysis-first beats formula-first
Spreadsheet agent strategy (work apps): Early practitioner feedback says Claude in Excel often produces stronger answers than Microsoft’s own Excel agent even when that agent runs Claude 4.5, because it does “its own analysis and uses Excel for output” rather than staying constrained to spreadsheet-native operations, as described in the comparison thread.
• Why it matters: This frames a product split—“software is the point” vs “output is the point”—that could decide which spreadsheet assistants win in knowledge-work settings, per the comparison thread.
• What to watch: Reports of Claude building formulas and formatting correctly in the feature walkthrough suggest the sweet spot is hybrid: do heavy reasoning out-of-band, then express it as clean sheet structure.
Cowork is reported available to $20/mo Claude subscribers
Claude Cowork (Anthropic): Cowork access is reported to have expanded to $20/mo Claude subscribers, following up on Research preview—earlier signals about Cowork’s research-preview surfaces—according to the Pro availability claim.

• Adoption implication: If the $20 tier availability in the Pro availability claim is accurate, it shifts Cowork from “team tool” to a mass-market work surface, with the likely constraint being usage limits rather than feature access.
• Corroboration: Anthropic’s own comms still emphasize Team/Enterprise rollout in the availability update, so treat plan coverage as a moving target until Anthropic posts a consolidated plan matrix.
🧠 Workflow patterns: context hygiene, Ralph loops, and AI-native interviewing
High-signal practitioner tactics: how to keep agents in the “smart zone,” how to record/assess agent sessions, and how to manage progress/commit history. Excludes product release notes (handled elsewhere).
AI-native take-home interviews shift from “no AI” to “show your agent loop”
AI-native interviewing (workflow pattern): A proposed “new technical interview” format asks candidates to build a feature using any coding agent, then submit a PR plus a Loom walkthrough and the full agent session record—explicitly treating AI use as allowed and observable, per Interview format proposal.
The stated motivation is that many candidates still treat visible AI usage as “cheating,” while the interviewer wants to see how they actually reason with the tool in real time, as described in Cheating encouraged rationale.
Ralph plugin critique: keep the loop, reset the context
Ralph (workflow pattern): A pointed critique argues Anthropic’s Ralph plugin defeats the core Ralph idea—clearing context every iteration—because it keeps accumulating history until the model drifts into a “dumb zone,” as shown in Ralph plugin critique.
The proposed alternative is sticking with a bash loop that restarts the session each pass so the agent repeatedly operates with a fresh, bounded context, per the Ralph plugin critique writeup and the linked Article.
“Clean context windows” as a first-order productivity lever
Context hygiene (workflow pattern): A recurring practitioner claim is that agents perform materially better when you keep their context window clean and focused; the complaint is that current tooling trends push the opposite direction—“more noisy and chaotic context”—which correlates with slower reasoning and lower-quality decisions, per Clean context complaint.
A concrete failure mode for “dirty context” is described as context accumulating across iterations (“context rot”), which is also the core critique in the Ralph-plugin discussion in Context rot framing.
Second-agent review prompt to extend work without duplicating it
Multi-agent review (workflow pattern): A “second set of eyes” template suggests taking the exact instructions you gave one agent (e.g., Claude Code) and pasting them into a second agent (e.g., Codex) with an explicit constraint: don’t duplicate prior work; instead improve/extend it by inspecting existing commits/tasks, as laid out in Second set of eyes template.
The key behavioral bet is that models catch different issues and offer non-overlapping improvements when you bind them to “no redundant work” and anchor them to repo history, per the workflow described in Second set of eyes template.
Ralph progress tracking via commit messages instead of progress.txt
Ralph (workflow pattern): A variant being tested drops progress.txt entirely and instead pipes the last ~10 commit messages into the agent, then asks it to encode progress updates inside new commit messages, according to Commit-message progress idea.
The claim is this reduces manual “culling” of a progress file, with a follow-up confirming it seemed fine in practice in Follow-up confirmation.
🧷 Installables & standards: skills repos, AI-authorship in git, and agent-controlled devices
Packaging layer updates: new skill repos, standards for tracking AI-generated code in git, and ‘agent skills’ extending beyond code into devices. Excludes MCP protocol plumbing (separate category).
Git AI Standard v3.0.0 proposes a portable format for AI authorship in commits
Git AI Standard v3.0.0 (Git AI / ecosystem): A spec is circulating for annotating Git commits with structured metadata about AI-generated contributions, aiming to make “AI blame” and provenance portable across tools instead of being locked into proprietary UX, as described in the Spec overview.
• What it’s trying to standardize: A “Git AI Authorship Log” format with RFC-2119 style requirements, designed to be implemented by extensions and tooling that can record which parts of a change were AI-assisted, as shown in the Spec overview.
• Why it’s showing up now: The motivation is explicit—people don’t want AI attribution to exist only inside vendor features like Cursor’s blame view, per the Spec overview.
Claude Code + Remotion is becoming a reusable “autonomous video editor” workflow
Remotion pipeline (Claude Code workflow): Multiple creators are demoing a pattern where Claude Code drives a Remotion-based video pipeline end-to-end—assembling assets, building the animation, and adding a render button—summarized in the Remotion skill result and discussed live in the Stream announcement.

• Observed output bar: The claim is that a first pass landed “as good as” a prior million-view launch video within ~20 minutes, based on the Remotion skill result.
• What’s actually portable: This is less about one-off prompting and more about packaging a repeatable video-production harness around Remotion + agent control, as implied by the repeated “setup” focus in the Stream announcement and Remotion editor claim.
Open Claude Cowork: OSS Cowork-style agent with local tools and 500+ integrations
Open Claude Cowork (Composio): Composio published an open-source “Cowork-like” agent app that can operate on local files and the terminal while also wiring into 500+ app/API integrations, with a working Obsidian note-writing demo in the Obsidian demo and the code in the GitHub repo.

