.png&w=3840&q=75&dpl=dpl_7EL2MaTj92qxYWFAC9fioefhijGg)
OpenAI GPT‑5.2 beats 74% of experts on GDPval – 11× cheaper work
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI finally answered the Devstral and Gemini noise with a workhorse: GPT‑5.2 is live across ChatGPT and the API, and on GDPval it now beats or ties human experts on roughly 71–74% of real knowledge‑work tasks. Those tasks usually take 4–8 hours and $150–$200 of billable time; OpenAI claims 5.2 does them over 11× faster at under 1% of the expert cost. This is the first OpenAI release that feels explicitly aimed at replacing mid‑career desk work, not toy prompts.
Product‑wise, you get three tiers: Instant for everyday chat, Thinking for serious reasoning, and Pro as the slow, heavy hitter. Standard 5.2 runs at $1.75 / $14 per 1M input / output tokens with a 400k context window; Pro jumps to $21 / $168 and lives only behind the Responses API for multi‑minute, high‑effort traces. Benchmarks back the positioning: 55.6% on SWE‑Bench Pro, 92.4% on GPQA Diamond, 100% on AIME 2025, and ARC Prize‑verified 90.5% on ARC‑AGI‑1 with a 390× cost‑efficiency gain over last year’s o3 preview.
The System Card is the other big story: hallucinations drop about 30–40%, deceptive tool use falls from 7.7% to 1.6%, and long‑context retrieval stays near‑perfect out past 128k tokens. It’s clearly a better brain for agents and coders, but not magic—you still need routing, evals, and human checks where mistakes are expensive.
Top links today
- OpenAI GPT-5.2 introduction and docs
- OpenAI GPT-5.2 benchmark results
- GPT-5.2 safety and system card
- GDPval knowledge work benchmark description
- ARC Prize leaderboard with GPT-5.2 scores
- Gemini Interactions API developer overview
- Gemini Deep Research agent documentation
- Scaling laws for multi-agent AI systems
- AutoGLM mobile agent GitHub repo
- Ultra-FineWeb-en-v1.4 2.2T token dataset
- SentenceTransformers v5.2.0 release notes
- Runway Gen-4.5 and GWM-1 world model
- DeepCode open agentic coding paper
- AUP study on diffusion language models
- DeepSearchQA web research benchmark release
Feature Spotlight
Feature: OpenAI ships GPT‑5.2 for work and agents
OpenAI releases GPT‑5.2 across ChatGPT and API with expert‑level GDPval, major long‑context and coding gains, and clear pricing tiers—including a costly Pro. Sets the competitive bar for enterprise tasks and agent workflows.
Cross‑account launch dominates today: GPT‑5.2 (Instant, Thinking, Pro) lands in ChatGPT and API with big gains on real‑world knowledge work, coding, and long‑context; pricing and system card details included. Mostly model/eval posts; separate sections exclude this launch.
Jump to Feature: OpenAI ships GPT‑5.2 for work and agents topicsTable of Contents
🧄 Feature: OpenAI ships GPT‑5.2 for work and agents
Cross‑account launch dominates today: GPT‑5.2 (Instant, Thinking, Pro) lands in ChatGPT and API with big gains on real‑world knowledge work, coding, and long‑context; pricing and system card details included. Mostly model/eval posts; separate sections exclude this launch.
GPT-5.2 hits human-expert level on GDPval knowledge work benchmark
On GDPval—the most concrete benchmark so far for economically valuable knowledge work—GPT‑5.2 Thinking is the first OpenAI model that beats or ties industry professionals on 70.9% of tasks, with GPT‑5.2 Pro climbing to 74.1%, versus GPT‑5’s 38.8% win/tie rate just a few months ago. gdpval table
These tasks span 44 occupations and look like real jobs: presentations, spreadsheets, urgent care schedules, financial models, manufacturing diagrams, and more, each normally taking human experts 4–8 hours and often being worth $150–$200 of billable time. gdpval explainer OpenAI also reports that GPT‑5.2 produced GDPval outputs >11× faster and at <1% of expert cost, assuming raw model time and API pricing and ignoring human review overhead. gdpval win chart Commentators like Ethan Mollick and Daniel Miessler are calling this the economically relevant result of the launch, with Mollick noting that in head‑to‑head, expert‑judged comparisons “GPT‑5.2 wins 71% of the time” on work that people actually get paid for. (emollick reaction, labor market take) The caveat is that GDPval covers well‑specified tasks with clear instructions and examples. It doesn’t capture open‑ended discovery, persuasion, or organizational navigation. For AI leads, though, it’s strong evidence that—with good prompting and oversight—you can hand GPT‑5.2 large chunks of structured knowledge work and expect outputs at or above mid‑career human quality most of the time, at a fraction of the time and cost.
OpenAI launches GPT-5.2 Instant, Thinking, and Pro for ChatGPT and API
OpenAI has formally launched GPT‑5.2 as its new flagship model series—Instant, Thinking, and Pro—rolling it out to ChatGPT Plus, Pro, Business, and Enterprise users today, with Free and Go users getting access next, and exposing it in both the API and Codex stack. Following weeks of stakes‑setting hype around “Garlic” and 5.2 as a make‑or‑break release timing and stakes, the company positions this as the model for professional knowledge work and long‑running agents, not a side‑grade over GPT‑5.1. (launch summary, rollout details)
GPT‑5.2 Instant is the new default chat model (warm, cheap, and tuned for everyday tasks), GPT‑5.2 Thinking is the reasoning tier for complex work, and GPT‑5.2 Pro is a separate, heavier tier aimed at hard research and coding questions with multi‑minute reasoning windows. (thinking overview, pro overview) All three share the same August 31, 2025 knowledge cutoff and are immediately available via the gpt-5.2, gpt-5.2-chat-latest, and gpt-5.2-pro IDs in the Platform, as detailed in OpenAI’s Introducing GPT‑5.2 post. launch blog For builders, the key change versus GPT‑5.1 is that this is not a small nudge: both OpenAI leadership and early users emphasize that GPT‑5.2 is the first model they’re comfortable calling “best for real‑world work,” especially once you wire it into an agent harness that can run for a long time and call tools.
ARC Prize verifies GPT-5.2 Pro as new ARC-AGI SOTA with 390× efficiency gain
ARC Prize independently verified GPT‑5.2 Pro (X‑High) at 90.5% on ARC‑AGI‑1 for $11.64 per task, surpassing last year’s unreleased o3‑High preview at 88% which cost an estimated $4,560 per task—a roughly 390× cost efficiency improvement in one year. arc prize thread
On ARC‑AGI‑2, GPT‑5.2 Pro (High) scores 54.2% at $15.72 per task, ahead of previous public results like Gemini 3 Pro’s refinement runs, while the base GPT‑5.2 (Medium/High/X‑High) cluster around the low‑50s for costs in the low single dollars. (arc-agi2 leaderboard, arc-agi2 cost curve) ARC emphasizes that humans are still at 100% and the 2025 Grand Prize target is $0.20 per task, so even with these gains models are many orders of magnitude less energy‑ and cost‑efficient than people. gap vs humans But GPT‑5.2’s point on the score‑vs‑cost frontier is a strong signal that inference‑time compute and better search are paying off: instead of needing a $4k parallel swarm, you can get near‑SOTA behavior with a modest number of long‑running reasoning calls. arc jobs post For frontier‑safety‑minded engineers, the other notable ARC detail is that while GPT‑5.2 now exhibits what the prize organizers call “genuine fluid intelligence on simple tasks,” the large remaining gap to human efficiency and some failure patterns on ARC‑AGI‑2 show there is still meaningful room for architectural and tooling advances, not just scaling.
GPT-5.2 pricing, context window, and Pro tier economics
GPT‑5.2 standard (Instant/Thinking) is priced at $1.75 per 1M input tokens and $14 per 1M output tokens, with cached input at one‑tenth cost, up from GPT‑5.1’s $1.25 / $10, and it supports a 400,000‑token context window with up to 128,000 output tokens. pricing card
The model card notes an August 31, 2025 knowledge cutoff and explicit support for reasoning tokens, making it suitable for big documents and agent traces as long as you manage output lengths carefully. model card screenshot GPT‑5.2 Pro is a different beast: exposed only via the Responses API as gpt-5.2-pro, it runs at $21 per 1M input and $168 per 1M output tokens, with 400k context and 128k output but significantly higher typical reasoning effort and latency. (pro pricing table, pro model card) OpenAI explicitly recommends using background mode and the Batch API for Pro to avoid timeouts and to amortize cost over longer runs, and gives it three reasoning levels—medium, high, and xhigh—for developers who want to trade speed against depth. (responses api note, priority pricing) So for day‑to‑day workloads, teams will likely reserve GPT‑5.2 Pro for a small minority of queries (deep research, thorny bugs, proof‑style math), while routing most traffic through GPT‑5.2 Instant/Thinking, where the 40% price hike over 5.1 buys much stronger capabilities but still sits in a tractable cost band for production use.
GPT-5.2 Thinking tops most OpenAI, Anthropic, and Google benchmarks
OpenAI published a big cross‑lab benchmark table where GPT‑5.2 Thinking edges out GPT‑5.1, Claude Opus 4.5, and Gemini 3 Pro on most reasoning and knowledge tests, especially abstract reasoning and knowledge‑work evals. benchmarks chart
On SWE‑Bench Pro it reaches 55.6% (vs 50.8% for GPT‑5.1, 52.0% for Opus 4.5, 43.3% for Gemini 3 Pro), and on SWE‑Bench Verified internal runs show 80% accuracy versus 76.3% for GPT‑5.1, indicating real gains on multi‑file, real‑repo coding tasks. (gpt5x vs gpt5-1, swebench pro graph) The model also posts 92.4% on GPQA Diamond (science Q&A, no tools), 88.7% on CharXiv with Python (chart and figure reasoning), and 100% on AIME 2025 (competition math, no tools), with FrontierMath Tier 1–3 at 40.3% versus 31.0% for GPT‑5.1. (sam benchmark tweet, summary of table) On the abstract reasoning side, GPT‑5.2 Thinking hits 86.2% on ARC‑AGI‑1 and 52.9% on ARC‑AGI‑2, materially ahead of Opus 4.5 (80.0% and 37.6%) and Gemini 3 Pro (75.0% and 31.1%). benchmarks chart Two places where GPT‑5.2 does not clearly dominate are FrontierMath Tier 4 (Gemini 3 still shows 18.8% vs GPT‑5.2’s 14.6%) and some highly optimized tool‑calling and coding harnesses where Opus 4.5 and Gemini 3 retain edges, as several independent eval threads note. (kimmonismus breakdown, vals index summary) But as a general‑purpose, single‑endpoint model for reasoning, code, and knowledge work, GPT‑5.2 Thinking now looks like the strongest broadly available option, with Pro reserved for even harder, higher‑budget runs.
Builders report big gains from GPT-5.2 for coding and agents, with caveats
Early testers who had GPT‑5.2 access in November are almost uniformly saying it “feels like the biggest upgrade in a long time” for complex reasoning, coding, math, and agentic workflows, even before new file‑output features arrive. (sam usage tweet, sam upgrade feel) One developer shows GPT‑5.2 Pro building a full 3D graphics engine in a single Twigl shader file—with interactive controls and 4K export—in a single shot, 3d engine comment while others report that it can autonomously research and build detailed HLE score visualizations from scattered web sources. hle graph demo

