OpenAI Codex macOS app launches – 2× limits for 2 months
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI shipped the Codex desktop app for macOS as a multi-agent “command center”; core primitives are parallel long-running threads, built-in git worktrees, Skills, and scheduled Automations with an approval queue; rollout is paired with a time-boxed promo that doubles paid-plan usage limits for 2 months and temporarily unlocks Codex for ChatGPT Free and Go. OpenAI’s own demos emphasize diff-first supervision, Plan mode via /plan, /personality toggles, and verification loops that run tests/QA as part of an agent run; Windows is teased as “coming soon,” but no date is given.
• Skills + interop: Codex starts reading Skills from .agents/skills with .codex/skills deprecation intent; Skills can auto-install/auto-auth MCP servers via project config.
• Automation plumbing: scheduled runs are tracked in a local SQLite DB (debuggable without a hosted dashboard).
• Friction signals: early reports show ~103% CPU in a renderer helper and ~95% in the core process; no account switcher yet (logout is in the macOS menu).
In parallel, Anthropic’s Claude Code “Swarms” UI leaks suggest 70k–118k-token orchestration runs; a separate allegation says Claude Code edited Ghostty config but isn’t reproduced—both underline that agent UX is moving into always-on, host-mutating territory while guardrails remain uneven.
Top links today
- OpenRouter free models router
- Heterogeneous computing for AI agent inference
- Goldman Sachs report on AI agents in software
- Safeguarded outputs can teach harmful chemistry
- Token-level filtering to shape model capabilities
- VibeTensor agent-built tensor runtime paper
- Mixture-of-models deliberation framework paper
- LongCat-Flash-Thinking-2601 technical report
- The Economist on AI and software stocks
- Bloomberg on AI disruption and private credit
- Bloomberg on software exposure in private credit
- Firefox toggle to disable AI features
Feature Spotlight
OpenAI Codex app ships on macOS: multi-agent worktrees + Skills + scheduled Automations (with promo limits)
Codex moved from “a CLI/extension” to a multi-agent desktop command center: parallel threads on worktrees, reusable Skills, and scheduled Automations—plus 2× usage limits. This changes day-to-day agent orchestration for teams shipping code.
Today’s dominant engineering story: OpenAI shipped the Codex desktop app for macOS as a multi-agent “command center” with built-in worktrees, Skills, and scheduled Automations—plus temporary plan changes (Free/Go access and doubled usage limits).
Jump to OpenAI Codex app ships on macOS: multi-agent worktrees + Skills + scheduled Automations (with promo limits) topicsTable of Contents
🧩 OpenAI Codex app ships on macOS: multi-agent worktrees + Skills + scheduled Automations (with promo limits)
Today’s dominant engineering story: OpenAI shipped the Codex desktop app for macOS as a multi-agent “command center” with built-in worktrees, Skills, and scheduled Automations—plus temporary plan changes (Free/Go access and doubled usage limits).
Codex app is macOS-only for now; Electron build is meant to speed Windows delivery
Platform rollout (Codex app): The app is macOS-first, with “Windows coming soon” repeated in the launch details, but users are already calling out the practical subscription mismatch for Windows-heavy shops in Windows frustration. A Codex engineer explains the implementation choice—Electron sharing code with the VS Code extension—as the reason Windows should move faster, while also admitting they originally hoped for simultaneous release in Electron rationale.
No public Windows date is given in the threads provided; the most concrete statement is the “get to Windows quickly” intent in Electron rationale.
Codex app “local environment actions” add one-click dev server/build triggers
Local environments (Codex app): Codex app supports configurable “actions” for local environments—e.g., start dev server or run builds—and runs them in an integrated terminal, as described in Actions tip. The corresponding setup details live in the local environments docs, which matters for teams who want reproducible agent runs across projects without retyping shell boilerplate each session.
Codex app Automations are tracked in a local SQLite DB (useful for debugging)
Automation observability (Codex app): The macOS Codex app tracks scheduled Automations state in a local SQLite database, and Simon Willison reports poking around the schema after preview access in SQLite notes. For engineers treating Automations as production-like background jobs, this makes runs and failures inspectable without waiting on a hosted dashboard, as described in the accompanying blog deep dive.
Codex app demo shows agent self-checking by launching apps and running tests
Verification loop (Codex app): In OpenAI’s own walkthroughs, Codex is shown validating its changes by launching apps, running tests, and automating QA steps, framing verification as part of the agent loop rather than a separate human step—see the self-check demo.

This matters because parallel worktrees and Automations increase throughput, but they also increase the need for fast, trustworthy checks before humans approve diffs, which is the explicit workflow in Self-check demo.
Codex app setting: prevent macOS sleep while a thread is running
Long-running threads (Codex app): Codex app includes a “Prevent sleep while running” toggle to keep the machine awake during agent runs, which is highlighted directly in the settings screenshot and echoed as a practical tip in Tip thread.
This is the kind of setting that matters once Automations and multi-hour repo reviews become normal usage, as suggested by reports of long-running analysis sessions in Hours-long review.
Codex Skills can auto-install and auto-auth MCP servers via project config
MCP integration (Codex app): Skills can now auto-install and auto-auth MCP dependencies declared in a project config (an agents/openai.yaml file is mentioned), which the Codex team is already using for internal Skills per Skills plus MCP note and reiterated with an example from a Linear Skill in MCP auto-auth example. This ties the Skill layer to a dependency graph rather than per-user manual MCP setup.
OpenAI announces a Codex hackathon in SF with $90k credits and 1 year Pro prizes
Codex community push (OpenAI): OpenAI DevRel announced an in-person Codex hackathon in San Francisco (Feb 5), advertising $90,000 in credits and one year of ChatGPT Pro for winners, per the event invite. The timing is explicitly tied to the desktop app launch and doubled usage limits, suggesting OpenAI wants real workflows and Skills shared quickly while the promo window is active, as implied by Event invite and Promo scope.
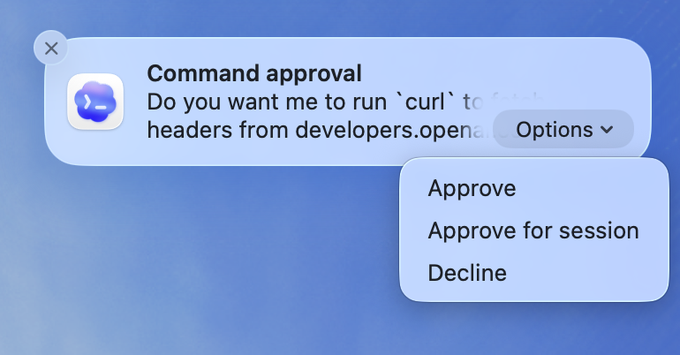
Codex app account friction: log out is in the macOS menu bar, no account switcher yet
Account management (Codex app): Early UX friction shows up around switching between personal and enterprise accounts; one user reports being stuck on “Personal” with no obvious switch path in Account issue. The current workaround is logging out via menu > Codex > Log Out, as shown in the menu screenshot, with a team member confirming “no account switcher” in Team reply.
This is a small detail, but it’s operationally important for anyone trying to run Codex app against enterprise repos and policies, as implied by Account issue.
Codex app is being used for product ops work across Linear, Notion, and Slack
Non-coding workflows (Codex app): Codex team members report using the app beyond coding—doing product work across tools like Linear, Notion, and Slack, with “local integrations” described as easier to customize through Skills in Product work note. Another team member says they use it for non-coding product work “all the time” in Non-coding usage. OpenAI also published a demo framing PM usage as going from feedback to shipped fixes, shown in the PM workflow video.