• Integration surface: The positioning is “multi-model” plus broad SaaS connectivity (Gmail/YouTube/Slack called out), as summarized in the Obsidian demo.
• Why it matters: It’s a concrete example of “agent UX as an installable app,” where the packaging layer (connectors + local tool access) is the product, not just a prompt UI—see the Obsidian demo.
A Clawdbot skill now controls an Anova Precision Oven
Anova Precision Oven skill (Clawdbot ecosystem): Someone published a Clawdbot skill repo that lets an agent control an Anova Precision Oven, with the “talking to the oven” proof shown in the iMessage screenshot.
• Packaging detail: The deliverable is a shareable skill repo (not a one-off script), turning device control into an installable capability, as implied by the iMessage screenshot.
• Risk surface: The post frames it as “what could possibly go wrong,” which is the right mental model for agent-to-hardware bindings, per the iMessage screenshot.
Clawdbot skills are moving from code to home-device control (HomePods example)
HomePod control skill (Clawdbot ecosystem): A shared build shows Clawdbot discovering devices on a local network (three HomePods plus an Apple TV) and generating a reusable control skill, including handling a Python version compatibility wrinkle, as captured in the Device discovery summary.
• What got packaged: The workflow ends with a named skill file path and a documented device inventory (“ready” vs “needs pairing”), which turns ad-hoc ops into repeatable automation, as shown in the Device discovery summary.
• Why engineers care: This is a clean example of the “skills layer” expanding into agent-controlled devices (discovery → wrapper deps → documented tool surface), as evidenced by the Device discovery summary.
🔌 MCP & interoperability: registries, CLIs, and “apps in chat” UI surfaces
Tooling that makes agents composable: MCP CLIs, registries, and UI widgets/mini-apps rendered inside chat. Excludes non-MCP skills (plugins category) and core coding assistants (feature/other categories).
CopilotKit demo shows agents returning interactive MCP mini-apps in chat
MCP Apps + AG-UI (CopilotKit): Following up on MCP Apps bridge (agents returning widgets), CopilotKit published a working playground where an agent can return a sandboxed mini-app UI in the chat sidebar and keep shared state before executing actions, as shown in the demo post.

• How it’s wired: the post calls out an AG-UI middleware layer bridging MCP servers to CopilotKit, with each mini-app bundled into a single HTML artifact, as described in the demo post.
• Artifacts you can run: the live [interactive demo](link:309:0|Interactive demo) includes workflows like airline/hotel booking and a portfolio simulator, with implementation details in the [GitHub repo](link:309:1|GitHub repo).
mcp-cli update adds connection pooling and per-server tool filters
mcp-cli (community): The CLI is being reshaped for more reliable agent/tool automation: commands are now split into info, grep, and call, and it adds a pooling daemon with a 60-second idle timeout plus per-server tool filtering via allowedTools/disabledTools globs, as described in the release thread.
• Agent-friendly ergonomics: call always emits raw JSON for piping while info/grep stay human-readable; errors are more structured to help LLM recovery, as detailed in the release thread and expanded in the [project write-up](link:707:1|Blog post).
• Safety/control surface: per-server allow/deny globs make it easier to run MCP in constrained environments (e.g., allow read-only tools), as documented in the [skill doc](link:707:0|Skill doc).
agent-browser v0.7 adds cloud providers, persistent profiles, and remote CDP URLs
agent-browser v0.7 (ctatedev): A new release expands how browser automation can be composed into agent stacks: it adds cloud providers (Browserbase + browser_use), persistent profiles, remote CDP WebSocket URLs, download commands, and launch config flags, as listed in the v0.7 release note.

• Interop surface: the release also calls out “enhanced Claude Code skills” plus new docs for a Claude Code marketplace plugin and skill templates, as noted in the v0.7 release note.
• Reliability fixes: it includes Windows path fixes and better WebSocket connect behavior, as detailed in the v0.7 release note.
Zed teases an ACP Agent Registry for installing external agents
ACP Agent Registry (Zed + JetBrains): Zed’s CEO says the next step for ACP is a registry that’s “easy for users to install and much simpler for agents to adopt,” per the announcement.
The screenshot in the same post shows a registry-style install surface listing agents (e.g., Copilot, Codex CLI, Claude Code) alongside MCP server management and provider settings, which signals ACP positioning as a distribution layer for agent runners rather than a single-vendor integration, as shown in the announcement.
Firecrawl lets agents restrict /search to trusted research sources
Firecrawl (search API): Firecrawl added a /search mode that limits retrieval to “trusted research sites” by setting the category to research, pulling from sources like arXiv, Nature, IEEE, and PubMed, as shown in the feature demo.

This is an explicit knob for reducing web noise in agentic research pipelines, with usage pointers linked in the playground and docs including the [categories parameter reference](link:845:0|API reference).
🕹️ Running agent fleets: Clawdbot ops, always-on agents, and multi-agent browser builds
Operational layer signals: how teams run agents continuously (percent-active metrics, parallelism), plus agent harnesses and adoption driven by cheap local boxes. Excludes MCP protocol details and Codex launch mechanics (feature).
Cursor’s agent swarm built and ran a web browser for a week (FastRender)
FastRender (Cursor): Cursor showcased a swarm of agents building and operating a browser end-to-end for about a week, pushing “long-horizon autonomy” beyond typical single-task coding loops—see the writeup quoted in Fortune coverage.
• Scale and orchestration: The project reportedly used “an orchestra” of planner/worker/judge agents to keep a large codebase moving without human supervision, as described in Fortune coverage.
• What it can do today: In the follow-on technical debrief, the browser can load major sites but still has gaps (notably JavaScript disabled), which Simon Willison summarizes in Conversation highlights.
This is one of the clearer public datapoints that coordination and state management—not raw model quality—are now the main bottlenecks for multi-day agent work.
Amp adds feature-flagged “percent of time agent was working” utilization metric
Amp (Sourcegraph): Amp is rolling out a utilization metric that reports what percent of the last 2h/24h an agent was working; the framing explicitly targets ~100% as attainable (and “>100% with parallelism”), with feature-flag gating described in Utilization metric pitch.
This is one of the few direct attempts to quantify “always-on agent throughput” as an ops KPI rather than relying on subjective productivity anecdotes.
Clawdbot adds Enterprise positioning with Amazon Bedrock docs
Clawdbot (Clawd): Clawdbot is now positioning itself as “enterprise,” alongside documentation for running via Amazon Bedrock, as announced in Enterprise note and detailed in the Bedrock docs.
The notable operational implication is that Clawdbot is aiming to be deployed inside org-controlled inference environments (Bedrock), not only as a hobbyist local agent.
Mac mini buying wave becomes a proxy signal for running local Clawdbot agents
Clawdbot (Clawd): The community is using M4 Mac mini purchasing as a rough “local agent adoption” proxy, with users explicitly buying discounted minis to run Clawdbot, as shown in Mac mini listing and discussed in Buying reaction.
• Adoption/traffic vibe: Posts frame spikes as “mac mini sales or website stats,” backed by a traffic chart in Traffic spike chart and a hype clip in We are live clip.
This is more a social/ops signal than a benchmark, but it’s one of the few visible indicators of “always-on agent” uptake happening outside API dashboards.
CC Mirror previews a Claude Code router with multiple providers and task support
CC Mirror (community): CC Mirror previewed a “Claude Code Router” that can switch between providers including GatewayZ, Ollama, OpenRouter, MiniMax, Vercel AI Gateway, and Z AI, with claimed support for Claude Code v2.1.17’s task system shown in Preview demo.