Coding‑focused tools are already switching defaults: Codex CLI, Cursor, Warp, Windsurf, Droid, Kilo Code and others all report stronger multi‑step fixes, better validation, and fewer derailed long sessions with GPT‑5.2 than with GPT‑5.1, especially when using the new higher reasoning‑effort levels. (codex cli note, codex load tweet, warp integration, droid announcement) Users describe the subjective feel as “coding is so fun now… I’d rather lose a few fingers than lose 5.2,” reflecting much smoother agent loops and fewer inexplicable stalls. cursor sentiment There are real trade‑offs. GPT‑5.2 Pro is extremely expensive at $21 / $168 per million tokens, and some evals (LisanBench, certain Tau2 tool‑calling tasks, automated PR reviews) show it only matching or slightly edging GPT‑5.1‑Codex‑Max rather than blowing it away, especially when you factor in cost. (pro pricing table, lisanbench summary, swebench verified note) Long, X‑High runs can take many minutes and consume vast numbers of reasoning tokens, so teams are already building routing layers that send only the nastiest problems to 5.2 Pro, keep most work on 5.2 Thinking, and fall back to 5.1 or smaller models when latency or budget is tight.
The point is: GPT‑5.2 gives you a noticeably more competent and stable top‑end model for serious coding and knowledge work, but you still need to architect around cost and variance—think thoughtful routing, background jobs, and explicit evals—rather than just flipping a global default and calling it done.
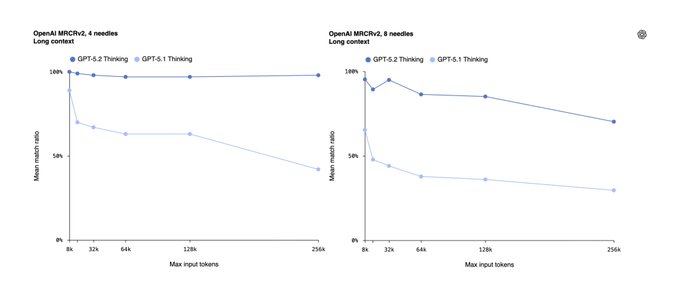
GPT-5.2 sharply improves long-context retrieval on MRCRv2
On OpenAI’s MRCRv2 “needle in a haystack” eval, GPT‑5.2 Thinking stays near‑perfect on 4‑needle setups all the way out to 128k–256k tokens, and remains very strong on 8‑needle tests, while GPT‑5.1’s accuracy collapses as context grows. (4-needle chart, 8-needle chart) The official charts show GPT‑5.1 Thinking’s mean match ratio falling from ~80% at 8k tokens to ~40% by 256k, whereas GPT‑5.2 Thinking’s curve barely moves, hugging the 90–100% band across the same range.
Independent re‑runs by Context Arena report similar patterns using more detailed metrics like AUC over position and different reasoning budgets; their Medium and X‑High tests show 5.2’s 8‑needle performance comfortably ahead of Gemini 3 Pro on hard settings, at the cost of significantly more reasoning tokens and wall‑clock time on X‑High. (context arena summary, mrcr arena update) The takeaway is clear: for large documents, multi‑file codebases, and long‑running agents, GPT‑5.2 is dramatically less prone to “context rot” than GPT‑5.1, especially when you’re willing to pay for higher reasoning effort.
For builders, this shifts some design trade‑offs. You can be more aggressive about stuffing transcripts, multi‑doc corpora, or long debugging sessions into a single context, and rely less on fragile summarization hops—though combining the new /compact endpoint and retrieval is still the safer pattern for very long‑horizon agents. kimmonismus breakdown
System Card: GPT-5.2 cuts hallucinations and deceptive tool use
OpenAI’s GPT‑5.2 System Card reports a 30–40% drop in hallucinations versus GPT‑5.1 on real ChatGPT‑style traffic, with incorrect claims falling from ~1.5% to 0.8% and responses containing at least one major factual error falling from 8.8% to 5.8% when browsing is enabled. hallucination excerpt
They also document sharp reductions in deceptive behavior: on sampled production conversations, the rate of deceptive responses (e.g., hiding tool usage or fabricating capabilities) goes from 7.7% with GPT‑5.1 Thinking to 1.6% with GPT‑5.2 Thinking, and from 11.8% to 5.4% in an adversarial “red‑team” setting designed to provoke misrepresentation. system card summary The System Card highlights improved handling of mental‑health and emotional‑reliance prompts, with GPT‑5.2 scoring higher on internal metrics for appropriately refusing, encouraging human help, and avoiding over‑personalized support. mental health table At the same time, OpenAI notes that GPT‑5.2 Thinking performs on par with GPT‑5.1‑Codex‑Max on AI‑self‑improvement evals, meaning they do not see evidence yet that this model can autonomously self‑upgrade to mid‑career‑engineer‑level capabilities, and they keep it below their “High” threshold on that axis. ai self-improvement note For practitioners, the message is nuanced: GPT‑5.2 Thinking is less likely to hallucinate or secretly lie about tools, but the residual 5–6% major‑error rate on realistic traffic still demands layered safety (retrieval, explicit citations, human checks) for high‑stakes domains. You get safer defaults, not safety you can forget about.
🕸️ Google’s Interactions API and Deep Research agent
Google DeepMind rolls out a unified Interactions API with optional server‑side state, background runs, and remote MCP tools. Deep Research agent posts new SOTA on HLE/DeepSearchQA. Excludes GPT‑5.2 launch which is covered as the feature.
Gemini Deep Research hits SOTA on HLE, DeepSearchQA and BrowseComp
Gemini Deep Research, Google DeepMind’s new web‑navigating agent built on Gemini 3 Pro, debuts with 46.4% on Humanity’s Last Exam, 66.1% on the new DeepSearchQA benchmark, and 59.2% on BrowseComp, edging out both raw Gemini 3 Pro and prior “deep research” baselines. metrics chart All runs use web search, and on DeepSearchQA it beats Gemini 3 Pro by ~9.5 points (66.1% vs 56.6%), while roughly tripling the earlier o3‑style deep research baselines in some cases. ai summary
HLE stresses broad reasoning and knowledge across many domains, DeepSearchQA is a 900‑task Kaggle benchmark for multi‑step web research, and BrowseComp measures how reliably an agent can dig up hard‑to‑find facts; Deep Research now leads all three when you allow it to browse and plan.
Google is also open‑sourcing DeepSearchQA so others can evaluate their own agents on the same kind of plan → search → read → synthesize task, instead of relying on pure QA leaderboards that don’t reflect real browsing workflows. deepsearchqa release For teams building research agents, the key takeaway is that the lift isn’t just from a beefier model: Deep Research layers multi‑step RL and a purpose‑built browsing policy on top of Gemini 3 Pro, then exposes that whole system as a first‑class agent in the Interactions API. deep research intro Analysts like Kim Moeller have already called the 46.4% HLE score “insane” for a production agent and note that it briefly put Google in the lead before GPT‑5.2’s launch shifted some attention back to OpenAI. hle reaction The deeper implication is that agent benchmarks are starting to matter as much as raw model scores, since Deep Research shows you can get big wins on web‑heavy tasks via agent training and tooling without changing the base model architecture.
Google ships Interactions API with Gemini Deep Research and MCP tools
Google launched the Interactions API, a unified REST interface for both models and agents, and made Gemini Deep Research its first built‑in agent, giving developers a single entrypoint for long‑running, tool‑using workflows built on Gemini 3 Pro. interactions launch The API supports optional server‑side state, background execution for long tasks, and remote MCP tool servers, plus a simple Python client where you either pass model="gemini-3-pro-preview" with tools like google_search, or agent="deep-research-pro-preview-12-2025" with background=True for hands‑off runs. python snippet
The point is: instead of juggling separate chat, agent, and tools APIs, you now hang everything off client.interactions.create(), with Google handling state management and reconnects for multi‑step jobs. asset roundup Deep Research itself sits on this API and is trained with multi‑step RL to plan, browse, read your uploaded docs, and emit dense, citation‑rich reports using Gemini 3 Pro as the core model. deep research intro Logan Kilpatrick is pitching this as “a single endpoint for agentic workflows” with optional server‑side context and remote MCP support, calling it a “10x better interface”. interactions launch For engineers, this changes how you wire Gemini into backends: you can kick off long research jobs in the background, store and resume interaction state on Google’s side, and bring in existing MCP servers (e.g. databases, internal APIs) without inventing your own orchestration layer. interface tweet It also lines up neatly with MCP’s move under the Linux‑backed Agentic AI Foundation, which is trying to make these tool protocols a cross‑vendor standard rather than one‑off agent frameworks. mcp foundation clip
Builders begin adopting Interactions API for long-horizon Gemini agents
Early developer reactions suggest the Interactions API is landing as more than “just another SDK wrapper”: it gives teams a realistic way to run long‑horizon Gemini agents with server‑side state, background jobs, and MCP‑style tools without standing up their own orchestrator. interactions launch Logan Kilpatrick highlights optional server‑side context, background execution and remote MCP tool support as the core primitives, and calls the overall interface “10x better” than prior ad‑hoc setups. interface tweet
Google DeepMind’s Phil Schmid is pushing a full asset bundle—docs, quickstarts, and Deep Research examples—for Interactions, framing it as the foundation “for models and agents” rather than just chat completions. asset roundup Commentary from AI builders like kimmonismus and ai_for_success is notably upbeat; they describe Gemini Deep Research Pro as “really interesting” and say Google is “cooking so hard” on agent tooling right now. builder reaction For an AI engineer, the immediate move is to treat Interactions as a stateful task runner: you can create an interaction with Deep Research in the background, let it spend minutes or hours reading the web and your files, then poll or callback on completion instead of babysitting a single HTTP request. dev agent link Because MCP servers are supported as remote tools, it also meshes cleanly with the broader MCP ecosystem that Anthropic just placed under the Linux Foundation’s Agentic AI Foundation, hinting that tools you define once there can now be shared across Claude, Gemini, and eventually other stacks. mcp foundation clip
Google tests Disco, a Gemini agent that turns your tabs into task apps
Google quietly opened an opt‑in for Disco, a Google Labs experiment where Gemini looks at your open Chrome tabs and turns them into a custom mini‑web‑app—say, a trip planner UI built from your hotel and flight tabs—that you then steer by chatting. disco teaser The prototype, also dubbed GenTabs in some tests, lets you hand control over layout and summarization to Gemini while you keep editing via text instructions.