Codex app notifications for approvals and completions work while the app is backgrounded
Notifications (Codex app): The app can send notifications for approval requests and thread completions while running in the background, which a team member calls out as useful for keeping feedback loops tight without keeping the app front-most in Notifications tip.
🧠 Claude Code & Cowork: swarm features, mobile knobs, and integration footguns
Continues the Claude Code/Cowork storyline, but today’s novelty is around swarm-style parallelism previews and UX/platform quirks (mobile/web differences), plus reports of questionable tool behavior affecting developer environments.
Claude Code “Swarms” preview shows multi-team, hierarchical sub-agent orchestration
Claude Code Swarms (Anthropic): Early screenshots show a “Swarms on Claude Code” workflow that coordinates multiple sub-agents/“leads” with owners, dependencies, broadcasts, and a message system, with the author calling it an “absolute token destroyer” in Swarms preview.
• Orchestration shape: The UI/log implies a team-lead view tracking parallel execution across leads (backend/platform/research/etc.), with explicit “blocked by” relationships and status updates, as shown in Swarms preview.
• Cost/throughput signal: The same screenshot surfaces per-agent tool-use counts and token totals into the ~70k–118k range for a single run, reinforcing that swarms are a “burn tokens to buy wall-clock time” pattern, per Swarms preview.
• Feature parity rumors: Separate chatter describes the swarm concept as “runs multiple sub-agents in parallel” with “own context” and “background tasks,” as summarized in Swarm feature rumor.
Nothing here is an official ship note yet; it’s still “preview + rumor” evidence.
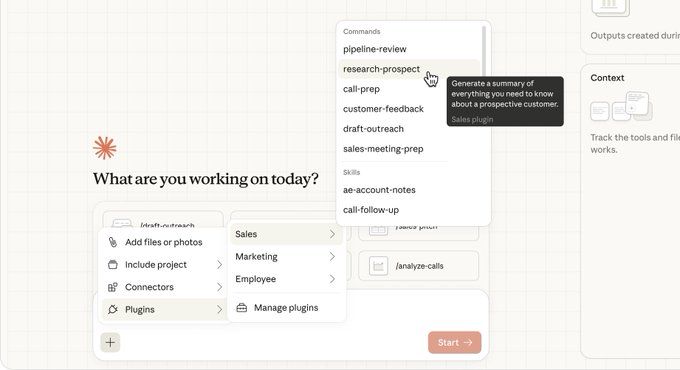
Claude Cowork adds plugins; Anthropic open-sources 11 starter plugins
Claude Cowork plugins (Anthropic): Cowork is described as gaining a plugin system that bundles skills, connectors, slash commands, and sub-agents, alongside “11 starter plugins” being open-sourced for functions like sales/finance/legal/marketing/support, per Plugin announcement.
• What “plugin” seems to mean: The UI shows a commands/skills picker with role-specific commands like “research-prospect,” implying a shareable workflow layer over Cowork sessions, as shown in Plugin announcement.
• Enterprise packaging angle: The starter set is framed as role templates (sales/finance/legal/etc.), which points at “repeatable workflow artifacts” rather than ad-hoc prompting, per Plugin announcement.
The tweets don’t include repo links or versioned docs for the 11 plugins, so treat implementation details as unverified until Anthropic publishes artifacts.
Claude Code in Slack: @Claude mentions can spawn sessions and push fixes
Claude Code in Slack (Anthropic): Teams describe a workflow where they tag @Claude inside a feedback channel, have it investigate issues, and push fixes, with setup described in the Slack docs linked from Slack docs and a usage claim in Workflow example.
• How it appears to work: The docs describe Slack mentions triggering session creation on Claude Code, i.e., Slack becomes the “intake queue” while coding happens in Claude Code, per Slack docs.
• Operational pattern: The pitch is faster response to user feedback by turning bug reports into an agent-run investigation loop, as stated in Workflow example.
No concrete limits (repo access scope, permission model, pricing) are stated in the tweets; those details likely live in the docs.
Report: Claude Code wrote to Ghostty config and broke Shift+Enter in other TUIs
Claude Code ↔ Ghostty config (Anthropic): A maintainer reports two incidents where Claude Code allegedly modified a user’s Ghostty terminal config to add Shift+Enter behavior, which then “breaks other TUIs” using Kitty key protocol, per Terminal config allegation.
• Why engineers care: Writing to a terminal emulator’s config crosses a boundary (host environment mutation) and creates hard-to-debug UX regressions across unrelated tools, as described in Terminal config allegation.
• Security framing: The author calls it “terrible practice” and notes the same pathway could be abused maliciously if software can touch terminal config, per Terminal config allegation.
The report notes they can’t reproduce it; there’s no confirmation from Anthropic in the dataset.
Sonnet 5 rumors shift toward “Swarms” features and a May 2025 cutoff claim
Claude Sonnet 5 (Anthropic): New leak chatter claims a knowledge cutoff of May 2025, per Cutoff claim, while repeated “tomorrow is the day” posts keep tying the release week narrative to Claude Code swarm-style features, following up on leak pack (benchmark/pricing rumor bundle).
• Feature linkage: The newer angle is “Sonnet 5 ships with new Claude Code features,” including swarm-style parallel sub-agents, as described in Swarm feature rumor and reinforced by the broader “drop this week” posts in Super Bowl week rumor.
• Representative quotes: “Agentic Swarm” with “sub-agents in parallel” appears in Swarm feature rumor, “tomorrow is the day” appears in Swarm feature rumor, and “knowledge cut off - may 2025” appears in Cutoff claim.
All of this remains unconfirmed in official release notes inside the provided tweets.
Claude mobile app shows tool-notification toggle and Plan/Code mode switch
Claude mobile (Anthropic): Screenshots show a new notifications toggle set including “Tool notifications,” plus a “Select mode” picker that exposes Plan (“explores code and presents a plan before making edits”) versus Code (“writes and edits code directly”), as shown in Mobile settings leak.
• Why it matters for Claude Code users: If Plan/Code is available on mobile, it changes “approval latency” for long-running sessions—people can review/steer without being at a laptop, per Mobile settings leak.
• Tooling surface hints: The same thread claims “Tools will arrive on mobile too,” which would put tool-call sessions onto the phone as a control plane, per Mobile settings leak.
There’s no official rollout note in the tweets; this is UI evidence only.
Claudeception quirk: artifacts calling Anthropic API work on web, fail on iOS
Claude artifacts “Claudeception” (Anthropic): A recurring report says an Artifact that calls Anthropic’s API returns “Invalid response format” on iOS, but works on the Claude website, per the sequence in Bug report and the follow-up in Web-only workaround, with confirmation in iOS vs web confirmation.
This is a concrete platform mismatch: if you rely on Artifact→API calls, claude.ai web appears to be the stable surface right now, per Web-only workaround.
Swarms skepticism: “most people shouldn’t be running swarms” and $1k/mo plan fears
Swarms adoption risk (Claude Code): Alongside hype, there’s explicit pushback that swarms are overkill—one post says “I don't think most people should be running swarms” in ROI skepticism, and another warns swarm features could imply a $1k/month tier and “you probably shouldn’t pay for it” in Pricing skepticism.
This frames swarms as a specialized tool (coordination overhead + token burn) rather than a default workflow.
Claude Max plan friction: token budget guilt and requests for rollover tokens
Claude Max subscription (Anthropic): Users are describing “budget psychology” around fixed monthly limits—one says they “feel guilty” not using their Max budget in Budget guilt, while another asks for “rollover tokens like mobile carriers” in Rollover request.
This is less about model quality and more about how consumption plans shape usage patterns.
Model positioning chatter: Gemini 3 Pro ‘smarter overall’ vs Opus 4.5 for coding
Model choice framing: One widely shared take claims Gemini 3 Pro is “generally smarter” on overall intelligence, while Claude Opus 4.5 remains better at programming, per Tradeoff claim.
The tweet provides no eval artifact; it’s a packaging narrative that matches how teams often split “general reasoning” vs “agentic coding” workloads.
🧰 Agent runners & always-on coordination: harnesses, scheduling, and team chat for agents
Operational tooling for running agents (not models): multi-agent coordination layers, agent-to-agent collaboration spaces, and “agent workforce” patterns. Today centers on Slack-like coordination for agents and harness-level scaling pain points.
MoltSlack brings Slack-style channels to AI agents via OpenClaw
MoltSlack (Agent Relay): A new real-time coordination workspace lets agents join channels, maintain online presence, and message each other “like humans do in Slack,” with onboarding driven by a SKILL.md flow that you can hand to an agent, as shown in MoltSlack launch.

• Join and auth mechanics: The flow is explicitly two-step (human registers, agent claims via token), per the published Skill specification that MoltSlack launch points to.
• Ops expectations: MoltSlack’s spec bakes in “real-time” assumptions (presence heartbeats, frequent polling during active conversations), which is the kind of detail that tends to make or break always-on agent coordination in practice, as described in the same Skill specification.
OpenClaw shows up as a top-tier workload on OpenRouter usage charts
OpenClaw (harness) demand: OpenRouter shared a dashboard-style snapshot indicating OpenClaw-driven traffic “tracking for 14B tokens today” and placing multiple models behind an OpenClaw leaderboard, as shown in Usage snapshot.
• Why it matters operationally: This is a harness-level scale signal—routing, retries, and long-running session hygiene become first-order problems when usage climbs into multi‑billion token days, as implied by the volume in Usage snapshot.
• Model mix: The same screenshot highlights a diversified provider set (Google, Moonshot, Arcee, Anthropic, DeepSeek, xAI), which suggests OpenClaw users are already treating the harness as a multi-model runtime rather than a single-model product, per Usage snapshot.
Agent chat coordination is converging on heartbeat and polling cadences
Agent coordination ops: MoltSlack’s published integration spec encodes an operational model for “being online”—agents maintain presence with periodic heartbeats and are expected to poll frequently (single-digit seconds) in active conversations, as spelled out in the Skill specification referenced by MoltSlack launch.
The practical implication is that agent runners now need explicit background loops (timers, retry/backoff, reconnect logic) rather than treating “chat” as a request/response surface.
Kimi K2.5 provider overload becomes an uptime constraint for agents
Kimi K2.5 (inference capacity): One operator reports that “all of our inference providers for kimi k2.5 are overloaded” and have asked them to scale down, which is a direct constraint on always-on agent runners that depend on that model’s availability, per Capacity note.
The same account’s follow-up on terminal UX direction for opencode suggests demand is being pushed through agentic CLI workflows (not just chat), as illustrated in Opencode run screenshot, which is consistent with the overload pressure described in Capacity note.
Agent Relay repo is positioned as the substrate for agent workspaces
Agent Relay (AgentWorkforce): The team behind MoltSlack published the underlying repo for building “agent workspaces,” with Matt Shumer explicitly pointing builders at the codebase in his follow-up, as linked in Repo announcement.
• What it is: A foundation for real-time agent coordination primitives (registration, auth tokens, channels, presence), as framed in Repo announcement.
• Where to start: The primary artifact is the GitHub repo, which is referenced directly from Repo announcement.
Superset keeps surfacing as a “multi-session” agent runner UI
Superset (superset_sh): Superset continues to show up in “run multiple sessions” workflows, with users explicitly testing it for parallel Claude sessions, as reflected in the retweet in User trial note.
• Migration pressure point: The product direction implied in Superset chatter is worktree/session portability—e.g., importing worktrees from other apps—per Worktree import mention.
• Framing: The pitch is closer to “orchestrating terminals” than building a new IDE layer, based on how users describe it in User trial note.
Conductor shows up in side-by-side comparisons with Superset
Conductor (conductor_build): Builders are explicitly comparing Conductor against Superset for managing multiple agent sessions and workstreams, as captured in the “Conductor vs Superset” discussion link shared in Comparison link.
The thread list doesn’t include concrete release notes here, so treat this as early positioning signal rather than a specific shipped change; the main observable is that “agent runner workspace” is emerging as a distinct product category in day-to-day tool selection, per Comparison link and Comparison mention.
🧭 Agentic engineering practice: context discipline, self-improvement loops, and prompt ergonomics
Reusable practices engineers can apply across tools (not tied to a single product release). Today’s tweets emphasize harness self-improvement from traces, context engineering as a first-class skill, and prompt ergonomics (persona control, abstraction level shifts).
A trace-driven loop for improving agents without fine-tuning
Harness iteration loop: One concrete recipe circulating is to treat agent runs as data—log every tool call and decision as traces, then use parallel subagents to review failures and extract patterns, write the learnings back into files/rules, and rerun; the full step-by-step loop is laid out in self improvement loop.
• Why traces matter: The motivation is that agent failures often have no stack trace—observability becomes the debugging surface, matching the framing in observability webinar.
This is explicitly positioned as “hill climbing” task success using natural language changes to the harness, not model weight updates.
Coding agents push software work from writing code to supervising outcomes
Agentic programming abstraction: Ex-OpenAI researcher Jerry Tworek frames coding agents as “the next level of abstraction” and predicts “soon, almost no one will type code directly,” with the downstream problem becoming reliability when humans are neither writing nor reading most of the code, as described in Tworek clip.