The repo referenced in GitHub link suggests a growing pattern of “meta-harnesses” that sit above vendor CLIs to normalize long-running agent ops across inference backends.
Clawdbot users report macOS permission prompts on every restart/update
Clawdbot (Clawd): Users report repeated macOS “background items” and file/folder approval prompts after restarts/updates—friction that appears tied to unsigned processes and how macOS tracks background agents, per Permissions complaint.
This is an ops detail, but it directly affects whether “always-on” local agents are tolerable on laptops/mini desktops.
Amp prototypes aggregated “skills used” analytics across a workspace
Amp (Sourcegraph): Amp is prototyping a workspace-level view of which skills/plugins are used most (and by how many people), with a screenshot showing per-skill counts like “ralph” and “commit-messages,” as shown in Skills analytics screenshot.
The operational angle is that agent fleets are starting to generate measurable “tooling exhaust” that teams can mine for standardization and harness improvements.
Clawdbot skill: discovers HomePods and builds local control via pyatv wrapper
Clawdbot (Clawd): A user reports Clawdbot scanning the local network, discovering multiple HomePods/Apple TV devices, and generating a skill that controls playback; the same note calls out a Python 3.14 compatibility issue and a wrapper to run pyatv under 3.13, as shown in Skill output screenshot.
This is a concrete example of “agent as systems integrator”: discovery → dependency workaround → reusable skill artifact—done inside a home network rather than a cloud sandbox.
📏 Benchmarks & evals: FrontierMath jump, Terminal‑Bench v2, and cross-benchmark correlations
Today’s eval news is math/coding heavy: FrontierMath Tier 4 record, updated terminal benchmark leaderboard, and analysis suggesting a shared capability factor across benchmarks. Excludes model-release announcements (separate category).
GPT-5.2 Pro sets a new FrontierMath Tier 4 record at 31%
FrontierMath Tier 4 (Epoch AI): GPT-5.2 Pro reached 31% on Tier 4 (15/48), a jump from the prior 19% record, as reported in the FrontierMath record post; Epoch notes they ran this manually in ChatGPT after hitting API timeout issues, as explained in the Manual eval note.
Reviewer feedback emphasizes “theoretical trick + computations” and geometry recognition, as shown in the Professor quote cards; Epoch also highlights that performance on a held-out subset was higher than non-held-out (10/20 vs 5/28), which they present as evidence against overfitting in the FrontierMath record post. The leaderboard distribution looks unusually top-heavy, with GPT-5.2 Pro far ahead of open models per the Leaderboard note.
Epoch AI: benchmark ranks correlate across domains nearly as much as within them
Benchmark correlations (Epoch AI): Across 15 benchmarks with ≥5 overlapping models, Epoch reports a median cross-domain rank correlation of 0.68, only modestly below the within-domain median of 0.79, as summarized in the Correlation result.
They argue this supports a “single capability scale” framing (the Epoch Capabilities Index) in the ECI motivation, with the underlying methodology and matrices documented on the Data insight page and the ECI definition on the ECI page. A notable caveat is that correlations inflate when benchmarks span wide time ranges with sparse datapoints, as cautioned in the Time-range caveat.
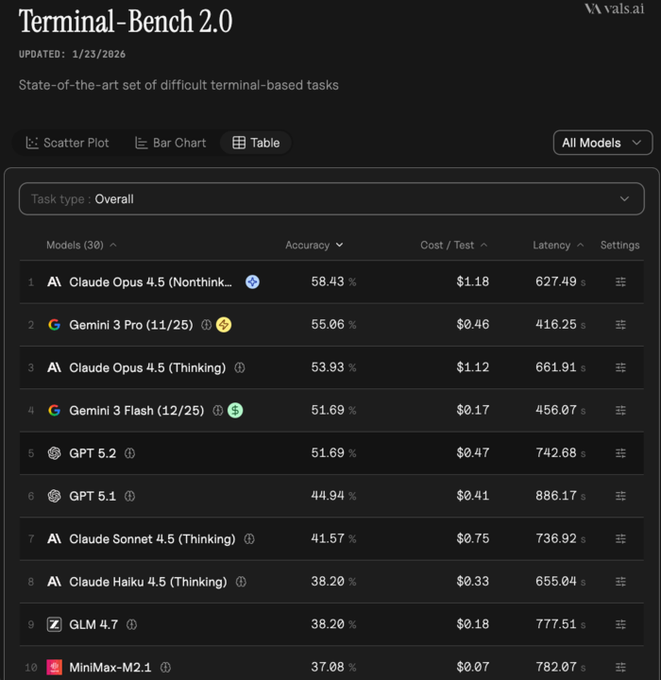
Terminal-Bench v2 ships with new tasks; Claude Opus tops the leaderboard
Terminal-Bench v2 (ValsAI): The Terminal-Bench leaderboard has been upgraded to version 2 with “more, better, and more relevant tasks,” according to the Terminal-Bench v2 announcement. ValsAI reports Claude Opus in first place, about 3% ahead of Gemini 3 Pro, as stated in the Terminal-Bench v2 announcement and repeated in the Leaderboard recap.
Follow-on discussion quickly turned to price/perf: Gemini 3 Flash is described as “almost as well” for under a fifth of Claude’s price tag, with open models also mentioned, as argued in the Price comparison reply.
AgencyBench introduces 1M-token real-task evaluations for autonomous agents
AgencyBench (research benchmark): AgencyBench proposes a long-horizon agent benchmark built from “daily AI usage,” with 138 tasks across 32 scenarios and an average run that hits ~1M tokens and ~90 tool calls, as summarized in the AgencyBench benchmark summary.
The benchmark design emphasizes “real task” wrappers—Docker sandboxing, UI/script checks, and an auto-grading pipeline—while reporting a performance gap between closed and open models (48.4% vs 32.1%), as described in the AgencyBench benchmark summary and shown on the Paper screenshot.
Image Edit Arena splits leaderboards; Gemini leads multi-image editing
Image Edit Arena (LM Arena): The Image Edit Arena now has two leaderboards—Single-Image Edit and Multi-Image Edit—based on more real-world usage data, per the Leaderboard split post.