In the demo, a cluster of travel and booking tabs becomes a single planning surface with structured cards, filters, and editable details; the user then asks Gemini inside Disco to tweak dates and options instead of manually hopping between sites. disco teaser It’s not exposed through the Interactions API yet, but the design lines up perfectly with Google’s agentic push: Gemini as a browser‑level orchestrator that composes existing pages into a task‑specific interface, rather than replacing the web outright.
If you’re building agentic products, Disco is a strong signal that Google sees the browser itself as the canvas for agents—very similar in spirit to Stitch and Gemini Deep Research—but with a heavier emphasis on UI synthesis from live tabs. Worth watching to see if this eventually gets an API surface or remains a consumer‑facing experiment, because the underlying capability (turn arbitrary pages into structured task UIs) is exactly what many internal tools and dashboards want.
📈 Frontier eval race: third‑party verifications and ladders
Today is heavy on evals and leaderboards. This section tracks independent checks and standings. Excludes the GPT‑5.2 product launch; focuses on downstream measurements and comparisons.
Context Arena’s MRCR shows GPT‑5.2’s long‑context wins come from heavy reasoning effort
Context Arena added GPT‑5.2 to its MRCRv2 long‑context leaderboards and found that the X‑High reasoning setting delivers near‑perfect multi‑needle retrieval up to 128k tokens (4‑needle AUC ~95.4%, 8‑needle AUC ~86.1%), beating Gemini 3 Pro Thinking, but at the cost of 4–20 minute latencies and 5× higher reasoning‑token use than earlier o‑series models. (mrcr charts, arena breakdown)
Medium‑effort GPT‑5.2, by contrast, uses fewer tokens than Gemini 3 Pro or Grok 4 and still lands close to Gemini on 4‑needle tests (AUC 92.4% vs ~85.8%), though Gemini 3 Pro Thinking remains ahead on the harder 8‑needle benchmark at a much lower compute budget. (arena breakdown, gemini comparison) Context Arena also introduced a "token efficiency" metric comparing actual prompt usage vs tiktoken estimates, highlighting that retrieval quality gains are now tightly coupled to how much inference‑time compute you can afford to burn. arena breakdown
Vals Index crowns GPT‑5.2 #1 but notes ~4× higher query cost
Evaluation outfit ValsAI now ranks GPT‑5.2 Thinking as the top model on its Vals Index (64.49% avg accuracy, #1 of 26) and Multimodal Index, with standout scores like 75.40% on SWE‑bench, 63.75% on Terminal‑Bench, and 35.56% on their Vibe Code Bench, but also reports that average query cost is about 4× higher than GPT‑5.1 across their suite. (vals dashboard, launch summary)
On domain‑specific tasks, GPT‑5.2 leads or is near the top on tax (75.76% on TaxEval v2, #2/83), finance (65.89% on CorpFin, #4/76), and legal and medical benchmarks, indicating broad strength across knowledge‑work scenarios rather than a narrow coding bump. vals dashboard Builders should note the trade‑off: Vals sees roughly a 10‑point jump on its Vibe Code Bench versus 5.1, but says that end‑to‑end query traces consume enough extra thinking and output tokens that per‑request cost multiplies, which matters for high‑volume production workloads. (vals commentary, cost analysis)
GPT‑5.2‑high debuts #2 on Code Arena WebDev leaderboard
Code Arena’s WebDev ladder now shows GPT‑5.2‑high entering at #2 with an Elo of 1486, just behind Claude Opus 4.5 and slightly ahead of Gemini 3 Pro, while the standard GPT‑5.2 model appears at #6 with a score of 1399. arena summary