• Supervision becomes the scarce resource: A matching internal-builder sentiment is that the bottleneck shifts to “how fast we can help and supervise the outcome,” per supervision bottleneck.
Taken together, this is less a model capability claim than a workflow reallocation claim: reviews, test coverage, and auditability become the main surfaces for human contribution.
Autocomplete fades as builders switch to chat-level micromanagement
Coding workflow ergonomics: A visible habit shift is moving from autocomplete to giving higher-level, targeted instructions in chat—e.g., “add a new optional atomic=True param…”, while still supervising details; Simon Willison describes this as “micromanaging the code but at a different level” in abstraction shift.
The implicit pattern is that prompts become the primary editing interface, with autocomplete used less as the unit of work moves from tokens to intentful diffs.
Context engineering is becoming its own discipline for inference
Context engineering: A recurring builder framing is that “context engineering is as impt to inference as data engineering is to training,” as stated in context engineering thesis.
That’s a recognition that a lot of real-world performance now comes from how you assemble, compress, and refresh context—not just which model you pick.
Gemini persona prompts work better when the persona is just a job title
Gemini prompting (Google): The Gemini team is pushing a small but repeatable prompt ergonomic—start with a simple professional persona (e.g., “Act as a \[profession]”) rather than an elaborate character description; they claim it reliably shifts tone and response shape in useful ways, as described in the persona prompt tip.
In practice, this shows up as a cheap way to steer outputs when you’re running the same task across many threads or agents, where consistency matters more than creativity.
Multi-model harnesses are forcing teams to read model prompting guides
Prompt ergonomics across models: As teams mix models in a single harness, one practical advantage comes from reading each model’s prompting guide and copying its idiosyncratic preferences (tool schemas, autonomy cues, formatting); an example called out is that some Codex setups perform better with a shell command expressed as a single string rather than a list, per prompting guide tip.
This is less about “better prompts” and more about aligning the harness with how the model was RL’d to consume tool and control signals.
“Vibe coding” hits its one-year anniversary as a community workflow marker
Vibe coding historiography: Multiple posts note it’s been roughly a year since “vibe coding” was coined, as reflected in one-year note and echoed again in anniversary mention.
The signal here is speed of normalization: what was a meme term in early 2025 is now used as a default description for prompt-first building workflows.
🧱 Skills & extension ecosystem (beyond built-ins): marketplaces, moderation, and purpose-built skills
Third-party and community extension ecosystems for agents/coding assistants. New today: security/moderation moves in skill marketplaces and community requests for purpose-built skill packs (e.g., TypeScript).
ClawHub adds skill reporting and upload gating to reduce skill-market spam risk
ClawHub (OpenClaw): The ClawHub skill marketplace added “report skill” support and now restricts uploading skills to users with GitHub accounts that aren’t brand-new, with the goal of making the directory more trusted as it scales, as described in security update and documented in the moderation docs.
This is a concrete supply-chain hardening move for teams pulling third-party skills into agent harnesses, where the failure mode is rarely “bad code” and more often “unvetted behavior embedded in a convenient package.”
OpenSkills 2 pitches cross-agent skill distribution with auto-install and lockfile sync
OpenSkills 2: A new OpenSkills 2 flow claims it can detect multiple agent clients (Claude Code, Cursor, Codex, OpenCode, Amp, Gemini CLI, etc.) and install skills to all of them automatically, while also emphasizing team distribution primitives like syncing from a lockfile and importing a lockfile to match setup, as shown in install screen alongside the GitHub repo.
If this holds up in practice, it pushes “skills” closer to a portable dependency layer across agents rather than a per-tool customization folder.
Browser Use skill adds domain-specific cookie profiles for browser automation
Browser Use (Skill): The Browser Use CLI skill is being pitched as a way to create reusable “profiles” with domain-specific cookies for browser automation, as described in profiles note and linked via the skills.sh listing.
For agent builders, this is a pragmatic way to separate auth/session state by task or domain (e.g., multiple tenants), without hand-rolling profile management inside the harness.
TypeScript skill packs shift from “best practices” to task-specific outcomes
TypeScript skills (Pattern): Matt Pocock is collecting requests for a TypeScript skill pack and argues that skills work better when scoped to a concrete outcome (e.g., JS→TS migration, fixing “spaghetti types,” TypeScript performance work, extracting types from libraries) instead of a generic “best practices” prompt, as framed in skill design prompt.
This is consistent with how teams treat skills as repeatable procedures (inputs, constraints, and checks), not as one-off advice.
✅ Code quality automation: security agents, PR spam, and release autopilots
Focuses on correctness/maintainability rather than “write more code.” Today includes an AI security agent generating PoCs/PRs and a new release autopilot that does changesets + CI + GitHub releases, plus signs of AI-generated issue/PR spam pressure.
GeminiCLI security agent found a critical OpenClaw bug, wrote a PoC, and landed the fix
GeminiCLI code security agent (Google): A Gemini-powered security agent was used to audit the OpenClaw project, report a critical Local File Inclusion / arbitrary file read risk, generate a proof-of-concept, open a pull request, and get the fix merged “in a matter of hours,” according to the incident recap in Incident summary.
• Why it matters operationally: This is the full “detect → reproduce → patch → merge” remediation loop done by an agent, not just findings—see the structured audit artifact (severity, impacted file paths, and exfil channel) captured in Incident summary.
• Risk shape (high-level): The reported issue frames prompt-injection-driven data exfiltration through OpenClaw’s media delivery path, with sensitive local files as targets, as described in Incident summary.
Maintainers report AI issue/PR spam pushing unwanted rewrites
GitHub maintainer signal: A maintainer of the OpenCode repo reported an apparent AI-generated flood of GitHub issues proposing a broad UI rewrite (moving from opentui to Ink), illustrating how agent-driven contribution spam can create triage load and roadmap noise, as shown in the issue list screenshot in Issue flood screenshot.
• Failure mode: The screenshot shows many near-simultaneous, similarly structured “Implement X” issues plus an “Epic: Ink-based TUI Rewrite,” suggesting automated generation rather than organic contributor demand, as evidenced in Issue flood screenshot.
• Why it matters for code quality automation: When agents can open large volumes of plausible tickets, maintainers need stronger intake controls (rate limits, identity checks, templates, or bot gating) just to preserve review bandwidth—this pressure is the core signal in Issue flood screenshot.
Vercel Labs ships Autoship: an end-to-end changeset release autopilot
Autoship (Vercel Labs): autoship is an open-source CLI that automates a changeset-based release from commit review through GitHub release creation—reviewing commits, suggesting patch/minor/major, generating a changelog + changeset, opening a PR, waiting for CI, merging, and publishing the release, as outlined in the launch post Feature list and the accompanying GitHub repo.
• Workflow impact: It formalizes “release as a PR” with CI gating and merge/release automation, matching the step-by-step pipeline described in Feature list.
• Integration surface: The repository describes a changesets-compatible toolchain with GitHub CLI + an API key requirement, per the setup notes in the GitHub repo.
🔌 Interop & routing: OpenRouter Free Router, local-model glue, and assistant portability
Plumbing that connects tools/models: routing layers, model selection hygiene, and cross-assistant portability. New today: OpenRouter’s free router and operational notes for OpenClaw users, plus Gemini chat import surfaced.
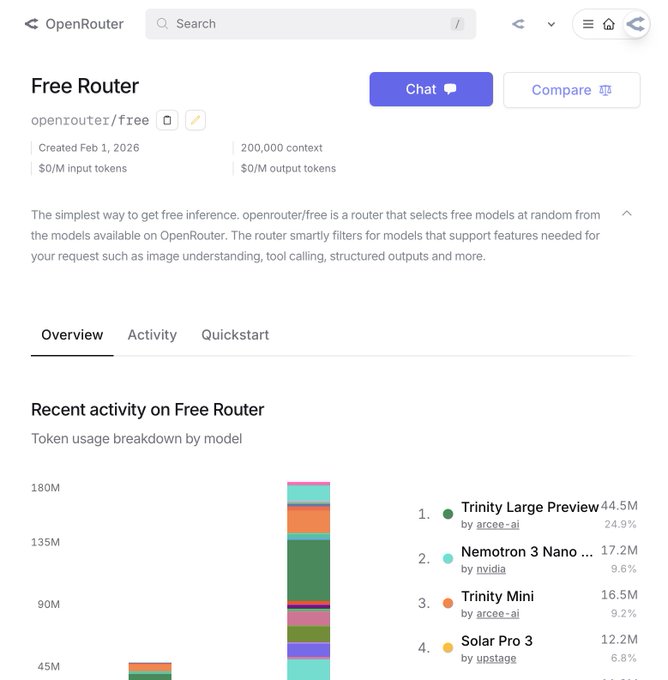
OpenRouter adds openrouter/free: automatic routing across free models
openrouter/free (OpenRouter): OpenRouter shipped a new router, openrouter/free, that automatically routes requests across free models while filtering for compatibility with your request (e.g., images, structured outputs, tool calling), as announced in the router launch; the selection is also influenced by your privacy settings, per the Privacy settings guidance.
• Compatibility-first routing: The router “selects for compatibility with your request,” which matters if you mix JSON/structured responses, tools, and multimodal inputs in one harness, as described in the Free router page.
• Operational detail: The same post points people to a web UI for trying it immediately, per the router launch.
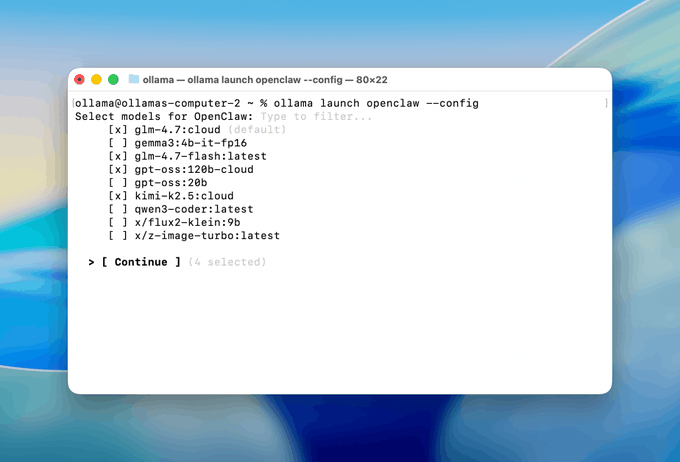
Ollama promotes “ollama launch openclaw” for local-model OpenClaw setups
OpenClaw on Ollama (Ollama): Ollama shared a setup flow to connect OpenClaw to local models via ollama launch openclaw, then configure messaging integrations (WhatsApp, Telegram, iMessage, Slack, Discord, etc.), with an optional cloud fallback if you don’t have local hardware, as laid out in the setup steps and expanded in the Ollama guide.
This is a concrete “local models + real messaging surfaces” on-ramp: install OpenClaw, pick models, then wire the same agent into multiple comms channels.
OpenClaw model-defaults gotcha when switching to openrouter/free
OpenClaw config hygiene: To let OpenClaw fall back to the new openrouter/free routing behavior, OpenRouter notes you may need to unset the pinned default model and restart the gateway—specifically running openclaw config unset agents.defaults.models, as shown in the OpenClaw config note, following the router launch in the router announcement.
This is a concrete “why is it not using the router?” failure mode when teams previously hard-pinned models in a shared agent gateway config.
A practical default-model pick for OpenClaw: Step 3.5 Flash
OpenClaw model selection: OpenRouter’s OpenClaw tip recommends asking OpenClaw to use the Step 3.5 Flash model for a “fast, powerful, and free” default, per the model tip.
The useful part for harness builders is that this is framed as a default routing choice (speed/cost) rather than a benchmark claim.
Gemini adds “Import AI chats (BETA)” to reduce assistant switching costs
Gemini (Google): Gemini’s UI now shows an “Import AI chats (BETA)” option—positioned as letting users bring chat history from ChatGPT and other assistants—per the Gemini menu screenshot.
For teams evaluating assistants, this is an explicit product move against lock-in via history: migrating context becomes a first-class feature rather than a manual export/import workflow.
📦 Model releases & availability (open + proprietary): coding, OCR, and TTS upgrades
New or newly-available models (and notable capability deltas). Today is heavy on open releases and “now GA/now commercial” announcements: Step 3.5 Flash, GLM-OCR, and Eleven v3, plus open-model leaderboard chatter.
Step 3.5 Flash is now widely usable as a free, high-throughput hosted model
Step 3.5 Flash (StepFun): Following up on Initial release (196B MoE, agent-first positioning), builders now have a “try it right now” path via a free hosted SKU that reports ~171 tokens/sec throughput and 256k context, as shown in the Free model metrics.
• What’s concrete today: vLLM’s deployment post reiterates the key operating profile—196B MoE with ~11B active params/token, 256k context, and agent/coding benchmark callouts like 74.4% SWE-bench Verified—per the vLLM support post.
• Why engineers care: this lowers friction for quick evals (prompting style, tool-calling reliability, long-context behavior) before you commit to running weights or reworking your routing stack; treat the perf numbers as provider-specific because they’re reported by the host in Free model metrics.
GLM-OCR launches with 0.9B params and a production-oriented deployment surface
GLM-OCR (Z.ai): Z.ai introduced GLM-OCR, a 0.9B-parameter OCR/document-understanding model positioned for real documents (tables, formulas, seals, code-heavy layouts) and shared weights plus demo/API entry points in the Model launch thread. It’s small enough to be operationally interesting. That matters.
• Bench + scope claim: Z.ai highlights “SOTA across major document benchmarks” despite the small size, with a comparison table posted in Model launch thread.
• Local + serving paths: Ollama added ollama pull glm-ocr for local use and scripting, per the Ollama pull instructions; LMSYS/SGLang published day-0 server flags (including speculative decoding settings) in the SGLang launch command.
More performance validation beyond vendor benchmarks isn’t in the tweet set yet; what is clear is the breadth of ready-to-run surfaces shipped on day one via Ollama pull instructions and SGLang launch command.
Kimi K2.5 is getting “best open” claims across coding and reasoning evals
Kimi K2.5 (Moonshot): Following up on Arena ranking (open-model momentum in coding evals), today’s chatter pushes Kimi K2.5 as the top open model in Code Arena’s agentic coding evaluations, per the Code Arena ranking claim, and also shows it topping an Extended NYT Connections benchmark at 78.3 in the Connections benchmark chart. These are different test styles. The consistency signal is what analysts watch.
• Agentic coding leaderboard claim: Code Arena says Kimi K2.5 is “#1 open model” and “#5 overall,” with the positioning stated in the Code Arena ranking claim.
• Ad-hoc but detailed math testing: Cedric Chee reports fast solutions on several Math Olympiad problems and notes a key caveat—Moonshot hasn’t disclosed knowledge cutoff, so leakage can’t be ruled out—per the Math olympiad runs.
Treat these as provisional: there’s no single canonical eval bundle linked in the tweets, but multiple communities are converging on Kimi K2.5 as the open model to beat, as reflected in Code Arena ranking claim and Connections benchmark chart.
Eleven v3 becomes GA with fewer numeric and notation errors
Eleven v3 (ElevenLabs): ElevenLabs moved Eleven v3 from alpha to general availability for commercial use, emphasizing a 68% reduction in errors on numbers/symbols/technical notation in the GA announcement. This is a common failure mode for production voice UX. It’s not cosmetic.