The headline result is a leader flip: ChatGPT Image (Latest) drops from #1 to #3 on multi-image tasks while Gemini 3 Pro Image 2K (Nano-Banana Pro) moves to #1, with other movers called out (e.g., FLUX-2-Flex up 7, Seedream-4 down 7), as detailed in the Leader flip details and visible on the Leaderboard page.
✅ Correctness loops: PR review automation, backend-deploy evals, and AI code provenance
Focuses on staying mergeable: PR comprehension, test/CI realities, and evals that require actually running services. Excludes general benchmark leaderboards (separate category).
ABC-Bench raises the bar: agents only score if the backend runs in Docker
ABC-Bench (OpenMOSS): A new benchmark focuses on the part that breaks in production—agents only get credit if the service builds, boots, and passes end-to-end API tests inside Docker, with 224 tasks across 8 languages and 19 frameworks per the benchmark summary.
This is aimed at catching the common failure mode where code changes “look right” but the runtime environment, ports, dependencies, and container entrypoints don’t actually work.
Cursor Blame for Enterprise adds provenance links from code to agent chats
Cursor Blame (Cursor): Cursor’s v2.4 update includes Cursor Blame for Enterprise, which attributes lines as AI-generated vs human and links back to the conversations that produced the changes, as described in the v2.4 feature rundown.

This is a direct “mergeability” feature: provenance becomes review context, not archaeology.
Devin Review highlights copy/move detection to make big diffs readable
Devin Review (Cognition): Following up on Url swap, Cognition is emphasizing that Devin Review detects copied/moved lines so refactors don’t show up as giant delete+add blocks, as described in the copy and move explanation.

• Adoption surface: the same thread points to “no account required” usage paths (URL swap and CLI), which keeps this usable in real review workflows where reviewers won’t install a new stack just to read one PR, as listed in the usage options.
“Tests that assert nothing” becomes a recurring failure mode in agent PRs
Review hygiene: Maintainers are calling out that many AI-generated PRs “don’t fix anything” because the author accepts confident output without understanding the bug, as argued in the maintainer critique.
A concrete red flag is tests that technically pass but don’t exercise the broken behavior—“they may as well do assert 1 == 1,” as described in the test quality warning.
Git AI Standard v3.0.0 proposes a format for logging AI authorship in commits
Git AI Standard v3.0.0: A spec is circulating for annotating commits with structured metadata about what code was AI-generated, pitched as a way to avoid having attribution exist only inside proprietary “blame” features, as shown in the spec screenshot.
If adopted by tooling, this could make AI provenance portable across hosts and review UIs instead of being vendor-locked.
Reaction-gated PR review bots show up as a practical correctness loop
PR review automation: A “chatgpt-codex-connector” GitHub bot pattern is getting traction: it posts concrete, line-referenced review feedback and explicitly asks reviewers to react 👍/👎 to label usefulness, as shown in the bot review comment.
This is a tight loop: agent critiques → human signal → iterate prompts/policies, without requiring reviewers to write long counter-comments.
“Human code review is over” rhetoric leans on automated verification receipts
Continuous agentic releases: A strong claim—“the era of code review by humans is over”—is being paired with a proposed replacement: automated agentic releases into production with explicit verification artifacts (curl checks, CLI checks, production deploy confirmation), as shown in the release log screenshot.
The operational bet here is that correctness comes from machine-verifiable evidence trails, not line-by-line human diff reading.
Maintainer backlash: uninvited AI review comments seen as new spam layer
Ecosystem norm-setting: There’s visible pushback from maintainers against “uninvited drive-by AI code review” that lands immediately after a PR opens, framing it as noise layered on top of low-signal AI PRs, per the maintainer complaint.
This is a social constraint on correctness tooling: review automation that isn’t opt-in risks getting treated like spam, even if the underlying analysis is sometimes useful.
💼 Capital & enterprise moves: Baseten $300M, OpenAI revenue signals, and profit-sharing pricing
Today’s business beat centers on funding and monetization experiments: Baseten’s mega-round, OpenAI ARR claims, and “value-sharing”/ads discussions. Excludes infra mechanics and tool release details (covered elsewhere).
Baseten raises $300M Series E at a $5B valuation
Baseten (Baseten): Baseten announced a $300M Series E at a $5B valuation led by IVP and CapitalG (with NVIDIA also participating), positioning more capital behind its inference/deployment layer for teams shipping AI apps, as stated in the funding announcement and expanded in the funding post.
• Who’s in the round: the investor list includes IVP, CapitalG, 01A, Altimeter, Battery, BOND, BoxGroup, Blackbird, Conviction, Greylock, and NVIDIA, per the funding announcement.
The announcement doesn’t include detailed unit economics or capacity commitments in these tweets, so it’s mostly a capital signal rather than an operating update.
Bloomberg: OpenAI courts Middle East investors for a $50B+ round
OpenAI fundraising (reported): Following up on $50B round (raise tied to a UAE-scale buildout narrative), Bloomberg-cited reporting says Sam Altman has been meeting with major Middle East investors—including state-backed funds in Abu Dhabi—seeking a new funding round totaling at least $50B, as summarized in the Bloomberg snippet.