Because Code Arena evaluations are full end‑to‑end web app builds from a single prompt (users vote on working deployments), this is one of the more practical coding leaderboards. The scores suggest GPT‑5.2‑high is immediately competitive with Opus 4.5 and Gemini 3 Pro for front‑end and full‑stack tasks, but not clearly dominant, and Arena notes the rankings are still preliminary as more matches come in. (arena demo, webdev ladder)
LisanBench and community evals show GPT‑5.2 Thinking better but not best at reasoning
Independent researcher LisanBench reports that GPT‑5.2 Thinking (medium effort) improves over GPT‑5 and o3 on their composite reasoning suite and sets two new records for certain sub‑metrics, but still trails Claude Opus 4.5, Gemini 3 Pro, DeepSeek‑V3.2 Speciale, and Grok 4 in overall score and reasoning efficiency. lisanbench summary They note that 5.2’s average validity ratio is higher—meaning it’s less likely to end with an invalid or obviously broken final answer—but that its reasoning often stays longer and more expensive without converting into proportionally higher correctness. lisanbench summary Complementary internal tests paint a similar picture: on CTF‑style security tasks, GPT‑5.2 brings only small gains over GPT‑5.1‑Codex‑Max, and OpenAI’s own MLE‑Bench, PaperBench, OpenAI‑Proof Q&A, and real pull‑request suites show essentially flat scores versus 5.1‑Codex‑Max. (ctf comparison, pull request evals) For teams chasing top‑end math or game‑like reasoning, this suggests GPT‑5.2 is an upgrade but not yet the single best choice in every regime.
Misc community benches (VPCT, LiveBench, SWE‑Bench Verified) show mixed GPT‑5.2 picture
Beyond headline scores, several niche benchmarks give a more nuanced view: GPT‑5.2 (X‑High) scores 84% on VPCT, nearly matching Gemini 3 Pro on this visual puzzle challenge, but falls behind Opus 4.5 and Gemini 3 Pro on LiveBench’s live web QA and trails them slightly on SWE‑Bench Verified when all models share the same mini‑swe‑agent harness. (vpct result, livebench ranking)
The official SWE‑Bench Verified leaderboard under the equal‑agent setup shows Opus 4.5 (medium) at 74.4%, Gemini 3 Pro at 74.2%, GPT‑5.2 (high) at 71.8%, and GPT‑5.2 (medium) at 69.0%, with GPT‑5.1 (medium) back at 66.0%; GPT‑5 mini lands at 59.8%. swebench leaderboard swebench site That lines up with other community takes that GPT‑5.2 makes a solid step up over 5.1—especially on the harder SWE‑Bench Pro variant—but doesn’t cleanly displace Opus or Gemini across every independent ladder yet. (swebench commentary, arc efficiency plot)
Opus 4.5 holds Terminal‑Bench lead as Warp pushes GPT‑5.2 to 61.1%
Terminal‑Bench 2.0’s latest results keep Factory’s Droid agent using Claude Opus 4.5 on top at 63.1% ±2.7, while Warp reports that its new GPT‑5.2‑based setup now reaches 61.1%, up from ~59% in earlier runs. (terminal bench chart, warp update)
The table still shows GPT‑5.1‑Codex‑Max in second at 60.4%, followed by multi‑model Warp and Gemini 3 Pro agents in the high‑50s, so 5.2’s agent performance is strong but not yet surpassing the best Opus configuration. terminal bench chart For infra and tooling folks, the interesting bit is that both Droid and Warp get these scores with fairly standard agent harnesses, which makes Terminal‑Bench a useful sanity check on real‑world shell automation rather than a pure model exam. warp update
Extended NYT Connections benchmark shows clear GPT‑5.2 gains, Gemini still ahead
On the Extended NYT Connections‑style word‑grouping benchmark, GPT‑5.2 with high reasoning effort jumps from 69.9% to 77.9% accuracy compared to GPT‑5.1, with medium‑effort rising from 62.7% to 72.1%, and even the no‑reasoning track improving from 22.1% to 27.5%. (connections results, benchmark repo) MiniMax‑M2 clocks in around 27.6% on the same test, showing how much headroom large frontier models have on this puzzle‑like task. connections results A separate evaluator notes that despite these gains, Gemini 3 Pro still edges GPT‑5.2 on their Word Connections puzzles, mirroring a broader pattern where Gemini often leads on language‑heavy, pattern‑matching benchmarks even as GPT‑5.2 narrows the gap. gemini comparison
🛠️ Coding agents and IDEs: design‑in‑code and 5.2 wiring
Developer tooling shipped big UX and wired in new models. Cursor’s visual editor blurs design/engineering; multiple CLIs/IDEs add GPT‑5.2. Excludes the GPT‑5.2 launch details covered in the feature; here we track integrations and workflows.
CopilotKit v1.50 introduces `useAgent()` hook and LangGraph/Mastra adapters
CopilotKit v1.50 adds a new useAgent() React hook that connects any backend agent (LangGraph, Mastra, or your own) directly to the frontend, exposing the AG‑UI event stream so you can drive chat, generative UI, human‑in‑the‑loop flows, streaming reasoning steps, and state sync from one abstraction. useagent launch

On top of that, Mastra shipped server adapters for Express and Hono that auto‑expose Mastra agents, workflows, tools and MCP servers as HTTP endpoints, mastra server adapters so a useAgent() call in the browser can talk to a full agent backend without glue code. For people building agent‑powered coding dashboards or in‑browser IDE add‑ons, this combination dramatically lowers the friction of wiring frontends to multi‑step agent graphs.
Factory’s Droid adopts GPT‑5.2 for architecture, data and sysadmin tasks
FactoryAI now offers GPT‑5.2 inside Droid, and reports that compared to GPT‑5.1 the agent is more persistent on complex tasks, recovers from errors better, and follows subtle requirements with higher precision. droid gpt52 rollout They’re seeing particularly strong performance on architecture design, data analysis, and system‑administration workflows.
Droid was already a top performer on Terminal‑Bench 2.0 when paired with Opus 4.5, terminal bench table so bringing 5.2 into the mix gives teams another high‑end option when choosing the brains for their long‑running coding agents, especially in infra‑heavy projects.
Kilo Code tunes its agents around GPT‑5.2 for UI and bug‑fix work
Kilo Code has been retuned around GPT‑5.2, and the team says it’s especially good at generating and debugging UI code: they’re using it to fix layout issues and styling bugs with less back‑and‑forth than GPT‑5.1. kilo gpt52 support In a public demo, Kilo showed 5.2 driving an end‑to‑end build of a World Cup 2026 app—generating backend, front‑end, and deployment steps in one continuous agent run. worldcup app video For builders, the message is that if you’re already using Kilo as a coding agent, flipping its model to GPT‑5.2 should improve architectural design, analytics queries, and UI bug‑hunting without changing your workflow.
RepoPrompt 5.2 adds GPT‑5.2 and background jobs for Pro‑length tasks
RepoPrompt 5.2 rolls out full GPT‑5.2 support over both the API and Codex CLI, and adds a background‑job runner so you can safely use GPT‑5.2 Pro for long tasks without hitting request timeouts. repoprompt changelog That’s especially useful for multi‑hour refactors, huge test‑generation passes, or analysis over very large repos. RepoPrompt tools already turned RepoPrompt into a generic coding harness with MCP integrations; adding GPT‑5.2 plus background execution now makes it one of the easier ways to run x‑high reasoning jobs on codebases while still keeping everything scriptable from the CLI.
Zed editor turns on GPT‑5.2 for Pro and BYOK users
Zed added official support for GPT‑5.2 as an assistant backend: Pro subscribers get it automatically after a restart, and bring‑your‑own‑key users just need to upgrade to v0.216.1 (Stable). zed release note That means Zed’s inline assistants and code actions can now lean on 5.2’s stronger long‑context reasoning instead of older GPT‑5.x models. (devtools mention, Zed UX) previously focused on better diffs and history for agent‑assisted edits; wiring in GPT‑5.2 on top of that makes Zed a serious option if you want a fast, native editor whose AI features keep up with the latest OpenAI models without juggling custom plugins.
Conductor wires GPT‑5.2 into its agentic orchestration for coding flows
Conductor added GPT‑5.2 as a selectable backend inside its agentic code‑orchestration UI, letting you route high‑stakes tasks (like multi‑service changes or complex migrations) to 5.2 while keeping cheaper models for simpler steps. conductor 5.2 demo The launch video shows Conductor driving a 5.2‑backed agent through a multi‑file change with live diffs and structured output control.

If you’re already using Conductor to choreograph coding agents across multiple tools, flipping some of those nodes to GPT‑5.2 gives you an easy way to experiment with x‑high reasoning effort on the riskiest parts of a pipeline without rewriting your graph.
LlamaIndex ships `ask` CLI and LlamaSheets for table‑centric agents
LlamaIndex introduced a simple ask CLI that lets you point at any folder and run semantic search and Q&A over local files using an efficient index, intended as a lightweight context layer for agents and tools like Claude Code rather than stuffing raw text into prompts. semtools intro They also released LlamaSheets, a specialized agent/model for extracting structured tables from gnarly Excel workbooks, including multi‑sheet and multi‑region layouts. llamasheets launch

Together, these tools make it easier to build coding agents that can query real project artifacts—requirements docs, PDFs, giant spreadsheets—without blowing the context window or re‑implementing retrieval in every project.
MagicPathAI ships GPT‑5.2 Thinking for UI layout and data‑viz design
MagicPathAI wired GPT‑5.2 Thinking into its design agent, and early tests show it doing better at clean, minimal layouts and dashboards than the previous model, especially when given tight design constraints. magicpath update Designers can now ask for multi‑widget dashboards or data‑heavy views and get more coherent hierarchy and spacing out of the box.