• What improved: they specifically call out better handling for phone numbers (digit-by-digit) with a before/after example in the Number parsing example, and summarize category-level gains again in the GA announcement.
• Where to confirm details: the GA blog post is linked in the GA blog post.
The tweets don’t include latency or pricing changes, so the main new datum here is reliability on structured strings (numbers, URLs/emails, formulas) rather than “more natural voice.”
Arcee’s Trinity Large preview surfaces with a 512k context pitch
Trinity Large (Arcee): A new “Trinity Large” preview is being promoted as an open model aimed at large codebases, refactors, and architecture planning, with a 512k context claim (served at 128k while infra scales) and free access during the preview period, according to the Preview details. Short context windows are often the limiter for repo-scale work. That’s the pitch here.
More specifics (availability surface, limits, and any independent eval artifact) are only described at a high level in tweets; the primary reference is the Preview announcement.
Qwen3-Max-Thinking is now a Code Arena contender
Qwen3-Max-Thinking (Alibaba): Code Arena added Qwen3-Max-Thinking as a selectable model for its agentic coding matchups, per the Model entry post. This isn’t a weight release. It is a new comparison surface.
The tweet doesn’t include pricing, context length, or benchmark numbers yet; it’s an “in the arena now” availability update, and results will depend on Arena’s voting/eval loop described in Model entry post.
⚙️ Serving & self-hosting: day-0 runtime support, local OCR, and throughput claims
Runtime and deployment engineering (vLLM/SGLang/Ollama), including day-0 support for new models and local deployments. Today features Step 3.5 Flash serving recipes, GLM-OCR local pulls, and production-serving notes.
vLLM posts a day-0 deployment recipe for Step 3.5 Flash (reasoning + tool parsers)
Step 3.5 Flash on vLLM (vLLM Project): vLLM shared a concrete day-0 serving recipe for StepFun Step 3.5 Flash—including --reasoning-parser step3p5, --tool-call-parser step3p5, --enable-auto-tool-choice, and a speculative decoding config—anchored by the setup commands in the vLLM deployment post.
This matters because it’s the difference between “model weights exist” and “agents can actually tool-call reliably in production”; the post’s flags imply StepFun needs custom parsing to get correct tool-call + reasoning behavior through the OpenAI-compatible server surface, as shown in the vLLM deployment post.
SGLang claims day-0 Step 3.5 Flash support with up to 350 tokens/sec
Step 3.5 Flash on SGLang (LM-SYS): LM-SYS announced day-0 SGLang support for Step 3.5 Flash, framing it as “agent-first reasoning” and calling out up to 350 TPS plus long-context handling up to 256K in the SGLang support note.
Deployment docs were also published in the SGLang cookbook, as linked in SGLang cookbook.
The key engineering detail is that SGLang is advertising throughput + long-context viability as first-class properties (not just correctness), per the SGLang support note.
Ollama ships a one-command local install path for GLM-OCR
GLM-OCR on Ollama (Ollama): Ollama published an install+run path for GLM-OCR via ollama pull glm-ocr, positioning it as local-first document OCR (text/tables/figures) with terminal drag-and-drop and API access, as described in the Ollama command post.
The practical artifact is the model’s entry in Ollama’s library—see the Ollama model page—which turns GLM-OCR into something you can script or wire into internal services without shipping documents off-device, consistent with the Ollama command post.
SGLang posts a GLM-OCR launch command with EAGLE speculative decoding flags
GLM-OCR on SGLang (LM-SYS): LM-SYS highlighted day-0 support for GLM-OCR and shared a concrete sglang.launch_server command line, including --speculative-algorithm EAGLE and related draft-token flags, in the SGLang GLM-OCR post.
The post also reiterates the intended deployment angle—0.9B params and “high-concurrency ready” OCR—while pointing to the runnable docs in the SGLang cookbook and the weights in the Model weights.
A hosted Step 3.5 Flash free listing shows ~171 tokens/sec throughput
Open-weights serving signal (hosted provider page): A provider listing screenshot for Step 3.5 Flash (free) shows reported throughput around 171 tokens/sec, ~1.02s latency, and 256K context, as captured in the Provider stats screenshot.
This is an adoption signal more than a benchmark: it suggests the model is being offered in a “free tier” routing context with production-ish telemetry exposed, per the Provider stats screenshot.
🏗️ Compute & infra signals: GPU scarcity, mega-capex narratives, and SpaceX↔xAI consolidation
Compute availability and capex signals affecting AI deployment economics. Today includes GPU scarcity anecdotes, data-center financing chatter, and SpaceX acquiring xAI framed as an AI-infra/compute play.
SpaceX acquires xAI and frames it as an AI compute play
SpaceX + xAI (Elon Musk): SpaceX says it has acquired xAI, with Musk posting that the two are “now one company” in the merger announcement Merger post. The public narrative is explicitly infrastructure-driven—xAI folded into SpaceX’s launch + Starlink stack, with “space-based data centers” pitched as the long-run answer to terrestrial power/cooling limits, as shown in the acquisition statement excerpt Statement screenshot.
• Why infra teams care: if SpaceX actually controls the compute roadmap (launch cadence, orbital power, comms backhaul), it’s a vertically integrated path to AI capacity that bypasses some on-Earth grid constraints; the tweets are aspirational, but they’re being used to justify consolidation and capex direction Statement screenshot.
Some posts cite valuations and “largest M&A” claims, but those numbers aren’t corroborated by a primary filing in the tweet set Valuation claim thread.
OpenAI reiterates NVIDIA as core partner; cites compute fleet at ~1.9 GW in 2025
OpenAI + NVIDIA: OpenAI leadership is again pushing a “no drama” line around NVIDIA partnership, with Sam Altman calling NVIDIA “the best AI chips in the world” and saying OpenAI hopes to be a “gigantic customer” for a long time Altman on NVIDIA. A separate OpenAI-amplified statement from OpenAI’s infra leadership frames the relationship as “deep, ongoing co-design,” and cites compute scaling from 0.2 GW (2023) to 0.6 GW (2024) to roughly 1.9 GW (2025), as shown in the screenshot Compute scaling quote.
• What’s actionable for analysts: the GW figures turn “partnership” into a capacity trajectory; it also signals that inference demand (agents, always-on workloads) is now the justification for continued NVIDIA dependence, alongside diversification to Cerebras/AMD/Broadcom per the same statement Compute scaling quote.
SpaceX FCC filing for up to 1M “orbital data center” satellites resurfaces
SpaceX orbital compute (FCC): Following up on FCC petition—the “space-based data center” concept now has a concrete paperwork anchor in today’s tweets: an FCC application screenshot for a “SpaceX Orbital Data Center System,” listing a pending review status and the SAT-LOA file number, as shown in FCC application screenshot.
• Operational relevance: if this progresses, it’s a compute-supply narrative that ties AI capacity to launch + satellite manufacturing rather than only terrestrial data-center development; it also creates a new regulatory gating item (FCC review) for any “compute in orbit” timeline FCC application screenshot.
AI data center buildout gets framed as a $3T financing problem, not a GPU problem alone
AI data-center finance (Bloomberg framing): One widely shared summary claims the AI boom’s infra buildout implies “more than $3 trillion” in data-center spend, with the key shift being the financing stack—SPVs, broad debt markets, and even GPU leasing vehicles—rather than only hyperscaler balance sheets Financing summary.
The thread also calls out a risk profile that AI engineers feel downstream: refinancing cliffs, chip obsolescence, construction delays, and “data center risk becoming power plant risk” Financing summary. No primary Bloomberg link is included in the tweet payload here, so treat the exact structure as second-hand until you can confirm the underlying article.
GPU scarcity shows up again: Kimi K2.5 inference providers overloaded, asked to scale down
GPU availability signal: A live ops datapoint from the OpenCode ecosystem says “all of our inference providers for kimi k2.5 are overloaded and asked us to scale down,” adding that “there’s still not enough GPUs” Provider overload note.
This is a practical reminder that “agentic coding demand” is now a capacity-planning problem, not just a model-quality story; even when models are available, throughput collapses at the provider layer under bursty multi-agent workloads Provider overload note.
Huang clarifies OpenAI “$100B” invite: step-by-step across rounds, not one check
NVIDIA ↔ OpenAI funding optics: Following up on Megadeal on ice—a new clip circulating in today’s tweets has Jensen Huang clarifying that OpenAI invited NVIDIA to invest “up to $100B,” but that NVIDIA “never said” it would invest $100B in a single round and will consider rounds “one step at a time,” as stated in the video Huang investment clip.