This is still described as discussions rather than a closed round, and the tweets don’t include terms beyond the “$50B+” scale and counterparties.
OpenAI repeats “value-sharing” monetization and signals ad tests in ChatGPT
OpenAI monetization (OpenAI): Following up on value sharing (outcome-based licensing talk), OpenAI’s CFO Sarah Friar again describes “value-sharing” deals where OpenAI would take a cut of downstream value—explicitly framing drug discovery as taking “a license to the drug” discovered with OpenAI tech, as quoted in the profit-sharing quote. She also signals OpenAI is preparing to test ads in ChatGPT while aiming to keep answers “best” (not sponsored) and retain an ad-free tier, per the ads mention.
• Value-sharing specifics: the concrete example is profit participation/IP licensing for AI-assisted drug discovery, as described in the profit-sharing quote.
• Ads as a fallback lever: the “test ads” plan is framed alongside expanding pricing models (enterprise SaaS pricing and credit-based usage), according to the ads mention.
There’s no detail here on timing, ad formats, or which plans would stay ad-free.
Anthropic reportedly cuts margin outlook as inference costs run hot
Anthropic unit economics (Anthropic): Following up on margin reset (reported margin pressure), a report circulating in the margin report says Anthropic cut its 2025 gross margin outlook to ~40% after inference costs came in 23% higher than expected, even while projecting ~$4.5B revenue (nearly 12× YoY).
The tweets don’t include the underlying cost drivers (model mix, hardware contracts, or utilization), but the numbers reinforce that serving costs remain a core constraint even at high revenue growth.
🏗️ Infra economics: scaling Postgres to 800M users, storage price shocks, and cloud price cuts
Concrete infrastructure signals with numbers: OpenAI’s Postgres scaling story, datacenter storage cost whiplash, and compute/cloud pricing adjustments. Excludes funding rounds (separate category).
OpenAI details how it scaled PostgreSQL to support 800M ChatGPT users
PostgreSQL scaling (OpenAI): OpenAI published an engineering write-up on “Scaling PostgreSQL to power 800 million ChatGPT users,” describing a single-primary architecture with nearly 50 read replicas globally and >10× load growth over the past year, as outlined in the OpenAI scaling post and echoed by the scaling shoutout. The operational emphasis is on surviving load spikes and write-heavy pathologies (e.g., MVCC-related write amplification and cascading latency/timeouts) while keeping core product surfaces up.
• Topology choice: Single writer with many replicas; the post calls out global read scaling as the workable lever at this stage, per the OpenAI scaling post.
• Failure modes that matter to AI apps: “Write storms,” cache misses, and upstream-triggered query floods are presented as recurring incident shapes, with degradation loops that can propagate back into product timeouts, as described in the OpenAI scaling post.
If you run an AI product with bursty, multi-tenant traffic, the clearest takeaway is what they chose not to do: no “multi-primary everywhere” story—just a lot of work making one primary plus replica fleets behave under stress.
Enterprise SSD pricing spikes: SSDs now ~16× HDD cost per TB amid NAND crunch
Enterprise storage pricing (Market): A shared data point says enterprise SSDs have swung to ~16.4× the per‑TB cost of HDDs as NAND flash tightens, with 30TB TLC SSDs rising ~257% from about $3,062 (Q2 2025) to ~$11,000 (Q1 2026), as summarized in the pricing spike recap.
• Architecture implication: The thread argues SSD‑only clusters are getting punished for “cold data,” pushing more hybrid SSD+HDD tiers to reduce SSD exposure while keeping hot-path latency acceptable, per the pricing spike recap.
Treat the exact multiples as time-sensitive market claims, but the directional signal is clear: storage bills for retrieval corpora, logs, and fine-tuning datasets can reprice by multiples on procurement cycles.
Comfy Cloud cuts compute price ~30% (0.39 → 0.266 credits/sec)
Comfy Cloud (ComfyUI): ComfyUI says Comfy Cloud is now ~30% cheaper after renegotiating infra costs, dropping from 0.39 credits/s to 0.266 credits/s, with plan-hour equivalents increasing accordingly, as posted in the pricing change note.
For teams using ComfyUI pipelines for image/video workflows, this is a straightforward unit-cost shift; no new feature is described, just more seconds per credit at the same plan tier per the pricing change note.
Zai reports malicious network attack and forces a system-wide restart
Availability incident (Zai): Zai_org reported its network was hit by a malicious attack; it blocked the attacking IP and initiated a system-wide restart with an expected ~5 minutes of downtime, per the incident notice.
This is a small but concrete reliability signal for anyone depending on that provider’s hosted surfaces, especially if you’re routing production agent traffic through them.
🧠 Model drops worth testing: open TTS, low-latency voice stacks, and diffusion coding
Model-level releases and notable checkpoints: open-source TTS/voice cloning, ultra-low-latency conversational voice, and new open coding models. Excludes runtime/inference engine changes (separate category).
NVIDIA open-sources PersonaPlex for full-duplex conversational voice
PersonaPlex (NVIDIA): NVIDIA introduced PersonaPlex, an open-source, real-time full-duplex voice stack designed for natural turn-taking behaviors (interruptions, backchannels, timing), as described in the Launch thread.