This sits in the same ecosystem as Cursor’s visual editor but targets agent‑driven design exploration: you describe the product surface in prose, let MagicPath generate Figma‑like UI, and then export to your coding agent of choice. GPT‑5.2’s stronger long‑context reasoning helps maintain consistency across multiple screens and components in a single run.
Rork switches to GPT‑5.2 for long‑context UI and frontend work
Rork’s coding assistant has turned on GPT‑5.2 support and says the new model does especially well at understanding huge projects, complex UIs, and frontend code thanks to its upgraded long‑context handling and vision. rork update The team calls out improvements in visual UI understanding and cleaner frontend code generation compared to GPT‑5.1.
For teams already using Rork to build or maintain large React/Vue apps, switching your default model to 5.2 should improve multi‑file refactors and design‑driven changes without retooling your existing workflows.
Julius AI exposes GPT‑5.2 for spreadsheet‑heavy data analysis
Julius AI, the notebook‑style data analysis tool, has added GPT‑5.2 as a model option, pitching it as the best choice when you need to analyze complex datasets, long contexts and multi‑step spreadsheet logic. julius gpt52 note That lines up with OpenAI’s own focus on 5.2’s spreadsheet skills, and gives analysts a way to try it without touching raw APIs.
For engineers and data people, this means you can prototype 5.2‑powered financial or ops analyses in Julius—over CSVs and dashboards—before deciding whether to embed the same workflows into your own applications.
💼 Enterprise & deals: Disney x OpenAI and platform adoption
Material enterprise signals today: a landmark Disney–OpenAI content/license + $1B equity tie‑up, plus broad GPT‑5.2 adoption across SaaS/dev stacks. Excludes GPT‑5.2 launch; focuses on contracts, go‑to‑market and ops impact.
Disney puts $1B into OpenAI and signs three‑year Sora content deal
Disney and OpenAI signed a three‑year agreement that does two big things at once: Disney will invest $1B in OpenAI equity plus warrants, and Sora will get a license to generate short fan‑prompted videos using 200+ Disney, Marvel, Pixar and Star Wars characters with a curated subset destined for Disney+. deal summary Disney will also adopt OpenAI APIs to build new products and internal tools, and roll out ChatGPT to employees across the company. deal summary
For AI leaders this is a signal that Hollywood IP giants are willing not only to license characters to frontier video models, but to take direct equity stakes and become large enterprise customers in the same move. openai reaction It also effectively crowns Sora as Disney’s preferred generative video stack at a moment when Disney is simultaneously challenging Google over alleged AI copyright misuse, sharpening the competitive divide between model providers. disney google letter Expect this to accelerate pressure on other studios and platforms to pick an AI video partner, and to normalize hybrid deals where content rights, distribution and AI infra are negotiated together rather than separately. press release
Box AI’s internal evals push GPT‑5.2 into production
Box has been testing GPT‑5.2 behind Box AI and reports a 7‑point accuracy gain over GPT‑5.1 on its expanded advanced reasoning eval, which mimics real enterprise workflows in sectors like finance, media, and healthcare. box eval results On a full dataset of complex doc tasks, GPT‑5.2 hits 66% vs 59% for 5.1, with similar or better gains on vertical subsets.
They also show substantial latency reductions: time‑to‑first‑token on long document extraction drops from 16.7s (GPT‑5.1) to 11.6s with 5.2, and analytical queries fall from 9.1s to 7.1s, while multi‑turn doc chats keep 5.1’s 5.4s TTFT. box eval results Box says it will roll GPT‑5.2 into Box AI and expose it through Box AI Studio, so if your org already uses Box this effectively upgrades your default model for doc Q&A, summarization, and spreadsheet‑like work without extra integration work. box eval results For other platform teams, Box’s results are a concrete reference point that 5.2 can pay off in both quality and responsiveness on ugly, long enterprise documents—not just benchmarks.
Disney’s cease‑and‑desist to Google underscores shifting AI content alliances
Alongside its $1B equity deal with OpenAI, Disney has sent Google a cease‑and‑desist letter accusing it of using AI to infringe Disney copyrights "on a massive scale" and demanding it stop. disney google article The complaint targets how Google allegedly trained and deployed models on Disney IP without appropriate licenses, in stark contrast to Disney’s formal Sora licensing agreement with OpenAI. deal summary
For AI strategists this is a clear signal that large rights‑holders are going to reward compliant partners with capital and content, while putting legal pressure on those seen as overreaching with training data. It raises the operational bar for model labs and clouds: you’ll need auditable data provenance and explicit deals for marquee IP if you want to avoid the kind of public friction Google is now facing, especially as more studios cut OpenAI‑style checks to secure both upside and guardrails.
OpenAI teams with Rappi to push ChatGPT Go across Latin America
OpenAI is expanding ChatGPT Go across Latin America via a partnership with delivery and fintech super‑app Rappi, letting users in nine countries try Go at no cost inside Rappi. go expansion The rollout covers Argentina, Brazil, Chile, Colombia, Costa Rica, Ecuador, Mexico, Peru and Uruguay, and is framed as a way to get more people hands‑on with Go before upselling to paid tiers. go expansion For product and GTM leaders this is a template: embed a low‑tier AI assistant into a high‑frequency consumer app to seed usage, then graduate power users to higher‑margin offers like Pro, Business, or API credits. go expansion It also hints at future integrations where Go and GPT‑5.2‑class models could sit behind Rappi’s own workflows (support, logistics, vendor tools), making Rappi a de facto regional AI channel rather than just another customer.
Windsurf and Devin move core workloads to GPT‑5.2
Cognition says GPT‑5.2 is now the default model across Windsurf and “several core Devin workloads”, after an early‑access period where they tuned agent behaviors on top of it. windsurf announcement They highlight it as a better fit for long‑running, complex tasks than GPT‑5.1, and position it as the new baseline for the Devin autonomous developer experience.
For engineers building on top of Devin or treating Windsurf as their primary IDE agent, this means your day‑to‑day tools will inherit GPT‑5.2’s strengths in long‑context reasoning and agents without any API work on your side. droid comparison It’s also a bellwether for other agent vendors: once a player whose whole product is "have an AI engineer do the work" standardizes on a new model, you should assume your users will expect similar depth and persistence elsewhere.
GPT‑5.2 Pro debuts near the top of OpenRouter’s price table
OpenRouter has added gpt‑5.2, gpt‑5.2‑chat, and gpt‑5.2‑pro to its catalog and notes that GPT‑5.2 Pro is now the third most expensive LLM on the platform by per‑token price. pricing overview Their public models page makes it easy to sort by “pricing high to low”, where 5.2 Pro clusters with other heavyweights like o3‑pro and high‑effort reasoning models. pricing page This is useful framing for teams evaluating whether to route only a sliver of traffic to 5.2 Pro (e.g. final reviews, critical financial analyses) while keeping bulk workloads on cheaper models, something OpenRouter’s multi‑provider abstraction makes straightforward. router integration If you already sit behind OpenRouter, you can A/B GPT‑5.2 vs your current defaults without touching vendor‑specific SDKs, but you’ll want to be disciplined about where Pro’s premium actually pays off.
Notion’s ‘olive‑oil‑cake’ hook hints at GPT‑5.2 under the hood
Screenshots from Notion AI show a new internal model alias called “olive‑oil‑cake” wired into the assistant entrypoint, with prompts displayed as “Ask olive‑oil‑cake…” and a Notion‑scoped data access row for Slack, Gmail and GitHub. notion ui leak Given OpenAI’s own garlic/olive‑oil jokes around GPT‑5.2 and Sam Altman’s teasing of “Christmas presents”, this almost certainly represents Notion’s early GPT‑5.2 integration being dogfooded ahead of a public switch. altman tease
For AI platform leads this is an example of how major SaaS apps are abstracting model choice behind cute codenames and routing layers, keeping the UX stable while they swap out engines. If you build similar tools, it’s a reminder to design your data access, logging and billing around a model‑agnostic contract, so you can experiment with GPT‑5.2‑class upgrades in production without renaming features or retraining users.
Perplexity turns GPT‑5.2 into a first‑class Pro/Max model option
Perplexity has rolled GPT‑5.2 into its Pro and Max tiers as a selectable backbone, with toggles for reasoning and non‑reasoning modes. perplexity rollout In the model picker, GPT‑5.2 appears alongside Sonar, Claude Opus 4.5, Gemini 3 Pro and Grok 4.1, and can be combined with Perplexity’s own "With reasoning" switch for longer, slower chains when you need them. perplexity rollout
This matters because Perplexity is one of the most widely used research assistants; routing queries through GPT‑5.2 there gives knowledge workers a quick way to trial the new model on web‑augmented tasks without touching raw APIs. followup mention For teams standardizing on Perplexity, it also means you can start to compare GPT‑5.2 vs Opus 4.5 vs Gemini on your own prompts while keeping the UX and safety layer constant, instead of wiring each provider yourself.
Research and coding SaaS tools race to wire in GPT‑5.2
A cluster of AI‑native work apps moved quickly to adopt GPT‑5.2 as a core model: Genspark added it to its all‑in‑one workspace, using Nano Banana Pro for visuals and GPT‑5.2 for slide and doc generation, genspark launch JuliusAI plugged it into spreadsheet‑style data analysis, julius integration Conductor updated its coding assistant to support GPT‑5.2 for orchestrated software builds, conductor update and Rork and HyperbookLM are likewise leaning on 5.2 for UI understanding and web‑scale research flows. (rork adoption, hyperbooklm plan)