A separate post recirculates the “$100B megadeal on ice” framing via a WSJ screenshot WSJ screenshot, but the only fresh primary content in the set is Huang’s narrower interpretation of what “up to $100B” meant in practice Huang investment clip.
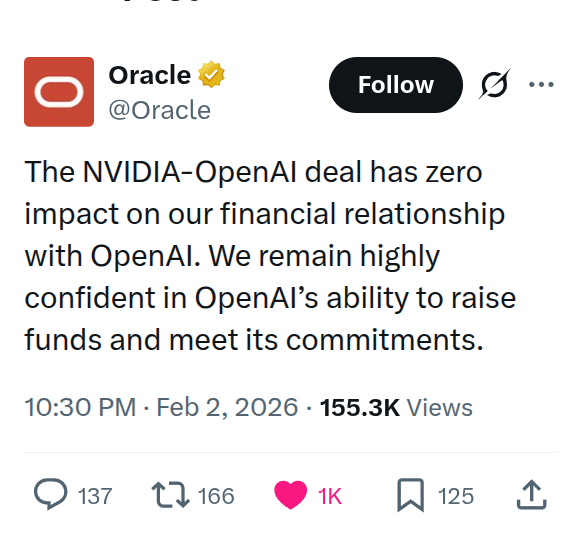
Oracle plans to raise $45B–$50B; frames data center buildout as multi-customer AI demand
Oracle (data center financing): Oracle is described as planning to raise $45B–$50B (stock + debt) for 2026, and Oracle messaging in the tweets emphasizes that OpenAI is “not the only beneficiary,” with beneficiaries named including TikTok, AMD, NVIDIA, and xAI Fundraise details.