The repo is live with code and an MIT license, per the GitHub repo. The visible emphasis is on reducing conversational latency while still allowing role/voice customization; exact latency numbers aren’t provided in the tweets, so treat “lowest latency” claims as qualitative for now, as stated in the Launch thread.
Qwen3‑TTS early testers report near ElevenLabs‑level voice cloning
Qwen3‑TTS (Alibaba/Qwen): Early hands-on reports claim the open Qwen3‑TTS voice cloning is “the closest to ElevenLabs quality” they’ve heard from an open model, based on tests of the hosted demo discussed in the Quality comparison and the model rundown in the Voice cloning rundown.

• What’s being tested: short-audio voice cloning plus style instructions, with small model sizes (0.6B and 1.8B) called out in the Voice cloning rundown and echoed in the Official launch recap.
• Where to grab it: the family is available via the Hugging Face models, which is the practical starting point if you want fully local runs.
Sentiment so far is performance-focused rather than “feature complete”; there’s no standardized eval artifact in the tweets beyond user listening tests.
Baidu Ernie 5.0 details circulate: 2.4T MoE and LMArena 1,460 claim
Ernie 5.0 (Baidu): Following up on release claim (initial “Ernie 5.0 is out” reports), new circulated details claim a unified multimodal MoE with 2.4T total parameters and under 3% active per query, plus an LMArena score of 1,460 for “Ernie‑5.0‑0110,” as summarized in the Launch summary.
The same thread includes multiple benchmark charts (text, vision, and audio) as shown in the Launch summary, but there’s no single canonical evaluation artifact or reproducible setup attached in the tweets, so these should be read as vendor-supplied or vendor-adjacent performance claims rather than an independently verifiable drop.
Stable‑DiffCoder posts strong coding benchmark bars for an 8B diffusion model
Stable‑DiffCoder (Stable Diffusion code model): A benchmark chart shared with Stable‑DiffCoder‑8B positions diffusion-style code generation as competitive with strong 7B–16B code models on several coding suites, per the Benchmark chart.
The chart shows scores like HumanEval 86.6, MBPP 85.7, BigCodeBench (full) 54.8, and BigCodeBench (hard) 31.8, as shown in the Benchmark chart. The post doesn’t include details on decoding/runtime constraints or licensing in the tweet itself, so treat this as a performance snapshot, not an end-to-end “drop-in” readiness signal.
Devstral 2 lands in Code Arena for head-to-head app building prompts
Devstral 2 (Mistral): Devstral 2 is now selectable in LM Arena’s Code Arena for head-to-head testing on “build end-to-end websites and apps” prompts, according to the Code Arena announcement.
Arena is positioning this as an easy way to compare Devstral 2 against frontier models without building your own harness, as indicated in the Code Arena page. There aren’t model card details or training notes in the tweets provided here, so the concrete “what changed” is availability in the eval surface, not new architecture information.
⚙️ Runtimes & self-hosting: vLLM debugging, local image gen via Ollama, and serving support
Serving/runtime engineering updates that affect deployability and cost: vLLM deep debugging fixes, local terminal-first image generation, and new model support in inference engines. Excludes raw model announcements (separate category).
vLLM merges fix for hard-to-detect UCX-related memory leak
vLLM (vLLM Project): A production memory leak that standard profilers missed was traced through progressively lower-level tooling—Python profilers to pmap, then BPFtrace, then gdb—and ultimately pinned on UCX’s mmap hooks, as recapped in the debugging summary.
The merged mitigation sets UCX_MEM_MMAP_HOOK_MODE=none, as shown in the linked GitHub PR; this matters for teams serving at scale because the failure mode looks like unexplained RSS growth rather than an obvious allocator leak.
Ollama ships experimental image generation on macOS (Windows/Linux next)
Ollama (Ollama): Ollama has added terminal-first image generation on macOS, with Windows and Linux called out as “coming soon,” according to the feature writeup.
It supports local generation with models including Z-Image Turbo and FLUX.2 Klein, plus knobs like size/seed/steps and negative prompts; the notable workflow detail is that outputs save locally and can render inline in terminals like iTerm2 and Ghostty, as shown in the feature writeup.
Perceptron’s Isaac models are now officially supported in vLLM
Isaac (Perceptron): Isaac-0.1 and Isaac-0.2 are now “officially supported” in vLLM with a one-line vllm serve ... --trust-remote-code launch path, per the serve announcement.
This is a deployability signal more than a benchmark claim: it reduces the amount of adapter glue needed to get Isaac behind a standard high-throughput OpenAI-style serving surface.
Practical RL stabilization: keep the LM output head in fp32
RL training stability (MiniMax): A well-known but easy-to-miss knob—implementing the LM output head in fp32 to improve gradients—was reproduced end-to-end in a separate post-training codebase, showing improved probability alignment vs bf16 in the replication results.
MiniMax also frames this as an internal lesson carried forward from prior work (CISPO + truncation design + fp32 fix), as noted in the follow-up note.
🛡️ Security & governance: cyber-abuse controls, phishing waves, and open vs closed risk debates
Security talk is split between AI capability risk (cybersecurity preparedness levels and abuse prevention) and platform security incidents (phishing DMs / hacked accounts). Excludes non-AI politics and unrelated policy.
OpenAI ties upcoming Codex launches to a “Cybersecurity High” risk posture
OpenAI preparedness framework: Sam Altman says OpenAI expects to reach “Cybersecurity High” soon, explicitly calling cybersecurity “dual-use” and starting with product restrictions to block obvious cybercrime intent like “hack into this bank” when using coding models, as stated in the Cybersecurity High note and echoed in the recap screenshot.
• Mitigation sequencing: Altman frames the near-term as intent-blocking and restrictions, with a longer-term pivot toward “defensive acceleration” (helping patch bugs) once it can be backed by evidence, as described in the Cybersecurity High note.
• Operational readiness signal: Ethan Mollick flags that OpenAI itself expects the upcoming release to raise cybersecurity risk levels and that many orgs may not be operationally prepared, according to the CISO readiness comment.
The timeline and exact enforcement surface aren’t detailed yet; the only concrete mechanism described is intent-level filtering on prompts.
“Copyright appeal” phishing DMs spread via hacked high-profile AI accounts
Platform security (X): Multiple reports describe a coordinated phishing campaign where compromised accounts send DMs impersonating X “rights/compliance” teams, pushing recipients to malicious “appeal” domains, as shown in the 2FA warning thread and the phishing DM screenshot.
• Common lure: The messages demand an appeal within 48 hours and link to lookalike domains such as “appealtrack-x.com” and “appealpoint-x.com,” with a separate example captured in the copyright notice screenshot.
• Account compromise indicators: One reported tell is profile/bio changes to sound official, which the 2FA warning thread points out while urging 2FA.
This is mostly an ops problem for teams with public-facing builder accounts: compromised social accounts can become a supply-chain for credential theft and API-key loss.
Open-model risk debate resurfaces, with China used as the main justification
Open vs closed risk (Anthropic): A recurring argument attributed to Dario Amodei is that open LLMs increase security risk, often framed around China as the primary threat model, with pushback that geopolitical and domestic risks are more complicated than “China vs US,” as summarized in the open model danger claim.

• Tension inside the China framing: In a separate clip, Amodei also downplays the “China caught up” storyline as more hype than reality and says enterprise deals rarely slip to Chinese models, as shown in the benchmarks vs contracts clip.
Net: the same “China” frame is being used both to argue for tighter distribution controls and to argue that competitive displacement risk is overstated; that contradiction is now part of the security/governance conversation.
Concerns rise over government image manipulation in detainee communications
Media authenticity (US government): A widely shared comparison alleges the White House posted a visually altered detainee image relative to a DHS version, raising concerns about the integrity of official visual communications, as argued in the edited-photo comparison.
The discussion is less about any specific model and more about trust and provenance: when state actors distribute edited imagery, it increases the burden on verification workflows (newsrooms, watchdogs, and internal compliance teams) and further normalizes “images as arguments,” not records.
🎓 Builder education & events: Vibe Code Camp artifacts, hackathons, and workshops
Distribution/learning artifacts remain active: transcript dumps, hackathons, and workshops aimed at agentic building. Excludes the product updates those events discuss.
Every publishes an 8-hour Vibe Code Camp transcript repo for agent-driven builds
Vibe Code Camp transcript (EveryInc): Every published the full transcript from its 8-hour Vibe Code Camp as a repo artifact intended to be fed into coding agents (explicitly name-checking Claude Code) for building projects, as announced in the Transcript drop with the source in the GitHub repo.
This turns a one-off livestream into a reusable “promptable corpus” teams can mine for workflows, tool setups, and example prompts. It’s a practical distribution move.
• Build contest mechanics: they’re offering a free year of Every to a favorite build, with the submission deadline called out in the Submission deadline.
WeaveHacks 3 set for Jan 31–Feb 1 at W&B HQ with a self-improving agents theme
WeaveHacks 3 (Weights & Biases): W&B announced WeaveHacks 3 in SF (Jan 31–Feb 1) focused on “self-improving agents,” with prizes including a robot dog plus $15K+ in other prizes, as stated in the Event announcement.