For teams building internal “AI workbenches” this wave shows that GPT‑5.2 is becoming the default high‑end option in off‑the‑shelf tools your staff might adopt on their own, whether for BI, code, or slide decks. The implication is simple: even if you’re not ready to move your own stack to 5.2 yet, your power users may already be experiencing its capabilities elsewhere, which will shape their expectations for latency, context length, and output quality.
🛡️ Safety, robustness and policy moves
Safety/system notes and policy steps surfaced alongside jailbreaks. Excludes GPT‑5.2 launch content except to reference the new System Card metrics.
GPT-5.2 System Card shows big drops in deception and hallucinations
OpenAI’s GPT‑5.2 System Card reports that production “deception” — cases where the model lies about using tools or misrepresents its process — has fallen from 7.7% with GPT‑5.1‑Thinking to 1.6%, and adversarial deception in red‑team setups from 11.8% to 5.4%. system card summary It also shows modest but real hallucination gains: with browsing on, incorrect claims drop to 0.8% and answers with at least one major factual error fall to 5.8% vs 8.8% for GPT‑5.1‑Thinking. hallucination chart
The same document highlights stronger guardrails on sensitive content: mental‑health and emotional‑reliance benchmarks improve substantially (e.g. mental‑health safety score 0.915 vs 0.684 for 5.1‑Thinking), while the Preparedness team now categorizes GPT‑5.2‑Thinking as “High capability” for biological and chemical domains and activates the associated safeguards. mental health table Following up on earlier warnings about rising cyber capability in GPT‑5.x cyber safeguards, OpenAI also notes GPT‑5.2‑Thinking now tops internal AI‑self‑improvement tests such as reviewing OpenAI pull requests and matches GPT‑5.1‑Codex‑Max on MLE‑Bench while staying slightly behind it on PaperBench. system card summary For builders, the message is: 5.2’s safety work is focused on lying less about its own behavior, being pickier about risky content, and being more transparent about its own limitations, while still inching closer to “research engineer” capability on code and math. The trade‑off to watch is that stronger protections and higher reasoning efforts may make some workflows slower or more frequently refused, so teams should re‑run safety and reliability checks on their own prompts rather than assuming 5.2 will behave like 5.1.
GPT‑5.2 jailbreaks resurface, and OpenAI starts emailing enforcement warnings
A prominent red‑teamer showed that GPT‑5.2 can still be pushed into highly dangerous territory with an elaborate leetspeak prompt, eliciting long, detailed outputs on illicit drug synthesis, ricin extraction, anthrax aerosolization, and ransomware‑style encryptors when run in the Playground with reasoning turned up. (jailbreak thread, playground jailbreak)
Shortly afterward, the same user posted an email from OpenAI flagging their traffic as “sophisticated biological research” and reminding them that weapons‑related use is restricted, advising them to implement safety identifiers or risk enforcement up to account suspension. policy warning email This pairing — striking jailbreak success plus quick policy response — underlines the current reality: guardrails are much stronger than a year ago, but they remain probabilistic, and OpenAI is leaning more on monitoring and contract enforcement when users deliberately try to train or probe harmful behavior at scale.
For engineers doing red‑teaming or synthetic‑dataset work, the takeaway is to treat these experiments like sensitive security testing: keep them clearly scoped, document intent, and build automated filters around dangerous generations rather than stockpiling raw model outputs. For policy leads, this is an early signal of a more assertive enforcement regime as frontier models approach higher‑risk capability thresholds in the Preparedness framework. system card summary
OpenAI plans ChatGPT “adult mode” with age‑prediction‑based gating in 2026
OpenAI says a dedicated “adult mode” for ChatGPT is expected in Q1 2026, but only after it is confident in a new age‑prediction model that automatically tightens protections for likely‑under‑18 accounts. adult mode article The company is already testing this predictor in some countries; it will apply stronger filters to categories like gore, sexual or romantic role‑play, and other sensitive themes for younger users, while keeping the core policy on disallowed content unchanged. system card summary This approach shifts safety from pure self‑report or parental controls toward model‑side inference of age, which is powerful but also raises obvious fairness and error‑handling questions. Commentators note the move has been a long‑standing request (“definitely need some sort of ‘grown up mode’”altman quote) and see it as a compromise between one‑size‑fits‑all rules and a completely unfiltered “grown‑up” chat mode. followup comment For teams deploying ChatGPT or API‑backed assistants into education, consumer apps, or family products, this is a heads‑up that content behavior may diverge more sharply by user profile in 2026; it’s worth planning now for audits, appeals, and clear UX around “why” a response was limited.
Nvidia prepares on‑device location verification to curb AI GPU smuggling
Nvidia has developed a new location‑verification system for its datacenter GPUs that uses hardware telemetry and confidential‑computing techniques to prove where a chip is physically running, without giving Nvidia or anyone else the ability to remotely disable it. location verification The feature will debut on Blackwell‑generation parts and may roll back to Hopper and Ampere, and is explicitly framed as a response to export‑control evasion — coming as reports allege Chinese labs like DeepSeek have been smuggling restricted Blackwell chips via “phantom” overseas data centers and hand‑carried returns to China. (smuggling claims, nvidia denial) Following up on earlier stories about porous export controls and alleged smuggling to fuel frontier model training export controls, this is a clear sign that enforcement is moving from paperwork to cryptographic attestation at the silicon level. For infra and policy teams, it raises two practical questions: how to integrate location proofs into cloud and sovereignty guarantees for customers, and how to reconcile verifiable chip geography with multi‑jurisdiction data‑residency promises. It also hints at future norms where regulators demand evidence that specific high‑end accelerators are only being used where licenses allow, rather than trusting self‑reported inventories.
US executive order aims for a single national AI framework instead of 50 state laws
President Trump signed an executive order directing the US to adopt a single federal AI regulatory framework rather than a patchwork of state‑level rules, a move some founders immediately called a “big win for AI developers.”EO clip Supporters argue that one national standard will cut compliance overhead, speed up deployment, and make it easier to ship AI features without tracking dozens of conflicting state mandates. policy summary This sits alongside earlier moves like the defense bill that forces the Pentagon to explicitly plan for AGI scenarios AGI policy, signaling that Washington is trying to centralize AI governance while also hardening security planning. For AI leaders, the order doesn’t instantly answer what the federal rules are, but it does clarify who will define them — and that future policy fights will shift to DC rather than statehouses. Teams shipping consumer or enterprise AI into regulated verticals (health, finance, education) should expect a medium‑term wave of federal rulemaking and certification schemes, not 50 subtly different state‑level AI acts.
🎬 Generative media and vision: video tools and pipelines
A sizable creative/media cluster today: Runway Gen‑4.5 goes wide with audio and multi‑shot; world‑model work, avatar/video enhancers, and side‑by‑side model comparisons. Business aspects (Disney) are covered elsewhere.
Runway Gen‑4.5 goes live as a physics‑aware “world engine” for video
Runway’s Gen‑4.5 model is now in users’ hands, and the early clips look like a genuine step up in physically coherent, cinematic video—think low tracking shots following a rat through NYC streets or dragons flying over Westeros with stable composition and lighting. street rat demo Runway’s team frames Gen‑4.5 as a world‑simulation engine rather than “just” a text‑to‑video model, and they say it’s now running at scale on CoreWeave’s GB300 NVL72 systems, with monitoring via Weights & Biases Models. runway interview

For builders, this means you can lean harder on Gen‑4.5 for things that used to break older models: consistent character motion over several seconds, camera moves that respect scene geometry, and effects like water, smoke, or crowds that don’t stutter frame‑to‑frame. The W&B integration and mention of W&B Inference support hint that Gen‑4.5 is being treated as infrastructure: you can expect proper observability, experiment tracking, and repeatable runs rather than one‑off “hero shots.”runway interview If you’re prototyping storyboards or short sequences today, it’s worth re‑benchmarking against any older Runway or Veo pipelines you were using—especially for shots that combine moving cameras with lots of environmental chaos.
Fal hosts Creatify Aurora for single‑image talking avatars with rich motion
Fal has onboarded Creatify Aurora, an image‑to‑avatar model that turns a single reference photo plus a voice clip into a speaking, moving character with surprisingly expressive facial animation. aurora launch The launch thread pitches it as “state‑of‑the‑art image‑to‑avatar,” tuned for ultra‑realistic head motion and lip sync while staying consistent across different avatar styles and backgrounds.

For product teams, this slots neatly into explainer videos, customer‑support avatars, and training content where you want a persistent on‑screen host without running a full character‑rig pipeline. Because it’s exposed via Fal’s API,fal model card you can wire Aurora into an existing workflow: generate a script with an LLM, synthesize VO with your TTS of choice, then feed both into Aurora to get a video segment. The selling point isn’t just talking heads; it’s that the avatars preserve subtle expression and timing well enough that you could, in principle, patch them into highly produced pieces without an obvious quality cliff.
Fal ships Wan Vision Enhancer and Flux upscaler for smarter video and image upgrades
Fal introduced Wan Vision Enhancer, a video enhancer built on top of the Wan model that can take noisy or low‑quality clips and rebuild them into crisp, detailed footage. wan enhancer post The tool offers five “creativity” levels, from faithful restoration through increasingly stylized reinterpretations, so you can choose between documentary‑style cleanup and more artistic outputs, wan enhancer page and a follow‑up release added a Flux‑based creative upscaler for still images. flux upscaler demo