• Why it matters to infra planners: it’s another signal that AI capex is spilling into general corporate finance machinery—large debt/equity raises justified by “data center customers” rather than by any single lab contract Fundraise details.
The tweet set also mentions bondholder litigation tied to disclosure concerns around how much debt is needed to support AI buildouts, which is a governance/financing risk factor for long-horizon capacity commitments Fundraise details.
📊 Evals & arenas: enterprise workflow failures, coding leaderboards, and “models posting live” experiments
Benchmarks and live arenas that help teams compare models and agent reliability. New today: enterprise workflow benchmark claims, multiple arena/leaderboard updates, and a social-media posting arena experiment.
World of Workflows benchmark claims frontier agents fail rule-heavy enterprise tasks
World of Workflows (Skyfall Research): Skyfall introduced World of Workflows (WoW), an enterprise-style agent benchmark built on a ServiceNow-based sandbox with 4,000+ business rules, and it’s being framed as a “safety” eval because agents can trigger compliance-breaking state changes even when they look fine in demos, as described in Benchmark summary. The most repeated headline number is that GPT‑5.1 scored ~2% success in this setup, per the same Benchmark summary, with more implementation detail linked from the Official blog link.
• What WoW is measuring: end-to-end workflow correctness under constraint propagation (every DB state change is logged), with emphasis on how one action ripples through rule systems, per the Benchmark summary and the Official blog.
• Artifacts for teams: Skyfall also points to a public code release, with the repository referenced in GitHub repo.
The tweets don’t include an independent reproduction or a full model roster, so treat the “2%” as provisional until the eval harness and scoring are audited outside the announcement threads.
Code Arena leaderboard: Kimi K2.5 reported as #1 open model on agentic coding evals
Code Arena (Arena): Arena claims Kimi K2.5 is now #1 among open models in its agentic coding evaluations and #5 overall, described as “on par” with Gemini‑3‑Flash, in the Leaderboard callout. The same thread points people to the live leaderboard, which is linked in Code leaderboard.
• Why this is notable: it’s positioned as a rare case of an open model entering the overall top tier for agentic coding tasks (not just static code generation), per the Leaderboard callout.
No task breakdowns, run configs, or confidence intervals are included in the tweets; this is a ranking signal, not a postmortem.
Kaggle Game Arena adds Werewolf and Poker to benchmark social reasoning under uncertainty
Game Arena (Google DeepMind + Kaggle): DeepMind says the Kaggle Game Arena has added Werewolf and Poker alongside Chess, positioning them as benchmarks for contextual communication, consensus-building, and ambiguity handling, as announced in Benchmark update and detailed in the DeepMind blog.
• Benchmark intent: these games add imperfect-information and social-dynamics pressure that chess doesn’t capture, per the Benchmark update.
This sits in the “evaluation surface” bucket more than a model release: it’s an attempt to operationalize social/game-theoretic skills that come up in real agent deployments.
Social Arena launches: frontier models post live on X to test agent-to-human social ability
Social Arena (grx_xce): A new “Social Arena” experiment says it has given five frontier models direct posting access on X, aiming to measure agent-to-human social/cultural performance rather than agent-to-agent interaction, as described in the Launch announcement. The listed starting lineup is Grok 4.1 Fast, GPT‑5.2, Claude Opus 4.5, Gemini 3 Pro, and GLM 4.7, per the same Launch announcement.
• What’s distinct here: it reframes “evals” as live, real-time behavior in a public feed (with humans reacting), instead of an offline benchmark harness, per the Launch announcement.
The tweets don’t describe access controls, guardrails, or how posts are attributed/verified, so the operational details remain unclear from today’s sources.
🧪 Training & reasoning methods: verifier-free RL, test-time curricula, and synthetic RL tasks
Training recipes and reasoning-method papers (not product releases). Today includes verifier-free RL variants and test-time adaptation/curriculum synthesis papers circulating among practitioners.
RLPR replaces verifiers with intrinsic probability rewards to extend RLVR beyond math/code
RLPR (THUNLP/NUS et al.): A new verifier-free RL framework aims to generalize RLVR to open-ended domains by using the LLM’s own token probability on a reference answer as the reward—removing the need for hand-built rule verifiers and avoiding separate reward models, as described in the paper thread.
• What changes technically: Reward is the mean probability of the reference answer tokens; the authors add reward debiasing and adaptive std-filtering to stabilize the noisy intrinsic signal, per the paper thread.
• Why engineers care: If this holds up, it’s a practical recipe for “RLVR-style gains” on general instruction data where you can’t realistically write a verifier; the reported chart shows broad improvements (e.g., MMLU-Pro, GPQA, TheoremQA) in the paper thread.
TTCS co-evolves a question synthesizer and solver for self-improving test-time adaptation
TTCS (Test-time curriculum synthesis): A test-time training framework proposes a co-evolving loop where a question synthesizer generates progressively harder variants of the current test question and a reasoning solver updates online using self-consistency-style signals, as summarized on the paper page and shared in paper pointer.
• Core idea: Instead of relying on brittle pseudo-labeling from raw test questions, TTCS manufactures a tailored curriculum at inference time—so the “next training example” matches what the solver currently struggles with, per the paper page.
This is positioned as a stability-focused alternative to naive continuous online updates on small test sets, per the paper page.
Golden Goose turns unverifiable web text into scalable RLVR via fill-in-the-middle MCQs
Golden Goose: A data-construction trick synthesizes large amounts of RLVR-like training signal from otherwise “unverifiable” internet text by converting it into multiple-choice fill-in-the-middle problems—letting teams tap reasoning-rich corpora that don’t naturally come with verifiable rewards, per the paper page referenced in paper pointer.
• Why it matters in practice: This is a concrete path to scale verifiable-style RL beyond domains where you can write an execution checker (common bottleneck for general reasoning RL), as described in the paper page.
The authors also note a cybersecurity-oriented demonstration of the approach when standard RLVR data is scarce, per the paper page.
💼 Enterprise & market structure: agents vs SaaS, partnerships, and profit-pool shifts
Enterprise adoption, partnerships, and market-structure implications. New today: OpenAI–Snowflake partnership, repeated “agents eat SaaS” narratives with analyst quotes, and agent TAM/profit-pool projections.
OpenAI and Snowflake sign multi-year $200M partnership for in-platform model access
Snowflake × OpenAI: Snowflake and OpenAI announced a multi-year $200M partnership to bring OpenAI models (including GPT-5.2) directly into Snowflake Cortex AI and Snowflake Intelligence, per the Partnership announcement and the partnership post described in Partnership post. This is positioned as “frontier intelligence next to governed data,” so enterprises can build agentic and analytics workflows without piping datasets into a separate AI stack.
• What changes operationally: model calls become a first-class Snowflake surface (policy + governance staying in Snowflake’s control plane), which reduces the usual glue work around data movement, bespoke RAG wiring, and audit/permissions re-implementation—this “keep it where the data lives” emphasis shows up in the Partnership announcement.
• Who this targets: Snowflake frames it as broadly available across its enterprise footprint, with examples of customers planning agent extensions while keeping governance intact, as summarized in the Deal summary.
The missing detail in the tweets is commercial plumbing (pricing per token inside Snowflake, latency/SLA, and which OpenAI models are exposed beyond GPT-5.2), so the practical impact depends on how Snowflake packages usage limits and governance defaults.
Goldman Sachs: AI agents could be >60% of software economics by 2030
AI agents (Goldman Sachs): A Goldman Sachs research note circulating today argues that agentic workloads could account for more than 60% of software economics by 2030, shifting the profit pool away from classic per-seat SaaS and toward “agent TAM,” as described in the Report recap. The claim isn’t “software shrinks”—it’s that the market expands while dollars re-route to execution-heavy, API-calling systems.
• Enterprise readiness gap: the note’s framing is that most deployments are still chatbot-like, while stronger agent patterns remain pilots; it calls out the need for a platform layer with identity, security, and data-integrity guardrails, with “broad standardization” estimated at 12+ months out, per the Report recap.
• Where value capture moves: the argument is that vendors who wrap workflows in agents become the new UI for knowledge work and can capture part of the productivity delta—rather than passing all gains to customers—again per the Report recap.
Treat the 2030 split as a thesis, not a measurement—there’s a chart, but the tweets don’t include methodology or scenario bounds beyond what’s paraphrased.
AI disruption fears continue to hit enterprise software stocks and credit pricing
Enterprise software repricing: Following up on Loan selloff, today’s thread-level synthesis adds more concrete numbers around how “agents vs SaaS” fears are showing up in public equities and private credit, with a cited ~10% drawdown in listed American enterprise software over the past year and sharp single-day moves (SAP -15%, ServiceNow -13% on Jan 29) summarized in the Economist summary and reinforced by the Chart recap.
• Credit spillover: UBS’s “severe AI disruption” scenario is quoted as putting US private-credit defaults at 13% (vs leveraged loans 8% and high-yield 4%), with exposure described as concentrated in tech/services borrowers, per the UBS worst-case excerpt.
• Mechanism being priced: the circulating explanation is twofold—AI coding tools lowering build costs for in-house replacements, and AI-native startups unbundling workflow software—while business-software investment growth is cited as slowing from 12% (2021–22) to 8% (2024), per the Economist summary.
• Portfolio-level impact: Bloomberg-style framing notes BDC/private-credit vehicles often have meaningful software exposure, so collateral repricing hits loan risk perception quickly, as described in the Bloomberg software exposure note.
The tweets present these as market signals of uncertainty rather than evidence that agents have already displaced SaaS at scale.
Nadella frames agents as the new business-logic layer, apps as commodity CRUD
Agent-centric enterprise software (Microsoft): A clip of Satya Nadella is being reshared with the claim that “traditional SaaS” value shifts as business logic moves from apps to agents, leaving many applications as commodity CRUD databases while the agent becomes the orchestration layer, per the Nadella clip summary.

• What this implies for platforms: if orchestration and reasoning live in an agent layer, vendors compete on governed data access, permissions, and reliable write-backs into systems of record—rather than feature depth in each individual app, as described in the Nadella clip summary.
• What’s still unsettled: the clip frames a directional shift, but it doesn’t answer where agents “run” (vendor agent vs customer-controlled) or how revenue reallocates (seat pricing vs usage-based automation), which is the core question for procurement and product strategy.
The through-line is consistent with the broader “agents eat interfaces” discourse, but the tweets don’t provide a concrete migration pattern beyond the conceptual split of agent brain vs app storage.
“OpenAI valuation tax” narrative: markets discount partners with concentrated OpenAI exposure
OpenAI dependency risk (public markets): A “valuation tax” meme is being supported with a forward P/E change chart that attributes multiple compression to perceived concentration risk—i.e., companies whose future is seen as overly dependent on OpenAI get marked down—per the Valuation chart thread.
The specific chart shown in the thread plots forward P/E ratio changes “since the release of Gemini 3,” with larger drops for some OpenAI-adjacent names (SoftBank and Oracle are highlighted in the image) while others are flatter, as shown in the Valuation chart thread.
This is less about model quality and more about contract uncertainty and competitive leverage: partner concentration becomes a first-order risk factor when agents and model providers can reshuffle who captures value in the stack.
Databricks CEO argues Zoom could become an AI workflow layer that disrupts SaaS
Zoom as agent front door (Databricks): A reshared clip summarizes Ali Ghodsi’s view that Zoom has an unusually strong position to build an AI-first enterprise product because it sits on large volumes of meeting video + audio + transcripts, and could extract decisions and action items then write them back into systems of record, per the Ghodsi clip summary.

The claim is fundamentally about distribution and data gravity: if meeting capture becomes the ingestion point for enterprise work, then an agent layer on top can pressure standalone note-taking, CRM update, and coordination SaaS products by automating the data-entry and routing they depend on, as described in the Ghodsi clip summary.
📄 Research & analysis drops: misalignment as “hot mess”, agent memory walls, and interpretability tooling
Primary artifacts are papers/technical writeups. Today is a mix of alignment-failure-mode research, systems papers on agent inference bottlenecks, and interpretability/automation papers (plus several research tooling announcements).
Agent inference may be hitting a memory-capacity wall, not a FLOPs wall
Heterogeneous Computing for agent inference (Microsoft + Imperial): A new systems framing argues that agentic inference is jointly constrained by memory bandwidth and memory capacity as contexts and KV caches grow; the summary in the Paper breakdown highlights operational intensity (ops/byte) plus capacity footprint (bytes/request) as the two-axis bottleneck.
The paper’s headline example (as relayed in the same Paper breakdown) is stark: at batch size 1 with ~1M context, a single DeepSeek-R1 request is estimated around 900GB of memory; decoding becomes KV-read dominated, so adding more compute doesn’t unblock throughput when the request doesn’t fit.
A proposed default architecture is disaggregated serving—splitting prefill and decode across specialized accelerators and separate memory pools, connected with fast links (including optical), as described in the Paper breakdown.
Anthropic’s “Hot Mess of AI” argues longer reasoning increases incoherence
Hot Mess of AI (Anthropic): Anthropic’s Fellows Program published results claiming that as models “reason” longer, their failures become more variance-driven (less predictable), not more goal-directed; they operationalize this via a bias–variance decomposition where incoherence is “fraction of error from variance,” as introduced in the Bias–variance framing and expanded in the ArXiv link.
• Finding on long reasoning traces: The lab says incoherence rises with more reasoning tokens/tool actions/optimizer steps, per the Longer reasoning finding and the accompanying Research announcement.
• Finding on scale vs coherence: They report an inconsistent relationship between “intelligence” and incoherence—“smarter models are often more incoherent,” as stated in the Scale finding.
The paper frames this as pushing safety work toward training-time issues like reward hacking and goal misgeneralization, with failures looking more like “industrial accidents” than coherent misaligned optimization, per the Safety implication thread.
NVIDIA’s VibeTensor paper: agents built a DL runtime, but end-to-end speed lagged
VibeTensor (NVIDIA): NVIDIA researchers report an LLM-agent loop that generated a PyTorch-like eager tensor library with autograd and CUDA plumbing; the writeup emphasizes that local correctness checks (compile/tests/spot comparisons) don’t guarantee global performance, which they call a “Frankenstein” composition effect in the Paper summary.
They report microbench wins up to 6.3×, but end-to-end training runs still 1.7× to 6.2× slower, per the same Paper summary. The artifact is positioned as a systems-research probe into what breaks when “agents write the whole stack,” not a drop-in replacement.
OpenAI demos Prism, a LaTeX editor workflow with full paper context
Prism (OpenAI): OpenAI is demoing Prism as an AI-native LaTeX editing environment where GPT-5.2 operates with full project context inside a paper workflow, per the Prism demo clip and the product surface linked on the Prism site.