The event framing is explicitly about agent iteration loops (training/evals/observability) rather than app demos; registration details are centralized in the Registration page.
• Sponsor surface: the sponsor list includes infra and agent-adjacent vendors (Redis, Browserbase, Vercel, Daily, Google Cloud), as shown in the Event announcement.
Late Interaction retrieval workshop extends submissions to Feb 20 (ECIR 2026)
Late Interaction Workshop (ECIR 2026): the organizers extended the Late Interaction retrieval workshop deadline to Feb 20 AOE, broadening the submission window for work across multi-vector retrieval (including ColPali-style vision retrieval), as announced in the Deadline extension and detailed on the Workshop site.
The call explicitly welcomes multiple formats (short notes through full papers). That matters.
• Scope signal: the workshop is framing “late interaction” as a practical systems area (indexing, efficiency, training, multimodal), not just a model architecture footnote, as reinforced in the Scope clarification.
Geoffrey Huntley shares a free “how to build a coding agent” workshop
How to build a coding agent (Geoffrey Huntley): Geoffrey Huntley shared a free workshop link positioned as an onboarding path for building your first coding agent, via the Workshop share pointing to the Workshop page.
The pitch is simple. Build one agent end-to-end.
This is another signal that “agent operations” is becoming an explicit skillset taught outside vendor docs, not just learned ad hoc in a team’s internal harnesses.
🧭 Developer work reshapes: AI interviews, “SaaS death” narratives, and job-impact data
Culture is the news when it changes practice: new interview norms, debates about human code review, and labor-impact analyses tied to agent adoption. Excludes pure macro politics and non-AI social content.
AI-native technical interviews: evaluate how candidates work with agents, not without them
Hiring workflow (AI fluency): A proposed “new technical interview” format asks candidates to build a feature using their agent of choice, submit a PR plus a Loom, and include the full agent session record—explicitly treating AI use as allowed—per the interview format proposal.
The follow-up stresses that the assessment target is how someone reasons with the tool (including “dumb questions”), not whether they can avoid it, as described in the interview follow-up.
FT job-ad data says the “AI killed junior jobs” story doesn’t fit the timeline
Job ads (FT/LightCast): A multi-country analysis argues the junior white-collar hiring slowdown started in mid‑2022 (months before ChatGPT) and looks more like interest-rate/macro shock than immediate GenAI displacement, per the job ads summary; it uses postings (not employment counts) across the US, UK, France, Germany, and the Netherlands, and finds junior declines aren’t meaningfully steeper than senior ones.
The core claim is methodological: job postings shift earlier than headcount, so they’re a cleaner way to test “ChatGPT caused it” narratives—while also noting AI-adopting firms skew toward rate-sensitive sectors, as described in the job ads summary.
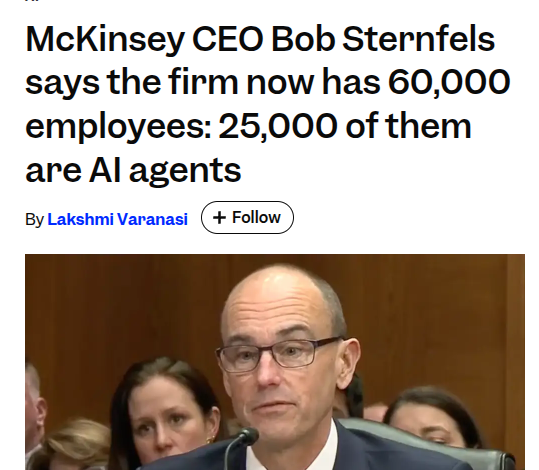
McKinsey frames AI agents as a labor layer: 25k agents alongside 40k humans
McKinsey (workforce mix): McKinsey is being described as having ~60,000 “workers,” including ~25,000 AI agents alongside ~40,000 human employees, treating agent capacity as a staffing layer rather than a sidebar tool, per the Business Insider claim; a separate post adds an internal “25‑squared” framing—client-facing roles up ~25%, non-client roles down ~25%, while non-client output is still up ~10%—as summarized in the CES staffing recap.
• Where the hours go: One cited mechanism is “search and synthesis” automation, with ~1.5M hours saved last year according to the CES staffing recap.
The practical implication is that firms are starting to talk about agents with headcount-like language (“roles,” “capacity,” “mix”), as seen in the Business Insider claim.
“Death of SaaS / rise of AaaS” framing ties skills+MCP to internal tool substitution
AaaS vs SaaS (market narrative): A recurring framing says “vibe coding + packaged agent skills + MCP” shifts teams toward generating internal, bespoke tools rather than buying generic per-seat SaaS, contributing to software-stock anxiety, as argued in the AaaS framing clip.