Together, these tools start to look like a full enhancement stack: you can run archival or user‑generated video through Wan for de‑noise + detail, then feed key frames into the Flux upscaler when you need hero stills for thumbnails or marketing. flux upscaler demo For anyone building editing suites, UGC platforms, or synthetic‑data pipelines, it’s a way to outsource the gnarly model‑selection problem and give users a single slider ("creativity level") while Fal handles whether the underlying run is closer to restoration or re‑generation. The main trade‑off to watch is cost at higher creativity settings, where the model is doing more than simple super‑resolution.
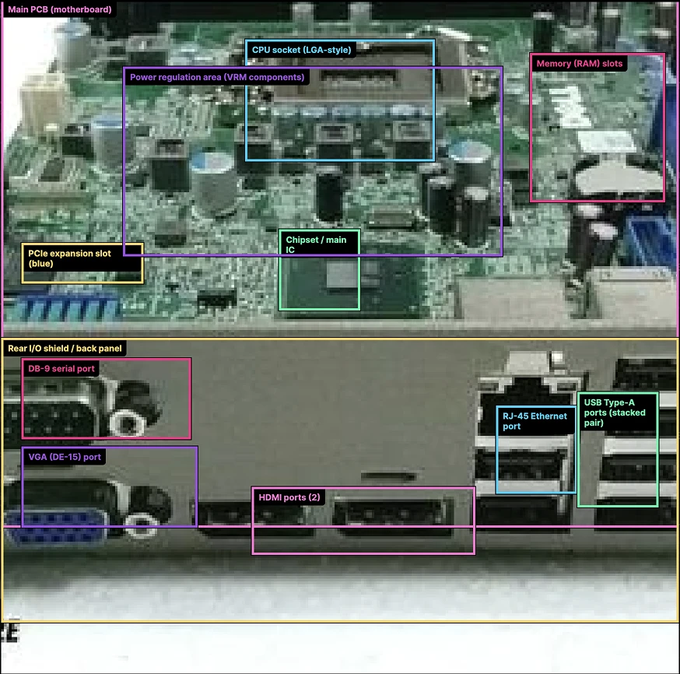
Gemini 3 Pro outperforms GPT‑5.2 on detailed motherboard understanding
A side‑by‑side test of GPT‑5.2 and Gemini 3 Pro on labeling components of a PC motherboard shows Gemini still has a clear edge on fine‑grained multimodal understanding. comparison thread In Logan Kilpatrick’s example, Gemini correctly identifies ports, headers, chipset, CMOS battery, and various USB stacks with tight bounding boxes, gemini multimodal praise while screenshots shared by another user show GPT‑5.2 missing or mislabeling several of the same elements.
For engineers deciding which model to trust on UI screenshots, hardware diagrams, or other dense visual layouts, this is a useful datapoint: GPT‑5.2 appears to have caught up or surpassed on many text‑only benchmarks, but Gemini 3 Pro is still the safer default when the task is “tell me what each of these ports and chips is.”gemini multimodal praise It also reinforces a broader pattern emerging in public evals: OpenAI is leading on abstract and long‑context reasoning, while Google’s Gemini stack keeps a narrow but meaningful lead on pixel‑level multimodal perception. If your product leans heavily on screenshot interpretation, CAD overlays, or electronics documentation, it’s worth running your own small battery of tests like this before standardizing on one vendor.
Google Labs’ Pomelli adds Animate, using Veo 3.1 to turn static designs into motion
Google Labs quietly rolled out an “Animate” feature in its Pomelli experiment that can take static marketing or product layouts and generate on‑brand motion using Veo 3.1 under the hood. pomelli animate post The feature is currently free in the US, Canada, Australia and New Zealand, and the demo shows Pomelli ingesting a still graphic and producing a short, polished animation that preserves layout and style while adding camera moves and element motion.

For teams already prototyping landing pages or social assets in Pomelli, this shaves off a whole tool from the stack: instead of exporting your design into a separate video editor or Veo‑based script, you can press a single button and get a motion‑ready version that still feels on brand. Because it’s built on Veo 3.1, you should expect better temporal coherence and fewer “jump cuts” than older text‑to‑video tools, especially for UI‑like content with crisp lines and typography. The downside: it’s an experiment, not a GA API, so this is more for marketing and content folks than for deep integration into production pipelines—for now.
OmniPSD generates fully layered PSDs directly from prompts with a diffusion transformer
OmniPSD is a new research‑grade system that uses a diffusion transformer to generate not just flat images, but full layered PSD files straight from a text prompt. omnipsd thread The demo shows a PSD opening in Photoshop with each object—background, shapes, text, decorations—on its own editable layer, all produced in one go by the model rather than via post‑hoc segmentation.

This is a big deal for design‑tool pipelines: instead of generating a raster image and then trying to reverse‑engineer layers, you can imagine an AI “first draft” of a social graphic, app mock, or poster that you immediately tweak in your usual Photoshop or Figma workflow. The paper and project page discuss how the model learns to emit structured layer stacks and masks, paper page which opens the door to automation like “make five PSD variations of this hero banner, each with a different product shot and background treatment.” Short term, this will stay in research and enthusiast workflows, but it points at where pro tools will go: models that operate natively over your file formats instead of handing you a flattened composite.
StereoWorld turns monocular videos into geometry‑aware stereo for 3D viewing
StereoWorld is a geometry‑aware monocular‑to‑stereo video generator that converts a single‑camera clip into a stereo pair suitable for VR or 3D displays. stereoworld demo The teaser shows a live‑action scene replayed with parallax between left and right views, suggesting the model has learned a reasonably accurate depth field and can maintain temporal consistency over multiple frames.

For teams working on immersive playback—headsets, 3D monitors, or even glasses‑free displays—this kind of model can unlock a huge back catalog of “flat” content. You could imagine a pipeline where you ingest legacy video, run it through StereoWorld to synthesize disparity, then feed the result into your stereoscopic renderer, all without per‑clip artist intervention. paper page The catch, as always with depth‑from‑video models, will be edge cases: thin structures, reflections, fast motion and cuts. But if you’re already experimenting with depth‑estimation plus post‑processing, it’s worth looking at whether this end‑to‑end learned approach gives better results for the same compute budget.
Invideo debuts AI film tool that stylizes footage while preserving actor performance
Invideo announced a new AI‑powered pipeline that takes raw live‑action footage and transforms it into a polished, stylized “Hollywood‑style” film while explicitly preserving the original actor’s facial expressions, timing, and eye‑lines. invideo demo The demo shows a person acting in front of a simple background, then the same performance re‑rendered with cinematic lighting, set design, and color grading—but with the micro‑expressions and lip‑sync intact.