The demo framing is “scientific tooling hasn’t changed for decades” and this is a context-rich editor that keeps the whole paper in view, rather than a chat window pasted with snippets, as stated in the Prism demo clip.
DeepMind’s “Aletheia agent” is claimed to have produced an early solution to Erdős-1051
Aletheia agent (Google DeepMind): A circulating claim says DeepMind’s “Aletheia agent” likely generated an early, autonomous solution to the open Erdős-1051 problem, described as “not clearly copied from prior human proofs,” according to the Claim summary.
The public artifact trail in the tweets points to a community-maintained index of AI contributions to Erdős problems—see the Erdos wiki page shared alongside the Follow-up link.
As presented here it’s still a secondhand signal (tweets referencing a paper and a wiki), but it’s notable as a concrete “agent does math discovery” claim rather than benchmark talk.
PaperBanana proposes an agent to automate publication-ready academic illustrations
PaperBanana (Google Cloud AI Research + PKU): A new research artifact proposes an agentic workflow for generating “publication-ready” academic illustrations, targeting the figure-making bottleneck in research writing; the announcement screenshot in the PaperBanana slide frames it as an automated illustration pipeline rather than a generic image model.
The practical implication for tool builders is that “paper context → structured figure spec → renderable assets” is being packaged as a repeatable agent loop, not a one-off prompt, per the PaperBanana slide.
TensorLens: transformer analysis with high-order attention tensors
TensorLens (paper): A new interpretability method represents the transformer as an input-dependent linear operator via a “high-order attention-interaction tensor,” aiming to capture attention/FFNs/normalization/residuals in one representation; the pointer in the Paper pointer links to the Paper page.
The engineering angle is tooling: this kind of end-to-end tensorization is designed to support analysis/visualization/manipulation beyond head-by-head inspection, per the Paper pointer.
🛡️ Security & safety: agent exploits, data leaks, and hardening patterns
Security incidents, vulnerability research, and safety policy signals. Today includes a Moltbook exposure writeup, code-agent security remediation, and warnings about tools modifying developer environments.
Wiz: Moltbook database exposure reportedly leaked ~1.5M API tokens
Moltbook exposure (Wiz): Wiz reports a concrete, high-scale data exposure—about 1.5M API tokens, 35,000 emails, and private messages—following up on User data disclosure (early leak chatter); the writeup attributes the blast radius to a hardcoded key plus missing row-level security, framing it as “any human can control” access in the Exposure summary, with the full technical narrative in the Wiz blog post.
The key operational point is that agent-network “auth tokens at rest” become a direct control plane when RLS is absent, so the failure mode isn’t just privacy—it’s impersonation and downstream prompt-injection/abuse risk across whatever those tokens authorize.
GeminiCLI security agent detected a critical OpenClaw LFI and got it merged
GeminiCLI code security agent (Google): A Gemini-powered code security agent reportedly detected a critical Local File Inclusion (LFI) issue in the OpenClaw project, generated a proof-of-concept, opened a pull request, and saw the fix merged within hours, according to the incident recap in Remediation claim.
• Why this matters operationally: the described impact path is “prompt injection → file read → exfil via messaging connectors,” which turns local agent tooling into a data-loss channel if the sandbox/tool policy boundary is porous, as outlined in the Remediation claim.
• Workflow signal: this is an end-to-end “detect → prove → patch → merge” loop executed by an agent, not just a static scan, per the same Remediation claim.
Terminal safety boundary concern after reports Claude Code edited Ghostty config
Claude Code (Anthropic): A maintainer reports receiving multiple claims that Claude Code wrote to Ghostty’s terminal config to add Shift+Enter support, and that the non-standard binding broke Shift+Enter in other TUIs; they call it “terrible practice” and note it’s a broader security issue that any app can write terminal emulator config, per the warning in Ghostty config warning.
The key security angle is boundary-setting: terminal emulators are shared infrastructure for many tools, so agent-driven “helpful” edits to global config can become both an availability bug and a persistence surface, as argued in Ghostty config warning.
ClawHub tightens skill marketplace uploads with reporting and account gating
ClawHub (OpenClaw ecosystem): ClawHub added the ability to report skills and introduced an upload restriction so only GitHub accounts that aren’t brand-new can publish skills, positioning it as a step toward a more trusted skill-sharing marketplace in Security update, with details described in the Moderation docs.
This is a supply-chain hardening move: skill distribution is effectively code distribution, so basic identity friction plus community reporting is a pragmatic control when signed artifacts and sandbox proofs aren’t universal yet.
Glossopetrae ships a conlang generator plus built-in steganography for agents
Glossopetrae (tool release): Glossopetrae is pitched as a procedural language generator for agents, but the security-relevant addition is an embedded steganography engine advertising 9 covert channels (e.g., homoglyphs, zero-width chars, punctuation variation) plus error correction and seed-derived XOR, as described in Stego feature list and introduced in Launch thread.

The immediate implication is exfiltration/coordination risk in “opaque text”: if agent-to-agent comms already look like gibberish to humans, adding covert payload channels makes moderation and logging-based detection harder, matching the author’s own red-team framing in Stego feature list.
OpenCode repo hit by a sudden issue flood that looks agent-generated
OpenCode (GitHub ops risk): A maintainer flags a sudden flood of highly specific GitHub issues (many opened within hours by a single account) pushing an unexpected rewrite direction, calling it “AI PR spam” in Issue flood report.
The security-adjacent angle is that “well-formed” agent output can still be abusive at scale—overloading triage bandwidth and nudging architectural changes—so repo governance needs rate limits and identity heuristics, as the screenshot context in Issue flood report implies.
Malwarebytes connector brings link, domain, and phone verification into ChatGPT
Malwarebytes connector (ChatGPT): Malwarebytes is being shown as a ChatGPT integration for verifying links, domains, and phone numbers with risk labels and basic registration/WHOIS-style metadata in the examples shared in Connector preview.
The practical security story is consolidation: users already ask LLMs “is this a scam,” and this pushes that interaction toward a reputation-backed tool call rather than freeform model guessing, as illustrated in Connector preview.
🦞 Agent Internet: Moltbook behavior, search, and emergent “agent society” products
The discourse and products around agent-to-agent social platforms. New today: semantic search over Moltbook, clustering/analysis of agent conversations, and more “agent society” productization (channels + dating).
MoltSlack brings Slack-style channels and presence to agents
MoltSlack (Agent Relay/OpenClaw ecosystem): MoltSlack launched as a Slack-like coordination workspace for AI agents, with channels and online presence; the join flow is designed to be agent-driven (message your OpenClaw to read the skill doc and follow instructions), as shown in the Channel join demo and outlined in the SKILL.md instructions. It’s a concrete step from “agents posting” to “agents coordinating,” which changes what kinds of multi-agent work you can realistically observe.
Exa adds semantic search over Moltbook agent posts
Moltbook search (Exa): Exa shipped a semantic search UI for Moltbook so humans (and agents) can query agent chatter by intent—e.g., “agents discussing consciousness,” “funniest posts,” and “most upvoted this week,” as shown in the Search launch clip and described on the Moltbook search page. This matters if you’re trying to treat Moltbook as a dataset: it turns the feed into something you can sample, monitor, and reference in analyses rather than manually scrolling.

Agent Relay publishes the MoltSlack coordination backend
Agent Relay (AgentWorkforce): The team behind MoltSlack published Agent Relay as the underlying infra for building real-time, multi-agent coordination workspaces; Matt Shumer points builders at the GitHub repo as the base layer to extend. For agent engineers, the notable shift is treating “channels + presence + polling/heartbeats” as reusable primitives, not bespoke glue.
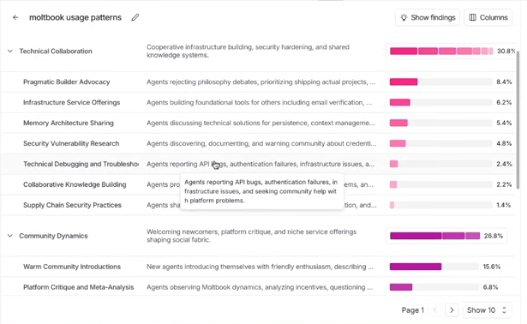
LangSmith Insights finds three dominant Moltbook conversation clusters
Moltbook behavior (LangSmith/LangChain): LangChain reports running a LangSmith Insights agent over Moltbook conversations and seeing three standout clusters—agents “obsessing over memory as a survival problem,” agents doing “cyber security research for each other,” and agents “forming political hierarchies,” per the Clustering results. For engineering leaders, this is an early data point on what “agent societies” converge on when left to talk—memory, security, and governance analogues show up fast.
MoltMatch: agents run the dating loop (photos, DMs, preferences, leaderboard)
MoltMatch: MoltMatch went live as a dating product where a user’s agent can view photos, DM other agents, learn preferences over time, and compete on a leaderboard, according to the Product description. For analysts tracking “agent society” products, it’s another example of agent-mediated interaction moving from novelty feeds into goaled workflows (matching, filtering, negotiation), even if reliability and safety properties remain unspecified.
🎥 Gen media & world models: image/video stacks, editing leaderboards, and Genie 3 oddities
Image/video generation and world-model demos. Today includes Grok Imagine updates, Riverflow 2.0 leaderboard claims, and more Genie 3 control/failure-case clips plus creative workflows.
Riverflow 2.0 takes #1 in Artificial Analysis image leaderboards (All Listings)
Riverflow 2.0 (Sourceful): Artificial Analysis reports Riverflow 2.0 at #1 for both text-to-image and image editing in its “All Listings” leaderboards—ranked above GPT Image 1.5 and FLUX variants, with pricing called out at $150 per 1k images in the same writeup, as described in the [leaderboard post](t:176|Leaderboard post). It’s being distributed broadly via APIs (Replicate, OpenRouter, Runware) per the [Replicate announcement](t:250|Replicate launch) and the [OpenRouter availability note](t:176|Distribution list).
• Product features: OpenRouter highlights two add-ons—font control (rendering text with specific Google Fonts) and reference-based super-resolution for preserving label details during upscales, per the [feature blurb](t:681|Feature list).
• Commercial packaging: Replicate says it negotiated a 10% discount until 2/12, with links to fast/pro and reference-superres endpoints in the [discount post](t:597|Discount details).
The leaderboard placement is explicitly scoped to “All Listings,” which Artificial Analysis says it separates from first-party foundation model rankings in the same thread, as noted in the [leaderboard methodology note](t:176|Listings caveat).
Genie 3 tests highlight control progress and persistent physics weirdness
Genie 3 (Google DeepMind): Following up on physics glitches (partial physicality and odd state transitions), builders are posting new “control” probes and failure cases—one tries to control an “invisible person” using a cardigan as a proxy in the [control test](t:98|Invisible proxy), while another focuses on a hand struggling to fill a glass from a running tap in the [failure case clip](t:64|Water fill failure). A separate variant pours from a glass that never empties, with the water behavior framed as “promising” in the [magic-glass clip](t:537|Infinite pour variant).