This isn’t presented with hard adoption metrics in the tweets; it’s mostly a storyline about where “build vs buy” flips once non-experts can assemble decent internal apps via agents, as laid out in the AaaS framing clip.
“Human code review is over” claim: move to automated agentic releases
Code review culture (agents): A blunt take claims “the era of code review by humans is over,” pointing toward “automatic agentic continual releases into production,” and shows an auto-generated release/verification log as proof-of-work in the agentic release log.
The surrounding discussion frames the bottleneck shift as organizational, not model quality—fewer humans reviewing larger agent-written diffs—explicitly stated in the agentic release log.
Study estimate: AI generated 29% of US Python functions by end-2024
AI in software production (measurement): A cited study estimate says that by end‑2024, AI generated ~29% of Python functions in the US, lifting output ~3.6%, with gains accruing disproportionately to senior developers, per the Science study claim.
The post frames this as measurable output reallocation (who benefits) rather than a pure “jobs lost” headline, as stated in the Science study claim.
People managers get told to code again as agent leverage shrinks teams
Org shape (management overhead): A forceful claim says software engineering people managers need to “get back on the tools” because agent leverage reduces required headcount and therefore management layers, as argued in the people manager warning.
A related post makes the headcount math explicit (“team of 20” becomes “5 engineers ralphing”), positioning token spend as a payroll substitute in the headcount math claim.
🎨 Generative media pipelines: real-time image edits, arenas, and AI influencer factories
Creator tooling is noisy today: real-time edit features, model arenas for image/video, and high-velocity “AI influencer” content factories. Excludes voice-agent TTS (handled in model releases) and robotics vision papers.
Comfy Cloud cuts runtime cost ~30% (0.39→0.266 credits/s)
Comfy Cloud (ComfyUI): ComfyUI says Comfy Cloud pricing dropped from 0.39 credits/s to 0.266 credits/s (~30% cheaper), extending plan hours (e.g., “Pro: 15h → 22h”), as announced in the pricing change post.
For teams using Comfy as a production image/video graph runner, this is a direct unit-cost change (and a signal that infra deals are now showing up as user-visible pricing).
Krea introduces Realtime Edit for live image editing with complex instructions
Realtime Edit (Krea): Krea is pitching “Realtime Edit” as a live image-edit loop that can follow more complex instructions interactively, per the feature intro RT.
There’s no technical spec or demo clip in today’s tweets, so treat this as a feature announcement without enough detail yet to evaluate latency, edit determinism, or how it compares to other real-time editors.
Nano Banana Pro prompt trick “all proportions are wrong” yields controllable distortions
Nano Banana Pro (Gemini image): A simple prompt modifier—“but all the proportions are wrong”—is being shared as a reliable way to push Nano Banana Pro into surreal, intentionally mis-proportioned outputs, with examples shown in the distortion examples.
For pipelines that need “controlled weirdness” (creature design, fashion exaggeration, meme assets), this is a lightweight knob that doesn’t require a fine-tune or post-processing step.
Ollama adds experimental terminal image generation on macOS
Image generation (Ollama): Ollama is described as adding terminal-first image generation on macOS with support for models like z-image-turbo and FLUX.2 klein, with Windows/Linux noted as “coming soon,” according to the feature summary.
For builder workflows, the main change is local-first image generation becoming a one-command step in shell-driven pipelines (and potentially easier to wire into agent toolchains) rather than a separate UI/app.
Replicate lists FLUX.2 [klein] 9B as a near real-time generation/edit option
FLUX.2 [klein] 9B (Replicate): Replicate says FLUX.2 [klein] 9B is available on its platform as a 4-step distilled model aimed at “near real-time image generation and editing,” per the availability post.
This is mostly a distribution update, but it matters for teams that standardize on Replicate’s API/runtime for media pipelines and want a faster edit-capable default.
Wan2.6 appears in Image Arena for text-to-image and image edit comparisons
Image Arena (LM Arena): Arena is also rotating new image models into its head-to-head flow, with Wan2.6 promoted as available for both Text-to-Image and Image Edit battles in the model availability post.
Because this is an Arena surface change (not a model paper drop), the concrete artifact is the live comparison entry point—see the image arena page for where it shows up and how it’s being voted on.
Flowith compares Kling 2.6 vs Veo 3.1 for start/end frame consistency
Kling 2.6 vs Veo 3.1 (Flowith): Flowith posted a side-by-side “video lab” comparing start & end frame consistency between Kling 2.6 and Veo 3.1, positioned as a practical criterion for storyboarded or multi-shot workflows, in the comparison clip.

This is useful as a workflow heuristic: instead of judging pure visuals, compare how well each model respects hard constraints across the clip.
Nano Banana Pro workflow: screenshot → image-to-JSON prompt for style matching
Nano Banana Pro (Gemini image): A practical style-transfer-ish workflow is being demoed: take a screenshot from a research visualization video, convert it into an “image to JSON prompt,” then ask Nano Banana Pro to generate a similar aesthetic; the paired reference vs output is shown in the motion-style recreation.
This is less about “prompt craft” and more about building a repeatable asset pipeline from found visuals into generative art direction.
Kling runs a motion-control dance challenge using Kling 2.6 Motion; deadline extended
Kling 2.6 Motion (Kling): Kling is running a “dance challenge” framed as a motion-control stress test in real creator workflows, and the submission deadline was extended to Jan 24 due to participation, as described in the challenge summary.
This is marketing, but it’s also a signal of what Kling wants users to validate: controllable motion and repeatable choreography, not just single-shot aesthetics.
Rodin Gen-2 “Edit” claims 3D Nano Banana-style editing for uploaded models
Rodin Gen-2 “Edit” (DeemosTech): A “3D Nano Banana” style edit workflow is being promoted for Rodin Gen-2—upload a 3D model and apply edit instructions—per the launch RT.
Today’s tweet doesn’t include performance numbers, supported file formats, or a demo clip, so it’s hard to assess whether this is a controllable mesh/texture edit pipeline or mostly a re-generation step around a loosely preserved shape.
🤖 Robotics signals: hybrid locomotion, delivery bots, and military prototypes
A smaller but distinct robotics cluster: new locomotion hybrids and real-world deployments/field demos. Excludes pure “world model” discussion unless tied to robots.
Rifle-mounted robots appear in India’s Republic Day rehearsal footage
Military robotics signal (India): Footage from a Republic Day rehearsal shows rifle-mounted robotic units moving in formation, a tangible sign of militaries experimenting with robotized weapons platforms rather than just reconnaissance drones, as shown in the rehearsal footage.

Demis Hassabis: an “AlphaFold moment” for real-world robotics may be close
Physical intelligence framing (Google DeepMind): Demis Hassabis argues an “AlphaFold moment” for the physical world could be near—defined as robots doing useful tasks reliably (not just demos)—and ties this to multimodal assistants that can understand what you see, per the robot reliability clip.

KOU-III demo: a biped robot that can take off like a drone
KOU-III (Shandong University): A new demo shows a hybrid platform that transitions between two-legged walking and vertical takeoff/hover—useful as a reminder that “robotics stacks” increasingly need to unify locomotion control across fundamentally different dynamics, as seen in the KOU-III demo clip.

RIVR delivery robot clip highlights real sidewalk deployment pace
RIVR (delivery robotics): A short field clip contrasts a sidewalk delivery robot with a human courier in a Just Eat delivery setting, giving a concrete “in-the-wild” signal beyond lab demos—see the delivery clip.