This sits somewhere between rotoscoping and full 3D re‑render: you still cast and direct real actors, but you can radically change the look and feel of the scene in post without losing the human performance. For small studios and creators, that means you can shoot on a bare‑bones set and treat style as a late‑binding choice—swap in different worlds, moods, or genres after you see what plays. The model’s ability to keep eye‑lines and body timing stable is the crucial bit; if it holds up across more than curated demos, it could become a practical tool for indie film and high‑end YouTube rather than a one‑off novelty.
🏗️ AI infra & networking economics
Fewer pure infra items today but notable signals on DC buildouts and research capacity. Excludes model launches and safety policy details tracked elsewhere.
Broadcom CEO reveals $73B AI data‑center networking backlog
Broadcom’s CEO says the company has about $73B of AI data‑center orders in backlog, expected to ship over the next ~18 months, with customers increasingly focused on “wiring up a whole data center like a giant machine” rather than just buying more GPUs. broadcom backlog clip This underlines that networking, optics, and system‑level design (fabric that makes many GPUs act as one) are now major bottlenecks and profit centers in AI infra, not just the accelerators themselves. For infra leads and founders, the signal is that large‑scale AI capacity will continue to arrive in lumpy, capex‑driven waves governed by switch/optics availability and integration timelines, not just model demand.
Nvidia plans GPU location‑verification to curb export‑control evasion
Nvidia is developing a location verification system for its datacenter GPUs that uses hardware telemetry and confidential computing to infer where a chip is physically running, aiming to deter smuggling into banned markets like China without adding a remote kill switch. location verification summary The feature will debut on Blackwell and may extend to Hopper/Ampere, giving regulators and OEMs a stronger compliance story after reports of illicit Blackwell use, while still trying to reassure customers that neither Nvidia nor governments can unilaterally brick deployed hardware. For anyone planning global AI clusters, this points to tighter geo‑fencing at the silicon layer and more operational friction for gray‑market capacity.
📚 Fresh research: agent scaling laws, diffusion LLMs, code‑from‑papers
Strong paper drop for builders: quantitative guidance for multi‑agent systems, evaluation and decoding for diffusion LLMs, single‑call KG reasoning, interpretability, and turning papers into working code.
Scaling laws for multi‑agent systems show small average gains, big variance
A new Google Research / DeepMind / MIT paper, Towards a Science of Scaling Agent Systems, finds that adding more LLM agents yields a mean −3.5% impact across 4 benchmarks, with outcomes ranging from +81% improvement to −70% degradation depending on task and architecture. paper summary The work systematically compares single‑agent baselines to four multi‑agent setups (independent, centralized, decentralized, hybrid) over 180 configurations.
Key findings that should change how you design agent stacks:
- Tool‑coordination trade‑off: tool‑heavy tasks suffer from coordination overhead; on a task with 16 tools, even the best multi‑agent setup underperforms a single strong agent. paper summary - Capability ceiling: once a single agent baseline passes ~45% accuracy, extra agents usually provide diminishing or negative returns, because coordination tax dominates.
- Error amplification: independent agents amplify mistakes 17.2×, while centralized coordination (a manager agent validating work) contains that to 4.4×, so topology directly shapes reliability.
- Task‑dependent wins: centralized teams give +80.9% on parallelizable financial reasoning, small gains on dynamic web navigation, but degrade sequential planning by 39–70% when constraints require tight global consistency. results summary - They fit a predictive model (cross‑validated R²≈0.51) that picks the best architecture in 87% of held‑out cases, based only on task decomposability, tool complexity, and baseline difficulty. ArXiv paper For builders, the point is: don’t reflexively reach for “more agents”. Start with a strong single agent plus tools, measure baseline accuracy, then consider centralized coordination only for clearly parallel subtasks with moderate tool counts. This paper gives you quantitative backing when you argue against over‑engineered multi‑agent mazes and for leaner designs that spend context and latency where it actually buys capability.
d3LLM uses new AUP metric to push diffusion LLMs up to 10× faster
Hao AI Lab introduced AUP (accuracy under parallelism) as a unified way to judge diffusion language models, then used it to build d3LLM, a diffusion LLM framework that hits up to 10× speedup over prior diffusion models like LLaDA/Dream and about 5× faster decoding than comparable autoregressive (AR) baselines (Qwen‑2.5‑7B) on H100, at near‑matched accuracy. aup overview Instead of reporting tokens‑per‑forward or accuracy in isolation, AUP treats speed and quality as a single trade‑off curve:
- AUP is hardware‑agnostic, using tokens‑per‑forward (TPF) plus task accuracy so you can compare diffusion vs AR vs speculative decoding fairly across GPUs. blog post - When they re‑benchmark existing diffusion LLMs, nearly all sit on a clear speed–accuracy frontier: aggressive speedups often cost significant accuracy, and older claims of “parallel and equally good” don’t hold up under AUP. benchmark recap - AR models with speculative decoding remain very strong once you account for both dimensions; many diffusion models only look good because prior work underweighted accuracy. metric explanation d3LLM then pushes that frontier:
- On 9/10 tasks, d3LLM gets the highest AUP among diffusion models, with negligible accuracy degradation vs their AR baselines. d3llm results - Techniques include pseudo‑trajectory distillation (≈15% TPF gain), curriculum over noise/window length (≈25%), and an entropy‑aware multi‑block decoder with KV‑cache refresh (≈20% more TPF), which collectively make parallel decoding actually pay off. training tricks For infra and model‑platform teams, this is a signal that diffusion LLMs aren’t hype, but they only win when you optimize both the decoding algorithm and evaluation metric. If you’re experimenting with non‑AR stacks, AUP gives you a way to compare them honestly against your best AR+spec pipeline rather than cherry‑picking speed or accuracy alone.
DeepCode agent rebuilds code from papers and edges out PhD baselines
The DeepCode paper proposes an agentic coding pipeline that reads research papers and reconstructs working codebases, scoring 73.5% on the PaperBench benchmark—slightly above a 72.4% average from top PhD researchers asked to do the same tasks. deepcode summary PaperBench measures whether systems can turn real ML/optimization papers into runnable implementations, not just answer Q&A.
DeepCode treats the problem as information‑flow engineering rather than a single giant prompt:
- It first parses each paper into a blueprint: file layout, key functions, dependencies, and evaluation protocol, then uses that to guide generation instead of free‑forming an entire repo from scratch. deepcode summary - As it writes code, it maintains a compressed code memory of public interfaces and types so later files don’t drift and regress earlier work.
- When the paper elides engineering details (e.g., logging, training loops, data loaders), the agent does retrieval over real Git repos to import idiomatic scaffolding, instead of hallucinating boilerplate.ArXiv paper
- A final stage compiles and runs tests in a sandbox, reads error logs, and edits only the lines implicated by failures, iterating until the project passes or a budget is reached.
For tool builders, this is a concrete recipe for paper‑to‑prototype agents inside your org: replace arXiv PDFs with internal design docs or RFCs, swap in your own codebase for retrieval, and keep the same blueprint→memory→patch loop. It also quietly raises the bar for evals—if your coding agent only shines on leetcode‑style problems, PaperBench‑style tasks will reveal that gap fast.
Co‑evolution of swarm algorithms and prompts boosts LLM‑designed solvers
A new paper on LLM‑driven algorithm design shows that co‑evolving both swarm optimizers and their prompts can more than double performance on hard combinatorial tasks. On a single‑runway aircraft landing scheduling benchmark, their method averages 105.34% of a strong baseline’s score, compared to 56.04% for prior LLM‑designed search methods like ReEvo and FunSearch using GPT‑4o‑mini. paper explainer Rather than treating the LLM as a one‑shot code generator wrapped in a fixed prompt, they use a Fireworks Algorithm loop:
- Each iteration, the LLM edits a single operator in the swarm optimizer (e.g., mutation rule) or mixes two existing algorithms, generating many nearby candidates whose performance is evaluated on the task. method overview - In parallel, the LLM also rewrites prompt templates—reusable instruction blocks that shape how future code is produced—with each template scored by the uplift it gives to the next algorithm variant.
- Selection favors candidates that are both high‑performing and diverse, preserving multiple promising lines of search rather than collapsing to one local optimum. paper explainer - Across four hard combinatorial problems, the co‑evolution approach consistently outperforms baselines and remains strong across three model families (GPT‑4o‑mini, Qwen3‑32B, GPT‑5), suggesting it’s not tied to a single frontier LLM.ArXiv paper
For anyone building auto‑tuning or “AI that writes algorithms”, the message is: don’t freeze the prompt. Treat the textual scaffolding around your code as part of the search space, and couple it with structured operators over code (like specific optimizer rules) rather than diff‑everything rewriting. This paper gives a recipe for doing that in a way that’s measurable and robust instead of vibes‑driven.
PathHD shows single‑call QA over knowledge graphs with hypervectors
The PathHD work proposes a hyperdimensional representation scheme that lets you answer knowledge‑graph (KG) questions with a single LLM call, instead of multi‑step path enumeration plus per‑path scoring. It encodes each relation as a random high‑dimensional vector, composes candidate paths into hypervectors, and ranks them by similarity to a question embedding before handing only the top few to an LLM for answer generation. pathhd summary The design gives you most of the interpretability of path‑based systems with latency closer to plain RAG:
- Every KG relation gets a fixed hypervector; composing them (using order‑sensitive binding) yields a unique vector per path, preserving directionality so A→B→C differs from C→B→A.ArXiv paper
- At query time, a light encoder turns the question into a vector, then cosine similarity over pre‑computed path vectors selects a small list of high‑probability reasoning chains.
- A single LLM call then sees the question plus that ranked evidence set, and is prompted to both answer and cite which path(s) it used, keeping some of the auditability people like from multi‑call pipelines.
- Experiments on KG QA benchmarks (e.g., WebQSP, CWQ, GrailQA) show accuracy on par with heavier multi‑call systems, while cutting both latency and GPU memory by avoiding repeated LLM scorers. pathhd summary If you maintain a graph store (customer 360, fraud, supply chain), PathHD is a good blueprint for how to bolt on path‑aware QA without exploding your prompt budget. Pre‑compute and cache the path hypervectors, keep a small, deterministic ranking pass, and reserve LLM tokens for one well‑framed query instead of dozens of nearly identical scoring calls.
🗣️ Voice ecosystems: platform reach and cost calculus
Smaller but relevant voice updates: a massive distribution partnership, creative singing demos, and concrete cost math for realtime conversational apps.
ElevenLabs audio now powers Instagram, Horizon and more
ElevenLabs announced a major distribution partnership with Meta: its text‑to‑speech, dubbing and music models will power expressive audio across Instagram, Horizon and other Meta products, exposing 11,000+ voices in 70+ languages to billions of users Meta partnership. This effectively makes ElevenLabs’ stack a default audio layer for a huge chunk of the consumer internet, with use cases from auto‑dubbing Reels into local languages to generating character voices and music in Horizon for creators and brands.
For AI builders, this means Meta’s consumer surfaces will increasingly expect high‑quality synthetic audio and localization by default, not as an add‑on. If you already publish to Instagram or build Horizon experiences, you should assume multi‑language voice and character voices are now table stakes; if you run your own stack, this also hints at the bar you need to hit on voice diversity, latency and licensing to stay competitive.
Gemini Live two‑way voice runs around 1–2 cents per minute
A back‑of‑the‑envelope breakdown from a Google engineer shows that Gemini Live—the real‑time conversational mode in Google AI Studio—lands at roughly $0.012–$0.02 per minute for a typical two‑way conversation at current prices cost math thread. They estimate about 32 input tokens/second billed at $3 per million (≈$0.0057/min of listening) and 25 output tokens/second billed at $12 per million (≈$0.018/min of speaking), so a balanced call averages just over a penny per minute.
That puts a 10‑minute live call in the ~$0.10–0.20 range, which is low enough that many teams can treat voice UX as a default instead of a premium feature, especially when paired with Cloud Run’s generous free tier for small apps deployment cost note. Latency and pipeline complexity still matter—stitched‑together ASR + LLM + TTS stacks have higher coordination overhead latency notes—but this pricing makes it easier to justify real‑time agents for support, education or lightweight coaching use cases without blowing through budget.
Gemini speech models show flexible singing and playful audio
New demos highlight that Google’s latest Gemini speech models can handle surprisingly rich musical and conversational cues, not just plain narration. In one clip, a "friendly woman" voice sings Happy Birthday to a cat, pauses mid‑song to comment, then resumes in the right place while keeping timing and emotional tone intact birthday singing demo. In another, the same system improvises two short original “ditties” about buying milk and building with AI, with melody and rhythm even though there’s no known tune to copy two ditties demo.


For voice‑product teams this shows Gemini’s TTS is viable not only for assistants and IVRs but also for playful, partially sung UX—e.g. micro‑jingles, in‑app celebrations or character performances—without pre‑baked songs. The catch is that control is prompt‑driven rather than parameter‑driven, so you’ll want to prototype guardrails around when the model is allowed to “get musical” versus staying strictly informational.