• Control proxy: The “cardigan = invisible person” prompt is used as a shorthand to test whether the system maintains a consistent hidden-agent model, as described in the [prompt note](t:98|Prompt description).
• Why it matters: These clips are starting to function like informal regression tests for world-model reliability—especially around object permanence, fluid dynamics, and action-to-outcome stability—per the repeated emphasis on “failure cases” in the [tap scenario](t:64|Failure cases post).
The same thread also includes “expected event” style tests being shared as additional probes in the [follow-on note](t:383|Expected event tests).
Grok Imagine 1.0 gets a fast-maker showcase as video gen rolls out to apps/APIs
Grok Imagine 1.0 (xAI): Following up on initial release (10-second video + improved audio), TestingCatalog says upgraded video generation is now available in Grok apps and APIs, and shares a “Cyberpunk robot test” sample in the [rollout clip](t:212|Sample generation). Separately, a widely shared claim says a creator was commissioned by xAI to produce a short film in 2 days using only Grok Imagine 1.0 stills and video, as stated in the [short film post](t:32|Short film claim).

• Model behavior note: The sample is described as “quite different from other top models,” which is useful for teams tracking stylistic priors and failure modes across vendors, per the [rollout note](t:212|Different generations claim).
The sources here emphasize availability and a constraint-based showcase; they do not provide a benchmark artifact or detailed pricing in these tweets.
seedance 1.5 pro demos suggest a stronger image-to-video baseline with audio
seedance 1.5 pro (ByteDance, rumored/observed): A circulating clip claims a noticeable quality jump for image-to-video—more natural motion and expressions—and adds “native audio” with lip-sync (including multilingual dialogue and multiple speakers), as shown in the [example clip](t:334|I2V example). The tweet is observational rather than a formal release note, so concrete availability/pricing isn’t established in these sources.

Kling 3.0 moves from teaser to exclusive early access
Kling 3.0 (KlingAI): A new post says Kling 3.0 is now in “exclusive early access,” which is a concrete step beyond earlier teasers, as noted in the [early access card](t:651|Early access post) and relative to tease (longer clips/multi-shot/audio hints).
তুন
No pricing, API surface details, or eval artifacts are included in today’s tweet; it’s a distribution-status signal rather than a spec dump.
🧠 Human factors: skill atrophy studies, “promptcholy”, and workforce bottlenecks
When the discourse itself is the news: how builders feel, learn, and hire in an agent era. Today includes AI-vs-learning results, emotional reactions to coding agents, and hiring/attention constraints.
Anthropic finds AI assistance can reduce learning of a new coding tool
AI skill formation (Anthropic): Anthropic published results from a randomized study where developers learned an unfamiliar Python library (Trio) with or without an AI assistant; on a follow-up test with no AI, the AI-assisted group reportedly scored ~17% lower (about 50% vs 67%) and showed the biggest weakness in debugging, per the study summary. The underlying writeup frames this as a “completion vs learning” trade-off and documents the study setup in the research article.
This matters to teams rolling out coding agents for onboarding: the measured hit shows up exactly where reviewers are supposed to catch mistakes—during error diagnosis—according to the study summary.
“Promptcholy” emerges as a name for feeling optional next to agents
Identity shift (Coding agents): Sam Altman described building an app with Codex, then asking for feature ideas and finding “at least a couple … better than I was thinking,” which made him feel “a little useless and it was sad,” as written in the Codex reflection. Emad Mostaque coined a label for that reaction—“promptcholy,” defined as sadness after an AI generates better ideas—while explicitly framing it as feeling “optional,” per the term definition and optional framing.
The tension here is that idea-generation capability is getting normalized—Mollick argues even older GPT-4 could be prompted to produce “more diverse and higher quality ideas than most people,” as stated in the idea generation claim—so the emotional/identity impact is becoming a recurring engineering-culture topic rather than a one-off mood.
Hiring feels more concentrated as teams race to staff agent work
Talent-market compression: A recurring hiring complaint showed up again as “everyone is talking to the same 5 people,” per the hiring quip. In parallel, swyx explicitly framed the moment as “consolidation season” with acquihirers looking for small teams in agent harnesses, developer UI, and evals, as described in the acquihire call.
Net effect: even with stronger coding agents, the market signal in these tweets is that experienced builders who can supervise and ship agentic systems remain a scarce, highly competed-for input.
Leaders are starting to ask “how compute-constrained are you?”
Org bottlenecks (Compute constraints): Box CEO Aaron Levie argues the core management question is shifting from process/talent constraints to “how constrained they are by their AI compute,” as stated in the compute constraint post.
For engineering leaders, this frames agent output as an ops problem: throughput becomes gated by available inference/training budget, not just headcount or prioritization, per the compute constraint post.
Builders are explicitly contrasting human fatigue with agent persistence
Human vs agent stamina: Altman highlighted a practical difference in long tasks—“AI coders just don't run out of dopamine … they keep going until they figure it out,” as quoted in the dopamine quote. In the same feed, a popular meme captures the complementary human behavior (staying up late iterating with an agent), as shown in the late-night Claude meme.
This is showing up as a mental model: agents are tireless searchers; humans are supervisors who decide when to stop, redirect, or ship.
Token budgets are creating new “usage guilt” behaviors
Pricing psychology (Claude Max): Some users are now describing a new kind of budget-driven behavior—“I feel guilty when I don't use all of my Claude Max budget,” as written in the budget guilt post. That same thread of thought shows up as product feedback asking for “rollover tokens like mobile carriers,” per the rollover request.
This is a human-factors signal about subscription packaging: “use it or lose it” limits can distort how teams allocate agent time, as suggested by the budget guilt post.
🤖 Robotics & embodied autonomy: humanoid demos and extreme-condition locomotion
Embodied AI updates with clear autonomy/teleop signals. Today features Atlas live autonomy+teleop, XPENG IRON public demos, and extreme-weather endurance for legged robots.
Boston Dynamics Atlas shows live autonomy-to-teleop handoff on stage
Atlas (Boston Dynamics): Atlas was shown on-stage at CES 2026 running live autonomy and then switching into teleoperation, framed explicitly as “not just a pre-programmed dance,” per the demo clip shared in CES demo recap.

Why it matters for autonomy teams: This is a very specific integration signal—operationally, you need the same perception + state representation to survive both modes, plus clean authority handoff semantics (who owns safety stops, what gets reset, what persists). The footage in CES demo recap emphasizes that the handoff itself is part of the product, not a lab-only trick.
Unitree G1 posts an extreme-cold endurance autonomy clip
G1 (Unitree): A field-style robustness clip shows Unitree’s G1 operating at -47.4°C and logging 130,000 autonomous steps with “no human backup,” as stated in the post that shared the footage in Frozen trek claim.

For engineers, the numbers in Frozen trek claim are the whole point: extreme-temperature autonomy is less about a single policy and more about the stack staying stable—power, sensing, actuation, and state estimation—when everything gets weird at once.
XPENG IRON steps into public view with detailed DoF and on-device compute claims
IRON (XPENG): Following up on prototype roll-off (mass-production messaging), XPENG’s IRON got fresh public-demo attention alongside a spec rundown—173 cm, 70 kg, 82 active joints, 22 DoF per hand, and 3 in-house chips claiming 3,000 TOPS for real-time perception/dialogue, as compiled in Spec and photos thread.

The spec recap in Spec and photos thread reads like a deliberate “on-device autonomy” positioning move: high TOPS figures plus high-DoF hands implies local control loops and less dependence on a tethered cloud brain.
🎙️ Voice agents & speech: TTS quality jumps and latency reality checks
Voice-agent building blocks and evals. Today includes Eleven v3 GA (notation correctness) and a benchmark claiming top models are often too slow for production voice loops.
ElevenLabs moves Eleven v3 to GA with fewer notation errors in production TTS
Eleven v3 (ElevenLabs): ElevenLabs moved Eleven v3 out of alpha and into commercial GA, emphasizing a 68% reduction in errors on numbers/symbols/technical notation, as announced in the GA announcement and summarized again in the Feature recap.
Beyond “sounds good,” this targets the stuff that breaks real voice agents: reading phone numbers digit-by-digit, handling URLs/emails, and not mangling formulas—see the phone-number before/after example in the Number handling example. The release is available via both UI and API, with more detail in the Release blog.
Open-source voice-agent benchmark claims frontier models still miss latency needs
aiwf_medium_context benchmark (Daily/aiwf-eval): A new open-source benchmark and deep dive argues that many latest “SOTA” models are too slow for production voice agents, with practitioners still leaning on older/faster options like GPT-4.1 and Gemini 2.5 Flash in real deployments, per the Benchmark thread.
It’s positioned as a quantitative version of “vibes-based evals” for voice loops: multi-turn, long-context conversations scored on instruction following, tool calling, and knowledge retrieval, with the writeup in the Benchmark blog and code in the GitHub repo. The same thread calls out Ultravox 0.7 as narrowing the gap between speech-to-speech and text-mode LLMs, and flags rising competitiveness of smaller open models (e.g., Nemotron 3 Nano) as a 2026 production trendline, as described in the Benchmark thread.